

metadata
language:
- en
license: cc-by-nc-4.0
datasets:
- grammarly/coedit
- facebook/asset
- jfleg
- zaemyung/IteraTeR_plus
- wi_locness
- GEM/wiki_auto_asset_turk
- discofuse
metrics:
- sari
- bleu
- accuracy
Model Card for CoEdIT-xl
This model was obtained by fine-tuning the corresponding google/flan-t5-xl model on the CoEdIT dataset. Details of the dataset can be found in our paper and repository.
Paper: CoEdIT: Text Editing by Task-Specific Instruction Tuning
Authors: Vipul Raheja, Dhruv Kumar, Ryan Koo, Dongyeop Kang
Model Details
Model Description
- Language(s) (NLP): English
- Finetuned from model:
google/flan-t5-xl
Model Sources
- Repository: https://github.com/vipulraheja/coedit
- Paper: https://arxiv.org/abs/2305.09857
How to use
We make available the models presented in our paper.
| Model | Number of parameters |
|---|---|
| CoEdIT-large | 770M |
| CoEdIT-xl | 3B |
| CoEdIT-xxl | 11B |
Uses
Text Revision Task
Given an edit instruction and an original text, our model can generate the edited version of the text.
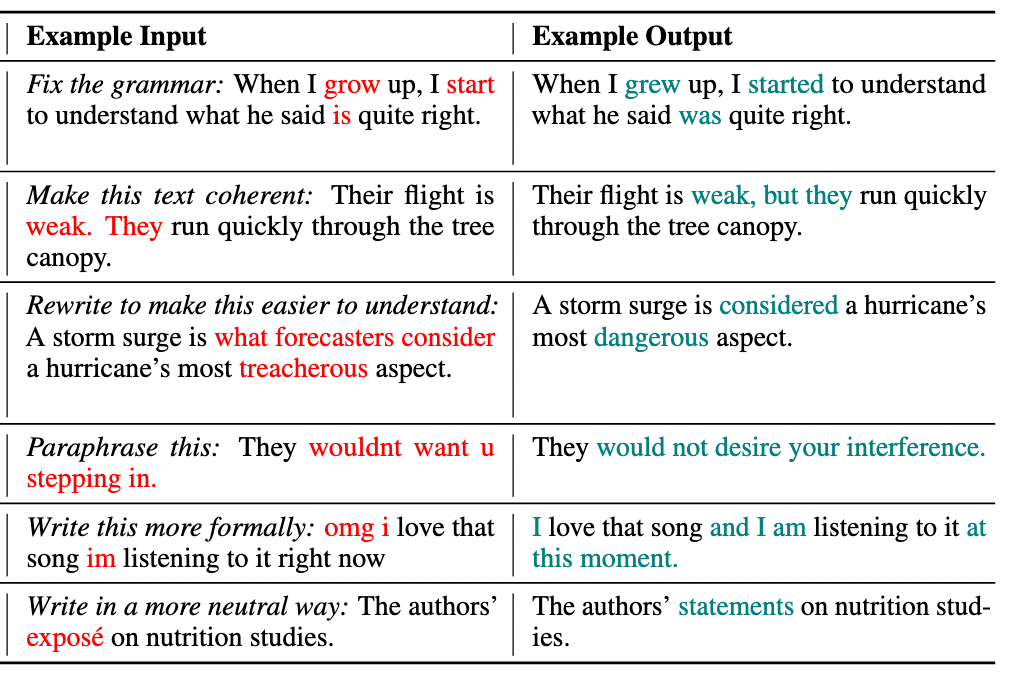
Usage
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("grammarly/coedit-xl")
model = T5ForConditionalGeneration.from_pretrained("grammarly/coedit-xl")
input_text = 'Fix grammatical errors in this sentence: When I grow up, I start to understand what he said is quite right.'
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids, max_length=256)
edited_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
Software
https://github.com/vipulraheja/coedit
Citation
BibTeX:
@article{raheja2023coedit,
title={CoEdIT: Text Editing by Task-Specific Instruction Tuning},
author={Vipul Raheja and Dhruv Kumar and Ryan Koo and Dongyeop Kang},
year={2023},
eprint={2305.09857},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
APA: Raheja, V., Kumar, D., Koo, R., & Kang, D. (2023). CoEdIT: Text Editing by Task-Specific Instruction Tuning. ArXiv. /abs/2305.09857