Audio Course documentation
音频数据集的预处理
音频数据集的预处理
使用🤗 Datasets加载数据集只是乐趣的一半。如果你计划用数据集训练模型或者运行推理,那么你还需要对数据进行预处理(pre-processing)。数据预处理通常包括以下几步:
- 音频重采样
- 对数据集进行过滤
- 将音频数据转换为模型要求的输入形式
音频重采样
load_dataset()函数在下载数据集时会保留数据集发布时的原始采样率。当你使用其他模型进行训练或推理时,该采样率也许会不符合要求。当采样率不同时,你可以进行重采样来将数据调整到模型所期望的采样率。
目前大多数的预训练模型采用了16千赫兹采样率的数据集进行预训练。在上一张探索MINDS-14数据集时,你可能注意到了该数据集采用了8千赫兹的采样率,这意味着我们需要对其进行上采样。
我们可以使用🤗 Datasets的cast_column()方法进行上采样。该方法不会在原位改动数据,而是在数据加载时进行实时的重采样。下面的代码可以将样本重采样到16千赫兹:
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))现在我们重新加载MINDS-14的第一个样本,并检查其是否按照我们提供的sampling_rate参数进行了重采样:
minds[0]输出
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}你可能注意到数列的值也有所变化。这是因为我们在重采样后会获得两倍于原来采样点数量的数值。
💡 关于重采样的背景知识:当信号的原始采样率为8千赫兹时,信号每秒钟会包含8000个采样点,并且我们知道该信号不会包含高于4千赫兹的频率成分。奈奎斯特采样定理保证了这一点。也因此,我们可以确保在两个采样点中间的原始连续信号呈一条平滑的曲线。在这样的条件下,上采样所要做的就只是根据对曲线的估计而计算出两个采样点中间的额外数值。与之相反的是,下采样过程需要我们首先过滤掉所有高于奈奎斯特极限的频率成分,之后才能重新计算采样点。也就是说,我们不能通过简单的每隔一个采样点丢弃一个采样点来进行2倍的下采样:这会造成信号的失真,我们称之为混叠失真。重采样过程十分棘手,因此我们推荐使用经过测试的工具库,例如librosa或🤗 Datasets。
过滤数据集
我们可能会需要用一些指标来过滤掉数据集中的一些数据。一种常见情况是限制音频文件的时长。举个例子,我们可能需要过滤掉所有长度超过20秒的音频来防止模型训练过程中的内存不足错误。
我们可以使用🤗 Datasets的filter方法并传入过滤逻辑的函数来进行过滤。首先我们需要编写一个函数来指示哪些样本需要保留,哪些样本需要舍弃。这里我们编写了is_audio_length_in_range()函数,在样本长度小于20秒时会返回True,否则返回False。
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS该过滤函数可以直接应用在数据集的列上,但我们的数据集并没有一个单独的记录音频长度的列。不过我们可以自己创建一列,然后进行过滤,最后在过滤完成之后删除该列。
# 使用librosa从音频文件里获取该音频的长度
new_column = [librosa.get_duration(filename=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# 使用🤗 Datasets的`filter`方法来进行过滤
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# 移除临时列
minds = minds.remove_columns(["duration"])
minds输出
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})我们可以看到数据集的样本数量从654个被过滤到了624个。
音频数据的预处理
在利用音频数据集时,最具挑战的工作之一便是给模型训练提供正确格式的数据。如你所见,原始的音频数据是一个单列的采样点数组。然而,无论是推理还是根据任务进行微调,大部分的预训练模型都需要将音频数据转化成其对应的输入特征。每个模型的输入特征都有不同的要求,往往根据模型的架构和其预训练的数据集所决定。好消息是,🤗 Transformers所支持的所有音频模型都提供了一个特征提取类,负责将原始的音频数据转化为该模型所需的输入特征格式。
特征提取器具体会对音频文件做些什么呢?我们可以参考Whisper的特征提取器来理解一些常用的特征提取变换。Whisper是一个自动语音识别(automatic specch recognition, ASR)的预训练模型,由OpenAI的Alec Radford等人于2022年9月发布。
首先,Whisper的特征提取器会加长/截短某一批次中的所有音频样本,确保他们均为长30秒的音频。短于30秒的样本会采用末尾补零的方式加长至30秒,因为零在音频信号中代表无信号或静音。长于30秒的音频会被截取至30秒。由于一批次的所有音频都被加长/截短至同一长度,我们不再需要使用attention mask。这是Whisper模型的特性之一,因为大多数其他的音频模型都需要使用attention mask来告诉模型输入的哪些部分进行了补值,来让这些被补值的位置在self-attention过程中被忽略。Whisper模型在训练时就在无需attention mask的情况下运行,并且能直接从输入的音频信号中推理出哪些部分需要被忽略。
Whisper的特征提取器所进行的第二个操作是将定长的音频数组转化为对数梅尔时频谱(log-mel spectrogram)。如前文所述,对数梅尔谱描述了各个频率成分是如何随时间变化的,并且在频率上使用了梅尔标度,在幅值上使用的分贝(对数)标度,使得频率和幅值的关系更接近于人耳的感知。
上述的所有变换都可以用简短的几行代码应用到原始的音频数据上。现在,我们从预训练的Whisper模型检查点(checkpoint)加载特征提取器,为音频数据做好准备:
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")然后,我们编写一个处理单个样本的函数,将该样本中的音频文件输入特征提取器feature_extractor。
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features我们可以使用🤗 Datasets的map方法将这个数据处理函数应用到数据集中的所有训练样本上:
minds = minds.map(prepare_dataset)
minds输出:
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)简单几步后,我们就获得了对数梅尔谱并存储在数据集的input_features列中。
我们来试着可视化minds数据集中的一个样本:
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()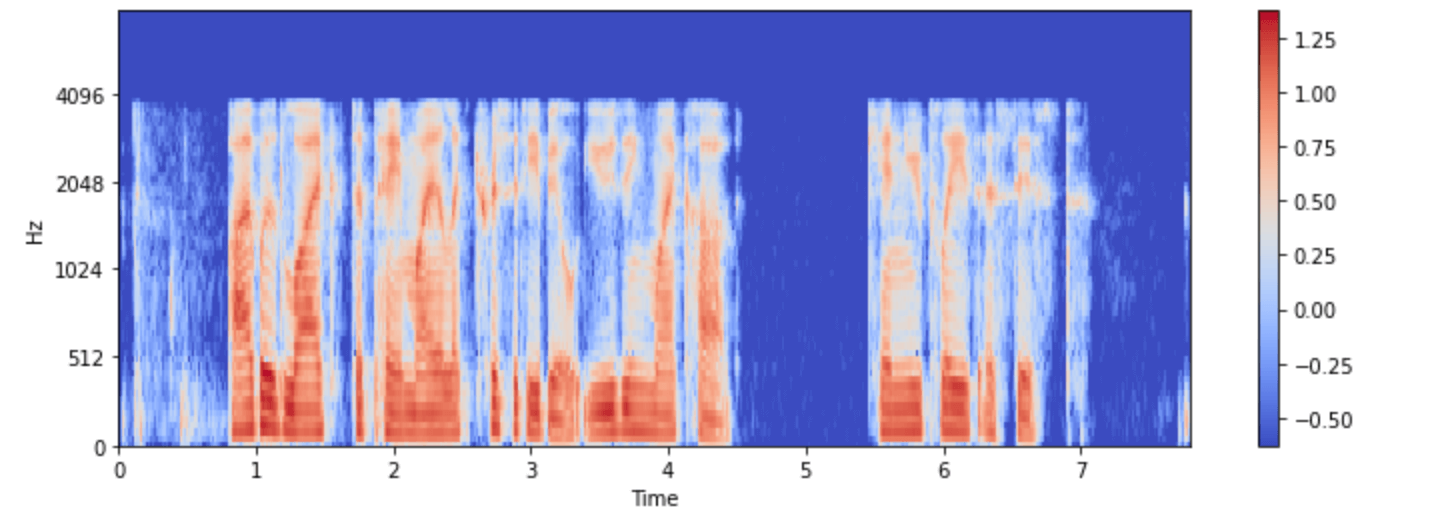
现在你可以看到经过预处理后的Whisper模型的输入了。
模型的特征提取器会保证将原始音频转化为模型所需要的输入格式。然而,许多音频相关的任务,比如语音识别,往往也是多模态的任务。🤗 Transformers库提供了针对各种文字模型的分词器(Tokenizer)。请参考我们的自然语言处理课程中对分词器的详细介绍。
我们可以分别加载Whisper中的特征提取器和其他多模态模型中的分词器,也可以通过processor将他们同时加载。如果想要更加简单的用法,你可以使用AutoProcessor从模型的检查点中直接加载特征提取器和processor:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")在本小节中,我们介绍了数据准备的基本流程。但要注意的是,您的自定义数据集往往会需要一些更复杂的数据预处理。针对这些情况,你可以扩展prepare_dataset()函数来实现各种自定义的数据转换流程。在🤗 Datasets的帮助下,只要您能将数据处理流程编写为Python函数,就可以将其应用在您的数据集上!