

license: apache-2.0
tags:
- dllm
- diffusion
- llm
- text_generation
library_name: transformers
LLaDA-MoE
LLaDA-MoE is a new and upgraded series of the LLaDA diffusion language model. This pre-release includes two cutting-edge models:
LLaDA-MoE-7B-A1B-Base: A base pre-trained model designed for research and secondary development.LLaDA-MoE-7B-A1B-Instruct: An instruction-tuned model optimized for practical applications.
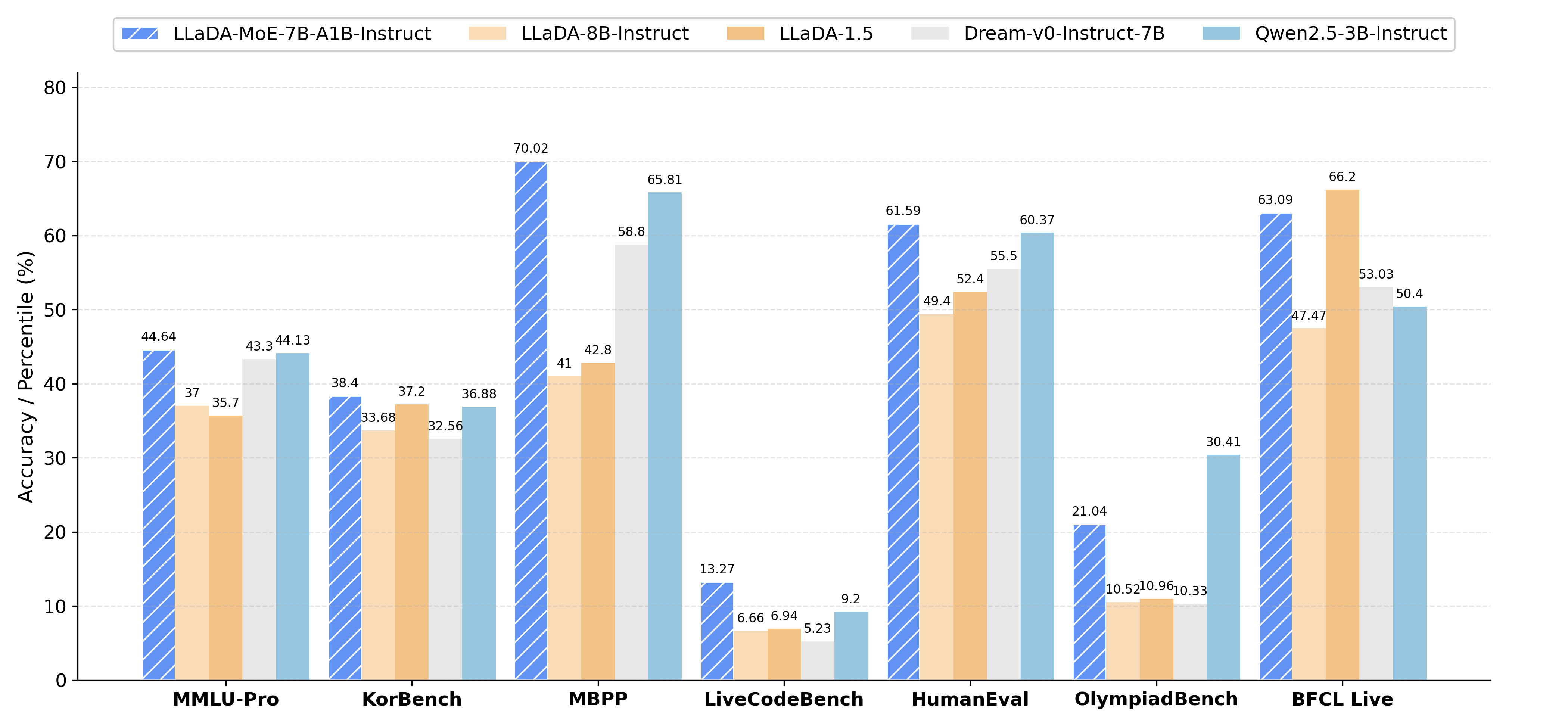
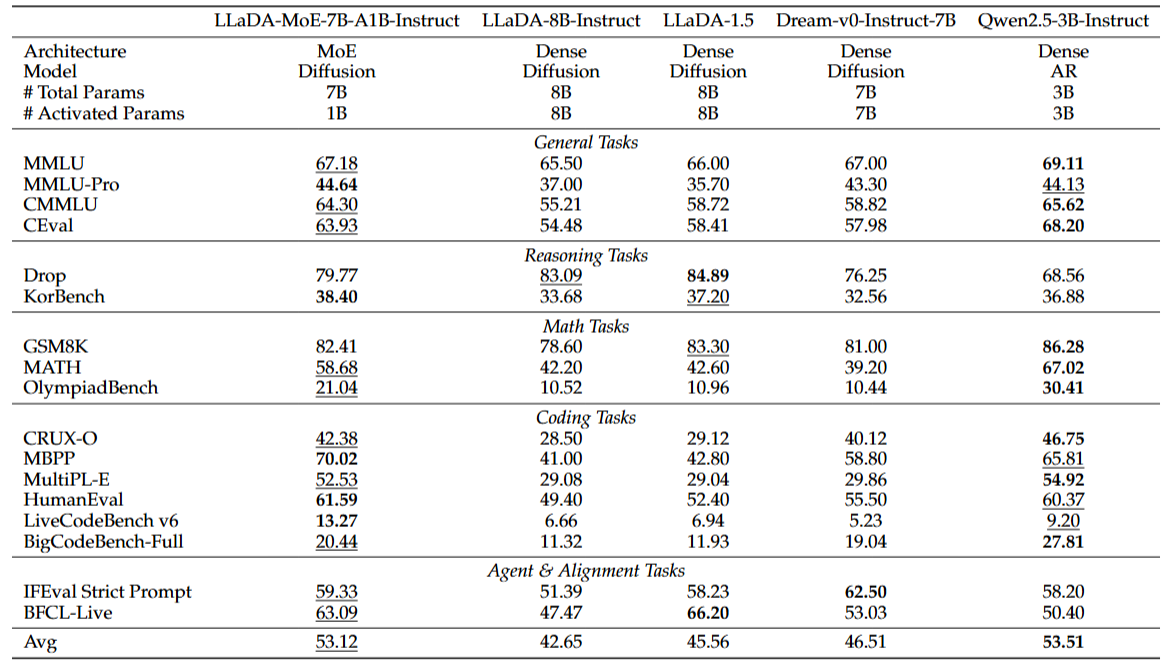
🚀 Performance Highlights
Leading MoE Architecture:
The first open-source Mixture-of-Experts (MoE) diffusion large language model, pre-trained from scratch on approximately 20 trillion tokens.Efficient Inference:
With 7 billion total parameters, only 1.4 billion are activated during inference. LLaDA-MoE significantly reduces computational costs while outperforming open-source dense models of similar scale.Impressive Performance on Code & Complex Reasoning:
Excels in tasks such as code generation and advanced mathematical reasoning, demonstrating strong reasoning capabilities.Tool Use:
Supports tool calling and achieves excellent performance in complex agent-based tasks.Open & Extensible:
Fully open-source with commitment to transparency. We plan to release a leading inference framework in the future and continue investing in cutting-edge areas like diffusion LLMs (dLLM) to drive disruptive innovation.
📦 Model Variants
| Model ID | Description | Hugging Face Link |
|---|---|---|
inclusionAI/LLaDA-MoE-7B-A1B-Base |
Base pre-trained model for research and fine-tuning. | 🤗 Model Card |
inclusionAI/LLaDA-MoE-7B-A1B-Instruct |
Instruction-tuned model, ready for downstream applications. | 🤗 Model Card |
🔍 Model Overview
LLaDA-MoE-7B-A1B has the following specifications:
- Type: Mixture-of-Experts (MoE) Diffusion Language Model
- Total Parameters (Non-Embedding): 7.03B
- Number of Layers: 16
- Attention Heads: 16
- Context Length: 4,096 tokens
- Position Embedding: Rotary (RoPE)
- Vocabulary Size: 157,184
⚡ Quickstart
Make sure you have transformers and its dependencies installed:
pip install transformers torch
You can then load the model using the AutoModelForCausalLM and AutoTokenizer classes:
import torch
import numpy as np
import torch.nn.functional as F
from transformers import AutoTokenizer, AutoModel
def add_gumbel_noise(logits, temperature):
if temperature == 0:
return logits
logits = logits.to(torch.float64)
noise = torch.rand_like(logits, dtype=torch.float64)
gumbel_noise = (- torch.log(noise)) ** temperature
return logits.exp() / gumbel_noise
def get_num_transfer_tokens(mask_index, steps):
mask_num = mask_index.sum(dim=1, keepdim=True)
base = mask_num // steps
remainder = mask_num % steps
num_transfer_tokens = torch.zeros(mask_num.size(0), steps, device=mask_index.device, dtype=torch.int64) + base
for i in range(mask_num.size(0)):
num_transfer_tokens[i, :remainder[i]] += 1
return num_transfer_tokens
@ torch.no_grad()
def generate(model, prompt, steps=128, gen_length=128, block_length=128, temperature=0.,
cfg_scale=0., remasking='low_confidence', mask_id=156895):
x = torch.full((1, prompt.shape[1] + gen_length), mask_id, dtype=torch.long).to(model.device)
x[:, :prompt.shape[1]] = prompt.clone()
prompt_index = (x != mask_id)
assert gen_length % block_length == 0
num_blocks = gen_length // block_length
assert steps % num_blocks == 0
steps = steps // num_blocks
for num_block in range(num_blocks):
block_mask_index = (x[:, prompt.shape[1] + num_block * block_length: prompt.shape[1] + (num_block + 1) * block_length:] == mask_id)
num_transfer_tokens = get_num_transfer_tokens(block_mask_index, steps)
for i in range(steps):
mask_index = (x == mask_id)
if cfg_scale > 0.:
un_x = x.clone()
un_x[prompt_index] = mask_id
x_ = torch.cat([x, un_x], dim=0)
logits = model(x_).logits
logits, un_logits = torch.chunk(logits, 2, dim=0)
logits = un_logits + (cfg_scale + 1) * (logits - un_logits)
else:
logits = model(x).logits
logits_with_noise = add_gumbel_noise(logits, temperature=temperature)
x0 = torch.argmax(logits_with_noise, dim=-1) # b, l
if remasking == 'low_confidence':
p = F.softmax(logits, dim=-1)
x0_p = torch.squeeze(
torch.gather(p, dim=-1, index=torch.unsqueeze(x0, -1)), -1) # b, l
elif remasking == 'random':
x0_p = torch.rand((x0.shape[0], x0.shape[1]), device=x0.device)
else:
raise NotImplementedError(remasking)
x0_p[:, prompt.shape[1] + (num_block + 1) * block_length:] = -np.inf
x0 = torch.where(mask_index, x0, x)
confidence = torch.where(mask_index, x0_p, -np.inf)
transfer_index = torch.zeros_like(x0, dtype=torch.bool, device=x0.device)
for j in range(confidence.shape[0]):
_, select_index = torch.topk(confidence[j], k=num_transfer_tokens[j, i])
transfer_index[j, select_index] = True
x[transfer_index] = x0[transfer_index]
return x
device = 'cuda'
model = AutoModel.from_pretrained('inclusionAI/LLaDA-MoE-7B-A1B-Instruct', trust_remote_code=True, torch_dtype=torch.bfloat16).to(device).eval()
tokenizer = AutoTokenizer.from_pretrained('inclusionAI/LLaDA-MoE-7B-A1B-Instruct', trust_remote_code=True)
prompt = "Lily can run 12 kilometers per hour for 4 hours. After that, she runs 6 kilometers per hour. How many kilometers can she run in 8 hours?"
m = [
{"role": "system", "content": "You are a helpful AI assistant."},
{"role": "user", "content": prompt}
]
prompt = tokenizer.apply_chat_template(m, add_generation_prompt=True, tokenize=False)
input_ids = tokenizer(prompt)['input_ids']
input_ids = torch.tensor(input_ids).to(device).unsqueeze(0)
text = generate(model, input_ids, steps=128, gen_length=128, block_length=32, temperature=0., cfg_scale=0., remasking='low_confidence')
print(tokenizer.batch_decode(text[:, input_ids.shape[1]:], skip_special_tokens=False)[0])
📚 Citation (Coming Soon)
We are preparing the technical report and citation information.
Stay tuned — citation details will be available soon.
🌐 License
This project is licensed under the terms of the Apache License 2.0.
🤝 Contact & Collaboration
For questions, collaborations, or feedback, please reach out via Hugging Face or open an issue in the repository.
👉 Join us in advancing open, efficient, and intelligent language models!