

language:
- en
- fr
- ro
- de
- multilingual
inference: false
pipeline_tag: visual-question-answering
license: apache-2.0
tags:
- matcha
Model card for MatCha - fine-tuned on Chart2text-pew
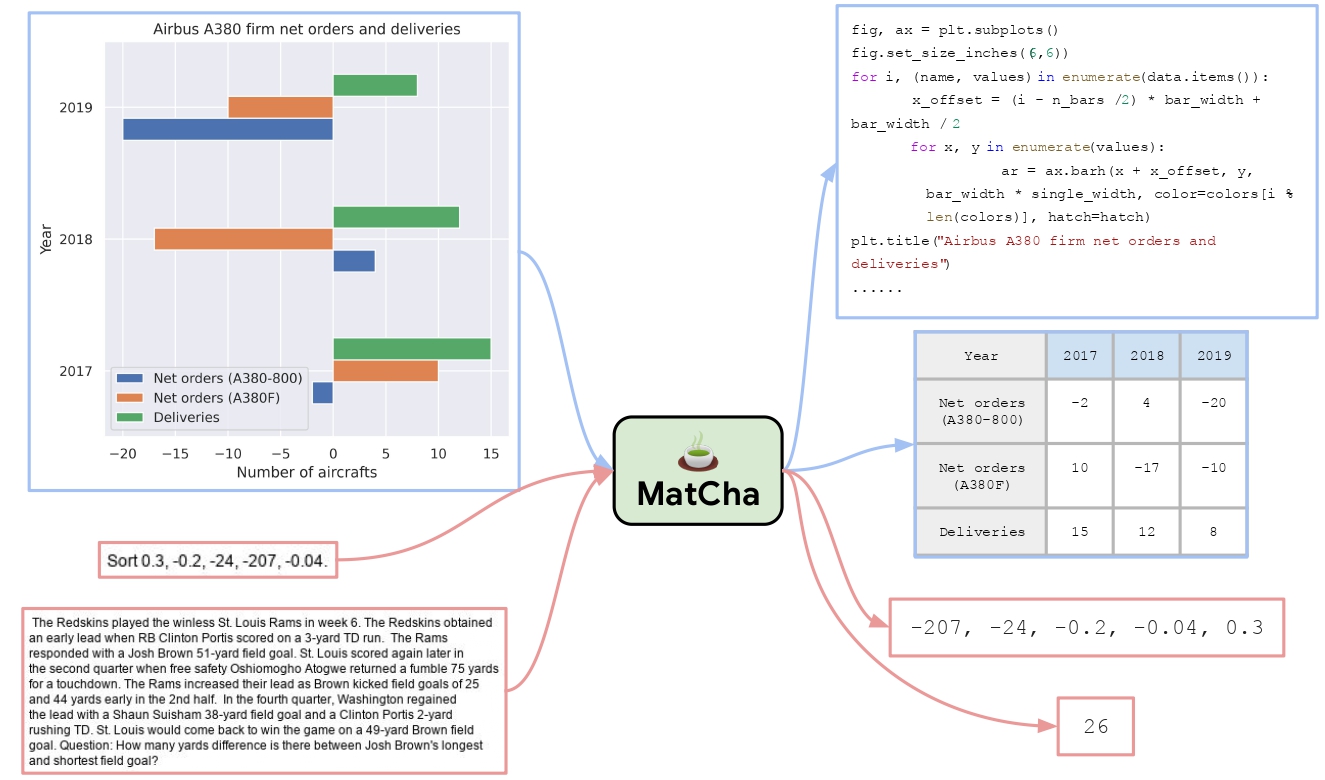
This model is the MatCha model, fine-tuned on Chart2text-pew dataset. This fine-tuned checkpoint might be better suited for chart summarization task.
Table of Contents
TL;DR
The abstract of the paper states that:
Visual language data such as plots, charts, and infographics are ubiquitous in the human world. However, state-of-the-art visionlanguage models do not perform well on these data. We propose MATCHA (Math reasoning and Chart derendering pretraining) to enhance visual language models’ capabilities jointly modeling charts/plots and language data. Specifically we propose several pretraining tasks that cover plot deconstruction and numerical reasoning which are the key capabilities in visual language modeling. We perform the MATCHA pretraining starting from Pix2Struct, a recently proposed imageto-text visual language model. On standard benchmarks such as PlotQA and ChartQA, MATCHA model outperforms state-of-the-art methods by as much as nearly 20%. We also examine how well MATCHA pretraining transfers to domains such as screenshot, textbook diagrams, and document figures and observe overall improvement, verifying the usefulness of MATCHA pretraining on broader visual language tasks.
Using the model
from transformers import Pix2StructProcessor, Pix2StructForConditionalGeneration
import requests
from PIL import Image
processor = Pix2StructProcessor.from_pretrained('google/matcha-chart2text-pew')
model = Pix2StructForConditionalGeneration.from_pretrained('google/matcha-chart2text-pew')
url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
predictions = model.generate(**inputs, max_new_tokens=512)
print(processor.decode(predictions[0], skip_special_tokens=True))
Converting from T5x to huggingface
You can use the convert_pix2struct_checkpoint_to_pytorch.py script as follows:
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --is_vqa
if you are converting a large model, run:
python convert_pix2struct_checkpoint_to_pytorch.py --t5x_checkpoint_path PATH_TO_T5X_CHECKPOINTS --pytorch_dump_path PATH_TO_SAVE --use-large --is_vqa
Once saved, you can push your converted model with the following snippet:
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
model = Pix2StructForConditionalGeneration.from_pretrained(PATH_TO_SAVE)
processor = Pix2StructProcessor.from_pretrained(PATH_TO_SAVE)
model.push_to_hub("USERNAME/MODEL_NAME")
processor.push_to_hub("USERNAME/MODEL_NAME")
Contribution
This model was originally contributed by Fangyu Liu, Francesco Piccinno et al. and added to the Hugging Face ecosystem by Younes Belkada.
Citation
If you want to cite this work, please consider citing the original paper:
@misc{liu2022matcha,
title={MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering},
author={Fangyu Liu and Francesco Piccinno and Syrine Krichene and Chenxi Pang and Kenton Lee and Mandar Joshi and Yasemin Altun and Nigel Collier and Julian Martin Eisenschlos},
year={2022},
eprint={2212.09662},
archivePrefix={arXiv},
primaryClass={cs.CL}
}