Deep RL Course documentation
The Reinforcement Learning Framework
The Reinforcement Learning Framework
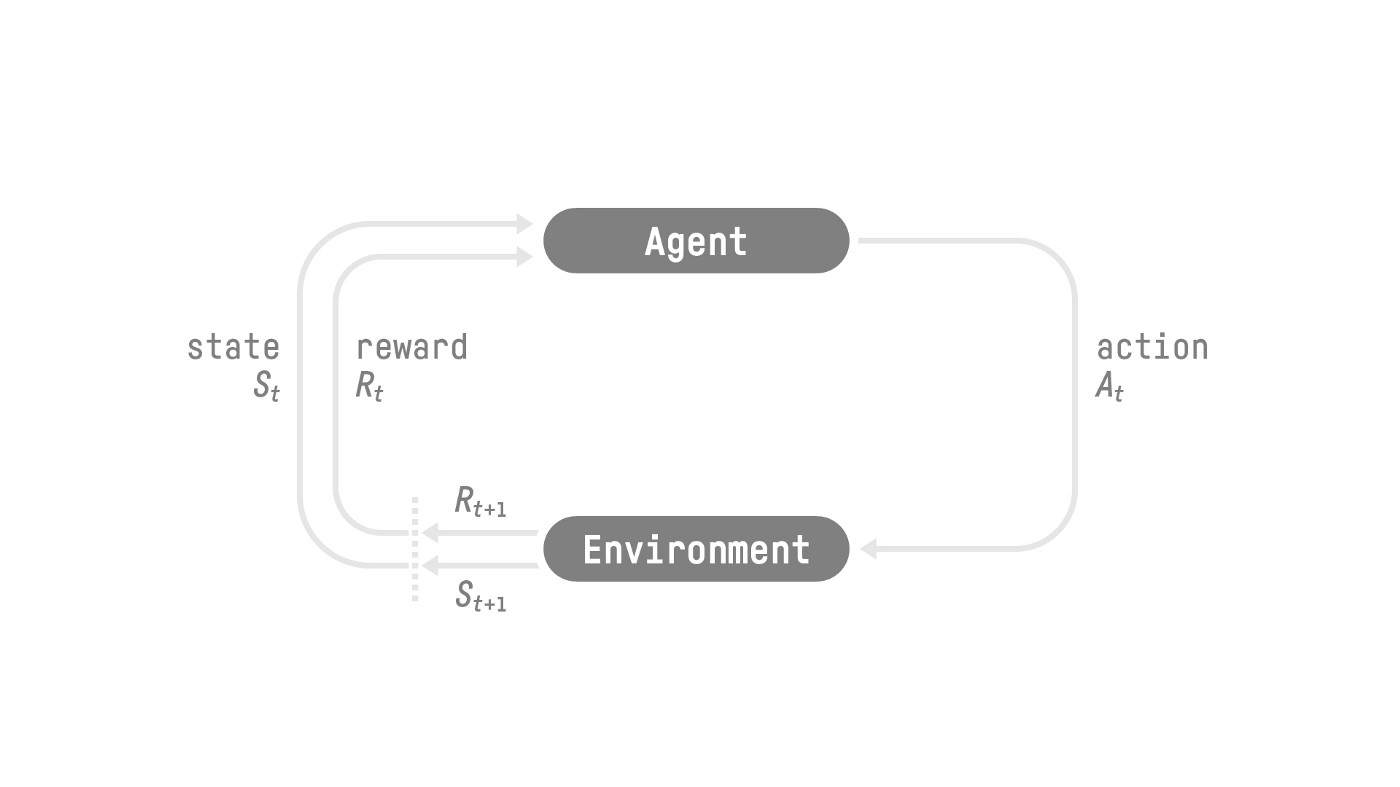
The RL Process
To understand the RL process, let’s imagine an agent learning to play a platform game:
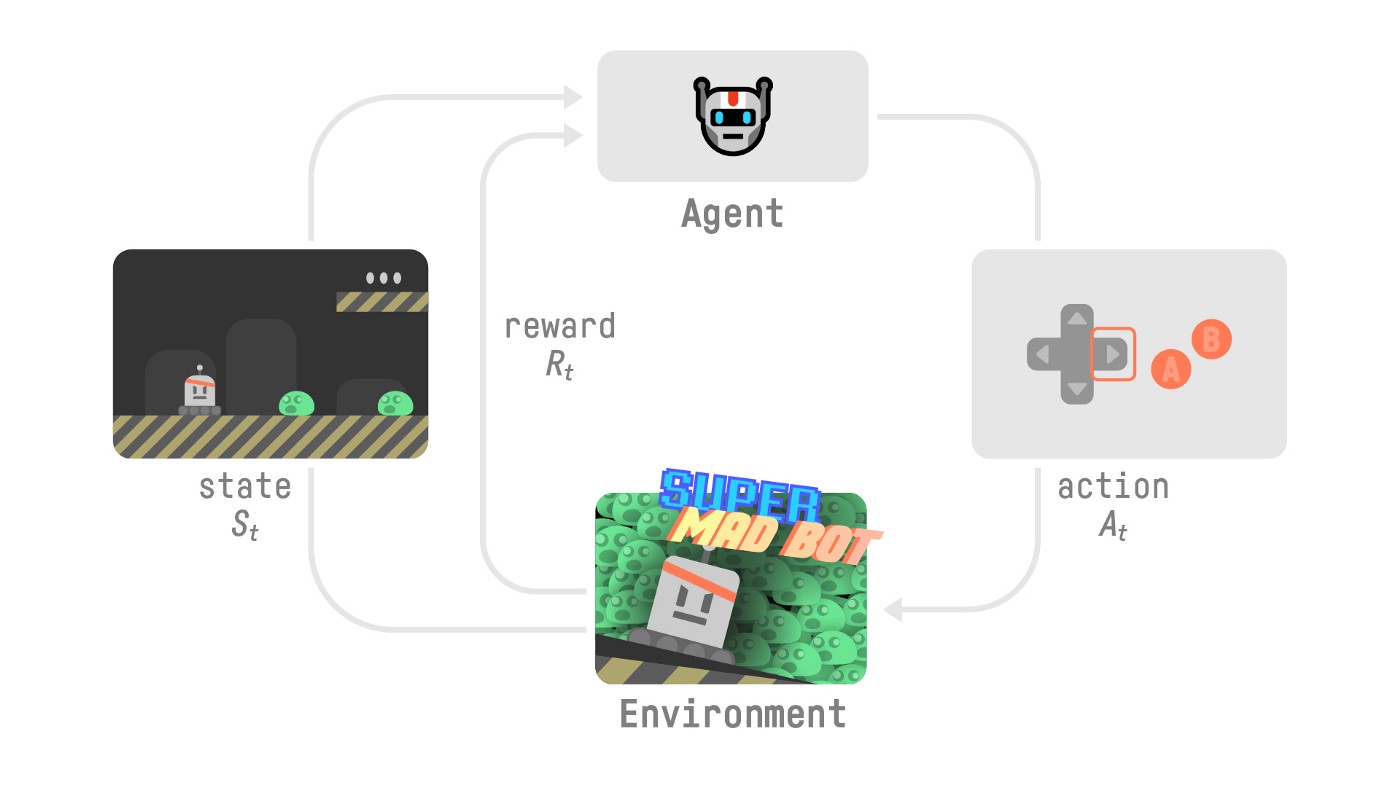
- Our Agent receives state from the Environment — we receive the first frame of our game (Environment).
- Based on that state, the Agent takes action — our Agent will move to the right.
- The environment goes to a new state — new frame.
- The environment gives some reward to the Agent — we’re not dead (Positive Reward +1).
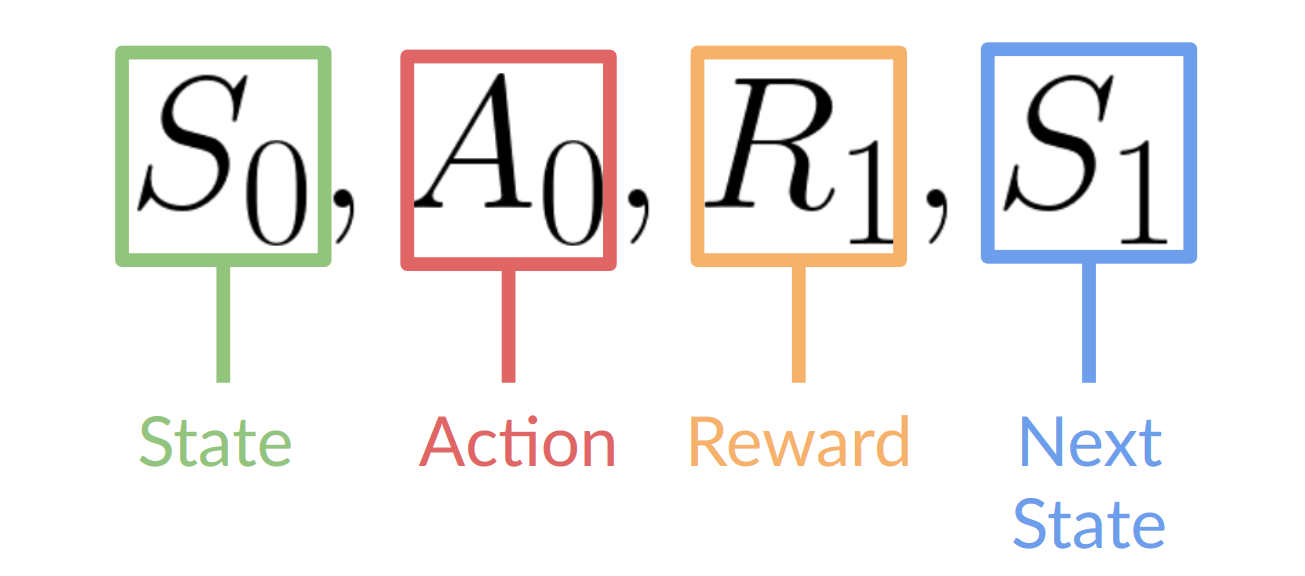
This RL loop outputs a sequence of state, action, reward and next state.
The agent’s goal is to maximize its cumulative reward, called the expected return.
The reward hypothesis: the central idea of Reinforcement Learning
⇒ Why is the goal of the agent to maximize the expected return?
Because RL is based on the reward hypothesis, which is that all goals can be described as the maximization of the expected return (expected cumulative reward).
That’s why in Reinforcement Learning, to have the best behavior, we aim to learn to take actions that maximize the expected cumulative reward.
Markov Property
In papers, you’ll see that the RL process is called a Markov Decision Process (MDP).
We’ll talk again about the Markov Property in the following units. But if you need to remember something today about it, it’s this: the Markov Property implies that our agent needs only the current state to decide what action to take and not the history of all the states and actions they took before.
Observations/States Space
Observations/States are the information our agent gets from the environment. In the case of a video game, it can be a frame (a screenshot). In the case of the trading agent, it can be the value of a certain stock, etc.
There is a differentiation to make between observation and state, however:
- State s: is a complete description of the state of the world (there is no hidden information). In a fully observed environment.

In a chess game, we have access to the whole board information, so we receive a state from the environment. In other words, the environment is fully observed.
- Observation o: is a partial description of the state. In a partially observed environment.

In Super Mario Bros, we only see the part of the level close to the player, so we receive an observation.
In Super Mario Bros, we are in a partially observed environment. We receive an observation since we only see a part of the level.
To recap:

Action Space
The Action space is the set of all possible actions in an environment.
The actions can come from a discrete or continuous space:
- Discrete space: the number of possible actions is finite.
Again, in Super Mario Bros, we have a finite set of actions since we have only 4 directions.
- Continuous space: the number of possible actions is infinite.

To recap:

Taking this information into consideration is crucial because it will have importance when choosing the RL algorithm in the future.
Rewards and the discounting
The reward is fundamental in RL because it’s the only feedback for the agent. Thanks to it, our agent knows if the action taken was good or not.
The cumulative reward at each time step t can be written as:
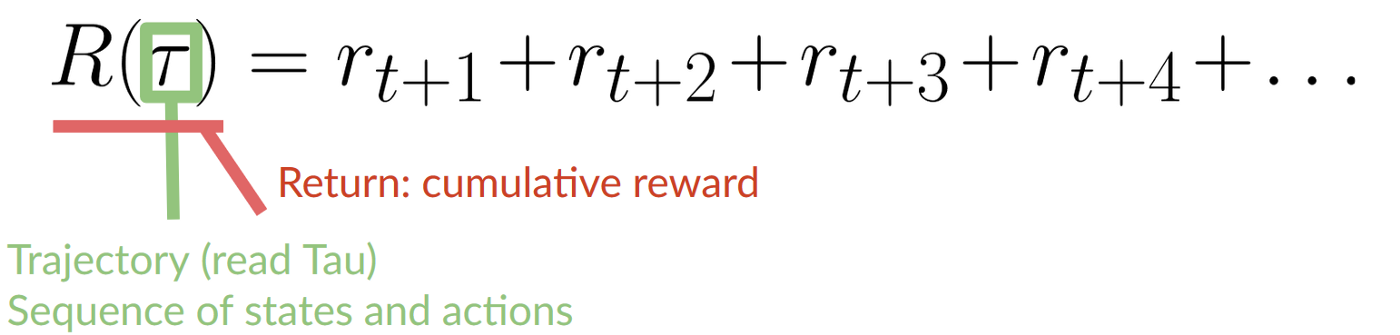
Which is equivalent to:
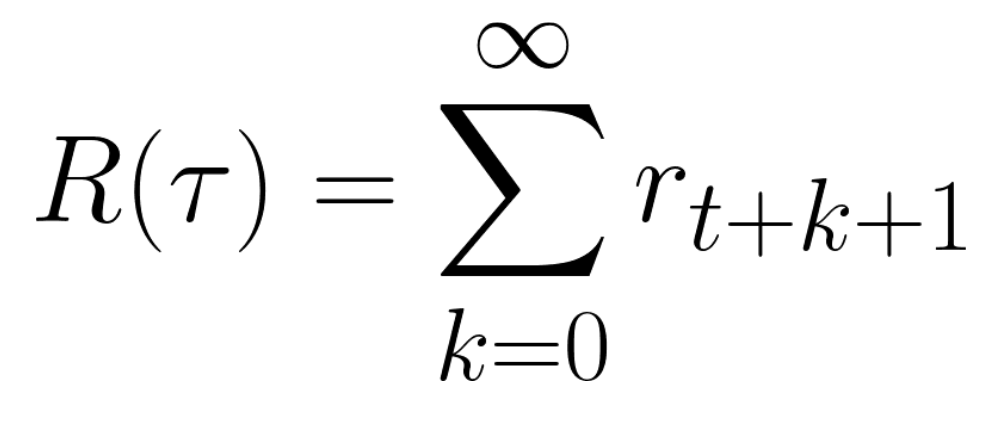
However, in reality, we can’t just add them like that. The rewards that come sooner (at the beginning of the game) are more likely to happen since they are more predictable than the long-term future reward.
Let’s say your agent is this tiny mouse that can move one tile each time step, and your opponent is the cat (that can move too). The mouse’s goal is to eat the maximum amount of cheese before being eaten by the cat.

As we can see in the diagram, it’s more probable to eat the cheese near us than the cheese close to the cat (the closer we are to the cat, the more dangerous it is).
Consequently, the reward near the cat, even if it is bigger (more cheese), will be more discounted since we’re not really sure we’ll be able to eat it.
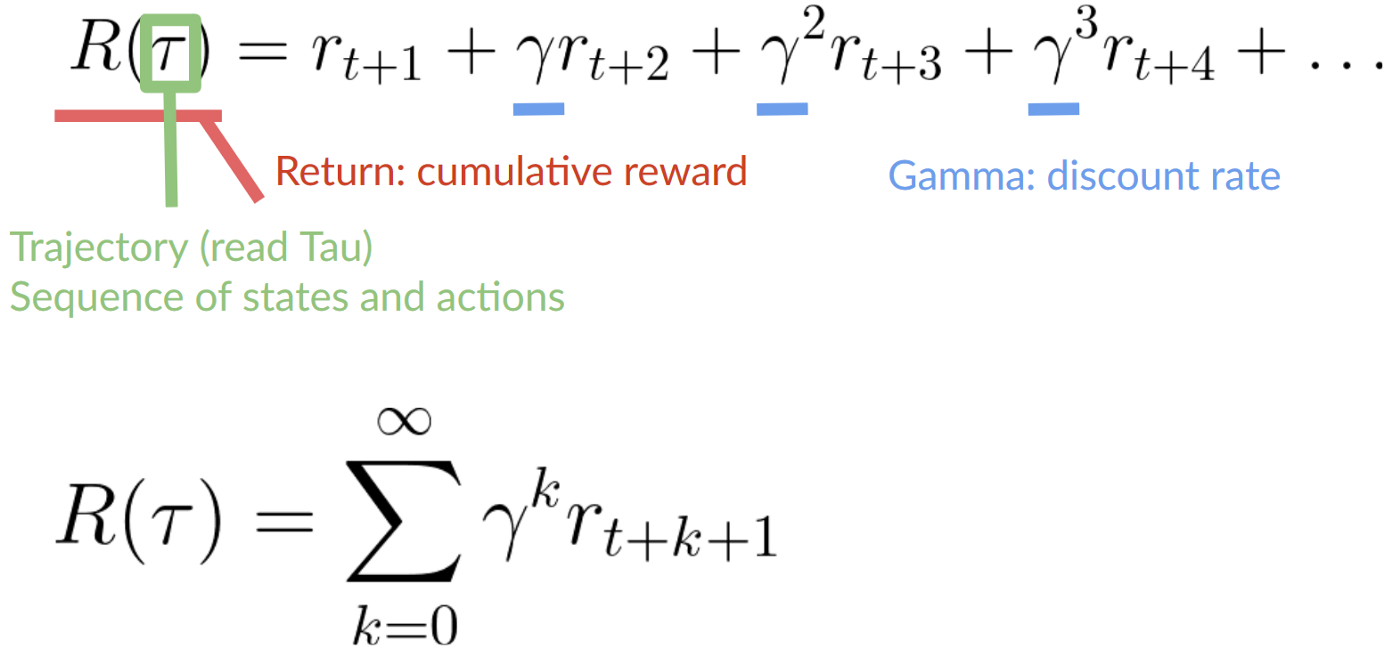
To discount the rewards, we proceed like this:
- We define a discount rate called gamma. It must be between 0 and 1. Most of the time between 0.95 and 0.99.
- The larger the gamma, the smaller the discount. This means our agent cares more about the long-term reward.
- On the other hand, the smaller the gamma, the bigger the discount. This means our agent cares more about the short term reward (the nearest cheese).
2. Then, each reward will be discounted by gamma to the exponent of the time step. As the time step increases, the cat gets closer to us, so the future reward is less and less likely to happen.
Our discounted expected cumulative reward is:
 < > Update on GitHub
< > Update on GitHub