(Optional) What is Curiosity in Deep Reinforcement Learning?
This is an (optional) introduction to Curiosity. If you want to learn more, you can read two additional articles where we dive into the mathematical details:
- Curiosity-Driven Learning through Next State Prediction
- Random Network Distillation: a new take on Curiosity-Driven Learning
Two Major Problems in Modern RL
To understand what Curiosity is, we first need to understand the two major problems with RL:
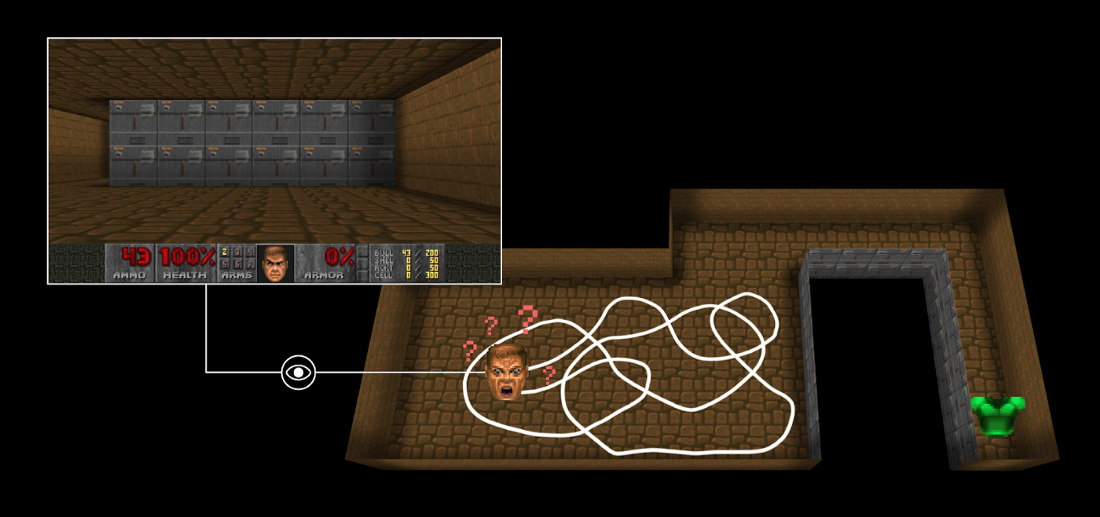
First, the sparse rewards problem: that is, most rewards do not contain information, and hence are set to zero.
Remember that RL is based on the reward hypothesis, which is the idea that each goal can be described as the maximization of the rewards. Therefore, rewards act as feedback for RL agents; if they don’t receive any, their knowledge of which action is appropriate (or not) cannot change.

For instance, in Vizdoom, a set of environments based on the game Doom “DoomMyWayHome,” your agent is only rewarded if it finds the vest. However, the vest is far away from your starting point, so most of your rewards will be zero. Therefore, if our agent does not receive useful feedback (dense rewards), it will take much longer to learn an optimal policy, and it can spend time turning around without finding the goal.
The second big problem is that the extrinsic reward function is handmade; in each environment, a human has to implement a reward function. But how we can scale that in big and complex environments?
So what is Curiosity?
A solution to these problems is to develop a reward function intrinsic to the agent, i.e., generated by the agent itself. The agent will act as a self-learner since it will be the student and its own feedback master.
This intrinsic reward mechanism is known as Curiosity because this reward pushes the agent to explore states that are novel/unfamiliar. To achieve that, our agent will receive a high reward when exploring new trajectories.
This reward is inspired by how humans act. We naturally have an intrinsic desire to explore environments and discover new things.
There are different ways to calculate this intrinsic reward. The classical approach (Curiosity through next-state prediction) is to calculate Curiosity as the error of our agent in predicting the next state, given the current state and action taken.

Because the idea of Curiosity is to encourage our agent to perform actions that reduce the uncertainty in the agent’s ability to predict the consequences of its actions (uncertainty will be higher in areas where the agent has spent less time or in areas with complex dynamics).
If the agent spends a lot of time on these states, it will be good at predicting the next state (low Curiosity). On the other hand, if it’s in a new, unexplored state, it will be hard to predict the following state (high Curiosity).

Using Curiosity will push our agent to favor transitions with high prediction error (which will be higher in areas where the agent has spent less time, or in areas with complex dynamics) and consequently better explore our environment.
There’s also other curiosity calculation methods. ML-Agents uses a more advanced one called Curiosity through random network distillation. This is out of the scope of the tutorial but if you’re interested I wrote an article explaining it in detail.
< > Update on GitHub