How Huggy works
Huggy is a Deep Reinforcement Learning environment made by Hugging Face and based on Puppo the Corgi, a project by the Unity MLAgents team. This environment was created using the Unity game engine and MLAgents. ML-Agents is a toolkit for the game engine from Unity that allows us to create environments using Unity or use pre-made environments to train our agents.
In this environment we aim to train Huggy to fetch the stick we throw. This means he needs to move correctly toward the stick.
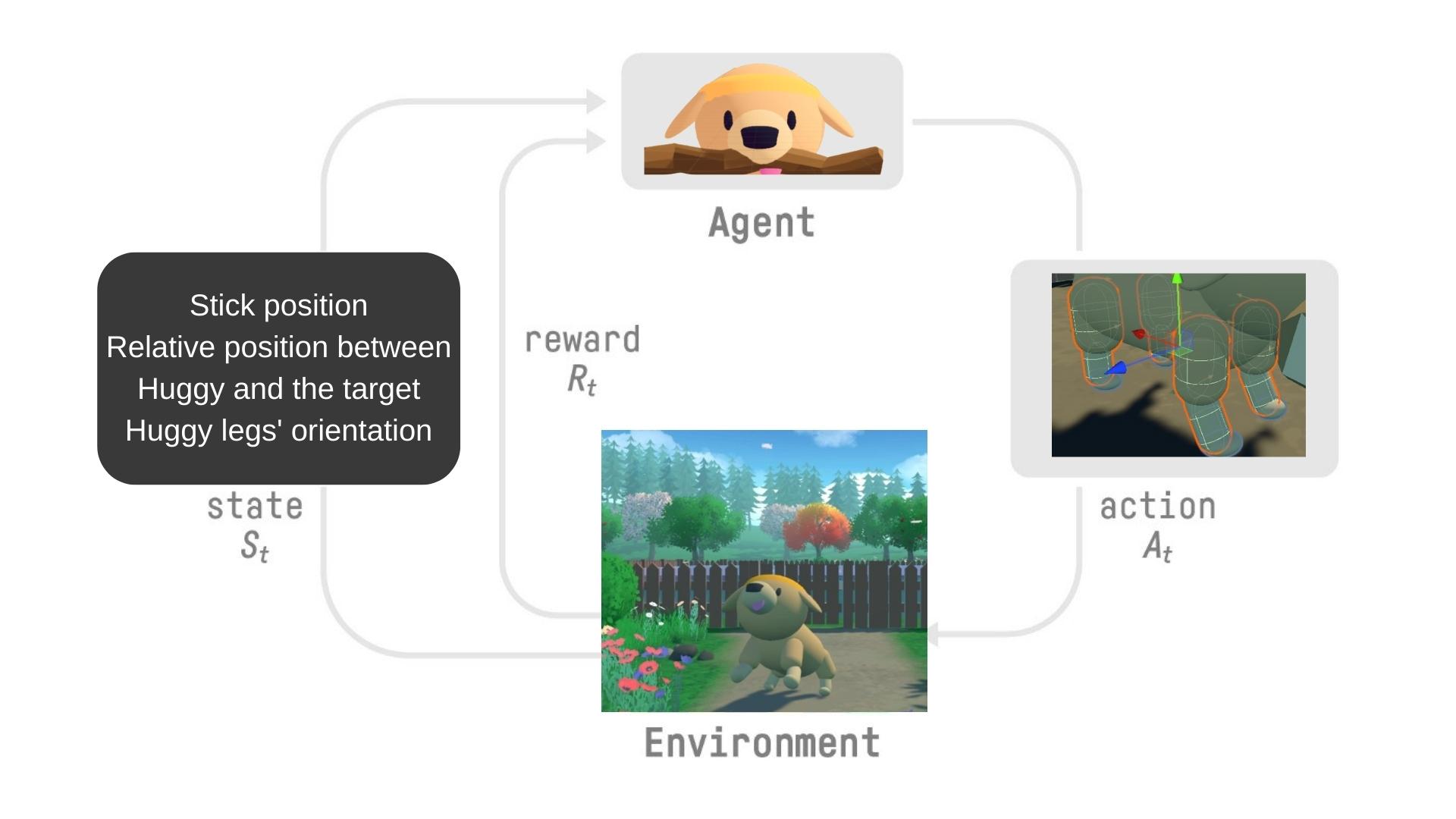
The State Space, what Huggy perceives.
Huggy doesn’t “see” his environment. Instead, we provide him information about the environment:
- The target (stick) position
- The relative position between himself and the target
- The orientation of his legs.
Given all this information, Huggy can use his policy to determine which action to take next to fulfill his goal.
The Action Space, what moves Huggy can perform

Joint motors drive Huggy’s legs. This means that to get the target, Huggy needs to learn to rotate the joint motors of each of his legs correctly so he can move.
The Reward Function
The reward function is designed so that Huggy will fulfill his goal: fetch the stick.
Remember that one of the foundations of Reinforcement Learning is the reward hypothesis: a goal can be described as the maximization of the expected cumulative reward.
Here, our goal is that Huggy goes towards the stick but without spinning too much. Hence, our reward function must translate this goal.
Our reward function:

- Orientation bonus: we reward him for getting close to the target.
- Time penalty: a fixed-time penalty given at every action to force him to get to the stick as fast as possible.
- Rotation penalty: we penalize Huggy if he spins too much and turns too quickly.
- Getting to the target reward: we reward Huggy for reaching the target.
If you want to see what this reward function looks like mathematically, check Puppo the Corgi presentation.
Train Huggy
Huggy aims to learn to run correctly and as fast as possible toward the goal. To do that, at every step and given the environment observation, he needs to decide how to rotate each joint motor of his legs to move correctly (not spinning too much) and towards the goal.
The training loop looks like this:
The training environment looks like this:

It’s a place where a stick is spawned randomly. When Huggy reaches it, the stick get spawned somewhere else. We built multiple copies of the environment for the training. This helps speed up the training by providing more diverse experiences.
Now that you have the big picture of the environment, you’re ready to train Huggy to fetch the stick.
To do that, we’re going to use MLAgents. Don’t worry if you have never used it before. In this unit we’ll use Google Colab to train Huggy, and then you’ll be able to load your trained Huggy and play with him directly in the browser.
In a future unit, we will study MLAgents more in-depth and see how it works. But for now, we keep things simple by just using the provided implementation.
< > Update on GitHub