language:
- nl
thumbnail: geobertje.png
tags:
- GEOBERTje
GEOBERTje
A Domain-Adapted Dutch Language Model Trained on Geological Borehole Descriptions

Description
GEOBERTje is a language model built upon the BERTje architecture, comprising 109 million parameters. It has been further trained using masked language modeling (MLM) on a dataset of approximately 300,000 borehole descriptions in the Dutch language from the Flanders region in Belgium. It can serve as the base language model for a variety of geological applications. For instance, by leveraging the model's understanding of geological terminology and borehole data, professionals can streamline the process of interpreting subsurface information and generating detailed 3D representations of geological structures. This capability opens up new possibilities for improved exploration, interpretation, and analysis in the field of geology.
Hugging Face API
How to use GEOBERTje as a pipeline:
from transformers import pipeline
pipe = pipeline("fill-mask", model="hghcomphys/geobertje-base-dutch-uncased")
pipe("grijs fijn zand met enkele [MASK]")
How to load it directly:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("hghcomphys/geobertje-base-dutch-uncased")
model = AutoModel.from_pretrained("hghcomphys/geobertje-base-dutch-uncased")
Application
To showcase the potential application of GEOBERTje, we fine-tuned it on a limited dataset of 3,000 labeled samples.
This fine-tuning allowed the model to classify various lithological categories.
For example Grijs kleiig zand, zeer fijn, met enkele grindjes will be classified as main lithology: fijn zand, second lithology: klei, third lithology: grind.
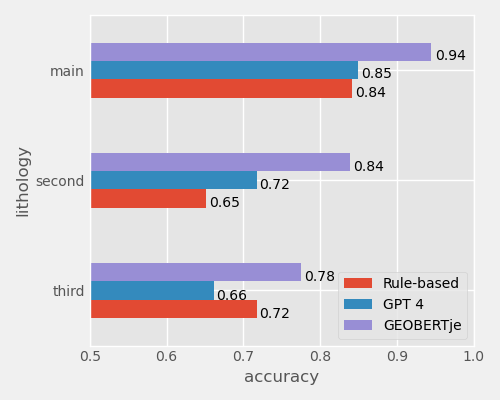
Our classifier obtained higher accuracy than conventional rule-based approaches or zero-shot classification using GPT-4.
The figure below shows comparative accuracy of rule-based, GPT-4, and GEOBERTje models in classifying
main, secondary, and tertiary lithology from geological drill core descriptions.