Introducción a los datos de audio
Por naturaleza, una onda sonora es una señal continua, es decir, que contiene un número infinito de valores de la señal en un tiempo determinado. Este es un problema para los dispositivos digitales que trabajan con un número finito de valores. La onda sonora necesita ser convertida en un serie de valores discretos para que pueda ser procesada, almacenada y transmitida por un por un dispositivo digital, esta representación discreta se conoce como representación digital.
Si exploras cualquier base de datos de audio, encontrarás archivos digitales con fragmentos de sonido que pueden contener narraciones o música.
Puedes encontrar diferentes formatos de archivo como .wav (Waveform Audio File), .flac (Free Lossless Audio Codec)
y .mp3 (MPEG-1 Audio Layer 3). Estos formatos difieren principalmente en como comprimen la representación digital de la señal de audio.
Examinemos como pasamos de una señal continua a una representación digital. La señal acústica(análoga) es primero capturada por un micrófono, que convierte las ondas sonoras en una señal electrica(Tambien análoga). La señal electrica es digitalizada por un conversor Análogo-Digital(ADC) para tener una representación digital a través del muestreo.
Muestreo y frecuencia de muestreo
El muestreo es el proceso de medir el valor de una señal continua en intervalos de tiempo fijos. La señal sampleada es discreta, ya que contiene un número finito de valores de la señal.
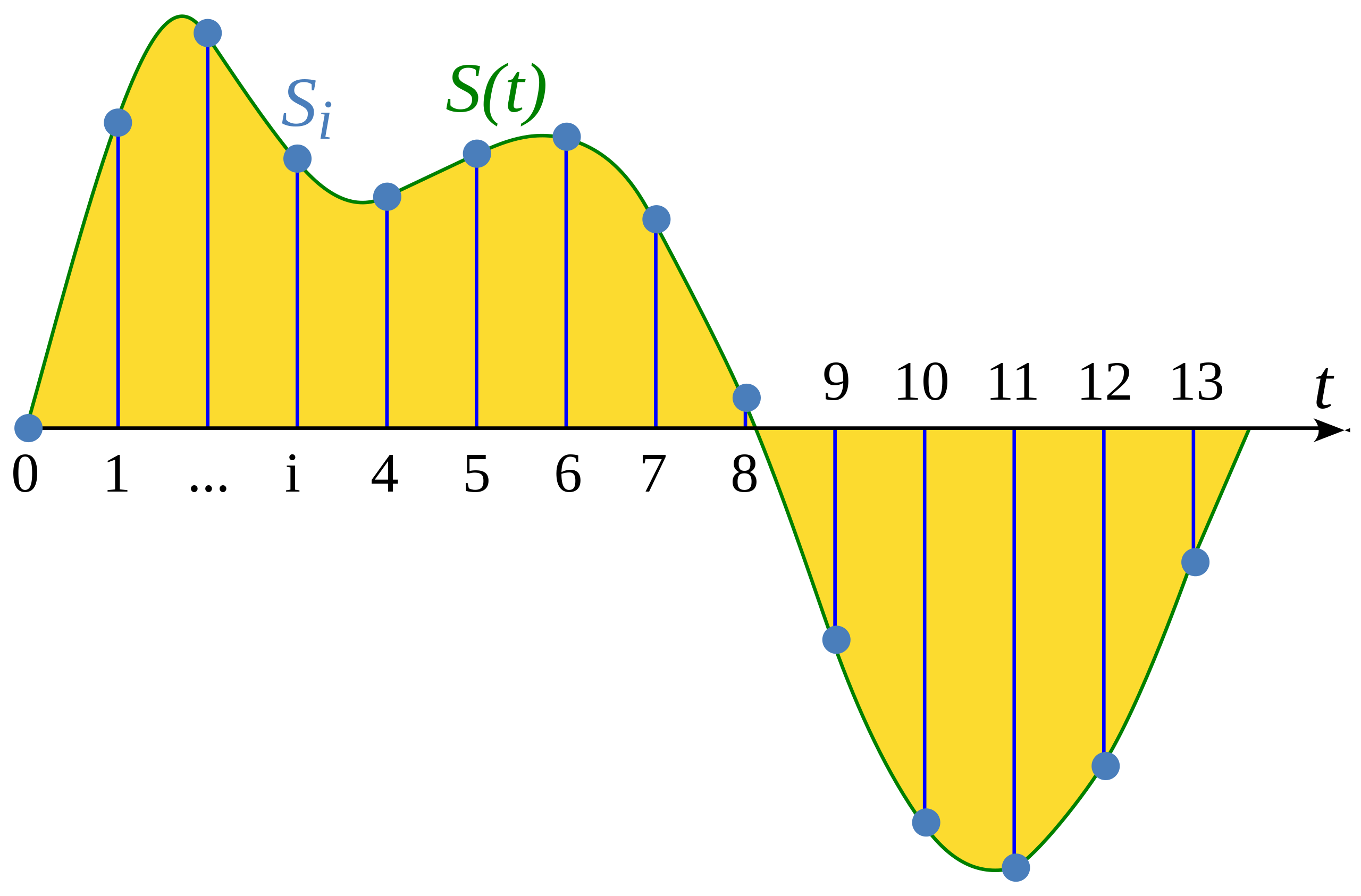
Ilustración de un articulo de Wikipedia: Muestreo(procesamiento de señal)
La Tasa de Muestreo (Tambien llamada frecuencia de muestreo) es el número de muestras capturadas en un segundo y es medida en unidades de Hertz (Hz). Para tener un punto de referencia, un audio con calidad de CD tiene una frecuencia de muestreo de 44,100 Hz, es decir que se capturan 44,100 muestras por segundo. Existen archivos de audio Hi-Fi que utilizan frecuencias de muestreo de 192,000 hz o 192kHz. Una frecuencia de muestreo comúnmente usada para entrenar modelos de voz es 16,0000 Hz o 16 kHz.
La elección de la frecuencia de muestreo determina la frecuencia más alta que puede ser representada digitalmente. Esto se conoce como el limite de Nyquist y es exactamente la mitad de la señal de la frecuencia de muestreo. Las frecuencias audibles en la voz humana estan por debajo de 8kHz, por lo que una frecuencia de 16kHz es suficiente. Usar una frecuencia de muestreo más alta no va a capturar más información pero si añade un costo computacional al procesamiento de estos archivos. En el caso contrario, elegir una frecuencia de muestreo muy baja puede resultar en perdidas de información. Audios de voz sampleados a 8kHz sonarán opacos, ya que las frecuencias por encima de 4kHz no pueden ser capturadas por esta frecuencia de muestreo.
Es importante asegurar que todos los ejemplos de audio de la base de datos tienen la misma frecuencia de muestreo. Si planeas usar tus propios audios para hacer fine-tunning de un modelo pre-entrenado, la frecuencia de muestreo de estos audios debe concordar con la frecuencia de muestreo con la que el modelo fue previamente entrenado. La frecuencia de muestreo determina el intervalo de tiempo entre muestras de audio sucesivas, lo que tiene un efecto en la resolución temporal de los datos de audio. Por ejemplo: un audio de 5 segundos con una frecuencia de muestreo de 16,000 Hz será representado como una serie de 80,000 valores, mientras que el mismo audio con una frecuencia de muestreo de 8,000hz será representado como una serie de 40,000 valores. Los modelos de transformers para audio tratan los ejemplos como secuencias y se basan en mecanismos de atención para aprender del audio o de representaciónes multimodales. Ya que la longitud de las secuencias difiere al usar frecuencias de muestreo diferentes, será dificil para el modelo generalizar para diferentes frecuencias de muestro. Resamplear es el proceso de convertir una señal a otra frecuencia de muestreo, es parte de la sección de preprosesamiento de datos de audio.
Amplitud y profundidad de bits
Mientras que la frecuencia de muestreo te indica con qué frecuencia se toman las muestras, ¿Qué representan exactamente los valores en cada muestra?
El sonido se produce por cambios en la presión del aire a frecuencias audibles para los humanos. La amplitud de un sonido describe el nivel de presión sonora en un momento dado y se mide en decibelios (dB). Percibimos la amplitud como volumen o intensidad del sonido. Por ejemplo, una voz normal al hablar está por debajo de los 60 dB, mientras que un concierto de rock puede llegar a los 125 dB, alcanzando los límites de la audición humana.
En el audio digital, cada muestra de audio registra la amplitud de la onda de audio en un momento específico. La profundidad de bits de la muestra determina con qué precisión se puede describir este valor de amplitud. Cuanto mayor sea la profundidad de bits, más fiel será la representación digital a la onda de sonido continua original.
Las profundidades de bits de audio más comunes son 16 bits y 24 bits. Cada una es una medida binaria que representa el número de pasos posibles en los que se puede cuantificar el valor de amplitud al convertirlo de continuo a discreto: 65.536 pasos para el audio de 16 bits y 16.777.216 pasos para el audio de 24 bits. Debido a que la cuantificación implica redondear el valor continuo a un valor discreto, el proceso de muestreo introduce ruido. Cuanto mayor sea la profundidad de bits, menor será este ruido de cuantificación. En la práctica, el ruido de cuantificación del audio de 16 bits ya es lo suficientemente pequeño como para ser audible, por lo que generalmente no es necesario utilizar profundidades de bits más altas.
También es posible encontrarse con audio de 32 bits. Este almacena las muestras como valores de punto flotante, mientras que el audio de 16 bits y 24 bits utiliza muestras enteras. La precisión de un valor de punto flotante de 32 bits es de 24 bits, lo que le otorga la misma profundidad de bits que el audio de 24 bits. Se espera que las muestras de audio de punto flotante se encuentren dentro del rango [-1.0, 1.0]. Dado que los modelos de aprendizaje automático trabajan naturalmente con datos de punto flotante, el audio debe convertirse primero al formato de punto flotante antes de poder ser utilizado para entrenar el modelo. Veremos cómo hacer esto en la próxima sección sobre Preprocesamiento.
Al igual que con las señales de audio continuas, la amplitud del audio digital se expresa típicamente en decibelios (dB). Dado que la audición humana es de naturaleza logarítmica, es decir, nuestros oídos son más sensibles a las pequeñas fluctuaciones en sonidos silenciosos que en sonidos fuertes, el volumen de un sonido es más fácil de interpretar si las amplitudes están en decibelios, que también son logarítmicos. La escala de decibelios para el audio real comienza en 0 dB, que representa el sonido más silencioso posible que los humanos pueden escuchar, y los sonidos más fuertes tienen valores más grandes. Sin embargo, para las señales de audio digital, 0 dB es la amplitud más alta posible, mientras que todas las demás amplitudes son negativas. Como regla general: cada -6 dB implica una reducción a la mitad de la amplitud, y cualquier valor por debajo de -60 dB generalmente es inaudible a menos que subas mucho el volumen.
Audio como forma de onda
Es posible que hayas visto los sonidos visualizados como una forma de onda(waveform), que representa los valores de las muestras a lo largo del tiempo y muestra los cambios en la amplitud del sonido. Esta representación también se conoce como la representación en el dominio del tiempo del sonido.
Este tipo de visualización es útil para identificar características específicas de la señal de audio, como la sincronización de eventos de sonido individuales, la intensidad general de la señal y cualquier irregularidad o ruido presente en el audio.
Para graficar la forma de onda de una señal de audio, usamos una libreria de Python llamada librosa:
pip install librosa
Carguemos un ejemplo de la libreria llamado “trumpet”:
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))El ejemplo es cargado como una tupla formada por una serie temporal de valores de audio(llamado array) y la frecuencia de muestreo (sampling_rate).
Grafiquemos este sonido usando la función waveshow() de librosa:
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)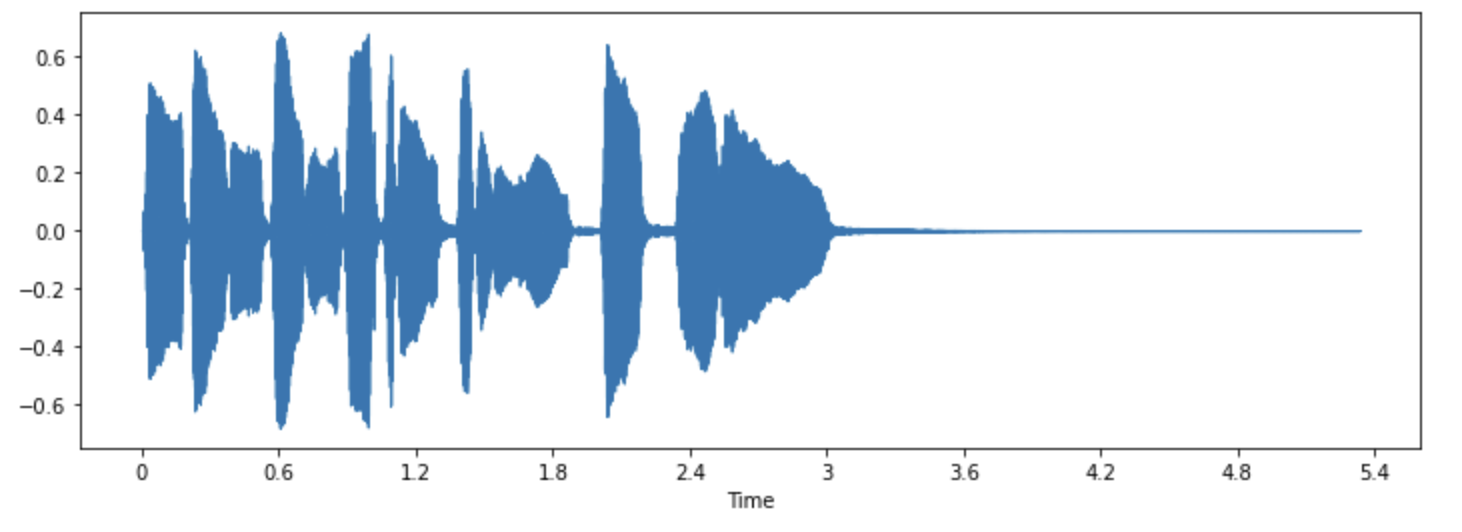
Esta representación grafica la amplitud de la señal en el eje y y el tiempo en el eje x. En otras palabras, cada punto corresponde a un único valor de muestra que se tomó cuando se muestreó este sonido. También es importante tener en cuenta que librosa devuelve el audio en forma de valores de punto flotante y que los valores de amplitud se encuentran dentro del rango [-1.0, 1.0].
Visualizar el audio junto con escucharlo puede ser una herramienta útil para comprender los datos con los que estás trabajando. Puedes observar la forma de la señal, identificar patrones y aprender a detectar ruido o distorsión. Si preprocesas los datos de alguna manera, como normalización, remuestreo o filtrado, puedes confirmar visualmente que los pasos de preprocesamiento se hayan aplicado correctamente.
Después de entrenar un modelo, también puedes visualizar las muestras donde se producen errores (por ejemplo, en una tarea de clasificación de audio) para solucionar el problema. Esto te permitirá depurar y entender mejor las áreas en las que el modelo puede tener dificultades o errores.
El espectro de frecuencia
Otra forma de visualizar los datos de audio es graficar el espectro de frecuencia de una señal de audio, también conocido como la representación en el dominio de la frecuencia. El espectro se calcula utilizando la transformada discreta de Fourier o DFT. Describe las frecuencias individuales que componen la señal y su intensidad.
Grafiquemos el espectro de frecuencia para el mismo sonido de trompeta mediante el cálculo de la transformada discreta de Fourier (DFT) utilizando la función rfft() de numpy. Si bien es posible trazar el espectro de toda la señal de audio, es más útil observar una pequeña región en su lugar. Aquí tomaremos la DFT de los primeros 4096 valores de muestra, que es aproximadamente la duración de la primera nota que se está tocando:
import numpy as np
dft_input = array[:4096]
# calcular la DFT
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# obtener la amplitud del espectro en decibeles
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# Obtener los bins de frecuencia
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")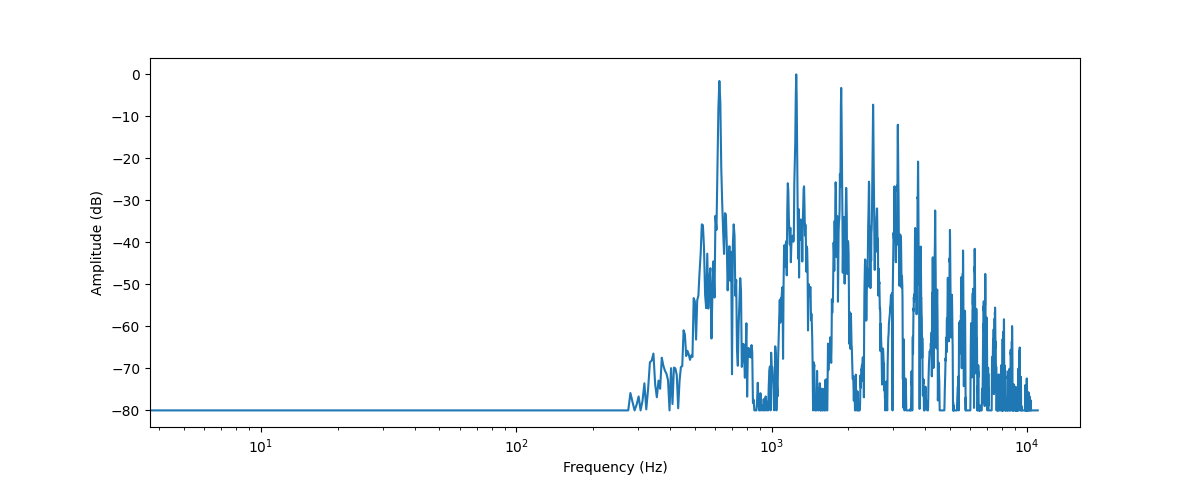
Esto representa la intensidad de los diferentes componentes de frecuencia que están presentes en este segmento de audio. Los valores de frecuencia se encuentran en el eje x, generalmente representados en una escala logarítmica, mientras que las amplitudes se encuentran en el eje y.
El espectro de frecuencia que hemos graficado muestra varios picos. Estos picos corresponden a los armónicos de la nota que se está tocando, siendo los armónicos más altos(en frecuencia) los más silenciosos. Dado que el primer pico se encuentra alrededor de 620 Hz, este es el espectro de frecuencia de una nota Mi♭.
La salida de la DFT es una matriz de números complejos, compuestos por componentes reales e imaginarios. Tomar la magnitud con np.abs(dft) extrae la información de amplitud del espectrograma. El ángulo entre los componentes reales e imaginarios proporciona el llamado espectro de fase, pero esto a menudo se descarta en aplicaciones de aprendizaje automático.
Utilizamos librosa.amplitude_to_db() para convertir los valores de amplitud a la escala de decibelios, lo que facilita ver los detalles más
sutiles en el espectro. A veces, las personas utilizan el espectro de potencia, que mide la energía en lugar de la amplitud; esto es simplemente
un espectro con los valores de amplitud elevados al cuadrado.+
El espectro de frecuencia de una señal de audio contiene exactamente la misma información que su representación en el dominio del tiempo(forma de onda); simplemente son dos formas diferentes de ver los mismos datos (en este caso, los primeros 4096 valores de muestra del sonido de trompeta). Mientras que la forma de onda representa la amplitud de la señal de audio a lo largo del tiempo, el espectro visualiza las amplitudes de las frecuencias individuales en un punto fijo en el tiempo.
Espectrograma
¿Y si queremos ver cómo cambian las frecuencias en una señal de audio? La trompeta toca varias notas que tienen diferentes frecuencias. El problema es que el espectro solo es una foto fija de las frecuencias en un instante determinado. La solución es tomar múltiples DFT, cada una abarcando un pequeño fragmento de la señal, y luego apilar los espectros resultantes en un espectrograma.
Un espectrograma grafica el contenido frecuencial de una señal de audio a medida que cambia en el tiempo. Esto nos permite ver en la misma gráfica la información de tiempo, frecuencia y amplitud. El algoritmo que permite hacer este representación se conoce como STFT o Transformada de tiempo corto de Fourier.
El espectrograma es una de las herramientas más útiles disponibles. Por ejemplo, cuando estamos trabajando con una grabación de música, podemos ver como contribuye cada instrumento y las voces al sonido general. En el habla, se pueden identificar los difrerentes sonidos de las vocales ya que cada vocal esta caracterizada por frecuencias particulares.
Grafiquemos ahora un espectrograma del mismo sonido de trompeta, usando las funciones de librosa stft() y specshow():
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()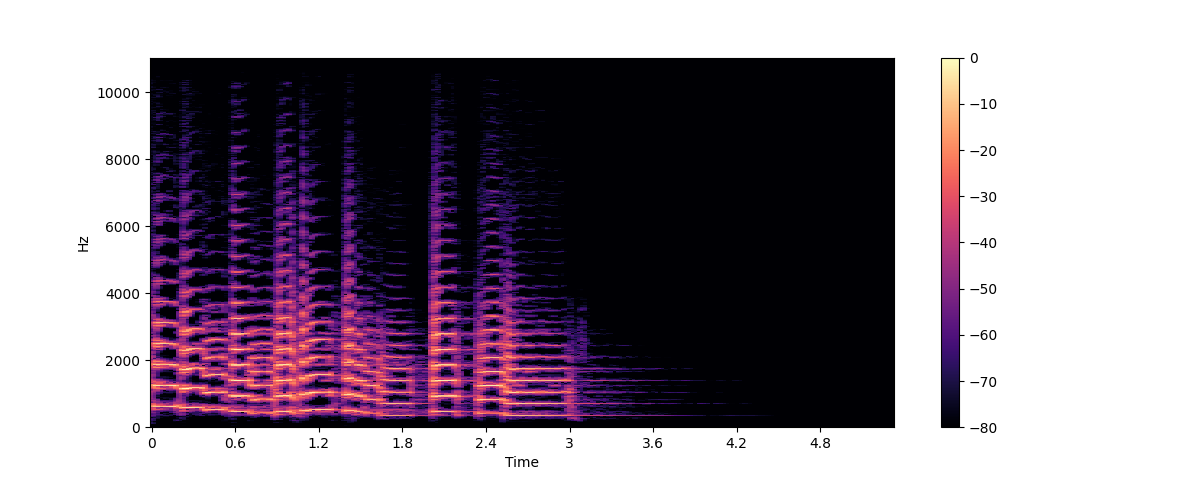
En este gráfico, el eje x representa el tiempo al igual que en la visulización de la forma de onda sin embargo el eje y ahora representa la frecuencia en hertz(Hz). La intensidad del color representa el nivel en decibelios (dB) de las componentes de frecuencia en cada punto del tiempo.
El espectrograma es creado al tomar pequeños segmentos de la señal de audio, comunmente de unos cuantos milisegundos y calculando
la transformada discreta de Fourier de cada segmento para obtener el espectro en frecuencia. Estos espectros se concatenan a lo
largo del eje temporal para crear un espectrograma. Cada columna en la imagen corresponde a un espectro de frecuencia, Por defecto,
la función librosa.stft() divide la señal en segmentos de 2048 muestras, lo que ofrece un buen resultado
para la resolución en frecuencia y la resolución temporal.
Dado que el espectrograma y la forma de onda son diferentes representaciones de los mismos datos, es posible convertir el espectrograma nuevamente en la forma de onda original utilizando la STFT inversa (transformada de Fourier de tiempo corto inversa). Sin embargo, esto requiere tanto la información de amplitud como la información de fase. Si el espectrograma fue generado por un modelo de aprendizaje automático, típicamente solo se genera la información de amplitud. En ese caso, podemos utilizar un algoritmo de reconstrucción de fase clásico como el algoritmo de Griffin-Lim, o utilizar una red neuronal llamada vocoder, para reconstruir una forma de onda a partir del espectrograma.
Los espectrogramas no solo se utilizan para visualización. Muchos modelos de aprendizaje automático toman espectrogramas como entrada, en lugar de formas de onda, y producen espectrogramas como salida.
Ahora que sabemos qué es un espectrograma y cómo se genera, echemos un vistazo a una variante ampliamente utilizada en el procesamiento del habla: el espectrograma de mel.
Espectrograma de Mel
Un espectrograma mel es una variante del espectrograma que se utiliza comúnmente en el procesamiento del habla y en tareas de aprendizaje automático. Es similar a un espectrograma en el sentido de que muestra el contenido de frecuencia de una señal de audio a lo largo del tiempo, pero en un eje de frecuencia diferente.
En un espectrograma estándar, el eje de frecuencia es lineal y se mide en hercios (Hz). Sin embargo, el sistema auditivo humano es más sensible a los cambios en las frecuencias bajas que en las frecuencias altas, y esta sensibilidad disminuye de manera logarítmica a medida que la frecuencia aumenta. La escala mel es una escala perceptual que aproxima la respuesta de frecuencia no lineal del oído humano.
Para crear un espectrograma de mel, se utiliza la STFT de la misma manera que vimos antes, dividiendo el audio en segmentos cortos para obtener una secuencia de espectros de frecuencia. Además, cada espectro se pasa a través de un conjunto de filtros(banco de filtros de mel) para transformar las frecuencias a la escala de mel.
Obsrevemos como podemos obtener el espectrograma de mel usando la función melspectrogram() de librosa, que realiza todos los pasos anteriores:
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()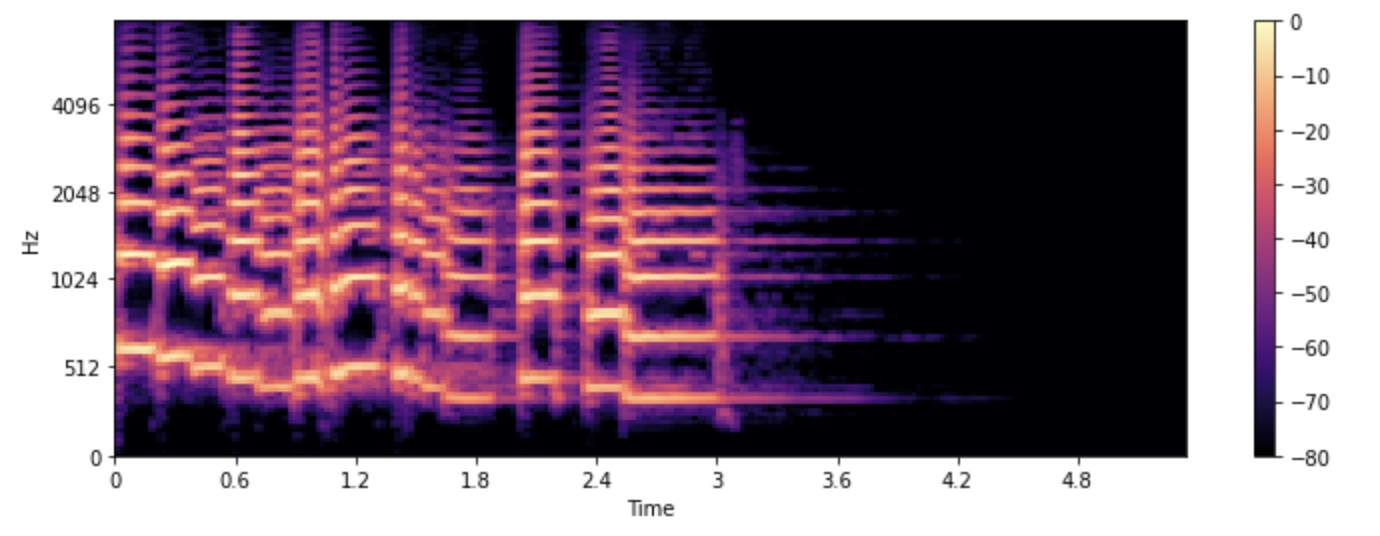
En el ejemplo anterior, n_mels representa el número de bandas de mel que se generarán. Las bandas de mel definen un conjunto de
rangos de frecuencia que dividen el espectro en componentes significativos desde el punto de vista perceptual, utilizando un
conjunto de filtros cuya forma y espaciado se eligen para imitar la forma en que el oído humano responde a diferentes frecuencias.
Los valores comunes para n_mels son 40 o 80. fmax indica la frecuencia más alta (en Hz) que nos interesa.
Al igual que con un espectrograma regular, es práctica común expresar la intensidad de los componentes de frecuencia de mel en decibelios.
Esto se conoce comúnmente como un espectrograma logarítmico de mel, porque la conversión a decibelios implica una operación logarítmica.
El ejemplo anterior se usó librosa.power_to_db() ya que la función librosa.feature.melspectrogram() crea un espectrograma de potencia.
💡 ¡No todos los espectrogramas mel son iguales! Existen dos variantes comumente usadas de las escalas de mel(“htk” y “slaney”),
, y en lugar del espectrograma de potencia, se puede estar usando el espectrograma de amplitud. El cálculo de un espectrograma
logarítmico de mel no siempre usa decibelios reales, puede que se haya aplicado solamente la función log. Por lo tanto,
si un modelo de aprendizaje automático espera un espectrograma de mel como entrada, verifica que estés calculándolo de la misma manera
para asegurarte de que sea compatible.
La creación de un espectrograma mel es una operación con pérdidas, ya que implica filtrar la señal. Convertir un espectrograma de mel de nuevo en una forma de onda es más difícil que hacerlo para un espectrograma regular, ya que requiere estimar las frecuencias que se eliminaron. Es por eso que se necesitan modelos de aprendizaje automático como el vocoder HiFiGAN para producir una forma de onda a partir de un espectrograma de mel.
En comparación con un espectrograma estándar, un espectrograma mel captura características más significativas de la señal de audio para la percepción humana, lo que lo convierte en una opción popular en tareas como el reconocimiento de voz, la identificación de hablantes y la clasificación de géneros musicales.
Ahora que sabes cómo visualizar datos de audio, trata de ver cómo se ven tus sonidos favoritos. :)
< > Update on GitHub