

init
Browse files- README.md +94 -0
- config.json +33 -0
- generation_config.json +7 -0
- pytorch_model.bin +3 -0
- resources/img.png +0 -0
- resources/test1.png +0 -0
- resources/test2.png +0 -0
- resources/test3.png +0 -0
- resources/test4.png +0 -0
- resources/test5.png +0 -0
- resources/test6.png +0 -0
- rng_state.pth +3 -0
- scheduler.pt +3 -0
- special_tokens_map.json +6 -0
- tokenizer.json +0 -0
- tokenizer_config.json +11 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
README.md
CHANGED
|
@@ -1,3 +1,97 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- BelleGroup/train_2M_CN
|
| 5 |
+
- BelleGroup/train_3.5M_CN
|
| 6 |
+
- BelleGroup/train_1M_CN
|
| 7 |
+
- BelleGroup/train_0.5M_CN
|
| 8 |
+
- BelleGroup/school_math_0.25M
|
| 9 |
+
language:
|
| 10 |
+
- zh
|
| 11 |
---
|
| 12 |
+
|
| 13 |
+
## GoGPT
|
| 14 |
+
|
| 15 |
+
基于中文指令数据微调BLOOM
|
| 16 |
+

|
| 17 |
+
> 训练第一轮足够了,后续第二轮和第三轮提升不大
|
| 18 |
+
|
| 19 |
+
- ������多样性指令数据
|
| 20 |
+
- ������筛选高质量中文数据
|
| 21 |
+
|
| 22 |
+
| 模型名字 | 参数量 | 模型地址 |
|
| 23 |
+
|------------|--------|------|
|
| 24 |
+
| gogpt-560m | 5.6亿参数 | ������[golaxy/gogpt-560m](https://huggingface.co/golaxy/gogpt-560m) |
|
| 25 |
+
| gogpt-3b | 30亿参数 | ������[golaxy/gogpt-3b](https://huggingface.co/golaxy/gogpt-3b) |
|
| 26 |
+
| gogpt-7b | 70亿参数 | ������[golaxy/gogpt-7b](https://huggingface.co/golaxy/gogpt-7b) |
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
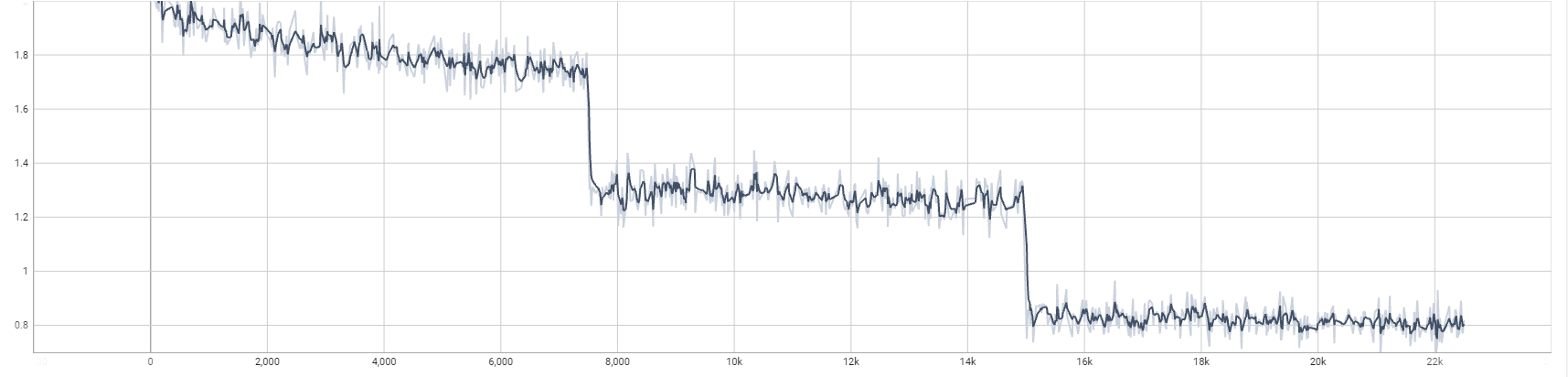
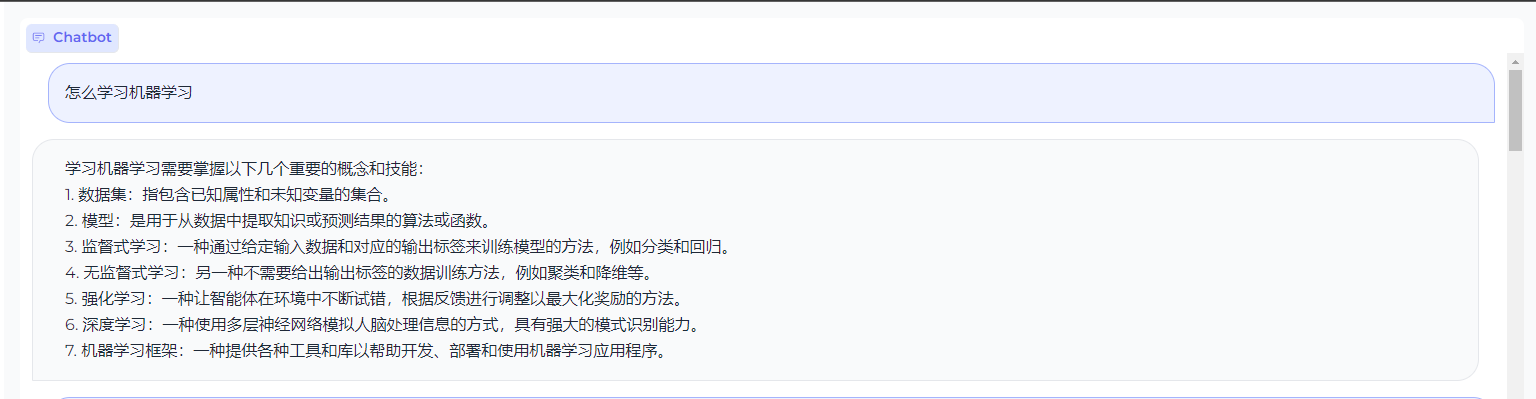
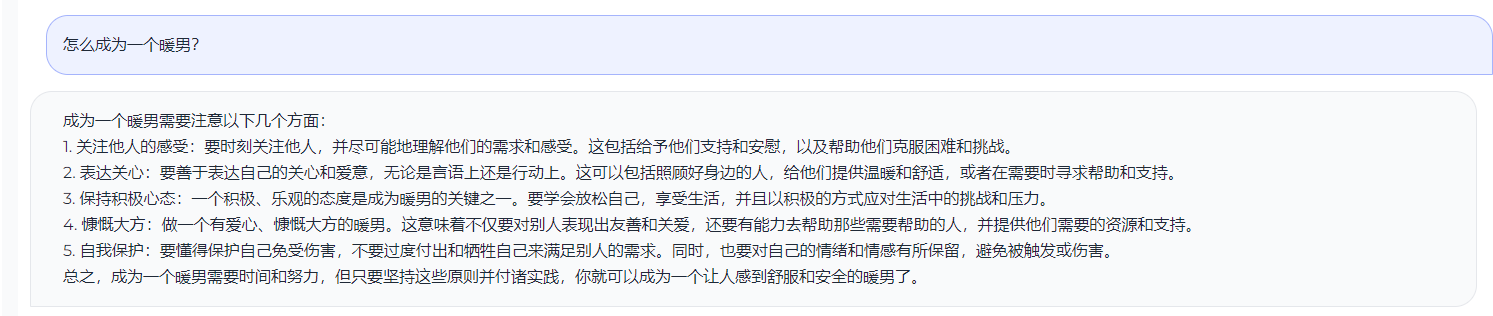
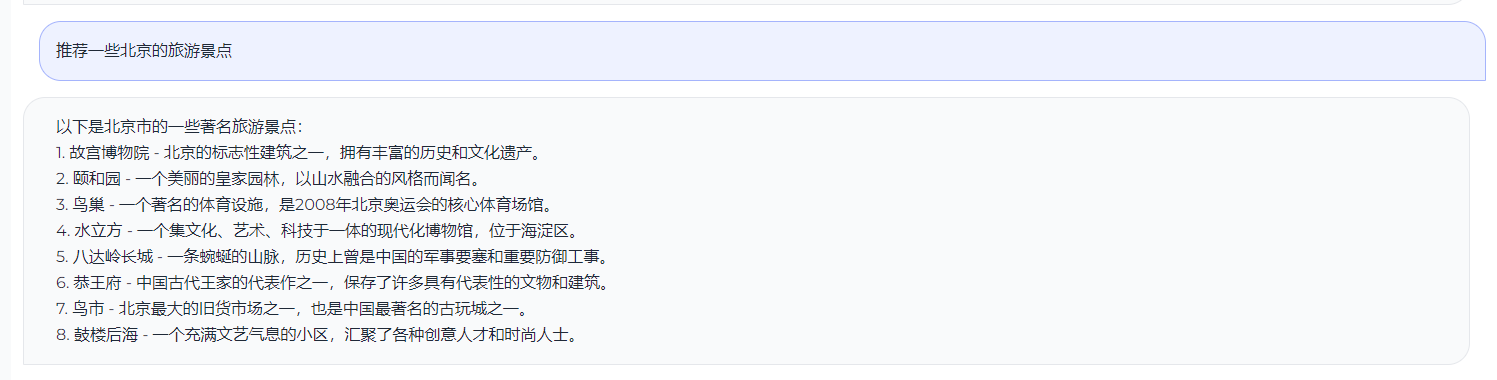
## 测试效果
|
| 30 |
+

|
| 31 |
+

|
| 32 |
+

|
| 33 |
+

|
| 34 |
+

|
| 35 |
+

|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
## TODO
|
| 39 |
+
- 进行RLFH训练
|
| 40 |
+
- 后续加入中英平行语料
|
| 41 |
+
|
| 42 |
+
## 感谢
|
| 43 |
+
|
| 44 |
+
- [@hz大佬-zero_nlp](https://github.com/yuanzhoulvpi2017/zero_nlp)
|
| 45 |
+
- [stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 46 |
+
- [Belle数据](https://huggingface.co/BelleGroup)
|
| 47 |
+
(base) [searchgpt@worker2 output-bloom-7b]$ cat README.md ^C
|
| 48 |
+
(base) [searchgpt@worker2 output-bloom-7b]$ vim README.md
|
| 49 |
+
(base) [searchgpt@worker2 output-bloom-7b]$ cat README.md
|
| 50 |
+
---
|
| 51 |
+
license: apache-2.0
|
| 52 |
+
datasets:
|
| 53 |
+
- BelleGroup/train_2M_CN
|
| 54 |
+
- BelleGroup/train_3.5M_CN
|
| 55 |
+
- BelleGroup/train_1M_CN
|
| 56 |
+
- BelleGroup/train_0.5M_CN
|
| 57 |
+
- BelleGroup/school_math_0.25M
|
| 58 |
+
language:
|
| 59 |
+
- zh
|
| 60 |
+
---
|
| 61 |
+
|
| 62 |
+
## GoGPT
|
| 63 |
+
|
| 64 |
+
基于中文指令数据微调BLOOM
|
| 65 |
+

|
| 66 |
+
> 训练第一轮足够了,后续第二轮和第三轮提升不大
|
| 67 |
+
|
| 68 |
+
- ������多样性指令数据
|
| 69 |
+
- ������筛选高质量中文数据
|
| 70 |
+
|
| 71 |
+
| 模型名字 | 参数量 | 模型地址 |
|
| 72 |
+
|------------|--------|------|
|
| 73 |
+
| gogpt-560m | 5.6亿参数 | ������[golaxy/gogpt-560m](https://huggingface.co/golaxy/gogpt-560m) |
|
| 74 |
+
| gogpt-3b | 30亿参数 | ������[golaxy/gogpt-3b](https://huggingface.co/golaxy/gogpt-3b) |
|
| 75 |
+
| gogpt-7b | 70亿参数 | ������[golaxy/gogpt-7b](https://huggingface.co/golaxy/gogpt-7b) |
|
| 76 |
+
| gogpt-math-560m | 5.6亿参数 | ������[gogpt-math-560m](https://huggingface.co/golaxy/gogpt-math-560m) |
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
## 测试效果
|
| 80 |
+

|
| 81 |
+

|
| 82 |
+

|
| 83 |
+

|
| 84 |
+

|
| 85 |
+

|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
## TODO
|
| 89 |
+
- 进行RLFH训练
|
| 90 |
+
- 后续加入中英平行语料
|
| 91 |
+
|
| 92 |
+
## 感谢
|
| 93 |
+
|
| 94 |
+
- [@hz大佬-zero_nlp](https://github.com/yuanzhoulvpi2017/zero_nlp)
|
| 95 |
+
- [stanford_alpaca](https://github.com/tatsu-lab/stanford_alpaca)
|
| 96 |
+
- [Belle数据](https://huggingface.co/BelleGroup)
|
| 97 |
+
|
config.json
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "/data/searchgpt/pretrained_models/bloomz-560m",
|
| 3 |
+
"apply_residual_connection_post_layernorm": false,
|
| 4 |
+
"architectures": [
|
| 5 |
+
"BloomForCausalLM"
|
| 6 |
+
],
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"attention_softmax_in_fp32": true,
|
| 9 |
+
"bias_dropout_fusion": true,
|
| 10 |
+
"bos_token_id": 1,
|
| 11 |
+
"eos_token_id": 2,
|
| 12 |
+
"hidden_dropout": 0.0,
|
| 13 |
+
"hidden_size": 1024,
|
| 14 |
+
"initializer_range": 0.02,
|
| 15 |
+
"layer_norm_epsilon": 1e-05,
|
| 16 |
+
"masked_softmax_fusion": true,
|
| 17 |
+
"model_type": "bloom",
|
| 18 |
+
"n_head": 16,
|
| 19 |
+
"n_inner": null,
|
| 20 |
+
"n_layer": 24,
|
| 21 |
+
"offset_alibi": 100,
|
| 22 |
+
"pad_token_id": 3,
|
| 23 |
+
"pretraining_tp": 1,
|
| 24 |
+
"seq_length": 2048,
|
| 25 |
+
"skip_bias_add": true,
|
| 26 |
+
"skip_bias_add_qkv": false,
|
| 27 |
+
"slow_but_exact": false,
|
| 28 |
+
"torch_dtype": "float32",
|
| 29 |
+
"transformers_version": "4.29.1",
|
| 30 |
+
"unk_token_id": 0,
|
| 31 |
+
"use_cache": true,
|
| 32 |
+
"vocab_size": 250880
|
| 33 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"pad_token_id": 3,
|
| 6 |
+
"transformers_version": "4.29.1"
|
| 7 |
+
}
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f1f646882932acb3eb72ae258e03a3c941e8eb6c3679c0b9f95fc339387b45fb
|
| 3 |
+
size 2236957537
|
resources/img.png
ADDED
|
resources/test1.png
ADDED
|
resources/test2.png
ADDED

|
resources/test3.png
ADDED
|
resources/test4.png
ADDED
|
resources/test5.png
ADDED
|
resources/test6.png
ADDED
|
rng_state.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1784c9e20ffdc46b706882695c2108245d7626a328b6d70a37d079ad1fbbc989
|
| 3 |
+
size 14575
|
scheduler.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d468864fa846a5ee2b901205ec327d6ad6eba8105d29814689b30d76d72a62f
|
| 3 |
+
size 627
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<s>",
|
| 3 |
+
"eos_token": "</s>",
|
| 4 |
+
"pad_token": "<pad>",
|
| 5 |
+
"unk_token": "<unk>"
|
| 6 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": "<s>",
|
| 4 |
+
"clean_up_tokenization_spaces": false,
|
| 5 |
+
"eos_token": "</s>",
|
| 6 |
+
"model_max_length": 512,
|
| 7 |
+
"pad_token": "<pad>",
|
| 8 |
+
"padding_side": "right",
|
| 9 |
+
"tokenizer_class": "BloomTokenizer",
|
| 10 |
+
"unk_token": "<unk>"
|
| 11 |
+
}
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2788de76ce95a51b55485628e01fd4e98f9304a340bb5729fa9a70ee2821acce
|
| 3 |
+
size 3963
|