
Felix Marty
commited on
Commit
·
97d3676
1
Parent(s):
9e86dfb
add model
Browse files- README.md +27 -0
- config.json +31 -0
- eval_results.json +3 -0
- model.onnx +3 -0
- no_qdq.png +0 -0
- ort_config.json +190 -0
- qdq.png +0 -0
- tokenizer_config.json +1 -0
- vocab.txt +0 -0
README.md
CHANGED
|
@@ -1,3 +1,30 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
datasets:
|
| 4 |
+
- sst2
|
| 5 |
+
- glue
|
| 6 |
---
|
| 7 |
+
This model is a fork of https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english , quantized using static Post-Training Quantization (PTQ) with ONNX Runtime and 🤗 Optimum library.
|
| 8 |
+
|
| 9 |
+
It achieves 0.896 accuracy on the validation set.
|
| 10 |
+
|
| 11 |
+
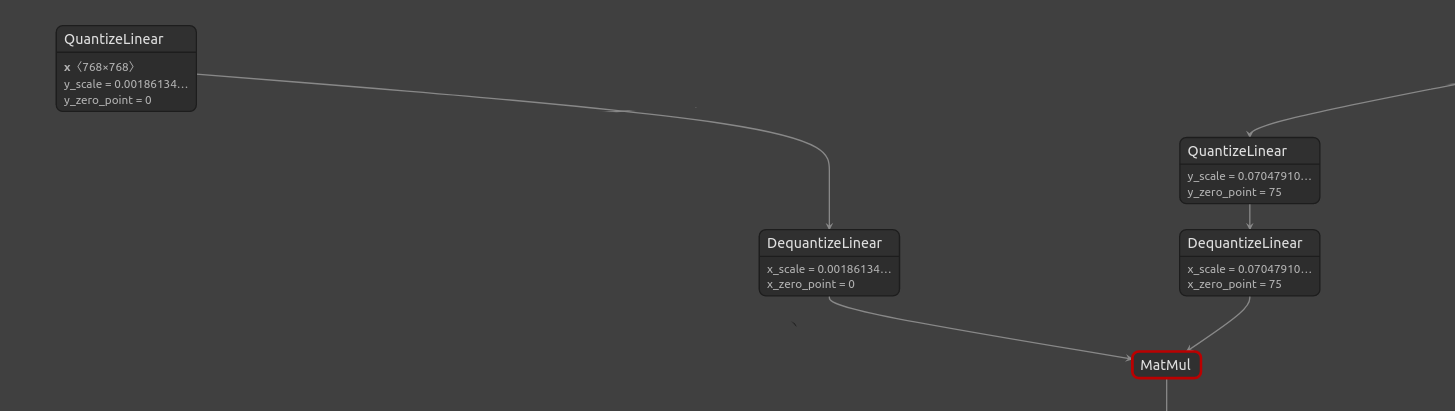
This model uses the ONNX Runtime static quantization configurations `qdq_add_pair_to_weight=True` and `qdq_dedicated_pair=True`, so that **weights are stored in fp32**, and full Quantize + Dequantize nodes are inserted for the weights, compared to the default where weights are stored in int8 and only a Dequantize node is inserted for weights. Moreover, here QDQ pairs have a single output. For more reference, see the documentation: https://github.com/microsoft/onnxruntime/blob/ade0d291749144e1962884a9cfa736d4e1e80ff8/onnxruntime/python/tools/quantization/quantize.py#L432-L441
|
| 12 |
+
|
| 13 |
+
This is useful to later load a static quantized model in TensorRT.
|
| 14 |
+
|
| 15 |
+
To load this model:
|
| 16 |
+
|
| 17 |
+
```python
|
| 18 |
+
from optimum.onnxruntime import ORTModelForSequenceClassification
|
| 19 |
+
model = ORTModelForSequenceClassification.from_pretrained("fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static")
|
| 20 |
+
```
|
| 21 |
+
|
| 22 |
+
<details>
|
| 23 |
+
<summary>Weights stored as int8, only DequantizeLinear nodes (model here: https://huggingface.co/fxmarty/distilbert-base-uncased-finetuned-sst-2-english-int8-static)</summary>
|
| 24 |
+

|
| 25 |
+
</details>
|
| 26 |
+
|
| 27 |
+
<details>
|
| 28 |
+
<summary>Weights stored as fp32, only QuantizeLinear + DequantizeLinear nodes (this model)</summary>
|
| 29 |
+

|
| 30 |
+
</details>
|
config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"activation": "gelu",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"DistilBertForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.1,
|
| 7 |
+
"dim": 768,
|
| 8 |
+
"dropout": 0.1,
|
| 9 |
+
"finetuning_task": "sst-2",
|
| 10 |
+
"hidden_dim": 3072,
|
| 11 |
+
"id2label": {
|
| 12 |
+
"0": "NEGATIVE",
|
| 13 |
+
"1": "POSITIVE"
|
| 14 |
+
},
|
| 15 |
+
"initializer_range": 0.02,
|
| 16 |
+
"label2id": {
|
| 17 |
+
"NEGATIVE": 0,
|
| 18 |
+
"POSITIVE": 1
|
| 19 |
+
},
|
| 20 |
+
"max_position_embeddings": 512,
|
| 21 |
+
"model_type": "distilbert",
|
| 22 |
+
"n_heads": 12,
|
| 23 |
+
"n_layers": 6,
|
| 24 |
+
"output_past": true,
|
| 25 |
+
"pad_token_id": 0,
|
| 26 |
+
"qa_dropout": 0.1,
|
| 27 |
+
"seq_classif_dropout": 0.2,
|
| 28 |
+
"sinusoidal_pos_embds": false,
|
| 29 |
+
"tie_weights_": true,
|
| 30 |
+
"vocab_size": 30522
|
| 31 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"accuracy": 0.8967889908256881
|
| 3 |
+
}
|
model.onnx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c3baf2c754c909076fb4deb57c5f5eae163b147532c09f2efe48f7eb3a0cf98c
|
| 3 |
+
size 267991623
|
no_qdq.png
ADDED

|
ort_config.json
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"opset": null,
|
| 3 |
+
"optimization": {},
|
| 4 |
+
"optimum_version": "1.4.1.dev0",
|
| 5 |
+
"quantization": {
|
| 6 |
+
"activations_dtype": "QInt8",
|
| 7 |
+
"activations_symmetric": false,
|
| 8 |
+
"format": "QDQ",
|
| 9 |
+
"is_static": true,
|
| 10 |
+
"mode": "QLinearOps",
|
| 11 |
+
"nodes_to_exclude": [
|
| 12 |
+
"Sub_471",
|
| 13 |
+
"Add_504",
|
| 14 |
+
"Pow_333",
|
| 15 |
+
"Add_241",
|
| 16 |
+
"Erf_239",
|
| 17 |
+
"Add_418",
|
| 18 |
+
"Mul_479",
|
| 19 |
+
"ReduceMean_310",
|
| 20 |
+
"Div_502",
|
| 21 |
+
"ReduceMean_142",
|
| 22 |
+
"Div_256",
|
| 23 |
+
"Sqrt_255",
|
| 24 |
+
"ReduceMean_498",
|
| 25 |
+
"Mul_162",
|
| 26 |
+
"Add_159",
|
| 27 |
+
"ReduceMean_494",
|
| 28 |
+
"Add_336",
|
| 29 |
+
"Div_396",
|
| 30 |
+
"ReduceMean_388",
|
| 31 |
+
"Erf_321",
|
| 32 |
+
"Sqrt_313",
|
| 33 |
+
"Mul_242",
|
| 34 |
+
"Mul_397",
|
| 35 |
+
"ReduceMean_170",
|
| 36 |
+
"ReduceMean_228",
|
| 37 |
+
"Mul_585",
|
| 38 |
+
"Add_141",
|
| 39 |
+
"ReduceMean_556",
|
| 40 |
+
"Sub_577",
|
| 41 |
+
"Div_338",
|
| 42 |
+
"Add_340",
|
| 43 |
+
"Add_165",
|
| 44 |
+
"Add_94",
|
| 45 |
+
"Add_305",
|
| 46 |
+
"ReduceMean_392",
|
| 47 |
+
"Add_387",
|
| 48 |
+
"Mul_160",
|
| 49 |
+
"Div_156",
|
| 50 |
+
"Div_92",
|
| 51 |
+
"ReduceMean_580",
|
| 52 |
+
"Mul_490",
|
| 53 |
+
"ReduceMean_412",
|
| 54 |
+
"ReduceMean_88",
|
| 55 |
+
"Mul_339",
|
| 56 |
+
"Div_314",
|
| 57 |
+
"Pow_579",
|
| 58 |
+
"Add_586",
|
| 59 |
+
"Mul_324",
|
| 60 |
+
"Pow_555",
|
| 61 |
+
"Div_420",
|
| 62 |
+
"Sub_389",
|
| 63 |
+
"ReduceMean_416",
|
| 64 |
+
"Mul_326",
|
| 65 |
+
"Div_238",
|
| 66 |
+
"Mul_572",
|
| 67 |
+
"ReduceMean_84",
|
| 68 |
+
"Pow_251",
|
| 69 |
+
"Add_558",
|
| 70 |
+
"Sub_331",
|
| 71 |
+
"Sqrt_149",
|
| 72 |
+
"Add_487",
|
| 73 |
+
"Add_398",
|
| 74 |
+
"Sub_143",
|
| 75 |
+
"Add_469",
|
| 76 |
+
"Add_551",
|
| 77 |
+
"Mul_503",
|
| 78 |
+
"Sub_553",
|
| 79 |
+
"Sqrt_231",
|
| 80 |
+
"Mul_175",
|
| 81 |
+
"Pow_169",
|
| 82 |
+
"Pow_473",
|
| 83 |
+
"ReduceMean_474",
|
| 84 |
+
"Sqrt_395",
|
| 85 |
+
"Add_312",
|
| 86 |
+
"Add_422",
|
| 87 |
+
"Erf_485",
|
| 88 |
+
"Sub_495",
|
| 89 |
+
"Add_148",
|
| 90 |
+
"Pow_415",
|
| 91 |
+
"Pow_497",
|
| 92 |
+
"Sub_167",
|
| 93 |
+
"Erf_403",
|
| 94 |
+
"Div_150",
|
| 95 |
+
"Pow_227",
|
| 96 |
+
"Div_174",
|
| 97 |
+
"Sub_413",
|
| 98 |
+
"ReduceMean_252",
|
| 99 |
+
"Add_230",
|
| 100 |
+
"Div_484",
|
| 101 |
+
"Mul_93",
|
| 102 |
+
"Mul_151",
|
| 103 |
+
"Add_394",
|
| 104 |
+
"Add_493",
|
| 105 |
+
"Add_247",
|
| 106 |
+
"Mul_421",
|
| 107 |
+
"Sub_225",
|
| 108 |
+
"Div_560",
|
| 109 |
+
"Sqrt_583",
|
| 110 |
+
"ReduceMean_306",
|
| 111 |
+
"Add_476",
|
| 112 |
+
"Sqrt_419",
|
| 113 |
+
"Sub_85",
|
| 114 |
+
"Mul_406",
|
| 115 |
+
"ReduceMean_166",
|
| 116 |
+
"Mul_570",
|
| 117 |
+
"Mul_315",
|
| 118 |
+
"ReduceMean_576",
|
| 119 |
+
"Pow_145",
|
| 120 |
+
"Mul_408",
|
| 121 |
+
"Add_258",
|
| 122 |
+
"Add_405",
|
| 123 |
+
"Add_575",
|
| 124 |
+
"ReduceMean_470",
|
| 125 |
+
"Mul_561",
|
| 126 |
+
"Pow_87",
|
| 127 |
+
"Add_254",
|
| 128 |
+
"Add_562",
|
| 129 |
+
"Sqrt_559",
|
| 130 |
+
"Pow_309",
|
| 131 |
+
"Add_411",
|
| 132 |
+
"Sqrt_91",
|
| 133 |
+
"Mul_257",
|
| 134 |
+
"Add_500",
|
| 135 |
+
"Add_83",
|
| 136 |
+
"Add_323",
|
| 137 |
+
"Sqrt_337",
|
| 138 |
+
"Div_584",
|
| 139 |
+
"Mul_488",
|
| 140 |
+
"Sqrt_477",
|
| 141 |
+
"ReduceMean_552",
|
| 142 |
+
"Div_320",
|
| 143 |
+
"Add_223",
|
| 144 |
+
"Add_329",
|
| 145 |
+
"Add_176",
|
| 146 |
+
"Add_316",
|
| 147 |
+
"Div_232",
|
| 148 |
+
"Add_480",
|
| 149 |
+
"Mul_244",
|
| 150 |
+
"ReduceMean_146",
|
| 151 |
+
"Add_90",
|
| 152 |
+
"Erf_157",
|
| 153 |
+
"Sub_307",
|
| 154 |
+
"ReduceMean_224",
|
| 155 |
+
"Erf_567",
|
| 156 |
+
"ReduceMean_330",
|
| 157 |
+
"Add_569",
|
| 158 |
+
"Add_582",
|
| 159 |
+
"Mul_233",
|
| 160 |
+
"Sqrt_501",
|
| 161 |
+
"Sqrt_173",
|
| 162 |
+
"ReduceMean_248",
|
| 163 |
+
"Pow_391",
|
| 164 |
+
"Div_402",
|
| 165 |
+
"Sub_249",
|
| 166 |
+
"Add_172",
|
| 167 |
+
"ReduceMean_334",
|
| 168 |
+
"Div_566",
|
| 169 |
+
"Div_478",
|
| 170 |
+
"Add_152",
|
| 171 |
+
"Add_234"
|
| 172 |
+
],
|
| 173 |
+
"nodes_to_quantize": [],
|
| 174 |
+
"operators_to_quantize": [
|
| 175 |
+
"MatMul",
|
| 176 |
+
"Add"
|
| 177 |
+
],
|
| 178 |
+
"per_channel": false,
|
| 179 |
+
"qdq_add_pair_to_weight": true,
|
| 180 |
+
"qdq_dedicated_pair": true,
|
| 181 |
+
"qdq_op_type_per_channel_support_to_axis": {
|
| 182 |
+
"MatMul": 1
|
| 183 |
+
},
|
| 184 |
+
"reduce_range": false,
|
| 185 |
+
"weights_dtype": "QInt8",
|
| 186 |
+
"weights_symmetric": true
|
| 187 |
+
},
|
| 188 |
+
"transformers_version": "4.23.0.dev0",
|
| 189 |
+
"use_external_data_format": false
|
| 190 |
+
}
|
qdq.png
ADDED
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"model_max_length": 512, "do_lower_case": true}
|
vocab.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|