
Upload model from GitHub.
Browse files- .gitattributes +2 -0
- CODEOWNERS +2 -0
- CODE_OF_CONDUCT.md +105 -0
- CodeT5.png +0 -0
- CodeT5_model_card.pdf +0 -0
- LICENSE.txt +12 -0
- README.md +247 -3
- SECURITY.md +7 -0
- _utils.py +306 -0
- codet5.gif +3 -0
- configs.py +137 -0
- evaluator/CodeBLEU/bleu.py +589 -0
- evaluator/CodeBLEU/calc_code_bleu.py +81 -0
- evaluator/CodeBLEU/dataflow_match.py +149 -0
- evaluator/CodeBLEU/keywords/c_sharp.txt +107 -0
- evaluator/CodeBLEU/keywords/java.txt +50 -0
- evaluator/CodeBLEU/parser/DFG.py +1184 -0
- evaluator/CodeBLEU/parser/__init__.py +8 -0
- evaluator/CodeBLEU/parser/build.py +21 -0
- evaluator/CodeBLEU/parser/build.sh +8 -0
- evaluator/CodeBLEU/parser/my-languages.so +3 -0
- evaluator/CodeBLEU/parser/utils.py +108 -0
- evaluator/CodeBLEU/readme.txt +1 -0
- evaluator/CodeBLEU/syntax_match.py +78 -0
- evaluator/CodeBLEU/utils.py +106 -0
- evaluator/CodeBLEU/weighted_ngram_match.py +558 -0
- evaluator/bleu.py +134 -0
- evaluator/smooth_bleu.py +208 -0
- models.py +398 -0
- run_clone.py +325 -0
- run_defect.py +314 -0
- run_gen.py +387 -0
- run_multi_gen.py +535 -0
- sh/exp_with_args.sh +94 -0
- sh/run_exp.py +165 -0
- tokenizer/apply_tokenizer.py +17 -0
- tokenizer/salesforce/codet5-merges.txt +0 -0
- tokenizer/salesforce/codet5-vocab.json +0 -0
- tokenizer/train_tokenizer.py +22 -0
- utils.py +263 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
codet5.gif filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
evaluator/CodeBLEU/parser/my-languages.so filter=lfs diff=lfs merge=lfs -text
|
CODEOWNERS
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Comment line immediately above ownership line is reserved for related gus information. Please be careful while editing.
|
| 2 |
+
#ECCN:Open Source
|
CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Salesforce Open Source Community Code of Conduct
|
| 2 |
+
|
| 3 |
+
## About the Code of Conduct
|
| 4 |
+
|
| 5 |
+
Equality is a core value at Salesforce. We believe a diverse and inclusive
|
| 6 |
+
community fosters innovation and creativity, and are committed to building a
|
| 7 |
+
culture where everyone feels included.
|
| 8 |
+
|
| 9 |
+
Salesforce open-source projects are committed to providing a friendly, safe, and
|
| 10 |
+
welcoming environment for all, regardless of gender identity and expression,
|
| 11 |
+
sexual orientation, disability, physical appearance, body size, ethnicity, nationality,
|
| 12 |
+
race, age, religion, level of experience, education, socioeconomic status, or
|
| 13 |
+
other similar personal characteristics.
|
| 14 |
+
|
| 15 |
+
The goal of this code of conduct is to specify a baseline standard of behavior so
|
| 16 |
+
that people with different social values and communication styles can work
|
| 17 |
+
together effectively, productively, and respectfully in our open source community.
|
| 18 |
+
It also establishes a mechanism for reporting issues and resolving conflicts.
|
| 19 |
+
|
| 20 |
+
All questions and reports of abusive, harassing, or otherwise unacceptable behavior
|
| 21 |
+
in a Salesforce open-source project may be reported by contacting the Salesforce
|
| 22 |
+
Open Source Conduct Committee at ossconduct@salesforce.com.
|
| 23 |
+
|
| 24 |
+
## Our Pledge
|
| 25 |
+
|
| 26 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 27 |
+
contributors and maintainers pledge to making participation in our project and
|
| 28 |
+
our community a harassment-free experience for everyone, regardless of gender
|
| 29 |
+
identity and expression, sexual orientation, disability, physical appearance,
|
| 30 |
+
body size, ethnicity, nationality, race, age, religion, level of experience, education,
|
| 31 |
+
socioeconomic status, or other similar personal characteristics.
|
| 32 |
+
|
| 33 |
+
## Our Standards
|
| 34 |
+
|
| 35 |
+
Examples of behavior that contributes to creating a positive environment
|
| 36 |
+
include:
|
| 37 |
+
|
| 38 |
+
* Using welcoming and inclusive language
|
| 39 |
+
* Being respectful of differing viewpoints and experiences
|
| 40 |
+
* Gracefully accepting constructive criticism
|
| 41 |
+
* Focusing on what is best for the community
|
| 42 |
+
* Showing empathy toward other community members
|
| 43 |
+
|
| 44 |
+
Examples of unacceptable behavior by participants include:
|
| 45 |
+
|
| 46 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 47 |
+
advances
|
| 48 |
+
* Personal attacks, insulting/derogatory comments, or trolling
|
| 49 |
+
* Public or private harassment
|
| 50 |
+
* Publishing, or threatening to publish, others' private information—such as
|
| 51 |
+
a physical or electronic address—without explicit permission
|
| 52 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 53 |
+
professional setting
|
| 54 |
+
* Advocating for or encouraging any of the above behaviors
|
| 55 |
+
|
| 56 |
+
## Our Responsibilities
|
| 57 |
+
|
| 58 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 59 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 60 |
+
response to any instances of unacceptable behavior.
|
| 61 |
+
|
| 62 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 63 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 64 |
+
that are not aligned with this Code of Conduct, or to ban temporarily or
|
| 65 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 66 |
+
threatening, offensive, or harmful.
|
| 67 |
+
|
| 68 |
+
## Scope
|
| 69 |
+
|
| 70 |
+
This Code of Conduct applies both within project spaces and in public spaces
|
| 71 |
+
when an individual is representing the project or its community. Examples of
|
| 72 |
+
representing a project or community include using an official project email
|
| 73 |
+
address, posting via an official social media account, or acting as an appointed
|
| 74 |
+
representative at an online or offline event. Representation of a project may be
|
| 75 |
+
further defined and clarified by project maintainers.
|
| 76 |
+
|
| 77 |
+
## Enforcement
|
| 78 |
+
|
| 79 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 80 |
+
reported by contacting the Salesforce Open Source Conduct Committee
|
| 81 |
+
at ossconduct@salesforce.com. All complaints will be reviewed and investigated
|
| 82 |
+
and will result in a response that is deemed necessary and appropriate to the
|
| 83 |
+
circumstances. The committee is obligated to maintain confidentiality with
|
| 84 |
+
regard to the reporter of an incident. Further details of specific enforcement
|
| 85 |
+
policies may be posted separately.
|
| 86 |
+
|
| 87 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 88 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 89 |
+
members of the project's leadership and the Salesforce Open Source Conduct
|
| 90 |
+
Committee.
|
| 91 |
+
|
| 92 |
+
## Attribution
|
| 93 |
+
|
| 94 |
+
This Code of Conduct is adapted from the [Contributor Covenant][contributor-covenant-home],
|
| 95 |
+
version 1.4, available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html.
|
| 96 |
+
It includes adaptions and additions from [Go Community Code of Conduct][golang-coc],
|
| 97 |
+
[CNCF Code of Conduct][cncf-coc], and [Microsoft Open Source Code of Conduct][microsoft-coc].
|
| 98 |
+
|
| 99 |
+
This Code of Conduct is licensed under the [Creative Commons Attribution 3.0 License][cc-by-3-us].
|
| 100 |
+
|
| 101 |
+
[contributor-covenant-home]: https://www.contributor-covenant.org (https://www.contributor-covenant.org/)
|
| 102 |
+
[golang-coc]: https://golang.org/conduct
|
| 103 |
+
[cncf-coc]: https://github.com/cncf/foundation/blob/master/code-of-conduct.md
|
| 104 |
+
[microsoft-coc]: https://opensource.microsoft.com/codeofconduct/
|
| 105 |
+
[cc-by-3-us]: https://creativecommons.org/licenses/by/3.0/us/
|
CodeT5.png
ADDED
|
CodeT5_model_card.pdf
ADDED
|
Binary file (114 kB). View file
|
|
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2021, Salesforce.com, Inc.
|
| 2 |
+
All rights reserved.
|
| 3 |
+
|
| 4 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 5 |
+
|
| 6 |
+
* Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 7 |
+
|
| 8 |
+
* Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 9 |
+
|
| 10 |
+
* Neither the name of Salesforce.com nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 11 |
+
|
| 12 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
README.md
CHANGED
|
@@ -1,3 +1,247 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation
|
| 2 |
+
|
| 3 |
+
This is the official PyTorch implementation for the following EMNLP 2021 paper from Salesforce Research:
|
| 4 |
+
|
| 5 |
+
**Title**: [CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation](https://arxiv.org/pdf/2109.00859.pdf)
|
| 6 |
+
|
| 7 |
+
**Authors**: [Yue Wang](https://yuewang-cuhk.github.io/), [Weishi Wang](https://www.linkedin.com/in/weishi-wang/)
|
| 8 |
+
, [Shafiq Joty](https://raihanjoty.github.io/), and [Steven C.H. Hoi](https://sites.google.com/view/stevenhoi/home)
|
| 9 |
+
|
| 10 |
+

|
| 11 |
+
|
| 12 |
+
## Updates
|
| 13 |
+
|
| 14 |
+
**July 06, 2022**
|
| 15 |
+
|
| 16 |
+
We release two large-sized CodeT5 checkpoints at Hugging Face: [Salesforce/codet5-large](https://huggingface.co/Salesforce/codet5-large) and [Salesforce/codet5-large-ntp-py](https://huggingface.co/Salesforce/codet5-large-ntp-py), which are introduced by the paper: [CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning](https://arxiv.org/pdf/2207.01780.pdf) by Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, Steven C.H. Hoi.
|
| 17 |
+
|
| 18 |
+
* CodeT5-large was pretrained using Masked Span Prediction (MSP) objective on CodeSearchNet and achieve new SOTA results on several CodeXGLUE benchmarks. The finetuned checkpoints are released at [here](https://console.cloud.google.com/storage/browser/sfr-codet5-data-research/finetuned_models). See Appendix A.1 of the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
|
| 19 |
+
|
| 20 |
+
* CodeT5-large-ntp-py was first pretrained using Masked Span Prediction (MSP) objective on CodeSearchNet and GCPY (the Python split of [Github Code](https://huggingface.co/datasets/codeparrot/github-code) data), followed by another 10 epochs on GCPY using Next Token Prediction (NTP) objective.
|
| 21 |
+
|
| 22 |
+
CodeT5-large-ntp-py is especially optimized for Python code generation tasks and employed as the foundation model for our [CodeRL](https://github.com/salesforce/CodeRL), yielding new SOTA results on the APPS Python competition-level program synthesis benchmark. See the [paper](https://arxiv.org/pdf/2207.01780.pdf) for more details.
|
| 23 |
+
|
| 24 |
+
**Oct 29, 2021**
|
| 25 |
+
|
| 26 |
+
We release [fine-tuned checkpoints](https://console.cloud.google.com/storage/browser/sfr-codet5-data-research/finetuned_models)
|
| 27 |
+
for all the downstream tasks covered in the paper.
|
| 28 |
+
|
| 29 |
+
**Oct 25, 2021**
|
| 30 |
+
|
| 31 |
+
We release a CodeT5-base fine-tuned
|
| 32 |
+
checkpoint ([Salesforce/codet5-base-multi-sum](https://huggingface.co/Salesforce/codet5-base-multi-sum)) for
|
| 33 |
+
multilingual code summarzation. Below is how to use this model:
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
from transformers import RobertaTokenizer, T5ForConditionalGeneration
|
| 37 |
+
|
| 38 |
+
if __name__ == '__main__':
|
| 39 |
+
tokenizer = RobertaTokenizer.from_pretrained('Salesforce/codet5-base')
|
| 40 |
+
model = T5ForConditionalGeneration.from_pretrained('Salesforce/codet5-base-multi-sum')
|
| 41 |
+
|
| 42 |
+
text = """def svg_to_image(string, size=None):
|
| 43 |
+
if isinstance(string, unicode):
|
| 44 |
+
string = string.encode('utf-8')
|
| 45 |
+
renderer = QtSvg.QSvgRenderer(QtCore.QByteArray(string))
|
| 46 |
+
if not renderer.isValid():
|
| 47 |
+
raise ValueError('Invalid SVG data.')
|
| 48 |
+
if size is None:
|
| 49 |
+
size = renderer.defaultSize()
|
| 50 |
+
image = QtGui.QImage(size, QtGui.QImage.Format_ARGB32)
|
| 51 |
+
painter = QtGui.QPainter(image)
|
| 52 |
+
renderer.render(painter)
|
| 53 |
+
return image"""
|
| 54 |
+
|
| 55 |
+
input_ids = tokenizer(text, return_tensors="pt").input_ids
|
| 56 |
+
|
| 57 |
+
generated_ids = model.generate(input_ids, max_length=20)
|
| 58 |
+
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
|
| 59 |
+
# this prints: "Convert a SVG string to a QImage."
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
**Oct 18, 2021**
|
| 63 |
+
|
| 64 |
+
We add a [model card](https://github.com/salesforce/CodeT5/blob/main/CodeT5_model_card.pdf) for CodeT5! Please reach out
|
| 65 |
+
if you have any questions about it.
|
| 66 |
+
|
| 67 |
+
**Sep 24, 2021**
|
| 68 |
+
|
| 69 |
+
CodeT5 is now in [hugginface](https://huggingface.co/)!
|
| 70 |
+
|
| 71 |
+
You can simply load the model ([CodeT5-small](https://huggingface.co/Salesforce/codet5-small)
|
| 72 |
+
and [CodeT5-base](https://huggingface.co/Salesforce/codet5-base)) and do the inference:
|
| 73 |
+
|
| 74 |
+
```python
|
| 75 |
+
from transformers import RobertaTokenizer, T5ForConditionalGeneration
|
| 76 |
+
|
| 77 |
+
tokenizer = RobertaTokenizer.from_pretrained('Salesforce/codet5-base')
|
| 78 |
+
model = T5ForConditionalGeneration.from_pretrained('Salesforce/codet5-base')
|
| 79 |
+
|
| 80 |
+
text = "def greet(user): print(f'hello <extra_id_0>!')"
|
| 81 |
+
input_ids = tokenizer(text, return_tensors="pt").input_ids
|
| 82 |
+
|
| 83 |
+
# simply generate one code span
|
| 84 |
+
generated_ids = model.generate(input_ids, max_length=8)
|
| 85 |
+
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
|
| 86 |
+
# this prints "{user.username}"
|
| 87 |
+
```
|
| 88 |
+
|
| 89 |
+
## Introduction
|
| 90 |
+
|
| 91 |
+
This repo provides the code for reproducing the experiments
|
| 92 |
+
in [CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation](https://arxiv.org/pdf/2109.00859.pdf)
|
| 93 |
+
. CodeT5 is a new pre-trained encoder-decoder model for programming languages, which is pre-trained on **8.35M**
|
| 94 |
+
functions in 8 programming languages (Python, Java, JavaScript, PHP, Ruby, Go, C, and C#). In total, it achieves
|
| 95 |
+
state-of-the-art results on **14 sub-tasks** in a code intelligence benchmark - [CodeXGLUE](https://github.com/microsoft/CodeXGLUE).
|
| 96 |
+
|
| 97 |
+
Paper link: https://arxiv.org/abs/2109.00859
|
| 98 |
+
|
| 99 |
+
Blog link: https://blog.salesforceairesearch.com/codet5/
|
| 100 |
+
|
| 101 |
+
The code currently includes two pre-trained checkpoints ([CodeT5-small](https://huggingface.co/Salesforce/codet5-small)
|
| 102 |
+
and [CodeT5-base](https://huggingface.co/Salesforce/codet5-base)) and scripts to fine-tune them on 4 generation tasks (
|
| 103 |
+
code summarization, code generation, translation, and refinement) plus 2 understanding tasks (code defect detection and
|
| 104 |
+
clone detection) in CodeXGLUE. We also provide their fine-tuned checkpoints to facilitate the easy replication
|
| 105 |
+
of our paper.
|
| 106 |
+
|
| 107 |
+
In practice, CodeT5 can be deployed as an AI-powered coding assistant to boost the productivity of software developers.
|
| 108 |
+
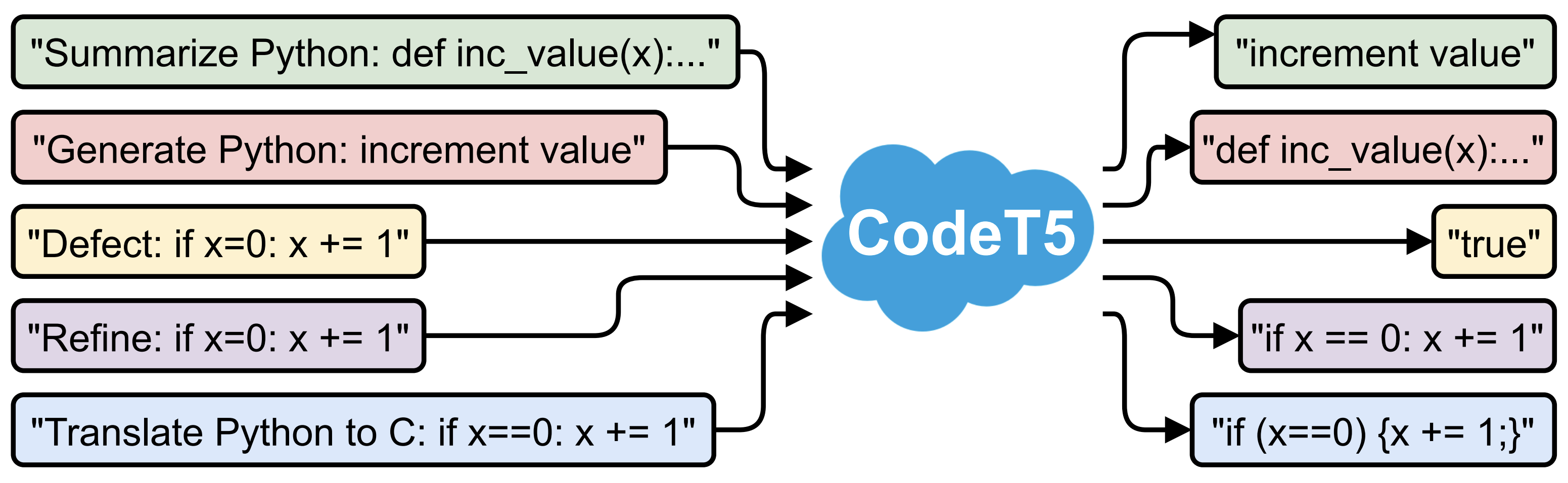
At Salesforce, we build an [AI coding assistant demo](https://github.com/salesforce/CodeT5/raw/main/codet5.gif) using
|
| 109 |
+
CodeT5 as a VS Code plugin to provide three capabilities for Apex developers:
|
| 110 |
+
|
| 111 |
+
- **Text-to-code generation**: generate code based on the natural language description.
|
| 112 |
+
- **Code autocompletion**: complete the whole function of code given the target function name.
|
| 113 |
+
- **Code summarization**: generate the summary of a function in natural language description.
|
| 114 |
+
|
| 115 |
+
## Table of Contents
|
| 116 |
+
|
| 117 |
+
1. [Citation](#citation)
|
| 118 |
+
2. [License](#license)
|
| 119 |
+
3. [Dependency](#dependency)
|
| 120 |
+
4. [Download](#download)
|
| 121 |
+
5. [Fine-tuning](#fine-tuning)
|
| 122 |
+
6. [Get Involved](#get-involved)
|
| 123 |
+
|
| 124 |
+
## Citation
|
| 125 |
+
|
| 126 |
+
If you find this code to be useful for your research, please consider citing:
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
@inproceedings{
|
| 130 |
+
wang2021codet5,
|
| 131 |
+
title={CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation},
|
| 132 |
+
author={Yue Wang, Weishi Wang, Shafiq Joty, Steven C.H. Hoi},
|
| 133 |
+
booktitle={Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021},
|
| 134 |
+
year={2021},
|
| 135 |
+
}
|
| 136 |
+
|
| 137 |
+
@article{coderl2022,
|
| 138 |
+
title={CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning},
|
| 139 |
+
author={Le, Hung and Wang, Yue and Gotmare, Akhilesh Deepak and Savarese, Silvio and Hoi, Steven C. H.},
|
| 140 |
+
journal={arXiv preprint arXiv:2207.01780},
|
| 141 |
+
year={2022}
|
| 142 |
+
}
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
## License
|
| 146 |
+
|
| 147 |
+
The code is released under the BSD-3 License (see `LICENSE.txt` for details), but we also ask that users respect the
|
| 148 |
+
following:
|
| 149 |
+
|
| 150 |
+
This software should not be used to promote or profit from:
|
| 151 |
+
|
| 152 |
+
violence, hate, and division,
|
| 153 |
+
|
| 154 |
+
environmental destruction,
|
| 155 |
+
|
| 156 |
+
abuse of human rights, or
|
| 157 |
+
|
| 158 |
+
the destruction of people's physical and mental health.
|
| 159 |
+
|
| 160 |
+
We encourage users of this software to tell us about the applications in which they are putting it to use by emailing
|
| 161 |
+
codeT5@salesforce.com, and to
|
| 162 |
+
use [appropriate](https://arxiv.org/abs/1810.03993) [documentation](https://www.partnershiponai.org/about-ml/) when
|
| 163 |
+
developing high-stakes applications of this model.
|
| 164 |
+
|
| 165 |
+
## Dependency
|
| 166 |
+
|
| 167 |
+
- Pytorch 1.7.1
|
| 168 |
+
- tensorboard 2.4.1
|
| 169 |
+
- transformers 4.6.1
|
| 170 |
+
- tree-sitter 0.2.2
|
| 171 |
+
|
| 172 |
+
## Download
|
| 173 |
+
|
| 174 |
+
* [Pre-trained checkpoints](https://console.cloud.google.com/storage/browser/sfr-codet5-data-research/pretrained_models)
|
| 175 |
+
* [Fine-tuning data](https://console.cloud.google.com/storage/browser/sfr-codet5-data-research/data)
|
| 176 |
+
* [Fine-tuned checkpoints](https://console.cloud.google.com/storage/browser/sfr-codet5-data-research/finetuned_models)
|
| 177 |
+
|
| 178 |
+
Instructions to download:
|
| 179 |
+
|
| 180 |
+
```
|
| 181 |
+
# pip install gsutil
|
| 182 |
+
cd your-cloned-codet5-path
|
| 183 |
+
|
| 184 |
+
gsutil -m cp -r "gs://sfr-codet5-data-research/pretrained_models" .
|
| 185 |
+
gsutil -m cp -r "gs://sfr-codet5-data-research/data" .
|
| 186 |
+
gsutil -m cp -r "gs://sfr-codet5-data-research/finetuned_models" .
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
## Fine-tuning
|
| 190 |
+
|
| 191 |
+
Go to `sh` folder, set the `WORKDIR` in `exp_with_args.sh` to be your cloned CodeT5 repository path.
|
| 192 |
+
|
| 193 |
+
You can use `run_exp.py` to run a broad set of experiments by simply passing the `model_tag`, `task`, and `sub_task`
|
| 194 |
+
arguments. In total, we support five models (i.e., ['roberta', 'codebert', 'bart_base', 'codet5_small', 'codet5_base'])
|
| 195 |
+
and six tasks (i.e., ['summarize', 'concode', 'translate', 'refine', 'defect', 'clone']). For each task, we use
|
| 196 |
+
the `sub_task` to specify which specific datasets to fine-tne on. Below is the full list:
|
| 197 |
+
|
| 198 |
+
| \--task | \--sub\_task | Description |
|
| 199 |
+
| --------- | ---------------------------------- | -------------------------------------------------------------------------------------------------------------------------------- |
|
| 200 |
+
| summarize | ruby/javascript/go/python/java/php | code summarization task on [CodeSearchNet](https://arxiv.org/abs/1909.09436) data with six PLs |
|
| 201 |
+
| concode | none | text-to-code generation on [Concode](https://aclanthology.org/D18-1192.pdf) data |
|
| 202 |
+
| translate | java-cs/cs-java | code-to-code translation between [Java and C#](https://arxiv.org/pdf/2102.04664.pdf) |
|
| 203 |
+
| refine | small/medium | code refinement on [code repair data](https://arxiv.org/pdf/1812.08693.pdf) with small/medium functions |
|
| 204 |
+
| defect | none | code defect detection in [C/C++ data](https://proceedings.neurips.cc/paper/2019/file/49265d2447bc3bbfe9e76306ce40a31f-Paper.pdf) |
|
| 205 |
+
| clone | none | code clone detection in [Java data](https://arxiv.org/pdf/2002.08653.pdf) |
|
| 206 |
+
|
| 207 |
+
For example, if you want to run CodeT5-base model on the code summarization task for Python, you can simply run:
|
| 208 |
+
|
| 209 |
+
```
|
| 210 |
+
python run_exp.py --model_tag codet5_base --task summarize --sub_task python
|
| 211 |
+
```
|
| 212 |
+
|
| 213 |
+
For multi-task training, you can type:
|
| 214 |
+
|
| 215 |
+
```
|
| 216 |
+
python run_exp.py --model_tag codet5_base --task multi_task --sub_task none
|
| 217 |
+
```
|
| 218 |
+
|
| 219 |
+
Besides, you can specify:
|
| 220 |
+
|
| 221 |
+
```
|
| 222 |
+
model_dir: where to save fine-tuning checkpoints
|
| 223 |
+
res_dir: where to save the performance results
|
| 224 |
+
summary_dir: where to save the training curves
|
| 225 |
+
data_num: how many data instances to use, the default -1 is for using the full data
|
| 226 |
+
gpu: the index of the GPU to use in the cluster
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
You can also revise the suggested
|
| 230 |
+
arguments [here](https://github.com/salesforce/CodeT5/blob/0bf3c0c43e92fcf54d9df68c793ac22f2b60aad4/sh/run_exp.py#L14) or directly customize the [exp_with_args.sh](https://github.com/salesforce/CodeT5/blob/main/sh/exp_with_args.sh) bash file.
|
| 231 |
+
Please refer to the argument flags in [configs.py](https://github.com/salesforce/CodeT5/blob/main/configs.py) for the full
|
| 232 |
+
available options. The saved training curves in `summary_dir` can be visualized using [tensorboard](https://pypi.org/project/tensorboard/).
|
| 233 |
+
Note that we employ one A100 GPU for all fine-tuning experiments.
|
| 234 |
+
|
| 235 |
+
### How to reproduce the results using the released finetuned checkpoints?
|
| 236 |
+
|
| 237 |
+
* Remove the `--do_train --do_eval --do_eval_bleu` and reserve only `--do_test` at [here](https://github.com/salesforce/CodeT5/blob/5b37c34f4bbbfcfd972c24a9dd1f45716568ecb5/sh/exp_with_args.sh#L84).
|
| 238 |
+
* Pass the path of your downloaded finetuned checkpoint to load at [here](https://github.com/salesforce/CodeT5/blob/5b37c34f4bbbfcfd972c24a9dd1f45716568ecb5/run_gen.py#L366), e.g., `file = "CodeT5/finetuned_models/summarize_python_codet5_base.bin"`
|
| 239 |
+
* Run the program: `python run_exp.py --model_tag codet5_base --task summarize --sub_task python`
|
| 240 |
+
|
| 241 |
+
### How to fine-tune on your own task and dataset?
|
| 242 |
+
If you want to fine-tune on your dataset, you can add your own task and sub_task in `configs.py` ([here](https://github.com/salesforce/CodeT5/blob/d27512d23ba6130e089e571d8c3e399760db1c31/configs.py#L11)) and add your data path and the function to read in `utils.py` ([here](https://github.com/salesforce/CodeT5/blob/5bb41e21b07fee73f310476a91ded00e385290d7/utils.py#L103) and [here](https://github.com/salesforce/CodeT5/blob/5bb41e21b07fee73f310476a91ded00e385290d7/utils.py#L149)). The read function can be implemented in `_utils.py` similar to [this one](https://github.com/salesforce/CodeT5/blob/aaf9c4a920c4986abfd54a74f5456b056b6409e0/_utils.py#L213). If your task to add is a generation task, you can simply reuse or customize the `run_gen.py`. For understanding tasks, please refer to `run_defect.py` and `run_clone.py`.
|
| 243 |
+
|
| 244 |
+
## Get Involved
|
| 245 |
+
|
| 246 |
+
Please create a GitHub issue if you have any questions, suggestions, requests or bug-reports. We welcome PRs!
|
| 247 |
+
|
SECURITY.md
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Security
|
| 2 |
+
|
| 3 |
+
Please report any security issue to [security@salesforce.com](mailto:security@salesforce.com)
|
| 4 |
+
as soon as it is discovered. This library limits its runtime dependencies in
|
| 5 |
+
order to reduce the total cost of ownership as much as can be, but all consumers
|
| 6 |
+
should remain vigilant and have their security stakeholders review all third-party
|
| 7 |
+
products (3PP) like this one and their dependencies.
|
_utils.py
ADDED
|
@@ -0,0 +1,306 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
def add_lang_by_task(target_str, task, sub_task):
|
| 5 |
+
if task == 'summarize':
|
| 6 |
+
target_str = '<en> ' + target_str
|
| 7 |
+
elif task == 'refine':
|
| 8 |
+
target_str = '<java> ' + target_str
|
| 9 |
+
elif task == 'translate':
|
| 10 |
+
if sub_task == 'java-cs':
|
| 11 |
+
target_str = '<c_sharp> ' + target_str
|
| 12 |
+
else:
|
| 13 |
+
target_str = '<java> ' + target_str
|
| 14 |
+
elif task == 'concode':
|
| 15 |
+
target_str = '<java> ' + target_str
|
| 16 |
+
elif task == 'defect':
|
| 17 |
+
target_str = target_str
|
| 18 |
+
return target_str
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def convert_examples_to_features(item):
|
| 22 |
+
example, example_index, tokenizer, args, stage = item
|
| 23 |
+
|
| 24 |
+
if args.model_type in ['t5', 'codet5'] and args.add_task_prefix:
|
| 25 |
+
if args.sub_task != 'none':
|
| 26 |
+
source_str = "{} {}: {}".format(args.task, args.sub_task, example.source)
|
| 27 |
+
else:
|
| 28 |
+
source_str = "{}: {}".format(args.task, example.source)
|
| 29 |
+
else:
|
| 30 |
+
source_str = example.source
|
| 31 |
+
|
| 32 |
+
source_str = source_str.replace('</s>', '<unk>')
|
| 33 |
+
source_ids = tokenizer.encode(source_str, max_length=args.max_source_length, padding='max_length', truncation=True)
|
| 34 |
+
assert source_ids.count(tokenizer.eos_token_id) == 1
|
| 35 |
+
if stage == 'test':
|
| 36 |
+
target_ids = []
|
| 37 |
+
else:
|
| 38 |
+
target_str = example.target
|
| 39 |
+
if args.add_lang_ids:
|
| 40 |
+
target_str = add_lang_by_task(example.target, args.task, args.sub_task)
|
| 41 |
+
if args.task in ['defect', 'clone']:
|
| 42 |
+
if target_str == 0:
|
| 43 |
+
target_str = 'false'
|
| 44 |
+
elif target_str == 1:
|
| 45 |
+
target_str = 'true'
|
| 46 |
+
else:
|
| 47 |
+
raise NameError
|
| 48 |
+
target_str = target_str.replace('</s>', '<unk>')
|
| 49 |
+
target_ids = tokenizer.encode(target_str, max_length=args.max_target_length, padding='max_length',
|
| 50 |
+
truncation=True)
|
| 51 |
+
assert target_ids.count(tokenizer.eos_token_id) == 1
|
| 52 |
+
|
| 53 |
+
return InputFeatures(
|
| 54 |
+
example_index,
|
| 55 |
+
source_ids,
|
| 56 |
+
target_ids,
|
| 57 |
+
url=example.url
|
| 58 |
+
)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def convert_clone_examples_to_features(item):
|
| 62 |
+
example, example_index, tokenizer, args = item
|
| 63 |
+
if args.model_type in ['t5', 'codet5'] and args.add_task_prefix:
|
| 64 |
+
source_str = "{}: {}".format(args.task, example.source)
|
| 65 |
+
target_str = "{}: {}".format(args.task, example.target)
|
| 66 |
+
else:
|
| 67 |
+
source_str = example.source
|
| 68 |
+
target_str = example.target
|
| 69 |
+
code1 = tokenizer.encode(source_str, max_length=args.max_source_length, padding='max_length', truncation=True)
|
| 70 |
+
code2 = tokenizer.encode(target_str, max_length=args.max_source_length, padding='max_length', truncation=True)
|
| 71 |
+
source_ids = code1 + code2
|
| 72 |
+
return CloneInputFeatures(example_index, source_ids, example.label, example.url1, example.url2)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def convert_defect_examples_to_features(item):
|
| 76 |
+
example, example_index, tokenizer, args = item
|
| 77 |
+
if args.model_type in ['t5', 'codet5'] and args.add_task_prefix:
|
| 78 |
+
source_str = "{}: {}".format(args.task, example.source)
|
| 79 |
+
else:
|
| 80 |
+
source_str = example.source
|
| 81 |
+
code = tokenizer.encode(source_str, max_length=args.max_source_length, padding='max_length', truncation=True)
|
| 82 |
+
return DefectInputFeatures(example_index, code, example.target)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class CloneInputFeatures(object):
|
| 86 |
+
"""A single training/test features for a example."""
|
| 87 |
+
|
| 88 |
+
def __init__(self,
|
| 89 |
+
example_id,
|
| 90 |
+
source_ids,
|
| 91 |
+
label,
|
| 92 |
+
url1,
|
| 93 |
+
url2
|
| 94 |
+
):
|
| 95 |
+
self.example_id = example_id
|
| 96 |
+
self.source_ids = source_ids
|
| 97 |
+
self.label = label
|
| 98 |
+
self.url1 = url1
|
| 99 |
+
self.url2 = url2
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class DefectInputFeatures(object):
|
| 103 |
+
"""A single training/test features for a example."""
|
| 104 |
+
|
| 105 |
+
def __init__(self,
|
| 106 |
+
example_id,
|
| 107 |
+
source_ids,
|
| 108 |
+
label
|
| 109 |
+
):
|
| 110 |
+
self.example_id = example_id
|
| 111 |
+
self.source_ids = source_ids
|
| 112 |
+
self.label = label
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
class InputFeatures(object):
|
| 116 |
+
"""A single training/test features for a example."""
|
| 117 |
+
|
| 118 |
+
def __init__(self,
|
| 119 |
+
example_id,
|
| 120 |
+
source_ids,
|
| 121 |
+
target_ids,
|
| 122 |
+
url=None
|
| 123 |
+
):
|
| 124 |
+
self.example_id = example_id
|
| 125 |
+
self.source_ids = source_ids
|
| 126 |
+
self.target_ids = target_ids
|
| 127 |
+
self.url = url
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
class Example(object):
|
| 131 |
+
"""A single training/test example."""
|
| 132 |
+
|
| 133 |
+
def __init__(self,
|
| 134 |
+
idx,
|
| 135 |
+
source,
|
| 136 |
+
target,
|
| 137 |
+
url=None,
|
| 138 |
+
task='',
|
| 139 |
+
sub_task=''
|
| 140 |
+
):
|
| 141 |
+
self.idx = idx
|
| 142 |
+
self.source = source
|
| 143 |
+
self.target = target
|
| 144 |
+
self.url = url
|
| 145 |
+
self.task = task
|
| 146 |
+
self.sub_task = sub_task
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
class CloneExample(object):
|
| 150 |
+
"""A single training/test example."""
|
| 151 |
+
|
| 152 |
+
def __init__(self,
|
| 153 |
+
code1,
|
| 154 |
+
code2,
|
| 155 |
+
label,
|
| 156 |
+
url1,
|
| 157 |
+
url2
|
| 158 |
+
):
|
| 159 |
+
self.source = code1
|
| 160 |
+
self.target = code2
|
| 161 |
+
self.label = label
|
| 162 |
+
self.url1 = url1
|
| 163 |
+
self.url2 = url2
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def read_translate_examples(filename, data_num):
|
| 167 |
+
"""Read examples from filename."""
|
| 168 |
+
examples = []
|
| 169 |
+
assert len(filename.split(',')) == 2
|
| 170 |
+
src_filename = filename.split(',')[0]
|
| 171 |
+
trg_filename = filename.split(',')[1]
|
| 172 |
+
idx = 0
|
| 173 |
+
with open(src_filename) as f1, open(trg_filename) as f2:
|
| 174 |
+
for line1, line2 in zip(f1, f2):
|
| 175 |
+
src = line1.strip()
|
| 176 |
+
trg = line2.strip()
|
| 177 |
+
examples.append(
|
| 178 |
+
Example(
|
| 179 |
+
idx=idx,
|
| 180 |
+
source=src,
|
| 181 |
+
target=trg,
|
| 182 |
+
)
|
| 183 |
+
)
|
| 184 |
+
idx += 1
|
| 185 |
+
if idx == data_num:
|
| 186 |
+
break
|
| 187 |
+
return examples
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def read_refine_examples(filename, data_num):
|
| 191 |
+
"""Read examples from filename."""
|
| 192 |
+
examples = []
|
| 193 |
+
assert len(filename.split(',')) == 2
|
| 194 |
+
src_filename = filename.split(',')[0]
|
| 195 |
+
trg_filename = filename.split(',')[1]
|
| 196 |
+
idx = 0
|
| 197 |
+
|
| 198 |
+
with open(src_filename) as f1, open(trg_filename) as f2:
|
| 199 |
+
for line1, line2 in zip(f1, f2):
|
| 200 |
+
examples.append(
|
| 201 |
+
Example(
|
| 202 |
+
idx=idx,
|
| 203 |
+
source=line1.strip(),
|
| 204 |
+
target=line2.strip(),
|
| 205 |
+
)
|
| 206 |
+
)
|
| 207 |
+
idx += 1
|
| 208 |
+
if idx == data_num:
|
| 209 |
+
break
|
| 210 |
+
return examples
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
def read_concode_examples(filename, data_num):
|
| 214 |
+
"""Read examples from filename."""
|
| 215 |
+
examples = []
|
| 216 |
+
|
| 217 |
+
with open(filename) as f:
|
| 218 |
+
for idx, line in enumerate(f):
|
| 219 |
+
x = json.loads(line)
|
| 220 |
+
examples.append(
|
| 221 |
+
Example(
|
| 222 |
+
idx=idx,
|
| 223 |
+
source=x["nl"].strip(),
|
| 224 |
+
target=x["code"].strip()
|
| 225 |
+
)
|
| 226 |
+
)
|
| 227 |
+
idx += 1
|
| 228 |
+
if idx == data_num:
|
| 229 |
+
break
|
| 230 |
+
return examples
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
def read_summarize_examples(filename, data_num):
|
| 234 |
+
"""Read examples from filename."""
|
| 235 |
+
examples = []
|
| 236 |
+
with open(filename, encoding="utf-8") as f:
|
| 237 |
+
for idx, line in enumerate(f):
|
| 238 |
+
line = line.strip()
|
| 239 |
+
js = json.loads(line)
|
| 240 |
+
if 'idx' not in js:
|
| 241 |
+
js['idx'] = idx
|
| 242 |
+
code = ' '.join(js['code_tokens']).replace('\n', ' ')
|
| 243 |
+
code = ' '.join(code.strip().split())
|
| 244 |
+
nl = ' '.join(js['docstring_tokens']).replace('\n', '')
|
| 245 |
+
nl = ' '.join(nl.strip().split())
|
| 246 |
+
examples.append(
|
| 247 |
+
Example(
|
| 248 |
+
idx=idx,
|
| 249 |
+
source=code,
|
| 250 |
+
target=nl,
|
| 251 |
+
)
|
| 252 |
+
)
|
| 253 |
+
if idx + 1 == data_num:
|
| 254 |
+
break
|
| 255 |
+
return examples
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
def read_defect_examples(filename, data_num):
|
| 259 |
+
"""Read examples from filename."""
|
| 260 |
+
examples = []
|
| 261 |
+
with open(filename, encoding="utf-8") as f:
|
| 262 |
+
for idx, line in enumerate(f):
|
| 263 |
+
line = line.strip()
|
| 264 |
+
js = json.loads(line)
|
| 265 |
+
|
| 266 |
+
code = ' '.join(js['func'].split())
|
| 267 |
+
examples.append(
|
| 268 |
+
Example(
|
| 269 |
+
idx=js['idx'],
|
| 270 |
+
source=code,
|
| 271 |
+
target=js['target']
|
| 272 |
+
)
|
| 273 |
+
)
|
| 274 |
+
if idx + 1 == data_num:
|
| 275 |
+
break
|
| 276 |
+
return examples
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
def read_clone_examples(filename, data_num):
|
| 280 |
+
"""Read examples from filename."""
|
| 281 |
+
index_filename = filename
|
| 282 |
+
url_to_code = {}
|
| 283 |
+
with open('/'.join(index_filename.split('/')[:-1]) + '/data.jsonl') as f:
|
| 284 |
+
for line in f:
|
| 285 |
+
line = line.strip()
|
| 286 |
+
js = json.loads(line)
|
| 287 |
+
code = ' '.join(js['func'].split())
|
| 288 |
+
url_to_code[js['idx']] = code
|
| 289 |
+
|
| 290 |
+
data = []
|
| 291 |
+
with open(index_filename) as f:
|
| 292 |
+
idx = 0
|
| 293 |
+
for line in f:
|
| 294 |
+
line = line.strip()
|
| 295 |
+
url1, url2, label = line.split('\t')
|
| 296 |
+
if url1 not in url_to_code or url2 not in url_to_code:
|
| 297 |
+
continue
|
| 298 |
+
if label == '0':
|
| 299 |
+
label = 0
|
| 300 |
+
else:
|
| 301 |
+
label = 1
|
| 302 |
+
data.append(CloneExample(url_to_code[url1], url_to_code[url2], label, url1, url2))
|
| 303 |
+
idx += 1
|
| 304 |
+
if idx == data_num:
|
| 305 |
+
break
|
| 306 |
+
return data
|
codet5.gif
ADDED

|
Git LFS Details
|
configs.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import torch
|
| 3 |
+
import logging
|
| 4 |
+
import multiprocessing
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
logger = logging.getLogger(__name__)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def add_args(parser):
|
| 11 |
+
parser.add_argument("--task", type=str, required=True,
|
| 12 |
+
choices=['summarize', 'concode', 'translate', 'refine', 'defect', 'clone', 'multi_task'])
|
| 13 |
+
parser.add_argument("--sub_task", type=str, default='')
|
| 14 |
+
parser.add_argument("--lang", type=str, default='')
|
| 15 |
+
parser.add_argument("--eval_task", type=str, default='')
|
| 16 |
+
parser.add_argument("--model_type", default="codet5", type=str, choices=['roberta', 'bart', 'codet5'])
|
| 17 |
+
parser.add_argument("--add_lang_ids", action='store_true')
|
| 18 |
+
parser.add_argument("--data_num", default=-1, type=int)
|
| 19 |
+
parser.add_argument("--start_epoch", default=0, type=int)
|
| 20 |
+
parser.add_argument("--num_train_epochs", default=100, type=int)
|
| 21 |
+
parser.add_argument("--patience", default=5, type=int)
|
| 22 |
+
parser.add_argument("--cache_path", type=str, required=True)
|
| 23 |
+
parser.add_argument("--summary_dir", type=str, required=True)
|
| 24 |
+
parser.add_argument("--data_dir", type=str, required=True)
|
| 25 |
+
parser.add_argument("--res_dir", type=str, required=True)
|
| 26 |
+
parser.add_argument("--res_fn", type=str, default='')
|
| 27 |
+
parser.add_argument("--add_task_prefix", action='store_true', help="Whether to add task prefix for t5 and codet5")
|
| 28 |
+
parser.add_argument("--save_last_checkpoints", action='store_true')
|
| 29 |
+
parser.add_argument("--always_save_model", action='store_true')
|
| 30 |
+
parser.add_argument("--do_eval_bleu", action='store_true', help="Whether to evaluate bleu on dev set.")
|
| 31 |
+
|
| 32 |
+
## Required parameters
|
| 33 |
+
parser.add_argument("--model_name_or_path", default="roberta-base", type=str,
|
| 34 |
+
help="Path to pre-trained model: e.g. roberta-base")
|
| 35 |
+
parser.add_argument("--output_dir", default=None, type=str, required=True,
|
| 36 |
+
help="The output directory where the model predictions and checkpoints will be written.")
|
| 37 |
+
parser.add_argument("--load_model_path", default=None, type=str,
|
| 38 |
+
help="Path to trained model: Should contain the .bin files")
|
| 39 |
+
## Other parameters
|
| 40 |
+
parser.add_argument("--train_filename", default=None, type=str,
|
| 41 |
+
help="The train filename. Should contain the .jsonl files for this task.")
|
| 42 |
+
parser.add_argument("--dev_filename", default=None, type=str,
|
| 43 |
+
help="The dev filename. Should contain the .jsonl files for this task.")
|
| 44 |
+
parser.add_argument("--test_filename", default=None, type=str,
|
| 45 |
+
help="The test filename. Should contain the .jsonl files for this task.")
|
| 46 |
+
|
| 47 |
+
parser.add_argument("--config_name", default="", type=str,
|
| 48 |
+
help="Pretrained config name or path if not the same as model_name")
|
| 49 |
+
parser.add_argument("--tokenizer_name", default="roberta-base", type=str,
|
| 50 |
+
help="Pretrained tokenizer name or path if not the same as model_name")
|
| 51 |
+
parser.add_argument("--max_source_length", default=64, type=int,
|
| 52 |
+
help="The maximum total source sequence length after tokenization. Sequences longer "
|
| 53 |
+
"than this will be truncated, sequences shorter will be padded.")
|
| 54 |
+
parser.add_argument("--max_target_length", default=32, type=int,
|
| 55 |
+
help="The maximum total target sequence length after tokenization. Sequences longer "
|
| 56 |
+
"than this will be truncated, sequences shorter will be padded.")
|
| 57 |
+
|
| 58 |
+
parser.add_argument("--do_train", action='store_true',
|
| 59 |
+
help="Whether to run eval on the train set.")
|
| 60 |
+
parser.add_argument("--do_eval", action='store_true',
|
| 61 |
+
help="Whether to run eval on the dev set.")
|
| 62 |
+
parser.add_argument("--do_test", action='store_true',
|
| 63 |
+
help="Whether to run eval on the dev set.")
|
| 64 |
+
parser.add_argument("--do_lower_case", action='store_true',
|
| 65 |
+
help="Set this flag if you are using an uncased model.")
|
| 66 |
+
parser.add_argument("--no_cuda", action='store_true',
|
| 67 |
+
help="Avoid using CUDA when available")
|
| 68 |
+
|
| 69 |
+
parser.add_argument("--train_batch_size", default=8, type=int,
|
| 70 |
+
help="Batch size per GPU/CPU for training.")
|
| 71 |
+
parser.add_argument("--eval_batch_size", default=8, type=int,
|
| 72 |
+
help="Batch size per GPU/CPU for evaluation.")
|
| 73 |
+
parser.add_argument('--gradient_accumulation_steps', type=int, default=1,
|
| 74 |
+
help="Number of updates steps to accumulate before performing a backward/update pass.")
|
| 75 |
+
parser.add_argument("--learning_rate", default=5e-5, type=float,
|
| 76 |
+
help="The initial learning rate for Adam.")
|
| 77 |
+
parser.add_argument("--beam_size", default=10, type=int,
|
| 78 |
+
help="beam size for beam search")
|
| 79 |
+
parser.add_argument("--weight_decay", default=0.0, type=float,
|
| 80 |
+
help="Weight deay if we apply some.")
|
| 81 |
+
parser.add_argument("--adam_epsilon", default=1e-8, type=float,
|
| 82 |
+
help="Epsilon for Adam optimizer.")
|
| 83 |
+
parser.add_argument("--max_grad_norm", default=1.0, type=float,
|
| 84 |
+
help="Max gradient norm.")
|
| 85 |
+
|
| 86 |
+
parser.add_argument("--save_steps", default=-1, type=int, )
|
| 87 |
+
parser.add_argument("--log_steps", default=-1, type=int, )
|
| 88 |
+
parser.add_argument("--max_steps", default=-1, type=int,
|
| 89 |
+
help="If > 0: set total number of training steps to perform. Override num_train_epochs.")
|
| 90 |
+
parser.add_argument("--eval_steps", default=-1, type=int,
|
| 91 |
+
help="")
|
| 92 |
+
parser.add_argument("--train_steps", default=-1, type=int,
|
| 93 |
+
help="")
|
| 94 |
+
parser.add_argument("--warmup_steps", default=100, type=int,
|
| 95 |
+
help="Linear warmup over warmup_steps.")
|
| 96 |
+
parser.add_argument("--local_rank", type=int, default=-1,
|
| 97 |
+
help="For distributed training: local_rank")
|
| 98 |
+
parser.add_argument('--seed', type=int, default=1234,
|
| 99 |
+
help="random seed for initialization")
|
| 100 |
+
args = parser.parse_args()
|
| 101 |
+
|
| 102 |
+
if args.task in ['summarize']:
|
| 103 |
+
args.lang = args.sub_task
|
| 104 |
+
elif args.task in ['refine', 'concode', 'clone']:
|
| 105 |
+
args.lang = 'java'
|
| 106 |
+
elif args.task == 'defect':
|
| 107 |
+
args.lang = 'c'
|
| 108 |
+
elif args.task == 'translate':
|
| 109 |
+
args.lang = 'c_sharp' if args.sub_task == 'java-cs' else 'java'
|
| 110 |
+
return args
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
def set_dist(args):
|
| 114 |
+
# Setup CUDA, GPU & distributed training
|
| 115 |
+
if args.local_rank == -1 or args.no_cuda:
|
| 116 |
+
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
| 117 |
+
args.n_gpu = torch.cuda.device_count()
|
| 118 |
+
else:
|
| 119 |
+
# Setup for distributed data parallel
|
| 120 |
+
torch.cuda.set_device(args.local_rank)
|
| 121 |
+
device = torch.device("cuda", args.local_rank)
|
| 122 |
+
torch.distributed.init_process_group(backend='nccl')
|
| 123 |
+
args.n_gpu = 1
|
| 124 |
+
cpu_cont = multiprocessing.cpu_count()
|
| 125 |
+
logger.warning("Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, cpu count: %d",
|
| 126 |
+
args.local_rank, device, args.n_gpu, bool(args.local_rank != -1), cpu_cont)
|
| 127 |
+
args.device = device
|
| 128 |
+
args.cpu_cont = cpu_cont
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def set_seed(args):
|
| 132 |
+
"""set random seed."""
|
| 133 |
+
random.seed(args.seed)
|
| 134 |
+
np.random.seed(args.seed)
|
| 135 |
+
torch.manual_seed(args.seed)
|
| 136 |
+
if args.n_gpu > 0:
|
| 137 |
+
torch.cuda.manual_seed_all(args.seed)
|
evaluator/CodeBLEU/bleu.py
ADDED
|
@@ -0,0 +1,589 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
# Natural Language Toolkit: BLEU Score
|
| 3 |
+
#
|
| 4 |
+
# Copyright (C) 2001-2020 NLTK Project
|
| 5 |
+
# Authors: Chin Yee Lee, Hengfeng Li, Ruxin Hou, Calvin Tanujaya Lim
|
| 6 |
+
# Contributors: Björn Mattsson, Dmitrijs Milajevs, Liling Tan
|
| 7 |
+
# URL: <http://nltk.org/>
|
| 8 |
+
# For license information, see LICENSE.TXT
|
| 9 |
+
|
| 10 |
+
"""BLEU score implementation."""
|
| 11 |
+
|
| 12 |
+
import math
|
| 13 |
+
import sys
|
| 14 |
+
from fractions import Fraction
|
| 15 |
+
import warnings
|
| 16 |
+
from collections import Counter
|
| 17 |
+
|
| 18 |
+
from evaluator.CodeBLEU.utils import ngrams
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def sentence_bleu(
|
| 22 |
+
references,
|
| 23 |
+
hypothesis,
|
| 24 |
+
weights=(0.25, 0.25, 0.25, 0.25),
|
| 25 |
+
smoothing_function=None,
|
| 26 |
+
auto_reweigh=False,
|
| 27 |
+
):
|
| 28 |
+
"""
|
| 29 |
+
Calculate BLEU score (Bilingual Evaluation Understudy) from
|
| 30 |
+
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002.
|
| 31 |
+
"BLEU: a method for automatic evaluation of machine translation."
|
| 32 |
+
In Proceedings of ACL. http://www.aclweb.org/anthology/P02-1040.pdf
|
| 33 |
+
>>> hypothesis1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
|
| 34 |
+
... 'ensures', 'that', 'the', 'military', 'always',
|
| 35 |
+
... 'obeys', 'the', 'commands', 'of', 'the', 'party']
|
| 36 |
+
>>> hypothesis2 = ['It', 'is', 'to', 'insure', 'the', 'troops',
|
| 37 |
+
... 'forever', 'hearing', 'the', 'activity', 'guidebook',
|
| 38 |
+
... 'that', 'party', 'direct']
|
| 39 |
+
>>> reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
|
| 40 |
+
... 'ensures', 'that', 'the', 'military', 'will', 'forever',
|
| 41 |
+
... 'heed', 'Party', 'commands']
|
| 42 |
+
>>> reference2 = ['It', 'is', 'the', 'guiding', 'principle', 'which',
|
| 43 |
+
... 'guarantees', 'the', 'military', 'forces', 'always',
|
| 44 |
+
... 'being', 'under', 'the', 'command', 'of', 'the',
|
| 45 |
+
... 'Party']
|
| 46 |
+
>>> reference3 = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
|
| 47 |
+
... 'army', 'always', 'to', 'heed', 'the', 'directions',
|
| 48 |
+
... 'of', 'the', 'party']
|
| 49 |
+
>>> sentence_bleu([reference1, reference2, reference3], hypothesis1) # doctest: +ELLIPSIS
|
| 50 |
+
0.5045...
|
| 51 |
+
If there is no ngrams overlap for any order of n-grams, BLEU returns the
|
| 52 |
+
value 0. This is because the precision for the order of n-grams without
|
| 53 |
+
overlap is 0, and the geometric mean in the final BLEU score computation
|
| 54 |
+
multiplies the 0 with the precision of other n-grams. This results in 0
|
| 55 |
+
(independently of the precision of the othe n-gram orders). The following
|
| 56 |
+
example has zero 3-gram and 4-gram overlaps:
|
| 57 |
+
>>> round(sentence_bleu([reference1, reference2, reference3], hypothesis2),4) # doctest: +ELLIPSIS
|
| 58 |
+
0.0
|
| 59 |
+
To avoid this harsh behaviour when no ngram overlaps are found a smoothing
|
| 60 |
+
function can be used.
|
| 61 |
+
>>> chencherry = SmoothingFunction()
|
| 62 |
+
>>> sentence_bleu([reference1, reference2, reference3], hypothesis2,
|
| 63 |
+
... smoothing_function=chencherry.method1) # doctest: +ELLIPSIS
|
| 64 |
+
0.0370...
|
| 65 |
+
The default BLEU calculates a score for up to 4-grams using uniform
|
| 66 |
+
weights (this is called BLEU-4). To evaluate your translations with
|
| 67 |
+
higher/lower order ngrams, use customized weights. E.g. when accounting
|
| 68 |
+
for up to 5-grams with uniform weights (this is called BLEU-5) use:
|
| 69 |
+
>>> weights = (1./5., 1./5., 1./5., 1./5., 1./5.)
|
| 70 |
+
>>> sentence_bleu([reference1, reference2, reference3], hypothesis1, weights) # doctest: +ELLIPSIS
|
| 71 |
+
0.3920...
|
| 72 |
+
:param references: reference sentences
|
| 73 |
+
:type references: list(list(str))
|
| 74 |
+
:param hypothesis: a hypothesis sentence
|
| 75 |
+
:type hypothesis: list(str)
|
| 76 |
+
:param weights: weights for unigrams, bigrams, trigrams and so on
|
| 77 |
+
:type weights: list(float)
|
| 78 |
+
:param smoothing_function:
|
| 79 |
+
:type smoothing_function: SmoothingFunction
|
| 80 |
+
:param auto_reweigh: Option to re-normalize the weights uniformly.
|
| 81 |
+
:type auto_reweigh: bool
|
| 82 |
+
:return: The sentence-level BLEU score.
|
| 83 |
+
:rtype: float
|
| 84 |
+
"""
|
| 85 |
+
return corpus_bleu(
|
| 86 |
+
[references], [hypothesis], weights, smoothing_function, auto_reweigh
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def corpus_bleu(
|
| 91 |
+
list_of_references,
|
| 92 |
+
hypotheses,
|
| 93 |
+
weights=(0.25, 0.25, 0.25, 0.25),
|
| 94 |
+
smoothing_function=None,
|
| 95 |
+
auto_reweigh=False,
|
| 96 |
+
):
|
| 97 |
+
"""
|
| 98 |
+
Calculate a single corpus-level BLEU score (aka. system-level BLEU) for all
|
| 99 |
+
the hypotheses and their respective references.
|
| 100 |
+
Instead of averaging the sentence level BLEU scores (i.e. marco-average
|
| 101 |
+
precision), the original BLEU metric (Papineni et al. 2002) accounts for
|
| 102 |
+
the micro-average precision (i.e. summing the numerators and denominators
|
| 103 |
+
for each hypothesis-reference(s) pairs before the division).
|
| 104 |
+
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
|
| 105 |
+
... 'ensures', 'that', 'the', 'military', 'always',
|
| 106 |
+
... 'obeys', 'the', 'commands', 'of', 'the', 'party']
|
| 107 |
+
>>> ref1a = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
|
| 108 |
+
... 'ensures', 'that', 'the', 'military', 'will', 'forever',
|
| 109 |
+
... 'heed', 'Party', 'commands']
|
| 110 |
+
>>> ref1b = ['It', 'is', 'the', 'guiding', 'principle', 'which',
|
| 111 |
+
... 'guarantees', 'the', 'military', 'forces', 'always',
|
| 112 |
+
... 'being', 'under', 'the', 'command', 'of', 'the', 'Party']
|
| 113 |
+
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
|
| 114 |
+
... 'army', 'always', 'to', 'heed', 'the', 'directions',
|
| 115 |
+
... 'of', 'the', 'party']
|
| 116 |
+
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
|
| 117 |
+
... 'interested', 'in', 'world', 'history']
|
| 118 |
+
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
|
| 119 |
+
... 'because', 'he', 'read', 'the', 'book']
|
| 120 |
+
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
|
| 121 |
+
>>> hypotheses = [hyp1, hyp2]
|
| 122 |
+
>>> corpus_bleu(list_of_references, hypotheses) # doctest: +ELLIPSIS
|
| 123 |
+
0.5920...
|
| 124 |
+
The example below show that corpus_bleu() is different from averaging
|
| 125 |
+
sentence_bleu() for hypotheses
|
| 126 |
+
>>> score1 = sentence_bleu([ref1a, ref1b, ref1c], hyp1)
|
| 127 |
+
>>> score2 = sentence_bleu([ref2a], hyp2)
|
| 128 |
+
>>> (score1 + score2) / 2 # doctest: +ELLIPSIS
|
| 129 |
+
0.6223...
|
| 130 |
+
:param list_of_references: a corpus of lists of reference sentences, w.r.t. hypotheses
|
| 131 |
+
:type list_of_references: list(list(list(str)))
|
| 132 |
+
:param hypotheses: a list of hypothesis sentences
|
| 133 |
+
:type hypotheses: list(list(str))
|
| 134 |
+
:param weights: weights for unigrams, bigrams, trigrams and so on
|
| 135 |
+
:type weights: list(float)
|
| 136 |
+
:param smoothing_function:
|
| 137 |
+
:type smoothing_function: SmoothingFunction
|
| 138 |
+
:param auto_reweigh: Option to re-normalize the weights uniformly.
|
| 139 |
+
:type auto_reweigh: bool
|
| 140 |
+
:return: The corpus-level BLEU score.
|
| 141 |
+
:rtype: float
|
| 142 |
+
"""
|
| 143 |
+
# Before proceeding to compute BLEU, perform sanity checks.
|
| 144 |
+
|
| 145 |
+
p_numerators = Counter() # Key = ngram order, and value = no. of ngram matches.
|
| 146 |
+
p_denominators = Counter() # Key = ngram order, and value = no. of ngram in ref.
|
| 147 |
+
hyp_lengths, ref_lengths = 0, 0
|
| 148 |
+
|
| 149 |
+
assert len(list_of_references) == len(hypotheses), (
|
| 150 |
+
"The number of hypotheses and their reference(s) should be the " "same "
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
# Iterate through each hypothesis and their corresponding references.
|
| 154 |
+
for references, hypothesis in zip(list_of_references, hypotheses):
|
| 155 |
+
# For each order of ngram, calculate the numerator and
|
| 156 |
+
# denominator for the corpus-level modified precision.
|
| 157 |
+
for i, _ in enumerate(weights, start=1):
|
| 158 |
+
p_i = modified_precision(references, hypothesis, i)
|
| 159 |
+
p_numerators[i] += p_i.numerator
|
| 160 |
+
p_denominators[i] += p_i.denominator
|
| 161 |
+
|
| 162 |
+
# Calculate the hypothesis length and the closest reference length.
|
| 163 |
+
# Adds them to the corpus-level hypothesis and reference counts.
|
| 164 |
+
hyp_len = len(hypothesis)
|
| 165 |
+
hyp_lengths += hyp_len
|
| 166 |
+
ref_lengths += closest_ref_length(references, hyp_len)
|
| 167 |
+
|
| 168 |
+
# Calculate corpus-level brevity penalty.
|
| 169 |
+
bp = brevity_penalty(ref_lengths, hyp_lengths)
|
| 170 |
+
|
| 171 |
+
# Uniformly re-weighting based on maximum hypothesis lengths if largest
|
| 172 |
+
# order of n-grams < 4 and weights is set at default.
|
| 173 |
+
if auto_reweigh:
|
| 174 |
+
if hyp_lengths < 4 and weights == (0.25, 0.25, 0.25, 0.25):
|
| 175 |
+
weights = (1 / hyp_lengths,) * hyp_lengths
|
| 176 |
+
|
| 177 |
+
# Collects the various precision values for the different ngram orders.
|
| 178 |
+
p_n = [
|
| 179 |
+
Fraction(p_numerators[i], p_denominators[i], _normalize=False)
|
| 180 |
+
for i, _ in enumerate(weights, start=1)
|
| 181 |
+
]
|
| 182 |
+
|
| 183 |
+
# Returns 0 if there's no matching n-grams
|
| 184 |
+
# We only need to check for p_numerators[1] == 0, since if there's
|
| 185 |
+
# no unigrams, there won't be any higher order ngrams.
|
| 186 |
+
if p_numerators[1] == 0:
|
| 187 |
+
return 0
|
| 188 |
+
|
| 189 |
+
# If there's no smoothing, set use method0 from SmoothinFunction class.
|
| 190 |
+
if not smoothing_function:
|
| 191 |
+
smoothing_function = SmoothingFunction().method1
|
| 192 |
+
# Smoothen the modified precision.
|
| 193 |
+
# Note: smoothing_function() may convert values into floats;
|
| 194 |
+
# it tries to retain the Fraction object as much as the
|
| 195 |
+
# smoothing method allows.
|
| 196 |
+
p_n = smoothing_function(
|
| 197 |
+
p_n, references=references, hypothesis=hypothesis, hyp_len=hyp_lengths
|
| 198 |
+
)
|
| 199 |
+
s = (w_i * math.log(p_i) for w_i, p_i in zip(weights, p_n))
|
| 200 |
+
s = bp * math.exp(math.fsum(s))
|
| 201 |
+
return s
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def modified_precision(references, hypothesis, n):
|
| 205 |
+
"""
|
| 206 |
+
Calculate modified ngram precision.
|
| 207 |
+
The normal precision method may lead to some wrong translations with
|
| 208 |
+
high-precision, e.g., the translation, in which a word of reference
|
| 209 |
+
repeats several times, has very high precision.
|
| 210 |
+
This function only returns the Fraction object that contains the numerator
|
| 211 |
+
and denominator necessary to calculate the corpus-level precision.
|
| 212 |
+
To calculate the modified precision for a single pair of hypothesis and
|
| 213 |
+
references, cast the Fraction object into a float.
|
| 214 |
+
The famous "the the the ... " example shows that you can get BLEU precision
|
| 215 |
+
by duplicating high frequency words.
|
| 216 |
+
>>> reference1 = 'the cat is on the mat'.split()
|
| 217 |
+
>>> reference2 = 'there is a cat on the mat'.split()
|
| 218 |
+
>>> hypothesis1 = 'the the the the the the the'.split()
|
| 219 |
+
>>> references = [reference1, reference2]
|
| 220 |
+
>>> float(modified_precision(references, hypothesis1, n=1)) # doctest: +ELLIPSIS
|
| 221 |
+
0.2857...
|
| 222 |
+
In the modified n-gram precision, a reference word will be considered
|
| 223 |
+
exhausted after a matching hypothesis word is identified, e.g.
|
| 224 |
+
>>> reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
|
| 225 |
+
... 'ensures', 'that', 'the', 'military', 'will',
|
| 226 |
+
... 'forever', 'heed', 'Party', 'commands']
|
| 227 |
+
>>> reference2 = ['It', 'is', 'the', 'guiding', 'principle', 'which',
|
| 228 |
+
... 'guarantees', 'the', 'military', 'forces', 'always',
|
| 229 |
+
... 'being', 'under', 'the', 'command', 'of', 'the',
|
| 230 |
+
... 'Party']
|
| 231 |
+
>>> reference3 = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
|
| 232 |
+
... 'army', 'always', 'to', 'heed', 'the', 'directions',
|
| 233 |
+
... 'of', 'the', 'party']
|
| 234 |
+
>>> hypothesis = 'of the'.split()
|
| 235 |
+
>>> references = [reference1, reference2, reference3]
|
| 236 |
+
>>> float(modified_precision(references, hypothesis, n=1))
|
| 237 |
+
1.0
|
| 238 |
+
>>> float(modified_precision(references, hypothesis, n=2))
|
| 239 |
+
1.0
|
| 240 |
+
An example of a normal machine translation hypothesis:
|
| 241 |
+
>>> hypothesis1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
|
| 242 |
+
... 'ensures', 'that', 'the', 'military', 'always',
|
| 243 |
+
... 'obeys', 'the', 'commands', 'of', 'the', 'party']
|
| 244 |
+
>>> hypothesis2 = ['It', 'is', 'to', 'insure', 'the', 'troops',
|
| 245 |
+
... 'forever', 'hearing', 'the', 'activity', 'guidebook',
|
| 246 |
+
... 'that', 'party', 'direct']
|
| 247 |
+
>>> reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
|
| 248 |
+
... 'ensures', 'that', 'the', 'military', 'will',
|
| 249 |
+
... 'forever', 'heed', 'Party', 'commands']
|
| 250 |
+
>>> reference2 = ['It', 'is', 'the', 'guiding', 'principle', 'which',
|
| 251 |
+
... 'guarantees', 'the', 'military', 'forces', 'always',
|
| 252 |
+
... 'being', 'under', 'the', 'command', 'of', 'the',
|
| 253 |
+
... 'Party']
|
| 254 |
+
>>> reference3 = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
|
| 255 |
+
... 'army', 'always', 'to', 'heed', 'the', 'directions',
|
| 256 |
+
... 'of', 'the', 'party']
|
| 257 |
+
>>> references = [reference1, reference2, reference3]
|
| 258 |
+
>>> float(modified_precision(references, hypothesis1, n=1)) # doctest: +ELLIPSIS
|
| 259 |
+
0.9444...
|
| 260 |
+
>>> float(modified_precision(references, hypothesis2, n=1)) # doctest: +ELLIPSIS
|
| 261 |
+
0.5714...
|
| 262 |
+
>>> float(modified_precision(references, hypothesis1, n=2)) # doctest: +ELLIPSIS
|
| 263 |
+
0.5882352941176471
|
| 264 |
+
>>> float(modified_precision(references, hypothesis2, n=2)) # doctest: +ELLIPSIS
|
| 265 |
+
0.07692...
|
| 266 |
+
:param references: A list of reference translations.
|
| 267 |
+
:type references: list(list(str))
|
| 268 |
+
:param hypothesis: A hypothesis translation.
|
| 269 |
+
:type hypothesis: list(str)
|
| 270 |
+
:param n: The ngram order.
|
| 271 |
+
:type n: int
|
| 272 |
+
:return: BLEU's modified precision for the nth order ngram.
|
| 273 |
+
:rtype: Fraction
|
| 274 |
+
"""
|
| 275 |
+
# Extracts all ngrams in hypothesis
|
| 276 |
+
# Set an empty Counter if hypothesis is empty.
|
| 277 |
+
|
| 278 |
+
counts = Counter(ngrams(hypothesis, n)) if len(hypothesis) >= n else Counter()
|
| 279 |
+
# Extract a union of references' counts.
|
| 280 |
+
# max_counts = reduce(or_, [Counter(ngrams(ref, n)) for ref in references])
|
| 281 |
+
max_counts = {}
|
| 282 |
+
for reference in references:
|
| 283 |
+
reference_counts = (
|
| 284 |
+
Counter(ngrams(reference, n)) if len(reference) >= n else Counter()
|
| 285 |
+
)
|
| 286 |
+
for ngram in counts:
|
| 287 |
+
max_counts[ngram] = max(max_counts.get(ngram, 0), reference_counts[ngram])
|
| 288 |
+
|
| 289 |
+
# Assigns the intersection between hypothesis and references' counts.
|
| 290 |
+
clipped_counts = {
|
| 291 |
+
ngram: min(count, max_counts[ngram]) for ngram, count in counts.items()
|
| 292 |
+
}
|
| 293 |
+
|
| 294 |
+
numerator = sum(clipped_counts.values())
|
| 295 |
+
# Ensures that denominator is minimum 1 to avoid ZeroDivisionError.
|
| 296 |
+
# Usually this happens when the ngram order is > len(reference).
|
| 297 |
+
denominator = max(1, sum(counts.values()))
|
| 298 |
+
|
| 299 |
+
return Fraction(numerator, denominator, _normalize=False)
|
| 300 |
+
|
| 301 |
+
|
| 302 |
+
def closest_ref_length(references, hyp_len):
|
| 303 |
+
"""
|
| 304 |
+
This function finds the reference that is the closest length to the
|
| 305 |
+
hypothesis. The closest reference length is referred to as *r* variable
|
| 306 |
+
from the brevity penalty formula in Papineni et. al. (2002)
|
| 307 |
+
:param references: A list of reference translations.
|
| 308 |
+
:type references: list(list(str))
|
| 309 |
+
:param hyp_len: The length of the hypothesis.
|
| 310 |
+
:type hyp_len: int
|
| 311 |
+
:return: The length of the reference that's closest to the hypothesis.
|
| 312 |
+
:rtype: int
|
| 313 |
+
"""
|
| 314 |
+
ref_lens = (len(reference) for reference in references)
|
| 315 |
+
closest_ref_len = min(
|
| 316 |
+
ref_lens, key=lambda ref_len: (abs(ref_len - hyp_len), ref_len)
|
| 317 |
+
)
|
| 318 |
+
return closest_ref_len
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
def brevity_penalty(closest_ref_len, hyp_len):
|
| 322 |
+
"""
|
| 323 |
+
Calculate brevity penalty.
|
| 324 |
+
As the modified n-gram precision still has the problem from the short
|
| 325 |
+
length sentence, brevity penalty is used to modify the overall BLEU
|
| 326 |
+
score according to length.
|
| 327 |
+
An example from the paper. There are three references with length 12, 15
|
| 328 |
+
and 17. And a concise hypothesis of the length 12. The brevity penalty is 1.
|
| 329 |
+
>>> reference1 = list('aaaaaaaaaaaa') # i.e. ['a'] * 12
|
| 330 |
+
>>> reference2 = list('aaaaaaaaaaaaaaa') # i.e. ['a'] * 15
|
| 331 |
+
>>> reference3 = list('aaaaaaaaaaaaaaaaa') # i.e. ['a'] * 17
|
| 332 |
+
>>> hypothesis = list('aaaaaaaaaaaa') # i.e. ['a'] * 12
|
| 333 |
+
>>> references = [reference1, reference2, reference3]
|
| 334 |
+
>>> hyp_len = len(hypothesis)
|
| 335 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 336 |
+
>>> brevity_penalty(closest_ref_len, hyp_len)
|
| 337 |
+
1.0
|
| 338 |
+
In case a hypothesis translation is shorter than the references, penalty is
|
| 339 |
+
applied.
|
| 340 |
+
>>> references = [['a'] * 28, ['a'] * 28]
|
| 341 |
+
>>> hypothesis = ['a'] * 12
|
| 342 |
+
>>> hyp_len = len(hypothesis)
|
| 343 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 344 |
+
>>> brevity_penalty(closest_ref_len, hyp_len)
|
| 345 |
+
0.2635971381157267
|
| 346 |
+
The length of the closest reference is used to compute the penalty. If the
|
| 347 |
+
length of a hypothesis is 12, and the reference lengths are 13 and 2, the
|
| 348 |
+
penalty is applied because the hypothesis length (12) is less then the
|
| 349 |
+
closest reference length (13).
|
| 350 |
+
>>> references = [['a'] * 13, ['a'] * 2]
|
| 351 |
+
>>> hypothesis = ['a'] * 12
|
| 352 |
+
>>> hyp_len = len(hypothesis)
|
| 353 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 354 |
+
>>> brevity_penalty(closest_ref_len, hyp_len) # doctest: +ELLIPSIS
|
| 355 |
+
0.9200...
|
| 356 |
+
The brevity penalty doesn't depend on reference order. More importantly,
|
| 357 |
+
when two reference sentences are at the same distance, the shortest
|
| 358 |
+
reference sentence length is used.
|
| 359 |
+
>>> references = [['a'] * 13, ['a'] * 11]
|
| 360 |
+
>>> hypothesis = ['a'] * 12
|
| 361 |
+
>>> hyp_len = len(hypothesis)
|
| 362 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 363 |
+
>>> bp1 = brevity_penalty(closest_ref_len, hyp_len)
|
| 364 |
+
>>> hyp_len = len(hypothesis)
|
| 365 |
+
>>> closest_ref_len = closest_ref_length(reversed(references), hyp_len)
|
| 366 |
+
>>> bp2 = brevity_penalty(closest_ref_len, hyp_len)
|
| 367 |
+
>>> bp1 == bp2 == 1
|
| 368 |
+
True
|
| 369 |
+
A test example from mteval-v13a.pl (starting from the line 705):
|
| 370 |
+
>>> references = [['a'] * 11, ['a'] * 8]
|
| 371 |
+
>>> hypothesis = ['a'] * 7
|
| 372 |
+
>>> hyp_len = len(hypothesis)
|
| 373 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 374 |
+
>>> brevity_penalty(closest_ref_len, hyp_len) # doctest: +ELLIPSIS
|
| 375 |
+
0.8668...
|
| 376 |
+
>>> references = [['a'] * 11, ['a'] * 8, ['a'] * 6, ['a'] * 7]
|
| 377 |
+
>>> hypothesis = ['a'] * 7
|
| 378 |
+
>>> hyp_len = len(hypothesis)
|
| 379 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 380 |
+
>>> brevity_penalty(closest_ref_len, hyp_len)
|
| 381 |
+
1.0
|
| 382 |
+
:param hyp_len: The length of the hypothesis for a single sentence OR the
|
| 383 |
+
sum of all the hypotheses' lengths for a corpus
|
| 384 |
+
:type hyp_len: int
|
| 385 |
+
:param closest_ref_len: The length of the closest reference for a single
|
| 386 |
+
hypothesis OR the sum of all the closest references for every hypotheses.
|
| 387 |
+
:type closest_ref_len: int
|
| 388 |
+
:return: BLEU's brevity penalty.
|
| 389 |
+
:rtype: float
|
| 390 |
+
"""
|
| 391 |
+
if hyp_len > closest_ref_len:
|
| 392 |
+
return 1
|
| 393 |
+
# If hypothesis is empty, brevity penalty = 0 should result in BLEU = 0.0
|
| 394 |
+
elif hyp_len == 0:
|
| 395 |
+
return 0
|
| 396 |
+
else:
|
| 397 |
+
return math.exp(1 - closest_ref_len / hyp_len)
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
class SmoothingFunction:
|
| 401 |
+
"""
|
| 402 |
+
This is an implementation of the smoothing techniques
|
| 403 |
+
for segment-level BLEU scores that was presented in
|
| 404 |
+
Boxing Chen and Collin Cherry (2014) A Systematic Comparison of
|
| 405 |
+
Smoothing Techniques for Sentence-Level BLEU. In WMT14.
|
| 406 |
+
http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf
|
| 407 |
+
"""
|
| 408 |
+
|
| 409 |
+
def __init__(self, epsilon=0.1, alpha=5, k=5):
|
| 410 |
+
"""
|
| 411 |
+
This will initialize the parameters required for the various smoothing
|
| 412 |
+
techniques, the default values are set to the numbers used in the
|
| 413 |
+
experiments from Chen and Cherry (2014).
|
| 414 |
+
>>> hypothesis1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which', 'ensures',
|
| 415 |
+
... 'that', 'the', 'military', 'always', 'obeys', 'the',
|
| 416 |
+
... 'commands', 'of', 'the', 'party']
|
| 417 |
+
>>> reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that', 'ensures',
|
| 418 |
+
... 'that', 'the', 'military', 'will', 'forever', 'heed',
|
| 419 |
+
... 'Party', 'commands']
|
| 420 |
+
>>> chencherry = SmoothingFunction()
|
| 421 |
+
>>> print(sentence_bleu([reference1], hypothesis1)) # doctest: +ELLIPSIS
|
| 422 |
+
0.4118...
|
| 423 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method0)) # doctest: +ELLIPSIS
|
| 424 |
+
0.4118...
|
| 425 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method1)) # doctest: +ELLIPSIS
|
| 426 |
+
0.4118...
|
| 427 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method2)) # doctest: +ELLIPSIS
|
| 428 |
+
0.4489...
|
| 429 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method3)) # doctest: +ELLIPSIS
|
| 430 |
+
0.4118...
|
| 431 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method4)) # doctest: +ELLIPSIS
|
| 432 |
+
0.4118...
|
| 433 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method5)) # doctest: +ELLIPSIS
|
| 434 |
+
0.4905...
|
| 435 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method6)) # doctest: +ELLIPSIS
|
| 436 |
+
0.4135...
|
| 437 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method7)) # doctest: +ELLIPSIS
|
| 438 |
+
0.4905...
|
| 439 |
+
:param epsilon: the epsilon value use in method 1
|
| 440 |
+
:type epsilon: float
|
| 441 |
+
:param alpha: the alpha value use in method 6
|
| 442 |
+
:type alpha: int
|
| 443 |
+
:param k: the k value use in method 4
|
| 444 |
+
:type k: int
|
| 445 |
+
"""
|
| 446 |
+
self.epsilon = epsilon
|
| 447 |
+
self.alpha = alpha
|
| 448 |
+
self.k = k
|
| 449 |
+
|
| 450 |
+
def method0(self, p_n, *args, **kwargs):
|
| 451 |
+
"""
|
| 452 |
+
No smoothing.
|
| 453 |
+
"""
|
| 454 |
+
p_n_new = []
|
| 455 |
+
for i, p_i in enumerate(p_n):
|
| 456 |
+
if p_i.numerator != 0:
|
| 457 |
+
p_n_new.append(p_i)
|
| 458 |
+
else:
|
| 459 |
+
_msg = str(
|
| 460 |
+
"\nThe hypothesis contains 0 counts of {}-gram overlaps.\n"
|
| 461 |
+
"Therefore the BLEU score evaluates to 0, independently of\n"
|
| 462 |
+
"how many N-gram overlaps of lower order it contains.\n"
|
| 463 |
+
"Consider using lower n-gram order or use "
|
| 464 |
+
"SmoothingFunction()"
|
| 465 |
+
).format(i + 1)
|
| 466 |
+
warnings.warn(_msg)
|
| 467 |
+
# When numerator==0 where denonminator==0 or !=0, the result
|
| 468 |
+
# for the precision score should be equal to 0 or undefined.
|
| 469 |
+
# Due to BLEU geometric mean computation in logarithm space,
|
| 470 |
+
# we we need to take the return sys.float_info.min such that
|
| 471 |
+
# math.log(sys.float_info.min) returns a 0 precision score.
|
| 472 |
+
p_n_new.append(sys.float_info.min)
|
| 473 |
+
return p_n_new
|
| 474 |
+
|
| 475 |
+
def method1(self, p_n, *args, **kwargs):
|
| 476 |
+
"""
|
| 477 |
+
Smoothing method 1: Add *epsilon* counts to precision with 0 counts.
|
| 478 |
+
"""
|
| 479 |
+
return [
|
| 480 |
+
(p_i.numerator + self.epsilon) / p_i.denominator
|
| 481 |
+
if p_i.numerator == 0
|
| 482 |
+
else p_i
|
| 483 |
+
for p_i in p_n
|
| 484 |
+
]
|
| 485 |
+
|
| 486 |
+
def method2(self, p_n, *args, **kwargs):
|
| 487 |
+
"""
|
| 488 |
+
Smoothing method 2: Add 1 to both numerator and denominator from
|
| 489 |
+
Chin-Yew Lin and Franz Josef Och (2004) Automatic evaluation of
|
| 490 |
+
machine translation quality using longest common subsequence and
|
| 491 |
+
skip-bigram statistics. In ACL04.
|
| 492 |
+
"""
|
| 493 |
+
return [
|
| 494 |
+
Fraction(p_i.numerator + 1, p_i.denominator + 1, _normalize=False)
|
| 495 |
+
for p_i in p_n
|
| 496 |
+
]
|
| 497 |
+
|
| 498 |
+
def method3(self, p_n, *args, **kwargs):
|
| 499 |
+
"""
|
| 500 |
+
Smoothing method 3: NIST geometric sequence smoothing
|
| 501 |
+
The smoothing is computed by taking 1 / ( 2^k ), instead of 0, for each
|
| 502 |
+
precision score whose matching n-gram count is null.
|
| 503 |
+
k is 1 for the first 'n' value for which the n-gram match count is null/
|
| 504 |
+
For example, if the text contains:
|
| 505 |
+
- one 2-gram match
|
| 506 |
+
- and (consequently) two 1-gram matches
|
| 507 |
+
the n-gram count for each individual precision score would be:
|
| 508 |
+
- n=1 => prec_count = 2 (two unigrams)
|
| 509 |
+
- n=2 => prec_count = 1 (one bigram)
|
| 510 |
+
- n=3 => prec_count = 1/2 (no trigram, taking 'smoothed' value of 1 / ( 2^k ), with k=1)
|
| 511 |
+
- n=4 => prec_count = 1/4 (no fourgram, taking 'smoothed' value of 1 / ( 2^k ), with k=2)
|
| 512 |
+
"""
|
| 513 |
+
incvnt = 1 # From the mteval-v13a.pl, it's referred to as k.
|
| 514 |
+
for i, p_i in enumerate(p_n):
|
| 515 |
+
if p_i.numerator == 0:
|
| 516 |
+
p_n[i] = 1 / (2 ** incvnt * p_i.denominator)
|
| 517 |
+
incvnt += 1
|
| 518 |
+
return p_n
|
| 519 |
+
|
| 520 |
+
def method4(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 521 |
+
"""
|
| 522 |
+
Smoothing method 4:
|
| 523 |
+
Shorter translations may have inflated precision values due to having
|
| 524 |
+
smaller denominators; therefore, we give them proportionally
|
| 525 |
+
smaller smoothed counts. Instead of scaling to 1/(2^k), Chen and Cherry
|
| 526 |
+
suggests dividing by 1/ln(len(T)), where T is the length of the translation.
|
| 527 |
+
"""
|
| 528 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 529 |
+
for i, p_i in enumerate(p_n):
|
| 530 |
+
if p_i.numerator == 0 and hyp_len != 0:
|
| 531 |
+
incvnt = i + 1 * self.k / math.log(
|
| 532 |
+
hyp_len
|
| 533 |
+
) # Note that this K is different from the K from NIST.
|
| 534 |
+
p_n[i] = incvnt / p_i.denominator
|
| 535 |
+
return p_n
|
| 536 |
+
|
| 537 |
+
def method5(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 538 |
+
"""
|
| 539 |
+
Smoothing method 5:
|
| 540 |
+
The matched counts for similar values of n should be similar. To a
|
| 541 |
+
calculate the n-gram matched count, it averages the n−1, n and n+1 gram
|
| 542 |
+
matched counts.
|
| 543 |
+
"""
|
| 544 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 545 |
+
m = {}
|
| 546 |
+
# Requires an precision value for an addition ngram order.
|
| 547 |
+
p_n_plus1 = p_n + [modified_precision(references, hypothesis, 5)]
|
| 548 |
+
m[-1] = p_n[0] + 1
|
| 549 |
+
for i, p_i in enumerate(p_n):
|
| 550 |
+
p_n[i] = (m[i - 1] + p_i + p_n_plus1[i + 1]) / 3
|
| 551 |
+
m[i] = p_n[i]
|
| 552 |
+
return p_n
|
| 553 |
+
|
| 554 |
+
def method6(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 555 |
+
"""
|
| 556 |
+
Smoothing method 6:
|
| 557 |
+
Interpolates the maximum likelihood estimate of the precision *p_n* with
|
| 558 |
+
a prior estimate *pi0*. The prior is estimated by assuming that the ratio
|
| 559 |
+
between pn and pn−1 will be the same as that between pn−1 and pn−2; from
|
| 560 |
+
Gao and He (2013) Training MRF-Based Phrase Translation Models using
|
| 561 |
+
Gradient Ascent. In NAACL.
|
| 562 |
+
"""
|
| 563 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 564 |
+
# This smoothing only works when p_1 and p_2 is non-zero.
|
| 565 |
+
# Raise an error with an appropriate message when the input is too short
|
| 566 |
+
# to use this smoothing technique.
|
| 567 |
+
assert p_n[2], "This smoothing method requires non-zero precision for bigrams."
|
| 568 |
+
for i, p_i in enumerate(p_n):
|
| 569 |
+
if i in [0, 1]: # Skips the first 2 orders of ngrams.
|
| 570 |
+
continue
|
| 571 |
+
else:
|
| 572 |
+
pi0 = 0 if p_n[i - 2] == 0 else p_n[i - 1] ** 2 / p_n[i - 2]
|
| 573 |
+
# No. of ngrams in translation that matches the reference.
|
| 574 |
+
m = p_i.numerator
|
| 575 |
+
# No. of ngrams in translation.
|
| 576 |
+
l = sum(1 for _ in ngrams(hypothesis, i + 1))
|
| 577 |
+
# Calculates the interpolated precision.
|
| 578 |
+
p_n[i] = (m + self.alpha * pi0) / (l + self.alpha)
|
| 579 |
+
return p_n
|
| 580 |
+
|
| 581 |
+
def method7(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 582 |
+
"""
|
| 583 |
+
Smoothing method 7:
|
| 584 |
+
Interpolates methods 4 and 5.
|
| 585 |
+
"""
|
| 586 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 587 |
+
p_n = self.method4(p_n, references, hypothesis, hyp_len)
|
| 588 |
+
p_n = self.method5(p_n, references, hypothesis, hyp_len)
|
| 589 |
+
return p_n
|
evaluator/CodeBLEU/calc_code_bleu.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
# https://github.com/microsoft/CodeXGLUE/tree/main/Code-Code/code-to-code-trans/evaluator/CodeBLEU
|
| 4 |
+
|
| 5 |
+
# -*- coding:utf-8 -*-
|
| 6 |
+
import argparse
|
| 7 |
+
import os
|
| 8 |
+
from evaluator.CodeBLEU import bleu, weighted_ngram_match, syntax_match, dataflow_match
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def get_codebleu(refs, hyp, lang, params='0.25,0.25,0.25,0.25'):
|
| 12 |
+
if not isinstance(refs, list):
|
| 13 |
+
refs = [refs]
|
| 14 |
+
alpha, beta, gamma, theta = [float(x) for x in params.split(',')]
|
| 15 |
+
|
| 16 |
+
# preprocess inputs
|
| 17 |
+
pre_references = [[x.strip() for x in open(file, 'r', encoding='utf-8').readlines()] for file in refs]
|
| 18 |
+
hypothesis = [x.strip() for x in open(hyp, 'r', encoding='utf-8').readlines()]
|
| 19 |
+
|
| 20 |
+
for i in range(len(pre_references)):
|
| 21 |
+
assert len(hypothesis) == len(pre_references[i])
|
| 22 |
+
|
| 23 |
+
references = []
|
| 24 |
+
for i in range(len(hypothesis)):
|
| 25 |
+
ref_for_instance = []
|
| 26 |
+
for j in range(len(pre_references)):
|
| 27 |
+
ref_for_instance.append(pre_references[j][i])
|
| 28 |
+
references.append(ref_for_instance)
|
| 29 |
+
assert len(references) == len(pre_references) * len(hypothesis)
|
| 30 |
+
|
| 31 |
+
# calculate ngram match (BLEU)
|
| 32 |
+
tokenized_hyps = [x.split() for x in hypothesis]
|
| 33 |
+
tokenized_refs = [[x.split() for x in reference] for reference in references]
|
| 34 |
+
|
| 35 |
+
ngram_match_score = bleu.corpus_bleu(tokenized_refs, tokenized_hyps)
|
| 36 |
+
|
| 37 |
+
# calculate weighted ngram match
|
| 38 |
+
root_dir = os.path.dirname(__file__)
|
| 39 |
+
keywords = [x.strip() for x in open(root_dir + '/keywords/' + lang + '.txt', 'r', encoding='utf-8').readlines()]
|
| 40 |
+
|
| 41 |
+
def make_weights(reference_tokens, key_word_list):
|
| 42 |
+
return {token: 1 if token in key_word_list else 0.2 for token in reference_tokens}
|
| 43 |
+
|
| 44 |
+
tokenized_refs_with_weights = [[[reference_tokens, make_weights(reference_tokens, keywords)] \
|
| 45 |
+
for reference_tokens in reference] for reference in tokenized_refs]
|
| 46 |
+
|
| 47 |
+
weighted_ngram_match_score = weighted_ngram_match.corpus_bleu(tokenized_refs_with_weights, tokenized_hyps)
|
| 48 |
+
|
| 49 |
+
# calculate syntax match
|
| 50 |
+
syntax_match_score = syntax_match.corpus_syntax_match(references, hypothesis, lang)
|
| 51 |
+
|
| 52 |
+
# calculate dataflow match
|
| 53 |
+
dataflow_match_score = dataflow_match.corpus_dataflow_match(references, hypothesis, lang)
|
| 54 |
+
|
| 55 |
+
print('ngram match: {0}, weighted ngram match: {1}, syntax_match: {2}, dataflow_match: {3}'. \
|
| 56 |
+
format(ngram_match_score, weighted_ngram_match_score, syntax_match_score, dataflow_match_score))
|
| 57 |
+
|
| 58 |
+
code_bleu_score = alpha * ngram_match_score \
|
| 59 |
+
+ beta * weighted_ngram_match_score \
|
| 60 |
+
+ gamma * syntax_match_score \
|
| 61 |
+
+ theta * dataflow_match_score
|
| 62 |
+
|
| 63 |
+
return code_bleu_score
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
if __name__ == '__main__':
|
| 67 |
+
parser = argparse.ArgumentParser()
|
| 68 |
+
parser.add_argument('--refs', type=str, nargs='+', required=True,
|
| 69 |
+
help='reference files')
|
| 70 |
+
parser.add_argument('--hyp', type=str, required=True,
|
| 71 |
+
help='hypothesis file')
|
| 72 |
+
parser.add_argument('--lang', type=str, required=True,
|
| 73 |
+
choices=['java', 'js', 'c_sharp', 'php', 'go', 'python', 'ruby'],
|
| 74 |
+
help='programming language')
|
| 75 |
+
parser.add_argument('--params', type=str, default='0.25,0.25,0.25,0.25',
|
| 76 |
+
help='alpha, beta and gamma')
|
| 77 |
+
|
| 78 |
+
args = parser.parse_args()
|
| 79 |
+
code_bleu_score = get_codebleu(args.refs, args.hyp, args.lang, args.params)
|
| 80 |
+
print('CodeBLEU score: ', code_bleu_score)
|
| 81 |
+
|
evaluator/CodeBLEU/dataflow_match.py
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from evaluator.CodeBLEU.parser import DFG_python, DFG_java, DFG_ruby, DFG_go, DFG_php, DFG_javascript, DFG_csharp
|
| 5 |
+
from evaluator.CodeBLEU.parser import (remove_comments_and_docstrings,
|
| 6 |
+
tree_to_token_index,
|
| 7 |
+
index_to_code_token,
|
| 8 |
+
tree_to_variable_index)
|
| 9 |
+
from tree_sitter import Language, Parser
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
root_dir = os.path.dirname(__file__)
|
| 13 |
+
|
| 14 |
+
dfg_function = {
|
| 15 |
+
'python': DFG_python,
|
| 16 |
+
'java': DFG_java,
|
| 17 |
+
'ruby': DFG_ruby,
|
| 18 |
+
'go': DFG_go,
|
| 19 |
+
'php': DFG_php,
|
| 20 |
+
'javascript': DFG_javascript,
|
| 21 |
+
'c_sharp': DFG_csharp,
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def calc_dataflow_match(references, candidate, lang):
|
| 26 |
+
return corpus_dataflow_match([references], [candidate], lang)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def corpus_dataflow_match(references, candidates, lang):
|
| 30 |
+
LANGUAGE = Language(root_dir + '/parser/my-languages.so', lang)
|
| 31 |
+
parser = Parser()
|
| 32 |
+
parser.set_language(LANGUAGE)
|
| 33 |
+
parser = [parser, dfg_function[lang]]
|
| 34 |
+
match_count = 0
|
| 35 |
+
total_count = 0
|
| 36 |
+
|
| 37 |
+
for i in range(len(candidates)):
|
| 38 |
+
references_sample = references[i]
|
| 39 |
+
candidate = candidates[i]
|
| 40 |
+
for reference in references_sample:
|
| 41 |
+
try:
|
| 42 |
+
candidate = remove_comments_and_docstrings(candidate, 'java')
|
| 43 |
+
except:
|
| 44 |
+
pass
|
| 45 |
+
try:
|
| 46 |
+
reference = remove_comments_and_docstrings(reference, 'java')
|
| 47 |
+
except:
|
| 48 |
+
pass
|
| 49 |
+
|
| 50 |
+
cand_dfg = get_data_flow(candidate, parser)
|
| 51 |
+
ref_dfg = get_data_flow(reference, parser)
|
| 52 |
+
|
| 53 |
+
normalized_cand_dfg = normalize_dataflow(cand_dfg)
|
| 54 |
+
normalized_ref_dfg = normalize_dataflow(ref_dfg)
|
| 55 |
+
|
| 56 |
+
if len(normalized_ref_dfg) > 0:
|
| 57 |
+
total_count += len(normalized_ref_dfg)
|
| 58 |
+
for dataflow in normalized_ref_dfg:
|
| 59 |
+
if dataflow in normalized_cand_dfg:
|
| 60 |
+
match_count += 1
|
| 61 |
+
normalized_cand_dfg.remove(dataflow)
|
| 62 |
+
if total_count == 0:
|
| 63 |
+
print(
|
| 64 |
+
"WARNING: There is no reference data-flows extracted from the whole corpus, and the data-flow match score degenerates to 0. Please consider ignoring this score.")
|
| 65 |
+
return 0
|
| 66 |
+
score = match_count / total_count
|
| 67 |
+
return score
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def get_data_flow(code, parser):
|
| 71 |
+
try:
|
| 72 |
+
tree = parser[0].parse(bytes(code, 'utf8'))
|
| 73 |
+
root_node = tree.root_node
|
| 74 |
+
tokens_index = tree_to_token_index(root_node)
|
| 75 |
+
code = code.split('\n')
|
| 76 |
+
code_tokens = [index_to_code_token(x, code) for x in tokens_index]
|
| 77 |
+
index_to_code = {}
|
| 78 |
+
for idx, (index, code) in enumerate(zip(tokens_index, code_tokens)):
|
| 79 |
+
index_to_code[index] = (idx, code)
|
| 80 |
+
try:
|
| 81 |
+
DFG, _ = parser[1](root_node, index_to_code, {})
|
| 82 |
+
except:
|
| 83 |
+
DFG = []
|
| 84 |
+
DFG = sorted(DFG, key=lambda x: x[1])
|
| 85 |
+
indexs = set()
|
| 86 |
+
for d in DFG:
|
| 87 |
+
if len(d[-1]) != 0:
|
| 88 |
+
indexs.add(d[1])
|
| 89 |
+
for x in d[-1]:
|
| 90 |
+
indexs.add(x)
|
| 91 |
+
new_DFG = []
|
| 92 |
+
for d in DFG:
|
| 93 |
+
if d[1] in indexs:
|
| 94 |
+
new_DFG.append(d)
|
| 95 |
+
codes = code_tokens
|
| 96 |
+
dfg = new_DFG
|
| 97 |
+
except:
|
| 98 |
+
codes = code.split()
|
| 99 |
+
dfg = []
|
| 100 |
+
# merge nodes
|
| 101 |
+
dic = {}
|
| 102 |
+
for d in dfg:
|
| 103 |
+
if d[1] not in dic:
|
| 104 |
+
dic[d[1]] = d
|
| 105 |
+
else:
|
| 106 |
+
dic[d[1]] = (d[0], d[1], d[2], list(set(dic[d[1]][3] + d[3])), list(set(dic[d[1]][4] + d[4])))
|
| 107 |
+
DFG = []
|
| 108 |
+
for d in dic:
|
| 109 |
+
DFG.append(dic[d])
|
| 110 |
+
dfg = DFG
|
| 111 |
+
return dfg
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
def normalize_dataflow_item(dataflow_item):
|
| 115 |
+
var_name = dataflow_item[0]
|
| 116 |
+
var_pos = dataflow_item[1]
|
| 117 |
+
relationship = dataflow_item[2]
|
| 118 |
+
par_vars_name_list = dataflow_item[3]
|
| 119 |
+
par_vars_pos_list = dataflow_item[4]
|
| 120 |
+
|
| 121 |
+
var_names = list(set(par_vars_name_list + [var_name]))
|
| 122 |
+
norm_names = {}
|
| 123 |
+
for i in range(len(var_names)):
|
| 124 |
+
norm_names[var_names[i]] = 'var_' + str(i)
|
| 125 |
+
|
| 126 |
+
norm_var_name = norm_names[var_name]
|
| 127 |
+
relationship = dataflow_item[2]
|
| 128 |
+
norm_par_vars_name_list = [norm_names[x] for x in par_vars_name_list]
|
| 129 |
+
|
| 130 |
+
return (norm_var_name, relationship, norm_par_vars_name_list)
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
def normalize_dataflow(dataflow):
|
| 134 |
+
var_dict = {}
|
| 135 |
+
i = 0
|
| 136 |
+
normalized_dataflow = []
|
| 137 |
+
for item in dataflow:
|
| 138 |
+
var_name = item[0]
|
| 139 |
+
relationship = item[2]
|
| 140 |
+
par_vars_name_list = item[3]
|
| 141 |
+
for name in par_vars_name_list:
|
| 142 |
+
if name not in var_dict:
|
| 143 |
+
var_dict[name] = 'var_' + str(i)
|
| 144 |
+
i += 1
|
| 145 |
+
if var_name not in var_dict:
|
| 146 |
+
var_dict[var_name] = 'var_' + str(i)
|
| 147 |
+
i += 1
|
| 148 |
+
normalized_dataflow.append((var_dict[var_name], relationship, [var_dict[x] for x in par_vars_name_list]))
|
| 149 |
+
return normalized_dataflow
|
evaluator/CodeBLEU/keywords/c_sharp.txt
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
abstract
|
| 2 |
+
as
|
| 3 |
+
base
|
| 4 |
+
bool
|
| 5 |
+
break
|
| 6 |
+
byte
|
| 7 |
+
case
|
| 8 |
+
catch
|
| 9 |
+
char
|
| 10 |
+
checked
|
| 11 |
+
class
|
| 12 |
+
const
|
| 13 |
+
continue
|
| 14 |
+
decimal
|
| 15 |
+
default
|
| 16 |
+
delegate
|
| 17 |
+
do
|
| 18 |
+
double
|
| 19 |
+
else
|
| 20 |
+
enum
|
| 21 |
+
event
|
| 22 |
+
explicit
|
| 23 |
+
extern
|
| 24 |
+
false
|
| 25 |
+
finally
|
| 26 |
+
fixed
|
| 27 |
+
float
|
| 28 |
+
for
|
| 29 |
+
foreach
|
| 30 |
+
goto
|
| 31 |
+
if
|
| 32 |
+
implicit
|
| 33 |
+
in
|
| 34 |
+
int
|
| 35 |
+
interface
|
| 36 |
+
internal
|
| 37 |
+
is
|
| 38 |
+
lock
|
| 39 |
+
long
|
| 40 |
+
namespace
|
| 41 |
+
new
|
| 42 |
+
null
|
| 43 |
+
object
|
| 44 |
+
operator
|
| 45 |
+
out
|
| 46 |
+
override
|
| 47 |
+
params
|
| 48 |
+
private
|
| 49 |
+
protected
|
| 50 |
+
public
|
| 51 |
+
readonly
|
| 52 |
+
ref
|
| 53 |
+
return
|
| 54 |
+
sbyte
|
| 55 |
+
sealed
|
| 56 |
+
short
|
| 57 |
+
sizeof
|
| 58 |
+
stackalloc
|
| 59 |
+
static
|
| 60 |
+
string
|
| 61 |
+
struct
|
| 62 |
+
switch
|
| 63 |
+
this
|
| 64 |
+
throw
|
| 65 |
+
true
|
| 66 |
+
try
|
| 67 |
+
typeof
|
| 68 |
+
uint
|
| 69 |
+
ulong
|
| 70 |
+
unchecked
|
| 71 |
+
unsafe
|
| 72 |
+
ushort
|
| 73 |
+
using
|
| 74 |
+
virtual
|
| 75 |
+
void
|
| 76 |
+
volatile
|
| 77 |
+
while
|
| 78 |
+
add
|
| 79 |
+
alias
|
| 80 |
+
ascending
|
| 81 |
+
async
|
| 82 |
+
await
|
| 83 |
+
by
|
| 84 |
+
descending
|
| 85 |
+
dynamic
|
| 86 |
+
equals
|
| 87 |
+
from
|
| 88 |
+
get
|
| 89 |
+
global
|
| 90 |
+
group
|
| 91 |
+
into
|
| 92 |
+
join
|
| 93 |
+
let
|
| 94 |
+
nameof
|
| 95 |
+
notnull
|
| 96 |
+
on
|
| 97 |
+
orderby
|
| 98 |
+
partial
|
| 99 |
+
remove
|
| 100 |
+
select
|
| 101 |
+
set
|
| 102 |
+
unmanaged
|
| 103 |
+
value
|
| 104 |
+
var
|
| 105 |
+
when
|
| 106 |
+
where
|
| 107 |
+
yield
|
evaluator/CodeBLEU/keywords/java.txt
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
abstract
|
| 2 |
+
assert
|
| 3 |
+
boolean
|
| 4 |
+
break
|
| 5 |
+
byte
|
| 6 |
+
case
|
| 7 |
+
catch
|
| 8 |
+
char
|
| 9 |
+
class
|
| 10 |
+
const
|
| 11 |
+
continue
|
| 12 |
+
default
|
| 13 |
+
do
|
| 14 |
+
double
|
| 15 |
+
else
|
| 16 |
+
enum
|
| 17 |
+
extends
|
| 18 |
+
final
|
| 19 |
+
finally
|
| 20 |
+
float
|
| 21 |
+
for
|
| 22 |
+
goto
|
| 23 |
+
if
|
| 24 |
+
implements
|
| 25 |
+
import
|
| 26 |
+
instanceof
|
| 27 |
+
int
|
| 28 |
+
interface
|
| 29 |
+
long
|
| 30 |
+
native
|
| 31 |
+
new
|
| 32 |
+
package
|
| 33 |
+
private
|
| 34 |
+
protected
|
| 35 |
+
public
|
| 36 |
+
return
|
| 37 |
+
short
|
| 38 |
+
static
|
| 39 |
+
strictfp
|
| 40 |
+
super
|
| 41 |
+
switch
|
| 42 |
+
synchronized
|
| 43 |
+
this
|
| 44 |
+
throw
|
| 45 |
+
throws
|
| 46 |
+
transient
|
| 47 |
+
try
|
| 48 |
+
void
|
| 49 |
+
volatile
|
| 50 |
+
while
|
evaluator/CodeBLEU/parser/DFG.py
ADDED
|
@@ -0,0 +1,1184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from tree_sitter import Language, Parser
|
| 5 |
+
from .utils import (remove_comments_and_docstrings,
|
| 6 |
+
tree_to_token_index,
|
| 7 |
+
index_to_code_token,
|
| 8 |
+
tree_to_variable_index)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def DFG_python(root_node,index_to_code,states):
|
| 12 |
+
assignment=['assignment','augmented_assignment','for_in_clause']
|
| 13 |
+
if_statement=['if_statement']
|
| 14 |
+
for_statement=['for_statement']
|
| 15 |
+
while_statement=['while_statement']
|
| 16 |
+
do_first_statement=['for_in_clause']
|
| 17 |
+
def_statement=['default_parameter']
|
| 18 |
+
states=states.copy()
|
| 19 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 20 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 21 |
+
if root_node.type==code:
|
| 22 |
+
return [],states
|
| 23 |
+
elif code in states:
|
| 24 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 25 |
+
else:
|
| 26 |
+
if root_node.type=='identifier':
|
| 27 |
+
states[code]=[idx]
|
| 28 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 29 |
+
elif root_node.type in def_statement:
|
| 30 |
+
name=root_node.child_by_field_name('name')
|
| 31 |
+
value=root_node.child_by_field_name('value')
|
| 32 |
+
DFG=[]
|
| 33 |
+
if value is None:
|
| 34 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 35 |
+
for index in indexs:
|
| 36 |
+
idx,code=index_to_code[index]
|
| 37 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 38 |
+
states[code]=[idx]
|
| 39 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 40 |
+
else:
|
| 41 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 42 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 43 |
+
temp,states=DFG_python(value,index_to_code,states)
|
| 44 |
+
DFG+=temp
|
| 45 |
+
for index1 in name_indexs:
|
| 46 |
+
idx1,code1=index_to_code[index1]
|
| 47 |
+
for index2 in value_indexs:
|
| 48 |
+
idx2,code2=index_to_code[index2]
|
| 49 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 50 |
+
states[code1]=[idx1]
|
| 51 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 52 |
+
elif root_node.type in assignment:
|
| 53 |
+
if root_node.type=='for_in_clause':
|
| 54 |
+
right_nodes=[root_node.children[-1]]
|
| 55 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 56 |
+
else:
|
| 57 |
+
if root_node.child_by_field_name('right') is None:
|
| 58 |
+
return [],states
|
| 59 |
+
left_nodes=[x for x in root_node.child_by_field_name('left').children if x.type!=',']
|
| 60 |
+
right_nodes=[x for x in root_node.child_by_field_name('right').children if x.type!=',']
|
| 61 |
+
if len(right_nodes)!=len(left_nodes):
|
| 62 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 63 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 64 |
+
if len(left_nodes)==0:
|
| 65 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 66 |
+
if len(right_nodes)==0:
|
| 67 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 68 |
+
DFG=[]
|
| 69 |
+
for node in right_nodes:
|
| 70 |
+
temp,states=DFG_python(node,index_to_code,states)
|
| 71 |
+
DFG+=temp
|
| 72 |
+
|
| 73 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 74 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 75 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 76 |
+
temp=[]
|
| 77 |
+
for token1_index in left_tokens_index:
|
| 78 |
+
idx1,code1=index_to_code[token1_index]
|
| 79 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 80 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 81 |
+
states[code1]=[idx1]
|
| 82 |
+
DFG+=temp
|
| 83 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 84 |
+
elif root_node.type in if_statement:
|
| 85 |
+
DFG=[]
|
| 86 |
+
current_states=states.copy()
|
| 87 |
+
others_states=[]
|
| 88 |
+
tag=False
|
| 89 |
+
if 'else' in root_node.type:
|
| 90 |
+
tag=True
|
| 91 |
+
for child in root_node.children:
|
| 92 |
+
if 'else' in child.type:
|
| 93 |
+
tag=True
|
| 94 |
+
if child.type not in ['elif_clause','else_clause']:
|
| 95 |
+
temp,current_states=DFG_python(child,index_to_code,current_states)
|
| 96 |
+
DFG+=temp
|
| 97 |
+
else:
|
| 98 |
+
temp,new_states=DFG_python(child,index_to_code,states)
|
| 99 |
+
DFG+=temp
|
| 100 |
+
others_states.append(new_states)
|
| 101 |
+
others_states.append(current_states)
|
| 102 |
+
if tag is False:
|
| 103 |
+
others_states.append(states)
|
| 104 |
+
new_states={}
|
| 105 |
+
for dic in others_states:
|
| 106 |
+
for key in dic:
|
| 107 |
+
if key not in new_states:
|
| 108 |
+
new_states[key]=dic[key].copy()
|
| 109 |
+
else:
|
| 110 |
+
new_states[key]+=dic[key]
|
| 111 |
+
for key in new_states:
|
| 112 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 113 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 114 |
+
elif root_node.type in for_statement:
|
| 115 |
+
DFG=[]
|
| 116 |
+
for i in range(2):
|
| 117 |
+
right_nodes=[x for x in root_node.child_by_field_name('right').children if x.type!=',']
|
| 118 |
+
left_nodes=[x for x in root_node.child_by_field_name('left').children if x.type!=',']
|
| 119 |
+
if len(right_nodes)!=len(left_nodes):
|
| 120 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 121 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 122 |
+
if len(left_nodes)==0:
|
| 123 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 124 |
+
if len(right_nodes)==0:
|
| 125 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 126 |
+
for node in right_nodes:
|
| 127 |
+
temp,states=DFG_python(node,index_to_code,states)
|
| 128 |
+
DFG+=temp
|
| 129 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 130 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 131 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 132 |
+
temp=[]
|
| 133 |
+
for token1_index in left_tokens_index:
|
| 134 |
+
idx1,code1=index_to_code[token1_index]
|
| 135 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 136 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 137 |
+
states[code1]=[idx1]
|
| 138 |
+
DFG+=temp
|
| 139 |
+
if root_node.children[-1].type=="block":
|
| 140 |
+
temp,states=DFG_python(root_node.children[-1],index_to_code,states)
|
| 141 |
+
DFG+=temp
|
| 142 |
+
dic={}
|
| 143 |
+
for x in DFG:
|
| 144 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 145 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 146 |
+
else:
|
| 147 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 148 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 149 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 150 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 151 |
+
elif root_node.type in while_statement:
|
| 152 |
+
DFG=[]
|
| 153 |
+
for i in range(2):
|
| 154 |
+
for child in root_node.children:
|
| 155 |
+
temp,states=DFG_python(child,index_to_code,states)
|
| 156 |
+
DFG+=temp
|
| 157 |
+
dic={}
|
| 158 |
+
for x in DFG:
|
| 159 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 160 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 161 |
+
else:
|
| 162 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 163 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 164 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 165 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 166 |
+
else:
|
| 167 |
+
DFG=[]
|
| 168 |
+
for child in root_node.children:
|
| 169 |
+
if child.type in do_first_statement:
|
| 170 |
+
temp,states=DFG_python(child,index_to_code,states)
|
| 171 |
+
DFG+=temp
|
| 172 |
+
for child in root_node.children:
|
| 173 |
+
if child.type not in do_first_statement:
|
| 174 |
+
temp,states=DFG_python(child,index_to_code,states)
|
| 175 |
+
DFG+=temp
|
| 176 |
+
|
| 177 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
def DFG_java(root_node,index_to_code,states):
|
| 181 |
+
assignment=['assignment_expression']
|
| 182 |
+
def_statement=['variable_declarator']
|
| 183 |
+
increment_statement=['update_expression']
|
| 184 |
+
if_statement=['if_statement','else']
|
| 185 |
+
for_statement=['for_statement']
|
| 186 |
+
enhanced_for_statement=['enhanced_for_statement']
|
| 187 |
+
while_statement=['while_statement']
|
| 188 |
+
do_first_statement=[]
|
| 189 |
+
states=states.copy()
|
| 190 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 191 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 192 |
+
if root_node.type==code:
|
| 193 |
+
return [],states
|
| 194 |
+
elif code in states:
|
| 195 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 196 |
+
else:
|
| 197 |
+
if root_node.type=='identifier':
|
| 198 |
+
states[code]=[idx]
|
| 199 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 200 |
+
elif root_node.type in def_statement:
|
| 201 |
+
name=root_node.child_by_field_name('name')
|
| 202 |
+
value=root_node.child_by_field_name('value')
|
| 203 |
+
DFG=[]
|
| 204 |
+
if value is None:
|
| 205 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 206 |
+
for index in indexs:
|
| 207 |
+
idx,code=index_to_code[index]
|
| 208 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 209 |
+
states[code]=[idx]
|
| 210 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 211 |
+
else:
|
| 212 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 213 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 214 |
+
temp,states=DFG_java(value,index_to_code,states)
|
| 215 |
+
DFG+=temp
|
| 216 |
+
for index1 in name_indexs:
|
| 217 |
+
idx1,code1=index_to_code[index1]
|
| 218 |
+
for index2 in value_indexs:
|
| 219 |
+
idx2,code2=index_to_code[index2]
|
| 220 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 221 |
+
states[code1]=[idx1]
|
| 222 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 223 |
+
elif root_node.type in assignment:
|
| 224 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 225 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 226 |
+
DFG=[]
|
| 227 |
+
temp,states=DFG_java(right_nodes,index_to_code,states)
|
| 228 |
+
DFG+=temp
|
| 229 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 230 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 231 |
+
for index1 in name_indexs:
|
| 232 |
+
idx1,code1=index_to_code[index1]
|
| 233 |
+
for index2 in value_indexs:
|
| 234 |
+
idx2,code2=index_to_code[index2]
|
| 235 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 236 |
+
states[code1]=[idx1]
|
| 237 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 238 |
+
elif root_node.type in increment_statement:
|
| 239 |
+
DFG=[]
|
| 240 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 241 |
+
for index1 in indexs:
|
| 242 |
+
idx1,code1=index_to_code[index1]
|
| 243 |
+
for index2 in indexs:
|
| 244 |
+
idx2,code2=index_to_code[index2]
|
| 245 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 246 |
+
states[code1]=[idx1]
|
| 247 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 248 |
+
elif root_node.type in if_statement:
|
| 249 |
+
DFG=[]
|
| 250 |
+
current_states=states.copy()
|
| 251 |
+
others_states=[]
|
| 252 |
+
flag=False
|
| 253 |
+
tag=False
|
| 254 |
+
if 'else' in root_node.type:
|
| 255 |
+
tag=True
|
| 256 |
+
for child in root_node.children:
|
| 257 |
+
if 'else' in child.type:
|
| 258 |
+
tag=True
|
| 259 |
+
if child.type not in if_statement and flag is False:
|
| 260 |
+
temp,current_states=DFG_java(child,index_to_code,current_states)
|
| 261 |
+
DFG+=temp
|
| 262 |
+
else:
|
| 263 |
+
flag=True
|
| 264 |
+
temp,new_states=DFG_java(child,index_to_code,states)
|
| 265 |
+
DFG+=temp
|
| 266 |
+
others_states.append(new_states)
|
| 267 |
+
others_states.append(current_states)
|
| 268 |
+
if tag is False:
|
| 269 |
+
others_states.append(states)
|
| 270 |
+
new_states={}
|
| 271 |
+
for dic in others_states:
|
| 272 |
+
for key in dic:
|
| 273 |
+
if key not in new_states:
|
| 274 |
+
new_states[key]=dic[key].copy()
|
| 275 |
+
else:
|
| 276 |
+
new_states[key]+=dic[key]
|
| 277 |
+
for key in new_states:
|
| 278 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 279 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 280 |
+
elif root_node.type in for_statement:
|
| 281 |
+
DFG=[]
|
| 282 |
+
for child in root_node.children:
|
| 283 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 284 |
+
DFG+=temp
|
| 285 |
+
flag=False
|
| 286 |
+
for child in root_node.children:
|
| 287 |
+
if flag:
|
| 288 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 289 |
+
DFG+=temp
|
| 290 |
+
elif child.type=="local_variable_declaration":
|
| 291 |
+
flag=True
|
| 292 |
+
dic={}
|
| 293 |
+
for x in DFG:
|
| 294 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 295 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 296 |
+
else:
|
| 297 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 298 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 299 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 300 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 301 |
+
elif root_node.type in enhanced_for_statement:
|
| 302 |
+
name=root_node.child_by_field_name('name')
|
| 303 |
+
value=root_node.child_by_field_name('value')
|
| 304 |
+
body=root_node.child_by_field_name('body')
|
| 305 |
+
DFG=[]
|
| 306 |
+
for i in range(2):
|
| 307 |
+
temp,states=DFG_java(value,index_to_code,states)
|
| 308 |
+
DFG+=temp
|
| 309 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 310 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 311 |
+
for index1 in name_indexs:
|
| 312 |
+
idx1,code1=index_to_code[index1]
|
| 313 |
+
for index2 in value_indexs:
|
| 314 |
+
idx2,code2=index_to_code[index2]
|
| 315 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 316 |
+
states[code1]=[idx1]
|
| 317 |
+
temp,states=DFG_java(body,index_to_code,states)
|
| 318 |
+
DFG+=temp
|
| 319 |
+
dic={}
|
| 320 |
+
for x in DFG:
|
| 321 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 322 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 323 |
+
else:
|
| 324 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 325 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 326 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 327 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 328 |
+
elif root_node.type in while_statement:
|
| 329 |
+
DFG=[]
|
| 330 |
+
for i in range(2):
|
| 331 |
+
for child in root_node.children:
|
| 332 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 333 |
+
DFG+=temp
|
| 334 |
+
dic={}
|
| 335 |
+
for x in DFG:
|
| 336 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 337 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 338 |
+
else:
|
| 339 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 340 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 341 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 342 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 343 |
+
else:
|
| 344 |
+
DFG=[]
|
| 345 |
+
for child in root_node.children:
|
| 346 |
+
if child.type in do_first_statement:
|
| 347 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 348 |
+
DFG+=temp
|
| 349 |
+
for child in root_node.children:
|
| 350 |
+
if child.type not in do_first_statement:
|
| 351 |
+
temp,states=DFG_java(child,index_to_code,states)
|
| 352 |
+
DFG+=temp
|
| 353 |
+
|
| 354 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 355 |
+
|
| 356 |
+
def DFG_csharp(root_node,index_to_code,states):
|
| 357 |
+
assignment=['assignment_expression']
|
| 358 |
+
def_statement=['variable_declarator']
|
| 359 |
+
increment_statement=['postfix_unary_expression']
|
| 360 |
+
if_statement=['if_statement','else']
|
| 361 |
+
for_statement=['for_statement']
|
| 362 |
+
enhanced_for_statement=['for_each_statement']
|
| 363 |
+
while_statement=['while_statement']
|
| 364 |
+
do_first_statement=[]
|
| 365 |
+
states=states.copy()
|
| 366 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 367 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 368 |
+
if root_node.type==code:
|
| 369 |
+
return [],states
|
| 370 |
+
elif code in states:
|
| 371 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 372 |
+
else:
|
| 373 |
+
if root_node.type=='identifier':
|
| 374 |
+
states[code]=[idx]
|
| 375 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 376 |
+
elif root_node.type in def_statement:
|
| 377 |
+
if len(root_node.children)==2:
|
| 378 |
+
name=root_node.children[0]
|
| 379 |
+
value=root_node.children[1]
|
| 380 |
+
else:
|
| 381 |
+
name=root_node.children[0]
|
| 382 |
+
value=None
|
| 383 |
+
DFG=[]
|
| 384 |
+
if value is None:
|
| 385 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 386 |
+
for index in indexs:
|
| 387 |
+
idx,code=index_to_code[index]
|
| 388 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 389 |
+
states[code]=[idx]
|
| 390 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 391 |
+
else:
|
| 392 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 393 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 394 |
+
temp,states=DFG_csharp(value,index_to_code,states)
|
| 395 |
+
DFG+=temp
|
| 396 |
+
for index1 in name_indexs:
|
| 397 |
+
idx1,code1=index_to_code[index1]
|
| 398 |
+
for index2 in value_indexs:
|
| 399 |
+
idx2,code2=index_to_code[index2]
|
| 400 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 401 |
+
states[code1]=[idx1]
|
| 402 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 403 |
+
elif root_node.type in assignment:
|
| 404 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 405 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 406 |
+
DFG=[]
|
| 407 |
+
temp,states=DFG_csharp(right_nodes,index_to_code,states)
|
| 408 |
+
DFG+=temp
|
| 409 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 410 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 411 |
+
for index1 in name_indexs:
|
| 412 |
+
idx1,code1=index_to_code[index1]
|
| 413 |
+
for index2 in value_indexs:
|
| 414 |
+
idx2,code2=index_to_code[index2]
|
| 415 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 416 |
+
states[code1]=[idx1]
|
| 417 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 418 |
+
elif root_node.type in increment_statement:
|
| 419 |
+
DFG=[]
|
| 420 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 421 |
+
for index1 in indexs:
|
| 422 |
+
idx1,code1=index_to_code[index1]
|
| 423 |
+
for index2 in indexs:
|
| 424 |
+
idx2,code2=index_to_code[index2]
|
| 425 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 426 |
+
states[code1]=[idx1]
|
| 427 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 428 |
+
elif root_node.type in if_statement:
|
| 429 |
+
DFG=[]
|
| 430 |
+
current_states=states.copy()
|
| 431 |
+
others_states=[]
|
| 432 |
+
flag=False
|
| 433 |
+
tag=False
|
| 434 |
+
if 'else' in root_node.type:
|
| 435 |
+
tag=True
|
| 436 |
+
for child in root_node.children:
|
| 437 |
+
if 'else' in child.type:
|
| 438 |
+
tag=True
|
| 439 |
+
if child.type not in if_statement and flag is False:
|
| 440 |
+
temp,current_states=DFG_csharp(child,index_to_code,current_states)
|
| 441 |
+
DFG+=temp
|
| 442 |
+
else:
|
| 443 |
+
flag=True
|
| 444 |
+
temp,new_states=DFG_csharp(child,index_to_code,states)
|
| 445 |
+
DFG+=temp
|
| 446 |
+
others_states.append(new_states)
|
| 447 |
+
others_states.append(current_states)
|
| 448 |
+
if tag is False:
|
| 449 |
+
others_states.append(states)
|
| 450 |
+
new_states={}
|
| 451 |
+
for dic in others_states:
|
| 452 |
+
for key in dic:
|
| 453 |
+
if key not in new_states:
|
| 454 |
+
new_states[key]=dic[key].copy()
|
| 455 |
+
else:
|
| 456 |
+
new_states[key]+=dic[key]
|
| 457 |
+
for key in new_states:
|
| 458 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 459 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 460 |
+
elif root_node.type in for_statement:
|
| 461 |
+
DFG=[]
|
| 462 |
+
for child in root_node.children:
|
| 463 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 464 |
+
DFG+=temp
|
| 465 |
+
flag=False
|
| 466 |
+
for child in root_node.children:
|
| 467 |
+
if flag:
|
| 468 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 469 |
+
DFG+=temp
|
| 470 |
+
elif child.type=="local_variable_declaration":
|
| 471 |
+
flag=True
|
| 472 |
+
dic={}
|
| 473 |
+
for x in DFG:
|
| 474 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 475 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 476 |
+
else:
|
| 477 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 478 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 479 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 480 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 481 |
+
elif root_node.type in enhanced_for_statement:
|
| 482 |
+
name=root_node.child_by_field_name('left')
|
| 483 |
+
value=root_node.child_by_field_name('right')
|
| 484 |
+
body=root_node.child_by_field_name('body')
|
| 485 |
+
DFG=[]
|
| 486 |
+
for i in range(2):
|
| 487 |
+
temp,states=DFG_csharp(value,index_to_code,states)
|
| 488 |
+
DFG+=temp
|
| 489 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 490 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 491 |
+
for index1 in name_indexs:
|
| 492 |
+
idx1,code1=index_to_code[index1]
|
| 493 |
+
for index2 in value_indexs:
|
| 494 |
+
idx2,code2=index_to_code[index2]
|
| 495 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 496 |
+
states[code1]=[idx1]
|
| 497 |
+
temp,states=DFG_csharp(body,index_to_code,states)
|
| 498 |
+
DFG+=temp
|
| 499 |
+
dic={}
|
| 500 |
+
for x in DFG:
|
| 501 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 502 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 503 |
+
else:
|
| 504 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 505 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 506 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 507 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 508 |
+
elif root_node.type in while_statement:
|
| 509 |
+
DFG=[]
|
| 510 |
+
for i in range(2):
|
| 511 |
+
for child in root_node.children:
|
| 512 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 513 |
+
DFG+=temp
|
| 514 |
+
dic={}
|
| 515 |
+
for x in DFG:
|
| 516 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 517 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 518 |
+
else:
|
| 519 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 520 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 521 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 522 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 523 |
+
else:
|
| 524 |
+
DFG=[]
|
| 525 |
+
for child in root_node.children:
|
| 526 |
+
if child.type in do_first_statement:
|
| 527 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 528 |
+
DFG+=temp
|
| 529 |
+
for child in root_node.children:
|
| 530 |
+
if child.type not in do_first_statement:
|
| 531 |
+
temp,states=DFG_csharp(child,index_to_code,states)
|
| 532 |
+
DFG+=temp
|
| 533 |
+
|
| 534 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 535 |
+
|
| 536 |
+
|
| 537 |
+
|
| 538 |
+
|
| 539 |
+
def DFG_ruby(root_node,index_to_code,states):
|
| 540 |
+
assignment=['assignment','operator_assignment']
|
| 541 |
+
if_statement=['if','elsif','else','unless','when']
|
| 542 |
+
for_statement=['for']
|
| 543 |
+
while_statement=['while_modifier','until']
|
| 544 |
+
do_first_statement=[]
|
| 545 |
+
def_statement=['keyword_parameter']
|
| 546 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 547 |
+
states=states.copy()
|
| 548 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 549 |
+
if root_node.type==code:
|
| 550 |
+
return [],states
|
| 551 |
+
elif code in states:
|
| 552 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 553 |
+
else:
|
| 554 |
+
if root_node.type=='identifier':
|
| 555 |
+
states[code]=[idx]
|
| 556 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 557 |
+
elif root_node.type in def_statement:
|
| 558 |
+
name=root_node.child_by_field_name('name')
|
| 559 |
+
value=root_node.child_by_field_name('value')
|
| 560 |
+
DFG=[]
|
| 561 |
+
if value is None:
|
| 562 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 563 |
+
for index in indexs:
|
| 564 |
+
idx,code=index_to_code[index]
|
| 565 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 566 |
+
states[code]=[idx]
|
| 567 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 568 |
+
else:
|
| 569 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 570 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 571 |
+
temp,states=DFG_ruby(value,index_to_code,states)
|
| 572 |
+
DFG+=temp
|
| 573 |
+
for index1 in name_indexs:
|
| 574 |
+
idx1,code1=index_to_code[index1]
|
| 575 |
+
for index2 in value_indexs:
|
| 576 |
+
idx2,code2=index_to_code[index2]
|
| 577 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 578 |
+
states[code1]=[idx1]
|
| 579 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 580 |
+
elif root_node.type in assignment:
|
| 581 |
+
left_nodes=[x for x in root_node.child_by_field_name('left').children if x.type!=',']
|
| 582 |
+
right_nodes=[x for x in root_node.child_by_field_name('right').children if x.type!=',']
|
| 583 |
+
if len(right_nodes)!=len(left_nodes):
|
| 584 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 585 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 586 |
+
if len(left_nodes)==0:
|
| 587 |
+
left_nodes=[root_node.child_by_field_name('left')]
|
| 588 |
+
if len(right_nodes)==0:
|
| 589 |
+
right_nodes=[root_node.child_by_field_name('right')]
|
| 590 |
+
if root_node.type=="operator_assignment":
|
| 591 |
+
left_nodes=[root_node.children[0]]
|
| 592 |
+
right_nodes=[root_node.children[-1]]
|
| 593 |
+
|
| 594 |
+
DFG=[]
|
| 595 |
+
for node in right_nodes:
|
| 596 |
+
temp,states=DFG_ruby(node,index_to_code,states)
|
| 597 |
+
DFG+=temp
|
| 598 |
+
|
| 599 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 600 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 601 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 602 |
+
temp=[]
|
| 603 |
+
for token1_index in left_tokens_index:
|
| 604 |
+
idx1,code1=index_to_code[token1_index]
|
| 605 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 606 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 607 |
+
states[code1]=[idx1]
|
| 608 |
+
DFG+=temp
|
| 609 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 610 |
+
elif root_node.type in if_statement:
|
| 611 |
+
DFG=[]
|
| 612 |
+
current_states=states.copy()
|
| 613 |
+
others_states=[]
|
| 614 |
+
tag=False
|
| 615 |
+
if 'else' in root_node.type:
|
| 616 |
+
tag=True
|
| 617 |
+
for child in root_node.children:
|
| 618 |
+
if 'else' in child.type:
|
| 619 |
+
tag=True
|
| 620 |
+
if child.type not in if_statement:
|
| 621 |
+
temp,current_states=DFG_ruby(child,index_to_code,current_states)
|
| 622 |
+
DFG+=temp
|
| 623 |
+
else:
|
| 624 |
+
temp,new_states=DFG_ruby(child,index_to_code,states)
|
| 625 |
+
DFG+=temp
|
| 626 |
+
others_states.append(new_states)
|
| 627 |
+
others_states.append(current_states)
|
| 628 |
+
if tag is False:
|
| 629 |
+
others_states.append(states)
|
| 630 |
+
new_states={}
|
| 631 |
+
for dic in others_states:
|
| 632 |
+
for key in dic:
|
| 633 |
+
if key not in new_states:
|
| 634 |
+
new_states[key]=dic[key].copy()
|
| 635 |
+
else:
|
| 636 |
+
new_states[key]+=dic[key]
|
| 637 |
+
for key in new_states:
|
| 638 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 639 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 640 |
+
elif root_node.type in for_statement:
|
| 641 |
+
DFG=[]
|
| 642 |
+
for i in range(2):
|
| 643 |
+
left_nodes=[root_node.child_by_field_name('pattern')]
|
| 644 |
+
right_nodes=[root_node.child_by_field_name('value')]
|
| 645 |
+
assert len(right_nodes)==len(left_nodes)
|
| 646 |
+
for node in right_nodes:
|
| 647 |
+
temp,states=DFG_ruby(node,index_to_code,states)
|
| 648 |
+
DFG+=temp
|
| 649 |
+
for left_node,right_node in zip(left_nodes,right_nodes):
|
| 650 |
+
left_tokens_index=tree_to_variable_index(left_node,index_to_code)
|
| 651 |
+
right_tokens_index=tree_to_variable_index(right_node,index_to_code)
|
| 652 |
+
temp=[]
|
| 653 |
+
for token1_index in left_tokens_index:
|
| 654 |
+
idx1,code1=index_to_code[token1_index]
|
| 655 |
+
temp.append((code1,idx1,'computedFrom',[index_to_code[x][1] for x in right_tokens_index],
|
| 656 |
+
[index_to_code[x][0] for x in right_tokens_index]))
|
| 657 |
+
states[code1]=[idx1]
|
| 658 |
+
DFG+=temp
|
| 659 |
+
temp,states=DFG_ruby(root_node.child_by_field_name('body'),index_to_code,states)
|
| 660 |
+
DFG+=temp
|
| 661 |
+
dic={}
|
| 662 |
+
for x in DFG:
|
| 663 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 664 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 665 |
+
else:
|
| 666 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 667 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 668 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 669 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 670 |
+
elif root_node.type in while_statement:
|
| 671 |
+
DFG=[]
|
| 672 |
+
for i in range(2):
|
| 673 |
+
for child in root_node.children:
|
| 674 |
+
temp,states=DFG_ruby(child,index_to_code,states)
|
| 675 |
+
DFG+=temp
|
| 676 |
+
dic={}
|
| 677 |
+
for x in DFG:
|
| 678 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 679 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 680 |
+
else:
|
| 681 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 682 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 683 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 684 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 685 |
+
else:
|
| 686 |
+
DFG=[]
|
| 687 |
+
for child in root_node.children:
|
| 688 |
+
if child.type in do_first_statement:
|
| 689 |
+
temp,states=DFG_ruby(child,index_to_code,states)
|
| 690 |
+
DFG+=temp
|
| 691 |
+
for child in root_node.children:
|
| 692 |
+
if child.type not in do_first_statement:
|
| 693 |
+
temp,states=DFG_ruby(child,index_to_code,states)
|
| 694 |
+
DFG+=temp
|
| 695 |
+
|
| 696 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 697 |
+
|
| 698 |
+
def DFG_go(root_node,index_to_code,states):
|
| 699 |
+
assignment=['assignment_statement',]
|
| 700 |
+
def_statement=['var_spec']
|
| 701 |
+
increment_statement=['inc_statement']
|
| 702 |
+
if_statement=['if_statement','else']
|
| 703 |
+
for_statement=['for_statement']
|
| 704 |
+
enhanced_for_statement=[]
|
| 705 |
+
while_statement=[]
|
| 706 |
+
do_first_statement=[]
|
| 707 |
+
states=states.copy()
|
| 708 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 709 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 710 |
+
if root_node.type==code:
|
| 711 |
+
return [],states
|
| 712 |
+
elif code in states:
|
| 713 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 714 |
+
else:
|
| 715 |
+
if root_node.type=='identifier':
|
| 716 |
+
states[code]=[idx]
|
| 717 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 718 |
+
elif root_node.type in def_statement:
|
| 719 |
+
name=root_node.child_by_field_name('name')
|
| 720 |
+
value=root_node.child_by_field_name('value')
|
| 721 |
+
DFG=[]
|
| 722 |
+
if value is None:
|
| 723 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 724 |
+
for index in indexs:
|
| 725 |
+
idx,code=index_to_code[index]
|
| 726 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 727 |
+
states[code]=[idx]
|
| 728 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 729 |
+
else:
|
| 730 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 731 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 732 |
+
temp,states=DFG_go(value,index_to_code,states)
|
| 733 |
+
DFG+=temp
|
| 734 |
+
for index1 in name_indexs:
|
| 735 |
+
idx1,code1=index_to_code[index1]
|
| 736 |
+
for index2 in value_indexs:
|
| 737 |
+
idx2,code2=index_to_code[index2]
|
| 738 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 739 |
+
states[code1]=[idx1]
|
| 740 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 741 |
+
elif root_node.type in assignment:
|
| 742 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 743 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 744 |
+
DFG=[]
|
| 745 |
+
temp,states=DFG_go(right_nodes,index_to_code,states)
|
| 746 |
+
DFG+=temp
|
| 747 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 748 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 749 |
+
for index1 in name_indexs:
|
| 750 |
+
idx1,code1=index_to_code[index1]
|
| 751 |
+
for index2 in value_indexs:
|
| 752 |
+
idx2,code2=index_to_code[index2]
|
| 753 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 754 |
+
states[code1]=[idx1]
|
| 755 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 756 |
+
elif root_node.type in increment_statement:
|
| 757 |
+
DFG=[]
|
| 758 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 759 |
+
for index1 in indexs:
|
| 760 |
+
idx1,code1=index_to_code[index1]
|
| 761 |
+
for index2 in indexs:
|
| 762 |
+
idx2,code2=index_to_code[index2]
|
| 763 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 764 |
+
states[code1]=[idx1]
|
| 765 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 766 |
+
elif root_node.type in if_statement:
|
| 767 |
+
DFG=[]
|
| 768 |
+
current_states=states.copy()
|
| 769 |
+
others_states=[]
|
| 770 |
+
flag=False
|
| 771 |
+
tag=False
|
| 772 |
+
if 'else' in root_node.type:
|
| 773 |
+
tag=True
|
| 774 |
+
for child in root_node.children:
|
| 775 |
+
if 'else' in child.type:
|
| 776 |
+
tag=True
|
| 777 |
+
if child.type not in if_statement and flag is False:
|
| 778 |
+
temp,current_states=DFG_go(child,index_to_code,current_states)
|
| 779 |
+
DFG+=temp
|
| 780 |
+
else:
|
| 781 |
+
flag=True
|
| 782 |
+
temp,new_states=DFG_go(child,index_to_code,states)
|
| 783 |
+
DFG+=temp
|
| 784 |
+
others_states.append(new_states)
|
| 785 |
+
others_states.append(current_states)
|
| 786 |
+
if tag is False:
|
| 787 |
+
others_states.append(states)
|
| 788 |
+
new_states={}
|
| 789 |
+
for dic in others_states:
|
| 790 |
+
for key in dic:
|
| 791 |
+
if key not in new_states:
|
| 792 |
+
new_states[key]=dic[key].copy()
|
| 793 |
+
else:
|
| 794 |
+
new_states[key]+=dic[key]
|
| 795 |
+
for key in states:
|
| 796 |
+
if key not in new_states:
|
| 797 |
+
new_states[key]=states[key]
|
| 798 |
+
else:
|
| 799 |
+
new_states[key]+=states[key]
|
| 800 |
+
for key in new_states:
|
| 801 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 802 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 803 |
+
elif root_node.type in for_statement:
|
| 804 |
+
DFG=[]
|
| 805 |
+
for child in root_node.children:
|
| 806 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 807 |
+
DFG+=temp
|
| 808 |
+
flag=False
|
| 809 |
+
for child in root_node.children:
|
| 810 |
+
if flag:
|
| 811 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 812 |
+
DFG+=temp
|
| 813 |
+
elif child.type=="for_clause":
|
| 814 |
+
if child.child_by_field_name('update') is not None:
|
| 815 |
+
temp,states=DFG_go(child.child_by_field_name('update'),index_to_code,states)
|
| 816 |
+
DFG+=temp
|
| 817 |
+
flag=True
|
| 818 |
+
dic={}
|
| 819 |
+
for x in DFG:
|
| 820 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 821 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 822 |
+
else:
|
| 823 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 824 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 825 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 826 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 827 |
+
else:
|
| 828 |
+
DFG=[]
|
| 829 |
+
for child in root_node.children:
|
| 830 |
+
if child.type in do_first_statement:
|
| 831 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 832 |
+
DFG+=temp
|
| 833 |
+
for child in root_node.children:
|
| 834 |
+
if child.type not in do_first_statement:
|
| 835 |
+
temp,states=DFG_go(child,index_to_code,states)
|
| 836 |
+
DFG+=temp
|
| 837 |
+
|
| 838 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 839 |
+
|
| 840 |
+
|
| 841 |
+
|
| 842 |
+
|
| 843 |
+
def DFG_php(root_node,index_to_code,states):
|
| 844 |
+
assignment=['assignment_expression','augmented_assignment_expression']
|
| 845 |
+
def_statement=['simple_parameter']
|
| 846 |
+
increment_statement=['update_expression']
|
| 847 |
+
if_statement=['if_statement','else_clause']
|
| 848 |
+
for_statement=['for_statement']
|
| 849 |
+
enhanced_for_statement=['foreach_statement']
|
| 850 |
+
while_statement=['while_statement']
|
| 851 |
+
do_first_statement=[]
|
| 852 |
+
states=states.copy()
|
| 853 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 854 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 855 |
+
if root_node.type==code:
|
| 856 |
+
return [],states
|
| 857 |
+
elif code in states:
|
| 858 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 859 |
+
else:
|
| 860 |
+
if root_node.type=='identifier':
|
| 861 |
+
states[code]=[idx]
|
| 862 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 863 |
+
elif root_node.type in def_statement:
|
| 864 |
+
name=root_node.child_by_field_name('name')
|
| 865 |
+
value=root_node.child_by_field_name('default_value')
|
| 866 |
+
DFG=[]
|
| 867 |
+
if value is None:
|
| 868 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 869 |
+
for index in indexs:
|
| 870 |
+
idx,code=index_to_code[index]
|
| 871 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 872 |
+
states[code]=[idx]
|
| 873 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 874 |
+
else:
|
| 875 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 876 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 877 |
+
temp,states=DFG_php(value,index_to_code,states)
|
| 878 |
+
DFG+=temp
|
| 879 |
+
for index1 in name_indexs:
|
| 880 |
+
idx1,code1=index_to_code[index1]
|
| 881 |
+
for index2 in value_indexs:
|
| 882 |
+
idx2,code2=index_to_code[index2]
|
| 883 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 884 |
+
states[code1]=[idx1]
|
| 885 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 886 |
+
elif root_node.type in assignment:
|
| 887 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 888 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 889 |
+
DFG=[]
|
| 890 |
+
temp,states=DFG_php(right_nodes,index_to_code,states)
|
| 891 |
+
DFG+=temp
|
| 892 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 893 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 894 |
+
for index1 in name_indexs:
|
| 895 |
+
idx1,code1=index_to_code[index1]
|
| 896 |
+
for index2 in value_indexs:
|
| 897 |
+
idx2,code2=index_to_code[index2]
|
| 898 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 899 |
+
states[code1]=[idx1]
|
| 900 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 901 |
+
elif root_node.type in increment_statement:
|
| 902 |
+
DFG=[]
|
| 903 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 904 |
+
for index1 in indexs:
|
| 905 |
+
idx1,code1=index_to_code[index1]
|
| 906 |
+
for index2 in indexs:
|
| 907 |
+
idx2,code2=index_to_code[index2]
|
| 908 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 909 |
+
states[code1]=[idx1]
|
| 910 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 911 |
+
elif root_node.type in if_statement:
|
| 912 |
+
DFG=[]
|
| 913 |
+
current_states=states.copy()
|
| 914 |
+
others_states=[]
|
| 915 |
+
flag=False
|
| 916 |
+
tag=False
|
| 917 |
+
if 'else' in root_node.type:
|
| 918 |
+
tag=True
|
| 919 |
+
for child in root_node.children:
|
| 920 |
+
if 'else' in child.type:
|
| 921 |
+
tag=True
|
| 922 |
+
if child.type not in if_statement and flag is False:
|
| 923 |
+
temp,current_states=DFG_php(child,index_to_code,current_states)
|
| 924 |
+
DFG+=temp
|
| 925 |
+
else:
|
| 926 |
+
flag=True
|
| 927 |
+
temp,new_states=DFG_php(child,index_to_code,states)
|
| 928 |
+
DFG+=temp
|
| 929 |
+
others_states.append(new_states)
|
| 930 |
+
others_states.append(current_states)
|
| 931 |
+
new_states={}
|
| 932 |
+
for dic in others_states:
|
| 933 |
+
for key in dic:
|
| 934 |
+
if key not in new_states:
|
| 935 |
+
new_states[key]=dic[key].copy()
|
| 936 |
+
else:
|
| 937 |
+
new_states[key]+=dic[key]
|
| 938 |
+
for key in states:
|
| 939 |
+
if key not in new_states:
|
| 940 |
+
new_states[key]=states[key]
|
| 941 |
+
else:
|
| 942 |
+
new_states[key]+=states[key]
|
| 943 |
+
for key in new_states:
|
| 944 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 945 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 946 |
+
elif root_node.type in for_statement:
|
| 947 |
+
DFG=[]
|
| 948 |
+
for child in root_node.children:
|
| 949 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 950 |
+
DFG+=temp
|
| 951 |
+
flag=False
|
| 952 |
+
for child in root_node.children:
|
| 953 |
+
if flag:
|
| 954 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 955 |
+
DFG+=temp
|
| 956 |
+
elif child.type=="assignment_expression":
|
| 957 |
+
flag=True
|
| 958 |
+
dic={}
|
| 959 |
+
for x in DFG:
|
| 960 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 961 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 962 |
+
else:
|
| 963 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 964 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 965 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 966 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 967 |
+
elif root_node.type in enhanced_for_statement:
|
| 968 |
+
name=None
|
| 969 |
+
value=None
|
| 970 |
+
for child in root_node.children:
|
| 971 |
+
if child.type=='variable_name' and value is None:
|
| 972 |
+
value=child
|
| 973 |
+
elif child.type=='variable_name' and name is None:
|
| 974 |
+
name=child
|
| 975 |
+
break
|
| 976 |
+
body=root_node.child_by_field_name('body')
|
| 977 |
+
DFG=[]
|
| 978 |
+
for i in range(2):
|
| 979 |
+
temp,states=DFG_php(value,index_to_code,states)
|
| 980 |
+
DFG+=temp
|
| 981 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 982 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 983 |
+
for index1 in name_indexs:
|
| 984 |
+
idx1,code1=index_to_code[index1]
|
| 985 |
+
for index2 in value_indexs:
|
| 986 |
+
idx2,code2=index_to_code[index2]
|
| 987 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 988 |
+
states[code1]=[idx1]
|
| 989 |
+
temp,states=DFG_php(body,index_to_code,states)
|
| 990 |
+
DFG+=temp
|
| 991 |
+
dic={}
|
| 992 |
+
for x in DFG:
|
| 993 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 994 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 995 |
+
else:
|
| 996 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 997 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 998 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 999 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1000 |
+
elif root_node.type in while_statement:
|
| 1001 |
+
DFG=[]
|
| 1002 |
+
for i in range(2):
|
| 1003 |
+
for child in root_node.children:
|
| 1004 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 1005 |
+
DFG+=temp
|
| 1006 |
+
dic={}
|
| 1007 |
+
for x in DFG:
|
| 1008 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 1009 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 1010 |
+
else:
|
| 1011 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 1012 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 1013 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 1014 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1015 |
+
else:
|
| 1016 |
+
DFG=[]
|
| 1017 |
+
for child in root_node.children:
|
| 1018 |
+
if child.type in do_first_statement:
|
| 1019 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 1020 |
+
DFG+=temp
|
| 1021 |
+
for child in root_node.children:
|
| 1022 |
+
if child.type not in do_first_statement:
|
| 1023 |
+
temp,states=DFG_php(child,index_to_code,states)
|
| 1024 |
+
DFG+=temp
|
| 1025 |
+
|
| 1026 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1027 |
+
|
| 1028 |
+
|
| 1029 |
+
def DFG_javascript(root_node,index_to_code,states):
|
| 1030 |
+
assignment=['assignment_pattern','augmented_assignment_expression']
|
| 1031 |
+
def_statement=['variable_declarator']
|
| 1032 |
+
increment_statement=['update_expression']
|
| 1033 |
+
if_statement=['if_statement','else']
|
| 1034 |
+
for_statement=['for_statement']
|
| 1035 |
+
enhanced_for_statement=[]
|
| 1036 |
+
while_statement=['while_statement']
|
| 1037 |
+
do_first_statement=[]
|
| 1038 |
+
states=states.copy()
|
| 1039 |
+
if (len(root_node.children)==0 or root_node.type in ['string_literal','string','character_literal']) and root_node.type!='comment':
|
| 1040 |
+
idx,code=index_to_code[(root_node.start_point,root_node.end_point)]
|
| 1041 |
+
if root_node.type==code:
|
| 1042 |
+
return [],states
|
| 1043 |
+
elif code in states:
|
| 1044 |
+
return [(code,idx,'comesFrom',[code],states[code].copy())],states
|
| 1045 |
+
else:
|
| 1046 |
+
if root_node.type=='identifier':
|
| 1047 |
+
states[code]=[idx]
|
| 1048 |
+
return [(code,idx,'comesFrom',[],[])],states
|
| 1049 |
+
elif root_node.type in def_statement:
|
| 1050 |
+
name=root_node.child_by_field_name('name')
|
| 1051 |
+
value=root_node.child_by_field_name('value')
|
| 1052 |
+
DFG=[]
|
| 1053 |
+
if value is None:
|
| 1054 |
+
indexs=tree_to_variable_index(name,index_to_code)
|
| 1055 |
+
for index in indexs:
|
| 1056 |
+
idx,code=index_to_code[index]
|
| 1057 |
+
DFG.append((code,idx,'comesFrom',[],[]))
|
| 1058 |
+
states[code]=[idx]
|
| 1059 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1060 |
+
else:
|
| 1061 |
+
name_indexs=tree_to_variable_index(name,index_to_code)
|
| 1062 |
+
value_indexs=tree_to_variable_index(value,index_to_code)
|
| 1063 |
+
temp,states=DFG_javascript(value,index_to_code,states)
|
| 1064 |
+
DFG+=temp
|
| 1065 |
+
for index1 in name_indexs:
|
| 1066 |
+
idx1,code1=index_to_code[index1]
|
| 1067 |
+
for index2 in value_indexs:
|
| 1068 |
+
idx2,code2=index_to_code[index2]
|
| 1069 |
+
DFG.append((code1,idx1,'comesFrom',[code2],[idx2]))
|
| 1070 |
+
states[code1]=[idx1]
|
| 1071 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1072 |
+
elif root_node.type in assignment:
|
| 1073 |
+
left_nodes=root_node.child_by_field_name('left')
|
| 1074 |
+
right_nodes=root_node.child_by_field_name('right')
|
| 1075 |
+
DFG=[]
|
| 1076 |
+
temp,states=DFG_javascript(right_nodes,index_to_code,states)
|
| 1077 |
+
DFG+=temp
|
| 1078 |
+
name_indexs=tree_to_variable_index(left_nodes,index_to_code)
|
| 1079 |
+
value_indexs=tree_to_variable_index(right_nodes,index_to_code)
|
| 1080 |
+
for index1 in name_indexs:
|
| 1081 |
+
idx1,code1=index_to_code[index1]
|
| 1082 |
+
for index2 in value_indexs:
|
| 1083 |
+
idx2,code2=index_to_code[index2]
|
| 1084 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 1085 |
+
states[code1]=[idx1]
|
| 1086 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1087 |
+
elif root_node.type in increment_statement:
|
| 1088 |
+
DFG=[]
|
| 1089 |
+
indexs=tree_to_variable_index(root_node,index_to_code)
|
| 1090 |
+
for index1 in indexs:
|
| 1091 |
+
idx1,code1=index_to_code[index1]
|
| 1092 |
+
for index2 in indexs:
|
| 1093 |
+
idx2,code2=index_to_code[index2]
|
| 1094 |
+
DFG.append((code1,idx1,'computedFrom',[code2],[idx2]))
|
| 1095 |
+
states[code1]=[idx1]
|
| 1096 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1097 |
+
elif root_node.type in if_statement:
|
| 1098 |
+
DFG=[]
|
| 1099 |
+
current_states=states.copy()
|
| 1100 |
+
others_states=[]
|
| 1101 |
+
flag=False
|
| 1102 |
+
tag=False
|
| 1103 |
+
if 'else' in root_node.type:
|
| 1104 |
+
tag=True
|
| 1105 |
+
for child in root_node.children:
|
| 1106 |
+
if 'else' in child.type:
|
| 1107 |
+
tag=True
|
| 1108 |
+
if child.type not in if_statement and flag is False:
|
| 1109 |
+
temp,current_states=DFG_javascript(child,index_to_code,current_states)
|
| 1110 |
+
DFG+=temp
|
| 1111 |
+
else:
|
| 1112 |
+
flag=True
|
| 1113 |
+
temp,new_states=DFG_javascript(child,index_to_code,states)
|
| 1114 |
+
DFG+=temp
|
| 1115 |
+
others_states.append(new_states)
|
| 1116 |
+
others_states.append(current_states)
|
| 1117 |
+
if tag is False:
|
| 1118 |
+
others_states.append(states)
|
| 1119 |
+
new_states={}
|
| 1120 |
+
for dic in others_states:
|
| 1121 |
+
for key in dic:
|
| 1122 |
+
if key not in new_states:
|
| 1123 |
+
new_states[key]=dic[key].copy()
|
| 1124 |
+
else:
|
| 1125 |
+
new_states[key]+=dic[key]
|
| 1126 |
+
for key in states:
|
| 1127 |
+
if key not in new_states:
|
| 1128 |
+
new_states[key]=states[key]
|
| 1129 |
+
else:
|
| 1130 |
+
new_states[key]+=states[key]
|
| 1131 |
+
for key in new_states:
|
| 1132 |
+
new_states[key]=sorted(list(set(new_states[key])))
|
| 1133 |
+
return sorted(DFG,key=lambda x:x[1]),new_states
|
| 1134 |
+
elif root_node.type in for_statement:
|
| 1135 |
+
DFG=[]
|
| 1136 |
+
for child in root_node.children:
|
| 1137 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1138 |
+
DFG+=temp
|
| 1139 |
+
flag=False
|
| 1140 |
+
for child in root_node.children:
|
| 1141 |
+
if flag:
|
| 1142 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1143 |
+
DFG+=temp
|
| 1144 |
+
elif child.type=="variable_declaration":
|
| 1145 |
+
flag=True
|
| 1146 |
+
dic={}
|
| 1147 |
+
for x in DFG:
|
| 1148 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 1149 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 1150 |
+
else:
|
| 1151 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 1152 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 1153 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 1154 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1155 |
+
elif root_node.type in while_statement:
|
| 1156 |
+
DFG=[]
|
| 1157 |
+
for i in range(2):
|
| 1158 |
+
for child in root_node.children:
|
| 1159 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1160 |
+
DFG+=temp
|
| 1161 |
+
dic={}
|
| 1162 |
+
for x in DFG:
|
| 1163 |
+
if (x[0],x[1],x[2]) not in dic:
|
| 1164 |
+
dic[(x[0],x[1],x[2])]=[x[3],x[4]]
|
| 1165 |
+
else:
|
| 1166 |
+
dic[(x[0],x[1],x[2])][0]=list(set(dic[(x[0],x[1],x[2])][0]+x[3]))
|
| 1167 |
+
dic[(x[0],x[1],x[2])][1]=sorted(list(set(dic[(x[0],x[1],x[2])][1]+x[4])))
|
| 1168 |
+
DFG=[(x[0],x[1],x[2],y[0],y[1]) for x,y in sorted(dic.items(),key=lambda t:t[0][1])]
|
| 1169 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1170 |
+
else:
|
| 1171 |
+
DFG=[]
|
| 1172 |
+
for child in root_node.children:
|
| 1173 |
+
if child.type in do_first_statement:
|
| 1174 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1175 |
+
DFG+=temp
|
| 1176 |
+
for child in root_node.children:
|
| 1177 |
+
if child.type not in do_first_statement:
|
| 1178 |
+
temp,states=DFG_javascript(child,index_to_code,states)
|
| 1179 |
+
DFG+=temp
|
| 1180 |
+
|
| 1181 |
+
return sorted(DFG,key=lambda x:x[1]),states
|
| 1182 |
+
|
| 1183 |
+
|
| 1184 |
+
|
evaluator/CodeBLEU/parser/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from .utils import (remove_comments_and_docstrings,
|
| 5 |
+
tree_to_token_index,
|
| 6 |
+
index_to_code_token,
|
| 7 |
+
tree_to_variable_index)
|
| 8 |
+
from .DFG import DFG_python,DFG_java,DFG_ruby,DFG_go,DFG_php,DFG_javascript,DFG_csharp
|
evaluator/CodeBLEU/parser/build.py
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from tree_sitter import Language, Parser
|
| 5 |
+
|
| 6 |
+
Language.build_library(
|
| 7 |
+
# Store the library in the `build` directory
|
| 8 |
+
'my-languages.so',
|
| 9 |
+
|
| 10 |
+
# Include one or more languages
|
| 11 |
+
[
|
| 12 |
+
'tree-sitter-go',
|
| 13 |
+
'tree-sitter-javascript',
|
| 14 |
+
'tree-sitter-python',
|
| 15 |
+
'tree-sitter-php',
|
| 16 |
+
'tree-sitter-java',
|
| 17 |
+
'tree-sitter-ruby',
|
| 18 |
+
'tree-sitter-c-sharp',
|
| 19 |
+
]
|
| 20 |
+
)
|
| 21 |
+
|
evaluator/CodeBLEU/parser/build.sh
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
git clone https://github.com/tree-sitter/tree-sitter-go
|
| 2 |
+
git clone https://github.com/tree-sitter/tree-sitter-javascript
|
| 3 |
+
git clone https://github.com/tree-sitter/tree-sitter-python
|
| 4 |
+
git clone https://github.com/tree-sitter/tree-sitter-ruby
|
| 5 |
+
git clone https://github.com/tree-sitter/tree-sitter-php
|
| 6 |
+
git clone https://github.com/tree-sitter/tree-sitter-java
|
| 7 |
+
git clone https://github.com/tree-sitter/tree-sitter-c-sharp
|
| 8 |
+
python build.py
|
evaluator/CodeBLEU/parser/my-languages.so
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:66d01dcb2f38f3ff418839a10b856d4a5e2ef38f472c21ad7c6fb4bd14fc307d
|
| 3 |
+
size 3000336
|
evaluator/CodeBLEU/parser/utils.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
import re
|
| 5 |
+
from io import StringIO
|
| 6 |
+
import tokenize
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def remove_comments_and_docstrings(source, lang):
|
| 10 |
+
if lang in ['python']:
|
| 11 |
+
"""
|
| 12 |
+
Returns 'source' minus comments and docstrings.
|
| 13 |
+
"""
|
| 14 |
+
io_obj = StringIO(source)
|
| 15 |
+
out = ""
|
| 16 |
+
prev_toktype = tokenize.INDENT
|
| 17 |
+
last_lineno = -1
|
| 18 |
+
last_col = 0
|
| 19 |
+
for tok in tokenize.generate_tokens(io_obj.readline):
|
| 20 |
+
token_type = tok[0]
|
| 21 |
+
token_string = tok[1]
|
| 22 |
+
start_line, start_col = tok[2]
|
| 23 |
+
end_line, end_col = tok[3]
|
| 24 |
+
ltext = tok[4]
|
| 25 |
+
if start_line > last_lineno:
|
| 26 |
+
last_col = 0
|
| 27 |
+
if start_col > last_col:
|
| 28 |
+
out += (" " * (start_col - last_col))
|
| 29 |
+
# Remove comments:
|
| 30 |
+
if token_type == tokenize.COMMENT:
|
| 31 |
+
pass
|
| 32 |
+
# This series of conditionals removes docstrings:
|
| 33 |
+
elif token_type == tokenize.STRING:
|
| 34 |
+
if prev_toktype != tokenize.INDENT:
|
| 35 |
+
# This is likely a docstring; double-check we're not inside an operator:
|
| 36 |
+
if prev_toktype != tokenize.NEWLINE:
|
| 37 |
+
if start_col > 0:
|
| 38 |
+
out += token_string
|
| 39 |
+
else:
|
| 40 |
+
out += token_string
|
| 41 |
+
prev_toktype = token_type
|
| 42 |
+
last_col = end_col
|
| 43 |
+
last_lineno = end_line
|
| 44 |
+
temp = []
|
| 45 |
+
for x in out.split('\n'):
|
| 46 |
+
if x.strip() != "":
|
| 47 |
+
temp.append(x)
|
| 48 |
+
return '\n'.join(temp)
|
| 49 |
+
elif lang in ['ruby']:
|
| 50 |
+
return source
|
| 51 |
+
else:
|
| 52 |
+
def replacer(match):
|
| 53 |
+
s = match.group(0)
|
| 54 |
+
if s.startswith('/'):
|
| 55 |
+
return " " # note: a space and not an empty string
|
| 56 |
+
else:
|
| 57 |
+
return s
|
| 58 |
+
|
| 59 |
+
pattern = re.compile(
|
| 60 |
+
r'//.*?$|/\*.*?\*/|\'(?:\\.|[^\\\'])*\'|"(?:\\.|[^\\"])*"',
|
| 61 |
+
re.DOTALL | re.MULTILINE
|
| 62 |
+
)
|
| 63 |
+
temp = []
|
| 64 |
+
for x in re.sub(pattern, replacer, source).split('\n'):
|
| 65 |
+
if x.strip() != "":
|
| 66 |
+
temp.append(x)
|
| 67 |
+
return '\n'.join(temp)
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def tree_to_token_index(root_node):
|
| 71 |
+
if (len(root_node.children) == 0 or root_node.type in ['string_literal', 'string',
|
| 72 |
+
'character_literal']) and root_node.type != 'comment':
|
| 73 |
+
return [(root_node.start_point, root_node.end_point)]
|
| 74 |
+
else:
|
| 75 |
+
code_tokens = []
|
| 76 |
+
for child in root_node.children:
|
| 77 |
+
code_tokens += tree_to_token_index(child)
|
| 78 |
+
return code_tokens
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def tree_to_variable_index(root_node, index_to_code):
|
| 82 |
+
if (len(root_node.children) == 0 or root_node.type in ['string_literal', 'string',
|
| 83 |
+
'character_literal']) and root_node.type != 'comment':
|
| 84 |
+
index = (root_node.start_point, root_node.end_point)
|
| 85 |
+
_, code = index_to_code[index]
|
| 86 |
+
if root_node.type != code:
|
| 87 |
+
return [(root_node.start_point, root_node.end_point)]
|
| 88 |
+
else:
|
| 89 |
+
return []
|
| 90 |
+
else:
|
| 91 |
+
code_tokens = []
|
| 92 |
+
for child in root_node.children:
|
| 93 |
+
code_tokens += tree_to_variable_index(child, index_to_code)
|
| 94 |
+
return code_tokens
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def index_to_code_token(index, code):
|
| 98 |
+
start_point = index[0]
|
| 99 |
+
end_point = index[1]
|
| 100 |
+
if start_point[0] == end_point[0]:
|
| 101 |
+
s = code[start_point[0]][start_point[1]:end_point[1]]
|
| 102 |
+
else:
|
| 103 |
+
s = ""
|
| 104 |
+
s += code[start_point[0]][start_point[1]:]
|
| 105 |
+
for i in range(start_point[0] + 1, end_point[0]):
|
| 106 |
+
s += code[i]
|
| 107 |
+
s += code[end_point[0]][:end_point[1]]
|
| 108 |
+
return s
|
evaluator/CodeBLEU/readme.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
python calc_code_bleu.py --refs reference_files --hyp candidate_file --language java ( or c_sharp) --params 0.25,0.25,0.25,0.25(default)
|
evaluator/CodeBLEU/syntax_match.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Microsoft Corporation.
|
| 2 |
+
# Licensed under the MIT license.
|
| 3 |
+
|
| 4 |
+
from evaluator.CodeBLEU.parser import DFG_python, DFG_java, DFG_ruby, DFG_go, DFG_php, DFG_javascript, DFG_csharp
|
| 5 |
+
from evaluator.CodeBLEU.parser import (remove_comments_and_docstrings,
|
| 6 |
+
tree_to_token_index,
|
| 7 |
+
index_to_code_token,
|
| 8 |
+
tree_to_variable_index)
|
| 9 |
+
from tree_sitter import Language, Parser
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
root_dir = os.path.dirname(__file__)
|
| 13 |
+
dfg_function = {
|
| 14 |
+
'python': DFG_python,
|
| 15 |
+
'java': DFG_java,
|
| 16 |
+
'ruby': DFG_ruby,
|
| 17 |
+
'go': DFG_go,
|
| 18 |
+
'php': DFG_php,
|
| 19 |
+
'javascript': DFG_javascript,
|
| 20 |
+
'c_sharp': DFG_csharp,
|
| 21 |
+
}
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def calc_syntax_match(references, candidate, lang):
|
| 25 |
+
return corpus_syntax_match([references], [candidate], lang)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def corpus_syntax_match(references, candidates, lang):
|
| 29 |
+
JAVA_LANGUAGE = Language(root_dir + '/parser/my-languages.so', lang)
|
| 30 |
+
parser = Parser()
|
| 31 |
+
parser.set_language(JAVA_LANGUAGE)
|
| 32 |
+
match_count = 0
|
| 33 |
+
total_count = 0
|
| 34 |
+
|
| 35 |
+
for i in range(len(candidates)):
|
| 36 |
+
references_sample = references[i]
|
| 37 |
+
candidate = candidates[i]
|
| 38 |
+
for reference in references_sample:
|
| 39 |
+
try:
|
| 40 |
+
candidate = remove_comments_and_docstrings(candidate, 'java')
|
| 41 |
+
except:
|
| 42 |
+
pass
|
| 43 |
+
try:
|
| 44 |
+
reference = remove_comments_and_docstrings(reference, 'java')
|
| 45 |
+
except:
|
| 46 |
+
pass
|
| 47 |
+
|
| 48 |
+
candidate_tree = parser.parse(bytes(candidate, 'utf8')).root_node
|
| 49 |
+
|
| 50 |
+
reference_tree = parser.parse(bytes(reference, 'utf8')).root_node
|
| 51 |
+
|
| 52 |
+
def get_all_sub_trees(root_node):
|
| 53 |
+
node_stack = []
|
| 54 |
+
sub_tree_sexp_list = []
|
| 55 |
+
depth = 1
|
| 56 |
+
node_stack.append([root_node, depth])
|
| 57 |
+
while len(node_stack) != 0:
|
| 58 |
+
cur_node, cur_depth = node_stack.pop()
|
| 59 |
+
sub_tree_sexp_list.append([cur_node.sexp(), cur_depth])
|
| 60 |
+
for child_node in cur_node.children:
|
| 61 |
+
if len(child_node.children) != 0:
|
| 62 |
+
depth = cur_depth + 1
|
| 63 |
+
node_stack.append([child_node, depth])
|
| 64 |
+
return sub_tree_sexp_list
|
| 65 |
+
|
| 66 |
+
cand_sexps = [x[0] for x in get_all_sub_trees(candidate_tree)]
|
| 67 |
+
ref_sexps = get_all_sub_trees(reference_tree)
|
| 68 |
+
|
| 69 |
+
# print(cand_sexps)
|
| 70 |
+
# print(ref_sexps)
|
| 71 |
+
|
| 72 |
+
for sub_tree, depth in ref_sexps:
|
| 73 |
+
if sub_tree in cand_sexps:
|
| 74 |
+
match_count += 1
|
| 75 |
+
total_count += len(ref_sexps)
|
| 76 |
+
|
| 77 |
+
score = match_count / total_count
|
| 78 |
+
return score
|
evaluator/CodeBLEU/utils.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Natural Language Toolkit: Utility functions
|
| 2 |
+
#
|
| 3 |
+
# Copyright (C) 2001-2020 NLTK Project
|
| 4 |
+
# Author: Steven Bird <stevenbird1@gmail.com>
|
| 5 |
+
# URL: <http://nltk.org/>
|
| 6 |
+
# For license information, see LICENSE.TXT
|
| 7 |
+
|
| 8 |
+
from itertools import chain
|
| 9 |
+
|
| 10 |
+
def pad_sequence(
|
| 11 |
+
sequence,
|
| 12 |
+
n,
|
| 13 |
+
pad_left=False,
|
| 14 |
+
pad_right=False,
|
| 15 |
+
left_pad_symbol=None,
|
| 16 |
+
right_pad_symbol=None,
|
| 17 |
+
):
|
| 18 |
+
"""
|
| 19 |
+
Returns a padded sequence of items before ngram extraction.
|
| 20 |
+
>>> list(pad_sequence([1,2,3,4,5], 2, pad_left=True, pad_right=True, left_pad_symbol='<s>', right_pad_symbol='</s>'))
|
| 21 |
+
['<s>', 1, 2, 3, 4, 5, '</s>']
|
| 22 |
+
>>> list(pad_sequence([1,2,3,4,5], 2, pad_left=True, left_pad_symbol='<s>'))
|
| 23 |
+
['<s>', 1, 2, 3, 4, 5]
|
| 24 |
+
>>> list(pad_sequence([1,2,3,4,5], 2, pad_right=True, right_pad_symbol='</s>'))
|
| 25 |
+
[1, 2, 3, 4, 5, '</s>']
|
| 26 |
+
:param sequence: the source data to be padded
|
| 27 |
+
:type sequence: sequence or iter
|
| 28 |
+
:param n: the degree of the ngrams
|
| 29 |
+
:type n: int
|
| 30 |
+
:param pad_left: whether the ngrams should be left-padded
|
| 31 |
+
:type pad_left: bool
|
| 32 |
+
:param pad_right: whether the ngrams should be right-padded
|
| 33 |
+
:type pad_right: bool
|
| 34 |
+
:param left_pad_symbol: the symbol to use for left padding (default is None)
|
| 35 |
+
:type left_pad_symbol: any
|
| 36 |
+
:param right_pad_symbol: the symbol to use for right padding (default is None)
|
| 37 |
+
:type right_pad_symbol: any
|
| 38 |
+
:rtype: sequence or iter
|
| 39 |
+
"""
|
| 40 |
+
sequence = iter(sequence)
|
| 41 |
+
if pad_left:
|
| 42 |
+
sequence = chain((left_pad_symbol,) * (n - 1), sequence)
|
| 43 |
+
if pad_right:
|
| 44 |
+
sequence = chain(sequence, (right_pad_symbol,) * (n - 1))
|
| 45 |
+
return sequence
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
# add a flag to pad the sequence so we get peripheral ngrams?
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def ngrams(
|
| 52 |
+
sequence,
|
| 53 |
+
n,
|
| 54 |
+
pad_left=False,
|
| 55 |
+
pad_right=False,
|
| 56 |
+
left_pad_symbol=None,
|
| 57 |
+
right_pad_symbol=None,
|
| 58 |
+
):
|
| 59 |
+
"""
|
| 60 |
+
Return the ngrams generated from a sequence of items, as an iterator.
|
| 61 |
+
For example:
|
| 62 |
+
>>> from nltk.util import ngrams
|
| 63 |
+
>>> list(ngrams([1,2,3,4,5], 3))
|
| 64 |
+
[(1, 2, 3), (2, 3, 4), (3, 4, 5)]
|
| 65 |
+
Wrap with list for a list version of this function. Set pad_left
|
| 66 |
+
or pad_right to true in order to get additional ngrams:
|
| 67 |
+
>>> list(ngrams([1,2,3,4,5], 2, pad_right=True))
|
| 68 |
+
[(1, 2), (2, 3), (3, 4), (4, 5), (5, None)]
|
| 69 |
+
>>> list(ngrams([1,2,3,4,5], 2, pad_right=True, right_pad_symbol='</s>'))
|
| 70 |
+
[(1, 2), (2, 3), (3, 4), (4, 5), (5, '</s>')]
|
| 71 |
+
>>> list(ngrams([1,2,3,4,5], 2, pad_left=True, left_pad_symbol='<s>'))
|
| 72 |
+
[('<s>', 1), (1, 2), (2, 3), (3, 4), (4, 5)]
|
| 73 |
+
>>> list(ngrams([1,2,3,4,5], 2, pad_left=True, pad_right=True, left_pad_symbol='<s>', right_pad_symbol='</s>'))
|
| 74 |
+
[('<s>', 1), (1, 2), (2, 3), (3, 4), (4, 5), (5, '</s>')]
|
| 75 |
+
:param sequence: the source data to be converted into ngrams
|
| 76 |
+
:type sequence: sequence or iter
|
| 77 |
+
:param n: the degree of the ngrams
|
| 78 |
+
:type n: int
|
| 79 |
+
:param pad_left: whether the ngrams should be left-padded
|
| 80 |
+
:type pad_left: bool
|
| 81 |
+
:param pad_right: whether the ngrams should be right-padded
|
| 82 |
+
:type pad_right: bool
|
| 83 |
+
:param left_pad_symbol: the symbol to use for left padding (default is None)
|
| 84 |
+
:type left_pad_symbol: any
|
| 85 |
+
:param right_pad_symbol: the symbol to use for right padding (default is None)
|
| 86 |
+
:type right_pad_symbol: any
|
| 87 |
+
:rtype: sequence or iter
|
| 88 |
+
"""
|
| 89 |
+
sequence = pad_sequence(
|
| 90 |
+
sequence, n, pad_left, pad_right, left_pad_symbol, right_pad_symbol
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
history = []
|
| 94 |
+
while n > 1:
|
| 95 |
+
# PEP 479, prevent RuntimeError from being raised when StopIteration bubbles out of generator
|
| 96 |
+
try:
|
| 97 |
+
next_item = next(sequence)
|
| 98 |
+
except StopIteration:
|
| 99 |
+
# no more data, terminate the generator
|
| 100 |
+
return
|
| 101 |
+
history.append(next_item)
|
| 102 |
+
n -= 1
|
| 103 |
+
for item in sequence:
|
| 104 |
+
history.append(item)
|
| 105 |
+
yield tuple(history)
|
| 106 |
+
del history[0]
|
evaluator/CodeBLEU/weighted_ngram_match.py
ADDED
|
@@ -0,0 +1,558 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
# Copyright (c) Microsoft Corporation.
|
| 3 |
+
# Licensed under the MIT license.
|
| 4 |
+
|
| 5 |
+
# Natural Language Toolkit: BLEU Score
|
| 6 |
+
#
|
| 7 |
+
# Copyright (C) 2001-2020 NLTK Project
|
| 8 |
+
# Authors: Chin Yee Lee, Hengfeng Li, Ruxin Hou, Calvin Tanujaya Lim
|
| 9 |
+
# Contributors: Björn Mattsson, Dmitrijs Milajevs, Liling Tan
|
| 10 |
+
# URL: <http://nltk.org/>
|
| 11 |
+
# For license information, see LICENSE.TXT
|
| 12 |
+
|
| 13 |
+
"""BLEU score implementation."""
|
| 14 |
+
|
| 15 |
+
import math
|
| 16 |
+
import sys
|
| 17 |
+
from fractions import Fraction
|
| 18 |
+
import warnings
|
| 19 |
+
from collections import Counter
|
| 20 |
+
|
| 21 |
+
from evaluator.CodeBLEU.utils import ngrams
|
| 22 |
+
import pdb
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def sentence_bleu(
|
| 26 |
+
references,
|
| 27 |
+
hypothesis,
|
| 28 |
+
weights=(0.25, 0.25, 0.25, 0.25),
|
| 29 |
+
smoothing_function=None,
|
| 30 |
+
auto_reweigh=False,
|
| 31 |
+
):
|
| 32 |
+
"""
|
| 33 |
+
Calculate BLEU score (Bilingual Evaluation Understudy) from
|
| 34 |
+
Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002.
|
| 35 |
+
"BLEU: a method for automatic evaluation of machine translation."
|
| 36 |
+
In Proceedings of ACL. http://www.aclweb.org/anthology/P02-1040.pdf
|
| 37 |
+
>>> hypothesis1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
|
| 38 |
+
... 'ensures', 'that', 'the', 'military', 'always',
|
| 39 |
+
... 'obeys', 'the', 'commands', 'of', 'the', 'party']
|
| 40 |
+
>>> hypothesis2 = ['It', 'is', 'to', 'insure', 'the', 'troops',
|
| 41 |
+
... 'forever', 'hearing', 'the', 'activity', 'guidebook',
|
| 42 |
+
... 'that', 'party', 'direct']
|
| 43 |
+
>>> reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
|
| 44 |
+
... 'ensures', 'that', 'the', 'military', 'will', 'forever',
|
| 45 |
+
... 'heed', 'Party', 'commands']
|
| 46 |
+
>>> reference2 = ['It', 'is', 'the', 'guiding', 'principle', 'which',
|
| 47 |
+
... 'guarantees', 'the', 'military', 'forces', 'always',
|
| 48 |
+
... 'being', 'under', 'the', 'command', 'of', 'the',
|
| 49 |
+
... 'Party']
|
| 50 |
+
>>> reference3 = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
|
| 51 |
+
... 'army', 'always', 'to', 'heed', 'the', 'directions',
|
| 52 |
+
... 'of', 'the', 'party']
|
| 53 |
+
>>> sentence_bleu([reference1, reference2, reference3], hypothesis1) # doctest: +ELLIPSIS
|
| 54 |
+
0.5045...
|
| 55 |
+
If there is no ngrams overlap for any order of n-grams, BLEU returns the
|
| 56 |
+
value 0. This is because the precision for the order of n-grams without
|
| 57 |
+
overlap is 0, and the geometric mean in the final BLEU score computation
|
| 58 |
+
multiplies the 0 with the precision of other n-grams. This results in 0
|
| 59 |
+
(independently of the precision of the othe n-gram orders). The following
|
| 60 |
+
example has zero 3-gram and 4-gram overlaps:
|
| 61 |
+
>>> round(sentence_bleu([reference1, reference2, reference3], hypothesis2),4) # doctest: +ELLIPSIS
|
| 62 |
+
0.0
|
| 63 |
+
To avoid this harsh behaviour when no ngram overlaps are found a smoothing
|
| 64 |
+
function can be used.
|
| 65 |
+
>>> chencherry = SmoothingFunction()
|
| 66 |
+
>>> sentence_bleu([reference1, reference2, reference3], hypothesis2,
|
| 67 |
+
... smoothing_function=chencherry.method1) # doctest: +ELLIPSIS
|
| 68 |
+
0.0370...
|
| 69 |
+
The default BLEU calculates a score for up to 4-grams using uniform
|
| 70 |
+
weights (this is called BLEU-4). To evaluate your translations with
|
| 71 |
+
higher/lower order ngrams, use customized weights. E.g. when accounting
|
| 72 |
+
for up to 5-grams with uniform weights (this is called BLEU-5) use:
|
| 73 |
+
>>> weights = (1./5., 1./5., 1./5., 1./5., 1./5.)
|
| 74 |
+
>>> sentence_bleu([reference1, reference2, reference3], hypothesis1, weights) # doctest: +ELLIPSIS
|
| 75 |
+
0.3920...
|
| 76 |
+
:param references: reference sentences
|
| 77 |
+
:type references: list(list(str))
|
| 78 |
+
:param hypothesis: a hypothesis sentence
|
| 79 |
+
:type hypothesis: list(str)
|
| 80 |
+
:param weights: weights for unigrams, bigrams, trigrams and so on
|
| 81 |
+
:type weights: list(float)
|
| 82 |
+
:param smoothing_function:
|
| 83 |
+
:type smoothing_function: SmoothingFunction
|
| 84 |
+
:param auto_reweigh: Option to re-normalize the weights uniformly.
|
| 85 |
+
:type auto_reweigh: bool
|
| 86 |
+
:return: The sentence-level BLEU score.
|
| 87 |
+
:rtype: float
|
| 88 |
+
"""
|
| 89 |
+
return corpus_bleu(
|
| 90 |
+
[references], [hypothesis], weights, smoothing_function, auto_reweigh
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def corpus_bleu(
|
| 95 |
+
list_of_references,
|
| 96 |
+
hypotheses,
|
| 97 |
+
weights=(0.25, 0.25, 0.25, 0.25),
|
| 98 |
+
smoothing_function=None,
|
| 99 |
+
auto_reweigh=False,
|
| 100 |
+
):
|
| 101 |
+
"""
|
| 102 |
+
Calculate a single corpus-level BLEU score (aka. system-level BLEU) for all
|
| 103 |
+
the hypotheses and their respective references.
|
| 104 |
+
Instead of averaging the sentence level BLEU scores (i.e. marco-average
|
| 105 |
+
precision), the original BLEU metric (Papineni et al. 2002) accounts for
|
| 106 |
+
the micro-average precision (i.e. summing the numerators and denominators
|
| 107 |
+
for each hypothesis-reference(s) pairs before the division).
|
| 108 |
+
>>> hyp1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which',
|
| 109 |
+
... 'ensures', 'that', 'the', 'military', 'always',
|
| 110 |
+
... 'obeys', 'the', 'commands', 'of', 'the', 'party']
|
| 111 |
+
>>> ref1a = ['It', 'is', 'a', 'guide', 'to', 'action', 'that',
|
| 112 |
+
... 'ensures', 'that', 'the', 'military', 'will', 'forever',
|
| 113 |
+
... 'heed', 'Party', 'commands']
|
| 114 |
+
>>> ref1b = ['It', 'is', 'the', 'guiding', 'principle', 'which',
|
| 115 |
+
... 'guarantees', 'the', 'military', 'forces', 'always',
|
| 116 |
+
... 'being', 'under', 'the', 'command', 'of', 'the', 'Party']
|
| 117 |
+
>>> ref1c = ['It', 'is', 'the', 'practical', 'guide', 'for', 'the',
|
| 118 |
+
... 'army', 'always', 'to', 'heed', 'the', 'directions',
|
| 119 |
+
... 'of', 'the', 'party']
|
| 120 |
+
>>> hyp2 = ['he', 'read', 'the', 'book', 'because', 'he', 'was',
|
| 121 |
+
... 'interested', 'in', 'world', 'history']
|
| 122 |
+
>>> ref2a = ['he', 'was', 'interested', 'in', 'world', 'history',
|
| 123 |
+
... 'because', 'he', 'read', 'the', 'book']
|
| 124 |
+
>>> list_of_references = [[ref1a, ref1b, ref1c], [ref2a]]
|
| 125 |
+
>>> hypotheses = [hyp1, hyp2]
|
| 126 |
+
>>> corpus_bleu(list_of_references, hypotheses) # doctest: +ELLIPSIS
|
| 127 |
+
0.5920...
|
| 128 |
+
The example below show that corpus_bleu() is different from averaging
|
| 129 |
+
sentence_bleu() for hypotheses
|
| 130 |
+
>>> score1 = sentence_bleu([ref1a, ref1b, ref1c], hyp1)
|
| 131 |
+
>>> score2 = sentence_bleu([ref2a], hyp2)
|
| 132 |
+
>>> (score1 + score2) / 2 # doctest: +ELLIPSIS
|
| 133 |
+
0.6223...
|
| 134 |
+
:param list_of_references: a corpus of lists of reference sentences, w.r.t. hypotheses
|
| 135 |
+
:type list_of_references: list(list(list(str)))
|
| 136 |
+
:param hypotheses: a list of hypothesis sentences
|
| 137 |
+
:type hypotheses: list(list(str))
|
| 138 |
+
:param weights: weights for unigrams, bigrams, trigrams and so on
|
| 139 |
+
:type weights: list(float)
|
| 140 |
+
:param smoothing_function:
|
| 141 |
+
:type smoothing_function: SmoothingFunction
|
| 142 |
+
:param auto_reweigh: Option to re-normalize the weights uniformly.
|
| 143 |
+
:type auto_reweigh: bool
|
| 144 |
+
:return: The corpus-level BLEU score.
|
| 145 |
+
:rtype: float
|
| 146 |
+
"""
|
| 147 |
+
# Before proceeding to compute BLEU, perform sanity checks.
|
| 148 |
+
|
| 149 |
+
p_numerators = Counter() # Key = ngram order, and value = no. of ngram matches.
|
| 150 |
+
p_denominators = Counter() # Key = ngram order, and value = no. of ngram in ref.
|
| 151 |
+
hyp_lengths, ref_lengths = 0, 0
|
| 152 |
+
|
| 153 |
+
assert len(list_of_references) == len(hypotheses), (
|
| 154 |
+
"The number of hypotheses and their reference(s) should be the " "same "
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
# Iterate through each hypothesis and their corresponding references.
|
| 158 |
+
for references, hypothesis in zip(list_of_references, hypotheses):
|
| 159 |
+
# For each order of ngram, calculate the numerator and
|
| 160 |
+
# denominator for the corpus-level modified precision.
|
| 161 |
+
for i, _ in enumerate(weights, start=1):
|
| 162 |
+
p_i_numeraotr, p_i_denominator = modified_recall(references, hypothesis, i)
|
| 163 |
+
p_numerators[i] += p_i_numeraotr
|
| 164 |
+
p_denominators[i] += p_i_denominator
|
| 165 |
+
|
| 166 |
+
# Calculate the hypothesis length and the closest reference length.
|
| 167 |
+
# Adds them to the corpus-level hypothesis and reference counts.
|
| 168 |
+
hyp_len = len(hypothesis)
|
| 169 |
+
hyp_lengths += hyp_len
|
| 170 |
+
ref_lengths += closest_ref_length(references, hyp_len)
|
| 171 |
+
|
| 172 |
+
# Calculate corpus-level brevity penalty.
|
| 173 |
+
bp = brevity_penalty(ref_lengths, hyp_lengths)
|
| 174 |
+
|
| 175 |
+
# Uniformly re-weighting based on maximum hypothesis lengths if largest
|
| 176 |
+
# order of n-grams < 4 and weights is set at default.
|
| 177 |
+
if auto_reweigh:
|
| 178 |
+
if hyp_lengths < 4 and weights == (0.25, 0.25, 0.25, 0.25):
|
| 179 |
+
weights = (1 / hyp_lengths,) * hyp_lengths
|
| 180 |
+
|
| 181 |
+
# Collects the various recall values for the different ngram orders.
|
| 182 |
+
p_n = [
|
| 183 |
+
(p_numerators[i], p_denominators[i])
|
| 184 |
+
for i, _ in enumerate(weights, start=1)
|
| 185 |
+
]
|
| 186 |
+
|
| 187 |
+
# Returns 0 if there's no matching n-grams
|
| 188 |
+
# We only need to check for p_numerators[1] == 0, since if there's
|
| 189 |
+
# no unigrams, there won't be any higher order ngrams.
|
| 190 |
+
if p_numerators[1] == 0:
|
| 191 |
+
return 0
|
| 192 |
+
|
| 193 |
+
# If there's no smoothing, set use method0 from SmoothinFunction class.
|
| 194 |
+
if not smoothing_function:
|
| 195 |
+
smoothing_function = SmoothingFunction().method1
|
| 196 |
+
# Smoothen the modified precision.
|
| 197 |
+
# Note: smoothing_function() may convert values into floats;
|
| 198 |
+
# it tries to retain the Fraction object as much as the
|
| 199 |
+
# smoothing method allows.
|
| 200 |
+
p_n = smoothing_function(
|
| 201 |
+
p_n, references=references, hypothesis=hypothesis, hyp_len=hyp_lengths
|
| 202 |
+
)
|
| 203 |
+
# pdb.set_trace()
|
| 204 |
+
s = (w_i * math.log(p_i[0]/p_i[1]) for w_i, p_i in zip(weights, p_n))
|
| 205 |
+
s = bp * math.exp(math.fsum(s))
|
| 206 |
+
return s
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def modified_recall(references, hypothesis, n):
|
| 210 |
+
"""
|
| 211 |
+
Calculate modified ngram recall.
|
| 212 |
+
:param references: A list of reference translations.
|
| 213 |
+
:type references: list(list(str))
|
| 214 |
+
:param hypothesis: A hypothesis translation.
|
| 215 |
+
:type hypothesis: list(str)
|
| 216 |
+
:param n: The ngram order.
|
| 217 |
+
:type n: int
|
| 218 |
+
:return: BLEU's modified precision for the nth order ngram.
|
| 219 |
+
:rtype: Fraction
|
| 220 |
+
"""
|
| 221 |
+
# Extracts all ngrams in hypothesis
|
| 222 |
+
# Set an empty Counter if hypothesis is empty.
|
| 223 |
+
# pdb.set_trace()
|
| 224 |
+
numerator = 0
|
| 225 |
+
denominator = 0
|
| 226 |
+
|
| 227 |
+
counts = Counter(ngrams(hypothesis, n)) if len(hypothesis) >= n else Counter()
|
| 228 |
+
# Extract a union of references' counts.
|
| 229 |
+
# max_counts = reduce(or_, [Counter(ngrams(ref, n)) for ref in references])
|
| 230 |
+
max_counts = {}
|
| 231 |
+
for reference_and_weights in references:
|
| 232 |
+
reference = reference_and_weights[0]
|
| 233 |
+
weights = reference_and_weights[1]
|
| 234 |
+
reference_counts = (
|
| 235 |
+
Counter(ngrams(reference, n)) if len(reference) >= n else Counter()
|
| 236 |
+
)
|
| 237 |
+
# for ngram in reference_counts:
|
| 238 |
+
# max_counts[ngram] = max(max_counts.get(ngram, 0), counts[ngram])
|
| 239 |
+
clipped_counts = {
|
| 240 |
+
ngram: min(count, counts[ngram]) for ngram, count in reference_counts.items()
|
| 241 |
+
}
|
| 242 |
+
# reweight
|
| 243 |
+
if n == 1 and len(weights) == len(reference_counts):
|
| 244 |
+
def weighted_sum(weights, counts):
|
| 245 |
+
sum_counts = 0
|
| 246 |
+
for ngram, count in counts.items():
|
| 247 |
+
sum_counts += count * (weights[ngram[0]] if ngram[0] in weights else 1)
|
| 248 |
+
return sum_counts
|
| 249 |
+
|
| 250 |
+
numerator += weighted_sum(weights, clipped_counts)
|
| 251 |
+
denominator += max(1, weighted_sum(weights, reference_counts))
|
| 252 |
+
|
| 253 |
+
else:
|
| 254 |
+
numerator += sum(clipped_counts.values())
|
| 255 |
+
denominator += max(1, sum(reference_counts.values()))
|
| 256 |
+
|
| 257 |
+
# # Assigns the intersection between hypothesis and references' counts.
|
| 258 |
+
# clipped_counts = {
|
| 259 |
+
# ngram: min(count, max_counts[ngram]) for ngram, count in counts.items()
|
| 260 |
+
# }
|
| 261 |
+
|
| 262 |
+
# numerator += sum(clipped_counts.values())
|
| 263 |
+
# # Ensures that denominator is minimum 1 to avoid ZeroDivisionError.
|
| 264 |
+
# # Usually this happens when the ngram order is > len(reference).
|
| 265 |
+
# denominator += max(1, sum(counts.values()))
|
| 266 |
+
|
| 267 |
+
#return Fraction(numerator, denominator, _normalize=False)
|
| 268 |
+
return numerator, denominator
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
def closest_ref_length(references, hyp_len):
|
| 272 |
+
"""
|
| 273 |
+
This function finds the reference that is the closest length to the
|
| 274 |
+
hypothesis. The closest reference length is referred to as *r* variable
|
| 275 |
+
from the brevity penalty formula in Papineni et. al. (2002)
|
| 276 |
+
:param references: A list of reference translations.
|
| 277 |
+
:type references: list(list(str))
|
| 278 |
+
:param hyp_len: The length of the hypothesis.
|
| 279 |
+
:type hyp_len: int
|
| 280 |
+
:return: The length of the reference that's closest to the hypothesis.
|
| 281 |
+
:rtype: int
|
| 282 |
+
"""
|
| 283 |
+
ref_lens = (len(reference) for reference in references)
|
| 284 |
+
closest_ref_len = min(
|
| 285 |
+
ref_lens, key=lambda ref_len: (abs(ref_len - hyp_len), ref_len)
|
| 286 |
+
)
|
| 287 |
+
return closest_ref_len
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def brevity_penalty(closest_ref_len, hyp_len):
|
| 291 |
+
"""
|
| 292 |
+
Calculate brevity penalty.
|
| 293 |
+
As the modified n-gram precision still has the problem from the short
|
| 294 |
+
length sentence, brevity penalty is used to modify the overall BLEU
|
| 295 |
+
score according to length.
|
| 296 |
+
An example from the paper. There are three references with length 12, 15
|
| 297 |
+
and 17. And a concise hypothesis of the length 12. The brevity penalty is 1.
|
| 298 |
+
>>> reference1 = list('aaaaaaaaaaaa') # i.e. ['a'] * 12
|
| 299 |
+
>>> reference2 = list('aaaaaaaaaaaaaaa') # i.e. ['a'] * 15
|
| 300 |
+
>>> reference3 = list('aaaaaaaaaaaaaaaaa') # i.e. ['a'] * 17
|
| 301 |
+
>>> hypothesis = list('aaaaaaaaaaaa') # i.e. ['a'] * 12
|
| 302 |
+
>>> references = [reference1, reference2, reference3]
|
| 303 |
+
>>> hyp_len = len(hypothesis)
|
| 304 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 305 |
+
>>> brevity_penalty(closest_ref_len, hyp_len)
|
| 306 |
+
1.0
|
| 307 |
+
In case a hypothesis translation is shorter than the references, penalty is
|
| 308 |
+
applied.
|
| 309 |
+
>>> references = [['a'] * 28, ['a'] * 28]
|
| 310 |
+
>>> hypothesis = ['a'] * 12
|
| 311 |
+
>>> hyp_len = len(hypothesis)
|
| 312 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 313 |
+
>>> brevity_penalty(closest_ref_len, hyp_len)
|
| 314 |
+
0.2635971381157267
|
| 315 |
+
The length of the closest reference is used to compute the penalty. If the
|
| 316 |
+
length of a hypothesis is 12, and the reference lengths are 13 and 2, the
|
| 317 |
+
penalty is applied because the hypothesis length (12) is less then the
|
| 318 |
+
closest reference length (13).
|
| 319 |
+
>>> references = [['a'] * 13, ['a'] * 2]
|
| 320 |
+
>>> hypothesis = ['a'] * 12
|
| 321 |
+
>>> hyp_len = len(hypothesis)
|
| 322 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 323 |
+
>>> brevity_penalty(closest_ref_len, hyp_len) # doctest: +ELLIPSIS
|
| 324 |
+
0.9200...
|
| 325 |
+
The brevity penalty doesn't depend on reference order. More importantly,
|
| 326 |
+
when two reference sentences are at the same distance, the shortest
|
| 327 |
+
reference sentence length is used.
|
| 328 |
+
>>> references = [['a'] * 13, ['a'] * 11]
|
| 329 |
+
>>> hypothesis = ['a'] * 12
|
| 330 |
+
>>> hyp_len = len(hypothesis)
|
| 331 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 332 |
+
>>> bp1 = brevity_penalty(closest_ref_len, hyp_len)
|
| 333 |
+
>>> hyp_len = len(hypothesis)
|
| 334 |
+
>>> closest_ref_len = closest_ref_length(reversed(references), hyp_len)
|
| 335 |
+
>>> bp2 = brevity_penalty(closest_ref_len, hyp_len)
|
| 336 |
+
>>> bp1 == bp2 == 1
|
| 337 |
+
True
|
| 338 |
+
A test example from mteval-v13a.pl (starting from the line 705):
|
| 339 |
+
>>> references = [['a'] * 11, ['a'] * 8]
|
| 340 |
+
>>> hypothesis = ['a'] * 7
|
| 341 |
+
>>> hyp_len = len(hypothesis)
|
| 342 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 343 |
+
>>> brevity_penalty(closest_ref_len, hyp_len) # doctest: +ELLIPSIS
|
| 344 |
+
0.8668...
|
| 345 |
+
>>> references = [['a'] * 11, ['a'] * 8, ['a'] * 6, ['a'] * 7]
|
| 346 |
+
>>> hypothesis = ['a'] * 7
|
| 347 |
+
>>> hyp_len = len(hypothesis)
|
| 348 |
+
>>> closest_ref_len = closest_ref_length(references, hyp_len)
|
| 349 |
+
>>> brevity_penalty(closest_ref_len, hyp_len)
|
| 350 |
+
1.0
|
| 351 |
+
:param hyp_len: The length of the hypothesis for a single sentence OR the
|
| 352 |
+
sum of all the hypotheses' lengths for a corpus
|
| 353 |
+
:type hyp_len: int
|
| 354 |
+
:param closest_ref_len: The length of the closest reference for a single
|
| 355 |
+
hypothesis OR the sum of all the closest references for every hypotheses.
|
| 356 |
+
:type closest_ref_len: int
|
| 357 |
+
:return: BLEU's brevity penalty.
|
| 358 |
+
:rtype: float
|
| 359 |
+
"""
|
| 360 |
+
if hyp_len > closest_ref_len:
|
| 361 |
+
return 1
|
| 362 |
+
# If hypothesis is empty, brevity penalty = 0 should result in BLEU = 0.0
|
| 363 |
+
elif hyp_len == 0:
|
| 364 |
+
return 0
|
| 365 |
+
else:
|
| 366 |
+
return math.exp(1 - closest_ref_len / hyp_len)
|
| 367 |
+
|
| 368 |
+
|
| 369 |
+
class SmoothingFunction:
|
| 370 |
+
"""
|
| 371 |
+
This is an implementation of the smoothing techniques
|
| 372 |
+
for segment-level BLEU scores that was presented in
|
| 373 |
+
Boxing Chen and Collin Cherry (2014) A Systematic Comparison of
|
| 374 |
+
Smoothing Techniques for Sentence-Level BLEU. In WMT14.
|
| 375 |
+
http://acl2014.org/acl2014/W14-33/pdf/W14-3346.pdf
|
| 376 |
+
"""
|
| 377 |
+
|
| 378 |
+
def __init__(self, epsilon=0.1, alpha=5, k=5):
|
| 379 |
+
"""
|
| 380 |
+
This will initialize the parameters required for the various smoothing
|
| 381 |
+
techniques, the default values are set to the numbers used in the
|
| 382 |
+
experiments from Chen and Cherry (2014).
|
| 383 |
+
>>> hypothesis1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'which', 'ensures',
|
| 384 |
+
... 'that', 'the', 'military', 'always', 'obeys', 'the',
|
| 385 |
+
... 'commands', 'of', 'the', 'party']
|
| 386 |
+
>>> reference1 = ['It', 'is', 'a', 'guide', 'to', 'action', 'that', 'ensures',
|
| 387 |
+
... 'that', 'the', 'military', 'will', 'forever', 'heed',
|
| 388 |
+
... 'Party', 'commands']
|
| 389 |
+
>>> chencherry = SmoothingFunction()
|
| 390 |
+
>>> print(sentence_bleu([reference1], hypothesis1)) # doctest: +ELLIPSIS
|
| 391 |
+
0.4118...
|
| 392 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method0)) # doctest: +ELLIPSIS
|
| 393 |
+
0.4118...
|
| 394 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method1)) # doctest: +ELLIPSIS
|
| 395 |
+
0.4118...
|
| 396 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method2)) # doctest: +ELLIPSIS
|
| 397 |
+
0.4489...
|
| 398 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method3)) # doctest: +ELLIPSIS
|
| 399 |
+
0.4118...
|
| 400 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method4)) # doctest: +ELLIPSIS
|
| 401 |
+
0.4118...
|
| 402 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method5)) # doctest: +ELLIPSIS
|
| 403 |
+
0.4905...
|
| 404 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method6)) # doctest: +ELLIPSIS
|
| 405 |
+
0.4135...
|
| 406 |
+
>>> print(sentence_bleu([reference1], hypothesis1, smoothing_function=chencherry.method7)) # doctest: +ELLIPSIS
|
| 407 |
+
0.4905...
|
| 408 |
+
:param epsilon: the epsilon value use in method 1
|
| 409 |
+
:type epsilon: float
|
| 410 |
+
:param alpha: the alpha value use in method 6
|
| 411 |
+
:type alpha: int
|
| 412 |
+
:param k: the k value use in method 4
|
| 413 |
+
:type k: int
|
| 414 |
+
"""
|
| 415 |
+
self.epsilon = epsilon
|
| 416 |
+
self.alpha = alpha
|
| 417 |
+
self.k = k
|
| 418 |
+
|
| 419 |
+
def method0(self, p_n, *args, **kwargs):
|
| 420 |
+
"""
|
| 421 |
+
No smoothing.
|
| 422 |
+
"""
|
| 423 |
+
p_n_new = []
|
| 424 |
+
for i, p_i in enumerate(p_n):
|
| 425 |
+
if p_i[0] != 0:
|
| 426 |
+
p_n_new.append(p_i)
|
| 427 |
+
else:
|
| 428 |
+
_msg = str(
|
| 429 |
+
"\nThe hypothesis contains 0 counts of {}-gram overlaps.\n"
|
| 430 |
+
"Therefore the BLEU score evaluates to 0, independently of\n"
|
| 431 |
+
"how many N-gram overlaps of lower order it contains.\n"
|
| 432 |
+
"Consider using lower n-gram order or use "
|
| 433 |
+
"SmoothingFunction()"
|
| 434 |
+
).format(i + 1)
|
| 435 |
+
warnings.warn(_msg)
|
| 436 |
+
# When numerator==0 where denonminator==0 or !=0, the result
|
| 437 |
+
# for the precision score should be equal to 0 or undefined.
|
| 438 |
+
# Due to BLEU geometric mean computation in logarithm space,
|
| 439 |
+
# we we need to take the return sys.float_info.min such that
|
| 440 |
+
# math.log(sys.float_info.min) returns a 0 precision score.
|
| 441 |
+
p_n_new.append(sys.float_info.min)
|
| 442 |
+
return p_n_new
|
| 443 |
+
|
| 444 |
+
def method1(self, p_n, *args, **kwargs):
|
| 445 |
+
"""
|
| 446 |
+
Smoothing method 1: Add *epsilon* counts to precision with 0 counts.
|
| 447 |
+
"""
|
| 448 |
+
return [
|
| 449 |
+
((p_i[0] + self.epsilon), p_i[1])
|
| 450 |
+
if p_i[0] == 0
|
| 451 |
+
else p_i
|
| 452 |
+
for p_i in p_n
|
| 453 |
+
]
|
| 454 |
+
|
| 455 |
+
def method2(self, p_n, *args, **kwargs):
|
| 456 |
+
"""
|
| 457 |
+
Smoothing method 2: Add 1 to both numerator and denominator from
|
| 458 |
+
Chin-Yew Lin and Franz Josef Och (2004) Automatic evaluation of
|
| 459 |
+
machine translation quality using longest common subsequence and
|
| 460 |
+
skip-bigram statistics. In ACL04.
|
| 461 |
+
"""
|
| 462 |
+
return [
|
| 463 |
+
(p_i[0] + 1, p_i[1] + 1)
|
| 464 |
+
for p_i in p_n
|
| 465 |
+
]
|
| 466 |
+
|
| 467 |
+
def method3(self, p_n, *args, **kwargs):
|
| 468 |
+
"""
|
| 469 |
+
Smoothing method 3: NIST geometric sequence smoothing
|
| 470 |
+
The smoothing is computed by taking 1 / ( 2^k ), instead of 0, for each
|
| 471 |
+
precision score whose matching n-gram count is null.
|
| 472 |
+
k is 1 for the first 'n' value for which the n-gram match count is null/
|
| 473 |
+
For example, if the text contains:
|
| 474 |
+
- one 2-gram match
|
| 475 |
+
- and (consequently) two 1-gram matches
|
| 476 |
+
the n-gram count for each individual precision score would be:
|
| 477 |
+
- n=1 => prec_count = 2 (two unigrams)
|
| 478 |
+
- n=2 => prec_count = 1 (one bigram)
|
| 479 |
+
- n=3 => prec_count = 1/2 (no trigram, taking 'smoothed' value of 1 / ( 2^k ), with k=1)
|
| 480 |
+
- n=4 => prec_count = 1/4 (no fourgram, taking 'smoothed' value of 1 / ( 2^k ), with k=2)
|
| 481 |
+
"""
|
| 482 |
+
incvnt = 1 # From the mteval-v13a.pl, it's referred to as k.
|
| 483 |
+
for i, p_i in enumerate(p_n):
|
| 484 |
+
if p_i.numerator == 0:
|
| 485 |
+
p_n[i] = 1 / (2 ** incvnt * p_i.denominator)
|
| 486 |
+
incvnt += 1
|
| 487 |
+
return p_n
|
| 488 |
+
|
| 489 |
+
def method4(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 490 |
+
"""
|
| 491 |
+
Smoothing method 4:
|
| 492 |
+
Shorter translations may have inflated precision values due to having
|
| 493 |
+
smaller denominators; therefore, we give them proportionally
|
| 494 |
+
smaller smoothed counts. Instead of scaling to 1/(2^k), Chen and Cherry
|
| 495 |
+
suggests dividing by 1/ln(len(T)), where T is the length of the translation.
|
| 496 |
+
"""
|
| 497 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 498 |
+
for i, p_i in enumerate(p_n):
|
| 499 |
+
if p_i.numerator == 0 and hyp_len != 0:
|
| 500 |
+
incvnt = i + 1 * self.k / math.log(
|
| 501 |
+
hyp_len
|
| 502 |
+
) # Note that this K is different from the K from NIST.
|
| 503 |
+
p_n[i] = incvnt / p_i.denominator
|
| 504 |
+
return p_n
|
| 505 |
+
|
| 506 |
+
def method5(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 507 |
+
"""
|
| 508 |
+
Smoothing method 5:
|
| 509 |
+
The matched counts for similar values of n should be similar. To a
|
| 510 |
+
calculate the n-gram matched count, it averages the n−1, n and n+1 gram
|
| 511 |
+
matched counts.
|
| 512 |
+
"""
|
| 513 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 514 |
+
m = {}
|
| 515 |
+
# Requires an precision value for an addition ngram order.
|
| 516 |
+
p_n_plus1 = p_n + [modified_precision(references, hypothesis, 5)]
|
| 517 |
+
m[-1] = p_n[0] + 1
|
| 518 |
+
for i, p_i in enumerate(p_n):
|
| 519 |
+
p_n[i] = (m[i - 1] + p_i + p_n_plus1[i + 1]) / 3
|
| 520 |
+
m[i] = p_n[i]
|
| 521 |
+
return p_n
|
| 522 |
+
|
| 523 |
+
def method6(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 524 |
+
"""
|
| 525 |
+
Smoothing method 6:
|
| 526 |
+
Interpolates the maximum likelihood estimate of the precision *p_n* with
|
| 527 |
+
a prior estimate *pi0*. The prior is estimated by assuming that the ratio
|
| 528 |
+
between pn and pn−1 will be the same as that between pn−1 and pn−2; from
|
| 529 |
+
Gao and He (2013) Training MRF-Based Phrase Translation Models using
|
| 530 |
+
Gradient Ascent. In NAACL.
|
| 531 |
+
"""
|
| 532 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 533 |
+
# This smoothing only works when p_1 and p_2 is non-zero.
|
| 534 |
+
# Raise an error with an appropriate message when the input is too short
|
| 535 |
+
# to use this smoothing technique.
|
| 536 |
+
assert p_n[2], "This smoothing method requires non-zero precision for bigrams."
|
| 537 |
+
for i, p_i in enumerate(p_n):
|
| 538 |
+
if i in [0, 1]: # Skips the first 2 orders of ngrams.
|
| 539 |
+
continue
|
| 540 |
+
else:
|
| 541 |
+
pi0 = 0 if p_n[i - 2] == 0 else p_n[i - 1] ** 2 / p_n[i - 2]
|
| 542 |
+
# No. of ngrams in translation that matches the reference.
|
| 543 |
+
m = p_i.numerator
|
| 544 |
+
# No. of ngrams in translation.
|
| 545 |
+
l = sum(1 for _ in ngrams(hypothesis, i + 1))
|
| 546 |
+
# Calculates the interpolated precision.
|
| 547 |
+
p_n[i] = (m + self.alpha * pi0) / (l + self.alpha)
|
| 548 |
+
return p_n
|
| 549 |
+
|
| 550 |
+
def method7(self, p_n, references, hypothesis, hyp_len=None, *args, **kwargs):
|
| 551 |
+
"""
|
| 552 |
+
Smoothing method 7:
|
| 553 |
+
Interpolates methods 4 and 5.
|
| 554 |
+
"""
|
| 555 |
+
hyp_len = hyp_len if hyp_len else len(hypothesis)
|
| 556 |
+
p_n = self.method4(p_n, references, hypothesis, hyp_len)
|
| 557 |
+
p_n = self.method5(p_n, references, hypothesis, hyp_len)
|
| 558 |
+
return p_n
|
evaluator/bleu.py
ADDED
|
@@ -0,0 +1,134 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2017 Google Inc. All Rights Reserved.
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
# ==============================================================================
|
| 15 |
+
|
| 16 |
+
"""Python implementation of BLEU and smooth-BLEU.
|
| 17 |
+
|
| 18 |
+
This module provides a Python implementation of BLEU and smooth-BLEU.
|
| 19 |
+
Smooth BLEU is computed following the method outlined in the paper:
|
| 20 |
+
Chin-Yew Lin, Franz Josef Och. ORANGE: a method for evaluating automatic
|
| 21 |
+
evaluation metrics for machine translation. COLING 2004.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import collections
|
| 25 |
+
import math
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def _get_ngrams(segment, max_order):
|
| 29 |
+
"""Extracts all n-grams upto a given maximum order from an input segment.
|
| 30 |
+
|
| 31 |
+
Args:
|
| 32 |
+
segment: text segment from which n-grams will be extracted.
|
| 33 |
+
max_order: maximum length in tokens of the n-grams returned by this
|
| 34 |
+
methods.
|
| 35 |
+
|
| 36 |
+
Returns:
|
| 37 |
+
The Counter containing all n-grams upto max_order in segment
|
| 38 |
+
with a count of how many times each n-gram occurred.
|
| 39 |
+
"""
|
| 40 |
+
ngram_counts = collections.Counter()
|
| 41 |
+
for order in range(1, max_order + 1):
|
| 42 |
+
for i in range(0, len(segment) - order + 1):
|
| 43 |
+
ngram = tuple(segment[i:i+order])
|
| 44 |
+
ngram_counts[ngram] += 1
|
| 45 |
+
return ngram_counts
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def compute_bleu(reference_corpus, translation_corpus, max_order=4,
|
| 49 |
+
smooth=False):
|
| 50 |
+
"""Computes BLEU score of translated segments against one or more references.
|
| 51 |
+
|
| 52 |
+
Args:
|
| 53 |
+
reference_corpus: list of lists of references for each translation. Each
|
| 54 |
+
reference should be tokenized into a list of tokens.
|
| 55 |
+
translation_corpus: list of translations to score. Each translation
|
| 56 |
+
should be tokenized into a list of tokens.
|
| 57 |
+
max_order: Maximum n-gram order to use when computing BLEU score.
|
| 58 |
+
smooth: Whether or not to apply Lin et al. 2004 smoothing.
|
| 59 |
+
|
| 60 |
+
Returns:
|
| 61 |
+
3-Tuple with the BLEU score, n-gram precisions, geometric mean of n-gram
|
| 62 |
+
precisions and brevity penalty.
|
| 63 |
+
"""
|
| 64 |
+
matches_by_order = [0] * max_order
|
| 65 |
+
possible_matches_by_order = [0] * max_order
|
| 66 |
+
reference_length = 0
|
| 67 |
+
translation_length = 0
|
| 68 |
+
for (references, translation) in zip(reference_corpus,
|
| 69 |
+
translation_corpus):
|
| 70 |
+
reference_length += min(len(r) for r in references)
|
| 71 |
+
translation_length += len(translation)
|
| 72 |
+
|
| 73 |
+
merged_ref_ngram_counts = collections.Counter()
|
| 74 |
+
for reference in references:
|
| 75 |
+
merged_ref_ngram_counts |= _get_ngrams(reference, max_order)
|
| 76 |
+
translation_ngram_counts = _get_ngrams(translation, max_order)
|
| 77 |
+
overlap = translation_ngram_counts & merged_ref_ngram_counts
|
| 78 |
+
for ngram in overlap:
|
| 79 |
+
matches_by_order[len(ngram)-1] += overlap[ngram]
|
| 80 |
+
for order in range(1, max_order+1):
|
| 81 |
+
possible_matches = len(translation) - order + 1
|
| 82 |
+
if possible_matches > 0:
|
| 83 |
+
possible_matches_by_order[order-1] += possible_matches
|
| 84 |
+
|
| 85 |
+
precisions = [0] * max_order
|
| 86 |
+
for i in range(0, max_order):
|
| 87 |
+
if smooth:
|
| 88 |
+
precisions[i] = ((matches_by_order[i] + 1.) /
|
| 89 |
+
(possible_matches_by_order[i] + 1.))
|
| 90 |
+
else:
|
| 91 |
+
if possible_matches_by_order[i] > 0:
|
| 92 |
+
precisions[i] = (float(matches_by_order[i]) /
|
| 93 |
+
possible_matches_by_order[i])
|
| 94 |
+
else:
|
| 95 |
+
precisions[i] = 0.0
|
| 96 |
+
|
| 97 |
+
if min(precisions) > 0:
|
| 98 |
+
p_log_sum = sum((1. / max_order) * math.log(p) for p in precisions)
|
| 99 |
+
geo_mean = math.exp(p_log_sum)
|
| 100 |
+
else:
|
| 101 |
+
geo_mean = 0
|
| 102 |
+
|
| 103 |
+
ratio = float(translation_length) / reference_length
|
| 104 |
+
|
| 105 |
+
if ratio > 1.0:
|
| 106 |
+
bp = 1.
|
| 107 |
+
else:
|
| 108 |
+
bp = math.exp(1 - 1. / ratio)
|
| 109 |
+
|
| 110 |
+
bleu = geo_mean * bp
|
| 111 |
+
|
| 112 |
+
return (bleu, precisions, bp, ratio, translation_length, reference_length)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def _bleu(ref_file, trans_file, subword_option=None):
|
| 116 |
+
max_order = 4
|
| 117 |
+
smooth = True
|
| 118 |
+
ref_files = [ref_file]
|
| 119 |
+
reference_text = []
|
| 120 |
+
for reference_filename in ref_files:
|
| 121 |
+
with open(reference_filename) as fh:
|
| 122 |
+
reference_text.append(fh.readlines())
|
| 123 |
+
per_segment_references = []
|
| 124 |
+
for references in zip(*reference_text):
|
| 125 |
+
reference_list = []
|
| 126 |
+
for reference in references:
|
| 127 |
+
reference_list.append(reference.strip().split())
|
| 128 |
+
per_segment_references.append(reference_list)
|
| 129 |
+
translations = []
|
| 130 |
+
with open(trans_file) as fh:
|
| 131 |
+
for line in fh:
|
| 132 |
+
translations.append(line.strip().split())
|
| 133 |
+
bleu_score, _, _, _, _, _ = compute_bleu(per_segment_references, translations, max_order, smooth)
|
| 134 |
+
return round(100 * bleu_score,2)
|
evaluator/smooth_bleu.py
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/python
|
| 2 |
+
|
| 3 |
+
'''
|
| 4 |
+
This script was adapted from the original version by hieuhoang1972 which is part of MOSES.
|
| 5 |
+
'''
|
| 6 |
+
|
| 7 |
+
# $Id: bleu.py 1307 2007-03-14 22:22:36Z hieuhoang1972 $
|
| 8 |
+
|
| 9 |
+
'''Provides:
|
| 10 |
+
|
| 11 |
+
cook_refs(refs, n=4): Transform a list of reference sentences as strings into a form usable by cook_test().
|
| 12 |
+
cook_test(test, refs, n=4): Transform a test sentence as a string (together with the cooked reference sentences) into a form usable by score_cooked().
|
| 13 |
+
score_cooked(alltest, n=4): Score a list of cooked test sentences.
|
| 14 |
+
|
| 15 |
+
score_set(s, testid, refids, n=4): Interface with dataset.py; calculate BLEU score of testid against refids.
|
| 16 |
+
|
| 17 |
+
The reason for breaking the BLEU computation into three phases cook_refs(), cook_test(), and score_cooked() is to allow the caller to calculate BLEU scores for multiple test sets as efficiently as possible.
|
| 18 |
+
'''
|
| 19 |
+
|
| 20 |
+
import sys, math, re, xml.sax.saxutils
|
| 21 |
+
import subprocess
|
| 22 |
+
import os
|
| 23 |
+
|
| 24 |
+
# Added to bypass NIST-style pre-processing of hyp and ref files -- wade
|
| 25 |
+
nonorm = 0
|
| 26 |
+
|
| 27 |
+
preserve_case = False
|
| 28 |
+
eff_ref_len = "shortest"
|
| 29 |
+
|
| 30 |
+
normalize1 = [
|
| 31 |
+
('<skipped>', ''), # strip "skipped" tags
|
| 32 |
+
(r'-\n', ''), # strip end-of-line hyphenation and join lines
|
| 33 |
+
(r'\n', ' '), # join lines
|
| 34 |
+
# (r'(\d)\s+(?=\d)', r'\1'), # join digits
|
| 35 |
+
]
|
| 36 |
+
normalize1 = [(re.compile(pattern), replace) for (pattern, replace) in normalize1]
|
| 37 |
+
|
| 38 |
+
normalize2 = [
|
| 39 |
+
(r'([\{-\~\[-\` -\&\(-\+\:-\@\/])', r' \1 '), # tokenize punctuation. apostrophe is missing
|
| 40 |
+
(r'([^0-9])([\.,])', r'\1 \2 '), # tokenize period and comma unless preceded by a digit
|
| 41 |
+
(r'([\.,])([^0-9])', r' \1 \2'), # tokenize period and comma unless followed by a digit
|
| 42 |
+
(r'([0-9])(-)', r'\1 \2 ') # tokenize dash when preceded by a digit
|
| 43 |
+
]
|
| 44 |
+
normalize2 = [(re.compile(pattern), replace) for (pattern, replace) in normalize2]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def normalize(s):
|
| 48 |
+
'''Normalize and tokenize text. This is lifted from NIST mteval-v11a.pl.'''
|
| 49 |
+
# Added to bypass NIST-style pre-processing of hyp and ref files -- wade
|
| 50 |
+
if (nonorm):
|
| 51 |
+
return s.split()
|
| 52 |
+
if type(s) is not str:
|
| 53 |
+
s = " ".join(s)
|
| 54 |
+
# language-independent part:
|
| 55 |
+
for (pattern, replace) in normalize1:
|
| 56 |
+
s = re.sub(pattern, replace, s)
|
| 57 |
+
s = xml.sax.saxutils.unescape(s, {'"': '"'})
|
| 58 |
+
# language-dependent part (assuming Western languages):
|
| 59 |
+
s = " %s " % s
|
| 60 |
+
if not preserve_case:
|
| 61 |
+
s = s.lower() # this might not be identical to the original
|
| 62 |
+
for (pattern, replace) in normalize2:
|
| 63 |
+
s = re.sub(pattern, replace, s)
|
| 64 |
+
return s.split()
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def count_ngrams(words, n=4):
|
| 68 |
+
counts = {}
|
| 69 |
+
for k in range(1, n + 1):
|
| 70 |
+
for i in range(len(words) - k + 1):
|
| 71 |
+
ngram = tuple(words[i:i + k])
|
| 72 |
+
counts[ngram] = counts.get(ngram, 0) + 1
|
| 73 |
+
return counts
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def cook_refs(refs, n=4):
|
| 77 |
+
'''Takes a list of reference sentences for a single segment
|
| 78 |
+
and returns an object that encapsulates everything that BLEU
|
| 79 |
+
needs to know about them.'''
|
| 80 |
+
|
| 81 |
+
refs = [normalize(ref) for ref in refs]
|
| 82 |
+
maxcounts = {}
|
| 83 |
+
for ref in refs:
|
| 84 |
+
counts = count_ngrams(ref, n)
|
| 85 |
+
for (ngram, count) in counts.items():
|
| 86 |
+
maxcounts[ngram] = max(maxcounts.get(ngram, 0), count)
|
| 87 |
+
return ([len(ref) for ref in refs], maxcounts)
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def cook_test(test, item, n=4):
|
| 91 |
+
'''Takes a test sentence and returns an object that
|
| 92 |
+
encapsulates everything that BLEU needs to know about it.'''
|
| 93 |
+
(reflens, refmaxcounts) = item
|
| 94 |
+
test = normalize(test)
|
| 95 |
+
result = {}
|
| 96 |
+
result["testlen"] = len(test)
|
| 97 |
+
|
| 98 |
+
# Calculate effective reference sentence length.
|
| 99 |
+
|
| 100 |
+
if eff_ref_len == "shortest":
|
| 101 |
+
result["reflen"] = min(reflens)
|
| 102 |
+
elif eff_ref_len == "average":
|
| 103 |
+
result["reflen"] = float(sum(reflens)) / len(reflens)
|
| 104 |
+
elif eff_ref_len == "closest":
|
| 105 |
+
min_diff = None
|
| 106 |
+
for reflen in reflens:
|
| 107 |
+
if min_diff is None or abs(reflen - len(test)) < min_diff:
|
| 108 |
+
min_diff = abs(reflen - len(test))
|
| 109 |
+
result['reflen'] = reflen
|
| 110 |
+
|
| 111 |
+
result["guess"] = [max(len(test) - k + 1, 0) for k in range(1, n + 1)]
|
| 112 |
+
|
| 113 |
+
result['correct'] = [0] * n
|
| 114 |
+
counts = count_ngrams(test, n)
|
| 115 |
+
for (ngram, count) in counts.items():
|
| 116 |
+
result["correct"][len(ngram) - 1] += min(refmaxcounts.get(ngram, 0), count)
|
| 117 |
+
|
| 118 |
+
return result
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def score_cooked(allcomps, n=4, ground=0, smooth=1):
|
| 122 |
+
totalcomps = {'testlen': 0, 'reflen': 0, 'guess': [0] * n, 'correct': [0] * n}
|
| 123 |
+
for comps in allcomps:
|
| 124 |
+
for key in ['testlen', 'reflen']:
|
| 125 |
+
totalcomps[key] += comps[key]
|
| 126 |
+
for key in ['guess', 'correct']:
|
| 127 |
+
for k in range(n):
|
| 128 |
+
totalcomps[key][k] += comps[key][k]
|
| 129 |
+
logbleu = 0.0
|
| 130 |
+
all_bleus = []
|
| 131 |
+
for k in range(n):
|
| 132 |
+
correct = totalcomps['correct'][k]
|
| 133 |
+
guess = totalcomps['guess'][k]
|
| 134 |
+
addsmooth = 0
|
| 135 |
+
if smooth == 1 and k > 0:
|
| 136 |
+
addsmooth = 1
|
| 137 |
+
logbleu += math.log(correct + addsmooth + sys.float_info.min) - math.log(guess + addsmooth + sys.float_info.min)
|
| 138 |
+
if guess == 0:
|
| 139 |
+
all_bleus.append(-10000000)
|
| 140 |
+
else:
|
| 141 |
+
all_bleus.append(math.log(correct + sys.float_info.min) - math.log(guess))
|
| 142 |
+
|
| 143 |
+
logbleu /= float(n)
|
| 144 |
+
all_bleus.insert(0, logbleu)
|
| 145 |
+
|
| 146 |
+
brevPenalty = min(0, 1 - float(totalcomps['reflen'] + 1) / (totalcomps['testlen'] + 1))
|
| 147 |
+
for i in range(len(all_bleus)):
|
| 148 |
+
if i == 0:
|
| 149 |
+
all_bleus[i] += brevPenalty
|
| 150 |
+
all_bleus[i] = math.exp(all_bleus[i])
|
| 151 |
+
return all_bleus
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def bleu(refs, candidate, ground=0, smooth=1):
|
| 155 |
+
refs = cook_refs(refs)
|
| 156 |
+
test = cook_test(candidate, refs)
|
| 157 |
+
return score_cooked([test], ground=ground, smooth=smooth)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
def splitPuncts(line):
|
| 161 |
+
return ' '.join(re.findall(r"[\w]+|[^\s\w]", line))
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def computeMaps(predictions, goldfile):
|
| 165 |
+
predictionMap = {}
|
| 166 |
+
goldMap = {}
|
| 167 |
+
gf = open(goldfile, 'r')
|
| 168 |
+
|
| 169 |
+
for row in predictions:
|
| 170 |
+
cols = row.strip().split('\t')
|
| 171 |
+
if len(cols) == 1:
|
| 172 |
+
(rid, pred) = (cols[0], '')
|
| 173 |
+
else:
|
| 174 |
+
(rid, pred) = (cols[0], cols[1])
|
| 175 |
+
predictionMap[rid] = [splitPuncts(pred.strip().lower())]
|
| 176 |
+
|
| 177 |
+
for row in gf:
|
| 178 |
+
(rid, pred) = row.split('\t')
|
| 179 |
+
if rid in predictionMap: # Only insert if the id exists for the method
|
| 180 |
+
if rid not in goldMap:
|
| 181 |
+
goldMap[rid] = []
|
| 182 |
+
goldMap[rid].append(splitPuncts(pred.strip().lower()))
|
| 183 |
+
|
| 184 |
+
sys.stderr.write('Total: ' + str(len(goldMap)) + '\n')
|
| 185 |
+
return (goldMap, predictionMap)
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
# m1 is the reference map
|
| 189 |
+
# m2 is the prediction map
|
| 190 |
+
def bleuFromMaps(m1, m2):
|
| 191 |
+
score = [0] * 5
|
| 192 |
+
num = 0.0
|
| 193 |
+
|
| 194 |
+
for key in m1:
|
| 195 |
+
if key in m2:
|
| 196 |
+
bl = bleu(m1[key], m2[key][0])
|
| 197 |
+
score = [score[i] + bl[i] for i in range(0, len(bl))]
|
| 198 |
+
num += 1
|
| 199 |
+
return [s * 100.0 / num for s in score]
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
if __name__ == '__main__':
|
| 203 |
+
reference_file = sys.argv[1]
|
| 204 |
+
predictions = []
|
| 205 |
+
for row in sys.stdin:
|
| 206 |
+
predictions.append(row)
|
| 207 |
+
(goldMap, predictionMap) = computeMaps(predictions, reference_file)
|
| 208 |
+
print(bleuFromMaps(goldMap, predictionMap)[0])
|
models.py
ADDED
|
@@ -0,0 +1,398 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import numpy as np
|
| 4 |
+
from transformers import (RobertaConfig, RobertaModel, RobertaTokenizer,
|
| 5 |
+
BartConfig, BartForConditionalGeneration, BartTokenizer,
|
| 6 |
+
T5Config, T5ForConditionalGeneration, T5Tokenizer)
|
| 7 |
+
import logging
|
| 8 |
+
|
| 9 |
+
logger = logging.getLogger(__name__)
|
| 10 |
+
|
| 11 |
+
MODEL_CLASSES = {'roberta': (RobertaConfig, RobertaModel, RobertaTokenizer),
|
| 12 |
+
't5': (T5Config, T5ForConditionalGeneration, T5Tokenizer),
|
| 13 |
+
'codet5': (T5Config, T5ForConditionalGeneration, RobertaTokenizer),
|
| 14 |
+
'bart': (BartConfig, BartForConditionalGeneration, BartTokenizer)}
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def get_model_size(model):
|
| 18 |
+
model_parameters = filter(lambda p: p.requires_grad, model.parameters())
|
| 19 |
+
model_size = sum([np.prod(p.size()) for p in model_parameters])
|
| 20 |
+
return "{}M".format(round(model_size / 1e+6))
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def build_or_load_gen_model(args):
|
| 24 |
+
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
|
| 25 |
+
config = config_class.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 26 |
+
tokenizer = tokenizer_class.from_pretrained(args.tokenizer_name)
|
| 27 |
+
if args.model_type == 'roberta':
|
| 28 |
+
encoder = model_class.from_pretrained(args.model_name_or_path, config=config)
|
| 29 |
+
decoder_layer = nn.TransformerDecoderLayer(d_model=config.hidden_size, nhead=config.num_attention_heads)
|
| 30 |
+
decoder = nn.TransformerDecoder(decoder_layer, num_layers=6)
|
| 31 |
+
model = Seq2Seq(encoder=encoder, decoder=decoder, config=config,
|
| 32 |
+
beam_size=args.beam_size, max_length=args.max_target_length,
|
| 33 |
+
sos_id=tokenizer.cls_token_id, eos_id=tokenizer.sep_token_id)
|
| 34 |
+
else:
|
| 35 |
+
model = model_class.from_pretrained(args.model_name_or_path)
|
| 36 |
+
|
| 37 |
+
logger.info("Finish loading model [%s] from %s", get_model_size(model), args.model_name_or_path)
|
| 38 |
+
|
| 39 |
+
if args.load_model_path is not None:
|
| 40 |
+
logger.info("Reload model from {}".format(args.load_model_path))
|
| 41 |
+
model.load_state_dict(torch.load(args.load_model_path))
|
| 42 |
+
|
| 43 |
+
return config, model, tokenizer
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class RobertaClassificationHead(nn.Module):
|
| 47 |
+
"""Head for sentence-level classification tasks."""
|
| 48 |
+
|
| 49 |
+
def __init__(self, config):
|
| 50 |
+
super().__init__()
|
| 51 |
+
self.dense = nn.Linear(config.hidden_size * 2, config.hidden_size)
|
| 52 |
+
self.out_proj = nn.Linear(config.hidden_size, 2)
|
| 53 |
+
|
| 54 |
+
def forward(self, x, **kwargs):
|
| 55 |
+
x = x.reshape(-1, x.size(-1) * 2)
|
| 56 |
+
x = self.dense(x)
|
| 57 |
+
x = torch.tanh(x)
|
| 58 |
+
x = self.out_proj(x)
|
| 59 |
+
return x
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class CloneModel(nn.Module):
|
| 63 |
+
def __init__(self, encoder, config, tokenizer, args):
|
| 64 |
+
super(CloneModel, self).__init__()
|
| 65 |
+
self.encoder = encoder
|
| 66 |
+
self.config = config
|
| 67 |
+
self.tokenizer = tokenizer
|
| 68 |
+
self.classifier = RobertaClassificationHead(config)
|
| 69 |
+
self.args = args
|
| 70 |
+
|
| 71 |
+
def get_t5_vec(self, source_ids):
|
| 72 |
+
attention_mask = source_ids.ne(self.tokenizer.pad_token_id)
|
| 73 |
+
outputs = self.encoder(input_ids=source_ids, attention_mask=attention_mask,
|
| 74 |
+
labels=source_ids, decoder_attention_mask=attention_mask, output_hidden_states=True)
|
| 75 |
+
hidden_states = outputs['decoder_hidden_states'][-1]
|
| 76 |
+
eos_mask = source_ids.eq(self.config.eos_token_id)
|
| 77 |
+
|
| 78 |
+
if len(torch.unique(eos_mask.sum(1))) > 1:
|
| 79 |
+
raise ValueError("All examples must have the same number of <eos> tokens.")
|
| 80 |
+
vec = hidden_states[eos_mask, :].view(hidden_states.size(0), -1,
|
| 81 |
+
hidden_states.size(-1))[:, -1, :]
|
| 82 |
+
return vec
|
| 83 |
+
|
| 84 |
+
def get_bart_vec(self, source_ids):
|
| 85 |
+
attention_mask = source_ids.ne(self.tokenizer.pad_token_id)
|
| 86 |
+
outputs = self.encoder(input_ids=source_ids, attention_mask=attention_mask,
|
| 87 |
+
labels=source_ids, decoder_attention_mask=attention_mask, output_hidden_states=True)
|
| 88 |
+
hidden_states = outputs['decoder_hidden_states'][-1]
|
| 89 |
+
eos_mask = source_ids.eq(self.config.eos_token_id)
|
| 90 |
+
|
| 91 |
+
if len(torch.unique(eos_mask.sum(1))) > 1:
|
| 92 |
+
raise ValueError("All examples must have the same number of <eos> tokens.")
|
| 93 |
+
vec = hidden_states[eos_mask, :].view(hidden_states.size(0), -1,
|
| 94 |
+
hidden_states.size(-1))[:, -1, :]
|
| 95 |
+
return vec
|
| 96 |
+
|
| 97 |
+
def get_roberta_vec(self, source_ids):
|
| 98 |
+
attention_mask = source_ids.ne(self.tokenizer.pad_token_id)
|
| 99 |
+
vec = self.encoder(input_ids=source_ids, attention_mask=attention_mask)[0][:, 0, :]
|
| 100 |
+
return vec
|
| 101 |
+
|
| 102 |
+
def forward(self, source_ids=None, labels=None):
|
| 103 |
+
source_ids = source_ids.view(-1, self.args.max_source_length)
|
| 104 |
+
|
| 105 |
+
if self.args.model_type == 'codet5':
|
| 106 |
+
vec = self.get_t5_vec(source_ids)
|
| 107 |
+
elif self.args.model_type == 'bart':
|
| 108 |
+
vec = self.get_bart_vec(source_ids)
|
| 109 |
+
elif self.args.model_type == 'roberta':
|
| 110 |
+
vec = self.get_roberta_vec(source_ids)
|
| 111 |
+
|
| 112 |
+
logits = self.classifier(vec)
|
| 113 |
+
prob = nn.functional.softmax(logits)
|
| 114 |
+
|
| 115 |
+
if labels is not None:
|
| 116 |
+
loss_fct = nn.CrossEntropyLoss()
|
| 117 |
+
loss = loss_fct(logits, labels)
|
| 118 |
+
return loss, prob
|
| 119 |
+
else:
|
| 120 |
+
return prob
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class DefectModel(nn.Module):
|
| 124 |
+
def __init__(self, encoder, config, tokenizer, args):
|
| 125 |
+
super(DefectModel, self).__init__()
|
| 126 |
+
self.encoder = encoder
|
| 127 |
+
self.config = config
|
| 128 |
+
self.tokenizer = tokenizer
|
| 129 |
+
self.classifier = nn.Linear(config.hidden_size, 2)
|
| 130 |
+
self.args = args
|
| 131 |
+
|
| 132 |
+
def get_t5_vec(self, source_ids):
|
| 133 |
+
attention_mask = source_ids.ne(self.tokenizer.pad_token_id)
|
| 134 |
+
outputs = self.encoder(input_ids=source_ids, attention_mask=attention_mask,
|
| 135 |
+
labels=source_ids, decoder_attention_mask=attention_mask, output_hidden_states=True)
|
| 136 |
+
hidden_states = outputs['decoder_hidden_states'][-1]
|
| 137 |
+
eos_mask = source_ids.eq(self.config.eos_token_id)
|
| 138 |
+
|
| 139 |
+
if len(torch.unique(eos_mask.sum(1))) > 1:
|
| 140 |
+
raise ValueError("All examples must have the same number of <eos> tokens.")
|
| 141 |
+
vec = hidden_states[eos_mask, :].view(hidden_states.size(0), -1,
|
| 142 |
+
hidden_states.size(-1))[:, -1, :]
|
| 143 |
+
return vec
|
| 144 |
+
|
| 145 |
+
def get_bart_vec(self, source_ids):
|
| 146 |
+
attention_mask = source_ids.ne(self.tokenizer.pad_token_id)
|
| 147 |
+
outputs = self.encoder(input_ids=source_ids, attention_mask=attention_mask,
|
| 148 |
+
labels=source_ids, decoder_attention_mask=attention_mask, output_hidden_states=True)
|
| 149 |
+
hidden_states = outputs['decoder_hidden_states'][-1]
|
| 150 |
+
eos_mask = source_ids.eq(self.config.eos_token_id)
|
| 151 |
+
|
| 152 |
+
if len(torch.unique(eos_mask.sum(1))) > 1:
|
| 153 |
+
raise ValueError("All examples must have the same number of <eos> tokens.")
|
| 154 |
+
vec = hidden_states[eos_mask, :].view(hidden_states.size(0), -1,
|
| 155 |
+
hidden_states.size(-1))[:, -1, :]
|
| 156 |
+
return vec
|
| 157 |
+
|
| 158 |
+
def get_roberta_vec(self, source_ids):
|
| 159 |
+
attention_mask = source_ids.ne(self.tokenizer.pad_token_id)
|
| 160 |
+
vec = self.encoder(input_ids=source_ids, attention_mask=attention_mask)[0][:, 0, :]
|
| 161 |
+
return vec
|
| 162 |
+
|
| 163 |
+
def forward(self, source_ids=None, labels=None):
|
| 164 |
+
source_ids = source_ids.view(-1, self.args.max_source_length)
|
| 165 |
+
|
| 166 |
+
if self.args.model_type == 'codet5':
|
| 167 |
+
vec = self.get_t5_vec(source_ids)
|
| 168 |
+
elif self.args.model_type == 'bart':
|
| 169 |
+
vec = self.get_bart_vec(source_ids)
|
| 170 |
+
elif self.args.model_type == 'roberta':
|
| 171 |
+
vec = self.get_roberta_vec(source_ids)
|
| 172 |
+
|
| 173 |
+
logits = self.classifier(vec)
|
| 174 |
+
prob = nn.functional.softmax(logits)
|
| 175 |
+
|
| 176 |
+
if labels is not None:
|
| 177 |
+
loss_fct = nn.CrossEntropyLoss()
|
| 178 |
+
loss = loss_fct(logits, labels)
|
| 179 |
+
return loss, prob
|
| 180 |
+
else:
|
| 181 |
+
return prob
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
# https://github.com/microsoft/CodeBERT/blob/master/CodeBERT/code2nl/model.py
|
| 185 |
+
class Seq2Seq(nn.Module):
|
| 186 |
+
"""
|
| 187 |
+
Build Seqence-to-Sequence.
|
| 188 |
+
|
| 189 |
+
Parameters:
|
| 190 |
+
|
| 191 |
+
* `encoder`- encoder of seq2seq model. e.g. roberta
|
| 192 |
+
* `decoder`- decoder of seq2seq model. e.g. transformer
|
| 193 |
+
* `config`- configuration of encoder model.
|
| 194 |
+
* `beam_size`- beam size for beam search.
|
| 195 |
+
* `max_length`- max length of target for beam search.
|
| 196 |
+
* `sos_id`- start of symbol ids in target for beam search.
|
| 197 |
+
* `eos_id`- end of symbol ids in target for beam search.
|
| 198 |
+
"""
|
| 199 |
+
|
| 200 |
+
def __init__(self, encoder, decoder, config, beam_size=None, max_length=None, sos_id=None, eos_id=None):
|
| 201 |
+
super(Seq2Seq, self).__init__()
|
| 202 |
+
self.encoder = encoder
|
| 203 |
+
self.decoder = decoder
|
| 204 |
+
self.config = config
|
| 205 |
+
self.register_buffer("bias", torch.tril(torch.ones(2048, 2048)))
|
| 206 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 207 |
+
self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 208 |
+
self.lsm = nn.LogSoftmax(dim=-1)
|
| 209 |
+
self.tie_weights()
|
| 210 |
+
|
| 211 |
+
self.beam_size = beam_size
|
| 212 |
+
self.max_length = max_length
|
| 213 |
+
self.sos_id = sos_id
|
| 214 |
+
self.eos_id = eos_id
|
| 215 |
+
|
| 216 |
+
def _tie_or_clone_weights(self, first_module, second_module):
|
| 217 |
+
""" Tie or clone module weights depending of weither we are using TorchScript or not
|
| 218 |
+
"""
|
| 219 |
+
if self.config.torchscript:
|
| 220 |
+
first_module.weight = nn.Parameter(second_module.weight.clone())
|
| 221 |
+
else:
|
| 222 |
+
first_module.weight = second_module.weight
|
| 223 |
+
|
| 224 |
+
def tie_weights(self):
|
| 225 |
+
""" Make sure we are sharing the input and output embeddings.
|
| 226 |
+
Export to TorchScript can't handle parameter sharing so we are cloning them instead.
|
| 227 |
+
"""
|
| 228 |
+
self._tie_or_clone_weights(self.lm_head,
|
| 229 |
+
self.encoder.embeddings.word_embeddings)
|
| 230 |
+
|
| 231 |
+
def forward(self, source_ids=None, source_mask=None, target_ids=None, target_mask=None, args=None):
|
| 232 |
+
outputs = self.encoder(source_ids, attention_mask=source_mask)
|
| 233 |
+
encoder_output = outputs[0].permute([1, 0, 2]).contiguous()
|
| 234 |
+
if target_ids is not None:
|
| 235 |
+
attn_mask = -1e4 * (1 - self.bias[:target_ids.shape[1], :target_ids.shape[1]])
|
| 236 |
+
tgt_embeddings = self.encoder.embeddings(target_ids).permute([1, 0, 2]).contiguous()
|
| 237 |
+
out = self.decoder(tgt_embeddings, encoder_output, tgt_mask=attn_mask,
|
| 238 |
+
memory_key_padding_mask=~source_mask)
|
| 239 |
+
# memory_key_padding_mask=(1 - source_mask).bool())
|
| 240 |
+
hidden_states = torch.tanh(self.dense(out)).permute([1, 0, 2]).contiguous()
|
| 241 |
+
lm_logits = self.lm_head(hidden_states)
|
| 242 |
+
# Shift so that tokens < n predict n
|
| 243 |
+
active_loss = target_mask[..., 1:].ne(0).view(-1) == 1
|
| 244 |
+
shift_logits = lm_logits[..., :-1, :].contiguous()
|
| 245 |
+
shift_labels = target_ids[..., 1:].contiguous()
|
| 246 |
+
# Flatten the tokens
|
| 247 |
+
loss_fct = nn.CrossEntropyLoss(ignore_index=-1)
|
| 248 |
+
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1))[active_loss],
|
| 249 |
+
shift_labels.view(-1)[active_loss])
|
| 250 |
+
|
| 251 |
+
outputs = loss, loss * active_loss.sum(), active_loss.sum()
|
| 252 |
+
return outputs
|
| 253 |
+
else:
|
| 254 |
+
# Predict
|
| 255 |
+
preds = []
|
| 256 |
+
zero = torch.cuda.LongTensor(1).fill_(0)
|
| 257 |
+
for i in range(source_ids.shape[0]):
|
| 258 |
+
context = encoder_output[:, i:i + 1]
|
| 259 |
+
context_mask = source_mask[i:i + 1, :]
|
| 260 |
+
beam = Beam(self.beam_size, self.sos_id, self.eos_id)
|
| 261 |
+
input_ids = beam.getCurrentState()
|
| 262 |
+
context = context.repeat(1, self.beam_size, 1)
|
| 263 |
+
context_mask = context_mask.repeat(self.beam_size, 1)
|
| 264 |
+
for _ in range(self.max_length):
|
| 265 |
+
if beam.done():
|
| 266 |
+
break
|
| 267 |
+
attn_mask = -1e4 * (1 - self.bias[:input_ids.shape[1], :input_ids.shape[1]])
|
| 268 |
+
tgt_embeddings = self.encoder.embeddings(input_ids).permute([1, 0, 2]).contiguous()
|
| 269 |
+
out = self.decoder(tgt_embeddings, context, tgt_mask=attn_mask,
|
| 270 |
+
memory_key_padding_mask=~context_mask)
|
| 271 |
+
# memory_key_padding_mask=(1 - context_mask).bool())
|
| 272 |
+
out = torch.tanh(self.dense(out))
|
| 273 |
+
hidden_states = out.permute([1, 0, 2]).contiguous()[:, -1, :]
|
| 274 |
+
out = self.lsm(self.lm_head(hidden_states)).data
|
| 275 |
+
beam.advance(out)
|
| 276 |
+
input_ids.data.copy_(input_ids.data.index_select(0, beam.getCurrentOrigin()))
|
| 277 |
+
input_ids = torch.cat((input_ids, beam.getCurrentState()), -1)
|
| 278 |
+
hyp = beam.getHyp(beam.getFinal())
|
| 279 |
+
pred = beam.buildTargetTokens(hyp)[:self.beam_size]
|
| 280 |
+
pred = [torch.cat([x.view(-1) for x in p] + [zero] * (self.max_length - len(p))).view(1, -1) for p in
|
| 281 |
+
pred]
|
| 282 |
+
preds.append(torch.cat(pred, 0).unsqueeze(0))
|
| 283 |
+
|
| 284 |
+
preds = torch.cat(preds, 0)
|
| 285 |
+
return preds
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
class Beam(object):
|
| 289 |
+
def __init__(self, size, sos, eos):
|
| 290 |
+
self.size = size
|
| 291 |
+
self.tt = torch.cuda
|
| 292 |
+
# The score for each translation on the beam.
|
| 293 |
+
self.scores = self.tt.FloatTensor(size).zero_()
|
| 294 |
+
# The backpointers at each time-step.
|
| 295 |
+
self.prevKs = []
|
| 296 |
+
# The outputs at each time-step.
|
| 297 |
+
self.nextYs = [self.tt.LongTensor(size)
|
| 298 |
+
.fill_(0)]
|
| 299 |
+
self.nextYs[0][0] = sos
|
| 300 |
+
# Has EOS topped the beam yet.
|
| 301 |
+
self._eos = eos
|
| 302 |
+
self.eosTop = False
|
| 303 |
+
# Time and k pair for finished.
|
| 304 |
+
self.finished = []
|
| 305 |
+
|
| 306 |
+
def getCurrentState(self):
|
| 307 |
+
"Get the outputs for the current timestep."
|
| 308 |
+
batch = self.tt.LongTensor(self.nextYs[-1]).view(-1, 1)
|
| 309 |
+
return batch
|
| 310 |
+
|
| 311 |
+
def getCurrentOrigin(self):
|
| 312 |
+
"Get the backpointers for the current timestep."
|
| 313 |
+
return self.prevKs[-1]
|
| 314 |
+
|
| 315 |
+
def advance(self, wordLk):
|
| 316 |
+
"""
|
| 317 |
+
Given prob over words for every last beam `wordLk` and attention
|
| 318 |
+
`attnOut`: Compute and update the beam search.
|
| 319 |
+
|
| 320 |
+
Parameters:
|
| 321 |
+
|
| 322 |
+
* `wordLk`- probs of advancing from the last step (K x words)
|
| 323 |
+
* `attnOut`- attention at the last step
|
| 324 |
+
|
| 325 |
+
Returns: True if beam search is complete.
|
| 326 |
+
"""
|
| 327 |
+
numWords = wordLk.size(1)
|
| 328 |
+
|
| 329 |
+
# Sum the previous scores.
|
| 330 |
+
if len(self.prevKs) > 0:
|
| 331 |
+
beamLk = wordLk + self.scores.unsqueeze(1).expand_as(wordLk)
|
| 332 |
+
|
| 333 |
+
# Don't let EOS have children.
|
| 334 |
+
for i in range(self.nextYs[-1].size(0)):
|
| 335 |
+
if self.nextYs[-1][i] == self._eos:
|
| 336 |
+
beamLk[i] = -1e20
|
| 337 |
+
else:
|
| 338 |
+
beamLk = wordLk[0]
|
| 339 |
+
flatBeamLk = beamLk.view(-1)
|
| 340 |
+
bestScores, bestScoresId = flatBeamLk.topk(self.size, 0, True, True)
|
| 341 |
+
|
| 342 |
+
self.scores = bestScores
|
| 343 |
+
|
| 344 |
+
# bestScoresId is flattened beam x word array, so calculate which
|
| 345 |
+
# word and beam each score came from
|
| 346 |
+
prevK = bestScoresId // numWords
|
| 347 |
+
self.prevKs.append(prevK)
|
| 348 |
+
self.nextYs.append((bestScoresId - prevK * numWords))
|
| 349 |
+
|
| 350 |
+
for i in range(self.nextYs[-1].size(0)):
|
| 351 |
+
if self.nextYs[-1][i] == self._eos:
|
| 352 |
+
s = self.scores[i]
|
| 353 |
+
self.finished.append((s, len(self.nextYs) - 1, i))
|
| 354 |
+
|
| 355 |
+
# End condition is when top-of-beam is EOS and no global score.
|
| 356 |
+
if self.nextYs[-1][0] == self._eos:
|
| 357 |
+
self.eosTop = True
|
| 358 |
+
|
| 359 |
+
def done(self):
|
| 360 |
+
return self.eosTop and len(self.finished) >= self.size
|
| 361 |
+
|
| 362 |
+
def getFinal(self):
|
| 363 |
+
if len(self.finished) == 0:
|
| 364 |
+
self.finished.append((self.scores[0], len(self.nextYs) - 1, 0))
|
| 365 |
+
self.finished.sort(key=lambda a: -a[0])
|
| 366 |
+
if len(self.finished) != self.size:
|
| 367 |
+
unfinished = []
|
| 368 |
+
for i in range(self.nextYs[-1].size(0)):
|
| 369 |
+
if self.nextYs[-1][i] != self._eos:
|
| 370 |
+
s = self.scores[i]
|
| 371 |
+
unfinished.append((s, len(self.nextYs) - 1, i))
|
| 372 |
+
unfinished.sort(key=lambda a: -a[0])
|
| 373 |
+
self.finished += unfinished[:self.size - len(self.finished)]
|
| 374 |
+
return self.finished[:self.size]
|
| 375 |
+
|
| 376 |
+
def getHyp(self, beam_res):
|
| 377 |
+
"""
|
| 378 |
+
Walk back to construct the full hypothesis.
|
| 379 |
+
"""
|
| 380 |
+
hyps = []
|
| 381 |
+
for _, timestep, k in beam_res:
|
| 382 |
+
hyp = []
|
| 383 |
+
for j in range(len(self.prevKs[:timestep]) - 1, -1, -1):
|
| 384 |
+
hyp.append(self.nextYs[j + 1][k])
|
| 385 |
+
k = self.prevKs[j][k]
|
| 386 |
+
hyps.append(hyp[::-1])
|
| 387 |
+
return hyps
|
| 388 |
+
|
| 389 |
+
def buildTargetTokens(self, preds):
|
| 390 |
+
sentence = []
|
| 391 |
+
for pred in preds:
|
| 392 |
+
tokens = []
|
| 393 |
+
for tok in pred:
|
| 394 |
+
if tok == self._eos:
|
| 395 |
+
break
|
| 396 |
+
tokens.append(tok)
|
| 397 |
+
sentence.append(tokens)
|
| 398 |
+
return sentence
|
run_clone.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).
|
| 18 |
+
GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned
|
| 19 |
+
using a masked language modeling (MLM) loss.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
from __future__ import absolute_import
|
| 23 |
+
import os
|
| 24 |
+
import pdb
|
| 25 |
+
|
| 26 |
+
from models import CloneModel
|
| 27 |
+
import logging
|
| 28 |
+
import argparse
|
| 29 |
+
import math
|
| 30 |
+
import numpy as np
|
| 31 |
+
from io import open
|
| 32 |
+
from tqdm import tqdm
|
| 33 |
+
import torch
|
| 34 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 35 |
+
from torch.utils.data import DataLoader, SequentialSampler, RandomSampler
|
| 36 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 37 |
+
from transformers import (AdamW, get_linear_schedule_with_warmup,
|
| 38 |
+
RobertaConfig, RobertaModel, RobertaTokenizer,
|
| 39 |
+
BartConfig, BartForConditionalGeneration, BartTokenizer,
|
| 40 |
+
T5Config, T5ForConditionalGeneration, T5Tokenizer)
|
| 41 |
+
import multiprocessing
|
| 42 |
+
from sklearn.metrics import recall_score, precision_score, f1_score
|
| 43 |
+
import time
|
| 44 |
+
|
| 45 |
+
from configs import add_args, set_seed
|
| 46 |
+
from utils import get_filenames, get_elapse_time, load_and_cache_clone_data
|
| 47 |
+
from models import get_model_size
|
| 48 |
+
|
| 49 |
+
MODEL_CLASSES = {'roberta': (RobertaConfig, RobertaModel, RobertaTokenizer),
|
| 50 |
+
't5': (T5Config, T5ForConditionalGeneration, T5Tokenizer),
|
| 51 |
+
'codet5': (T5Config, T5ForConditionalGeneration, RobertaTokenizer),
|
| 52 |
+
'bart': (BartConfig, BartForConditionalGeneration, BartTokenizer)}
|
| 53 |
+
|
| 54 |
+
cpu_cont = multiprocessing.cpu_count()
|
| 55 |
+
|
| 56 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 57 |
+
datefmt='%m/%d/%Y %H:%M:%S',
|
| 58 |
+
level=logging.INFO)
|
| 59 |
+
logger = logging.getLogger(__name__)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def evaluate(args, model, eval_examples, eval_data, write_to_pred=False):
|
| 63 |
+
eval_sampler = SequentialSampler(eval_data)
|
| 64 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
|
| 65 |
+
|
| 66 |
+
# Eval!
|
| 67 |
+
logger.info("***** Running evaluation *****")
|
| 68 |
+
logger.info(" Num examples = %d", len(eval_examples))
|
| 69 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 70 |
+
eval_loss = 0.0
|
| 71 |
+
nb_eval_steps = 0
|
| 72 |
+
model.eval()
|
| 73 |
+
logits = []
|
| 74 |
+
y_trues = []
|
| 75 |
+
for batch in tqdm(eval_dataloader, total=len(eval_dataloader), desc="Evaluating"):
|
| 76 |
+
inputs = batch[0].to(args.device)
|
| 77 |
+
labels = batch[1].to(args.device)
|
| 78 |
+
with torch.no_grad():
|
| 79 |
+
lm_loss, logit = model(inputs, labels)
|
| 80 |
+
eval_loss += lm_loss.mean().item()
|
| 81 |
+
logits.append(logit.cpu().numpy())
|
| 82 |
+
y_trues.append(labels.cpu().numpy())
|
| 83 |
+
nb_eval_steps += 1
|
| 84 |
+
logits = np.concatenate(logits, 0)
|
| 85 |
+
y_trues = np.concatenate(y_trues, 0)
|
| 86 |
+
best_threshold = 0.5
|
| 87 |
+
|
| 88 |
+
y_preds = logits[:, 1] > best_threshold
|
| 89 |
+
recall = recall_score(y_trues, y_preds)
|
| 90 |
+
precision = precision_score(y_trues, y_preds)
|
| 91 |
+
f1 = f1_score(y_trues, y_preds)
|
| 92 |
+
result = {
|
| 93 |
+
"eval_recall": float(recall),
|
| 94 |
+
"eval_precision": float(precision),
|
| 95 |
+
"eval_f1": float(f1),
|
| 96 |
+
"eval_threshold": best_threshold,
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
logger.info("***** Eval results *****")
|
| 100 |
+
for key in sorted(result.keys()):
|
| 101 |
+
logger.info(" %s = %s", key, str(round(result[key], 4)))
|
| 102 |
+
logger.info(" " + "*" * 20)
|
| 103 |
+
|
| 104 |
+
if write_to_pred:
|
| 105 |
+
with open(os.path.join(args.output_dir, "predictions.txt"), 'w') as f:
|
| 106 |
+
for example, pred in zip(eval_examples, y_preds):
|
| 107 |
+
if pred:
|
| 108 |
+
f.write(example.url1 + '\t' + example.url2 + '\t' + '1' + '\n')
|
| 109 |
+
else:
|
| 110 |
+
f.write(example.url1 + '\t' + example.url2 + '\t' + '0' + '\n')
|
| 111 |
+
|
| 112 |
+
return result
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def main():
|
| 116 |
+
parser = argparse.ArgumentParser()
|
| 117 |
+
t0 = time.time()
|
| 118 |
+
args = add_args(parser)
|
| 119 |
+
logger.info(args)
|
| 120 |
+
|
| 121 |
+
# Setup CUDA, GPU & distributed training
|
| 122 |
+
if args.local_rank == -1 or args.no_cuda:
|
| 123 |
+
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
| 124 |
+
args.n_gpu = torch.cuda.device_count()
|
| 125 |
+
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
|
| 126 |
+
torch.cuda.set_device(args.local_rank)
|
| 127 |
+
device = torch.device("cuda", args.local_rank)
|
| 128 |
+
torch.distributed.init_process_group(backend='nccl')
|
| 129 |
+
args.n_gpu = 1
|
| 130 |
+
|
| 131 |
+
logger.warning("Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, cpu count: %d",
|
| 132 |
+
args.local_rank, device, args.n_gpu, bool(args.local_rank != -1), cpu_cont)
|
| 133 |
+
args.device = device
|
| 134 |
+
set_seed(args)
|
| 135 |
+
|
| 136 |
+
# Build model
|
| 137 |
+
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
|
| 138 |
+
config = config_class.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 139 |
+
model = model_class.from_pretrained(args.model_name_or_path)
|
| 140 |
+
tokenizer = tokenizer_class.from_pretrained(args.tokenizer_name)
|
| 141 |
+
model.resize_token_embeddings(32000)
|
| 142 |
+
|
| 143 |
+
model = CloneModel(model, config, tokenizer, args)
|
| 144 |
+
logger.info("Finish loading model [%s] from %s", get_model_size(model), args.model_name_or_path)
|
| 145 |
+
|
| 146 |
+
if args.load_model_path is not None:
|
| 147 |
+
logger.info("Reload model from {}".format(args.load_model_path))
|
| 148 |
+
model.load_state_dict(torch.load(args.load_model_path))
|
| 149 |
+
|
| 150 |
+
model.to(device)
|
| 151 |
+
|
| 152 |
+
pool = multiprocessing.Pool(cpu_cont)
|
| 153 |
+
args.train_filename, args.dev_filename, args.test_filename = get_filenames(args.data_dir, args.task, args.sub_task)
|
| 154 |
+
fa = open(os.path.join(args.output_dir, 'summary.log'), 'a+')
|
| 155 |
+
|
| 156 |
+
if args.do_train:
|
| 157 |
+
if args.n_gpu > 1:
|
| 158 |
+
# multi-gpu training
|
| 159 |
+
model = torch.nn.DataParallel(model)
|
| 160 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 161 |
+
summary_fn = '{}/{}'.format(args.summary_dir, '/'.join(args.output_dir.split('/')[1:]))
|
| 162 |
+
tb_writer = SummaryWriter(summary_fn)
|
| 163 |
+
|
| 164 |
+
# Prepare training data loader
|
| 165 |
+
train_examples, train_data = load_and_cache_clone_data(args, args.train_filename, pool, tokenizer, 'train',
|
| 166 |
+
is_sample=False)
|
| 167 |
+
if args.local_rank == -1:
|
| 168 |
+
train_sampler = RandomSampler(train_data)
|
| 169 |
+
else:
|
| 170 |
+
train_sampler = DistributedSampler(train_data)
|
| 171 |
+
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.train_batch_size)
|
| 172 |
+
|
| 173 |
+
num_train_optimization_steps = args.num_train_epochs * len(train_dataloader)
|
| 174 |
+
save_steps = max(len(train_dataloader) // 5, 1)
|
| 175 |
+
|
| 176 |
+
# Prepare optimizer and schedule (linear warmup and decay)
|
| 177 |
+
no_decay = ['bias', 'LayerNorm.weight']
|
| 178 |
+
optimizer_grouped_parameters = [
|
| 179 |
+
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 180 |
+
'weight_decay': args.weight_decay},
|
| 181 |
+
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
|
| 182 |
+
]
|
| 183 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
|
| 184 |
+
|
| 185 |
+
if args.warmup_steps < 1:
|
| 186 |
+
warmup_steps = num_train_optimization_steps * args.warmup_steps
|
| 187 |
+
else:
|
| 188 |
+
warmup_steps = int(args.warmup_steps)
|
| 189 |
+
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps,
|
| 190 |
+
num_training_steps=num_train_optimization_steps)
|
| 191 |
+
|
| 192 |
+
# Start training
|
| 193 |
+
train_example_num = len(train_data)
|
| 194 |
+
logger.info("***** Running training *****")
|
| 195 |
+
logger.info(" Num examples = %d", train_example_num)
|
| 196 |
+
logger.info(" Batch size = %d", args.train_batch_size)
|
| 197 |
+
logger.info(" Batch num = %d", math.ceil(train_example_num / args.train_batch_size))
|
| 198 |
+
logger.info(" Num epoch = %d", args.num_train_epochs)
|
| 199 |
+
|
| 200 |
+
global_step, best_f1 = 0, 0
|
| 201 |
+
not_f1_inc_cnt = 0
|
| 202 |
+
is_early_stop = False
|
| 203 |
+
for cur_epoch in range(args.start_epoch, int(args.num_train_epochs)):
|
| 204 |
+
bar = tqdm(train_dataloader, total=len(train_dataloader), desc="Training")
|
| 205 |
+
nb_tr_examples, nb_tr_steps, tr_loss = 0, 0, 0
|
| 206 |
+
model.train()
|
| 207 |
+
for step, batch in enumerate(bar):
|
| 208 |
+
batch = tuple(t.to(device) for t in batch)
|
| 209 |
+
source_ids, labels = batch
|
| 210 |
+
# pdb.set_trace()
|
| 211 |
+
|
| 212 |
+
loss, logits = model(source_ids, labels)
|
| 213 |
+
|
| 214 |
+
if args.n_gpu > 1:
|
| 215 |
+
loss = loss.mean() # mean() to average on multi-gpu.
|
| 216 |
+
if args.gradient_accumulation_steps > 1:
|
| 217 |
+
loss = loss / args.gradient_accumulation_steps
|
| 218 |
+
tr_loss += loss.item()
|
| 219 |
+
|
| 220 |
+
nb_tr_examples += source_ids.size(0)
|
| 221 |
+
nb_tr_steps += 1
|
| 222 |
+
loss.backward()
|
| 223 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 224 |
+
|
| 225 |
+
if nb_tr_steps % args.gradient_accumulation_steps == 0:
|
| 226 |
+
# Update parameters
|
| 227 |
+
optimizer.step()
|
| 228 |
+
optimizer.zero_grad()
|
| 229 |
+
scheduler.step()
|
| 230 |
+
global_step += 1
|
| 231 |
+
train_loss = round(tr_loss * args.gradient_accumulation_steps / nb_tr_steps, 4)
|
| 232 |
+
bar.set_description("[{}] Train loss {}".format(cur_epoch, round(train_loss, 3)))
|
| 233 |
+
|
| 234 |
+
if (step + 1) % save_steps == 0 and args.do_eval:
|
| 235 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 236 |
+
torch.cuda.empty_cache()
|
| 237 |
+
|
| 238 |
+
eval_examples, eval_data = load_and_cache_clone_data(args, args.dev_filename, pool, tokenizer,
|
| 239 |
+
'valid', is_sample=True)
|
| 240 |
+
|
| 241 |
+
result = evaluate(args, model, eval_examples, eval_data)
|
| 242 |
+
eval_f1 = result['eval_f1']
|
| 243 |
+
|
| 244 |
+
if args.data_num == -1:
|
| 245 |
+
tb_writer.add_scalar('dev_f1', round(eval_f1, 4), cur_epoch)
|
| 246 |
+
|
| 247 |
+
# save last checkpoint
|
| 248 |
+
last_output_dir = os.path.join(args.output_dir, 'checkpoint-last')
|
| 249 |
+
if not os.path.exists(last_output_dir):
|
| 250 |
+
os.makedirs(last_output_dir)
|
| 251 |
+
|
| 252 |
+
if True or args.data_num == -1 and args.save_last_checkpoints:
|
| 253 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 254 |
+
output_model_file = os.path.join(last_output_dir, "pytorch_model.bin")
|
| 255 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 256 |
+
logger.info("Save the last model into %s", output_model_file)
|
| 257 |
+
|
| 258 |
+
if eval_f1 > best_f1:
|
| 259 |
+
not_f1_inc_cnt = 0
|
| 260 |
+
logger.info(" Best f1: %s", round(eval_f1, 4))
|
| 261 |
+
logger.info(" " + "*" * 20)
|
| 262 |
+
fa.write("[%d] Best f1 changed into %.4f\n" % (cur_epoch, round(eval_f1, 4)))
|
| 263 |
+
best_f1 = eval_f1
|
| 264 |
+
# Save best checkpoint for best ppl
|
| 265 |
+
output_dir = os.path.join(args.output_dir, 'checkpoint-best-f1')
|
| 266 |
+
if not os.path.exists(output_dir):
|
| 267 |
+
os.makedirs(output_dir)
|
| 268 |
+
if args.data_num == -1 or True:
|
| 269 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 270 |
+
output_model_file = os.path.join(output_dir, "pytorch_model.bin")
|
| 271 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 272 |
+
logger.info("Save the best ppl model into %s", output_model_file)
|
| 273 |
+
else:
|
| 274 |
+
not_f1_inc_cnt += 1
|
| 275 |
+
logger.info("F1 does not increase for %d epochs", not_f1_inc_cnt)
|
| 276 |
+
if not_f1_inc_cnt > args.patience:
|
| 277 |
+
logger.info("Early stop as f1 do not increase for %d times", not_f1_inc_cnt)
|
| 278 |
+
fa.write("[%d] Early stop as not_f1_inc_cnt=%d\n" % (cur_epoch, not_f1_inc_cnt))
|
| 279 |
+
is_early_stop = True
|
| 280 |
+
break
|
| 281 |
+
|
| 282 |
+
model.train()
|
| 283 |
+
if is_early_stop:
|
| 284 |
+
break
|
| 285 |
+
|
| 286 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 287 |
+
torch.cuda.empty_cache()
|
| 288 |
+
|
| 289 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 290 |
+
tb_writer.close()
|
| 291 |
+
|
| 292 |
+
if args.do_test:
|
| 293 |
+
logger.info(" " + "***** Testing *****")
|
| 294 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 295 |
+
|
| 296 |
+
for criteria in ['best-f1']:
|
| 297 |
+
file = os.path.join(args.output_dir, 'checkpoint-{}/pytorch_model.bin'.format(criteria))
|
| 298 |
+
logger.info("Reload model from {}".format(file))
|
| 299 |
+
model.load_state_dict(torch.load(file))
|
| 300 |
+
|
| 301 |
+
if args.n_gpu > 1:
|
| 302 |
+
# multi-gpu training
|
| 303 |
+
model = torch.nn.DataParallel(model)
|
| 304 |
+
|
| 305 |
+
eval_examples, eval_data = load_and_cache_clone_data(args, args.test_filename, pool, tokenizer, 'test',
|
| 306 |
+
False)
|
| 307 |
+
|
| 308 |
+
result = evaluate(args, model, eval_examples, eval_data, write_to_pred=True)
|
| 309 |
+
logger.info(" test_f1=%.4f", result['eval_f1'])
|
| 310 |
+
logger.info(" test_prec=%.4f", result['eval_precision'])
|
| 311 |
+
logger.info(" test_rec=%.4f", result['eval_recall'])
|
| 312 |
+
logger.info(" " + "*" * 20)
|
| 313 |
+
|
| 314 |
+
fa.write("[%s] test-f1: %.4f, precision: %.4f, recall: %.4f\n" % (
|
| 315 |
+
criteria, result['eval_f1'], result['eval_precision'], result['eval_recall']))
|
| 316 |
+
if args.res_fn:
|
| 317 |
+
with open(args.res_fn, 'a+') as f:
|
| 318 |
+
f.write('[Time: {}] {}\n'.format(get_elapse_time(t0), file))
|
| 319 |
+
f.write("[%s] f1: %.4f, precision: %.4f, recall: %.4f\n\n" % (
|
| 320 |
+
criteria, result['eval_f1'], result['eval_precision'], result['eval_recall']))
|
| 321 |
+
fa.close()
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
if __name__ == "__main__":
|
| 325 |
+
main()
|
run_defect.py
ADDED
|
@@ -0,0 +1,314 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).
|
| 18 |
+
GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned
|
| 19 |
+
using a masked language modeling (MLM) loss.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
from __future__ import absolute_import
|
| 23 |
+
import os
|
| 24 |
+
import logging
|
| 25 |
+
import argparse
|
| 26 |
+
import math
|
| 27 |
+
import numpy as np
|
| 28 |
+
from io import open
|
| 29 |
+
from tqdm import tqdm
|
| 30 |
+
import torch
|
| 31 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 32 |
+
from torch.utils.data import DataLoader, Dataset, SequentialSampler, RandomSampler, TensorDataset
|
| 33 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 34 |
+
from transformers import (WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup,
|
| 35 |
+
RobertaConfig, RobertaModel, RobertaTokenizer,
|
| 36 |
+
BartConfig, BartForConditionalGeneration, BartTokenizer,
|
| 37 |
+
T5Config, T5ForConditionalGeneration, T5Tokenizer)
|
| 38 |
+
import multiprocessing
|
| 39 |
+
import time
|
| 40 |
+
|
| 41 |
+
from models import DefectModel
|
| 42 |
+
from configs import add_args, set_seed
|
| 43 |
+
from utils import get_filenames, get_elapse_time, load_and_cache_defect_data
|
| 44 |
+
from models import get_model_size
|
| 45 |
+
|
| 46 |
+
MODEL_CLASSES = {'roberta': (RobertaConfig, RobertaModel, RobertaTokenizer),
|
| 47 |
+
't5': (T5Config, T5ForConditionalGeneration, T5Tokenizer),
|
| 48 |
+
'codet5': (T5Config, T5ForConditionalGeneration, RobertaTokenizer),
|
| 49 |
+
'bart': (BartConfig, BartForConditionalGeneration, BartTokenizer)}
|
| 50 |
+
|
| 51 |
+
cpu_cont = multiprocessing.cpu_count()
|
| 52 |
+
|
| 53 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 54 |
+
datefmt='%m/%d/%Y %H:%M:%S',
|
| 55 |
+
level=logging.INFO)
|
| 56 |
+
logger = logging.getLogger(__name__)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def evaluate(args, model, eval_examples, eval_data, write_to_pred=False):
|
| 60 |
+
eval_sampler = SequentialSampler(eval_data)
|
| 61 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
|
| 62 |
+
|
| 63 |
+
# Eval!
|
| 64 |
+
logger.info("***** Running evaluation *****")
|
| 65 |
+
logger.info(" Num examples = %d", len(eval_examples))
|
| 66 |
+
logger.info(" Num batches = %d", len(eval_dataloader))
|
| 67 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 68 |
+
eval_loss = 0.0
|
| 69 |
+
nb_eval_steps = 0
|
| 70 |
+
model.eval()
|
| 71 |
+
logits = []
|
| 72 |
+
labels = []
|
| 73 |
+
for batch in tqdm(eval_dataloader, total=len(eval_dataloader), desc="Evaluating"):
|
| 74 |
+
inputs = batch[0].to(args.device)
|
| 75 |
+
label = batch[1].to(args.device)
|
| 76 |
+
with torch.no_grad():
|
| 77 |
+
lm_loss, logit = model(inputs, label)
|
| 78 |
+
eval_loss += lm_loss.mean().item()
|
| 79 |
+
logits.append(logit.cpu().numpy())
|
| 80 |
+
labels.append(label.cpu().numpy())
|
| 81 |
+
nb_eval_steps += 1
|
| 82 |
+
logits = np.concatenate(logits, 0)
|
| 83 |
+
labels = np.concatenate(labels, 0)
|
| 84 |
+
preds = logits[:, 1] > 0.5
|
| 85 |
+
eval_acc = np.mean(labels == preds)
|
| 86 |
+
eval_loss = eval_loss / nb_eval_steps
|
| 87 |
+
perplexity = torch.tensor(eval_loss)
|
| 88 |
+
|
| 89 |
+
result = {
|
| 90 |
+
"eval_loss": float(perplexity),
|
| 91 |
+
"eval_acc": round(eval_acc, 4),
|
| 92 |
+
}
|
| 93 |
+
|
| 94 |
+
logger.info("***** Eval results *****")
|
| 95 |
+
for key in sorted(result.keys()):
|
| 96 |
+
logger.info(" %s = %s", key, str(round(result[key], 4)))
|
| 97 |
+
|
| 98 |
+
if write_to_pred:
|
| 99 |
+
with open(os.path.join(args.output_dir, "predictions.txt"), 'w') as f:
|
| 100 |
+
for example, pred in zip(eval_examples, preds):
|
| 101 |
+
if pred:
|
| 102 |
+
f.write(str(example.idx) + '\t1\n')
|
| 103 |
+
else:
|
| 104 |
+
f.write(str(example.idx) + '\t0\n')
|
| 105 |
+
|
| 106 |
+
return result
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def main():
|
| 110 |
+
parser = argparse.ArgumentParser()
|
| 111 |
+
t0 = time.time()
|
| 112 |
+
args = add_args(parser)
|
| 113 |
+
logger.info(args)
|
| 114 |
+
|
| 115 |
+
# Setup CUDA, GPU & distributed training
|
| 116 |
+
if args.local_rank == -1 or args.no_cuda:
|
| 117 |
+
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
|
| 118 |
+
args.n_gpu = torch.cuda.device_count()
|
| 119 |
+
else: # Initializes the distributed backend which will take care of sychronizing nodes/GPUs
|
| 120 |
+
torch.cuda.set_device(args.local_rank)
|
| 121 |
+
device = torch.device("cuda", args.local_rank)
|
| 122 |
+
torch.distributed.init_process_group(backend='nccl')
|
| 123 |
+
args.n_gpu = 1
|
| 124 |
+
|
| 125 |
+
logger.warning("Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, cpu count: %d",
|
| 126 |
+
args.local_rank, device, args.n_gpu, bool(args.local_rank != -1), cpu_cont)
|
| 127 |
+
args.device = device
|
| 128 |
+
set_seed(args)
|
| 129 |
+
|
| 130 |
+
# Build model
|
| 131 |
+
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
|
| 132 |
+
config = config_class.from_pretrained(args.config_name if args.config_name else args.model_name_or_path)
|
| 133 |
+
model = model_class.from_pretrained(args.model_name_or_path)
|
| 134 |
+
tokenizer = tokenizer_class.from_pretrained(args.tokenizer_name)
|
| 135 |
+
|
| 136 |
+
model = DefectModel(model, config, tokenizer, args)
|
| 137 |
+
logger.info("Finish loading model [%s] from %s", get_model_size(model), args.model_name_or_path)
|
| 138 |
+
|
| 139 |
+
if args.load_model_path is not None:
|
| 140 |
+
logger.info("Reload model from {}".format(args.load_model_path))
|
| 141 |
+
model.load_state_dict(torch.load(args.load_model_path))
|
| 142 |
+
|
| 143 |
+
model.to(device)
|
| 144 |
+
|
| 145 |
+
pool = multiprocessing.Pool(cpu_cont)
|
| 146 |
+
args.train_filename, args.dev_filename, args.test_filename = get_filenames(args.data_dir, args.task, args.sub_task)
|
| 147 |
+
fa = open(os.path.join(args.output_dir, 'summary.log'), 'a+')
|
| 148 |
+
|
| 149 |
+
if args.do_train:
|
| 150 |
+
if args.n_gpu > 1:
|
| 151 |
+
# multi-gpu training
|
| 152 |
+
model = torch.nn.DataParallel(model)
|
| 153 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 154 |
+
summary_fn = '{}/{}'.format(args.summary_dir, '/'.join(args.output_dir.split('/')[1:]))
|
| 155 |
+
tb_writer = SummaryWriter(summary_fn)
|
| 156 |
+
|
| 157 |
+
# Prepare training data loader
|
| 158 |
+
train_examples, train_data = load_and_cache_defect_data(args, args.train_filename, pool, tokenizer, 'train',
|
| 159 |
+
is_sample=False)
|
| 160 |
+
if args.local_rank == -1:
|
| 161 |
+
train_sampler = RandomSampler(train_data)
|
| 162 |
+
else:
|
| 163 |
+
train_sampler = DistributedSampler(train_data)
|
| 164 |
+
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.train_batch_size)
|
| 165 |
+
|
| 166 |
+
num_train_optimization_steps = args.num_train_epochs * len(train_dataloader)
|
| 167 |
+
save_steps = max(len(train_dataloader), 1)
|
| 168 |
+
|
| 169 |
+
# Prepare optimizer and schedule (linear warmup and decay)
|
| 170 |
+
no_decay = ['bias', 'LayerNorm.weight']
|
| 171 |
+
optimizer_grouped_parameters = [
|
| 172 |
+
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 173 |
+
'weight_decay': args.weight_decay},
|
| 174 |
+
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
|
| 175 |
+
]
|
| 176 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
|
| 177 |
+
|
| 178 |
+
if args.warmup_steps < 1:
|
| 179 |
+
warmup_steps = num_train_optimization_steps * args.warmup_steps
|
| 180 |
+
else:
|
| 181 |
+
warmup_steps = int(args.warmup_steps)
|
| 182 |
+
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps,
|
| 183 |
+
num_training_steps=num_train_optimization_steps)
|
| 184 |
+
|
| 185 |
+
# Start training
|
| 186 |
+
train_example_num = len(train_data)
|
| 187 |
+
logger.info("***** Running training *****")
|
| 188 |
+
logger.info(" Num examples = %d", train_example_num)
|
| 189 |
+
logger.info(" Batch size = %d", args.train_batch_size)
|
| 190 |
+
logger.info(" Batch num = %d", math.ceil(train_example_num / args.train_batch_size))
|
| 191 |
+
logger.info(" Num epoch = %d", args.num_train_epochs)
|
| 192 |
+
|
| 193 |
+
global_step, best_acc = 0, 0
|
| 194 |
+
not_acc_inc_cnt = 0
|
| 195 |
+
is_early_stop = False
|
| 196 |
+
for cur_epoch in range(args.start_epoch, int(args.num_train_epochs)):
|
| 197 |
+
bar = tqdm(train_dataloader, total=len(train_dataloader), desc="Training")
|
| 198 |
+
nb_tr_examples, nb_tr_steps, tr_loss = 0, 0, 0
|
| 199 |
+
model.train()
|
| 200 |
+
for step, batch in enumerate(bar):
|
| 201 |
+
batch = tuple(t.to(device) for t in batch)
|
| 202 |
+
source_ids, labels = batch
|
| 203 |
+
|
| 204 |
+
loss, logits = model(source_ids, labels)
|
| 205 |
+
|
| 206 |
+
if args.n_gpu > 1:
|
| 207 |
+
loss = loss.mean() # mean() to average on multi-gpu.
|
| 208 |
+
if args.gradient_accumulation_steps > 1:
|
| 209 |
+
loss = loss / args.gradient_accumulation_steps
|
| 210 |
+
tr_loss += loss.item()
|
| 211 |
+
|
| 212 |
+
nb_tr_examples += source_ids.size(0)
|
| 213 |
+
nb_tr_steps += 1
|
| 214 |
+
loss.backward()
|
| 215 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
|
| 216 |
+
|
| 217 |
+
if nb_tr_steps % args.gradient_accumulation_steps == 0:
|
| 218 |
+
# Update parameters
|
| 219 |
+
optimizer.step()
|
| 220 |
+
optimizer.zero_grad()
|
| 221 |
+
scheduler.step()
|
| 222 |
+
global_step += 1
|
| 223 |
+
train_loss = round(tr_loss * args.gradient_accumulation_steps / nb_tr_steps, 4)
|
| 224 |
+
bar.set_description("[{}] Train loss {}".format(cur_epoch, round(train_loss, 3)))
|
| 225 |
+
|
| 226 |
+
if (step + 1) % save_steps == 0 and args.do_eval:
|
| 227 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 228 |
+
torch.cuda.empty_cache()
|
| 229 |
+
|
| 230 |
+
eval_examples, eval_data = load_and_cache_defect_data(args, args.dev_filename, pool, tokenizer,
|
| 231 |
+
'valid', is_sample=False)
|
| 232 |
+
|
| 233 |
+
result = evaluate(args, model, eval_examples, eval_data)
|
| 234 |
+
eval_acc = result['eval_acc']
|
| 235 |
+
|
| 236 |
+
if args.data_num == -1:
|
| 237 |
+
tb_writer.add_scalar('dev_acc', round(eval_acc, 4), cur_epoch)
|
| 238 |
+
|
| 239 |
+
# save last checkpoint
|
| 240 |
+
last_output_dir = os.path.join(args.output_dir, 'checkpoint-last')
|
| 241 |
+
if not os.path.exists(last_output_dir):
|
| 242 |
+
os.makedirs(last_output_dir)
|
| 243 |
+
|
| 244 |
+
if True or args.data_num == -1 and args.save_last_checkpoints:
|
| 245 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 246 |
+
output_model_file = os.path.join(last_output_dir, "pytorch_model.bin")
|
| 247 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 248 |
+
logger.info("Save the last model into %s", output_model_file)
|
| 249 |
+
|
| 250 |
+
if eval_acc > best_acc:
|
| 251 |
+
not_acc_inc_cnt = 0
|
| 252 |
+
logger.info(" Best acc: %s", round(eval_acc, 4))
|
| 253 |
+
logger.info(" " + "*" * 20)
|
| 254 |
+
fa.write("[%d] Best acc changed into %.4f\n" % (cur_epoch, round(eval_acc, 4)))
|
| 255 |
+
best_acc = eval_acc
|
| 256 |
+
# Save best checkpoint for best ppl
|
| 257 |
+
output_dir = os.path.join(args.output_dir, 'checkpoint-best-acc')
|
| 258 |
+
if not os.path.exists(output_dir):
|
| 259 |
+
os.makedirs(output_dir)
|
| 260 |
+
if args.data_num == -1 or True:
|
| 261 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 262 |
+
output_model_file = os.path.join(output_dir, "pytorch_model.bin")
|
| 263 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 264 |
+
logger.info("Save the best ppl model into %s", output_model_file)
|
| 265 |
+
else:
|
| 266 |
+
not_acc_inc_cnt += 1
|
| 267 |
+
logger.info("acc does not increase for %d epochs", not_acc_inc_cnt)
|
| 268 |
+
if not_acc_inc_cnt > args.patience:
|
| 269 |
+
logger.info("Early stop as acc do not increase for %d times", not_acc_inc_cnt)
|
| 270 |
+
fa.write("[%d] Early stop as not_acc_inc_cnt=%d\n" % (cur_epoch, not_acc_inc_cnt))
|
| 271 |
+
is_early_stop = True
|
| 272 |
+
break
|
| 273 |
+
|
| 274 |
+
model.train()
|
| 275 |
+
if is_early_stop:
|
| 276 |
+
break
|
| 277 |
+
|
| 278 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 279 |
+
torch.cuda.empty_cache()
|
| 280 |
+
|
| 281 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 282 |
+
tb_writer.close()
|
| 283 |
+
|
| 284 |
+
if args.do_test:
|
| 285 |
+
logger.info(" " + "***** Testing *****")
|
| 286 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 287 |
+
|
| 288 |
+
for criteria in ['best-acc']:
|
| 289 |
+
file = os.path.join(args.output_dir, 'checkpoint-{}/pytorch_model.bin'.format(criteria))
|
| 290 |
+
logger.info("Reload model from {}".format(file))
|
| 291 |
+
model.load_state_dict(torch.load(file))
|
| 292 |
+
|
| 293 |
+
if args.n_gpu > 1:
|
| 294 |
+
# multi-gpu training
|
| 295 |
+
model = torch.nn.DataParallel(model)
|
| 296 |
+
|
| 297 |
+
eval_examples, eval_data = load_and_cache_defect_data(args, args.test_filename, pool, tokenizer, 'test',
|
| 298 |
+
False)
|
| 299 |
+
|
| 300 |
+
result = evaluate(args, model, eval_examples, eval_data, write_to_pred=True)
|
| 301 |
+
logger.info(" test_acc=%.4f", result['eval_acc'])
|
| 302 |
+
logger.info(" " + "*" * 20)
|
| 303 |
+
|
| 304 |
+
fa.write("[%s] test-acc: %.4f\n" % (criteria, result['eval_acc']))
|
| 305 |
+
if args.res_fn:
|
| 306 |
+
with open(args.res_fn, 'a+') as f:
|
| 307 |
+
f.write('[Time: {}] {}\n'.format(get_elapse_time(t0), file))
|
| 308 |
+
f.write("[%s] acc: %.4f\n\n" % (
|
| 309 |
+
criteria, result['eval_acc']))
|
| 310 |
+
fa.close()
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
if __name__ == "__main__":
|
| 314 |
+
main()
|
run_gen.py
ADDED
|
@@ -0,0 +1,387 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).
|
| 18 |
+
GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned
|
| 19 |
+
using a masked language modeling (MLM) loss.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
import os
|
| 23 |
+
import logging
|
| 24 |
+
import argparse
|
| 25 |
+
import math
|
| 26 |
+
import numpy as np
|
| 27 |
+
from tqdm import tqdm
|
| 28 |
+
import multiprocessing
|
| 29 |
+
import time
|
| 30 |
+
|
| 31 |
+
import torch
|
| 32 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 33 |
+
from torch.utils.data import DataLoader, SequentialSampler, RandomSampler
|
| 34 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 35 |
+
from transformers import AdamW, get_linear_schedule_with_warmup
|
| 36 |
+
from models import build_or_load_gen_model
|
| 37 |
+
from evaluator import smooth_bleu
|
| 38 |
+
from evaluator.CodeBLEU import calc_code_bleu
|
| 39 |
+
from evaluator.bleu import _bleu
|
| 40 |
+
from utils import get_filenames, get_elapse_time, load_and_cache_gen_data
|
| 41 |
+
from configs import add_args, set_seed, set_dist
|
| 42 |
+
|
| 43 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 44 |
+
datefmt='%m/%d/%Y %H:%M:%S',
|
| 45 |
+
level=logging.INFO)
|
| 46 |
+
logger = logging.getLogger(__name__)
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def eval_ppl_epoch(args, eval_data, eval_examples, model, tokenizer):
|
| 50 |
+
eval_sampler = SequentialSampler(eval_data)
|
| 51 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size,
|
| 52 |
+
num_workers=4, pin_memory=True)
|
| 53 |
+
# Start evaluating model
|
| 54 |
+
logger.info(" " + "***** Running ppl evaluation *****")
|
| 55 |
+
logger.info(" Num examples = %d", len(eval_examples))
|
| 56 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 57 |
+
|
| 58 |
+
model.eval()
|
| 59 |
+
eval_loss, batch_num = 0, 0
|
| 60 |
+
for batch in tqdm(eval_dataloader, total=len(eval_dataloader), desc="Eval ppl"):
|
| 61 |
+
batch = tuple(t.to(args.device) for t in batch)
|
| 62 |
+
source_ids, target_ids = batch
|
| 63 |
+
source_mask = source_ids.ne(tokenizer.pad_token_id)
|
| 64 |
+
target_mask = target_ids.ne(tokenizer.pad_token_id)
|
| 65 |
+
|
| 66 |
+
with torch.no_grad():
|
| 67 |
+
if args.model_type == 'roberta':
|
| 68 |
+
loss, _, _ = model(source_ids=source_ids, source_mask=source_mask,
|
| 69 |
+
target_ids=target_ids, target_mask=target_mask)
|
| 70 |
+
else:
|
| 71 |
+
outputs = model(input_ids=source_ids, attention_mask=source_mask,
|
| 72 |
+
labels=target_ids, decoder_attention_mask=target_mask)
|
| 73 |
+
loss = outputs.loss
|
| 74 |
+
|
| 75 |
+
eval_loss += loss.item()
|
| 76 |
+
batch_num += 1
|
| 77 |
+
eval_loss = eval_loss / batch_num
|
| 78 |
+
eval_ppl = round(np.exp(eval_loss), 5)
|
| 79 |
+
return eval_ppl
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
def eval_bleu_epoch(args, eval_data, eval_examples, model, tokenizer, split_tag, criteria):
|
| 83 |
+
logger.info(" ***** Running bleu evaluation on {} data*****".format(split_tag))
|
| 84 |
+
logger.info(" Num examples = %d", len(eval_examples))
|
| 85 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 86 |
+
eval_sampler = SequentialSampler(eval_data)
|
| 87 |
+
if args.data_num == -1:
|
| 88 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size,
|
| 89 |
+
num_workers=4, pin_memory=True)
|
| 90 |
+
else:
|
| 91 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
|
| 92 |
+
|
| 93 |
+
model.eval()
|
| 94 |
+
pred_ids = []
|
| 95 |
+
bleu, codebleu = 0.0, 0.0
|
| 96 |
+
for batch in tqdm(eval_dataloader, total=len(eval_dataloader), desc="Eval bleu for {} set".format(split_tag)):
|
| 97 |
+
source_ids = batch[0].to(args.device)
|
| 98 |
+
source_mask = source_ids.ne(tokenizer.pad_token_id)
|
| 99 |
+
with torch.no_grad():
|
| 100 |
+
if args.model_type == 'roberta':
|
| 101 |
+
preds = model(source_ids=source_ids, source_mask=source_mask)
|
| 102 |
+
|
| 103 |
+
top_preds = [pred[0].cpu().numpy() for pred in preds]
|
| 104 |
+
else:
|
| 105 |
+
preds = model.generate(source_ids,
|
| 106 |
+
attention_mask=source_mask,
|
| 107 |
+
use_cache=True,
|
| 108 |
+
num_beams=args.beam_size,
|
| 109 |
+
early_stopping=args.task == 'summarize',
|
| 110 |
+
max_length=args.max_target_length)
|
| 111 |
+
top_preds = list(preds.cpu().numpy())
|
| 112 |
+
pred_ids.extend(top_preds)
|
| 113 |
+
|
| 114 |
+
pred_nls = [tokenizer.decode(id, skip_special_tokens=True, clean_up_tokenization_spaces=False) for id in pred_ids]
|
| 115 |
+
|
| 116 |
+
output_fn = os.path.join(args.res_dir, "test_{}.output".format(criteria))
|
| 117 |
+
gold_fn = os.path.join(args.res_dir, "test_{}.gold".format(criteria))
|
| 118 |
+
src_fn = os.path.join(args.res_dir, "test_{}.src".format(criteria))
|
| 119 |
+
|
| 120 |
+
if args.task in ['defect']:
|
| 121 |
+
target_dict = {0: 'false', 1: 'true'}
|
| 122 |
+
golds = [target_dict[ex.target] for ex in eval_examples]
|
| 123 |
+
eval_acc = np.mean([int(p == g) for p, g in zip(pred_nls, golds)])
|
| 124 |
+
result = {'em': eval_acc * 100, 'bleu': 0, 'codebleu': 0}
|
| 125 |
+
|
| 126 |
+
with open(output_fn, 'w') as f, open(gold_fn, 'w') as f1, open(src_fn, 'w') as f2:
|
| 127 |
+
for pred_nl, gold in zip(pred_nls, eval_examples):
|
| 128 |
+
f.write(pred_nl.strip() + '\n')
|
| 129 |
+
f1.write(target_dict[gold.target] + '\n')
|
| 130 |
+
f2.write(gold.source.strip() + '\n')
|
| 131 |
+
logger.info("Save the predictions into %s", output_fn)
|
| 132 |
+
else:
|
| 133 |
+
dev_accs, predictions = [], []
|
| 134 |
+
with open(output_fn, 'w') as f, open(gold_fn, 'w') as f1, open(src_fn, 'w') as f2:
|
| 135 |
+
for pred_nl, gold in zip(pred_nls, eval_examples):
|
| 136 |
+
dev_accs.append(pred_nl.strip() == gold.target.strip())
|
| 137 |
+
if args.task in ['summarize']:
|
| 138 |
+
# for smooth-bleu4 evaluation
|
| 139 |
+
predictions.append(str(gold.idx) + '\t' + pred_nl)
|
| 140 |
+
f.write(str(gold.idx) + '\t' + pred_nl.strip() + '\n')
|
| 141 |
+
f1.write(str(gold.idx) + '\t' + gold.target.strip() + '\n')
|
| 142 |
+
f2.write(str(gold.idx) + '\t' + gold.source.strip() + '\n')
|
| 143 |
+
else:
|
| 144 |
+
f.write(pred_nl.strip() + '\n')
|
| 145 |
+
f1.write(gold.target.strip() + '\n')
|
| 146 |
+
f2.write(gold.source.strip() + '\n')
|
| 147 |
+
|
| 148 |
+
if args.task == 'summarize':
|
| 149 |
+
(goldMap, predictionMap) = smooth_bleu.computeMaps(predictions, gold_fn)
|
| 150 |
+
bleu = round(smooth_bleu.bleuFromMaps(goldMap, predictionMap)[0], 2)
|
| 151 |
+
else:
|
| 152 |
+
bleu = round(_bleu(gold_fn, output_fn), 2)
|
| 153 |
+
if args.task in ['concode', 'translate', 'refine']:
|
| 154 |
+
codebleu = calc_code_bleu.get_codebleu(gold_fn, output_fn, args.lang)
|
| 155 |
+
|
| 156 |
+
result = {'em': np.mean(dev_accs) * 100, 'bleu': bleu}
|
| 157 |
+
if args.task == 'concode':
|
| 158 |
+
result['codebleu'] = codebleu * 100
|
| 159 |
+
|
| 160 |
+
logger.info("***** Eval results *****")
|
| 161 |
+
for key in sorted(result.keys()):
|
| 162 |
+
logger.info(" %s = %s", key, str(round(result[key], 4)))
|
| 163 |
+
|
| 164 |
+
return result
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def main():
|
| 168 |
+
parser = argparse.ArgumentParser()
|
| 169 |
+
args = add_args(parser)
|
| 170 |
+
logger.info(args)
|
| 171 |
+
t0 = time.time()
|
| 172 |
+
|
| 173 |
+
set_dist(args)
|
| 174 |
+
set_seed(args)
|
| 175 |
+
config, model, tokenizer = build_or_load_gen_model(args)
|
| 176 |
+
model.to(args.device)
|
| 177 |
+
if args.n_gpu > 1:
|
| 178 |
+
# for DataParallel
|
| 179 |
+
model = torch.nn.DataParallel(model)
|
| 180 |
+
pool = multiprocessing.Pool(args.cpu_cont)
|
| 181 |
+
args.train_filename, args.dev_filename, args.test_filename = get_filenames(args.data_dir, args.task, args.sub_task)
|
| 182 |
+
fa = open(os.path.join(args.output_dir, 'summary.log'), 'a+')
|
| 183 |
+
|
| 184 |
+
if args.do_train:
|
| 185 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 186 |
+
summary_fn = '{}/{}'.format(args.summary_dir, '/'.join(args.output_dir.split('/')[1:]))
|
| 187 |
+
tb_writer = SummaryWriter(summary_fn)
|
| 188 |
+
|
| 189 |
+
# Prepare training data loader
|
| 190 |
+
train_examples, train_data = load_and_cache_gen_data(args, args.train_filename, pool, tokenizer, 'train')
|
| 191 |
+
train_sampler = RandomSampler(train_data) if args.local_rank == -1 else DistributedSampler(train_data)
|
| 192 |
+
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.train_batch_size,
|
| 193 |
+
num_workers=4, pin_memory=True)
|
| 194 |
+
|
| 195 |
+
# Prepare optimizer and schedule (linear warmup and decay)
|
| 196 |
+
no_decay = ['bias', 'LayerNorm.weight']
|
| 197 |
+
optimizer_grouped_parameters = [
|
| 198 |
+
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 199 |
+
'weight_decay': args.weight_decay},
|
| 200 |
+
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
|
| 201 |
+
]
|
| 202 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
|
| 203 |
+
num_train_optimization_steps = args.num_train_epochs * len(train_dataloader)
|
| 204 |
+
scheduler = get_linear_schedule_with_warmup(optimizer,
|
| 205 |
+
num_warmup_steps=args.warmup_steps,
|
| 206 |
+
num_training_steps=num_train_optimization_steps)
|
| 207 |
+
|
| 208 |
+
# Start training
|
| 209 |
+
train_example_num = len(train_data)
|
| 210 |
+
logger.info("***** Running training *****")
|
| 211 |
+
logger.info(" Num examples = %d", train_example_num)
|
| 212 |
+
logger.info(" Batch size = %d", args.train_batch_size)
|
| 213 |
+
logger.info(" Batch num = %d", math.ceil(train_example_num / args.train_batch_size))
|
| 214 |
+
logger.info(" Num epoch = %d", args.num_train_epochs)
|
| 215 |
+
|
| 216 |
+
dev_dataset = {}
|
| 217 |
+
global_step, best_bleu_em, best_ppl = 0, -1, 1e6
|
| 218 |
+
not_loss_dec_cnt, not_bleu_em_inc_cnt = 0, 0 if args.do_eval_bleu else 1e6
|
| 219 |
+
|
| 220 |
+
for cur_epoch in range(args.start_epoch, int(args.num_train_epochs)):
|
| 221 |
+
bar = tqdm(train_dataloader, total=len(train_dataloader), desc="Training")
|
| 222 |
+
nb_tr_examples, nb_tr_steps, tr_loss = 0, 0, 0
|
| 223 |
+
model.train()
|
| 224 |
+
for step, batch in enumerate(bar):
|
| 225 |
+
batch = tuple(t.to(args.device) for t in batch)
|
| 226 |
+
source_ids, target_ids = batch
|
| 227 |
+
source_mask = source_ids.ne(tokenizer.pad_token_id)
|
| 228 |
+
target_mask = target_ids.ne(tokenizer.pad_token_id)
|
| 229 |
+
|
| 230 |
+
if args.model_type == 'roberta':
|
| 231 |
+
loss, _, _ = model(source_ids=source_ids, source_mask=source_mask,
|
| 232 |
+
target_ids=target_ids, target_mask=target_mask)
|
| 233 |
+
else:
|
| 234 |
+
outputs = model(input_ids=source_ids, attention_mask=source_mask,
|
| 235 |
+
labels=target_ids, decoder_attention_mask=target_mask)
|
| 236 |
+
loss = outputs.loss
|
| 237 |
+
|
| 238 |
+
if args.n_gpu > 1:
|
| 239 |
+
loss = loss.mean() # mean() to average on multi-gpu.
|
| 240 |
+
if args.gradient_accumulation_steps > 1:
|
| 241 |
+
loss = loss / args.gradient_accumulation_steps
|
| 242 |
+
tr_loss += loss.item()
|
| 243 |
+
|
| 244 |
+
nb_tr_examples += source_ids.size(0)
|
| 245 |
+
nb_tr_steps += 1
|
| 246 |
+
loss.backward()
|
| 247 |
+
|
| 248 |
+
if nb_tr_steps % args.gradient_accumulation_steps == 0:
|
| 249 |
+
# Update parameters
|
| 250 |
+
optimizer.step()
|
| 251 |
+
optimizer.zero_grad()
|
| 252 |
+
scheduler.step()
|
| 253 |
+
global_step += 1
|
| 254 |
+
train_loss = round(tr_loss * args.gradient_accumulation_steps / (nb_tr_steps + 1), 4)
|
| 255 |
+
bar.set_description("[{}] Train loss {}".format(cur_epoch, round(train_loss, 3)))
|
| 256 |
+
|
| 257 |
+
if args.do_eval:
|
| 258 |
+
# Eval model with dev dataset
|
| 259 |
+
if 'dev_loss' in dev_dataset:
|
| 260 |
+
eval_examples, eval_data = dev_dataset['dev_loss']
|
| 261 |
+
else:
|
| 262 |
+
eval_examples, eval_data = load_and_cache_gen_data(args, args.dev_filename, pool, tokenizer, 'dev')
|
| 263 |
+
dev_dataset['dev_loss'] = eval_examples, eval_data
|
| 264 |
+
|
| 265 |
+
eval_ppl = eval_ppl_epoch(args, eval_data, eval_examples, model, tokenizer)
|
| 266 |
+
result = {'epoch': cur_epoch, 'global_step': global_step, 'eval_ppl': eval_ppl}
|
| 267 |
+
for key in sorted(result.keys()):
|
| 268 |
+
logger.info(" %s = %s", key, str(result[key]))
|
| 269 |
+
logger.info(" " + "*" * 20)
|
| 270 |
+
if args.data_num == -1:
|
| 271 |
+
tb_writer.add_scalar('dev_ppl', eval_ppl, cur_epoch)
|
| 272 |
+
|
| 273 |
+
# save last checkpoint
|
| 274 |
+
if args.save_last_checkpoints:
|
| 275 |
+
last_output_dir = os.path.join(args.output_dir, 'checkpoint-last')
|
| 276 |
+
if not os.path.exists(last_output_dir):
|
| 277 |
+
os.makedirs(last_output_dir)
|
| 278 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 279 |
+
output_model_file = os.path.join(last_output_dir, "pytorch_model.bin")
|
| 280 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 281 |
+
logger.info("Save the last model into %s", output_model_file)
|
| 282 |
+
|
| 283 |
+
if eval_ppl < best_ppl:
|
| 284 |
+
not_loss_dec_cnt = 0
|
| 285 |
+
logger.info(" Best ppl:%s", eval_ppl)
|
| 286 |
+
logger.info(" " + "*" * 20)
|
| 287 |
+
fa.write("[%d] Best ppl changed into %.4f\n" % (cur_epoch, eval_ppl))
|
| 288 |
+
best_ppl = eval_ppl
|
| 289 |
+
|
| 290 |
+
# Save best checkpoint for best ppl
|
| 291 |
+
output_dir = os.path.join(args.output_dir, 'checkpoint-best-ppl')
|
| 292 |
+
if not os.path.exists(output_dir):
|
| 293 |
+
os.makedirs(output_dir)
|
| 294 |
+
if args.always_save_model:
|
| 295 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 296 |
+
output_model_file = os.path.join(output_dir, "pytorch_model.bin")
|
| 297 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 298 |
+
logger.info("Save the best ppl model into %s", output_model_file)
|
| 299 |
+
else:
|
| 300 |
+
not_loss_dec_cnt += 1
|
| 301 |
+
logger.info("Ppl does not decrease for %d epochs", not_loss_dec_cnt)
|
| 302 |
+
if all([x > args.patience for x in [not_bleu_em_inc_cnt, not_loss_dec_cnt]]):
|
| 303 |
+
early_stop_str = "[%d] Early stop as not_bleu_em_inc_cnt=%d, and not_loss_dec_cnt=%d\n" % (
|
| 304 |
+
cur_epoch, not_bleu_em_inc_cnt, not_loss_dec_cnt)
|
| 305 |
+
logger.info(early_stop_str)
|
| 306 |
+
fa.write(early_stop_str)
|
| 307 |
+
break
|
| 308 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 309 |
+
torch.cuda.empty_cache()
|
| 310 |
+
if args.do_eval_bleu:
|
| 311 |
+
eval_examples, eval_data = load_and_cache_gen_data(args, args.dev_filename, pool, tokenizer, 'dev',
|
| 312 |
+
only_src=True, is_sample=True)
|
| 313 |
+
|
| 314 |
+
result = eval_bleu_epoch(args, eval_data, eval_examples, model, tokenizer, 'dev', 'e%d' % cur_epoch)
|
| 315 |
+
dev_bleu, dev_em = result['bleu'], result['em']
|
| 316 |
+
if args.task in ['summarize']:
|
| 317 |
+
dev_bleu_em = dev_bleu
|
| 318 |
+
elif args.task in ['defect']:
|
| 319 |
+
dev_bleu_em = dev_em
|
| 320 |
+
else:
|
| 321 |
+
dev_bleu_em = dev_bleu + dev_em
|
| 322 |
+
if args.data_num == -1:
|
| 323 |
+
tb_writer.add_scalar('dev_bleu_em', dev_bleu_em, cur_epoch)
|
| 324 |
+
# tb_writer.add_scalar('dev_em', dev_em, cur_epoch)
|
| 325 |
+
if dev_bleu_em > best_bleu_em:
|
| 326 |
+
not_bleu_em_inc_cnt = 0
|
| 327 |
+
logger.info(" [%d] Best bleu+em: %.2f (bleu: %.2f, em: %.2f)",
|
| 328 |
+
cur_epoch, dev_bleu_em, dev_bleu, dev_em)
|
| 329 |
+
logger.info(" " + "*" * 20)
|
| 330 |
+
best_bleu_em = dev_bleu_em
|
| 331 |
+
fa.write("[%d] Best bleu+em changed into %.2f (bleu: %.2f, em: %.2f)\n" % (
|
| 332 |
+
cur_epoch, best_bleu_em, dev_bleu, dev_em))
|
| 333 |
+
# Save best checkpoint for best bleu
|
| 334 |
+
output_dir = os.path.join(args.output_dir, 'checkpoint-best-bleu')
|
| 335 |
+
if not os.path.exists(output_dir):
|
| 336 |
+
os.makedirs(output_dir)
|
| 337 |
+
if args.data_num == -1 or args.always_save_model:
|
| 338 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 339 |
+
output_model_file = os.path.join(output_dir, "pytorch_model.bin")
|
| 340 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 341 |
+
logger.info("Save the best bleu model into %s", output_model_file)
|
| 342 |
+
else:
|
| 343 |
+
not_bleu_em_inc_cnt += 1
|
| 344 |
+
logger.info("Bleu does not increase for %d epochs", not_bleu_em_inc_cnt)
|
| 345 |
+
fa.write(
|
| 346 |
+
"[%d] Best bleu+em (%.2f) does not drop changed for %d epochs, cur bleu+em: %.2f (bleu: %.2f, em: %.2f)\n" % (
|
| 347 |
+
cur_epoch, best_bleu_em, not_bleu_em_inc_cnt, dev_bleu_em, dev_bleu, dev_em))
|
| 348 |
+
if all([x > args.patience for x in [not_bleu_em_inc_cnt, not_loss_dec_cnt]]):
|
| 349 |
+
stop_early_str = "[%d] Early stop as not_bleu_em_inc_cnt=%d, and not_loss_dec_cnt=%d\n" % (
|
| 350 |
+
cur_epoch, not_bleu_em_inc_cnt, not_loss_dec_cnt)
|
| 351 |
+
logger.info(stop_early_str)
|
| 352 |
+
fa.write(stop_early_str)
|
| 353 |
+
break
|
| 354 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 355 |
+
torch.cuda.empty_cache()
|
| 356 |
+
|
| 357 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 358 |
+
tb_writer.close()
|
| 359 |
+
logger.info("Finish training and take %s", get_elapse_time(t0))
|
| 360 |
+
|
| 361 |
+
if args.do_test:
|
| 362 |
+
logger.info(" " + "***** Testing *****")
|
| 363 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 364 |
+
|
| 365 |
+
for criteria in ['best-bleu']:
|
| 366 |
+
file = os.path.join(args.output_dir, 'checkpoint-{}/pytorch_model.bin'.format(criteria))
|
| 367 |
+
logger.info("Reload model from {}".format(file))
|
| 368 |
+
model.load_state_dict(torch.load(file))
|
| 369 |
+
eval_examples, eval_data = load_and_cache_gen_data(args, args.test_filename, pool, tokenizer, 'test',
|
| 370 |
+
only_src=True, is_sample=False)
|
| 371 |
+
result = eval_bleu_epoch(args, eval_data, eval_examples, model, tokenizer, 'test', criteria)
|
| 372 |
+
test_bleu, test_em = result['bleu'], result['em']
|
| 373 |
+
test_codebleu = result['codebleu'] if 'codebleu' in result else 0
|
| 374 |
+
result_str = "[%s] bleu-4: %.2f, em: %.4f, codebleu: %.4f\n" % (criteria, test_bleu, test_em, test_codebleu)
|
| 375 |
+
logger.info(result_str)
|
| 376 |
+
fa.write(result_str)
|
| 377 |
+
if args.res_fn:
|
| 378 |
+
with open(args.res_fn, 'a+') as f:
|
| 379 |
+
f.write('[Time: {}] {}\n'.format(get_elapse_time(t0), file))
|
| 380 |
+
f.write(result_str)
|
| 381 |
+
logger.info("Finish and take {}".format(get_elapse_time(t0)))
|
| 382 |
+
fa.write("Finish and take {}".format(get_elapse_time(t0)))
|
| 383 |
+
fa.close()
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
if __name__ == "__main__":
|
| 387 |
+
main()
|
run_multi_gen.py
ADDED
|
@@ -0,0 +1,535 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
|
| 3 |
+
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""
|
| 17 |
+
Fine-tuning the library models for language modeling on a text file (GPT, GPT-2, BERT, RoBERTa).
|
| 18 |
+
GPT and GPT-2 are fine-tuned using a causal language modeling (CLM) loss while BERT and RoBERTa are fine-tuned
|
| 19 |
+
using a masked language modeling (MLM) loss.
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
import os
|
| 23 |
+
import torch
|
| 24 |
+
import logging
|
| 25 |
+
import argparse
|
| 26 |
+
import math
|
| 27 |
+
import numpy as np
|
| 28 |
+
from tqdm import tqdm
|
| 29 |
+
from itertools import cycle
|
| 30 |
+
import multiprocessing
|
| 31 |
+
import time
|
| 32 |
+
import sys
|
| 33 |
+
import pdb
|
| 34 |
+
|
| 35 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 36 |
+
from torch.utils.data import DataLoader, SequentialSampler, RandomSampler
|
| 37 |
+
from torch.utils.data.distributed import DistributedSampler
|
| 38 |
+
from transformers import AdamW, get_linear_schedule_with_warmup
|
| 39 |
+
from models import build_or_load_gen_model
|
| 40 |
+
from evaluator import smooth_bleu
|
| 41 |
+
from evaluator.CodeBLEU import calc_code_bleu
|
| 42 |
+
from evaluator.bleu import _bleu
|
| 43 |
+
from utils import get_elapse_time, load_and_cache_multi_gen_data
|
| 44 |
+
from configs import add_args, set_seed, set_dist
|
| 45 |
+
|
| 46 |
+
cpu_cont = multiprocessing.cpu_count()
|
| 47 |
+
|
| 48 |
+
logging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(message)s',
|
| 49 |
+
datefmt='%m/%d/%Y %H:%M:%S',
|
| 50 |
+
level=logging.INFO)
|
| 51 |
+
logger = logging.getLogger(__name__)
|
| 52 |
+
WORKER_NUM = 0
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def get_max_trg_len_by_task(task, sub_task):
|
| 56 |
+
if task == 'summarize':
|
| 57 |
+
max_target_length = 128
|
| 58 |
+
elif task == 'translate':
|
| 59 |
+
max_target_length = 256
|
| 60 |
+
elif task == 'refine':
|
| 61 |
+
if sub_task == 'small':
|
| 62 |
+
max_target_length = 120
|
| 63 |
+
else:
|
| 64 |
+
max_target_length = 240
|
| 65 |
+
elif task == 'concode':
|
| 66 |
+
max_target_length = 150
|
| 67 |
+
elif task == 'defect':
|
| 68 |
+
max_target_length = 3
|
| 69 |
+
return max_target_length
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def get_bs(cur_task, model_tag):
|
| 73 |
+
task = cur_task.split('_')[0]
|
| 74 |
+
sub_task = cur_task.split('_')[-1]
|
| 75 |
+
if 'codet5_small' in model_tag:
|
| 76 |
+
bs = 32
|
| 77 |
+
if task == 'summarize' or task == 'translate' or (task == 'refine' and sub_task == 'small'):
|
| 78 |
+
bs = 64
|
| 79 |
+
else:
|
| 80 |
+
# codet5_base
|
| 81 |
+
bs = 28
|
| 82 |
+
if task == 'translate':
|
| 83 |
+
bs = 25
|
| 84 |
+
elif task == 'summarize':
|
| 85 |
+
bs = 40
|
| 86 |
+
return bs
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def eval_bleu(args, eval_data, eval_examples, model, tokenizer, split_tag, cur_task, criteria):
|
| 90 |
+
eval_sampler = SequentialSampler(eval_data)
|
| 91 |
+
if args.data_num == -1:
|
| 92 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size,
|
| 93 |
+
num_workers=4, pin_memory=True)
|
| 94 |
+
else:
|
| 95 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
|
| 96 |
+
task = cur_task.split('_')[0]
|
| 97 |
+
sub_task = cur_task.split('_')[-1]
|
| 98 |
+
max_target_length = get_max_trg_len_by_task(task, sub_task)
|
| 99 |
+
|
| 100 |
+
model.eval()
|
| 101 |
+
pred_ids = []
|
| 102 |
+
for batch in tqdm(eval_dataloader, total=len(eval_dataloader), desc="Eval bleu for {} set".format(split_tag)):
|
| 103 |
+
source_ids = batch[0].to(args.device)
|
| 104 |
+
source_mask = source_ids.ne(tokenizer.pad_token_id)
|
| 105 |
+
with torch.no_grad():
|
| 106 |
+
if args.model_type == 'roberta':
|
| 107 |
+
preds = model(source_ids=source_ids, source_mask=source_mask)
|
| 108 |
+
|
| 109 |
+
top_preds = [pred[0].cpu().numpy() for pred in preds]
|
| 110 |
+
else:
|
| 111 |
+
preds = model.generate(source_ids,
|
| 112 |
+
attention_mask=source_mask,
|
| 113 |
+
use_cache=True,
|
| 114 |
+
num_beams=5,
|
| 115 |
+
max_length=max_target_length, # length_penalty=0.6,
|
| 116 |
+
early_stopping=task == 'summarize')
|
| 117 |
+
top_preds = list(preds.cpu().numpy())
|
| 118 |
+
pred_ids.extend(top_preds)
|
| 119 |
+
|
| 120 |
+
pred_nls = [tokenizer.decode(id, skip_special_tokens=True, clean_up_tokenization_spaces=False) for id in pred_ids]
|
| 121 |
+
if task == 'defect':
|
| 122 |
+
target_dict = {0: 'false', 1: 'true'}
|
| 123 |
+
golds = [target_dict[ex.target] for ex in eval_examples]
|
| 124 |
+
eval_acc = np.mean([int(p == g) for p, g in zip(pred_nls, golds)])
|
| 125 |
+
result = {'em': eval_acc, 'bleu': 0, 'codebleu': 0}
|
| 126 |
+
|
| 127 |
+
else:
|
| 128 |
+
dev_accs = []
|
| 129 |
+
predictions = []
|
| 130 |
+
res_dir = os.path.join(args.res_dir, cur_task)
|
| 131 |
+
if not os.path.exists(res_dir):
|
| 132 |
+
os.makedirs(res_dir)
|
| 133 |
+
output_fn = os.path.join(res_dir, "test_{}.output".format(criteria))
|
| 134 |
+
gold_fn = os.path.join(res_dir, "test_{}.gold".format(criteria))
|
| 135 |
+
with open(output_fn, 'w') as f, open(gold_fn, 'w') as f1:
|
| 136 |
+
for pred_nl, gold in zip(pred_nls, eval_examples):
|
| 137 |
+
dev_accs.append(pred_nl.strip() == gold.target.strip())
|
| 138 |
+
if task == 'summarize':
|
| 139 |
+
predictions.append(str(gold.idx) + '\t' + pred_nl)
|
| 140 |
+
f.write(str(gold.idx) + '\t' + pred_nl.strip() + '\n')
|
| 141 |
+
f1.write(str(gold.idx) + '\t' + gold.target.strip() + '\n')
|
| 142 |
+
else:
|
| 143 |
+
f.write(pred_nl.strip() + '\n')
|
| 144 |
+
f1.write(gold.target.strip() + '\n')
|
| 145 |
+
|
| 146 |
+
try:
|
| 147 |
+
if task == 'summarize':
|
| 148 |
+
(goldMap, predictionMap) = smooth_bleu.computeMaps(predictions, gold_fn)
|
| 149 |
+
bleu = round(smooth_bleu.bleuFromMaps(goldMap, predictionMap)[0], 2)
|
| 150 |
+
else:
|
| 151 |
+
|
| 152 |
+
bleu = round(_bleu(gold_fn, output_fn), 2)
|
| 153 |
+
if split_tag == 'test':
|
| 154 |
+
if task in ['summarize', 'search']:
|
| 155 |
+
cur_lang = sub_task
|
| 156 |
+
elif task in ['refine', 'concode', 'clone']:
|
| 157 |
+
cur_lang = 'java'
|
| 158 |
+
elif task == 'defect':
|
| 159 |
+
cur_lang = 'c'
|
| 160 |
+
elif task == 'translate':
|
| 161 |
+
cur_lang = 'c_sharp' if sub_task == 'java-cs' else 'java'
|
| 162 |
+
codebleu = calc_code_bleu.get_codebleu(gold_fn, output_fn, cur_lang)
|
| 163 |
+
except:
|
| 164 |
+
bleu = 0.0
|
| 165 |
+
codebleu = 0.0
|
| 166 |
+
|
| 167 |
+
result = {}
|
| 168 |
+
em = np.mean(dev_accs) * 100
|
| 169 |
+
result['em'] = em
|
| 170 |
+
result['bleu'] = bleu
|
| 171 |
+
if not args.task == 'summarize' and split_tag == 'test':
|
| 172 |
+
result['codebleu'] = codebleu * 100
|
| 173 |
+
|
| 174 |
+
logger.info("***** Eval results [%s] *****", cur_task)
|
| 175 |
+
for key in sorted(result.keys()):
|
| 176 |
+
logger.info(" %s = %s", key, str(round(result[key], 4)))
|
| 177 |
+
|
| 178 |
+
return result
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def main():
|
| 182 |
+
parser = argparse.ArgumentParser()
|
| 183 |
+
args = add_args(parser)
|
| 184 |
+
logger.info(args)
|
| 185 |
+
t0 = time.time()
|
| 186 |
+
|
| 187 |
+
set_dist(args)
|
| 188 |
+
set_seed(args)
|
| 189 |
+
config, model, tokenizer = build_or_load_gen_model(args)
|
| 190 |
+
model.to(args.device)
|
| 191 |
+
if args.n_gpu > 1:
|
| 192 |
+
# for DataParallel
|
| 193 |
+
model = torch.nn.DataParallel(model)
|
| 194 |
+
pool = multiprocessing.Pool(args.cpu_cont)
|
| 195 |
+
fa = open(os.path.join(args.output_dir, 'summary.log'), 'a+')
|
| 196 |
+
|
| 197 |
+
fa_dict = {}
|
| 198 |
+
if args.do_train:
|
| 199 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 200 |
+
summary_fn = './tensorboard/{}'.format('/'.join(args.output_dir.split('/')[1:]))
|
| 201 |
+
tb_writer = SummaryWriter(summary_fn)
|
| 202 |
+
|
| 203 |
+
# Prepare training data loader
|
| 204 |
+
train_examples_data_dict = load_and_cache_multi_gen_data(args, pool, tokenizer, 'train', is_sample=False)
|
| 205 |
+
train_data_list = [v[1] for k, v in train_examples_data_dict.items()]
|
| 206 |
+
all_tasks = [k for k, v in train_examples_data_dict.items()]
|
| 207 |
+
total_train_data_num = sum([len(v[0]) for k, v in train_examples_data_dict.items()])
|
| 208 |
+
|
| 209 |
+
for cur_task in all_tasks:
|
| 210 |
+
summary_dir = os.path.join(args.output_dir, 'summary')
|
| 211 |
+
if not os.path.exists(summary_dir):
|
| 212 |
+
os.makedirs(summary_dir)
|
| 213 |
+
fa_dict[cur_task] = open(os.path.join(summary_dir, '{}_summary.log'.format(cur_task)), 'a+')
|
| 214 |
+
|
| 215 |
+
train_dataloader_dict = dict()
|
| 216 |
+
for train_data, cur_task in zip(train_data_list, all_tasks):
|
| 217 |
+
if args.local_rank == -1:
|
| 218 |
+
train_sampler = RandomSampler(train_data)
|
| 219 |
+
else:
|
| 220 |
+
train_sampler = DistributedSampler(train_data)
|
| 221 |
+
if args.data_num == -1:
|
| 222 |
+
train_dataloader = DataLoader(train_data, sampler=train_sampler,
|
| 223 |
+
batch_size=get_bs(cur_task, args.model_name_or_path),
|
| 224 |
+
num_workers=WORKER_NUM, pin_memory=True)
|
| 225 |
+
else:
|
| 226 |
+
train_dataloader = DataLoader(train_data, sampler=train_sampler,
|
| 227 |
+
batch_size=get_bs(cur_task, args.model_name_or_path))
|
| 228 |
+
|
| 229 |
+
train_dataloader_dict[cur_task] = cycle(train_dataloader)
|
| 230 |
+
|
| 231 |
+
# Prepare optimizer and schedule (linear warmup and decay)
|
| 232 |
+
no_decay = ['bias', 'LayerNorm.weight']
|
| 233 |
+
optimizer_grouped_parameters = [
|
| 234 |
+
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
|
| 235 |
+
'weight_decay': args.weight_decay},
|
| 236 |
+
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
|
| 237 |
+
]
|
| 238 |
+
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
|
| 239 |
+
|
| 240 |
+
scheduler = get_linear_schedule_with_warmup(optimizer,
|
| 241 |
+
num_warmup_steps=args.warmup_steps,
|
| 242 |
+
num_training_steps=args.max_steps)
|
| 243 |
+
|
| 244 |
+
# Start training
|
| 245 |
+
logger.info("***** Running training *****")
|
| 246 |
+
logger.info(" Total train data num = %d", total_train_data_num)
|
| 247 |
+
logger.info(" Max step = %d, Save step = %d", args.max_steps, args.save_steps)
|
| 248 |
+
|
| 249 |
+
dev_dataset = {}
|
| 250 |
+
step, global_step = 0, 0
|
| 251 |
+
best_bleu_em = dict([(k, -1) for k in all_tasks])
|
| 252 |
+
best_loss = dict([(k, 1e6) for k in all_tasks])
|
| 253 |
+
not_bleu_em_inc_cnt = dict([(k, 0) for k in all_tasks])
|
| 254 |
+
is_early_stop = dict([(k, 0) for k in all_tasks])
|
| 255 |
+
|
| 256 |
+
patience_pairs = []
|
| 257 |
+
for cur_task in all_tasks:
|
| 258 |
+
task = cur_task.split('_')[0]
|
| 259 |
+
if task == 'summarize':
|
| 260 |
+
patience_pairs.append((cur_task, 2))
|
| 261 |
+
elif task == 'translate':
|
| 262 |
+
patience_pairs.append((cur_task, 5))
|
| 263 |
+
elif task == 'refine':
|
| 264 |
+
patience_pairs.append((cur_task, 5))
|
| 265 |
+
elif task == 'concode':
|
| 266 |
+
patience_pairs.append((cur_task, 3))
|
| 267 |
+
elif task == 'defect':
|
| 268 |
+
patience_pairs.append((cur_task, 2))
|
| 269 |
+
patience_dict = dict(patience_pairs)
|
| 270 |
+
logger.info('Patience: %s', patience_dict)
|
| 271 |
+
|
| 272 |
+
probs = [len(x) for x in train_data_list]
|
| 273 |
+
probs = [x / sum(probs) for x in probs]
|
| 274 |
+
probs = [x ** 0.7 for x in probs]
|
| 275 |
+
probs = [x / sum(probs) for x in probs]
|
| 276 |
+
|
| 277 |
+
nb_tr_examples, nb_tr_steps, tr_nb, tr_loss, logging_loss = 0, 0, 0, 0, 0
|
| 278 |
+
|
| 279 |
+
bar = tqdm(total=args.max_steps, desc="Training")
|
| 280 |
+
skip_cnt = 0
|
| 281 |
+
while True:
|
| 282 |
+
cur_task = np.random.choice(all_tasks, 1, p=probs)[0]
|
| 283 |
+
train_dataloader = train_dataloader_dict[cur_task]
|
| 284 |
+
if is_early_stop[cur_task]:
|
| 285 |
+
skip_cnt += 1
|
| 286 |
+
if skip_cnt > 50:
|
| 287 |
+
logger.info('All tasks have early stopped at %d', step)
|
| 288 |
+
break
|
| 289 |
+
continue
|
| 290 |
+
else:
|
| 291 |
+
skip_cnt = 0
|
| 292 |
+
|
| 293 |
+
step += 1
|
| 294 |
+
batch = next(train_dataloader)
|
| 295 |
+
|
| 296 |
+
model.train()
|
| 297 |
+
batch = tuple(t.to(args.device) for t in batch)
|
| 298 |
+
source_ids, target_ids = batch
|
| 299 |
+
# logger.info('cur_task: %s, bs: %d', cur_task, source_ids.shape[0])
|
| 300 |
+
source_mask = source_ids.ne(tokenizer.pad_token_id)
|
| 301 |
+
target_mask = target_ids.ne(tokenizer.pad_token_id)
|
| 302 |
+
# pdb.set_trace()
|
| 303 |
+
|
| 304 |
+
if args.model_type == 'roberta':
|
| 305 |
+
loss, _, _ = model(source_ids=source_ids, source_mask=source_mask,
|
| 306 |
+
target_ids=target_ids, target_mask=target_mask)
|
| 307 |
+
else:
|
| 308 |
+
outputs = model(input_ids=source_ids, attention_mask=source_mask,
|
| 309 |
+
labels=target_ids, decoder_attention_mask=target_mask)
|
| 310 |
+
loss = outputs.loss
|
| 311 |
+
|
| 312 |
+
if args.n_gpu > 1:
|
| 313 |
+
loss = loss.mean() # mean() to average on multi-gpu.
|
| 314 |
+
if args.gradient_accumulation_steps > 1:
|
| 315 |
+
loss = loss / args.gradient_accumulation_steps
|
| 316 |
+
tr_loss += loss.item()
|
| 317 |
+
|
| 318 |
+
nb_tr_examples += source_ids.size(0)
|
| 319 |
+
nb_tr_steps += 1
|
| 320 |
+
loss.backward()
|
| 321 |
+
|
| 322 |
+
if nb_tr_steps % args.gradient_accumulation_steps == 0:
|
| 323 |
+
# Update parameters
|
| 324 |
+
optimizer.step()
|
| 325 |
+
optimizer.zero_grad()
|
| 326 |
+
scheduler.step()
|
| 327 |
+
global_step += 1
|
| 328 |
+
train_loss = round((tr_loss - logging_loss) / (global_step - tr_nb), 6)
|
| 329 |
+
bar.update(1)
|
| 330 |
+
bar.set_description("[{}] Train loss {}".format(step, round(train_loss, 3)))
|
| 331 |
+
|
| 332 |
+
if args.local_rank in [-1, 0] and args.log_steps > 0 and global_step % args.log_steps == 0:
|
| 333 |
+
logging_loss = train_loss
|
| 334 |
+
tr_nb = global_step
|
| 335 |
+
|
| 336 |
+
if args.do_eval and args.local_rank in [-1, 0] \
|
| 337 |
+
and args.save_steps > 0 and global_step % args.save_steps == 0:
|
| 338 |
+
# save last checkpoint
|
| 339 |
+
if args.data_num == -1 and args.save_last_checkpoints:
|
| 340 |
+
last_output_dir = os.path.join(args.output_dir, 'checkpoint-last')
|
| 341 |
+
if not os.path.exists(last_output_dir):
|
| 342 |
+
os.makedirs(last_output_dir)
|
| 343 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 344 |
+
output_model_file = os.path.join(last_output_dir, "pytorch_model.bin")
|
| 345 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 346 |
+
logger.info("Save the last model into %s", output_model_file)
|
| 347 |
+
if global_step % 100000 == 0:
|
| 348 |
+
step_tag = '{}00k'.format(global_step // 100000)
|
| 349 |
+
last_output_dir = os.path.join(args.output_dir, 'checkpoint-step-{}'.format(step_tag))
|
| 350 |
+
if not os.path.exists(last_output_dir):
|
| 351 |
+
os.makedirs(last_output_dir)
|
| 352 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 353 |
+
output_model_file = os.path.join(last_output_dir, "pytorch_model.bin")
|
| 354 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 355 |
+
logger.info("Save the last model into %s", output_model_file)
|
| 356 |
+
# Eval model with dev dataset
|
| 357 |
+
if 'dev_loss' in dev_dataset:
|
| 358 |
+
eval_examples_data_dict = dev_dataset['dev_loss']
|
| 359 |
+
else:
|
| 360 |
+
eval_examples_data_dict = load_and_cache_multi_gen_data(args, pool, tokenizer, 'dev')
|
| 361 |
+
dev_dataset['dev_loss'] = eval_examples_data_dict
|
| 362 |
+
|
| 363 |
+
for cur_task in eval_examples_data_dict.keys():
|
| 364 |
+
if is_early_stop[cur_task]:
|
| 365 |
+
continue
|
| 366 |
+
eval_examples, eval_data = eval_examples_data_dict[cur_task]
|
| 367 |
+
eval_sampler = SequentialSampler(eval_data)
|
| 368 |
+
if args.data_num == -1:
|
| 369 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler,
|
| 370 |
+
batch_size=args.eval_batch_size,
|
| 371 |
+
num_workers=4, pin_memory=True)
|
| 372 |
+
else:
|
| 373 |
+
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler,
|
| 374 |
+
batch_size=args.eval_batch_size)
|
| 375 |
+
|
| 376 |
+
logger.info(" " + "***** Running ppl evaluation on [{}] *****".format(cur_task))
|
| 377 |
+
logger.info(" Num examples = %d", len(eval_examples))
|
| 378 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 379 |
+
|
| 380 |
+
# Start Evaluating model
|
| 381 |
+
model.eval()
|
| 382 |
+
eval_loss, batch_num = 0, 0
|
| 383 |
+
for batch in tqdm(eval_dataloader, total=len(eval_dataloader), desc="Eval ppl"):
|
| 384 |
+
batch = tuple(t.to(args.device) for t in batch)
|
| 385 |
+
source_ids, target_ids = batch
|
| 386 |
+
source_mask = source_ids.ne(tokenizer.pad_token_id)
|
| 387 |
+
target_mask = target_ids.ne(tokenizer.pad_token_id)
|
| 388 |
+
|
| 389 |
+
with torch.no_grad():
|
| 390 |
+
if args.model_type == 'roberta':
|
| 391 |
+
loss, _, _ = model(source_ids=source_ids, source_mask=source_mask,
|
| 392 |
+
target_ids=target_ids, target_mask=target_mask)
|
| 393 |
+
else:
|
| 394 |
+
outputs = model(input_ids=source_ids, attention_mask=source_mask,
|
| 395 |
+
labels=target_ids, decoder_attention_mask=target_mask)
|
| 396 |
+
loss = outputs.loss
|
| 397 |
+
|
| 398 |
+
eval_loss += loss.item()
|
| 399 |
+
batch_num += 1
|
| 400 |
+
# Pring loss of dev dataset
|
| 401 |
+
eval_loss = eval_loss / batch_num
|
| 402 |
+
result = {'cur_task': cur_task,
|
| 403 |
+
'global_step': global_step,
|
| 404 |
+
'eval_ppl': round(np.exp(eval_loss), 5),
|
| 405 |
+
'train_loss': round(train_loss, 5)}
|
| 406 |
+
for key in sorted(result.keys()):
|
| 407 |
+
logger.info(" %s = %s", key, str(result[key]))
|
| 408 |
+
logger.info(" " + "*" * 20)
|
| 409 |
+
|
| 410 |
+
if args.data_num == -1:
|
| 411 |
+
tb_writer.add_scalar('dev_ppl_{}'.format(cur_task),
|
| 412 |
+
round(np.exp(eval_loss), 5),
|
| 413 |
+
global_step)
|
| 414 |
+
|
| 415 |
+
if eval_loss < best_loss[cur_task]:
|
| 416 |
+
logger.info(" Best ppl:%s", round(np.exp(eval_loss), 5))
|
| 417 |
+
logger.info(" " + "*" * 20)
|
| 418 |
+
fa_dict[cur_task].write(
|
| 419 |
+
"[%d: %s] Best ppl changed into %.4f\n" % (global_step, cur_task, np.exp(eval_loss)))
|
| 420 |
+
best_loss[cur_task] = eval_loss
|
| 421 |
+
|
| 422 |
+
# Save best checkpoint for best ppl
|
| 423 |
+
output_dir = os.path.join(args.output_dir, 'checkpoint-best-ppl', cur_task)
|
| 424 |
+
if not os.path.exists(output_dir):
|
| 425 |
+
os.makedirs(output_dir)
|
| 426 |
+
if args.data_num == -1 or args.always_save_model:
|
| 427 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 428 |
+
output_model_file = os.path.join(output_dir, "pytorch_model.bin")
|
| 429 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 430 |
+
logger.info("Save the best ppl model into %s", output_model_file)
|
| 431 |
+
|
| 432 |
+
if args.do_eval_bleu:
|
| 433 |
+
eval_examples_data_dict = load_and_cache_multi_gen_data(args, pool, tokenizer, 'dev',
|
| 434 |
+
only_src=True, is_sample=True)
|
| 435 |
+
for cur_task in eval_examples_data_dict.keys():
|
| 436 |
+
if is_early_stop[cur_task]:
|
| 437 |
+
continue
|
| 438 |
+
eval_examples, eval_data = eval_examples_data_dict[cur_task]
|
| 439 |
+
|
| 440 |
+
# pdb.set_trace()
|
| 441 |
+
result = eval_bleu(args, eval_data, eval_examples, model, tokenizer, 'dev', cur_task,
|
| 442 |
+
criteria='e{}'.format(global_step))
|
| 443 |
+
dev_bleu, dev_em = result['bleu'], result['em']
|
| 444 |
+
if args.task == 'summarize':
|
| 445 |
+
dev_bleu_em = dev_bleu
|
| 446 |
+
elif args.task in ['defect', 'clone']:
|
| 447 |
+
dev_bleu_em = dev_em
|
| 448 |
+
else:
|
| 449 |
+
dev_bleu_em = dev_bleu + dev_em
|
| 450 |
+
if args.data_num == -1:
|
| 451 |
+
tb_writer.add_scalar('dev_bleu_em_{}'.format(cur_task), dev_bleu_em, global_step)
|
| 452 |
+
|
| 453 |
+
if dev_bleu_em > best_bleu_em[cur_task]:
|
| 454 |
+
not_bleu_em_inc_cnt[cur_task] = 0
|
| 455 |
+
logger.info(" [%d: %s] Best bleu+em: %.2f (bleu: %.2f, em: %.2f)",
|
| 456 |
+
global_step, cur_task, dev_bleu_em, dev_bleu, dev_em)
|
| 457 |
+
logger.info(" " + "*" * 20)
|
| 458 |
+
best_bleu_em[cur_task] = dev_bleu_em
|
| 459 |
+
fa_dict[cur_task].write(
|
| 460 |
+
"[%d: %s] Best bleu+em changed into %.2f (bleu: %.2f, em: %.2f)\n" % (
|
| 461 |
+
global_step, cur_task, best_bleu_em[cur_task], dev_bleu, dev_em))
|
| 462 |
+
# Save best checkpoint for best bleu
|
| 463 |
+
output_dir = os.path.join(args.output_dir, 'checkpoint-best-bleu', cur_task)
|
| 464 |
+
if not os.path.exists(output_dir):
|
| 465 |
+
os.makedirs(output_dir)
|
| 466 |
+
if args.data_num == -1 or args.always_save_model:
|
| 467 |
+
model_to_save = model.module if hasattr(model, 'module') else model
|
| 468 |
+
output_model_file = os.path.join(output_dir, "pytorch_model.bin")
|
| 469 |
+
torch.save(model_to_save.state_dict(), output_model_file)
|
| 470 |
+
logger.info("Save the best bleu model into %s", output_model_file)
|
| 471 |
+
else:
|
| 472 |
+
not_bleu_em_inc_cnt[cur_task] += 1
|
| 473 |
+
logger.info("[%d %s] bleu/em does not increase for %d eval steps",
|
| 474 |
+
global_step, cur_task, not_bleu_em_inc_cnt[cur_task])
|
| 475 |
+
if not_bleu_em_inc_cnt[cur_task] > patience_dict[cur_task]:
|
| 476 |
+
logger.info("[%d %s] Early stop as bleu/em does not increase for %d eval steps",
|
| 477 |
+
global_step, cur_task, not_bleu_em_inc_cnt[cur_task])
|
| 478 |
+
is_early_stop[cur_task] = 1
|
| 479 |
+
fa_dict[cur_task].write(
|
| 480 |
+
"[%d %s] Early stop as bleu/em does not increase for %d eval steps, takes %s" %
|
| 481 |
+
(global_step, cur_task, not_bleu_em_inc_cnt[cur_task], get_elapse_time(t0)))
|
| 482 |
+
|
| 483 |
+
logger.info("***** CUDA.empty_cache() *****")
|
| 484 |
+
torch.cuda.empty_cache()
|
| 485 |
+
if global_step >= args.max_steps:
|
| 486 |
+
logger.info("Reach the max step: %d", args.max_steps)
|
| 487 |
+
break
|
| 488 |
+
|
| 489 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 490 |
+
tb_writer.close()
|
| 491 |
+
logger.info("Finish training and take %.2f", time.time() - t0)
|
| 492 |
+
for cur_task in all_tasks:
|
| 493 |
+
fa_dict[cur_task].close()
|
| 494 |
+
|
| 495 |
+
if args.do_test:
|
| 496 |
+
logger.info(" " + "***** Testing *****")
|
| 497 |
+
logger.info(" Batch size = %d", args.eval_batch_size)
|
| 498 |
+
eval_examples_data_dict = load_and_cache_multi_gen_data(args, pool, tokenizer, 'test', only_src=True)
|
| 499 |
+
all_tasks = list(eval_examples_data_dict.keys())
|
| 500 |
+
for cur_task in all_tasks:
|
| 501 |
+
summary_dir = os.path.join(args.output_dir, 'summary')
|
| 502 |
+
if not os.path.exists(summary_dir):
|
| 503 |
+
os.makedirs(summary_dir)
|
| 504 |
+
fa_dict[cur_task] = open(os.path.join(summary_dir, '{}_summary.log'.format(cur_task)), 'a+')
|
| 505 |
+
|
| 506 |
+
for cur_task in all_tasks:
|
| 507 |
+
eval_examples, eval_data = eval_examples_data_dict[cur_task]
|
| 508 |
+
args.task = cur_task.split('_')[0]
|
| 509 |
+
args.sub_task = cur_task.split('_')[-1]
|
| 510 |
+
|
| 511 |
+
for criteria in ['best-bleu', 'best-ppl', 'last']:
|
| 512 |
+
file = os.path.join(args.output_dir, 'checkpoint-{}/{}/pytorch_model.bin'.format(criteria, cur_task))
|
| 513 |
+
model.load_state_dict(torch.load(file))
|
| 514 |
+
|
| 515 |
+
result = eval_bleu(args, eval_data, eval_examples, model, tokenizer, 'test', cur_task, criteria)
|
| 516 |
+
test_bleu, test_em = result['bleu'], result['em']
|
| 517 |
+
test_codebleu = result['codebleu'] if 'codebleu' in result else 0
|
| 518 |
+
result_str = "[%s %s] bleu-4: %.2f, em: %.4f, codebleu: %.4f\n" % (
|
| 519 |
+
cur_task, criteria, test_bleu, test_em, test_codebleu)
|
| 520 |
+
logger.info(result_str)
|
| 521 |
+
fa_dict[cur_task].write(result_str)
|
| 522 |
+
fa.write(result_str)
|
| 523 |
+
if args.res_fn:
|
| 524 |
+
with open(args.res_fn, 'a+') as f:
|
| 525 |
+
f.write('[Time: {}] {}\n'.format(get_elapse_time(t0), file))
|
| 526 |
+
f.write(result_str)
|
| 527 |
+
logger.info("Finish and take {}".format(get_elapse_time(t0)))
|
| 528 |
+
for cur_task in all_tasks:
|
| 529 |
+
fa_dict[cur_task].close()
|
| 530 |
+
fa.write("Finish and take {}".format(get_elapse_time(t0)))
|
| 531 |
+
fa.close()
|
| 532 |
+
|
| 533 |
+
|
| 534 |
+
if __name__ == "__main__":
|
| 535 |
+
main()
|
sh/exp_with_args.sh
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
WORKDIR="your_CodeT5_path/CodeT5"
|
| 2 |
+
export PYTHONPATH=$WORKDIR
|
| 3 |
+
|
| 4 |
+
TASK=${1}
|
| 5 |
+
SUB_TASK=${2}
|
| 6 |
+
MODEL_TAG=${3}
|
| 7 |
+
GPU=${4}
|
| 8 |
+
DATA_NUM=${5}
|
| 9 |
+
BS=${6}
|
| 10 |
+
LR=${7}
|
| 11 |
+
SRC_LEN=${8}
|
| 12 |
+
TRG_LEN=${9}
|
| 13 |
+
PATIENCE=${10}
|
| 14 |
+
EPOCH=${11}
|
| 15 |
+
WARMUP=${12}
|
| 16 |
+
MODEL_DIR=${13}
|
| 17 |
+
SUMMARY_DIR=${14}
|
| 18 |
+
RES_FN=${15}
|
| 19 |
+
|
| 20 |
+
if [[ $DATA_NUM == -1 ]]; then
|
| 21 |
+
DATA_TAG='all'
|
| 22 |
+
else
|
| 23 |
+
DATA_TAG=$DATA_NUM
|
| 24 |
+
EPOCH=1
|
| 25 |
+
fi
|
| 26 |
+
|
| 27 |
+
if [[ ${TASK} == 'multi_task' ]]; then
|
| 28 |
+
FULL_MODEL_TAG=${MODEL_TAG}_${DATA_TAG}_lr${LR}_s${16}
|
| 29 |
+
else
|
| 30 |
+
FULL_MODEL_TAG=${MODEL_TAG}_${DATA_TAG}_lr${LR}_bs${BS}_src${SRC_LEN}_trg${TRG_LEN}_pat${PATIENCE}_e${EPOCH}
|
| 31 |
+
fi
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
if [[ ${SUB_TASK} == none ]]; then
|
| 35 |
+
OUTPUT_DIR=${MODEL_DIR}/${TASK}/${FULL_MODEL_TAG}
|
| 36 |
+
else
|
| 37 |
+
OUTPUT_DIR=${MODEL_DIR}/${TASK}/${SUB_TASK}/${FULL_MODEL_TAG}
|
| 38 |
+
fi
|
| 39 |
+
|
| 40 |
+
CACHE_DIR=${OUTPUT_DIR}/cache_data
|
| 41 |
+
RES_DIR=${OUTPUT_DIR}/prediction
|
| 42 |
+
LOG=${OUTPUT_DIR}/train.log
|
| 43 |
+
mkdir -p ${OUTPUT_DIR}
|
| 44 |
+
mkdir -p ${CACHE_DIR}
|
| 45 |
+
mkdir -p ${RES_DIR}
|
| 46 |
+
|
| 47 |
+
if [[ $MODEL_TAG == roberta ]]; then
|
| 48 |
+
MODEL_TYPE=roberta
|
| 49 |
+
TOKENIZER=roberta-base
|
| 50 |
+
MODEL_PATH=roberta-base
|
| 51 |
+
elif [[ $MODEL_TAG == codebert ]]; then
|
| 52 |
+
MODEL_TYPE=roberta
|
| 53 |
+
TOKENIZER=roberta-base
|
| 54 |
+
MODEL_PATH=microsoft/codebert-base
|
| 55 |
+
elif [[ $MODEL_TAG == bart_base ]]; then
|
| 56 |
+
MODEL_TYPE=bart
|
| 57 |
+
TOKENIZER=facebook/bart-base
|
| 58 |
+
MODEL_PATH=facebook/bart-base
|
| 59 |
+
elif [[ $MODEL_TAG == codet5_small ]]; then
|
| 60 |
+
MODEL_TYPE=codet5
|
| 61 |
+
TOKENIZER=Salesforce/codet5-small
|
| 62 |
+
MODEL_PATH=Salesforce/codet5-small
|
| 63 |
+
elif [[ $MODEL_TAG == codet5_base ]]; then
|
| 64 |
+
MODEL_TYPE=codet5
|
| 65 |
+
TOKENIZER=Salesforce/codet5-base
|
| 66 |
+
MODEL_PATH=Salesforce/codet5-base
|
| 67 |
+
elif [[ $MODEL_TAG == codet5_large ]]; then
|
| 68 |
+
MODEL_TYPE=codet5
|
| 69 |
+
TOKENIZER=Salesforce/codet5-large
|
| 70 |
+
MODEL_PATH=Salesforce/codet5-large
|
| 71 |
+
fi
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
if [[ ${TASK} == 'multi_task' ]]; then
|
| 75 |
+
RUN_FN=${WORKDIR}/run_multi_gen.py
|
| 76 |
+
MULTI_TASK_AUG='--max_steps '${16}' --save_steps '${17}' --log_steps '${18}
|
| 77 |
+
elif [[ ${TASK} == 'clone' ]]; then
|
| 78 |
+
RUN_FN=${WORKDIR}/run_clone.py
|
| 79 |
+
elif [[ ${TASK} == 'defect' ]] && [[ ${MODEL_TYPE} == 'roberta' || ${MODEL_TYPE} == 'bart' ]]; then
|
| 80 |
+
RUN_FN=${WORKDIR}/run_defect.py
|
| 81 |
+
else
|
| 82 |
+
RUN_FN=${WORKDIR}/run_gen.py
|
| 83 |
+
fi
|
| 84 |
+
|
| 85 |
+
CUDA_VISIBLE_DEVICES=${GPU} \
|
| 86 |
+
python ${RUN_FN} ${MULTI_TASK_AUG} \
|
| 87 |
+
--do_train --do_eval --do_eval_bleu --do_test \
|
| 88 |
+
--task ${TASK} --sub_task ${SUB_TASK} --model_type ${MODEL_TYPE} --data_num ${DATA_NUM} \
|
| 89 |
+
--num_train_epochs ${EPOCH} --warmup_steps ${WARMUP} --learning_rate ${LR}e-5 --patience ${PATIENCE} \
|
| 90 |
+
--tokenizer_name=${TOKENIZER} --model_name_or_path=${MODEL_PATH} --data_dir ${WORKDIR}/data \
|
| 91 |
+
--cache_path ${CACHE_DIR} --output_dir ${OUTPUT_DIR} --summary_dir ${SUMMARY_DIR} \
|
| 92 |
+
--save_last_checkpoints --always_save_model --res_dir ${RES_DIR} --res_fn ${RES_FN} \
|
| 93 |
+
--train_batch_size ${BS} --eval_batch_size ${BS} --max_source_length ${SRC_LEN} --max_target_length ${TRG_LEN} \
|
| 94 |
+
2>&1 | tee ${LOG}
|
sh/run_exp.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import os
|
| 3 |
+
import argparse
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def get_cmd(task, sub_task, model_tag, gpu, data_num, bs, lr, source_length, target_length, patience, epoch, warmup,
|
| 7 |
+
model_dir, summary_dir, res_fn, max_steps=None, save_steps=None, log_steps=None):
|
| 8 |
+
if max_steps is None:
|
| 9 |
+
cmd_str = 'bash exp_with_args.sh %s %s %s %d %d %d %d %d %d %d %d %d %s %s %s' % \
|
| 10 |
+
(task, sub_task, model_tag, gpu, data_num, bs, lr, source_length, target_length, patience, epoch,
|
| 11 |
+
warmup, model_dir, summary_dir, res_fn)
|
| 12 |
+
else:
|
| 13 |
+
cmd_str = 'bash exp_with_args.sh %s %s %s %d %d %d %d %d %d %d %d %d %s %s %s %d %d %d' % \
|
| 14 |
+
(task, sub_task, model_tag, gpu, data_num, bs, lr, source_length, target_length, patience, epoch,
|
| 15 |
+
warmup, model_dir, summary_dir, res_fn, max_steps, save_steps, log_steps)
|
| 16 |
+
return cmd_str
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_args_by_task_model(task, sub_task, model_tag):
|
| 20 |
+
if task == 'translate':
|
| 21 |
+
# java-cs: Read 10300 examples, avg src len: 13, avg trg len: 15, max src len: 136, max trg len: 118
|
| 22 |
+
# [TOKENIZE] avg src len: 45, avg trg len: 56, max src len: 391, max trg len: 404
|
| 23 |
+
src_len = 320
|
| 24 |
+
trg_len = 256
|
| 25 |
+
epoch = 100
|
| 26 |
+
patience = 5
|
| 27 |
+
elif task == 'summarize':
|
| 28 |
+
# ruby: Read 24927 examples, avg src len: 66, avg trg len: 12, max src len: 501, max trg len: 146
|
| 29 |
+
# [TOKENIZE] avg src len: 100, avg trg len: 13, max src len: 1250, max trg len: 161
|
| 30 |
+
# Python: Read 251820 examples, avg src len: 100, avg trg len: 11, max src len: 512, max trg len: 222
|
| 31 |
+
# [TOKENIZE] avg src len: 142, avg trg len: 12, max src len: 2016, max trg len: 245
|
| 32 |
+
# Javascript: Read 58025 examples, avg src len: 114, avg trg len: 11, max src len: 512, max trg len: 165
|
| 33 |
+
# [TOKENIZE] avg src len: 136, avg trg len: 12, max src len: 3016, max trg len: 177
|
| 34 |
+
src_len = 256
|
| 35 |
+
trg_len = 128
|
| 36 |
+
epoch = 15
|
| 37 |
+
patience = 2
|
| 38 |
+
elif task == 'refine':
|
| 39 |
+
# small: Read 46680 examples, avg src len: 31, avg trg len: 28, max src len: 50, max trg len: 50
|
| 40 |
+
# [TOKENIZE] avg src len: 50, avg trg len: 45, max src len: 129, max trg len: 121
|
| 41 |
+
# medium: Read 52364 examples, avg src len: 74, avg trg len: 73, max src len: 100, max trg len: 100
|
| 42 |
+
# [TOKENIZE] avg src len: 117, avg trg len: 114, max src len: 238, max trg len: 238
|
| 43 |
+
if sub_task == 'small':
|
| 44 |
+
src_len = 130
|
| 45 |
+
trg_len = 120
|
| 46 |
+
elif sub_task == 'medium':
|
| 47 |
+
src_len = 240
|
| 48 |
+
trg_len = 240
|
| 49 |
+
epoch = 50
|
| 50 |
+
patience = 5
|
| 51 |
+
elif task == 'concode':
|
| 52 |
+
# Read 100000 examples, avg src len: 71, avg trg len: 26, max src len: 567, max trg len: 140
|
| 53 |
+
# [TOKENIZE] avg src len: 213, avg trg len: 33, max src len: 2246, max trg len: 264
|
| 54 |
+
src_len = 320
|
| 55 |
+
trg_len = 150
|
| 56 |
+
epoch = 30
|
| 57 |
+
patience = 3
|
| 58 |
+
elif task == 'defect':
|
| 59 |
+
# Read 21854 examples, avg src len: 187, avg trg len: 1, max src len: 12195, max trg len: 1
|
| 60 |
+
# [TOKENIZE] avg src len: 597, avg trg len: 1, max src len: 41447, max trg len: 1
|
| 61 |
+
src_len = 512
|
| 62 |
+
trg_len = 3
|
| 63 |
+
epoch = 10
|
| 64 |
+
patience = 2
|
| 65 |
+
elif task == 'clone':
|
| 66 |
+
# Read 901028 examples, avg src len: 120, avg trg len: 123, max src len: 5270, max trg len: 5270
|
| 67 |
+
# [TOKENIZE] avg src len: 318, avg trg len: 323, max src len: 15111, max trg len: 15111
|
| 68 |
+
src_len = 400
|
| 69 |
+
trg_len = 400
|
| 70 |
+
epoch = 1
|
| 71 |
+
patience = 2
|
| 72 |
+
|
| 73 |
+
if 'codet5_small' in model_tag:
|
| 74 |
+
bs = 32
|
| 75 |
+
if task == 'summarize' or task == 'translate' or (task == 'refine' and sub_task == 'small'):
|
| 76 |
+
bs = 64
|
| 77 |
+
elif task == 'clone':
|
| 78 |
+
bs = 25
|
| 79 |
+
elif 'codet5_large' in model_tag:
|
| 80 |
+
bs = 8
|
| 81 |
+
else:
|
| 82 |
+
bs = 32
|
| 83 |
+
if task == 'translate':
|
| 84 |
+
bs = 25
|
| 85 |
+
elif task == 'summarize':
|
| 86 |
+
bs = 48
|
| 87 |
+
elif task == 'clone':
|
| 88 |
+
if model_tag in ['codebert', 'roberta']:
|
| 89 |
+
bs = 16
|
| 90 |
+
else:
|
| 91 |
+
bs = 10
|
| 92 |
+
lr = 5
|
| 93 |
+
if task == 'concode':
|
| 94 |
+
lr = 10
|
| 95 |
+
elif task == 'defect':
|
| 96 |
+
lr = 2
|
| 97 |
+
return bs, lr, src_len, trg_len, patience, epoch
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def run_one_exp(args):
|
| 101 |
+
bs, lr, src_len, trg_len, patience, epoch = get_args_by_task_model(args.task, args.sub_task, args.model_tag)
|
| 102 |
+
print('============================Start Running==========================')
|
| 103 |
+
cmd_str = get_cmd(task=args.task, sub_task=args.sub_task, model_tag=args.model_tag, gpu=args.gpu,
|
| 104 |
+
data_num=args.data_num, bs=bs, lr=lr, source_length=src_len, target_length=trg_len,
|
| 105 |
+
patience=patience, epoch=epoch, warmup=1000,
|
| 106 |
+
model_dir=args.model_dir, summary_dir=args.summary_dir,
|
| 107 |
+
res_fn='{}/{}_{}.txt'.format(args.res_dir, args.task, args.model_tag))
|
| 108 |
+
print('%s\n' % cmd_str)
|
| 109 |
+
os.system(cmd_str)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def run_multi_task_exp(args):
|
| 113 |
+
# Total train data num = 1149722 (for all five tasks)
|
| 114 |
+
if 'codet5_small' in args.model_tag:
|
| 115 |
+
bs, lr, max_steps, save_steps, log_steps = 60, 5, 600000, 20000, 100
|
| 116 |
+
else:
|
| 117 |
+
bs, lr, max_steps, save_steps, log_steps = 25, 5, 800000, 20000, 100
|
| 118 |
+
|
| 119 |
+
if args.data_num != -1:
|
| 120 |
+
max_steps, save_steps, log_steps = 1000, 200, 50
|
| 121 |
+
print('============================Start Running==========================')
|
| 122 |
+
cmd_str = get_cmd(task='multi_task', sub_task='none', model_tag=args.model_tag, gpu=args.gpu,
|
| 123 |
+
data_num=args.data_num, bs=bs, lr=lr, source_length=-1, target_length=-1,
|
| 124 |
+
patience=-1, epoch=-1, warmup=1000,
|
| 125 |
+
model_dir=args.model_dir, summary_dir=args.summary_dir,
|
| 126 |
+
res_fn='{}/multi_task_{}.txt'.format(args.res_dir, args.model_tag),
|
| 127 |
+
max_steps=max_steps, save_steps=save_steps, log_steps=log_steps)
|
| 128 |
+
print('%s\n' % cmd_str)
|
| 129 |
+
os.system(cmd_str)
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def get_sub_tasks(task):
|
| 133 |
+
if task == 'summarize':
|
| 134 |
+
sub_tasks = ['ruby', 'javascript', 'go', 'python', 'java', 'php']
|
| 135 |
+
elif task == 'translate':
|
| 136 |
+
sub_tasks = ['java-cs', 'cs-java']
|
| 137 |
+
elif task == 'refine':
|
| 138 |
+
sub_tasks = ['small', 'medium']
|
| 139 |
+
elif task in ['concode', 'defect', 'clone', 'multi_task']:
|
| 140 |
+
sub_tasks = ['none']
|
| 141 |
+
return sub_tasks
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
if __name__ == '__main__':
|
| 145 |
+
parser = argparse.ArgumentParser()
|
| 146 |
+
parser.add_argument("--model_tag", type=str, default='codet5_base',
|
| 147 |
+
choices=['roberta', 'codebert', 'bart_base', 'codet5_small', 'codet5_base', 'codet5_large'])
|
| 148 |
+
parser.add_argument("--task", type=str, default='summarize', choices=['summarize', 'concode', 'translate',
|
| 149 |
+
'refine', 'defect', 'clone', 'multi_task'])
|
| 150 |
+
parser.add_argument("--sub_task", type=str, default='ruby')
|
| 151 |
+
parser.add_argument("--res_dir", type=str, default='results', help='directory to save fine-tuning results')
|
| 152 |
+
parser.add_argument("--model_dir", type=str, default='saved_models', help='directory to save fine-tuned models')
|
| 153 |
+
parser.add_argument("--summary_dir", type=str, default='tensorboard', help='directory to save tensorboard summary')
|
| 154 |
+
parser.add_argument("--data_num", type=int, default=-1, help='number of data instances to use, -1 for full data')
|
| 155 |
+
parser.add_argument("--gpu", type=int, default=0, help='index of the gpu to use in a cluster')
|
| 156 |
+
args = parser.parse_args()
|
| 157 |
+
|
| 158 |
+
if not os.path.exists(args.res_dir):
|
| 159 |
+
os.makedirs(args.res_dir)
|
| 160 |
+
|
| 161 |
+
assert args.sub_task in get_sub_tasks(args.task)
|
| 162 |
+
if args.task != 'multi_task':
|
| 163 |
+
run_one_exp(args)
|
| 164 |
+
else:
|
| 165 |
+
run_multi_task_exp(args)
|
tokenizer/apply_tokenizer.py
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tokenizers import ByteLevelBPETokenizer
|
| 2 |
+
|
| 3 |
+
tokenizer = ByteLevelBPETokenizer.from_file(
|
| 4 |
+
"./salesforce/codet5-vocab.json",
|
| 5 |
+
"./salesforce/codet5-merges.txt"
|
| 6 |
+
)
|
| 7 |
+
tokenizer.add_special_tokens([
|
| 8 |
+
"<pad>",
|
| 9 |
+
"<s>",
|
| 10 |
+
"</s>",
|
| 11 |
+
"<unk>",
|
| 12 |
+
"<mask>"
|
| 13 |
+
])
|
| 14 |
+
|
| 15 |
+
print(
|
| 16 |
+
tokenizer.encode("<s> hello <unk> Don't you love 🤗 Transformers <mask> yes . </s>").tokens
|
| 17 |
+
)
|
tokenizer/salesforce/codet5-merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/salesforce/codet5-vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer/train_tokenizer.py
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from tokenizers import ByteLevelBPETokenizer
|
| 2 |
+
|
| 3 |
+
paths = ['train_code.txt', 'train_doc.txt']
|
| 4 |
+
|
| 5 |
+
# Initialize a tokenizer
|
| 6 |
+
tokenizer = ByteLevelBPETokenizer()
|
| 7 |
+
|
| 8 |
+
# Customize training
|
| 9 |
+
tokenizer.train(files=paths, vocab_size=32000, min_frequency=3, special_tokens=[
|
| 10 |
+
"<pad>",
|
| 11 |
+
"<s>",
|
| 12 |
+
"</s>",
|
| 13 |
+
"<unk>",
|
| 14 |
+
"<mask>"
|
| 15 |
+
])
|
| 16 |
+
|
| 17 |
+
# Save files to disk
|
| 18 |
+
tokenizer.save_model("./salesforce", "codet5")
|
| 19 |
+
|
| 20 |
+
print(
|
| 21 |
+
tokenizer.encode("<s> hello <unk> Don't you love 🤗 Transformers <mask> yes . </s>").tokens
|
| 22 |
+
)
|
utils.py
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.utils.data import TensorDataset
|
| 2 |
+
import numpy as np
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
import random
|
| 6 |
+
import torch
|
| 7 |
+
import time
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from _utils import *
|
| 10 |
+
|
| 11 |
+
logger = logging.getLogger(__name__)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def load_and_cache_gen_data(args, filename, pool, tokenizer, split_tag, only_src=False, is_sample=False):
|
| 15 |
+
# cache the data into args.cache_path except it is sampled
|
| 16 |
+
# only_src: control whether to return only source ids for bleu evaluating (dev/test)
|
| 17 |
+
# return: examples (Example object), data (TensorDataset)
|
| 18 |
+
data_tag = '_all' if args.data_num == -1 else '_%d' % args.data_num
|
| 19 |
+
cache_fn = '{}/{}.pt'.format(args.cache_path, split_tag + ('_src' if only_src else '') + data_tag)
|
| 20 |
+
|
| 21 |
+
examples = read_examples(filename, args.data_num, args.task)
|
| 22 |
+
|
| 23 |
+
if is_sample:
|
| 24 |
+
examples = random.sample(examples, min(5000, len(examples)))
|
| 25 |
+
if split_tag == 'train':
|
| 26 |
+
calc_stats(examples, tokenizer, is_tokenize=True)
|
| 27 |
+
else:
|
| 28 |
+
calc_stats(examples)
|
| 29 |
+
if os.path.exists(cache_fn) and not is_sample:
|
| 30 |
+
logger.info("Load cache data from %s", cache_fn)
|
| 31 |
+
data = torch.load(cache_fn)
|
| 32 |
+
else:
|
| 33 |
+
if is_sample:
|
| 34 |
+
logger.info("Sample 5k data for computing bleu from %s", filename)
|
| 35 |
+
else:
|
| 36 |
+
logger.info("Create cache data into %s", cache_fn)
|
| 37 |
+
tuple_examples = [(example, idx, tokenizer, args, split_tag) for idx, example in enumerate(examples)]
|
| 38 |
+
features = pool.map(convert_examples_to_features, tqdm(tuple_examples, total=len(tuple_examples)))
|
| 39 |
+
all_source_ids = torch.tensor([f.source_ids for f in features], dtype=torch.long)
|
| 40 |
+
if split_tag == 'test' or only_src:
|
| 41 |
+
data = TensorDataset(all_source_ids)
|
| 42 |
+
else:
|
| 43 |
+
all_target_ids = torch.tensor([f.target_ids for f in features], dtype=torch.long)
|
| 44 |
+
data = TensorDataset(all_source_ids, all_target_ids)
|
| 45 |
+
if args.local_rank in [-1, 0] and not is_sample:
|
| 46 |
+
torch.save(data, cache_fn)
|
| 47 |
+
return examples, data
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def load_and_cache_clone_data(args, filename, pool, tokenizer, split_tag, is_sample=False):
|
| 51 |
+
cache_fn = '{}/{}.pt'.format(args.cache_path, split_tag + '_all' if args.data_num == -1 else '_%d' % args.data_num)
|
| 52 |
+
examples = read_examples(filename, args.data_num, args.task)
|
| 53 |
+
if is_sample:
|
| 54 |
+
examples = random.sample(examples, int(len(examples) * 0.1))
|
| 55 |
+
|
| 56 |
+
calc_stats(examples, tokenizer, is_tokenize=True)
|
| 57 |
+
if os.path.exists(cache_fn):
|
| 58 |
+
logger.info("Load cache data from %s", cache_fn)
|
| 59 |
+
data = torch.load(cache_fn)
|
| 60 |
+
else:
|
| 61 |
+
if is_sample:
|
| 62 |
+
logger.info("Sample 10 percent of data from %s", filename)
|
| 63 |
+
elif args.data_num == -1:
|
| 64 |
+
logger.info("Create cache data into %s", cache_fn)
|
| 65 |
+
tuple_examples = [(example, idx, tokenizer, args) for idx, example in enumerate(examples)]
|
| 66 |
+
features = pool.map(convert_clone_examples_to_features, tqdm(tuple_examples, total=len(tuple_examples)))
|
| 67 |
+
all_source_ids = torch.tensor([f.source_ids for f in features], dtype=torch.long)
|
| 68 |
+
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
|
| 69 |
+
data = TensorDataset(all_source_ids, all_labels)
|
| 70 |
+
|
| 71 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 72 |
+
torch.save(data, cache_fn)
|
| 73 |
+
return examples, data
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def load_and_cache_defect_data(args, filename, pool, tokenizer, split_tag, is_sample=False):
|
| 77 |
+
cache_fn = os.path.join(args.cache_path, split_tag)
|
| 78 |
+
examples = read_examples(filename, args.data_num, args.task)
|
| 79 |
+
if is_sample:
|
| 80 |
+
examples = random.sample(examples, int(len(examples) * 0.1))
|
| 81 |
+
|
| 82 |
+
calc_stats(examples, tokenizer, is_tokenize=True)
|
| 83 |
+
if os.path.exists(cache_fn):
|
| 84 |
+
logger.info("Load cache data from %s", cache_fn)
|
| 85 |
+
data = torch.load(cache_fn)
|
| 86 |
+
else:
|
| 87 |
+
if is_sample:
|
| 88 |
+
logger.info("Sample 10 percent of data from %s", filename)
|
| 89 |
+
elif args.data_num == -1:
|
| 90 |
+
logger.info("Create cache data into %s", cache_fn)
|
| 91 |
+
tuple_examples = [(example, idx, tokenizer, args) for idx, example in enumerate(examples)]
|
| 92 |
+
features = pool.map(convert_defect_examples_to_features, tqdm(tuple_examples, total=len(tuple_examples)))
|
| 93 |
+
# features = [convert_clone_examples_to_features(x) for x in tuple_examples]
|
| 94 |
+
all_source_ids = torch.tensor([f.source_ids for f in features], dtype=torch.long)
|
| 95 |
+
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
|
| 96 |
+
data = TensorDataset(all_source_ids, all_labels)
|
| 97 |
+
|
| 98 |
+
if args.local_rank in [-1, 0] and args.data_num == -1:
|
| 99 |
+
torch.save(data, cache_fn)
|
| 100 |
+
return examples, data
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def load_and_cache_multi_gen_data(args, pool, tokenizer, split_tag, only_src=False, is_sample=False):
|
| 104 |
+
cache_fn = os.path.join(args.cache_path, split_tag)
|
| 105 |
+
if os.path.exists(cache_fn) and not is_sample:
|
| 106 |
+
logger.info("Load cache data from %s", cache_fn)
|
| 107 |
+
examples_data_dict = torch.load(cache_fn)
|
| 108 |
+
else:
|
| 109 |
+
examples_data_dict = {}
|
| 110 |
+
|
| 111 |
+
task_list = ['summarize', 'translate', 'refine', 'concode', 'defect']
|
| 112 |
+
for task in task_list:
|
| 113 |
+
if task == 'summarize':
|
| 114 |
+
sub_tasks = ['ruby', 'javascript', 'go', 'python', 'java', 'php']
|
| 115 |
+
elif task == 'translate':
|
| 116 |
+
sub_tasks = ['java-cs', 'cs-java']
|
| 117 |
+
elif task == 'refine':
|
| 118 |
+
sub_tasks = ['small', 'medium']
|
| 119 |
+
else:
|
| 120 |
+
sub_tasks = ['none']
|
| 121 |
+
args.task = task
|
| 122 |
+
for sub_task in sub_tasks:
|
| 123 |
+
args.sub_task = sub_task
|
| 124 |
+
if task == 'summarize':
|
| 125 |
+
args.max_source_length = 256
|
| 126 |
+
args.max_target_length = 128
|
| 127 |
+
elif task == 'translate':
|
| 128 |
+
args.max_source_length = 320
|
| 129 |
+
args.max_target_length = 256
|
| 130 |
+
elif task == 'refine':
|
| 131 |
+
if sub_task == 'small':
|
| 132 |
+
args.max_source_length = 130
|
| 133 |
+
args.max_target_length = 120
|
| 134 |
+
else:
|
| 135 |
+
args.max_source_length = 240
|
| 136 |
+
args.max_target_length = 240
|
| 137 |
+
elif task == 'concode':
|
| 138 |
+
args.max_source_length = 320
|
| 139 |
+
args.max_target_length = 150
|
| 140 |
+
elif task == 'defect':
|
| 141 |
+
args.max_source_length = 512
|
| 142 |
+
args.max_target_length = 3 # as do not need to add lang ids
|
| 143 |
+
|
| 144 |
+
filename = get_filenames(args.data_dir, args.task, args.sub_task, split_tag)
|
| 145 |
+
examples = read_examples(filename, args.data_num, args.task)
|
| 146 |
+
if is_sample:
|
| 147 |
+
examples = random.sample(examples, min(5000, len(examples)))
|
| 148 |
+
if split_tag == 'train':
|
| 149 |
+
calc_stats(examples, tokenizer, is_tokenize=True)
|
| 150 |
+
else:
|
| 151 |
+
calc_stats(examples)
|
| 152 |
+
|
| 153 |
+
tuple_examples = [(example, idx, tokenizer, args, split_tag) for idx, example in enumerate(examples)]
|
| 154 |
+
if args.data_num == -1:
|
| 155 |
+
features = pool.map(convert_examples_to_features, tqdm(tuple_examples, total=len(tuple_examples)))
|
| 156 |
+
else:
|
| 157 |
+
features = [convert_examples_to_features(x) for x in tuple_examples]
|
| 158 |
+
all_source_ids = torch.tensor([f.source_ids for f in features], dtype=torch.long)
|
| 159 |
+
if only_src:
|
| 160 |
+
data = TensorDataset(all_source_ids)
|
| 161 |
+
else:
|
| 162 |
+
all_target_ids = torch.tensor([f.target_ids for f in features], dtype=torch.long)
|
| 163 |
+
data = TensorDataset(all_source_ids, all_target_ids)
|
| 164 |
+
examples_data_dict['{}_{}'.format(task, sub_task) if sub_task != 'none' else task] = (examples, data)
|
| 165 |
+
|
| 166 |
+
if args.local_rank in [-1, 0] and not is_sample:
|
| 167 |
+
torch.save(examples_data_dict, cache_fn)
|
| 168 |
+
logger.info("Save data into %s", cache_fn)
|
| 169 |
+
return examples_data_dict
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def get_filenames(data_root, task, sub_task, split=''):
|
| 173 |
+
if task == 'concode':
|
| 174 |
+
data_dir = '{}/{}'.format(data_root, task)
|
| 175 |
+
train_fn = '{}/train.json'.format(data_dir)
|
| 176 |
+
dev_fn = '{}/dev.json'.format(data_dir)
|
| 177 |
+
test_fn = '{}/test.json'.format(data_dir)
|
| 178 |
+
elif task == 'summarize':
|
| 179 |
+
data_dir = '{}/{}/{}'.format(data_root, task, sub_task)
|
| 180 |
+
train_fn = '{}/train.jsonl'.format(data_dir)
|
| 181 |
+
dev_fn = '{}/valid.jsonl'.format(data_dir)
|
| 182 |
+
test_fn = '{}/test.jsonl'.format(data_dir)
|
| 183 |
+
elif task == 'refine':
|
| 184 |
+
data_dir = '{}/{}/{}'.format(data_root, task, sub_task)
|
| 185 |
+
train_fn = '{}/train.buggy-fixed.buggy,{}/train.buggy-fixed.fixed'.format(data_dir, data_dir)
|
| 186 |
+
dev_fn = '{}/valid.buggy-fixed.buggy,{}/valid.buggy-fixed.fixed'.format(data_dir, data_dir)
|
| 187 |
+
test_fn = '{}/test.buggy-fixed.buggy,{}/test.buggy-fixed.fixed'.format(data_dir, data_dir)
|
| 188 |
+
elif task == 'translate':
|
| 189 |
+
data_dir = '{}/{}'.format(data_root, task)
|
| 190 |
+
if sub_task == 'cs-java':
|
| 191 |
+
train_fn = '{}/train.java-cs.txt.cs,{}/train.java-cs.txt.java'.format(data_dir, data_dir)
|
| 192 |
+
dev_fn = '{}/valid.java-cs.txt.cs,{}/valid.java-cs.txt.java'.format(data_dir, data_dir)
|
| 193 |
+
test_fn = '{}/test.java-cs.txt.cs,{}/test.java-cs.txt.java'.format(data_dir, data_dir)
|
| 194 |
+
else:
|
| 195 |
+
train_fn = '{}/train.java-cs.txt.java,{}/train.java-cs.txt.cs'.format(data_dir, data_dir)
|
| 196 |
+
dev_fn = '{}/valid.java-cs.txt.java,{}/valid.java-cs.txt.cs'.format(data_dir, data_dir)
|
| 197 |
+
test_fn = '{}/test.java-cs.txt.java,{}/test.java-cs.txt.cs'.format(data_dir, data_dir)
|
| 198 |
+
elif task == 'clone':
|
| 199 |
+
data_dir = '{}/{}'.format(data_root, task)
|
| 200 |
+
train_fn = '{}/train.txt'.format(data_dir)
|
| 201 |
+
dev_fn = '{}/valid.txt'.format(data_dir)
|
| 202 |
+
test_fn = '{}/test.txt'.format(data_dir)
|
| 203 |
+
elif task == 'defect':
|
| 204 |
+
data_dir = '{}/{}'.format(data_root, task)
|
| 205 |
+
train_fn = '{}/train.jsonl'.format(data_dir)
|
| 206 |
+
dev_fn = '{}/valid.jsonl'.format(data_dir)
|
| 207 |
+
test_fn = '{}/test.jsonl'.format(data_dir)
|
| 208 |
+
if split == 'train':
|
| 209 |
+
return train_fn
|
| 210 |
+
elif split == 'dev':
|
| 211 |
+
return dev_fn
|
| 212 |
+
elif split == 'test':
|
| 213 |
+
return test_fn
|
| 214 |
+
else:
|
| 215 |
+
return train_fn, dev_fn, test_fn
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def read_examples(filename, data_num, task):
|
| 219 |
+
read_example_dict = {
|
| 220 |
+
'summarize': read_summarize_examples,
|
| 221 |
+
'refine': read_refine_examples,
|
| 222 |
+
'translate': read_translate_examples,
|
| 223 |
+
'concode': read_concode_examples,
|
| 224 |
+
'clone': read_clone_examples,
|
| 225 |
+
'defect': read_defect_examples,
|
| 226 |
+
}
|
| 227 |
+
return read_example_dict[task](filename, data_num)
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
def calc_stats(examples, tokenizer=None, is_tokenize=False):
|
| 231 |
+
avg_src_len = []
|
| 232 |
+
avg_trg_len = []
|
| 233 |
+
avg_src_len_tokenize = []
|
| 234 |
+
avg_trg_len_tokenize = []
|
| 235 |
+
for ex in examples:
|
| 236 |
+
if is_tokenize:
|
| 237 |
+
avg_src_len.append(len(ex.source.split()))
|
| 238 |
+
avg_trg_len.append(len(str(ex.target).split()))
|
| 239 |
+
avg_src_len_tokenize.append(len(tokenizer.tokenize(ex.source)))
|
| 240 |
+
avg_trg_len_tokenize.append(len(tokenizer.tokenize(str(ex.target))))
|
| 241 |
+
else:
|
| 242 |
+
avg_src_len.append(len(ex.source.split()))
|
| 243 |
+
avg_trg_len.append(len(str(ex.target).split()))
|
| 244 |
+
if is_tokenize:
|
| 245 |
+
logger.info("Read %d examples, avg src len: %d, avg trg len: %d, max src len: %d, max trg len: %d",
|
| 246 |
+
len(examples), np.mean(avg_src_len), np.mean(avg_trg_len), max(avg_src_len), max(avg_trg_len))
|
| 247 |
+
logger.info("[TOKENIZE] avg src len: %d, avg trg len: %d, max src len: %d, max trg len: %d",
|
| 248 |
+
np.mean(avg_src_len_tokenize), np.mean(avg_trg_len_tokenize), max(avg_src_len_tokenize),
|
| 249 |
+
max(avg_trg_len_tokenize))
|
| 250 |
+
else:
|
| 251 |
+
logger.info("Read %d examples, avg src len: %d, avg trg len: %d, max src len: %d, max trg len: %d",
|
| 252 |
+
len(examples), np.mean(avg_src_len), np.mean(avg_trg_len), max(avg_src_len), max(avg_trg_len))
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def get_elapse_time(t0):
|
| 256 |
+
elapse_time = time.time() - t0
|
| 257 |
+
if elapse_time > 3600:
|
| 258 |
+
hour = int(elapse_time // 3600)
|
| 259 |
+
minute = int((elapse_time % 3600) // 60)
|
| 260 |
+
return "{}h{}m".format(hour, minute)
|
| 261 |
+
else:
|
| 262 |
+
minute = int((elapse_time % 3600) // 60)
|
| 263 |
+
return "{}m".format(minute)
|