
Upload 51 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +8 -0
- README.md +298 -0
- app.py +89 -0
- ckpts/ckpts_file.txt +0 -0
- data/data_file.txt +0 -0
- image/low_haze_rain_00469_01_lq.png +3 -0
- image/low_haze_snow_00337_01_lq.png +3 -0
- img_file/OneRestore_poster.png +3 -0
- img_file/abstract.jpg +3 -0
- img_file/cal_psnr_ssim.py +96 -0
- img_file/clear_img.jpg +0 -0
- img_file/control1.jpg +0 -0
- img_file/control2.jpg +0 -0
- img_file/depth_map.jpg +0 -0
- img_file/l+h+r.jpg +0 -0
- img_file/l+h+s.jpg +0 -0
- img_file/light_map.jpg +0 -0
- img_file/logo_onerestore.png +0 -0
- img_file/metric.png +0 -0
- img_file/metrics_CDD-11_psnr_ssim.xlsx +0 -0
- img_file/pipeline.jpg +3 -0
- img_file/rain_mask.jpg +0 -0
- img_file/real.jpg +3 -0
- img_file/snow_mask.png +0 -0
- img_file/syn.jpg +0 -0
- makedataset.py +157 -0
- model/Embedder.py +238 -0
- model/OneRestore.py +314 -0
- model/loss.py +222 -0
- output/low_haze_rain_00469_01_lq.png +3 -0
- output/low_haze_snow_00337_01_lq.png +3 -0
- remove_optim.py +32 -0
- requirements.txt +10 -0
- syn_data/data/clear/1.jpg +0 -0
- syn_data/data/depth_map/1.jpg +0 -0
- syn_data/data/light_map/1.jpg +0 -0
- syn_data/data/rain_mask/00001.jpg +0 -0
- syn_data/data/rain_mask/00002.jpg +0 -0
- syn_data/data/rain_mask/00003.jpg +0 -0
- syn_data/data/snow_mask/beautiful_smile_00001.jpg +0 -0
- syn_data/data/snow_mask/beautiful_smile_00006.jpg +0 -0
- syn_data/data/snow_mask/beautiful_smile_00008.jpg +0 -0
- syn_data/out/1.jpg +0 -0
- syn_data/syn_data.py +86 -0
- test.py +82 -0
- train_Embedder.py +104 -0
- train_OneRestore_multi-gpu.py +153 -0
- train_OneRestore_single-gpu.py +140 -0
- utils/glove.6B.300d.txt +5 -0
- utils/utils.py +232 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,11 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
image/low_haze_rain_00469_01_lq.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
image/low_haze_snow_00337_01_lq.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
img_file/abstract.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
img_file/OneRestore_poster.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
img_file/pipeline.jpg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
img_file/real.jpg filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
output/low_haze_rain_00469_01_lq.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
output/low_haze_snow_00337_01_lq.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
</div>
|
| 2 |
+
<div align=center>
|
| 3 |
+
<img src="https://github.com/gy65896/OneRestore/blob/main/img_file/logo_onerestore.png" width="200">
|
| 4 |
+
</div>
|
| 5 |
+
|
| 6 |
+
# <p align=center> [ECCV 2024] OneRestore: A Universal Restoration Framework for Composite Degradation</p>
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
<div align="center">
|
| 10 |
+
|
| 11 |
+
[](https://arxiv.org/abs/2407.04621)
|
| 12 |
+
[](https://arxiv.org/abs/2407.04621)
|
| 13 |
+
[](https://gy65896.github.io/projects/ECCV2024_OneRestore/index.html)
|
| 14 |
+
[](https://github.com/gy65896/OneRestore/blob/main/img_file/OneRestore_poster.png)
|
| 15 |
+
[](https://www.youtube.com/watch?v=AFr5tZdPlZ4)
|
| 16 |
+
|
| 17 |
+
[](https://hits.seeyoufarm.com)
|
| 18 |
+
[](https://huggingface.co/spaces/gy65896/OneRestore)
|
| 19 |
+
[](https://github.com/gy65896/OneRestore/issues?q=is%3Aissue+is%3Aclosed)
|
| 20 |
+
[](https://github.com/gy65896/OneRestore/issues)
|
| 21 |
+
|
| 22 |
+
[](https://paperswithcode.com/sota/low-light-image-enhancement-on-lol?p=onerestore-a-universal-restoration-framework)
|
| 23 |
+
[](https://paperswithcode.com/sota/image-dehazing-on-sots-outdoor?p=onerestore-a-universal-restoration-framework)
|
| 24 |
+
[](https://paperswithcode.com/sota/rain-removal-on-did-mdn?p=onerestore-a-universal-restoration-framework)
|
| 25 |
+
[](https://paperswithcode.com/sota/snow-removal-on-snow100k?p=onerestore-a-universal-restoration-framework)
|
| 26 |
+
|
| 27 |
+
</div>
|
| 28 |
+
<div align=center>
|
| 29 |
+
<img src="https://github.com/gy65896/OneRestore/blob/main/img_file/abstract.jpg" width="720">
|
| 30 |
+
</div>
|
| 31 |
+
|
| 32 |
+
---
|
| 33 |
+
>**OneRestore: A Universal Restoration Framework for Composite Degradation**<br> [Yu Guo](https://scholar.google.com/citations?user=klYz-acAAAAJ&hl=zh-CN)<sup>† </sup>, [Yuan Gao](https://scholar.google.com.hk/citations?user=4JpRnU4AAAAJ&hl=zh-CN)<sup>† </sup>, [Yuxu Lu](https://scholar.google.com.hk/citations?user=XXge2_0AAAAJ&hl=zh-CN), [Huilin Zhu](https://scholar.google.com.hk/citations?hl=zh-CN&user=fluPrxcAAAAJ), [Ryan Wen Liu](http://mipc.whut.edu.cn/index.html)<sup>* </sup>, [Shengfeng He](http://www.shengfenghe.com/)<sup>* </sup> <br>
|
| 34 |
+
(† Co-first Author, * Corresponding Author)<br>
|
| 35 |
+
>European Conference on Computer Vision
|
| 36 |
+
|
| 37 |
+
> **Abstract:** *In real-world scenarios, image impairments often manifest as composite degradations, presenting a complex interplay of elements such as low light, haze, rain, and snow. Despite this reality, existing restoration methods typically target isolated degradation types, thereby falling short in environments where multiple degrading factors coexist. To bridge this gap, our study proposes a versatile imaging model that consolidates four physical corruption paradigms to accurately represent complex, composite degradation scenarios. In this context, we propose OneRestore, a novel transformer-based framework designed for adaptive, controllable scene restoration. The proposed framework leverages a unique cross-attention mechanism, merging degraded scene descriptors with image features, allowing for nuanced restoration. Our model allows versatile input scene descriptors, ranging from manual text embeddings to automatic extractions based on visual attributes. Our methodology is further enhanced through a composite degradation restoration loss, using extra degraded images as negative samples to fortify model constraints. Comparative results on synthetic and real-world datasets demonstrate OneRestore as a superior solution, significantly advancing the state-of-the-art in addressing complex, composite degradations.*
|
| 38 |
+
---
|
| 39 |
+
|
| 40 |
+
## News 🚀
|
| 41 |
+
* **2024.09.07**: [Hugging Face Demo](https://huggingface.co/spaces/gy65896/OneRestore) is released.
|
| 42 |
+
* **2024.09.05**: Video and poster are released.
|
| 43 |
+
* **2024.09.04**: Code for data synthesis is released.
|
| 44 |
+
* **2024.07.27**: Code for multiple GPUs training is released.
|
| 45 |
+
* **2024.07.20**: [New Website](https://gy65896.github.io/projects/ECCV2024_OneRestore) has been created.
|
| 46 |
+
* **2024.07.10**: [Paper](https://arxiv.org/abs/2407.04621) is released on ArXiv.
|
| 47 |
+
* **2024.07.07**: Code and Dataset are released.
|
| 48 |
+
* **2024.07.02**: OneRestore is accepted by [ECCV2024](https://eccv.ecva.net/).
|
| 49 |
+
|
| 50 |
+
## Network Architecture
|
| 51 |
+
|
| 52 |
+
</div>
|
| 53 |
+
<div align=center>
|
| 54 |
+
<img src="https://github.com/gy65896/OneRestore/blob/main/img_file/pipeline.jpg" width="1080">
|
| 55 |
+
</div>
|
| 56 |
+
|
| 57 |
+
## Quick Start
|
| 58 |
+
|
| 59 |
+
### Install
|
| 60 |
+
|
| 61 |
+
- python 3.7
|
| 62 |
+
- cuda 11.7
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
# git clone this repository
|
| 66 |
+
git clone https://github.com/gy65896/OneRestore.git
|
| 67 |
+
cd OneRestore
|
| 68 |
+
|
| 69 |
+
# create new anaconda env
|
| 70 |
+
conda create -n onerestore python=3.7
|
| 71 |
+
conda activate onerestore
|
| 72 |
+
|
| 73 |
+
# download ckpts
|
| 74 |
+
put embedder_model.tar and onerestore_cdd-11.tar in ckpts folder
|
| 75 |
+
|
| 76 |
+
# install pytorch (Take cuda 11.7 as an example to install torch 1.13)
|
| 77 |
+
pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117
|
| 78 |
+
|
| 79 |
+
# install other packages
|
| 80 |
+
pip install -r requirements.txt
|
| 81 |
+
pip install gensim
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
### Pretrained Models
|
| 85 |
+
|
| 86 |
+
Please download our pre-trained models and put them in `./ckpts`.
|
| 87 |
+
|
| 88 |
+
| Model | Description
|
| 89 |
+
| :--- | :----------
|
| 90 |
+
|[embedder_model.tar](https://1drv.ms/u/s!As3rCDROnrbLgqpnhSQFIoD9msXWOA?e=aUpHOT) | Text/Visual Embedder trained on our CDD-11.
|
| 91 |
+
|[onerestore_cdd-11.tar](https://1drv.ms/u/s!As3rCDROnrbLgqpmWkGBku6oj33efg?e=7yUGfN) | OneRestore trained on our CDD-11.
|
| 92 |
+
|[onerestore_real.tar](https://1drv.ms/u/s!As3rCDROnrbLgqpi-iJOyN6OSYqiaA?e=QFfMeL) | OneRestore trained on our CDD-11 for Real Scenes.
|
| 93 |
+
|[onerestore_lol.tar](https://1drv.ms/u/s!As3rCDROnrbLgqpkSoVB1j-wYHFpHg?e=0gR9pn) | OneRestore trained on LOL (low light enhancement benchmark).
|
| 94 |
+
|[onerestore_reside_ots.tar](https://1drv.ms/u/s!As3rCDROnrbLgqpjGh8KjfM_QIJzEw?e=zabGTw) | OneRestore trained on RESIDE-OTS (image dehazing benchmark).
|
| 95 |
+
|[onerestore_rain1200.tar](https://1drv.ms/u/s!As3rCDROnrbLgqplAFHv6B348jarGA?e=GuduMT) | OneRestore trained on Rain1200 (image deraining benchmark).
|
| 96 |
+
|[onerestore_snow100k.tar](https://1drv.ms/u/s!As3rCDROnrbLgqphsWWxLZN_7JFJDQ?e=pqezzo) | OneRestore trained on Snow100k-L (image desnowing benchmark).
|
| 97 |
+
|
| 98 |
+
### Inference
|
| 99 |
+
|
| 100 |
+
We provide two samples in `./image` for the quick inference:
|
| 101 |
+
|
| 102 |
+
```
|
| 103 |
+
python test.py --embedder-model-path ./ckpts/embedder_model.tar --restore-model-path ./ckpts/onerestore_cdd-11.tar --input ./image/ --output ./output/ --concat
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
You can also input the prompt to perform controllable restoration. For example:
|
| 107 |
+
|
| 108 |
+
```
|
| 109 |
+
python test.py --embedder-model-path ./ckpts/embedder_model.tar --restore-model-path ./ckpts/onerestore_cdd-11.tar --prompt low_haze --input ./image/ --output ./output/ --concat
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
## Training
|
| 113 |
+
|
| 114 |
+
### Prepare Dataset
|
| 115 |
+
|
| 116 |
+
We provide the download link of our Composite Degradation Dataset with 11 types of degradation ([CDD-11](https://1drv.ms/f/s!As3rCDROnrbLgqpezG4sao-u9ddDhw?e=A0REHx)).
|
| 117 |
+
|
| 118 |
+
Preparing the train and test datasets as follows:
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
./data/
|
| 122 |
+
|--train
|
| 123 |
+
| |--clear
|
| 124 |
+
| | |--000001.png
|
| 125 |
+
| | |--000002.png
|
| 126 |
+
| |--low
|
| 127 |
+
| |--haze
|
| 128 |
+
| |--rain
|
| 129 |
+
| |--snow
|
| 130 |
+
| |--low_haze
|
| 131 |
+
| |--low_rain
|
| 132 |
+
| |--low_snow
|
| 133 |
+
| |--haze_rain
|
| 134 |
+
| |--haze_snow
|
| 135 |
+
| |--low_haze_rain
|
| 136 |
+
| |--low_haze_snow
|
| 137 |
+
|--test
|
| 138 |
+
```
|
| 139 |
+
### Train Model
|
| 140 |
+
|
| 141 |
+
**1. Train Text/Visual Embedder by**
|
| 142 |
+
|
| 143 |
+
```
|
| 144 |
+
python train_Embedder.py --train-dir ./data/CDD-11_train --test-dir ./data/CDD-11_test --check-dir ./ckpts --batch 256 --num-workers 0 --epoch 200 --lr 1e-4 --lr-decay 50
|
| 145 |
+
```
|
| 146 |
+
|
| 147 |
+
**2. Remove the optimizer weights in the Embedder model file by**
|
| 148 |
+
|
| 149 |
+
```
|
| 150 |
+
python remove_optim.py --type Embedder --input-file ./ckpts/embedder_model.tar --output-file ./ckpts/embedder_model.tar
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
**3. Generate the `dataset.h5` file for training OneRestore by**
|
| 154 |
+
|
| 155 |
+
```
|
| 156 |
+
python makedataset.py --train-path ./data/CDD-11_train --data-name dataset.h5 --patch-size 256 --stride 200
|
| 157 |
+
```
|
| 158 |
+
|
| 159 |
+
**4. Train OneRestore model by**
|
| 160 |
+
|
| 161 |
+
- **Single GPU**
|
| 162 |
+
|
| 163 |
+
```
|
| 164 |
+
python train_OneRestore_single-gpu.py --embedder-model-path ./ckpts/embedder_model.tar --save-model-path ./ckpts --train-input ./dataset.h5 --test-input ./data/CDD-11_test --output ./result/ --epoch 120 --bs 4 --lr 1e-4 --adjust-lr 30 --num-works 4
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
- **Multiple GPUs**
|
| 168 |
+
|
| 169 |
+
Assuming you train the OneRestore model using 4 GPUs (e.g., 0, 1, 2, and 3), you can use the following command. Note that the number of nproc_per_node should equal the number of GPUs.
|
| 170 |
+
|
| 171 |
+
```
|
| 172 |
+
CUDA_VISIBLE_DEVICES=0, 1, 2, 3 torchrun --nproc_per_node=4 train_OneRestore_multi-gpu.py --embedder-model-path ./ckpts/embedder_model.tar --save-model-path ./ckpts --train-input ./dataset.h5 --test-input ./data/CDD-11_test --output ./result/ --epoch 120 --bs 4 --lr 1e-4 --adjust-lr 30 --num-works 4
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
**5. Remove the optimizer weights in the OneRestore model file by**
|
| 176 |
+
|
| 177 |
+
```
|
| 178 |
+
python remove_optim.py --type OneRestore --input-file ./ckpts/onerestore_model.tar --output-file ./ckpts/onerestore_model.tar
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
### Customize your own composite degradation dataset
|
| 182 |
+
|
| 183 |
+
**1. Prepare raw data**
|
| 184 |
+
|
| 185 |
+
- Collect your own clear images.
|
| 186 |
+
- Generate the depth map based on [MegaDepth](https://github.com/zhengqili/MegaDepth).
|
| 187 |
+
- Generate the light map based on [LIME](https://github.com/estija/LIME).
|
| 188 |
+
- Generate the rain mask database based on [RainStreakGen](https://github.com/liruoteng/RainStreakGen?tab=readme-ov-file).
|
| 189 |
+
- Download the snow mask database from [Snow100k](https://sites.google.com/view/yunfuliu/desnownet).
|
| 190 |
+
|
| 191 |
+
A generated example is as follows:
|
| 192 |
+
|
| 193 |
+
| Clear Image | Depth Map | Light Map | Rain Mask | Snow Mask
|
| 194 |
+
| :--- | :---| :---| :--- | :---
|
| 195 |
+
| <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/clear_img.jpg" width="200"> | <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/depth_map.jpg" width="200"> | <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/light_map.jpg" width="200"> | <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/rain_mask.jpg" width="200"> | <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/snow_mask.png" width="200">
|
| 196 |
+
|
| 197 |
+
(Note: The rain and snow masks do not require strict alignment with the image.)
|
| 198 |
+
|
| 199 |
+
- Prepare the dataset as follows:
|
| 200 |
+
|
| 201 |
+
```
|
| 202 |
+
./syn_data/
|
| 203 |
+
|--data
|
| 204 |
+
| |--clear
|
| 205 |
+
| | |--000001.png
|
| 206 |
+
| | |--000002.png
|
| 207 |
+
| |--depth_map
|
| 208 |
+
| | |--000001.png
|
| 209 |
+
| | |--000002.png
|
| 210 |
+
| |--light_map
|
| 211 |
+
| | |--000001.png
|
| 212 |
+
| | |--000002.png
|
| 213 |
+
| |--rain_mask
|
| 214 |
+
| | |--aaaaaa.png
|
| 215 |
+
| | |--bbbbbb.png
|
| 216 |
+
| |--snow_mask
|
| 217 |
+
| | |--cccccc.png
|
| 218 |
+
| | |--dddddd.png
|
| 219 |
+
|--out
|
| 220 |
+
```
|
| 221 |
+
|
| 222 |
+
**2. Generate composite degradation images**
|
| 223 |
+
|
| 224 |
+
- low+haze+rain
|
| 225 |
+
|
| 226 |
+
```
|
| 227 |
+
python syn_data.py --hq-file ./data/clear/ --light-file ./data/light_map/ --depth-file ./data/depth_map/ --rain-file ./data/rain_mask/ --snow-file ./data/snow_mask/ --out-file ./out/ --low --haze --rain
|
| 228 |
+
```
|
| 229 |
+
|
| 230 |
+
- low+haze+snow
|
| 231 |
+
|
| 232 |
+
```
|
| 233 |
+
python syn_data.py --hq-file ./data/clear/ --light-file ./data/light_map/ --depth-file ./data/depth_map/ --rain-file ./data/rain_mask/ --snow-file ./data/snow_mask/ --out-file ./out/ --low --haze --snow
|
| 234 |
+
```
|
| 235 |
+
(Note: The degradation types can be customized according to specific needs.)
|
| 236 |
+
|
| 237 |
+
| Clear Image | low+haze+rain | low+haze+snow
|
| 238 |
+
| :--- | :--- | :---
|
| 239 |
+
| <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/clear_img.jpg" width="200"> | <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/l+h+r.jpg" width="200"> | <img src="https://github.com/gy65896/OneRestore/blob/main/img_file/l+h+s.jpg" width="200">
|
| 240 |
+
|
| 241 |
+
## Performance
|
| 242 |
+
|
| 243 |
+
### CDD-11
|
| 244 |
+
|
| 245 |
+
| Types | Methods | Venue & Year | PSNR ↑ | SSIM ↑ | #Params |
|
| 246 |
+
|-------------------|-----------------------------------------------|--------------|----------|----------|------------|
|
| 247 |
+
| Input | [Input](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuNlQAAAAABf9KaFodlfC8H-K_MNiriFw?e=SiOrWU) | | 16.00 | 0.6008 | - |
|
| 248 |
+
| One-to-One | [MIRNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuMlQAAAAABBzDLjLu69noXflImQ2V9ng?e=4wohVK) | ECCV2020 | 25.97 | 0.8474 | 31.79M |
|
| 249 |
+
| One-to-One | [MPRNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuLlQAAAAAB_iz3hjLHZDMi-RyxHKgDDg?e=SwSQML) | CVPR2021 | 25.47 | 0.8555 | 15.74M |
|
| 250 |
+
| One-to-One | [MIRNetv2](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuQlQAAAAAB2miyepdTE3qdy4z2-LM4pg?e=moXVAR) | TPAMI2022 | 25.37 | 0.8335 | 5.86M |
|
| 251 |
+
| One-to-One | [Restormer](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuPlQAAAAABE86t03kpAVm_TZDIBPKolw?e=vHAR7A) | CVPR2022 | 26.99 | 0.8646 | 26.13M |
|
| 252 |
+
| One-to-One | [DGUNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuOlQAAAAABZkHj8tMamqaGhQ0w4VwFrg?e=lfDUlx) | CVPR2022 | 26.92 | 0.8559 | 17.33M |
|
| 253 |
+
| One-to-One | [NAFNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/EWm9jiJiZLlLgq1trYO67EsB42LrjGpepvpS4oLqKnj8xg?e=5Efa4W) | ECCV2022 | 24.13 | 0.7964 | 17.11M |
|
| 254 |
+
| One-to-One | [SRUDC](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuWlQAAAAABf9RNAUZH_xL6wF4aODWKqA?e=h4EqVN) | ICCV2023 | 27.64 | 0.8600 | 6.80M |
|
| 255 |
+
| One-to-One | [Fourmer](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuXlQAAAAABQKrbA47G8kMD2cf7Chq5EQ?e=vOiWV0) | ICML2023 | 23.44 | 0.7885 | 0.55M |
|
| 256 |
+
| One-to-One | [OKNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuVlQAAAAABSMzfS1xEOxLeuvw8HsGyMw?e=jRmf9t) | AAAI2024 | 26.33 | 0.8605 | 4.72M |
|
| 257 |
+
| One-to-Many | [AirNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMualQAAAAABYJ96PX0fipkP93zRXN_NVw?e=sXFOl8) | CVPR2022 | 23.75 | 0.8140 | 8.93M |
|
| 258 |
+
| One-to-Many | [TransWeather](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuZlQAAAAABoBiLjwJ8L2kl6rGQO5PeJA?e=msprhI) | CVPR2022 | 23.13 | 0.7810 | 21.90M |
|
| 259 |
+
| One-to-Many | [WeatherDiff](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuYlQAAAAABxdWbznZA1CQ0Bh1JH_ze-A?e=LEkcZw) | TPAMI2023 | 22.49 | 0.7985 | 82.96M |
|
| 260 |
+
| One-to-Many | [PromptIR](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMublQAAAAAB9aGo3QK-WlKkL5ItITW9Hg?e=wXrJf1) | NIPS2023 | 25.90 | 0.8499 | 38.45M |
|
| 261 |
+
| One-to-Many | [WGWSNet](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMudlQAAAAABi3HUMldxdoLHgDcUNoWMPw?e=z0qjAH) | CVPR2023 | 26.96 | 0.8626 | 25.76M |
|
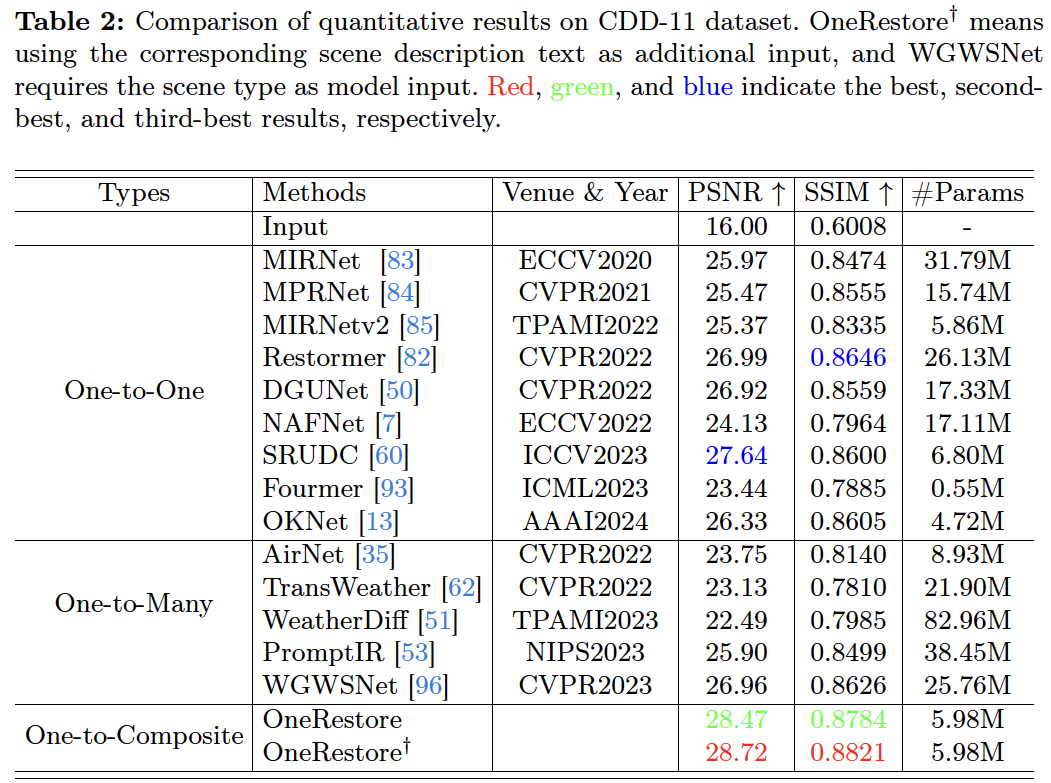
| 262 |
+
| One-to-Composite | [OneRestore](https://1drv.ms/u/c/cbb69e4e3408ebcd/Ec3rCDROnrYggMuclQAAAAABSmNvDBKR1u5rDtqQnZ8X7A?e=OcnrjY) | ECCV2024 | 28.47 | 0.8784 | 5.98M |
|
| 263 |
+
| One-to-Composite | [OneRestore<sup>† </sup>](https://1drv.ms/u/c/cbb69e4e3408ebcd/EVM43y_W_WxAjrZqZdK9sfoBk1vpSzKilG0m7T-3i3la-A?e=dbNsD3) | ECCV2024 | 28.72 | 0.8821 | 5.98M |
|
| 264 |
+
|
| 265 |
+
[Indicator calculation code](https://github.com/gy65896/OneRestore/blob/main/img_file/cal_psnr_ssim.py) and [numerical results](https://github.com/gy65896/OneRestore/blob/main/img_file/metrics_CDD-11_psnr_ssim.xlsx) can be download here.
|
| 266 |
+
|
| 267 |
+
</div>
|
| 268 |
+
<div align=center>
|
| 269 |
+
<img src="https://github.com/gy65896/OneRestore/blob/main/img_file/syn.jpg" width="1080">
|
| 270 |
+
</div>
|
| 271 |
+
|
| 272 |
+
### Real Scene
|
| 273 |
+
|
| 274 |
+
</div>
|
| 275 |
+
<div align=center>
|
| 276 |
+
<img src="https://github.com/gy65896/OneRestore/blob/main/img_file/real.jpg" width="1080">
|
| 277 |
+
</div>
|
| 278 |
+
|
| 279 |
+
### Controllability
|
| 280 |
+
|
| 281 |
+
</div>
|
| 282 |
+
<div align=center>
|
| 283 |
+
<img src="https://github.com/gy65896/OneRestore/blob/main/img_file/control1.jpg" width="410"><img src="https://github.com/gy65896/OneRestore/blob/main/img_file/control2.jpg" width="410">
|
| 284 |
+
</div>
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
## Citation
|
| 288 |
+
|
| 289 |
+
```
|
| 290 |
+
@inproceedings{guo2024onerestore,
|
| 291 |
+
title={OneRestore: A Universal Restoration Framework for Composite Degradation},
|
| 292 |
+
author={Guo, Yu and Gao, Yuan and Lu, Yuxu and Liu, Ryan Wen and He, Shengfeng},
|
| 293 |
+
booktitle={European Conference on Computer Vision},
|
| 294 |
+
year={2024}
|
| 295 |
+
}
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
#### If you have any questions, please get in touch with me (guoyu65896@gmail.com).
|
app.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
import gradio as gr
|
| 4 |
+
from torchvision import transforms
|
| 5 |
+
from PIL import Image
|
| 6 |
+
import numpy as np
|
| 7 |
+
from utils.utils import load_restore_ckpt, load_embedder_ckpt
|
| 8 |
+
import os
|
| 9 |
+
from gradio_imageslider import ImageSlider
|
| 10 |
+
|
| 11 |
+
# Enforce CPU usage
|
| 12 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 13 |
+
|
| 14 |
+
embedder_model_path = "ckpts/embedder_model.tar" # Update with actual path to embedder checkpoint
|
| 15 |
+
restorer_model_path = "ckpts/onerestore_cdd-11.tar" # Update with actual path to restorer checkpoint
|
| 16 |
+
|
| 17 |
+
# Load models on CPU only
|
| 18 |
+
embedder = load_embedder_ckpt(device, freeze_model=True, ckpt_name=embedder_model_path)
|
| 19 |
+
restorer = load_restore_ckpt(device, freeze_model=True, ckpt_name=restorer_model_path)
|
| 20 |
+
|
| 21 |
+
# Define image preprocessing and postprocessing
|
| 22 |
+
transform_resize = transforms.Compose([
|
| 23 |
+
transforms.Resize([224,224]),
|
| 24 |
+
transforms.ToTensor()
|
| 25 |
+
])
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def postprocess_image(tensor):
|
| 29 |
+
image = tensor.squeeze(0).cpu().detach().numpy()
|
| 30 |
+
image = (image) * 255 # Assuming output in [-1, 1], rescale to [0, 255]
|
| 31 |
+
image = np.clip(image, 0, 255).astype("uint8") # Clip values to [0, 255]
|
| 32 |
+
return Image.fromarray(image.transpose(1, 2, 0)) # Reorder to (H, W, C)
|
| 33 |
+
|
| 34 |
+
# Define the enhancement function
|
| 35 |
+
def enhance_image(image, degradation_type=None):
|
| 36 |
+
# Preprocess the image
|
| 37 |
+
input_tensor = torch.Tensor((np.array(image)/255).transpose(2, 0, 1)).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 38 |
+
lq_em = transform_resize(image).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 39 |
+
lq_em = transform_resize(image).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 40 |
+
|
| 41 |
+
# Generate embedding
|
| 42 |
+
if degradation_type == "auto" or degradation_type is None:
|
| 43 |
+
text_embedding, _, [text] = embedder(lq_em, 'image_encoder')
|
| 44 |
+
else:
|
| 45 |
+
text_embedding, _, [text] = embedder([degradation_type], 'text_encoder')
|
| 46 |
+
|
| 47 |
+
# Model inference
|
| 48 |
+
with torch.no_grad():
|
| 49 |
+
enhanced_tensor = restorer(input_tensor, text_embedding)
|
| 50 |
+
|
| 51 |
+
# Postprocess the output
|
| 52 |
+
return (image, postprocess_image(enhanced_tensor)), text
|
| 53 |
+
|
| 54 |
+
# Define the Gradio interface
|
| 55 |
+
def inference(image, degradation_type=None):
|
| 56 |
+
return enhance_image(image, degradation_type)
|
| 57 |
+
|
| 58 |
+
#### Image,Prompts examples
|
| 59 |
+
examples = [
|
| 60 |
+
['image/low_haze_rain_00469_01_lq.png'],
|
| 61 |
+
['image/low_haze_snow_00337_01_lq.png'],
|
| 62 |
+
]
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
# Create the Gradio app interface using updated API
|
| 67 |
+
interface = gr.Interface(
|
| 68 |
+
fn=inference,
|
| 69 |
+
inputs=[
|
| 70 |
+
gr.Image(type="pil", value="image/low_haze_rain_00469_01_lq.png"), # Image input
|
| 71 |
+
gr.Dropdown(['auto', 'low', 'haze', 'rain', 'snow',\
|
| 72 |
+
'low_haze', 'low_rain', 'low_snow', 'haze_rain',\
|
| 73 |
+
'haze_snow', 'low_haze_rain', 'low_haze_snow'], label="Degradation Type", value="auto") # Manual or auto degradation
|
| 74 |
+
],
|
| 75 |
+
outputs=[
|
| 76 |
+
ImageSlider(label="Restored Image",
|
| 77 |
+
type="pil",
|
| 78 |
+
show_download_button=True,
|
| 79 |
+
), # Enhanced image outputImageSlider(type="pil", show_download_button=True, ),
|
| 80 |
+
gr.Textbox(label="Degradation Type") # Display the estimated degradation type
|
| 81 |
+
],
|
| 82 |
+
title="Image Restoration with OneRestore",
|
| 83 |
+
description="Upload an image and enhance it using OneRestore model. You can choose to let the model automatically estimate the degradation type or set it manually.",
|
| 84 |
+
examples=examples,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
# Launch the app
|
| 88 |
+
if __name__ == "__main__":
|
| 89 |
+
interface.launch()
|
ckpts/ckpts_file.txt
ADDED
|
File without changes
|
data/data_file.txt
ADDED
|
File without changes
|
image/low_haze_rain_00469_01_lq.png
ADDED

|
Git LFS Details
|
image/low_haze_snow_00337_01_lq.png
ADDED

|
Git LFS Details
|
img_file/OneRestore_poster.png
ADDED

|
Git LFS Details
|
img_file/abstract.jpg
ADDED

|
Git LFS Details
|
img_file/cal_psnr_ssim.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
import random
|
| 5 |
+
from skimage.metrics import peak_signal_noise_ratio as compare_psnr
|
| 6 |
+
from skimage.metrics import mean_squared_error as compare_mse
|
| 7 |
+
from skimage.metrics import structural_similarity as compare_ssim
|
| 8 |
+
# Modified function to add progress display using tqdm for better progress tracking
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
import pandas as pd
|
| 11 |
+
# Updated function with progress display for PSNR and SSIM calculation
|
| 12 |
+
def calculate_psnr_ssim_with_progress(clear_folder, methods, degradation_types, win_size=7):
|
| 13 |
+
# Get list of all clear images
|
| 14 |
+
img_list = [img for img in os.listdir(clear_folder) if img.endswith('.png')]
|
| 15 |
+
|
| 16 |
+
# Initialize matrices to store mean PSNR and SSIM values
|
| 17 |
+
psnr_matrix = np.zeros((len(methods), len(degradation_types)))
|
| 18 |
+
ssim_matrix = np.zeros((len(methods), len(degradation_types)))
|
| 19 |
+
|
| 20 |
+
# Total number of tasks for progress tracking
|
| 21 |
+
total_tasks = len(methods) * len(degradation_types) * len(img_list)
|
| 22 |
+
print(len(methods), len(degradation_types), len(img_list))
|
| 23 |
+
|
| 24 |
+
# Create a progress bar
|
| 25 |
+
with tqdm(total=total_tasks, desc="Processing Images", unit="task") as pbar:
|
| 26 |
+
# Loop over methods
|
| 27 |
+
for k, method in enumerate(methods):
|
| 28 |
+
print(f"Processing method: {method}")
|
| 29 |
+
|
| 30 |
+
# Loop over degradation types
|
| 31 |
+
for j, degradation_type in enumerate(degradation_types):
|
| 32 |
+
psnr_values = []
|
| 33 |
+
ssim_values = []
|
| 34 |
+
|
| 35 |
+
# Loop over each image in the clear folder
|
| 36 |
+
for img_name in img_list:
|
| 37 |
+
clear_img_path = os.path.join(clear_folder, img_name)
|
| 38 |
+
degraded_img_path = f'./{method}/{degradation_type}/{img_name}'
|
| 39 |
+
|
| 40 |
+
# Read the clear and degraded images
|
| 41 |
+
clear_img = cv2.imread(clear_img_path) / 255.0
|
| 42 |
+
degraded_img = cv2.imread(degraded_img_path) / 255.0
|
| 43 |
+
|
| 44 |
+
# Ensure the images are read correctly
|
| 45 |
+
if clear_img is not None and degraded_img is not None:
|
| 46 |
+
# Compute PSNR and SSIM between clear and degraded image
|
| 47 |
+
psnr_value = compare_psnr(clear_img, degraded_img, data_range=1.0)
|
| 48 |
+
|
| 49 |
+
# Compute SSIM with specified window size and for multichannel images
|
| 50 |
+
ssim_value = compare_ssim(clear_img, degraded_img, multichannel=True,
|
| 51 |
+
win_size=min(win_size, clear_img.shape[0], clear_img.shape[1]),
|
| 52 |
+
channel_axis=-1, data_range=1.0)
|
| 53 |
+
|
| 54 |
+
# Store values
|
| 55 |
+
psnr_values.append(psnr_value)
|
| 56 |
+
ssim_values.append(ssim_value)
|
| 57 |
+
|
| 58 |
+
# Update progress bar after processing each image
|
| 59 |
+
pbar.update(1)
|
| 60 |
+
|
| 61 |
+
# Calculate mean PSNR and SSIM for the current method and degradation type
|
| 62 |
+
if psnr_values:
|
| 63 |
+
psnr_matrix[k, j] = np.mean(psnr_values)
|
| 64 |
+
if ssim_values:
|
| 65 |
+
ssim_matrix[k, j] = np.mean(ssim_values)
|
| 66 |
+
|
| 67 |
+
return psnr_matrix, ssim_matrix
|
| 68 |
+
|
| 69 |
+
def save_matrices_to_excel(psnr_matrix, ssim_matrix, methods, degradation_types, output_file='metrics.xlsx'):
|
| 70 |
+
# Create DataFrames for PSNR and SSIM matrices
|
| 71 |
+
psnr_df = pd.DataFrame(psnr_matrix, index=methods, columns=degradation_types)
|
| 72 |
+
ssim_df = pd.DataFrame(ssim_matrix, index=methods, columns=degradation_types)
|
| 73 |
+
|
| 74 |
+
# Create a writer to write both DataFrames to the same Excel file
|
| 75 |
+
with pd.ExcelWriter(output_file) as writer:
|
| 76 |
+
psnr_df.to_excel(writer, sheet_name='PSNR')
|
| 77 |
+
ssim_df.to_excel(writer, sheet_name='SSIM')
|
| 78 |
+
|
| 79 |
+
print(f'Matrices saved to {output_file}')
|
| 80 |
+
|
| 81 |
+
# Define the parameters
|
| 82 |
+
clear_folder = './00_gt'
|
| 83 |
+
methods = ['01_input', '02_MIRNet', '03_MPRNet', '04_MIRNetv2', '05_Restormer',
|
| 84 |
+
'06_DGUNet', '07_NAFNet', '08_SRUDC', '09_Fourmer', '10_OKNet', '11_AirNet',
|
| 85 |
+
'12_TransWeather', '13_WeatherDiff', '14_PromptIR', '15_WGWSNet', '16_OneRestore_visual', '17_OneRestore']
|
| 86 |
+
degradation_types = ['low', 'haze', 'rain', 'snow', 'low_haze', 'low_rain', 'low_snow', 'haze_rain', 'haze_snow', 'low_haze_rain', 'low_haze_snow']
|
| 87 |
+
|
| 88 |
+
# This is the function that will be used to calculate the PSNR and SSIM values across methods and degradation types
|
| 89 |
+
# To use the function, uncomment the line below and ensure the file paths are set correctly in your environment
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
psnr_matrix, ssim_matrix = calculate_psnr_ssim_with_progress(clear_folder, methods, degradation_types)
|
| 93 |
+
save_matrices_to_excel(psnr_matrix, ssim_matrix, methods, degradation_types)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
img_file/clear_img.jpg
ADDED
|
|
img_file/control1.jpg
ADDED

|
img_file/control2.jpg
ADDED

|
img_file/depth_map.jpg
ADDED

|
img_file/l+h+r.jpg
ADDED

|
img_file/l+h+s.jpg
ADDED

|
img_file/light_map.jpg
ADDED

|
img_file/logo_onerestore.png
ADDED
|
|
img_file/metric.png
ADDED
|
img_file/metrics_CDD-11_psnr_ssim.xlsx
ADDED
|
Binary file (15.7 kB). View file
|
|
|
img_file/pipeline.jpg
ADDED

|
Git LFS Details
|
img_file/rain_mask.jpg
ADDED

|
img_file/real.jpg
ADDED

|
Git LFS Details
|
img_file/snow_mask.png
ADDED

|
img_file/syn.jpg
ADDED

|
makedataset.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
"""
|
| 3 |
+
Created on Wed Feb 12 20:00:46 2020
|
| 4 |
+
|
| 5 |
+
@author: Administrator
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import os.path
|
| 10 |
+
import random
|
| 11 |
+
import numpy as np
|
| 12 |
+
import cv2
|
| 13 |
+
import h5py
|
| 14 |
+
import torch
|
| 15 |
+
import torch.utils.data as udata
|
| 16 |
+
import argparse
|
| 17 |
+
from PIL import Image
|
| 18 |
+
class Dataset(udata.Dataset):
|
| 19 |
+
r"""Implements torch.utils.data.Dataset
|
| 20 |
+
"""
|
| 21 |
+
def __init__(self, file, trainrgb=True,trainsyn = True, shuffle=False):
|
| 22 |
+
super(Dataset, self).__init__()
|
| 23 |
+
self.trainrgb = trainrgb
|
| 24 |
+
self.trainsyn = trainsyn
|
| 25 |
+
self.train_haze = file
|
| 26 |
+
|
| 27 |
+
h5f = h5py.File(self.train_haze, 'r')
|
| 28 |
+
|
| 29 |
+
self.keys = list(h5f.keys())
|
| 30 |
+
if shuffle:
|
| 31 |
+
random.shuffle(self.keys)
|
| 32 |
+
h5f.close()
|
| 33 |
+
|
| 34 |
+
def __len__(self):
|
| 35 |
+
return len(self.keys)
|
| 36 |
+
|
| 37 |
+
def __getitem__(self, index):
|
| 38 |
+
|
| 39 |
+
h5f = h5py.File(self.train_haze, 'r')
|
| 40 |
+
|
| 41 |
+
key = self.keys[index]
|
| 42 |
+
data = np.array(h5f[key])
|
| 43 |
+
h5f.close()
|
| 44 |
+
return torch.Tensor(data)
|
| 45 |
+
|
| 46 |
+
def data_augmentation(clear, mode):
|
| 47 |
+
r"""Performs dat augmentation of the input image
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
image: a cv2 (OpenCV) image
|
| 51 |
+
mode: int. Choice of transformation to apply to the image
|
| 52 |
+
0 - no transformation
|
| 53 |
+
1 - flip up and down
|
| 54 |
+
2 - rotate counterwise 90 degree
|
| 55 |
+
3 - rotate 90 degree and flip up and down
|
| 56 |
+
4 - rotate 180 degree
|
| 57 |
+
5 - rotate 180 degree and flip
|
| 58 |
+
6 - rotate 270 degree
|
| 59 |
+
7 - rotate 270 degree and flip
|
| 60 |
+
"""
|
| 61 |
+
clear = np.transpose(clear, (2, 3, 0, 1))
|
| 62 |
+
if mode == 0:
|
| 63 |
+
# original
|
| 64 |
+
clear = clear
|
| 65 |
+
elif mode == 1:
|
| 66 |
+
# flip up and down
|
| 67 |
+
clear = np.flipud(clear)
|
| 68 |
+
elif mode == 2:
|
| 69 |
+
# rotate counterwise 90 degree
|
| 70 |
+
clear = np.rot90(clear)
|
| 71 |
+
elif mode == 3:
|
| 72 |
+
# rotate 90 degree and flip up and down
|
| 73 |
+
clear = np.rot90(clear)
|
| 74 |
+
clear = np.flipud(clear)
|
| 75 |
+
elif mode == 4:
|
| 76 |
+
# rotate 180 degree
|
| 77 |
+
clear = np.rot90(clear, k=2)
|
| 78 |
+
elif mode == 5:
|
| 79 |
+
# rotate 180 degree and flip
|
| 80 |
+
clear = np.rot90(clear, k=2)
|
| 81 |
+
clear = np.flipud(clear)
|
| 82 |
+
elif mode == 6:
|
| 83 |
+
# rotate 270 degree
|
| 84 |
+
clear = np.rot90(clear, k=3)
|
| 85 |
+
elif mode == 7:
|
| 86 |
+
# rotate 270 degree and flip
|
| 87 |
+
clear = np.rot90(clear, k=3)
|
| 88 |
+
clear = np.flipud(clear)
|
| 89 |
+
else:
|
| 90 |
+
raise Exception('Invalid choice of image transformation')
|
| 91 |
+
return np.transpose(clear, (2, 3, 0, 1))
|
| 92 |
+
|
| 93 |
+
def img_to_patches(img,win,stride,Syn=True):
|
| 94 |
+
typ, chl, raw, col = img.shape
|
| 95 |
+
chl = int(chl)
|
| 96 |
+
num_raw = np.ceil((raw-win)/stride+1).astype(np.uint8)
|
| 97 |
+
num_col = np.ceil((col-win)/stride+1).astype(np.uint8)
|
| 98 |
+
count = 0
|
| 99 |
+
total_process = int(num_col)*int(num_raw)
|
| 100 |
+
img_patches = np.zeros([typ, chl, win, win, total_process])
|
| 101 |
+
if Syn:
|
| 102 |
+
for i in range(num_raw):
|
| 103 |
+
for j in range(num_col):
|
| 104 |
+
if stride * i + win <= raw and stride * j + win <=col:
|
| 105 |
+
img_patches[:,:,:,:,count] = img[:, :, stride*i : stride*i + win, stride*j : stride*j + win]
|
| 106 |
+
elif stride * i + win > raw and stride * j + win<=col:
|
| 107 |
+
img_patches[:,:,:,:,count] = img[:, :,raw-win : raw,stride * j : stride * j + win]
|
| 108 |
+
elif stride * i + win <= raw and stride*j + win>col:
|
| 109 |
+
img_patches[:,:,:,:,count] = img[:, :,stride*i : stride*i + win, col-win : col]
|
| 110 |
+
else:
|
| 111 |
+
img_patches[:,:,:,:,count] = img[:, :,raw-win : raw,col-win : col]
|
| 112 |
+
img_patches[:,:,:,:,count] = data_augmentation(img_patches[:, :, :, :, count], np.random.randint(0, 7))
|
| 113 |
+
count +=1
|
| 114 |
+
return img_patches
|
| 115 |
+
|
| 116 |
+
def read_img(img):
|
| 117 |
+
return np.array(Image.open(img))/255.
|
| 118 |
+
|
| 119 |
+
def Train_data(args):
|
| 120 |
+
file_list = os.listdir(f'{args.train_path}/{args.gt_name}')
|
| 121 |
+
|
| 122 |
+
with h5py.File(args.data_name, 'w') as h5f:
|
| 123 |
+
count = 0
|
| 124 |
+
for i in range(len(file_list)):
|
| 125 |
+
print(file_list[i])
|
| 126 |
+
img_list = []
|
| 127 |
+
|
| 128 |
+
img_list.append(read_img(f'{args.train_path}/{args.gt_name}/{file_list[i]}'))
|
| 129 |
+
for j in args.degradation_name:
|
| 130 |
+
img_list.append(read_img(f'{args.train_path}/{j}/{file_list[i]}'))
|
| 131 |
+
|
| 132 |
+
img = np.stack(img_list,0)
|
| 133 |
+
img = img_to_patches(img.transpose(0, 3, 1, 2), args.patch_size, args.stride)
|
| 134 |
+
|
| 135 |
+
for nx in range(img.shape[4]):
|
| 136 |
+
data = img[:,:,:,:,nx]
|
| 137 |
+
print(count, data.shape)
|
| 138 |
+
h5f.create_dataset(str(count), data=data)
|
| 139 |
+
count += 1
|
| 140 |
+
h5f.close()
|
| 141 |
+
|
| 142 |
+
if __name__ == "__main__":
|
| 143 |
+
|
| 144 |
+
parser = argparse.ArgumentParser(description = "Building the training patch database")
|
| 145 |
+
parser.add_argument("--patch-size", type = int, default=256, help="Patch size")
|
| 146 |
+
parser.add_argument("--stride", type = int, default=200, help="Size of stride")
|
| 147 |
+
|
| 148 |
+
parser.add_argument("--train-path", type = str, default='./data/CDD-11_train', help="Train path")
|
| 149 |
+
parser.add_argument("--data-name", type = str, default='dataset.h5', help="Data name")
|
| 150 |
+
|
| 151 |
+
parser.add_argument("--gt-name", type = str, default='clear', help="HQ name")
|
| 152 |
+
parser.add_argument("--degradation-name", type = list, default=['low','haze','rain','snow',\
|
| 153 |
+
'low_haze','low_rain','low_snow','haze_rain','haze_snow','low_haze_rain','low_haze_snow'], help="LQ name")
|
| 154 |
+
|
| 155 |
+
args = parser.parse_args()
|
| 156 |
+
|
| 157 |
+
Train_data(args)
|
model/Embedder.py
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch, torchvision
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
import torchvision.transforms as transforms
|
| 6 |
+
from utils.utils_word_embedding import initialize_wordembedding_matrix
|
| 7 |
+
|
| 8 |
+
class Backbone(nn.Module):
|
| 9 |
+
def __init__(self, backbone='resnet18'):
|
| 10 |
+
super(Backbone, self).__init__()
|
| 11 |
+
|
| 12 |
+
if backbone == 'resnet18':
|
| 13 |
+
resnet = torchvision.models.resnet.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
|
| 14 |
+
elif backbone == 'resnet50':
|
| 15 |
+
resnet = torchvision.models.resnet.resnet50(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
|
| 16 |
+
elif backbone == 'resnet101':
|
| 17 |
+
resnet = torchvision.models.resnet.resnet101(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)
|
| 18 |
+
|
| 19 |
+
self.block0 = nn.Sequential(
|
| 20 |
+
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool,
|
| 21 |
+
)
|
| 22 |
+
self.block1 = resnet.layer1
|
| 23 |
+
self.block2 = resnet.layer2
|
| 24 |
+
self.block3 = resnet.layer3
|
| 25 |
+
self.block4 = resnet.layer4
|
| 26 |
+
|
| 27 |
+
def forward(self, x, returned=[4]):
|
| 28 |
+
blocks = [self.block0(x)]
|
| 29 |
+
|
| 30 |
+
blocks.append(self.block1(blocks[-1]))
|
| 31 |
+
blocks.append(self.block2(blocks[-1]))
|
| 32 |
+
blocks.append(self.block3(blocks[-1]))
|
| 33 |
+
blocks.append(self.block4(blocks[-1]))
|
| 34 |
+
|
| 35 |
+
out = [blocks[i] for i in returned]
|
| 36 |
+
return out
|
| 37 |
+
|
| 38 |
+
class CosineClassifier(nn.Module):
|
| 39 |
+
def __init__(self, temp=0.05):
|
| 40 |
+
super(CosineClassifier, self).__init__()
|
| 41 |
+
self.temp = temp
|
| 42 |
+
|
| 43 |
+
def forward(self, img, concept, scale=True):
|
| 44 |
+
"""
|
| 45 |
+
img: (bs, emb_dim)
|
| 46 |
+
concept: (n_class, emb_dim)
|
| 47 |
+
"""
|
| 48 |
+
img_norm = F.normalize(img, dim=-1)
|
| 49 |
+
concept_norm = F.normalize(concept, dim=-1)
|
| 50 |
+
pred = torch.matmul(img_norm, concept_norm.transpose(0, 1))
|
| 51 |
+
if scale:
|
| 52 |
+
pred = pred / self.temp
|
| 53 |
+
return pred
|
| 54 |
+
|
| 55 |
+
class Embedder(nn.Module):
|
| 56 |
+
"""
|
| 57 |
+
Text and Visual Embedding Model.
|
| 58 |
+
"""
|
| 59 |
+
def __init__(self,
|
| 60 |
+
type_name,
|
| 61 |
+
feat_dim = 512,
|
| 62 |
+
mid_dim = 1024,
|
| 63 |
+
out_dim = 324,
|
| 64 |
+
drop_rate = 0.35,
|
| 65 |
+
cosine_cls_temp = 0.05,
|
| 66 |
+
wordembs = 'glove',
|
| 67 |
+
extractor_name = 'resnet18'):
|
| 68 |
+
super(Embedder, self).__init__()
|
| 69 |
+
|
| 70 |
+
mean, std = [0.485, 0.456, 0.406], [0.229, 0.224, 0.225]
|
| 71 |
+
self.type_name = type_name
|
| 72 |
+
self.feat_dim = feat_dim
|
| 73 |
+
self.mid_dim = mid_dim
|
| 74 |
+
self.out_dim = out_dim
|
| 75 |
+
self.drop_rate = drop_rate
|
| 76 |
+
self.cosine_cls_temp = cosine_cls_temp
|
| 77 |
+
self.wordembs = wordembs
|
| 78 |
+
self.extractor_name = extractor_name
|
| 79 |
+
self.transform = transforms.Normalize(mean, std)
|
| 80 |
+
|
| 81 |
+
self._setup_word_embedding()
|
| 82 |
+
self._setup_image_embedding()
|
| 83 |
+
|
| 84 |
+
def _setup_image_embedding(self):
|
| 85 |
+
# image embedding
|
| 86 |
+
self.feat_extractor = Backbone(self.extractor_name)
|
| 87 |
+
|
| 88 |
+
img_emb_modules = [
|
| 89 |
+
nn.Conv2d(self.feat_dim, self.mid_dim, kernel_size=1, bias=False),
|
| 90 |
+
nn.BatchNorm2d(self.mid_dim),
|
| 91 |
+
nn.ReLU()
|
| 92 |
+
]
|
| 93 |
+
if self.drop_rate > 0:
|
| 94 |
+
img_emb_modules += [nn.Dropout2d(self.drop_rate)]
|
| 95 |
+
self.img_embedder = nn.Sequential(*img_emb_modules)
|
| 96 |
+
|
| 97 |
+
self.img_avg_pool = nn.AdaptiveAvgPool2d((1, 1))
|
| 98 |
+
self.img_final = nn.Linear(self.mid_dim, self.out_dim)
|
| 99 |
+
|
| 100 |
+
self.classifier = CosineClassifier(temp=self.cosine_cls_temp)
|
| 101 |
+
|
| 102 |
+
def _setup_word_embedding(self):
|
| 103 |
+
|
| 104 |
+
self.type2idx = {self.type_name[i]: i for i in range(len(self.type_name))}
|
| 105 |
+
self.num_type = len(self.type_name)
|
| 106 |
+
train_type = [self.type2idx[type_i] for type_i in self.type_name]
|
| 107 |
+
self.train_type = torch.LongTensor(train_type).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 108 |
+
|
| 109 |
+
wordemb, self.word_dim = \
|
| 110 |
+
initialize_wordembedding_matrix(self.wordembs, self.type_name)
|
| 111 |
+
|
| 112 |
+
self.embedder = nn.Embedding(self.num_type, self.word_dim)
|
| 113 |
+
self.embedder.weight.data.copy_(wordemb)
|
| 114 |
+
|
| 115 |
+
self.mlp = nn.Sequential(
|
| 116 |
+
nn.Linear(self.word_dim, self.out_dim),
|
| 117 |
+
nn.ReLU(True)
|
| 118 |
+
)
|
| 119 |
+
|
| 120 |
+
def train_forward(self, batch):
|
| 121 |
+
|
| 122 |
+
scene, img = batch[0], self.transform(batch[1])
|
| 123 |
+
bs = img.shape[0]
|
| 124 |
+
|
| 125 |
+
# word embedding
|
| 126 |
+
scene_emb = self.embedder(self.train_type)
|
| 127 |
+
scene_weight = self.mlp(scene_emb)
|
| 128 |
+
|
| 129 |
+
#image embedding
|
| 130 |
+
img = self.feat_extractor(img)[0]
|
| 131 |
+
img = self.img_embedder(img)
|
| 132 |
+
img = self.img_avg_pool(img).squeeze(3).squeeze(2)
|
| 133 |
+
img = self.img_final(img)
|
| 134 |
+
|
| 135 |
+
pred = self.classifier(img, scene_weight)
|
| 136 |
+
label_loss = F.cross_entropy(pred, scene)
|
| 137 |
+
pred = torch.max(pred, dim=1)[1]
|
| 138 |
+
type_pred = self.train_type[pred]
|
| 139 |
+
correct_type = (type_pred == scene)
|
| 140 |
+
out = {
|
| 141 |
+
'loss_total': label_loss,
|
| 142 |
+
'acc_type': torch.div(correct_type.sum(),float(bs)),
|
| 143 |
+
}
|
| 144 |
+
|
| 145 |
+
return out
|
| 146 |
+
|
| 147 |
+
def image_encoder_forward(self, batch):
|
| 148 |
+
img = self.transform(batch)
|
| 149 |
+
|
| 150 |
+
# word embedding
|
| 151 |
+
scene_emb = self.embedder(self.train_type)
|
| 152 |
+
scene_weight = self.mlp(scene_emb)
|
| 153 |
+
|
| 154 |
+
#image embedding
|
| 155 |
+
img = self.feat_extractor(img)[0]
|
| 156 |
+
bs, _, h, w = img.shape
|
| 157 |
+
img = self.img_embedder(img)
|
| 158 |
+
img = self.img_avg_pool(img).squeeze(3).squeeze(2)
|
| 159 |
+
img = self.img_final(img)
|
| 160 |
+
|
| 161 |
+
pred = self.classifier(img, scene_weight)
|
| 162 |
+
pred = torch.max(pred, dim=1)[1]
|
| 163 |
+
|
| 164 |
+
out_embedding = torch.zeros((bs,self.out_dim)).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 165 |
+
for i in range(bs):
|
| 166 |
+
out_embedding[i,:] = scene_weight[pred[i],:]
|
| 167 |
+
num_type = self.train_type[pred]
|
| 168 |
+
text_type = [self.type_name[num_type[i]] for i in range(bs)]
|
| 169 |
+
|
| 170 |
+
return out_embedding, num_type, text_type
|
| 171 |
+
|
| 172 |
+
def text_encoder_forward(self, text):
|
| 173 |
+
|
| 174 |
+
bs = len(text)
|
| 175 |
+
|
| 176 |
+
# word embedding
|
| 177 |
+
scene_emb = self.embedder(self.train_type)
|
| 178 |
+
scene_weight = self.mlp(scene_emb)
|
| 179 |
+
|
| 180 |
+
num_type = torch.zeros((bs)).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 181 |
+
for i in range(bs):
|
| 182 |
+
num_type[i] = self.type2idx[text[i]]
|
| 183 |
+
|
| 184 |
+
out_embedding = torch.zeros((bs,self.out_dim)).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 185 |
+
for i in range(bs):
|
| 186 |
+
out_embedding[i,:] = scene_weight[int(num_type[i]),:]
|
| 187 |
+
text_type = text
|
| 188 |
+
|
| 189 |
+
return out_embedding, num_type, text_type
|
| 190 |
+
|
| 191 |
+
def text_idx_encoder_forward(self, idx):
|
| 192 |
+
|
| 193 |
+
bs = idx.shape[0]
|
| 194 |
+
|
| 195 |
+
# word embedding
|
| 196 |
+
scene_emb = self.embedder(self.train_type)
|
| 197 |
+
scene_weight = self.mlp(scene_emb)
|
| 198 |
+
|
| 199 |
+
num_type = idx
|
| 200 |
+
|
| 201 |
+
out_embedding = torch.zeros((bs,self.out_dim)).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 202 |
+
for i in range(bs):
|
| 203 |
+
out_embedding[i,:] = scene_weight[int(num_type[i]),:]
|
| 204 |
+
|
| 205 |
+
return out_embedding
|
| 206 |
+
|
| 207 |
+
def contrast_loss_forward(self, batch):
|
| 208 |
+
|
| 209 |
+
img = self.transform(batch)
|
| 210 |
+
|
| 211 |
+
#image embedding
|
| 212 |
+
img = self.feat_extractor(img)[0]
|
| 213 |
+
img = self.img_embedder(img)
|
| 214 |
+
img = self.img_avg_pool(img).squeeze(3).squeeze(2)
|
| 215 |
+
img = self.img_final(img)
|
| 216 |
+
|
| 217 |
+
return img
|
| 218 |
+
|
| 219 |
+
def forward(self, x, type = 'image_encoder'):
|
| 220 |
+
|
| 221 |
+
if type == 'train':
|
| 222 |
+
out = self.train_forward(x)
|
| 223 |
+
|
| 224 |
+
elif type == 'image_encoder':
|
| 225 |
+
with torch.no_grad():
|
| 226 |
+
out = self.image_encoder_forward(x)
|
| 227 |
+
|
| 228 |
+
elif type == 'text_encoder':
|
| 229 |
+
out = self.text_encoder_forward(x)
|
| 230 |
+
|
| 231 |
+
elif type == 'text_idx_encoder':
|
| 232 |
+
out = self.text_idx_encoder_forward(x)
|
| 233 |
+
|
| 234 |
+
elif type == 'visual_embed':
|
| 235 |
+
x = F.interpolate(x,size=(224,224),mode='bilinear')
|
| 236 |
+
out = self.contrast_loss_forward(x)
|
| 237 |
+
|
| 238 |
+
return out
|
model/OneRestore.py
ADDED
|
@@ -0,0 +1,314 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
"""
|
| 3 |
+
Created on Sun Jun 20 16:14:37 2021
|
| 4 |
+
|
| 5 |
+
@author: Administrator
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
from __future__ import absolute_import
|
| 10 |
+
from __future__ import division
|
| 11 |
+
from __future__ import print_function
|
| 12 |
+
from torchvision import transforms
|
| 13 |
+
import torch, math
|
| 14 |
+
import torch.nn as nn
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from einops import rearrange, repeat
|
| 17 |
+
import numbers
|
| 18 |
+
|
| 19 |
+
from thop import profile
|
| 20 |
+
import numpy as np
|
| 21 |
+
import time
|
| 22 |
+
from torchvision import transforms
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class OneRestore(nn.Module):
|
| 26 |
+
def __init__(self, channel = 32):
|
| 27 |
+
super(OneRestore,self).__init__()
|
| 28 |
+
self.norm = lambda x: (x-0.5)/0.5
|
| 29 |
+
self.denorm = lambda x: (x+1)/2
|
| 30 |
+
self.in_conv = nn.Conv2d(3,channel,kernel_size=1,stride=1,padding=0,bias=False)
|
| 31 |
+
self.encoder = encoder(channel)
|
| 32 |
+
self.middle = backbone(channel)
|
| 33 |
+
self.decoder = decoder(channel)
|
| 34 |
+
self.out_conv = nn.Conv2d(channel,3,kernel_size=1,stride=1,padding=0,bias=False)
|
| 35 |
+
|
| 36 |
+
def forward(self,x,embedding):
|
| 37 |
+
x_in = self.in_conv(self.norm(x))
|
| 38 |
+
x_l, x_m, x_s, x_ss = self.encoder(x_in, embedding)
|
| 39 |
+
x_mid = self.middle(x_ss, embedding)
|
| 40 |
+
x_out = self.decoder(x_mid, x_ss, x_s, x_m, x_l, embedding)
|
| 41 |
+
out = self.out_conv(x_out) + x
|
| 42 |
+
return self.denorm(out)
|
| 43 |
+
|
| 44 |
+
class encoder(nn.Module):
|
| 45 |
+
def __init__(self,channel):
|
| 46 |
+
super(encoder,self).__init__()
|
| 47 |
+
|
| 48 |
+
self.el = ResidualBlock(channel)#16
|
| 49 |
+
self.em = ResidualBlock(channel*2)#32
|
| 50 |
+
self.es = ResidualBlock(channel*4)#64
|
| 51 |
+
self.ess = ResidualBlock(channel*8)#128
|
| 52 |
+
|
| 53 |
+
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
|
| 54 |
+
self.conv_eltem = nn.Conv2d(channel,2*channel,kernel_size=1,stride=1,padding=0,bias=False)#16 32
|
| 55 |
+
self.conv_emtes = nn.Conv2d(2*channel,4*channel,kernel_size=1,stride=1,padding=0,bias=False)#32 64
|
| 56 |
+
self.conv_estess = nn.Conv2d(4*channel,8*channel,kernel_size=1,stride=1,padding=0,bias=False)#64 128
|
| 57 |
+
self.conv_esstesss = nn.Conv2d(8*channel,16*channel,kernel_size=1,stride=1,padding=0,bias=False)#128 256
|
| 58 |
+
|
| 59 |
+
def forward(self,x,embedding):
|
| 60 |
+
|
| 61 |
+
elout = self.el(x, embedding)#16
|
| 62 |
+
x_emin = self.conv_eltem(self.maxpool(elout))#32
|
| 63 |
+
emout = self.em(x_emin, embedding)
|
| 64 |
+
x_esin = self.conv_emtes(self.maxpool(emout))
|
| 65 |
+
esout = self.es(x_esin, embedding)
|
| 66 |
+
x_esin = self.conv_estess(self.maxpool(esout))
|
| 67 |
+
essout = self.ess(x_esin, embedding)#128
|
| 68 |
+
|
| 69 |
+
return elout, emout, esout, essout#,esssout
|
| 70 |
+
|
| 71 |
+
class backbone(nn.Module):
|
| 72 |
+
def __init__(self,channel):
|
| 73 |
+
super(backbone,self).__init__()
|
| 74 |
+
|
| 75 |
+
self.s1 = ResidualBlock(channel*8)#128
|
| 76 |
+
self.s2 = ResidualBlock(channel*8)#128
|
| 77 |
+
|
| 78 |
+
def forward(self,x,embedding):
|
| 79 |
+
|
| 80 |
+
share1 = self.s1(x, embedding)
|
| 81 |
+
share2 = self.s2(share1, embedding)
|
| 82 |
+
|
| 83 |
+
return share2
|
| 84 |
+
|
| 85 |
+
class decoder(nn.Module):
|
| 86 |
+
def __init__(self,channel):
|
| 87 |
+
super(decoder,self).__init__()
|
| 88 |
+
|
| 89 |
+
self.dss = ResidualBlock(channel*8)#128
|
| 90 |
+
self.ds = ResidualBlock(channel*4)#64
|
| 91 |
+
self.dm = ResidualBlock(channel*2)#32
|
| 92 |
+
self.dl = ResidualBlock(channel)#16
|
| 93 |
+
|
| 94 |
+
#self.conv_dssstdss = nn.Conv2d(16*channel,8*channel,kernel_size=1,stride=1,padding=0,bias=False)#256 128
|
| 95 |
+
self.conv_dsstds = nn.Conv2d(8*channel,4*channel,kernel_size=1,stride=1,padding=0,bias=False)#128 64
|
| 96 |
+
self.conv_dstdm = nn.Conv2d(4*channel,2*channel,kernel_size=1,stride=1,padding=0,bias=False)#64 32
|
| 97 |
+
self.conv_dmtdl = nn.Conv2d(2*channel,channel,kernel_size=1,stride=1,padding=0,bias=False)#32 16
|
| 98 |
+
|
| 99 |
+
def _upsample(self,x,y):
|
| 100 |
+
_,_,H0,W0 = y.size()
|
| 101 |
+
return F.interpolate(x,size=(H0,W0),mode='bilinear')
|
| 102 |
+
|
| 103 |
+
def forward(self, x, x_ss, x_s, x_m, x_l, embedding):
|
| 104 |
+
|
| 105 |
+
dssout = self.dss(x + x_ss, embedding)
|
| 106 |
+
x_dsin = self.conv_dsstds(self._upsample(dssout, x_s))
|
| 107 |
+
dsout = self.ds(x_dsin + x_s, embedding)
|
| 108 |
+
x_dmin = self.conv_dstdm(self._upsample(dsout, x_m))
|
| 109 |
+
dmout = self.dm(x_dmin + x_m, embedding)
|
| 110 |
+
x_dlin = self.conv_dmtdl(self._upsample(dmout, x_l))
|
| 111 |
+
dlout = self.dl(x_dlin + x_l, embedding)
|
| 112 |
+
|
| 113 |
+
return dlout
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
class ResidualBlock(nn.Module): # Edge-oriented Residual Convolution Block 面向边缘的残差网络块 解决梯度消失的问题
|
| 117 |
+
def __init__(self, channel, norm=False):
|
| 118 |
+
super(ResidualBlock, self).__init__()
|
| 119 |
+
|
| 120 |
+
self.el = TransformerBlock(channel, num_heads=8, ffn_expansion_factor=2.66, bias=False, LayerNorm_type='WithBias')
|
| 121 |
+
|
| 122 |
+
def forward(self, x,embedding):
|
| 123 |
+
return self.el(x,embedding)
|
| 124 |
+
|
| 125 |
+
def to_3d(x):
|
| 126 |
+
return rearrange(x, 'b c h w -> b (h w) c')
|
| 127 |
+
|
| 128 |
+
def to_4d(x, h, w):
|
| 129 |
+
return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
class BiasFree_LayerNorm(nn.Module):
|
| 133 |
+
def __init__(self, normalized_shape):
|
| 134 |
+
super(BiasFree_LayerNorm, self).__init__()
|
| 135 |
+
if isinstance(normalized_shape, numbers.Integral):
|
| 136 |
+
normalized_shape = (normalized_shape,)
|
| 137 |
+
normalized_shape = torch.Size(normalized_shape)
|
| 138 |
+
assert len(normalized_shape) == 1
|
| 139 |
+
self.weight = nn.Parameter(torch.ones(normalized_shape))
|
| 140 |
+
self.normalized_shape = normalized_shape
|
| 141 |
+
|
| 142 |
+
def forward(self, x):
|
| 143 |
+
sigma = x.var(-1, keepdim=True, unbiased=False)
|
| 144 |
+
return x / torch.sqrt(sigma + 1e-5) * self.weight
|
| 145 |
+
|
| 146 |
+
class WithBias_LayerNorm(nn.Module):
|
| 147 |
+
def __init__(self, normalized_shape):
|
| 148 |
+
super(WithBias_LayerNorm, self).__init__()
|
| 149 |
+
if isinstance(normalized_shape, numbers.Integral):
|
| 150 |
+
normalized_shape = (normalized_shape,)
|
| 151 |
+
normalized_shape = torch.Size(normalized_shape)
|
| 152 |
+
assert len(normalized_shape) == 1
|
| 153 |
+
|
| 154 |
+
self.weight = nn.Parameter(torch.ones(normalized_shape))
|
| 155 |
+
self.bias = nn.Parameter(torch.zeros(normalized_shape))
|
| 156 |
+
self.normalized_shape = normalized_shape
|
| 157 |
+
|
| 158 |
+
def forward(self, x):
|
| 159 |
+
mu = x.mean(-1, keepdim=True)
|
| 160 |
+
sigma = x.var(-1, keepdim=True, unbiased=False)
|
| 161 |
+
return (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight + self.bias
|
| 162 |
+
|
| 163 |
+
class LayerNorm(nn.Module):
|
| 164 |
+
def __init__(self, dim, LayerNorm_type):
|
| 165 |
+
super(LayerNorm, self).__init__()
|
| 166 |
+
if LayerNorm_type == 'BiasFree':
|
| 167 |
+
self.body = BiasFree_LayerNorm(dim)
|
| 168 |
+
else:
|
| 169 |
+
self.body = WithBias_LayerNorm(dim)
|
| 170 |
+
|
| 171 |
+
def forward(self, x):
|
| 172 |
+
h, w = x.shape[-2:]
|
| 173 |
+
return to_4d(self.body(to_3d(x)), h, w)
|
| 174 |
+
|
| 175 |
+
class Cross_Attention(nn.Module):
|
| 176 |
+
def __init__(self,
|
| 177 |
+
dim,
|
| 178 |
+
num_heads,
|
| 179 |
+
bias,
|
| 180 |
+
q_dim = 324):
|
| 181 |
+
super(Cross_Attention, self).__init__()
|
| 182 |
+
self.dim = dim
|
| 183 |
+
self.num_heads = num_heads
|
| 184 |
+
sqrt_q_dim = int(math.sqrt(q_dim))
|
| 185 |
+
self.resize = transforms.Resize([sqrt_q_dim, sqrt_q_dim])
|
| 186 |
+
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
|
| 187 |
+
|
| 188 |
+
self.q = nn.Linear(q_dim, q_dim, bias=bias)
|
| 189 |
+
|
| 190 |
+
self.kv = nn.Conv2d(dim, dim*2, kernel_size=1, bias=bias)
|
| 191 |
+
self.kv_dwconv = nn.Conv2d(dim*2, dim*2, kernel_size=3, stride=1, padding=1, groups=dim*2, bias=bias)
|
| 192 |
+
|
| 193 |
+
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
|
| 194 |
+
def forward(self, x, query):
|
| 195 |
+
b,c,h,w = x.shape
|
| 196 |
+
|
| 197 |
+
q = self.q(query)
|
| 198 |
+
k, v = self.kv_dwconv(self.kv(x)).chunk(2, dim=1)
|
| 199 |
+
k = self.resize(k)
|
| 200 |
+
|
| 201 |
+
q = repeat(q, 'b l -> b head c l', head=self.num_heads, c=self.dim//self.num_heads)
|
| 202 |
+
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
|
| 203 |
+
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
|
| 204 |
+
|
| 205 |
+
q = torch.nn.functional.normalize(q, dim=-1)
|
| 206 |
+
k = torch.nn.functional.normalize(k, dim=-1)
|
| 207 |
+
|
| 208 |
+
attn = (q @ k.transpose(-2, -1)) * self.temperature
|
| 209 |
+
attn = attn.softmax(dim=-1)
|
| 210 |
+
|
| 211 |
+
out = (attn @ v)
|
| 212 |
+
|
| 213 |
+
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
|
| 214 |
+
|
| 215 |
+
out = self.project_out(out)
|
| 216 |
+
return out
|
| 217 |
+
|
| 218 |
+
class Self_Attention(nn.Module):
|
| 219 |
+
def __init__(self,
|
| 220 |
+
dim,
|
| 221 |
+
num_heads,
|
| 222 |
+
bias):
|
| 223 |
+
super(Self_Attention, self).__init__()
|
| 224 |
+
self.num_heads = num_heads
|
| 225 |
+
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
|
| 226 |
+
|
| 227 |
+
self.qkv = nn.Conv2d(dim, dim*3, kernel_size=1, bias=bias)
|
| 228 |
+
self.qkv_dwconv = nn.Conv2d(dim*3, dim*3, kernel_size=3, stride=1, padding=1, groups=dim*3, bias=bias)
|
| 229 |
+
self.project_out = nn.Conv2d(dim, dim, kernel_size=1, bias=bias)
|
| 230 |
+
def forward(self, x):
|
| 231 |
+
b,c,h,w = x.shape
|
| 232 |
+
|
| 233 |
+
qkv = self.qkv_dwconv(self.qkv(x))
|
| 234 |
+
q,k,v = qkv.chunk(3, dim=1)
|
| 235 |
+
|
| 236 |
+
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
|
| 237 |
+
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
|
| 238 |
+
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
|
| 239 |
+
|
| 240 |
+
q = torch.nn.functional.normalize(q, dim=-1)
|
| 241 |
+
k = torch.nn.functional.normalize(k, dim=-1)
|
| 242 |
+
|
| 243 |
+
attn = (q @ k.transpose(-2, -1)) * self.temperature
|
| 244 |
+
attn = attn.softmax(dim=-1)
|
| 245 |
+
|
| 246 |
+
out = (attn @ v)
|
| 247 |
+
|
| 248 |
+
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
|
| 249 |
+
|
| 250 |
+
out = self.project_out(out)
|
| 251 |
+
return out
|
| 252 |
+
|
| 253 |
+
class FeedForward(nn.Module):
|
| 254 |
+
def __init__(self,
|
| 255 |
+
dim,
|
| 256 |
+
ffn_expansion_factor,
|
| 257 |
+
bias):
|
| 258 |
+
super(FeedForward, self).__init__()
|
| 259 |
+
|
| 260 |
+
hidden_features = int(dim * ffn_expansion_factor)
|
| 261 |
+
|
| 262 |
+
self.project_in = nn.Conv2d(dim, hidden_features * 2, kernel_size=1, bias=bias)
|
| 263 |
+
|
| 264 |
+
self.dwconv = nn.Conv2d(hidden_features * 2, hidden_features * 2, kernel_size=3, stride=1, padding=1,
|
| 265 |
+
groups=hidden_features * 2, bias=bias)
|
| 266 |
+
|
| 267 |
+
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
|
| 268 |
+
|
| 269 |
+
def forward(self, x):
|
| 270 |
+
x = self.project_in(x)
|
| 271 |
+
x1, x2 = self.dwconv(x).chunk(2, dim=1)
|
| 272 |
+
x = F.gelu(x1) * x2
|
| 273 |
+
x = self.project_out(x)
|
| 274 |
+
return x
|
| 275 |
+
|
| 276 |
+
class TransformerBlock(nn.Module):
|
| 277 |
+
def __init__(self,
|
| 278 |
+
dim,
|
| 279 |
+
num_heads=8,
|
| 280 |
+
ffn_expansion_factor=2.66,
|
| 281 |
+
bias=False,
|
| 282 |
+
LayerNorm_type='WithBias'):
|
| 283 |
+
super(TransformerBlock, self).__init__()
|
| 284 |
+
self.norm1 = LayerNorm(dim, LayerNorm_type)
|
| 285 |
+
self.cross_attn = Cross_Attention(dim, num_heads, bias)
|
| 286 |
+
self.norm2 = LayerNorm(dim, LayerNorm_type)
|
| 287 |
+
self.self_attn = Self_Attention(dim, num_heads, bias)
|
| 288 |
+
self.norm3 = LayerNorm(dim, LayerNorm_type)
|
| 289 |
+
self.ffn = FeedForward(dim, ffn_expansion_factor, bias)
|
| 290 |
+
|
| 291 |
+
def forward(self, x, query):
|
| 292 |
+
x = x + self.cross_attn(self.norm1(x),query)
|
| 293 |
+
x = x + self.self_attn(self.norm2(x))
|
| 294 |
+
x = x + self.ffn(self.norm3(x))
|
| 295 |
+
return x
|
| 296 |
+
|
| 297 |
+
if __name__ == '__main__':
|
| 298 |
+
net = OneRestore().to("cuda" if torch.cuda.is_available() else "cpu")
|
| 299 |
+
# x = torch.Tensor(np.random.random((2,3,256,256))).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 300 |
+
# query = torch.Tensor(np.random.random((2, 324))).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 301 |
+
# out = net(x, query)
|
| 302 |
+
# print(out.shape)
|
| 303 |
+
input = torch.randn(1, 3, 512, 512).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 304 |
+
query = torch.Tensor(np.random.random((1, 324))).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 305 |
+
macs, _ = profile(net, inputs=(input, query))
|
| 306 |
+
total = sum([param.nelement() for param in net.parameters()])
|
| 307 |
+
print('Macs = ' + str(macs/1000**3) + 'G')
|
| 308 |
+
print('Params = ' + str(total/1e6) + 'M')
|
| 309 |
+
|
| 310 |
+
from fvcore.nn import FlopCountAnalysis, parameter_count_table
|
| 311 |
+
flops = FlopCountAnalysis(net, (input, query))
|
| 312 |
+
print("FLOPs", flops.total()/1000**3)
|
| 313 |
+
|
| 314 |
+
|
model/loss.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.autograd import Variable
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
import cv2 as cv
|
| 6 |
+
import numpy as np
|
| 7 |
+
from matplotlib import pyplot as plt
|
| 8 |
+
from math import exp
|
| 9 |
+
from torchvision import transforms
|
| 10 |
+
from torchvision.models import vgg16
|
| 11 |
+
import torchvision
|
| 12 |
+
'''
|
| 13 |
+
MS-SSIM Loss
|
| 14 |
+
'''
|
| 15 |
+
|
| 16 |
+
def gaussian(window_size, sigma):
|
| 17 |
+
gauss = torch.Tensor([exp(-(x - window_size//2)**2/float(2*sigma**2)) for x in range(window_size)])
|
| 18 |
+
return gauss/gauss.sum()
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def create_window(window_size, channel=1):
|
| 22 |
+
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
|
| 23 |
+
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
|
| 24 |
+
window = _2D_window.expand(channel, 1, window_size, window_size).contiguous()
|
| 25 |
+
return window
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def ssim(img1, img2, window_size=11, window=None, size_average=True, full=False, val_range=None):
|
| 29 |
+
# Value range can be different from 255. Other common ranges are 1 (sigmoid) and 2 (tanh).
|
| 30 |
+
if val_range is None:
|
| 31 |
+
if torch.max(img1) > 128:
|
| 32 |
+
max_val = 255
|
| 33 |
+
else:
|
| 34 |
+
max_val = 1
|
| 35 |
+
|
| 36 |
+
if torch.min(img1) < -0.5:
|
| 37 |
+
min_val = -1
|
| 38 |
+
else:
|
| 39 |
+
min_val = 0
|
| 40 |
+
L = max_val - min_val
|
| 41 |
+
else:
|
| 42 |
+
L = val_range
|
| 43 |
+
|
| 44 |
+
padd = 0
|
| 45 |
+
(_, channel, height, width) = img1.size()
|
| 46 |
+
if window is None:
|
| 47 |
+
real_size = min(window_size, height, width)
|
| 48 |
+
window = create_window(real_size, channel=channel).to(img1.device)
|
| 49 |
+
|
| 50 |
+
mu1 = F.conv2d(img1, window, padding=padd, groups=channel)
|
| 51 |
+
mu2 = F.conv2d(img2, window, padding=padd, groups=channel)
|
| 52 |
+
|
| 53 |
+
mu1_sq = mu1.pow(2)
|
| 54 |
+
mu2_sq = mu2.pow(2)
|
| 55 |
+
mu1_mu2 = mu1 * mu2
|
| 56 |
+
|
| 57 |
+
sigma1_sq = F.conv2d(img1 * img1, window, padding=padd, groups=channel) - mu1_sq
|
| 58 |
+
sigma2_sq = F.conv2d(img2 * img2, window, padding=padd, groups=channel) - mu2_sq
|
| 59 |
+
sigma12 = F.conv2d(img1 * img2, window, padding=padd, groups=channel) - mu1_mu2
|
| 60 |
+
|
| 61 |
+
C1 = (0.01 * L) ** 2
|
| 62 |
+
C2 = (0.03 * L) ** 2
|
| 63 |
+
|
| 64 |
+
v1 = 2.0 * sigma12 + C2
|
| 65 |
+
v2 = sigma1_sq + sigma2_sq + C2
|
| 66 |
+
cs = torch.mean(v1 / v2) # contrast sensitivity
|
| 67 |
+
|
| 68 |
+
ssim_map = ((2 * mu1_mu2 + C1) * v1) / ((mu1_sq + mu2_sq + C1) * v2)
|
| 69 |
+
|
| 70 |
+
if size_average:
|
| 71 |
+
ret = ssim_map.mean()
|
| 72 |
+
else:
|
| 73 |
+
ret = ssim_map.mean(1).mean(1).mean(1)
|
| 74 |
+
|
| 75 |
+
if full:
|
| 76 |
+
return ret, cs
|
| 77 |
+
return ret
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def msssim(img1, img2, window_size=11, size_average=True, val_range=None, normalize=False):
|
| 81 |
+
weights = torch.FloatTensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333]).to(img1.device)
|
| 82 |
+
levels = weights.size()[0]
|
| 83 |
+
mssim = []
|
| 84 |
+
mcs = []
|
| 85 |
+
for _ in range(levels):
|
| 86 |
+
sim, cs = ssim(img1, img2, window_size=window_size, size_average=size_average, full=True, val_range=val_range)
|
| 87 |
+
mssim.append(sim)
|
| 88 |
+
mcs.append(cs)
|
| 89 |
+
|
| 90 |
+
img1 = F.avg_pool2d(img1, (2, 2))
|
| 91 |
+
img2 = F.avg_pool2d(img2, (2, 2))
|
| 92 |
+
|
| 93 |
+
mssim = torch.stack(mssim)
|
| 94 |
+
mcs = torch.stack(mcs)
|
| 95 |
+
|
| 96 |
+
# Normalize (to avoid NaNs during training unstable models, not compliant with original definition)
|
| 97 |
+
if normalize:
|
| 98 |
+
mssim = (mssim + 1) / 2
|
| 99 |
+
mcs = (mcs + 1) / 2
|
| 100 |
+
|
| 101 |
+
pow1 = mcs ** weights
|
| 102 |
+
pow2 = mssim ** weights
|
| 103 |
+
# From Matlab implementation https://ece.uwaterloo.ca/~z70wang/research/iwssim/
|
| 104 |
+
output = torch.prod(pow1[:-1] * pow2[-1])
|
| 105 |
+
return output
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
# Classes to re-use window
|
| 109 |
+
class SSIM(torch.nn.Module):
|
| 110 |
+
def __init__(self, window_size=11, size_average=True, val_range=None):
|
| 111 |
+
super(SSIM, self).__init__()
|
| 112 |
+
self.window_size = window_size
|
| 113 |
+
self.size_average = size_average
|
| 114 |
+
self.val_range = val_range
|
| 115 |
+
|
| 116 |
+
# Assume 1 channel for SSIM
|
| 117 |
+
self.channel = 1
|
| 118 |
+
self.window = create_window(window_size)
|
| 119 |
+
|
| 120 |
+
def forward(self, img1, img2):
|
| 121 |
+
(_, channel, _, _) = img1.size()
|
| 122 |
+
|
| 123 |
+
if channel == self.channel and self.window.dtype == img1.dtype:
|
| 124 |
+
window = self.window
|
| 125 |
+
else:
|
| 126 |
+
window = create_window(self.window_size, channel).to(img1.device).type(img1.dtype)
|
| 127 |
+
self.window = window
|
| 128 |
+
self.channel = channel
|
| 129 |
+
|
| 130 |
+
return ssim(img1, img2, window=window, window_size=self.window_size, size_average=self.size_average)
|
| 131 |
+
|
| 132 |
+
class MSSSIM(torch.nn.Module):
|
| 133 |
+
def __init__(self, window_size=11, size_average=True, channel=3):
|
| 134 |
+
super(MSSSIM, self).__init__()
|
| 135 |
+
self.window_size = window_size
|
| 136 |
+
self.size_average = size_average
|
| 137 |
+
self.channel = channel
|
| 138 |
+
|
| 139 |
+
def forward(self, img1, img2):
|
| 140 |
+
# TODO: store window between calls if possible
|
| 141 |
+
return msssim(img1, img2, window_size=self.window_size, size_average=self.size_average)
|
| 142 |
+
|
| 143 |
+
class TVLoss(nn.Module):
|
| 144 |
+
def __init__(self,TVLoss_weight=1):
|
| 145 |
+
super(TVLoss,self).__init__()
|
| 146 |
+
self.TVLoss_weight = TVLoss_weight
|
| 147 |
+
|
| 148 |
+
def forward(self,x):
|
| 149 |
+
batch_size = x.size()[0]
|
| 150 |
+
h_x = x.size()[2]
|
| 151 |
+
w_x = x.size()[3]
|
| 152 |
+
count_h = self._tensor_size(x[:,:,1:,:]) #算出总共求了多少次差
|
| 153 |
+
count_w = self._tensor_size(x[:,:,:,1:])
|
| 154 |
+
h_tv = torch.pow((x[:,:,1:,:]-x[:,:,:h_x-1,:]),2).sum()
|
| 155 |
+
# x[:,:,1:,:]-x[:,:,:h_x-1,:]就是对原图进行错位,分成两张像素位置差1的图片,第一张图片
|
| 156 |
+
# 从像素点1开始(原图从0开始),到最后一个像素点,第二张图片从像素点0开始,到倒数第二个
|
| 157 |
+
# 像素点,这样就实现了对原图进行错位,分成两张图的操作,做差之后就是原图中每个像素点与相
|
| 158 |
+
# 邻的下一个像素点的差。
|
| 159 |
+
w_tv = torch.pow((x[:,:,:,1:]-x[:,:,:,:w_x-1]),2).sum()
|
| 160 |
+
return self.TVLoss_weight*2*(h_tv/count_h+w_tv/count_w)/batch_size
|
| 161 |
+
|
| 162 |
+
def _tensor_size(self,t):
|
| 163 |
+
return t.size()[1]*t.size()[2]*t.size()[3]
|
| 164 |
+
|
| 165 |
+
def _tensor_size(self,t):
|
| 166 |
+
return t.size()[1]*t.size()[2]*t.size()[3]
|
| 167 |
+
|
| 168 |
+
class ContrastLoss(nn.Module):
|
| 169 |
+
def __init__(self):
|
| 170 |
+
super(ContrastLoss, self).__init__()
|
| 171 |
+
self.l1 = nn.L1Loss()
|
| 172 |
+
self.model = vgg16(weights = torchvision.models.VGG16_Weights.DEFAULT)
|
| 173 |
+
self.model = self.model.features[:16].to("cuda" if torch.cuda.is_available() else "cpu")
|
| 174 |
+
for param in self.model.parameters():
|
| 175 |
+
param.requires_grad = False
|
| 176 |
+
self.layer_name_mapping = {
|
| 177 |
+
'3': "relu1_2",
|
| 178 |
+
'8': "relu2_2",
|
| 179 |
+
'15': "relu3_3"
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
def gen_features(self, x):
|
| 183 |
+
output = []
|
| 184 |
+
for name, module in self.model._modules.items():
|
| 185 |
+
x = module(x)
|
| 186 |
+
if name in self.layer_name_mapping:
|
| 187 |
+
output.append(x)
|
| 188 |
+
return output
|
| 189 |
+
def forward(self, inp, pos, neg, out):
|
| 190 |
+
inp_t = inp
|
| 191 |
+
inp_x0 = self.gen_features(inp_t)
|
| 192 |
+
pos_t = pos
|
| 193 |
+
pos_x0 = self.gen_features(pos_t)
|
| 194 |
+
out_t = out
|
| 195 |
+
out_x0 = self.gen_features(out_t)
|
| 196 |
+
neg_t, neg_x0 = [],[]
|
| 197 |
+
for i in range(neg.shape[1]):
|
| 198 |
+
neg_i = neg[:,i,:,:]
|
| 199 |
+
neg_t.append(neg_i)
|
| 200 |
+
neg_x0_i = self.gen_features(neg_i)
|
| 201 |
+
neg_x0.append(neg_x0_i)
|
| 202 |
+
loss = 0
|
| 203 |
+
for i in range(len(pos_x0)):
|
| 204 |
+
pos_term = self.l1(out_x0[i], pos_x0[i].detach())
|
| 205 |
+
inp_term = self.l1(out_x0[i], inp_x0[i].detach())/(len(neg_x0)+1)
|
| 206 |
+
neg_term = sum(self.l1(out_x0[i], neg_x0[j][i].detach()) for j in range(len(neg_x0)))/(len(neg_x0)+1)
|
| 207 |
+
loss = loss + pos_term / (inp_term+neg_term+1e-7)
|
| 208 |
+
return loss / len(pos_x0)
|
| 209 |
+
|
| 210 |
+
class Total_loss(nn.Module):
|
| 211 |
+
def __init__(self, args):
|
| 212 |
+
super(Total_loss, self).__init__()
|
| 213 |
+
self.con_loss = ContrastLoss()
|
| 214 |
+
self.weight_sl1, self.weight_msssim, self.weight_drl = args.loss_weight
|
| 215 |
+
|
| 216 |
+
def forward(self, inp, pos, neg, out):
|
| 217 |
+
smooth_loss_l1 = F.smooth_l1_loss(out, pos)
|
| 218 |
+
msssim_loss = 1-msssim(out, pos, normalize=True)
|
| 219 |
+
c_loss = self.con_loss(inp[0], pos, neg, out)
|
| 220 |
+
|
| 221 |
+
total_loss = self.weight_sl1 * smooth_loss_l1 + self.weight_msssim * msssim_loss + self.weight_drl * c_loss
|
| 222 |
+
return total_loss
|
output/low_haze_rain_00469_01_lq.png
ADDED

|
Git LFS Details
|
output/low_haze_snow_00337_01_lq.png
ADDED

|
Git LFS Details
|
remove_optim.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch, argparse
|
| 2 |
+
from model.OneRestore import OneRestore
|
| 3 |
+
from model.Embedder import Embedder
|
| 4 |
+
|
| 5 |
+
parser = argparse.ArgumentParser()
|
| 6 |
+
|
| 7 |
+
parser.add_argument("--type", type=str, default = 'OneRestore')
|
| 8 |
+
parser.add_argument("--input-file", type=str, default = './ckpts/onerestore_cdd-11.tar')
|
| 9 |
+
parser.add_argument("--output-file", type=str, default = './ckpts/onerestore_cdd-11.tar')
|
| 10 |
+
|
| 11 |
+
args = parser.parse_args()
|
| 12 |
+
|
| 13 |
+
if args.type == 'OneRestore':
|
| 14 |
+
restorer = OneRestore().to("cuda" if torch.cuda.is_available() else "cpu")
|
| 15 |
+
restorer_info = torch.load(args.input_file, map_location='cuda:0')
|
| 16 |
+
weights_dict = {}
|
| 17 |
+
for k, v in restorer_info['state_dict'].items():
|
| 18 |
+
new_k = k.replace('module.', '') if 'module' in k else k
|
| 19 |
+
weights_dict[new_k] = v
|
| 20 |
+
restorer.load_state_dict(weights_dict)
|
| 21 |
+
torch.save(restorer.state_dict(), args.output_file)
|
| 22 |
+
elif args.type == 'Embedder':
|
| 23 |
+
combine_type = ['clear', 'low', 'haze', 'rain', 'snow',\
|
| 24 |
+
'low_haze', 'low_rain', 'low_snow', 'haze_rain',\
|
| 25 |
+
'haze_snow', 'low_haze_rain', 'low_haze_snow']
|
| 26 |
+
embedder = Embedder(combine_type).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 27 |
+
embedder_info = torch.load(args.input_file)
|
| 28 |
+
embedder.load_state_dict(embedder_info['state_dict'])
|
| 29 |
+
torch.save(embedder.state_dict(), args.output_file)
|
| 30 |
+
else:
|
| 31 |
+
print('ERROR!')
|
| 32 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pillow
|
| 2 |
+
numpy
|
| 3 |
+
scikit-image
|
| 4 |
+
pandas
|
| 5 |
+
einops
|
| 6 |
+
thop
|
| 7 |
+
fasttext
|
| 8 |
+
opencv-python
|
| 9 |
+
h5py
|
| 10 |
+
matplotlib
|
syn_data/data/clear/1.jpg
ADDED

|
syn_data/data/depth_map/1.jpg
ADDED

|
syn_data/data/light_map/1.jpg
ADDED

|
syn_data/data/rain_mask/00001.jpg
ADDED

|
syn_data/data/rain_mask/00002.jpg
ADDED

|
syn_data/data/rain_mask/00003.jpg
ADDED

|
syn_data/data/snow_mask/beautiful_smile_00001.jpg
ADDED

|
syn_data/data/snow_mask/beautiful_smile_00006.jpg
ADDED

|
syn_data/data/snow_mask/beautiful_smile_00008.jpg
ADDED

|
syn_data/out/1.jpg
ADDED

|
syn_data/syn_data.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, argparse, cv2, random
|
| 2 |
+
import numpy as np
|
| 3 |
+
from skimage import exposure
|
| 4 |
+
|
| 5 |
+
def guideFilter(I, p, winSize, eps):
|
| 6 |
+
mean_I = cv2.blur(I, winSize)
|
| 7 |
+
mean_p = cv2.blur(p, winSize)
|
| 8 |
+
mean_II = cv2.blur(I * I, winSize)
|
| 9 |
+
mean_Ip = cv2.blur(I * p, winSize)
|
| 10 |
+
var_I = mean_II - mean_I * mean_I
|
| 11 |
+
cov_Ip = mean_Ip - mean_I * mean_p
|
| 12 |
+
a = cov_Ip / (var_I + eps)
|
| 13 |
+
b = mean_p - a * mean_I
|
| 14 |
+
mean_a = cv2.blur(a, winSize)
|
| 15 |
+
mean_b = cv2.blur(b, winSize)
|
| 16 |
+
q = mean_a * I + mean_b
|
| 17 |
+
return q
|
| 18 |
+
|
| 19 |
+
def syn_low(img, light, img_gray, light_max=3,
|
| 20 |
+
light_min=2, noise_max=0.08, noise_min=0.03):
|
| 21 |
+
light = guideFilter(light, img_gray,(3,3),0.01)[:, :, np.newaxis]
|
| 22 |
+
n = np.random.uniform(noise_min, noise_max)
|
| 23 |
+
R = img / (light + 1e-7)
|
| 24 |
+
L = (light + 1e-7) ** np.random.uniform(light_min, light_max)
|
| 25 |
+
return np.clip(R * L + np.random.normal(0, n, img.shape), 0, 1)
|
| 26 |
+
|
| 27 |
+
def syn_haze(img, depth, beta_max=2.0, beta_min=1.0, A_max=0.9, A_min=0.6,
|
| 28 |
+
color_max=0, color_min=0):
|
| 29 |
+
beta = np.random.rand(1) * (beta_max - beta_min) + beta_min
|
| 30 |
+
t = np.exp(-np.minimum(1 - cv2.blur(depth,(22,22)),0.7) * beta)
|
| 31 |
+
A = np.random.rand(1) * (A_max - A_min) + A_min
|
| 32 |
+
A_random = np.random.rand(3) * (color_max - color_min) + color_min
|
| 33 |
+
A = A + A_random
|
| 34 |
+
return np.clip(img * t + A * (1 - t), 0, 1)
|
| 35 |
+
|
| 36 |
+
def syn_data(hq_file, light_file, depth_file, rain_file, snow_file, out_file,
|
| 37 |
+
low, haze, rain, snow):
|
| 38 |
+
file_list = os.listdir(hq_file)
|
| 39 |
+
rain_list = os.listdir(rain_file)
|
| 40 |
+
snow_list = os.listdir(snow_file)
|
| 41 |
+
num_rain = random.sample(range(0,len(rain_list)),len(rain_list))
|
| 42 |
+
num_snow = random.sample(range(0,len(snow_list)),len(snow_list))
|
| 43 |
+
for i in range(1, len(file_list)):
|
| 44 |
+
img = cv2.imread(hq_file+file_list[i])
|
| 45 |
+
w, h, _ = img.shape
|
| 46 |
+
light = cv2.cvtColor(cv2.imread(light_file + file_list[i]), cv2.COLOR_RGB2GRAY) / 255.0
|
| 47 |
+
depth = cv2.imread(depth_file + file_list[i]) / 255.0
|
| 48 |
+
rain_mask = cv2.imread(rain_file + rain_list[num_rain[i]]) / 255.0
|
| 49 |
+
rain_mask = cv2.resize(rain_mask,(h,w))
|
| 50 |
+
snow_mask = cv2.imread(snow_file + snow_list[num_snow[i]]) / 255.0
|
| 51 |
+
snow_mask = cv2.resize(snow_mask, (h, w))
|
| 52 |
+
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)/ 255.0
|
| 53 |
+
lq = img.copy()/255.0
|
| 54 |
+
color_dis = 1
|
| 55 |
+
|
| 56 |
+
if low:
|
| 57 |
+
lq = syn_low(lq, light, img_gray)
|
| 58 |
+
if rain:
|
| 59 |
+
lq = lq+rain_mask
|
| 60 |
+
if snow:
|
| 61 |
+
lq = lq*(1-snow_mask)+color_dis*snow_mask
|
| 62 |
+
if haze:
|
| 63 |
+
lq = syn_haze(lq, depth)
|
| 64 |
+
|
| 65 |
+
# out = np.concatenate((lq*255.0,img),1)
|
| 66 |
+
out = lq*255.0
|
| 67 |
+
cv2.imwrite(out_file + file_list[i], out)
|
| 68 |
+
|
| 69 |
+
if __name__ == "__main__":
|
| 70 |
+
parser = argparse.ArgumentParser()
|
| 71 |
+
# load model
|
| 72 |
+
parser.add_argument("--hq-file", type=str, default = './data/clear/')
|
| 73 |
+
parser.add_argument("--light-file", type=str, default = './data/light_map/')
|
| 74 |
+
parser.add_argument("--depth-file", type=str, default = './data/depth_map/')
|
| 75 |
+
parser.add_argument("--rain-file", type=str, default = './data/rain_mask/')
|
| 76 |
+
parser.add_argument("--snow-file", type=str, default = './data/snow_mask/')
|
| 77 |
+
parser.add_argument("--out-file", type=str, default = './out/')
|
| 78 |
+
parser.add_argument("--low", action='store_true')
|
| 79 |
+
parser.add_argument("--haze", action='store_true')
|
| 80 |
+
parser.add_argument("--rain", action='store_true')
|
| 81 |
+
parser.add_argument("--snow", action='store_true')
|
| 82 |
+
|
| 83 |
+
args = parser.parse_args()
|
| 84 |
+
|
| 85 |
+
syn_data(args.hq_file, args.light_file, args.depth_file, args.rain_file,
|
| 86 |
+
args.snow_file, args.out_file, args.low, args.haze, args.rain, args.snow)
|
test.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, time, argparse
|
| 2 |
+
from PIL import Image
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
from torchvision import transforms
|
| 8 |
+
|
| 9 |
+
from torchvision.utils import save_image as imwrite
|
| 10 |
+
from utils.utils import print_args, load_restore_ckpt, load_embedder_ckpt
|
| 11 |
+
|
| 12 |
+
transform_resize = transforms.Compose([
|
| 13 |
+
transforms.Resize([224,224]),
|
| 14 |
+
transforms.ToTensor()
|
| 15 |
+
])
|
| 16 |
+
|
| 17 |
+
def main(args):
|
| 18 |
+
|
| 19 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 20 |
+
#train
|
| 21 |
+
print('> Model Initialization...')
|
| 22 |
+
|
| 23 |
+
embedder = load_embedder_ckpt(device, freeze_model=True, ckpt_name=args.embedder_model_path)
|
| 24 |
+
restorer = load_restore_ckpt(device, freeze_model=True, ckpt_name=args.restore_model_path)
|
| 25 |
+
|
| 26 |
+
os.makedirs(args.output,exist_ok=True)
|
| 27 |
+
|
| 28 |
+
files = os.listdir(argspar.input)
|
| 29 |
+
time_record = []
|
| 30 |
+
for i in files:
|
| 31 |
+
lq = Image.open(f'{argspar.input}/{i}')
|
| 32 |
+
|
| 33 |
+
with torch.no_grad():
|
| 34 |
+
lq_re = torch.Tensor((np.array(lq)/255).transpose(2, 0, 1)).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 35 |
+
lq_em = transform_resize(lq).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 36 |
+
|
| 37 |
+
start_time = time.time()
|
| 38 |
+
|
| 39 |
+
if args.prompt == None:
|
| 40 |
+
text_embedding, _, [text] = embedder(lq_em,'image_encoder')
|
| 41 |
+
print(f'This is {text} degradation estimated by visual embedder.')
|
| 42 |
+
else:
|
| 43 |
+
text_embedding, _, [text] = embedder([args.prompt],'text_encoder')
|
| 44 |
+
print(f'This is {text} degradation generated by input text.')
|
| 45 |
+
|
| 46 |
+
out = restorer(lq_re, text_embedding)
|
| 47 |
+
|
| 48 |
+
run_time = time.time()-start_time
|
| 49 |
+
time_record.append(run_time)
|
| 50 |
+
|
| 51 |
+
if args.concat:
|
| 52 |
+
out = torch.cat((lq_re, out), dim=3)
|
| 53 |
+
|
| 54 |
+
imwrite(out, f'{args.output}/{i}', range=(0, 1))
|
| 55 |
+
|
| 56 |
+
print(f'{i} Running Time: {run_time:.4f}.')
|
| 57 |
+
print(f'Average time is {np.mean(np.array(run_time))}')
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
|
| 61 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
|
| 62 |
+
if __name__ == '__main__':
|
| 63 |
+
|
| 64 |
+
parser = argparse.ArgumentParser(description = "OneRestore Running")
|
| 65 |
+
|
| 66 |
+
# load model
|
| 67 |
+
parser.add_argument("--embedder-model-path", type=str, default = "./ckpts/embedder_model.tar", help = 'embedder model path')
|
| 68 |
+
parser.add_argument("--restore-model-path", type=str, default = "./ckpts/onerestore_cdd-11.tar", help = 'restore model path')
|
| 69 |
+
|
| 70 |
+
# select model automatic (prompt=False) or manual (prompt=True, text={'clear', 'low', 'haze', 'rain', 'snow',\
|
| 71 |
+
# 'low_haze', 'low_rain', 'low_snow', 'haze_rain', 'haze_snow', 'low_haze_rain', 'low_haze_snow'})
|
| 72 |
+
parser.add_argument("--prompt", type=str, default = None, help = 'prompt')
|
| 73 |
+
|
| 74 |
+
parser.add_argument("--input", type=str, default = "./image/", help = 'image path')
|
| 75 |
+
parser.add_argument("--output", type=str, default = "./output/", help = 'output path')
|
| 76 |
+
parser.add_argument("--concat", action='store_true', help = 'output path')
|
| 77 |
+
|
| 78 |
+
argspar = parser.parse_args()
|
| 79 |
+
|
| 80 |
+
print_args(argspar)
|
| 81 |
+
|
| 82 |
+
main(argspar)
|
train_Embedder.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse, os, torch, time
|
| 2 |
+
import torch.optim
|
| 3 |
+
|
| 4 |
+
from utils.utils import load_embedder_ckpt_with_optim, adjust_learning_rate, freeze_text_embedder, AverageMeter
|
| 5 |
+
from utils.utils_data import init_embedding_data
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def train_embedding(cur_epoch, model, optimizer, trainloader, testloader, device, cfg_em):
|
| 10 |
+
torch.backends.cudnn.benchmark = False
|
| 11 |
+
torch.backends.cudnn.enabled = True
|
| 12 |
+
|
| 13 |
+
acc_train_meter = AverageMeter()
|
| 14 |
+
acc_test_meter = AverageMeter()
|
| 15 |
+
loss_train_meter = AverageMeter()
|
| 16 |
+
loss_test_meter = AverageMeter()
|
| 17 |
+
time_train_meter = AverageMeter()
|
| 18 |
+
time_test_meter = AverageMeter()
|
| 19 |
+
|
| 20 |
+
freeze_text_embedder(model)
|
| 21 |
+
for k,v in model.named_parameters():
|
| 22 |
+
print('{}: {}'.format(k, v.requires_grad))
|
| 23 |
+
for epoch in range(cur_epoch, cfg_em.epoch+1):
|
| 24 |
+
|
| 25 |
+
optimizer = adjust_learning_rate(optimizer, epoch-1, cfg_em.lr_decay)
|
| 26 |
+
lr = optimizer.param_groups[-1]['lr']
|
| 27 |
+
|
| 28 |
+
model.train()
|
| 29 |
+
for idx, batch in enumerate(trainloader):
|
| 30 |
+
for i in range(len(batch)):
|
| 31 |
+
batch[i] = batch[i].to("cuda" if torch.cuda.is_available() else "cpu")
|
| 32 |
+
time_start = time.time()
|
| 33 |
+
out = model(batch, 'train')
|
| 34 |
+
loss = out['loss_total']
|
| 35 |
+
acc = out['acc_type']
|
| 36 |
+
time_train_meter.update(time.time() - time_start)
|
| 37 |
+
|
| 38 |
+
acc_train_meter.update(acc)
|
| 39 |
+
loss_train_meter.update(loss)
|
| 40 |
+
|
| 41 |
+
optimizer.zero_grad()
|
| 42 |
+
loss.backward()
|
| 43 |
+
optimizer.step()
|
| 44 |
+
|
| 45 |
+
print(f'Epoch:{epoch}|Iter:{idx+1}/{len(trainloader)}|lr:{lr},'
|
| 46 |
+
f'Loss: {loss_train_meter.avg:.3f},'
|
| 47 |
+
f'Acc: {acc_train_meter.avg:.3f},'
|
| 48 |
+
f'Time: {time_train_meter.avg:.3f},', flush=True)
|
| 49 |
+
|
| 50 |
+
model.eval()
|
| 51 |
+
for idx, batch in enumerate(testloader):
|
| 52 |
+
for i in range(len(batch)):
|
| 53 |
+
batch[i] = batch[i].to("cuda" if torch.cuda.is_available() else "cpu")
|
| 54 |
+
|
| 55 |
+
time_start = time.time()
|
| 56 |
+
out = model(batch, 'train')
|
| 57 |
+
loss = out['loss_total']
|
| 58 |
+
acc = out['acc_type']
|
| 59 |
+
time_test_meter.update(time.time() - time_start)
|
| 60 |
+
|
| 61 |
+
acc_test_meter.update(acc)
|
| 62 |
+
loss_test_meter.update(loss)
|
| 63 |
+
print(f'Epoch:{epoch}|Iter:{idx+1}/{len(testloader)}|lr:{lr},'
|
| 64 |
+
f'Loss: {loss_test_meter.avg:.3f},'
|
| 65 |
+
f'Acc: {acc_test_meter.avg:.3f},'
|
| 66 |
+
f'Time: {time_test_meter.avg:.3f},', flush=True)
|
| 67 |
+
|
| 68 |
+
torch.save({'epoch': epoch, 'state_dict': model.state_dict(), 'optimizer' : optimizer.state_dict()},
|
| 69 |
+
f'{cfg_em.check_dir}/embedder_model_epoch{epoch}_{acc_train_meter.avg:.3f}_{loss_train_meter.avg:.3f}_{acc_test_meter.avg:.3f}_{loss_test_meter.avg:.3f}.tar')
|
| 70 |
+
acc_train_meter.reset()
|
| 71 |
+
acc_test_meter.reset()
|
| 72 |
+
loss_train_meter.reset()
|
| 73 |
+
loss_test_meter.reset()
|
| 74 |
+
time_train_meter.reset()
|
| 75 |
+
time_test_meter.reset()
|
| 76 |
+
print('Done!')
|
| 77 |
+
|
| 78 |
+
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
|
| 79 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
|
| 80 |
+
if __name__ == "__main__":
|
| 81 |
+
parser = argparse.ArgumentParser()
|
| 82 |
+
# load model
|
| 83 |
+
parser.add_argument("--seed", type=int, default = 124)
|
| 84 |
+
parser.add_argument("--pre_weight", type=str, default = '')
|
| 85 |
+
parser.add_argument("--lr", type=float, default = 0.0001)
|
| 86 |
+
parser.add_argument("--type_name", type=list, default = ['clear', 'low', 'haze', 'rain',\
|
| 87 |
+
'snow', 'low_haze', 'low_rain', 'low_snow', 'haze_rain',\
|
| 88 |
+
'haze_snow', 'low_haze_rain', 'low_haze_snow'])
|
| 89 |
+
parser.add_argument("--train-dir", type=str, default = './data/CDD-11_train/')
|
| 90 |
+
parser.add_argument("--test-dir", type=str, default = './data/CDD-11_test/')
|
| 91 |
+
parser.add_argument("--batch", type=int, default = 128)
|
| 92 |
+
parser.add_argument("--num-workers", type=int, default = 0)
|
| 93 |
+
parser.add_argument("--epoch", type=int, default = 200)
|
| 94 |
+
parser.add_argument("--lr-decay", type=int, default = 50)
|
| 95 |
+
parser.add_argument("--check-dir", type=str, default = "./ckpts")
|
| 96 |
+
|
| 97 |
+
args = parser.parse_args()
|
| 98 |
+
|
| 99 |
+
os.makedirs(args.check_dir,exist_ok=True)
|
| 100 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 101 |
+
|
| 102 |
+
embedder, optimizer, cur_epoch, device = load_embedder_ckpt_with_optim(device, args)
|
| 103 |
+
trainloader, testloader = init_embedding_data(args, 'train')
|
| 104 |
+
train_embedding(cur_epoch, embedder, optimizer, trainloader, testloader, device, args)
|
train_OneRestore_multi-gpu.py
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, time, torch, argparse
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
from torchvision.utils import save_image as imwrite
|
| 5 |
+
import numpy as np
|
| 6 |
+
from torchvision import transforms
|
| 7 |
+
from makedataset import Dataset
|
| 8 |
+
from utils.utils import print_args, load_restore_ckpt_with_optim, load_embedder_ckpt, adjust_learning_rate, data_process, tensor_metric, load_excel, save_checkpoint
|
| 9 |
+
from model.loss import Total_loss
|
| 10 |
+
from model.Embedder import Embedder
|
| 11 |
+
from model.OneRestore import OneRestore
|
| 12 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 13 |
+
from PIL import Image
|
| 14 |
+
|
| 15 |
+
torch.distributed.init_process_group(backend="nccl")
|
| 16 |
+
local_rank = torch.distributed.get_rank()
|
| 17 |
+
torch.cuda.set_device(local_rank)
|
| 18 |
+
device = torch.device("cuda", local_rank)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
transform_resize = transforms.Compose([
|
| 22 |
+
transforms.Resize([224,224]),
|
| 23 |
+
transforms.ToTensor()
|
| 24 |
+
])
|
| 25 |
+
|
| 26 |
+
def main(args):
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
print('> Model Initialization...')
|
| 30 |
+
embedder = load_embedder_ckpt(device, freeze_model=True, ckpt_name=args.embedder_model_path)
|
| 31 |
+
restorer, optimizer, cur_epoch = load_restore_ckpt_with_optim(device, local_rank=local_rank, freeze_model=False, ckpt_name=args.restore_model_path, lr=args.lr)
|
| 32 |
+
loss = Total_loss(args)
|
| 33 |
+
|
| 34 |
+
print('> Loading dataset...')
|
| 35 |
+
data = Dataset(args.train_input)
|
| 36 |
+
dataset = DataLoader(dataset=data, batch_size=args.bs,
|
| 37 |
+
shuffle=False,
|
| 38 |
+
num_workers=args.num_works,
|
| 39 |
+
pin_memory=True,drop_last=False,
|
| 40 |
+
sampler=DistributedSampler(data,shuffle=True))
|
| 41 |
+
|
| 42 |
+
print('> Start training...')
|
| 43 |
+
start_all = time.time()
|
| 44 |
+
train(restorer, embedder, optimizer, loss, cur_epoch, args, dataset, device)
|
| 45 |
+
end_all = time.time()
|
| 46 |
+
print('Whloe Training Time:' +str(end_all-start_all)+'s.')
|
| 47 |
+
|
| 48 |
+
def train(restorer, embedder, optimizer, loss, cur_epoch, args, dataset, device):
|
| 49 |
+
|
| 50 |
+
metric = []
|
| 51 |
+
for epoch in range(cur_epoch, args.epoch):
|
| 52 |
+
optimizer = adjust_learning_rate(optimizer, epoch, args.adjust_lr)
|
| 53 |
+
learnrate = optimizer.param_groups[-1]['lr']
|
| 54 |
+
restorer.train()
|
| 55 |
+
|
| 56 |
+
for i, data in enumerate(dataset,0):
|
| 57 |
+
pos, inp, neg = data_process(data, args, device)
|
| 58 |
+
|
| 59 |
+
text_embedding,_,_ = embedder(inp[1],'text_encoder')
|
| 60 |
+
out = restorer(inp[0], text_embedding)
|
| 61 |
+
|
| 62 |
+
restorer.zero_grad()
|
| 63 |
+
total_loss = loss(inp, pos, neg, out)
|
| 64 |
+
total_loss.backward()
|
| 65 |
+
optimizer.step()
|
| 66 |
+
|
| 67 |
+
mse = tensor_metric(pos,out, 'MSE', data_range=1)
|
| 68 |
+
psnr = tensor_metric(pos,out, 'PSNR', data_range=1)
|
| 69 |
+
ssim = tensor_metric(pos,out, 'SSIM', data_range=1)
|
| 70 |
+
|
| 71 |
+
print("[epoch %d][%d/%d] lr :%f Floss: %.4f MSE: %.4f PSNR: %.4f SSIM: %.4f"%(epoch+1, i+1, \
|
| 72 |
+
len(dataset), learnrate, total_loss.item(), mse, psnr, ssim))
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
psnr_t1, ssim_t1, psnr_t2, ssim_t2 = test(args, restorer, embedder, device, epoch)
|
| 76 |
+
metric.append([psnr_t1, ssim_t1, psnr_t2, ssim_t2])
|
| 77 |
+
print("[epoch %d] Test images PSNR1: %.4f SSIM1: %.4f"%(epoch+1, psnr_t1,ssim_t1))
|
| 78 |
+
|
| 79 |
+
load_excel(metric)
|
| 80 |
+
save_checkpoint({'epoch': epoch + 1,'state_dict': restorer.state_dict(),'optimizer' : optimizer.state_dict()},\
|
| 81 |
+
args.save_model_path, epoch+1, psnr_t1,ssim_t1,psnr_t2,ssim_t2)
|
| 82 |
+
|
| 83 |
+
def test(args, restorer, embedder, device, epoch=-1):
|
| 84 |
+
combine_type = args.degr_type
|
| 85 |
+
psnr_1, psnr_2, ssim_1, ssim_2 = 0, 0, 0, 0
|
| 86 |
+
os.makedirs(args.output,exist_ok=True)
|
| 87 |
+
|
| 88 |
+
for i in range(len(combine_type)-1):
|
| 89 |
+
file_list = os.listdir(f'{args.test_input}/{combine_type[i+1]}/')
|
| 90 |
+
for j in range(len(file_list)):
|
| 91 |
+
hq = Image.open(f'{args.test_input}/{combine_type[0]}/{file_list[j]}')
|
| 92 |
+
lq = Image.open(f'{args.test_input}/{combine_type[i+1]}/{file_list[j]}')
|
| 93 |
+
restorer.eval()
|
| 94 |
+
with torch.no_grad():
|
| 95 |
+
lq_re = torch.Tensor((np.array(lq)/255).transpose(2, 0, 1)).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 96 |
+
lq_em = transform_resize(lq).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 97 |
+
hq = torch.Tensor((np.array(hq)/255).transpose(2, 0, 1)).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 98 |
+
|
| 99 |
+
starttime = time.time()
|
| 100 |
+
|
| 101 |
+
text_embedding_1,_,text_1 = embedder([combine_type[i+1]],'text_encoder')
|
| 102 |
+
text_embedding_2,_, text_2 = embedder(lq_em,'image_encoder')
|
| 103 |
+
out_1 = restorer(lq_re, text_embedding_1)
|
| 104 |
+
if text_1 != text_2:
|
| 105 |
+
print(text_1, text_2)
|
| 106 |
+
out_2 = restorer(lq_re, text_embedding_2)
|
| 107 |
+
else:
|
| 108 |
+
out_2 = out_1
|
| 109 |
+
|
| 110 |
+
endtime1 = time.time()
|
| 111 |
+
|
| 112 |
+
imwrite(torch.cat((lq_re, out_1, out_2, hq), dim=3), args.output \
|
| 113 |
+
+ file_list[j][:-4] + '_' + str(epoch) + '_' + combine_type[i+1] + '.png', range=(0, 1))
|
| 114 |
+
# due to the vision problem, you can replace above line by
|
| 115 |
+
# imwrite(torch.cat((lq_re, out_1, out_2, hq), dim=3), args.output \
|
| 116 |
+
# + file_list[j][:-4] + '_' + str(epoch) + '_' + combine_type[i+1] + '.png')
|
| 117 |
+
psnr_1 += tensor_metric(hq, out_1, 'PSNR', data_range=1)
|
| 118 |
+
ssim_1 += tensor_metric(hq, out_1, 'SSIM', data_range=1)
|
| 119 |
+
psnr_2 += tensor_metric(hq, out_2, 'PSNR', data_range=1)
|
| 120 |
+
ssim_2 += tensor_metric(hq, out_2, 'SSIM', data_range=1)
|
| 121 |
+
print('The ' + file_list[j][:-4] + ' Time:' + str(endtime1 - starttime) + 's.')
|
| 122 |
+
|
| 123 |
+
return psnr_1 / (len(file_list)*len(combine_type)), ssim_1 / (len(file_list)*len(combine_type)),\
|
| 124 |
+
psnr_2 / (len(file_list)*len(combine_type)), ssim_2 / (len(file_list)*len(combine_type))
|
| 125 |
+
|
| 126 |
+
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
|
| 127 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
|
| 128 |
+
if __name__ == '__main__':
|
| 129 |
+
|
| 130 |
+
parser = argparse.ArgumentParser(description = "OneRestore Training")
|
| 131 |
+
|
| 132 |
+
# load model
|
| 133 |
+
parser.add_argument("--embedder-model-path", type=str, default = "./ckpts/embedder_model.tar", help = 'embedder model path')
|
| 134 |
+
parser.add_argument("--restore-model-path", type=str, default = None, help = 'restore model path')
|
| 135 |
+
parser.add_argument("--save-model-path", type=str, default = "./ckpts/", help = 'restore model path')
|
| 136 |
+
|
| 137 |
+
parser.add_argument("--epoch", type=int, default = 300, help = 'epoch number')
|
| 138 |
+
parser.add_argument("--bs", type=int, default = 4, help = 'batchsize')
|
| 139 |
+
parser.add_argument("--lr", type=float, default = 1e-4, help = 'learning rate')
|
| 140 |
+
parser.add_argument("--adjust-lr", type=int, default = 30, help = 'adjust learning rate')
|
| 141 |
+
parser.add_argument("--num-works", type=int, default = 4, help = 'number works')
|
| 142 |
+
parser.add_argument("--loss-weight", type=tuple, default = (0.6,0.3,0.1), help = 'loss weights')
|
| 143 |
+
parser.add_argument("--degr-type", type=list, default = ['clear', 'low', 'haze', 'rain', 'snow',\
|
| 144 |
+
'low_haze', 'low_rain', 'low_snow', 'haze_rain', 'haze_snow', 'low_haze_rain', 'low_haze_snow'], help = 'degradation type')
|
| 145 |
+
|
| 146 |
+
parser.add_argument("--train-input", type=str, default = "./dataset.h5", help = 'train data')
|
| 147 |
+
parser.add_argument("--test-input", type=str, default = "./data/CDD-11_test", help = 'test path')
|
| 148 |
+
parser.add_argument("--output", type=str, default = "./result/", help = 'output path')
|
| 149 |
+
|
| 150 |
+
argspar = parser.parse_args()
|
| 151 |
+
|
| 152 |
+
print_args(argspar)
|
| 153 |
+
main(argspar)
|
train_OneRestore_single-gpu.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, time, torch, argparse
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
from torch.utils.data import DataLoader
|
| 4 |
+
from torchvision.utils import save_image as imwrite
|
| 5 |
+
import numpy as np
|
| 6 |
+
from torchvision import transforms
|
| 7 |
+
from makedataset import Dataset
|
| 8 |
+
from utils.utils import print_args, load_restore_ckpt_with_optim, load_embedder_ckpt, adjust_learning_rate, data_process, tensor_metric, load_excel, save_checkpoint
|
| 9 |
+
from model.loss import Total_loss
|
| 10 |
+
|
| 11 |
+
from PIL import Image
|
| 12 |
+
|
| 13 |
+
transform_resize = transforms.Compose([
|
| 14 |
+
transforms.Resize([224,224]),
|
| 15 |
+
transforms.ToTensor()
|
| 16 |
+
])
|
| 17 |
+
|
| 18 |
+
def main(args):
|
| 19 |
+
|
| 20 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 21 |
+
|
| 22 |
+
print('> Model Initialization...')
|
| 23 |
+
|
| 24 |
+
embedder = load_embedder_ckpt(device, freeze_model=True, ckpt_name=args.embedder_model_path)
|
| 25 |
+
restorer, optimizer, cur_epoch = load_restore_ckpt_with_optim(device, freeze_model=False, ckpt_name=args.restore_model_path, lr=args.lr)
|
| 26 |
+
loss = Total_loss(args)
|
| 27 |
+
|
| 28 |
+
print('> Loading dataset...')
|
| 29 |
+
data = Dataset(args.train_input)
|
| 30 |
+
dataset = DataLoader(dataset=data, num_workers=args.num_works, batch_size=args.bs, shuffle=True)
|
| 31 |
+
|
| 32 |
+
print('> Start training...')
|
| 33 |
+
start_all = time.time()
|
| 34 |
+
train(restorer, embedder, optimizer, loss, cur_epoch, args, dataset, device)
|
| 35 |
+
end_all = time.time()
|
| 36 |
+
print('Whloe Training Time:' +str(end_all-start_all)+'s.')
|
| 37 |
+
|
| 38 |
+
def train(restorer, embedder, optimizer, loss, cur_epoch, args, dataset, device):
|
| 39 |
+
|
| 40 |
+
metric = []
|
| 41 |
+
for epoch in range(cur_epoch, args.epoch):
|
| 42 |
+
optimizer = adjust_learning_rate(optimizer, epoch, args.adjust_lr)
|
| 43 |
+
learnrate = optimizer.param_groups[-1]['lr']
|
| 44 |
+
restorer.train()
|
| 45 |
+
|
| 46 |
+
for i, data in enumerate(dataset,0):
|
| 47 |
+
pos, inp, neg = data_process(data, args, device)
|
| 48 |
+
|
| 49 |
+
text_embedding,_,_ = embedder(inp[1],'text_encoder')
|
| 50 |
+
out = restorer(inp[0], text_embedding)
|
| 51 |
+
|
| 52 |
+
restorer.zero_grad()
|
| 53 |
+
total_loss = loss(inp, pos, neg, out)
|
| 54 |
+
total_loss.backward()
|
| 55 |
+
optimizer.step()
|
| 56 |
+
|
| 57 |
+
mse = tensor_metric(pos,out, 'MSE', data_range=1)
|
| 58 |
+
psnr = tensor_metric(pos,out, 'PSNR', data_range=1)
|
| 59 |
+
ssim = tensor_metric(pos,out, 'SSIM', data_range=1)
|
| 60 |
+
|
| 61 |
+
print("[epoch %d][%d/%d] lr :%f Floss: %.4f MSE: %.4f PSNR: %.4f SSIM: %.4f"%(epoch+1, i+1, \
|
| 62 |
+
len(dataset), learnrate, total_loss.item(), mse, psnr, ssim))
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
psnr_t1, ssim_t1, psnr_t2, ssim_t2 = test(args, restorer, embedder, device, epoch)
|
| 66 |
+
metric.append([psnr_t1, ssim_t1, psnr_t2, ssim_t2])
|
| 67 |
+
print("[epoch %d] Test images PSNR1: %.4f SSIM1: %.4f"%(epoch+1, psnr_t1,ssim_t1))
|
| 68 |
+
|
| 69 |
+
load_excel(metric)
|
| 70 |
+
save_checkpoint({'epoch': epoch + 1,'state_dict': restorer.state_dict(),'optimizer' : optimizer.state_dict()},\
|
| 71 |
+
args.save_model_path, epoch+1, psnr_t1,ssim_t1,psnr_t2,ssim_t2)
|
| 72 |
+
|
| 73 |
+
def test(args, restorer, embedder, device, epoch=-1):
|
| 74 |
+
combine_type = args.degr_type
|
| 75 |
+
psnr_1, psnr_2, ssim_1, ssim_2 = 0, 0, 0, 0
|
| 76 |
+
os.makedirs(args.output,exist_ok=True)
|
| 77 |
+
|
| 78 |
+
for i in range(len(combine_type)-1):
|
| 79 |
+
file_list = os.listdir(f'{args.test_input}/{combine_type[i+1]}/')
|
| 80 |
+
for j in range(len(file_list)):
|
| 81 |
+
hq = Image.open(f'{args.test_input}/{combine_type[0]}/{file_list[j]}')
|
| 82 |
+
lq = Image.open(f'{args.test_input}/{combine_type[i+1]}/{file_list[j]}')
|
| 83 |
+
restorer.eval()
|
| 84 |
+
with torch.no_grad():
|
| 85 |
+
lq_re = torch.Tensor((np.array(lq)/255).transpose(2, 0, 1)).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 86 |
+
lq_em = transform_resize(lq).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 87 |
+
hq = torch.Tensor((np.array(hq)/255).transpose(2, 0, 1)).unsqueeze(0).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 88 |
+
|
| 89 |
+
starttime = time.time()
|
| 90 |
+
|
| 91 |
+
text_embedding_1,_,text_1 = embedder([combine_type[i+1]],'text_encoder')
|
| 92 |
+
text_embedding_2,_, text_2 = embedder(lq_em,'image_encoder')
|
| 93 |
+
out_1 = restorer(lq_re, text_embedding_1)
|
| 94 |
+
if text_1 != text_2:
|
| 95 |
+
print(text_1, text_2)
|
| 96 |
+
out_2 = restorer(lq_re, text_embedding_2)
|
| 97 |
+
else:
|
| 98 |
+
out_2 = out_1
|
| 99 |
+
|
| 100 |
+
endtime1 = time.time()
|
| 101 |
+
|
| 102 |
+
imwrite(torch.cat((lq_re, out_1, out_2, hq), dim=3), args.output \
|
| 103 |
+
+ file_list[j][:-4] + '_' + str(epoch) + '_' + combine_type[i+1] + '.png', range=(0, 1))
|
| 104 |
+
psnr_1 += tensor_metric(hq, out_1, 'PSNR', data_range=1)
|
| 105 |
+
ssim_1 += tensor_metric(hq, out_1, 'SSIM', data_range=1)
|
| 106 |
+
psnr_2 += tensor_metric(hq, out_2, 'PSNR', data_range=1)
|
| 107 |
+
ssim_2 += tensor_metric(hq, out_2, 'SSIM', data_range=1)
|
| 108 |
+
print('The ' + file_list[j][:-4] + ' Time:' + str(endtime1 - starttime) + 's.')
|
| 109 |
+
|
| 110 |
+
return psnr_1 / (len(file_list)*len(combine_type)), ssim_1 / (len(file_list)*len(combine_type)),\
|
| 111 |
+
psnr_2 / (len(file_list)*len(combine_type)), ssim_2 / (len(file_list)*len(combine_type))
|
| 112 |
+
|
| 113 |
+
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
|
| 114 |
+
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
|
| 115 |
+
if __name__ == '__main__':
|
| 116 |
+
|
| 117 |
+
parser = argparse.ArgumentParser(description = "OneRestore Training")
|
| 118 |
+
|
| 119 |
+
# load model
|
| 120 |
+
parser.add_argument("--embedder-model-path", type=str, default = "./ckpts/embedder_model.tar", help = 'embedder model path')
|
| 121 |
+
parser.add_argument("--restore-model-path", type=str, default = None, help = 'restore model path')
|
| 122 |
+
parser.add_argument("--save-model-path", type=str, default = "./ckpts/", help = 'restore model path')
|
| 123 |
+
|
| 124 |
+
parser.add_argument("--epoch", type=int, default = 300, help = 'epoch number')
|
| 125 |
+
parser.add_argument("--bs", type=int, default = 4, help = 'batchsize')
|
| 126 |
+
parser.add_argument("--lr", type=float, default = 1e-4, help = 'learning rate')
|
| 127 |
+
parser.add_argument("--adjust-lr", type=int, default = 30, help = 'adjust learning rate')
|
| 128 |
+
parser.add_argument("--num-works", type=int, default = 4, help = 'number works')
|
| 129 |
+
parser.add_argument("--loss-weight", type=tuple, default = (0.6,0.3,0.1), help = 'loss weights')
|
| 130 |
+
parser.add_argument("--degr-type", type=list, default = ['clear', 'low', 'haze', 'rain', 'snow',\
|
| 131 |
+
'low_haze', 'low_rain', 'low_snow', 'haze_rain', 'haze_snow', 'low_haze_rain', 'low_haze_snow'], help = 'degradation type')
|
| 132 |
+
|
| 133 |
+
parser.add_argument("--train-input", type=str, default = "./dataset.h5", help = 'train data')
|
| 134 |
+
parser.add_argument("--test-input", type=str, default = "./data/CDD-11_test", help = 'test path')
|
| 135 |
+
parser.add_argument("--output", type=str, default = "./result/", help = 'output path')
|
| 136 |
+
|
| 137 |
+
argspar = parser.parse_args()
|
| 138 |
+
|
| 139 |
+
print_args(argspar)
|
| 140 |
+
main(argspar)
|
utils/glove.6B.300d.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
clear -0.081023 -0.29179 0.052021 -0.13324 0.028162 -0.0031446 -0.17156 0.063324 0.16568 -2.1722 -0.14127 0.087891 -0.2298 0.069017 0.21673 0.36556 -0.39979 -0.15506 0.099728 0.202 0.16989 0.14807 0.10938 -0.17141 -0.7258 -0.13189 -0.052768 -0.26383 -0.13189 -0.11408 0.081757 0.14773 -0.24342 0.0076364 -1.0992 0.13661 0.19262 -0.30012 0.031524 0.11439 -0.10854 0.21089 -0.037365 0.23449 0.054638 0.21505 0.023071 0.20918 -0.08606 -0.078589 -0.26945 -0.040802 -0.042601 -0.12093 -0.33614 0.25624 -0.35266 -0.17224 0.31018 0.6426 -0.036072 0.1558 0.26609 0.17298 -0.08158 0.0085636 0.13196 -0.11876 -0.19205 -0.32204 -0.092694 -0.19274 0.0056832 0.17194 0.24011 0.014739 0.091188 0.45903 0.0047753 -0.18136 -0.16434 0.012617 0.42791 0.075318 -0.042848 -0.055952 -0.071895 0.086806 0.078092 0.20169 -0.34189 -0.01975 -0.44579 -0.093254 0.23684 0.098079 -0.0018186 -0.13013 0.054252 -0.68408 0.21378 -0.084742 -0.12383 0.36645 -0.46434 0.56799 0.22341 0.31607 -0.23559 0.033889 0.062509 -0.31468 0.27684 -0.13729 -0.027181 0.17143 -0.35535 0.14426 0.14137 -0.27987 0.051007 0.1689 0.48614 0.43247 -0.31014 -0.2273 -0.17253 0.50221 -0.29023 -0.16833 -0.027586 0.25614 0.096051 0.19145 -0.15576 0.50767 0.0064827 -0.047304 0.47358 -0.029665 -0.095882 0.064574 0.1247 -0.3439 -0.59591 -0.17307 0.30627 0.16351 -0.21709 -0.13142 -0.029781 0.079412 0.36018 -0.068721 0.367 0.26454 0.1306 -0.34602 0.22326 0.22999 0.14122 -0.3084 0.22239 -0.13701 0.24538 0.10902 0.33084 0.052159 -0.54817 0.32921 0.33889 -0.060382 -0.16611 -0.26388 0.13997 -0.15486 -0.05013 -0.089628 -0.0080954 0.13155 -0.019735 0.25758 0.37509 -0.012096 -0.49247 0.13436 -0.21072 -0.13763 0.24047 0.13328 -0.043418 0.0070651 0.30496 -0.11184 0.68017 -0.65417 -0.39198 0.075546 -0.2043 0.041099 0.84586 -0.3361 -0.26385 -0.39417 -0.25468 -0.095349 0.19947 -0.30772 -0.53846 0.18258 -0.091379 -0.27183 0.10918 -0.042102 -0.25614 -0.039694 0.34987 -0.24526 -0.011983 -0.024231 0.62785 -0.16641 0.026109 0.029096 -0.16937 0.25329 -0.12066 0.023087 0.16152 -0.14058 0.044846 0.4533 0.34099 -0.028432 -0.39407 -0.068924 -0.29128 -0.012954 0.048176 -0.090455 -0.0098771 -0.022352 0.091535 -0.084673 -0.43955 -0.25237 0.79719 0.21526 0.0019634 -0.10022 -0.075669 -0.25113 -0.12675 0.12179 0.25892 0.026661 -0.38419 -0.18566 -0.15325 0.44484 -0.088815 0.10119 0.0060884 0.293 -0.415 0.26712 0.033683 -0.42317 0.22025 -0.027351 0.40923 -0.013339 -0.29543 0.37699 -0.019656 -0.082896 -1.5198 0.2961 0.81263 -0.18199 0.59082 0.007938 0.2309 0.23573 0.24941 -0.18754 -0.04029 0.17258 0.1948 0.131 -0.21552 0.016352 0.62256 0.41283 0.40387 -0.062911 -0.093159 -0.078137 -0.30083 -0.035913
|
| 2 |
+
low -0.21751 0.43389 0.149 0.14107 0.2574 -0.12448 0.0047523 0.035596 0.10741 -2.1047 0.17181 -0.15079 -0.044546 -0.090869 -0.43288 -0.13611 -0.0058198 -0.064724 0.23531 -0.36224 -0.21305 -0.075476 0.46786 -0.18465 -0.19746 -0.097471 0.39984 -0.084092 -0.53715 0.27303 -0.087786 0.24297 -0.38444 0.28854 -0.7873 0.089192 -0.26376 -0.16287 0.35911 0.30458 0.24502 0.22553 -0.0031653 0.47358 0.31146 -0.13823 0.075685 -0.10776 0.38329 -0.13762 0.51707 -0.16707 -0.037466 -0.7236 -0.4151 -0.42359 0.14354 0.046639 0.17527 0.48721 0.26708 -0.031042 0.86002 -0.3946 -0.50514 -0.51294 0.58527 0.18819 -0.29543 0.68596 -0.1035 0.22565 0.185 0.058375 0.030999 0.11929 0.12353 0.12873 0.42126 0.14188 -0.050079 -0.2683 0.12126 0.32302 0.27623 0.5414 0.074715 -0.1949 -0.47053 0.02313 0.68686 0.60158 -0.16194 -0.3651 0.41796 -0.22905 0.074734 0.17509 -0.44255 0.3518 -0.40079 -0.28305 0.39133 0.32303 -0.63198 -0.1507 -0.16894 0.17169 0.18894 0.027644 -0.36997 -0.26366 0.36344 -0.049584 0.32724 0.049712 0.051381 -0.058867 -0.2621 -0.50359 -0.21435 -0.25527 0.22161 0.66558 0.2224 0.27607 0.58587 -0.3071 0.24905 0.098802 -0.26459 0.77839 0.014585 0.86936 0.2329 -0.0027986 -0.087016 0.10863 0.18987 0.54552 0.24903 0.059293 0.30362 -0.028582 -0.6569 0.1206 -0.055416 -0.093077 -0.0012132 -0.15009 0.11192 -0.62139 -0.035773 0.1165 0.36541 0.55984 -0.19964 -0.065579 0.097118 -0.1672 0.13677 -0.95276 -0.25994 0.064799 -0.042161 0.12046 0.12391 0.0017478 0.29533 0.40176 0.057528 0.57864 -0.9973 0.13805 -0.30689 0.11015 -0.35402 -0.13434 -0.24479 0.50355 -0.18675 -0.22337 0.29573 0.21612 -0.068496 -0.60643 0.79013 -0.26975 -0.15492 0.70849 0.21372 0.62962 -0.0056421 0.53597 -0.54259 -0.34726 -0.29945 -0.51895 0.28471 -0.14973 0.54188 0.53535 -0.11233 0.19291 -0.24707 0.058424 -0.5473 -0.06426 0.47187 0.11149 0.28313 -0.23876 -0.10552 -0.051705 -0.28853 -0.13702 0.040562 -0.032269 0.10368 -0.29381 0.33416 0.038269 0.029697 -0.48604 -0.26334 0.28942 -0.0093944 0.13942 -0.29043 0.27332 0.16614 -0.028973 -0.32829 -0.034614 -0.0012628 0.062871 -0.000894 0.22467 0.16005 0.23141 -0.19918 0.16465 0.15247 0.29742 -1.0225 0.056188 0.91529 -0.47809 -0.24204 -0.3158 0.21033 -0.13616 0.10777 -0.26815 -0.44804 -0.12696 -0.43468 0.17849 -0.48101 0.026114 0.057368 0.26052 -0.030488 0.051275 -0.36344 0.11878 0.2279 -0.086855 -0.01455 0.070256 -0.16753 0.61449 -0.27428 -0.17901 -0.36261 0.093134 -1.5724 0.47192 -0.52493 -0.27512 -0.37945 0.29588 0.020506 0.08707 0.057053 0.37167 -0.056446 -0.38735 -0.31246 0.028304 -0.058202 0.067263 -0.58761 0.074556 0.49917 0.45134 -0.51433 -0.60996 0.076835 -0.078086
|
| 3 |
+
haze -0.0061289 -0.2702 0.16559 -0.29621 -0.66216 -0.1756 0.46686 1.0362 -0.20692 -0.36097 0.98615 0.32297 -0.55094 -0.36163 -0.27046 0.052225 -0.10079 0.22536 -0.095491 0.17188 0.058372 0.083556 -0.28255 0.12623 -0.0094164 -0.028727 -0.20589 -0.3932 -0.2935 -0.36104 1.0595 0.14423 -0.311 -0.20573 0.11827 -0.0048368 -0.8324 -0.10389 0.34491 0.34006 0.10354 0.11593 0.47379 -0.1042 0.38523 -0.57589 0.027253 -0.44913 -0.52822 -0.44094 0.71219 -0.12278 0.034288 -0.6935 -0.57852 0.33917 0.35018 -0.30193 0.55504 0.085603 -0.21189 -0.51958 -0.17589 -0.13369 0.2976 -0.26048 0.068146 0.62144 0.3416 -0.54399 -0.23937 -0.34802 -0.31469 -0.59554 -0.25011 -0.11644 0.19993 -0.1636 0.24289 -0.0022965 0.3064 -0.26188 0.27166 0.1962 0.37527 -0.22408 0.52979 0.59141 0.035196 0.10632 -0.28318 0.18766 -0.12253 0.41932 -0.64713 0.26068 0.67209 -0.23333 0.030945 -0.15135 0.61662 -0.0025061 -0.58374 0.51866 -0.89244 1.0056 0.15919 0.29183 -0.059984 0.10701 -0.32101 -1.0921 -0.050394 -0.074584 0.56258 -0.5915 0.048547 0.085668 -0.39964 -0.40997 0.093632 -0.22538 -0.83102 -0.051418 -0.31192 0.36056 -0.028854 -0.046907 0.09394 0.012504 0.34555 0.56564 0.48111 0.092143 0.82492 -0.20086 -0.27718 0.9004 0.38921 0.028667 0.78904 0.44698 -0.26892 0.073712 -0.73296 -0.46286 0.53386 0.53514 0.04207 -0.11448 0.27771 0.080703 -0.017482 0.43225 0.047742 -0.095399 -0.063173 -0.36341 0.2948 0.15311 -0.55934 -0.88294 0.62005 -0.23936 0.51953 -0.49463 0.41669 0.61169 -0.20471 -0.0056962 -0.29331 0.46269 0.084808 -0.049355 -0.64697 -0.85777 0.34718 -0.16176 0.14756 -0.65658 -0.54259 -0.13124 -0.88851 0.070637 -0.84926 -0.69345 0.4024 -0.5683 -0.68142 -0.1402 -0.36857 0.36013 -0.49769 -0.17478 0.77214 -0.23962 0.32951 1.0984 -0.00011441 0.9649 -0.13312 0.64326 -0.037091 0.35672 0.025156 0.046782 0.19764 -0.22757 -0.39887 -0.3045 -0.45283 -0.0045182 0.032546 -0.076483 0.72189 -0.038917 1.0621 -0.55688 0.56429 0.11264 0.40465 -0.53146 0.16851 0.69236 -0.24456 0.038704 0.69151 0.16591 -0.43451 0.14115 0.84069 0.29081 -0.31053 -0.6849 -0.27188 -0.32813 0.57882 0.13779 0.36621 -0.45935 0.27899 -0.32315 -0.5743 0.19837 0.0046648 0.18459 0.43369 0.22359 0.16652 -0.081114 -0.54539 -1.0103 -0.14539 0.12021 0.078636 -0.26667 -0.65403 0.4096 0.07257 0.036639 0.21757 0.25738 0.51675 -0.031326 -0.3869 0.012763 -0.45692 0.13828 -0.48614 -0.53757 0.50268 0.47865 -0.049528 -0.032281 -0.4486 0.036258 -0.12295 -0.46811 -0.019014 0.035839 -0.55749 0.018281 -0.88963 -0.024676 -0.19482 -0.19364 0.0069875 0.12679 -0.37379 -0.34094 -0.051568 0.55404 -0.29656 0.26045 0.50872 -0.37399 0.20334 0.70298 -0.3271 -0.24116
|
| 4 |
+
rain -0.52618 -0.54041 -0.89537 -0.35598 -0.74356 -0.66838 0.26326 0.89254 0.14362 -0.34904 0.25866 -0.11143 -0.52035 0.1436 -0.075728 -0.84569 -0.28762 0.049872 0.39234 0.52551 -0.39244 -0.2822 -0.097458 -0.12929 -0.38623 0.17261 0.7574 -0.29868 -0.691 -0.36639 0.63951 0.25255 -0.22299 0.16387 -0.83199 -0.30276 -0.32411 -0.36789 -0.073673 0.54726 0.14785 0.26259 0.086208 -0.033827 0.044403 -0.2135 0.3761 0.33816 -0.36696 -0.2096 0.025934 0.47679 0.23046 -0.44333 -0.65379 0.85762 0.62861 -0.70343 1.1284 0.2497 -0.34459 0.17005 0.27826 0.01167 -0.44087 -0.12649 0.31811 0.073688 -0.17127 -0.023486 0.34294 0.18888 -0.15694 -0.37975 -0.58313 -0.45624 -0.5968 0.09743 -0.50593 -0.64092 0.083647 0.38474 -0.15071 0.55042 -0.68742 0.14893 -0.039046 -0.19582 0.61498 -0.066786 0.63395 -0.4659 0.44123 -0.55136 -0.17711 0.97118 0.26321 -0.035901 -0.11096 -0.11161 0.353 1.026 -0.2605 -0.12231 0.31695 0.35807 0.2526 0.21803 -0.47766 -0.13033 -0.36929 -0.88388 -0.1249 0.27972 0.017521 0.19048 0.38647 -0.10236 0.26691 -0.66637 -0.66046 -0.48598 -0.5029 0.59602 -0.23975 -0.054244 0.71177 0.097479 0.18964 0.60496 -0.2421 1.261 0.5195 0.12978 0.28374 0.1499 -0.073072 -0.064345 0.041775 0.20712 -0.13972 0.021692 -0.45101 -0.077633 -0.58888 -0.0062811 0.50587 0.63067 -0.096216 -0.45549 -0.10162 -0.74026 -0.45125 0.16204 0.34589 0.2203 0.73482 -0.72055 0.019937 0.50934 -0.045864 -1.0167 0.4202 0.29336 0.057842 0.19622 0.71137 0.44455 -0.11329 -0.23249 0.3283 0.6458 -0.032498 0.58903 0.067438 -0.21519 0.24967 -0.047893 -0.12095 0.20468 -0.010392 -0.10827 0.5248 -0.013868 -0.40703 -0.2761 0.61498 -0.12118 -0.70097 -0.76415 -0.37243 0.3 -0.32852 -0.13877 0.23339 -0.58504 0.54768 -0.090521 0.30928 -0.19777 0.68883 0.043808 -0.012833 0.25696 0.017598 -0.11323 -0.76201 0.42972 -0.22032 -0.43818 -0.57085 0.23867 -0.098037 -0.4015 0.27659 -0.51578 -0.28637 -0.37785 0.83469 0.10563 1.1508 -0.67165 0.095388 -0.070545 0.039198 0.17726 0.44885 -0.045378 0.22337 -0.24957 0.93144 -0.16601 -0.095582 -0.60227 0.20068 -0.10264 -0.62696 0.048702 0.34737 -0.10634 -0.35068 0.11719 -0.79712 -0.32956 -0.60446 -0.0049038 -0.3351 -0.060065 -0.3063 -0.15462 -0.099521 -0.1788 0.098109 -0.59477 0.53245 -0.15388 0.063044 -0.47686 0.26712 -0.064799 0.2029 -0.093498 -0.44456 0.4692 -0.13718 0.035772 -0.74958 -0.51603 0.47025 -0.65103 0.027106 0.31463 -0.51519 -0.09912 -0.30605 0.2127 -1.6502 -0.34658 -0.19282 0.036578 -0.33871 0.21323 0.54172 -0.17543 -0.60187 -0.14679 0.20983 -0.084584 0.070885 -0.21752 -0.12642 0.030381 0.075461 0.86541 0.30098 0.22916 0.049217 -0.21204 0.32909 -0.021816
|
| 5 |
+
snow -0.6961 -0.3339 -0.66542 -0.16459 -0.70283 0.053264 0.57508 1.1246 -0.41143 -0.93335 -0.397 -0.13949 -0.21725 0.49383 -0.16481 -0.43673 -0.39998 -0.14702 0.5828 0.73123 -0.16808 0.050093 0.20341 0.093283 -0.18944 -0.0092796 0.0064213 -0.5586 0.079708 0.034177 0.503 -0.084123 -0.15241 0.042398 -0.95865 0.13482 0.10695 0.22212 0.16383 0.081416 -0.61437 0.60299 0.53843 0.33915 -0.060046 -0.12329 0.30417 0.067838 -0.058329 -0.24791 -0.28177 0.32273 -0.12639 -0.40664 -0.42578 0.71366 0.18676 -0.49576 0.56635 0.39411 -0.11876 0.62798 0.50193 -0.38534 -0.32333 -0.29613 -0.1984 0.082042 -0.63666 -0.25177 0.070225 0.23886 -0.35341 -0.30615 -0.7898 -0.014515 -0.096662 0.27064 0.37095 -0.3916 0.15589 0.40176 -0.12316 -0.0069311 -0.17538 0.29317 -0.035662 -0.062503 -0.11821 -0.26708 0.33433 -0.41039 -0.44941 -0.058539 -0.5973 -0.060833 0.014623 0.031391 0.041093 0.21223 0.54304 0.51444 -0.2447 -0.034937 -0.61583 0.24116 0.93612 0.29663 -0.01733 0.39864 -0.399 -0.69927 0.010899 0.044804 0.096444 0.20555 0.37109 0.13219 0.29942 -0.28494 -0.071103 -0.45338 -0.22126 -0.31673 -0.10643 0.040453 -0.15324 0.33191 0.27801 -0.25143 -0.41784 1.1352 0.18709 0.57932 0.14912 0.42731 -0.81353 0.35546 0.10287 -0.10858 0.13692 0.11451 -0.68607 -0.17115 -0.52708 0.28953 0.5147 0.25549 -0.23139 -0.44275 0.42679 -0.41475 0.041182 -0.2664 0.60967 0.03783 0.27371 -0.5267 0.12029 0.5208 0.59519 -1.1315 0.19505 -0.2528 0.34636 0.82065 0.63271 0.091682 0.38433 -0.81108 0.18232 0.19068 -0.13031 0.21336 0.074454 -0.094498 0.47594 -0.31026 -0.11718 0.092891 0.22067 -0.16721 0.71703 0.30143 -0.40609 -0.16231 0.31315 -0.59325 -0.53404 -0.1087 -0.23026 0.36507 0.30648 -0.75576 -0.20767 -0.46966 -0.21035 0.0091924 0.5057 0.45564 0.84145 -0.19412 0.23964 0.85852 0.05229 -0.0011899 -0.29387 0.044187 -0.23886 0.19207 -0.0079459 -0.25773 0.31145 -0.47615 -0.00056431 -0.8941 -0.38667 -0.37907 0.52821 -0.45513 0.53567 0.13216 0.39741 -0.4904 0.24118 -0.11714 0.27007 0.15184 0.42316 -0.39708 0.13827 -0.27638 0.29908 -0.76008 0.061752 -0.4452 -0.5132 0.12124 0.15792 -0.57067 -0.68793 -0.33873 -0.43291 -0.46817 -0.84667 -0.65852 -0.59116 -0.043406 -0.013031 0.11246 -0.35374 0.3923 0.1172 -0.56268 0.83477 -0.34675 0.054568 -0.48494 0.12108 -0.15504 -0.047008 -0.2665 0.024593 0.70123 0.21284 -0.077796 0.050835 0.3865 0.37534 -0.48749 -0.013739 0.57852 -0.90425 -0.0062806 -0.28674 -0.017749 -1.0189 -0.71371 -0.36557 -0.73412 -0.027371 -0.071396 0.64792 -0.057281 -0.2512 0.039567 0.076976 0.34572 0.34606 -0.38323 -0.074011 -0.14153 -0.03109 0.53137 -0.35708 -0.28263 0.098663 0.17693 -0.39297 0.27708
|
utils/utils.py
ADDED
|
@@ -0,0 +1,232 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import os
|
| 4 |
+
from torch.autograd import Variable
|
| 5 |
+
from skimage.metrics import peak_signal_noise_ratio as compare_psnr
|
| 6 |
+
from skimage.metrics import mean_squared_error as compare_mse
|
| 7 |
+
from skimage.metrics import structural_similarity as compare_ssim
|
| 8 |
+
import pandas as pd
|
| 9 |
+
|
| 10 |
+
from model.OneRestore import OneRestore
|
| 11 |
+
from model.Embedder import Embedder
|
| 12 |
+
|
| 13 |
+
def load_embedder_ckpt(device, freeze_model=False, ckpt_name=None,
|
| 14 |
+
combine_type = ['clear', 'low', 'haze', 'rain', 'snow',\
|
| 15 |
+
'low_haze', 'low_rain', 'low_snow', 'haze_rain',\
|
| 16 |
+
'haze_snow', 'low_haze_rain', 'low_haze_snow']):
|
| 17 |
+
if ckpt_name != None:
|
| 18 |
+
if torch.cuda.is_available():
|
| 19 |
+
model_info = torch.load(ckpt_name)
|
| 20 |
+
else:
|
| 21 |
+
model_info = torch.load(ckpt_name, map_location=torch.device('cpu'))
|
| 22 |
+
|
| 23 |
+
print('==> loading existing Embedder model:', ckpt_name)
|
| 24 |
+
model = Embedder(combine_type)
|
| 25 |
+
model.load_state_dict(model_info)
|
| 26 |
+
model.to("cuda" if torch.cuda.is_available() else "cpu")
|
| 27 |
+
|
| 28 |
+
else:
|
| 29 |
+
print('==> Initialize Embedder model.')
|
| 30 |
+
model = Embedder(combine_type)
|
| 31 |
+
model.to("cuda" if torch.cuda.is_available() else "cpu")
|
| 32 |
+
|
| 33 |
+
if freeze_model:
|
| 34 |
+
freeze(model)
|
| 35 |
+
|
| 36 |
+
return model
|
| 37 |
+
|
| 38 |
+
def load_restore_ckpt(device, freeze_model=False, ckpt_name=None):
|
| 39 |
+
if ckpt_name != None:
|
| 40 |
+
if torch.cuda.is_available():
|
| 41 |
+
model_info = torch.load(ckpt_name)
|
| 42 |
+
else:
|
| 43 |
+
model_info = torch.load(ckpt_name, map_location=torch.device('cpu'))
|
| 44 |
+
print('==> loading existing OneRestore model:', ckpt_name)
|
| 45 |
+
model = OneRestore().to("cuda" if torch.cuda.is_available() else "cpu")
|
| 46 |
+
model.load_state_dict(model_info)
|
| 47 |
+
else:
|
| 48 |
+
print('==> Initialize OneRestore model.')
|
| 49 |
+
model = OneRestore().to("cuda" if torch.cuda.is_available() else "cpu")
|
| 50 |
+
model = torch.nn.DataParallel(model).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 51 |
+
|
| 52 |
+
if freeze_model:
|
| 53 |
+
freeze(model)
|
| 54 |
+
total = sum([param.nelement() for param in model.parameters()])
|
| 55 |
+
print("Number of OneRestore parameter: %.2fM" % (total/1e6))
|
| 56 |
+
|
| 57 |
+
return model
|
| 58 |
+
|
| 59 |
+
def load_restore_ckpt_with_optim(device, local_rank=None, freeze_model=False, ckpt_name=None, lr=None):
|
| 60 |
+
if ckpt_name != None:
|
| 61 |
+
if torch.cuda.is_available():
|
| 62 |
+
model_info = torch.load(ckpt_name)
|
| 63 |
+
else:
|
| 64 |
+
model_info = torch.load(ckpt_name, map_location=torch.device('cpu'))
|
| 65 |
+
|
| 66 |
+
print('==> loading existing OneRestore model:', ckpt_name)
|
| 67 |
+
model = OneRestore().to("cuda" if torch.cuda.is_available() else "cpu")
|
| 68 |
+
optimizer = torch.optim.Adam(model.parameters(), lr=lr) if lr != None else None
|
| 69 |
+
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank, find_unused_parameters=True) if local_rank != None else model
|
| 70 |
+
|
| 71 |
+
if local_rank != None:
|
| 72 |
+
model.load_state_dict(model_info['state_dict'])
|
| 73 |
+
else:
|
| 74 |
+
weights_dict = {}
|
| 75 |
+
for k, v in model_info['state_dict'].items():
|
| 76 |
+
new_k = k.replace('module.', '') if 'module' in k else k
|
| 77 |
+
weights_dict[new_k] = v
|
| 78 |
+
model.load_state_dict(weights_dict)
|
| 79 |
+
optimizer = torch.optim.Adam(model.parameters())
|
| 80 |
+
optimizer.load_state_dict(model_info['optimizer'])
|
| 81 |
+
cur_epoch = model_info['epoch']
|
| 82 |
+
else:
|
| 83 |
+
print('==> Initialize OneRestore model.')
|
| 84 |
+
model = OneRestore().to("cuda" if torch.cuda.is_available() else "cpu")
|
| 85 |
+
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
|
| 86 |
+
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank, find_unused_parameters=True) if local_rank != None else torch.nn.DataParallel(model)
|
| 87 |
+
cur_epoch = 0
|
| 88 |
+
|
| 89 |
+
if freeze_model:
|
| 90 |
+
freeze(model)
|
| 91 |
+
total = sum([param.nelement() for param in model.parameters()])
|
| 92 |
+
print("Number of OneRestore parameter: %.2fM" % (total/1e6))
|
| 93 |
+
|
| 94 |
+
return model, optimizer, cur_epoch
|
| 95 |
+
|
| 96 |
+
def load_embedder_ckpt_with_optim(device, args, combine_type = ['clear', 'low', 'haze', 'rain', 'snow',\
|
| 97 |
+
'low_haze', 'low_rain', 'low_snow', 'haze_rain', 'haze_snow', 'low_haze_rain', 'low_haze_snow']):
|
| 98 |
+
print('Init embedder')
|
| 99 |
+
# seed
|
| 100 |
+
if args.seed == -1:
|
| 101 |
+
args.seed = np.random.randint(1, 10000)
|
| 102 |
+
seed = args.seed
|
| 103 |
+
np.random.seed(seed)
|
| 104 |
+
torch.manual_seed(seed)
|
| 105 |
+
print('Training embedder seed:', seed)
|
| 106 |
+
|
| 107 |
+
# embedder model
|
| 108 |
+
embedder = Embedder(combine_type).to("cuda" if torch.cuda.is_available() else "cpu")
|
| 109 |
+
|
| 110 |
+
if args.pre_weight == '':
|
| 111 |
+
optimizer = torch.optim.Adam(embedder.parameters(), lr=args.lr)
|
| 112 |
+
cur_epoch = 1
|
| 113 |
+
else:
|
| 114 |
+
try:
|
| 115 |
+
embedder_info = torch.load(f'{args.check_dir}/{args.pre_weight}')
|
| 116 |
+
if torch.cuda.is_available():
|
| 117 |
+
embedder_info = torch.load(f'{args.check_dir}/{args.pre_weight}')
|
| 118 |
+
else:
|
| 119 |
+
embedder_info = torch.load(f'{args.check_dir}/{args.pre_weight}', map_location=torch.device('cpu'))
|
| 120 |
+
embedder.load_state_dict(embedder_info['state_dict'])
|
| 121 |
+
optimizer = torch.optim.Adam(embedder.parameters(), lr=args.lr)
|
| 122 |
+
optimizer.load_state_dict(embedder_info['optimizer'])
|
| 123 |
+
cur_epoch = embedder_info['epoch'] + 1
|
| 124 |
+
except:
|
| 125 |
+
print('Pre-trained model loading error!')
|
| 126 |
+
return embedder, optimizer, cur_epoch, device
|
| 127 |
+
|
| 128 |
+
def freeze_text_embedder(m):
|
| 129 |
+
"""Freezes module m.
|
| 130 |
+
"""
|
| 131 |
+
m.eval()
|
| 132 |
+
for name, para in m.named_parameters():
|
| 133 |
+
if name == 'embedder.weight' or name == 'mlp.0.weight' or name == 'mlp.0.bias':
|
| 134 |
+
print(name)
|
| 135 |
+
para.requires_grad = False
|
| 136 |
+
para.grad = None
|
| 137 |
+
|
| 138 |
+
class AverageMeter(object):
|
| 139 |
+
"""Computes and stores the average and current value"""
|
| 140 |
+
|
| 141 |
+
def __init__(self):
|
| 142 |
+
self.reset()
|
| 143 |
+
|
| 144 |
+
def reset(self):
|
| 145 |
+
self.val = 0
|
| 146 |
+
self.avg = 0
|
| 147 |
+
self.sum = 0
|
| 148 |
+
self.count = 0
|
| 149 |
+
|
| 150 |
+
def update(self, val, n=1):
|
| 151 |
+
self.val = val
|
| 152 |
+
self.sum += val * n
|
| 153 |
+
self.count += n
|
| 154 |
+
self.avg = self.sum / self.count
|
| 155 |
+
|
| 156 |
+
def data_process(data, args, device):
|
| 157 |
+
combine_type = args.degr_type
|
| 158 |
+
b,n,c,w,h = data.size()
|
| 159 |
+
|
| 160 |
+
pos_data = data[:,0,:,:,:]
|
| 161 |
+
|
| 162 |
+
inp_data = torch.zeros((b,c,w,h))
|
| 163 |
+
inp_class = []
|
| 164 |
+
|
| 165 |
+
neg_data = torch.zeros((b,n-2,c,w,h))
|
| 166 |
+
|
| 167 |
+
index = np.random.randint(1, n, (b))
|
| 168 |
+
for i in range(b):
|
| 169 |
+
k = 0
|
| 170 |
+
for j in range(n):
|
| 171 |
+
if j == 0:
|
| 172 |
+
continue
|
| 173 |
+
elif index[i] == j:
|
| 174 |
+
inp_class.append(combine_type[index[i]])
|
| 175 |
+
inp_data[i, :, :, :] = data[i, index[i], :, :,:]
|
| 176 |
+
else:
|
| 177 |
+
neg_data[i,k,:,:,:] = data[i, j, :, :,:]
|
| 178 |
+
k=k+1
|
| 179 |
+
return pos_data.to("cuda" if torch.cuda.is_available() else "cpu"), [inp_data.to("cuda" if torch.cuda.is_available() else "cpu"), inp_class], neg_data.to("cuda" if torch.cuda.is_available() else "cpu")
|
| 180 |
+
|
| 181 |
+
def print_args(argspar):
|
| 182 |
+
print("\nParameter Print")
|
| 183 |
+
for p, v in zip(argspar.__dict__.keys(), argspar.__dict__.values()):
|
| 184 |
+
print('\t{}: {}'.format(p, v))
|
| 185 |
+
print('\n')
|
| 186 |
+
|
| 187 |
+
def adjust_learning_rate(optimizer, epoch, lr_update_freq):
|
| 188 |
+
if not epoch % lr_update_freq and epoch:
|
| 189 |
+
for param_group in optimizer.param_groups:
|
| 190 |
+
param_group['lr'] = param_group['lr'] /2
|
| 191 |
+
return optimizer
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def tensor_metric(img, imclean, model, data_range=1):
|
| 195 |
+
|
| 196 |
+
img_cpu = img.data.cpu().numpy().astype(np.float32).transpose(0,2,3,1)
|
| 197 |
+
imgclean = imclean.data.cpu().numpy().astype(np.float32).transpose(0,2,3,1)
|
| 198 |
+
|
| 199 |
+
SUM = 0
|
| 200 |
+
for i in range(img_cpu.shape[0]):
|
| 201 |
+
|
| 202 |
+
if model == 'PSNR':
|
| 203 |
+
SUM += compare_psnr(imgclean[i, :, :, :], img_cpu[i, :, :, :],data_range=data_range)
|
| 204 |
+
elif model == 'MSE':
|
| 205 |
+
SUM += compare_mse(imgclean[i, :, :, :], img_cpu[i, :, :, :])
|
| 206 |
+
elif model == 'SSIM':
|
| 207 |
+
SUM += compare_ssim(imgclean[i, :, :, :], img_cpu[i, :, :, :], data_range=data_range, multichannel = True)
|
| 208 |
+
# due to the skimage vision problem, you can replace above line by
|
| 209 |
+
# SUM += compare_ssim(imgclean[i, :, :, :], img_cpu[i, :, :, :], data_range=data_range, channel_axis=-1)
|
| 210 |
+
else:
|
| 211 |
+
print('Model False!')
|
| 212 |
+
|
| 213 |
+
return SUM/img_cpu.shape[0]
|
| 214 |
+
|
| 215 |
+
def save_checkpoint(stateF, checkpoint, epoch, psnr_t1,ssim_t1,psnr_t2,ssim_t2, filename='model.tar'):
|
| 216 |
+
torch.save(stateF, checkpoint + 'OneRestore_model_%d_%.4f_%.4f_%.4f_%.4f.tar'%(epoch,psnr_t1,ssim_t1,psnr_t2,ssim_t2))
|
| 217 |
+
|
| 218 |
+
def load_excel(x):
|
| 219 |
+
data1 = pd.DataFrame(x)
|
| 220 |
+
|
| 221 |
+
writer = pd.ExcelWriter('./mertic_result.xlsx')
|
| 222 |
+
data1.to_excel(writer, 'PSNR-SSIM', float_format='%.5f')
|
| 223 |
+
# writer.save()
|
| 224 |
+
writer.close()
|
| 225 |
+
|
| 226 |
+
def freeze(m):
|
| 227 |
+
"""Freezes module m.
|
| 228 |
+
"""
|
| 229 |
+
m.eval()
|
| 230 |
+
for p in m.parameters():
|
| 231 |
+
p.requires_grad = False
|
| 232 |
+
p.grad = None
|