
Commit
•
c0b77c8
1
Parent(s):
390260f
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: mit
|
| 3 |
+
language:
|
| 4 |
+
- es
|
| 5 |
+
metrics:
|
| 6 |
+
- accuracy
|
| 7 |
+
tags:
|
| 8 |
+
- code
|
| 9 |
+
- nlp
|
| 10 |
+
- custom
|
| 11 |
+
- bilma
|
| 12 |
+
tokenizer:
|
| 13 |
+
- yes
|
| 14 |
+
---
|
| 15 |
+
# BILMA (Bert In Latin aMericA)
|
| 16 |
+
|
| 17 |
+
Bilma is a BERT implementation in tensorflow and trained on the Masked Language Model task under the
|
| 18 |
+
https://sadit.github.io/regional-spanish-models-talk-2022/ datasets. It is a model trained on regionalized
|
| 19 |
+
Spanish short texts from the Twitter (now X) platform.
|
| 20 |
+
|
| 21 |
+
We have pretrained models for the countries of Argentina, Chile, Colombia, Spain, Mexico, United States, Uruguay, and Venezuela.
|
| 22 |
+
|
| 23 |
+
The accuracy of the models trained on the MLM task for different regions are:
|
| 24 |
+
|
| 25 |
+
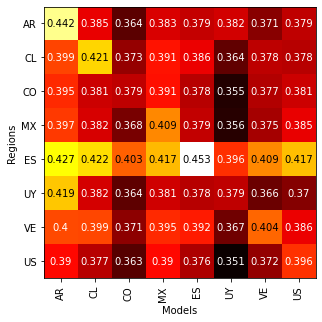
|
| 26 |
+
|
| 27 |
+
# Pre-requisites
|
| 28 |
+
|
| 29 |
+
You will need TensorFlow 2.4 or newer.
|
| 30 |
+
|
| 31 |
+
# Quick guide
|
| 32 |
+
|
| 33 |
+
Install the following version for the transformers library
|
| 34 |
+
```
|
| 35 |
+
!pip install transformers==4.30.2
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
Instanciate the tokenizer and the trained model
|
| 41 |
+
```
|
| 42 |
+
from transformers import AutoTokenizer
|
| 43 |
+
from transformers import TFAutoModel
|
| 44 |
+
|
| 45 |
+
tok = AutoTokenizer.from_pretrained("guillermoruiz/bilma_mx")
|
| 46 |
+
model = TFAutoModel.from_pretrained("guillermoruiz/bilma_mx", trust_remote_code=True)
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
Now,we will need some text and then pass it through the tokenizer:
|
| 50 |
+
```
|
| 51 |
+
text = ["Vamos a comer [MASK].",
|
| 52 |
+
"Hace mucho que no voy al [MASK]."]
|
| 53 |
+
t = tok(text, padding="max_length", return_tensors="tf", max_length=280)
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
With this, we are ready to use the model
|
| 57 |
+
```
|
| 58 |
+
p = model(t)
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
Now, we get the most likely words with:
|
| 62 |
+
```
|
| 63 |
+
import tensorflow as tf
|
| 64 |
+
tok.batch_decode(tf.argmax(p["logits"], 2)[:,1:], skip_special_tokens=True)
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
which produces the output:
|
| 68 |
+
```
|
| 69 |
+
['vamos a comer tacos.', 'hace mucho que no voy al gym.']
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
If you find this model useful for your research, please cite the following paper:
|
| 73 |
+
```
|
| 74 |
+
@misc{tellez2022regionalized,
|
| 75 |
+
title={Regionalized models for Spanish language variations based on Twitter},
|
| 76 |
+
author={Eric S. Tellez and Daniela Moctezuma and Sabino Miranda and Mario Graff and Guillermo Ruiz},
|
| 77 |
+
year={2022},
|
| 78 |
+
eprint={2110.06128},
|
| 79 |
+
archivePrefix={arXiv},
|
| 80 |
+
primaryClass={cs.CL}
|
| 81 |
+
}
|
| 82 |
+
```
|