单元简介
在本节中,我们将探讨如何使用 Transformers 将语音转换为文本,这一任务被称为 语音识别。
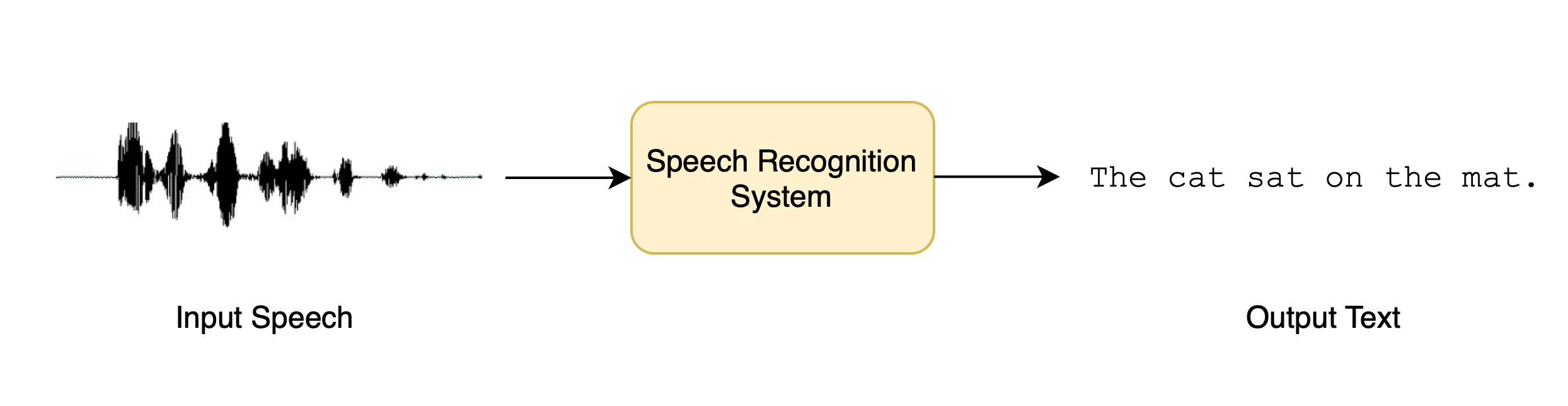
语音识别,也称为自动语音识别(ASR)或语音转文本(STT),是最受欢迎和令人兴奋的语音处理任务之一。 它广泛应用于包括口述、语音助手、视频字幕和会议记录在内的多种应用中。
您可能在不知不觉中多次使用过语音识别系统,比如说您智能手机中的数字助手(Siri、Google Assistant、Alexa)! 当您使用这些助手时,它们首先要做的就是将您的语音转写为书面文本,准备用于各种下游任务(比如为您查询天气预报 🌤️)。
试试下面的语音识别 demo。您可以使用麦克风录制自己的声音,或拖放音频样本文件进行转写:
语音识别是一项具有挑战性的任务,它需要对音频和文本都有所了解。输入的音频可能有很多背景噪音,并且可能由具有各种口音的说话人发出,这使得从中识别出语音变得困难。 书面文本可能包含无声音的字符,如标点符号,这些信息仅从音频中推断很困难。这些都是我们在构建有效的语音识别系统时必须克服的障碍!
现在我们已经定义了我们的任务,我们可以开始更详细地研究语音识别。通过本单元的学习,您将对各种可用的预训练语音识别模型有一个良好的基本理解,并了解如何通过 🤗 Transformers 库使用它们。 您还将了解对一个领域或某种特定语言微调 ASR 模型的过程,使您能够为遇到的任何任务构建一个高效的系统。您将能够向您的亲朋好友现场演示您的模型,一个能够将任何语音转换为文本的模型!
具体而言,我们将介绍: