

First model version
Browse files- README.md +91 -0
- config.json +28 -0
- generation_config.json +7 -0
- images/jetmoe_architecture.png +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +297 -0
- special_tokens_map.json +24 -0
- tokenizer.json +0 -0
- tokenizer_config.json +43 -0
README.md
CHANGED
|
@@ -1,3 +1,94 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
| 4 |
+
# **JetMoE**
|
| 5 |
+
**JetMoE-8B** is an 8B Mixture-of-Experts (MoE) language model developed by [Yikang Shen](https://scholar.google.com.hk/citations?user=qff5rRYAAAAJ) and [MyShell](https://myshell.ai/).
|
| 6 |
+
The goal of JetMoE is to provide a LLaMA2-level performance and efficient language model with a very limited budget.
|
| 7 |
+
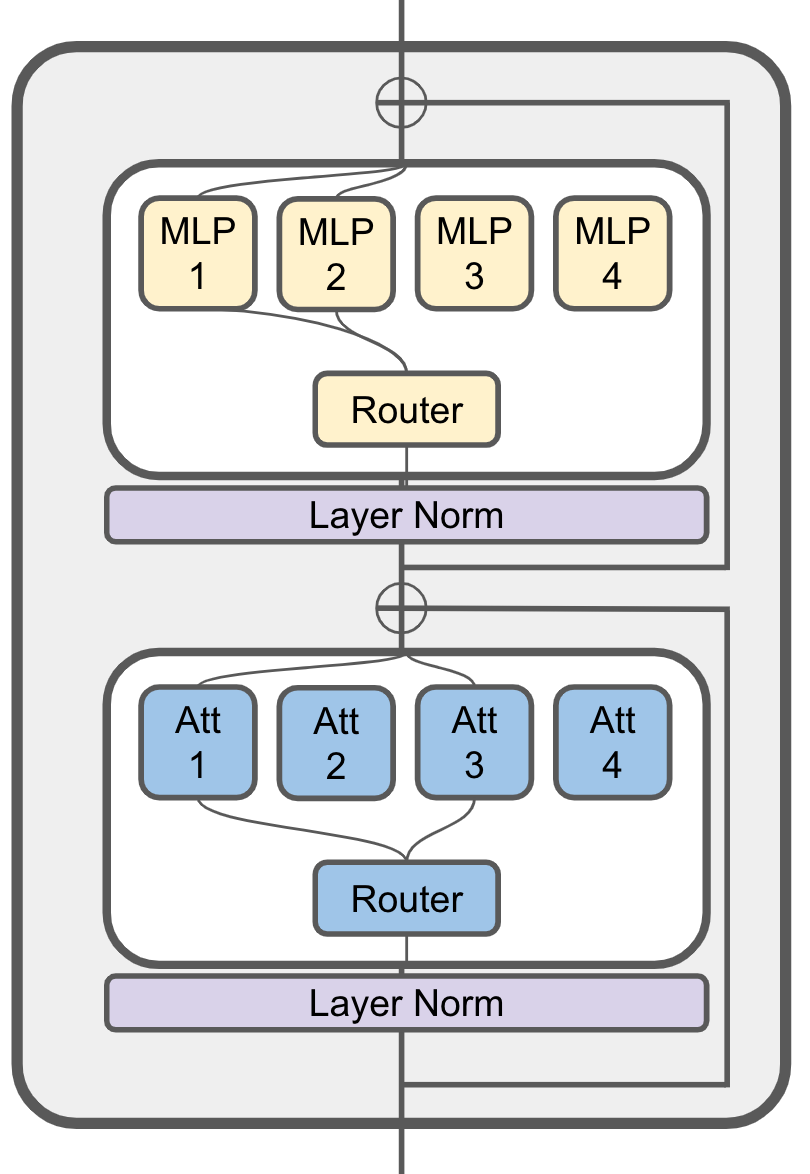
To achieve this goal, JetMoE uses a sparsely activated architecture inspired by the [ModuleFormer](https://arxiv.org/abs/2306.04640).
|
| 8 |
+
Each JetMoE block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts.
|
| 9 |
+
Given the input tokens, it activates a subset of its experts to process them.
|
| 10 |
+
Thus, JetMoE-8B has 8B parameters in total, but only 2B are activated for each input token.
|
| 11 |
+
This sparse activation schema enables JetMoE achieve much better training throughput compared to similar size dense models.
|
| 12 |
+
The model is trained with 1.25T tokens from publicly available datasets on 96 H100s within 13 days.
|
| 13 |
+
Given the current market price of H100 GPU hours, training the model only costs around 0.1 million dollars.
|
| 14 |
+
To our surprise, JetMoE-8B performs even better than LLaMA2-7B, LLaMA-13B, and DeepseekMoE-16B despite the lower training cost and computation.
|
| 15 |
+
Compared to a model with similar training and inference computation, JetMoE-8B achieves significantly better performance compared to Gemma-2B.
|
| 16 |
+
|
| 17 |
+
<figure>
|
| 18 |
+
<center>
|
| 19 |
+
<img src="images/jetmoe_architecture.png" width="40%">
|
| 20 |
+
<figcaption>JetMoE Architecture</figcaption>
|
| 21 |
+
</center>
|
| 22 |
+
</figure>
|
| 23 |
+
|
| 24 |
+
## Evaluation Results
|
| 25 |
+
|Model|Activate Params|Training Tokens|ARC-challenge|Hellaswag|MMLU|TruthfulQA|WinoGrande|GSM8k|Open LLM Leaderboard Average|MBPP|HumanEval|
|
| 26 |
+
|---|---|---|---|---|---|---|---|---|---|---|---|
|
| 27 |
+
||||acc|acc|acc|acc|acc|acc|acc|Pass@1|Pass@1|
|
| 28 |
+
|LLaMA2-7B|7B|2T|53.1|78.6|46.9|38.8|**74**|14.5|51.0|20.8|12.8|
|
| 29 |
+
|LLaMA-13B|13B|1T|**56.2**|**80.9**|47.7|39.5|**76.2**|7.6|51.4|22.0|15.8|
|
| 30 |
+
|DeepseekMoE-16B|2.8B|2T|53.2|79.8|46.3|36.1|73.7|17.3|51.1|34.0|**25.0**|
|
| 31 |
+
|Gemma-2B|2B|2T|48.4|71.8|41.8|33.1|66.3|16.9|46.4|28.0|24.4|
|
| 32 |
+
|JetMoE-8B|2.2B|1.25T|48.7|80.5|**49.2**|**41.7**|70.2|**27.8**|**53.0**|**34.2**|14.6|
|
| 33 |
+
|
| 34 |
+
## Model Usage
|
| 35 |
+
To load the models, you need install this package:
|
| 36 |
+
```
|
| 37 |
+
pip install -e .
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
Then you can load the model with the following code:
|
| 41 |
+
```
|
| 42 |
+
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModelForSequenceClassification
|
| 43 |
+
from jetmoe import JetMoEForCausalLM, JetMoEConfig, JetMoEForSequenceClassification
|
| 44 |
+
AutoConfig.register("jetmoe", JetMoEConfig)
|
| 45 |
+
AutoModelForCausalLM.register(JetMoEConfig, JetMoEForCausalLM)
|
| 46 |
+
AutoModelForSequenceClassification.register(JetMoEConfig, JetMoEForSequenceClassification)
|
| 47 |
+
|
| 48 |
+
tokenizer = AutoTokenizer.from_pretrained('JetMoE/JetMoE-8B')
|
| 49 |
+
model = AutoModelForCausalLM.from_pretrained('JetMoE/JetMoE-8B')
|
| 50 |
+
```
|
| 51 |
+
The MoE code is based on the [ScatterMoE](https://github.com/shawntan/scattermoe). The code is still under active development, we are happy to receive any feedback or suggestions.
|
| 52 |
+
|
| 53 |
+
## Model Details
|
| 54 |
+
JetMoE-8B has 24 blocks.
|
| 55 |
+
Each block has two MoE layers: Mixture of Attention heads (MoA) and Mixture of MLP Experts (MoE).
|
| 56 |
+
Each MoA and MoE layer has 8 expert, and 2 experts are activated for each input token.
|
| 57 |
+
It has 8 billion parameters in total and 2.2B active parameters.
|
| 58 |
+
JetMoE-8B is trained on 1.25T tokens from publicly available datasets, with a learning rate of 5.0 x 10<sup>-4</sup> and a global batch-size of 4M tokens.
|
| 59 |
+
|
| 60 |
+
**Model Developers** JetMoE is developed by Yikang Shen and MyShell.
|
| 61 |
+
|
| 62 |
+
**Input** Models input text only.
|
| 63 |
+
|
| 64 |
+
**Output** Models generate text only.
|
| 65 |
+
|
| 66 |
+
## Training Data
|
| 67 |
+
JetMoE models are pretrained on 1.25T tokens of data from publicly available sources.
|
| 68 |
+
|
| 69 |
+
## Authors
|
| 70 |
+
This project is currently contributed by the following authors:
|
| 71 |
+
- Yikang Shen
|
| 72 |
+
- Zhen Guo
|
| 73 |
+
- Tianle Cai
|
| 74 |
+
- Zengyi Qin
|
| 75 |
+
|
| 76 |
+
## Technical Report
|
| 77 |
+
For more details, please refer to the JetMoE Technical Report (Coming Soon).
|
| 78 |
+
|
| 79 |
+
<!-- ## Citation
|
| 80 |
+
|
| 81 |
+
Please cite the following paper if you use the data or code in this repo.
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
@article{
|
| 85 |
+
}
|
| 86 |
+
``` -->
|
| 87 |
+
|
| 88 |
+
## JetMoE Model Index
|
| 89 |
+
|Model|Index|
|
| 90 |
+
|---|---|
|
| 91 |
+
|JetMoE-8B| [Link](https://huggingface.co/jetmoe/JetMoE-8B) |
|
| 92 |
+
|
| 93 |
+
## Ethical Considerations and Limitations
|
| 94 |
+
JetMoE is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, JetMoE’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of JetMoE, developers should perform safety testing and tuning tailored to their specific applications of the model.
|
config.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation_function": "silu",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"JetMoEForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"bos_token_id": 1,
|
| 7 |
+
"eos_token_id": 2,
|
| 8 |
+
"ffn_hidden_size": 5632,
|
| 9 |
+
"kv_channels": 128,
|
| 10 |
+
"layer_norm_epsilon": 1e-05,
|
| 11 |
+
"length_penalty": 1.0,
|
| 12 |
+
"moe_num_experts": 8,
|
| 13 |
+
"moe_top_k": 2,
|
| 14 |
+
"n_embd": 2048,
|
| 15 |
+
"n_head": 16,
|
| 16 |
+
"n_layer": 24,
|
| 17 |
+
"n_positions": 4096,
|
| 18 |
+
"num_key_value_heads": 8,
|
| 19 |
+
"num_layers": 24,
|
| 20 |
+
"rms_norm_eps": 1e-05,
|
| 21 |
+
"rope_theta": 10000.0,
|
| 22 |
+
"rotary_percent": 1.0,
|
| 23 |
+
"tie_word_embeddings": true,
|
| 24 |
+
"transformers_version": null,
|
| 25 |
+
"use_cache": true,
|
| 26 |
+
"vocab_size": 32000,
|
| 27 |
+
"glu": true
|
| 28 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 2,
|
| 6 |
+
"transformers_version": "4.37.0"
|
| 7 |
+
}
|
images/jetmoe_architecture.png
ADDED
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec472ef5ccae7be6181856a8dac3f4c2743fff491606d82266b6f82e94fa274e
|
| 3 |
+
size 4879574808
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4ee73ffb225275e9cced7473181f9dcb12a79c27d5d6fa31c2ae09964233e057
|
| 3 |
+
size 4933085104
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:562ea54a02baa7ed6d250bdb7835a9867dbb9ceaacd0a65d127eee5257a94b16
|
| 3 |
+
size 4933085160
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fb1997ac5dfbe2fddbfc45644db3b2963427adda13202bf4cf8c38a6daee8029
|
| 3 |
+
size 2298765920
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,297 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 17044475904
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 7 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 8 |
+
"model.layers.0.mlp.bias": "model-00001-of-00004.safetensors",
|
| 9 |
+
"model.layers.0.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 10 |
+
"model.layers.0.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"model.layers.0.mlp.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 12 |
+
"model.layers.0.mlp.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"model.layers.0.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 15 |
+
"model.layers.0.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"model.layers.0.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"model.layers.0.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"model.layers.0.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"model.layers.1.mlp.bias": "model-00001-of-00004.safetensors",
|
| 21 |
+
"model.layers.1.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"model.layers.1.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"model.layers.1.mlp.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"model.layers.1.mlp.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 26 |
+
"model.layers.1.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 27 |
+
"model.layers.1.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"model.layers.1.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 29 |
+
"model.layers.1.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"model.layers.1.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 31 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 32 |
+
"model.layers.10.mlp.bias": "model-00002-of-00004.safetensors",
|
| 33 |
+
"model.layers.10.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 34 |
+
"model.layers.10.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 35 |
+
"model.layers.10.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 36 |
+
"model.layers.10.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"model.layers.10.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 39 |
+
"model.layers.10.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"model.layers.10.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"model.layers.10.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"model.layers.10.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"model.layers.11.mlp.bias": "model-00002-of-00004.safetensors",
|
| 45 |
+
"model.layers.11.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"model.layers.11.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"model.layers.11.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"model.layers.11.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"model.layers.11.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 51 |
+
"model.layers.11.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"model.layers.11.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"model.layers.11.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"model.layers.11.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"model.layers.12.mlp.bias": "model-00002-of-00004.safetensors",
|
| 57 |
+
"model.layers.12.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"model.layers.12.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"model.layers.12.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"model.layers.12.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"model.layers.12.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 63 |
+
"model.layers.12.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"model.layers.12.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"model.layers.12.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"model.layers.12.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"model.layers.13.mlp.bias": "model-00002-of-00004.safetensors",
|
| 69 |
+
"model.layers.13.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"model.layers.13.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"model.layers.13.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 72 |
+
"model.layers.13.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 73 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"model.layers.13.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 75 |
+
"model.layers.13.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"model.layers.13.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"model.layers.13.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"model.layers.13.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"model.layers.14.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 80 |
+
"model.layers.14.mlp.bias": "model-00003-of-00004.safetensors",
|
| 81 |
+
"model.layers.14.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 82 |
+
"model.layers.14.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 83 |
+
"model.layers.14.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 84 |
+
"model.layers.14.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 85 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 86 |
+
"model.layers.14.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 87 |
+
"model.layers.14.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 88 |
+
"model.layers.14.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 89 |
+
"model.layers.14.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 90 |
+
"model.layers.14.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 91 |
+
"model.layers.15.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 92 |
+
"model.layers.15.mlp.bias": "model-00003-of-00004.safetensors",
|
| 93 |
+
"model.layers.15.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 94 |
+
"model.layers.15.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 95 |
+
"model.layers.15.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 96 |
+
"model.layers.15.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 97 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 98 |
+
"model.layers.15.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 99 |
+
"model.layers.15.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 100 |
+
"model.layers.15.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 101 |
+
"model.layers.15.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 102 |
+
"model.layers.15.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 103 |
+
"model.layers.16.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 104 |
+
"model.layers.16.mlp.bias": "model-00003-of-00004.safetensors",
|
| 105 |
+
"model.layers.16.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 106 |
+
"model.layers.16.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 107 |
+
"model.layers.16.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 108 |
+
"model.layers.16.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 109 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 110 |
+
"model.layers.16.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 111 |
+
"model.layers.16.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 112 |
+
"model.layers.16.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 113 |
+
"model.layers.16.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 114 |
+
"model.layers.16.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 115 |
+
"model.layers.17.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 116 |
+
"model.layers.17.mlp.bias": "model-00003-of-00004.safetensors",
|
| 117 |
+
"model.layers.17.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 118 |
+
"model.layers.17.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 119 |
+
"model.layers.17.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 120 |
+
"model.layers.17.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 121 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 122 |
+
"model.layers.17.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 123 |
+
"model.layers.17.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 124 |
+
"model.layers.17.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 125 |
+
"model.layers.17.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 126 |
+
"model.layers.17.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 127 |
+
"model.layers.18.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 128 |
+
"model.layers.18.mlp.bias": "model-00003-of-00004.safetensors",
|
| 129 |
+
"model.layers.18.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 130 |
+
"model.layers.18.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 131 |
+
"model.layers.18.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 132 |
+
"model.layers.18.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 133 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 134 |
+
"model.layers.18.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 135 |
+
"model.layers.18.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 136 |
+
"model.layers.18.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 137 |
+
"model.layers.18.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 138 |
+
"model.layers.18.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 139 |
+
"model.layers.19.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 140 |
+
"model.layers.19.mlp.bias": "model-00003-of-00004.safetensors",
|
| 141 |
+
"model.layers.19.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 142 |
+
"model.layers.19.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 143 |
+
"model.layers.19.mlp.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 144 |
+
"model.layers.19.mlp.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 145 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 146 |
+
"model.layers.19.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 147 |
+
"model.layers.19.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 148 |
+
"model.layers.19.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 149 |
+
"model.layers.19.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 150 |
+
"model.layers.19.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 151 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 152 |
+
"model.layers.2.mlp.bias": "model-00001-of-00004.safetensors",
|
| 153 |
+
"model.layers.2.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 154 |
+
"model.layers.2.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 155 |
+
"model.layers.2.mlp.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 156 |
+
"model.layers.2.mlp.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 157 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 158 |
+
"model.layers.2.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 159 |
+
"model.layers.2.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 160 |
+
"model.layers.2.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 161 |
+
"model.layers.2.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 162 |
+
"model.layers.2.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 163 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 164 |
+
"model.layers.20.mlp.bias": "model-00003-of-00004.safetensors",
|
| 165 |
+
"model.layers.20.mlp.glu_linear.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"model.layers.20.mlp.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"model.layers.20.mlp.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 168 |
+
"model.layers.20.mlp.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 169 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 170 |
+
"model.layers.20.self_attention.experts.bias": "model-00003-of-00004.safetensors",
|
| 171 |
+
"model.layers.20.self_attention.experts.input_linear.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"model.layers.20.self_attention.experts.output_linear.weight": "model-00003-of-00004.safetensors",
|
| 173 |
+
"model.layers.20.self_attention.experts.router.layer.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"model.layers.20.self_attention.kv_proj.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"model.layers.21.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 176 |
+
"model.layers.21.mlp.bias": "model-00004-of-00004.safetensors",
|
| 177 |
+
"model.layers.21.mlp.glu_linear.weight": "model-00004-of-00004.safetensors",
|
| 178 |
+
"model.layers.21.mlp.input_linear.weight": "model-00004-of-00004.safetensors",
|
| 179 |
+
"model.layers.21.mlp.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 180 |
+
"model.layers.21.mlp.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 181 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 182 |
+
"model.layers.21.self_attention.experts.bias": "model-00004-of-00004.safetensors",
|
| 183 |
+
"model.layers.21.self_attention.experts.input_linear.weight": "model-00004-of-00004.safetensors",
|
| 184 |
+
"model.layers.21.self_attention.experts.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 185 |
+
"model.layers.21.self_attention.experts.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 186 |
+
"model.layers.21.self_attention.kv_proj.weight": "model-00004-of-00004.safetensors",
|
| 187 |
+
"model.layers.22.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 188 |
+
"model.layers.22.mlp.bias": "model-00004-of-00004.safetensors",
|
| 189 |
+
"model.layers.22.mlp.glu_linear.weight": "model-00004-of-00004.safetensors",
|
| 190 |
+
"model.layers.22.mlp.input_linear.weight": "model-00004-of-00004.safetensors",
|
| 191 |
+
"model.layers.22.mlp.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 192 |
+
"model.layers.22.mlp.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 193 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 194 |
+
"model.layers.22.self_attention.experts.bias": "model-00004-of-00004.safetensors",
|
| 195 |
+
"model.layers.22.self_attention.experts.input_linear.weight": "model-00004-of-00004.safetensors",
|
| 196 |
+
"model.layers.22.self_attention.experts.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 197 |
+
"model.layers.22.self_attention.experts.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 198 |
+
"model.layers.22.self_attention.kv_proj.weight": "model-00004-of-00004.safetensors",
|
| 199 |
+
"model.layers.23.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 200 |
+
"model.layers.23.mlp.bias": "model-00004-of-00004.safetensors",
|
| 201 |
+
"model.layers.23.mlp.glu_linear.weight": "model-00004-of-00004.safetensors",
|
| 202 |
+
"model.layers.23.mlp.input_linear.weight": "model-00004-of-00004.safetensors",
|
| 203 |
+
"model.layers.23.mlp.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 204 |
+
"model.layers.23.mlp.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 205 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 206 |
+
"model.layers.23.self_attention.experts.bias": "model-00004-of-00004.safetensors",
|
| 207 |
+
"model.layers.23.self_attention.experts.input_linear.weight": "model-00004-of-00004.safetensors",
|
| 208 |
+
"model.layers.23.self_attention.experts.output_linear.weight": "model-00004-of-00004.safetensors",
|
| 209 |
+
"model.layers.23.self_attention.experts.router.layer.weight": "model-00004-of-00004.safetensors",
|
| 210 |
+
"model.layers.23.self_attention.kv_proj.weight": "model-00004-of-00004.safetensors",
|
| 211 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 212 |
+
"model.layers.3.mlp.bias": "model-00001-of-00004.safetensors",
|
| 213 |
+
"model.layers.3.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 214 |
+
"model.layers.3.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 215 |
+
"model.layers.3.mlp.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 216 |
+
"model.layers.3.mlp.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 217 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 218 |
+
"model.layers.3.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 219 |
+
"model.layers.3.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 220 |
+
"model.layers.3.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 221 |
+
"model.layers.3.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 222 |
+
"model.layers.3.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 223 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 224 |
+
"model.layers.4.mlp.bias": "model-00001-of-00004.safetensors",
|
| 225 |
+
"model.layers.4.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 226 |
+
"model.layers.4.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 227 |
+
"model.layers.4.mlp.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 228 |
+
"model.layers.4.mlp.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 229 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 230 |
+
"model.layers.4.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 231 |
+
"model.layers.4.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 232 |
+
"model.layers.4.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 233 |
+
"model.layers.4.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 234 |
+
"model.layers.4.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 235 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 236 |
+
"model.layers.5.mlp.bias": "model-00001-of-00004.safetensors",
|
| 237 |
+
"model.layers.5.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 238 |
+
"model.layers.5.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 239 |
+
"model.layers.5.mlp.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 240 |
+
"model.layers.5.mlp.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 241 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 242 |
+
"model.layers.5.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 243 |
+
"model.layers.5.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 244 |
+
"model.layers.5.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 245 |
+
"model.layers.5.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 246 |
+
"model.layers.5.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 247 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 248 |
+
"model.layers.6.mlp.bias": "model-00001-of-00004.safetensors",
|
| 249 |
+
"model.layers.6.mlp.glu_linear.weight": "model-00001-of-00004.safetensors",
|
| 250 |
+
"model.layers.6.mlp.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 251 |
+
"model.layers.6.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 252 |
+
"model.layers.6.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 253 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 254 |
+
"model.layers.6.self_attention.experts.bias": "model-00001-of-00004.safetensors",
|
| 255 |
+
"model.layers.6.self_attention.experts.input_linear.weight": "model-00001-of-00004.safetensors",
|
| 256 |
+
"model.layers.6.self_attention.experts.output_linear.weight": "model-00001-of-00004.safetensors",
|
| 257 |
+
"model.layers.6.self_attention.experts.router.layer.weight": "model-00001-of-00004.safetensors",
|
| 258 |
+
"model.layers.6.self_attention.kv_proj.weight": "model-00001-of-00004.safetensors",
|
| 259 |
+
"model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 260 |
+
"model.layers.7.mlp.bias": "model-00002-of-00004.safetensors",
|
| 261 |
+
"model.layers.7.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 262 |
+
"model.layers.7.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 263 |
+
"model.layers.7.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 264 |
+
"model.layers.7.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 265 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 266 |
+
"model.layers.7.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 267 |
+
"model.layers.7.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 268 |
+
"model.layers.7.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 269 |
+
"model.layers.7.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 270 |
+
"model.layers.7.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 271 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 272 |
+
"model.layers.8.mlp.bias": "model-00002-of-00004.safetensors",
|
| 273 |
+
"model.layers.8.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 274 |
+
"model.layers.8.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 275 |
+
"model.layers.8.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 276 |
+
"model.layers.8.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 277 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 278 |
+
"model.layers.8.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 279 |
+
"model.layers.8.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 280 |
+
"model.layers.8.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 281 |
+
"model.layers.8.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 282 |
+
"model.layers.8.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 283 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 284 |
+
"model.layers.9.mlp.bias": "model-00002-of-00004.safetensors",
|
| 285 |
+
"model.layers.9.mlp.glu_linear.weight": "model-00002-of-00004.safetensors",
|
| 286 |
+
"model.layers.9.mlp.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 287 |
+
"model.layers.9.mlp.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 288 |
+
"model.layers.9.mlp.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 289 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 290 |
+
"model.layers.9.self_attention.experts.bias": "model-00002-of-00004.safetensors",
|
| 291 |
+
"model.layers.9.self_attention.experts.input_linear.weight": "model-00002-of-00004.safetensors",
|
| 292 |
+
"model.layers.9.self_attention.experts.output_linear.weight": "model-00002-of-00004.safetensors",
|
| 293 |
+
"model.layers.9.self_attention.experts.router.layer.weight": "model-00002-of-00004.safetensors",
|
| 294 |
+
"model.layers.9.self_attention.kv_proj.weight": "model-00002-of-00004.safetensors",
|
| 295 |
+
"model.norm.weight": "model-00004-of-00004.safetensors"
|
| 296 |
+
}
|
| 297 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "</s>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"clean_up_tokenization_spaces": false,
|
| 33 |
+
"eos_token": "</s>",
|
| 34 |
+
"legacy": true,
|
| 35 |
+
"model_max_length": 4096,
|
| 36 |
+
"pad_token": "</s>",
|
| 37 |
+
"padding_side": "left",
|
| 38 |
+
"sp_model_kwargs": {},
|
| 39 |
+
"spaces_between_special_tokens": false,
|
| 40 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 41 |
+
"unk_token": "<unk>",
|
| 42 |
+
"use_default_system_prompt": false
|
| 43 |
+
}
|