

update readme
Browse files- README.md +3 -2
- images/Phase1_data.png +0 -0
- images/Phase2_data.png +0 -0
README.md
CHANGED
|
@@ -64,11 +64,12 @@ JetMoE-8x1B is trained on 1.25T tokens from publicly available datasets, with a
|
|
| 64 |
**Output** Models generate text only.
|
| 65 |
|
| 66 |
## Training Details
|
| 67 |
-
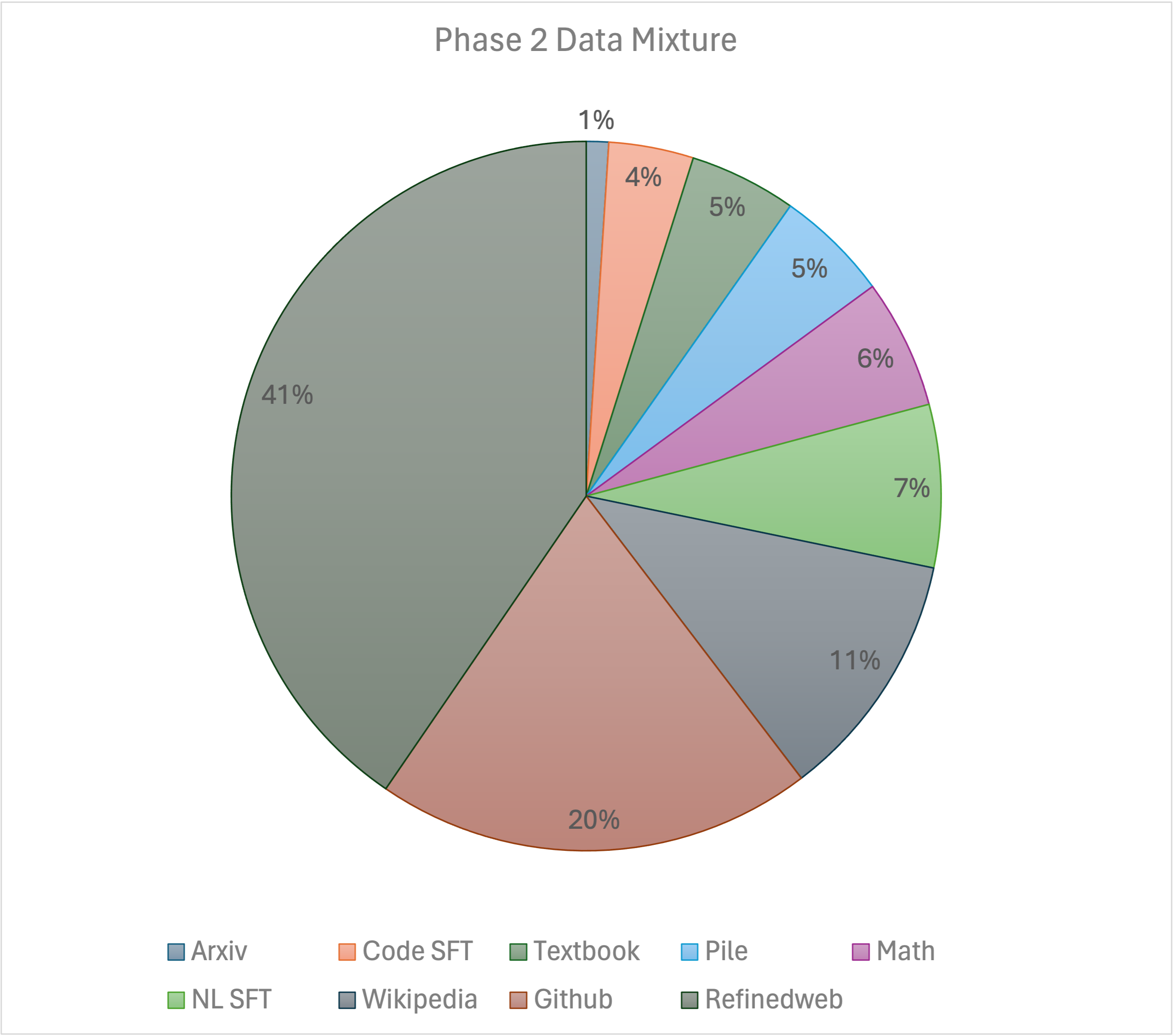
Our training recipe follows the [MiniCPM](https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?pvs=4)'s two-phases training method. Phase 1 uses a constant learning rate with linear warmup and is trained on 1 trillion tokens from large-scale open-source pretraining datasets, including RefinedWeb, Pile, Github data, etc. Phase 2 uses
|
|
|
|
| 68 |
<figure>
|
| 69 |
<center>
|
| 70 |
<img src="images/Phase1_data.png" width="60%">
|
| 71 |
-
<img src="images/Phase2_data.png" width="
|
| 72 |
</center>
|
| 73 |
</figure>
|
| 74 |
|
|
|
|
| 64 |
**Output** Models generate text only.
|
| 65 |
|
| 66 |
## Training Details
|
| 67 |
+
Our training recipe follows the [MiniCPM](https://shengdinghu.notion.site/MiniCPM-Unveiling-the-Potential-of-End-side-Large-Language-Models-d4d3a8c426424654a4e80e42a711cb20?pvs=4)'s two-phases training method. Phase 1 uses a constant learning rate with linear warmup and is trained on 1 trillion tokens from large-scale open-source pretraining datasets, including RefinedWeb, Pile, Github data, etc. Phase 2 uses exponential learning rate decay and is trained on 250 billion tokens from phase 1 datasets and extra high-quality open-source datasets.
|
| 68 |
+
|
| 69 |
<figure>
|
| 70 |
<center>
|
| 71 |
<img src="images/Phase1_data.png" width="60%">
|
| 72 |
+
<img src="images/Phase2_data.png" width="60%">
|
| 73 |
</center>
|
| 74 |
</figure>
|
| 75 |
|
images/Phase1_data.png
CHANGED

|

|
images/Phase2_data.png
CHANGED

|
|