TRL documentation
Examples of using peft and trl to finetune 8-bit models with Low Rank Adaption
Examples of using peft and trl to finetune 8-bit models with Low Rank Adaption
The notebooks and scripts in this examples show how to fine-tune a model with a sentiment classifier (such as lvwerra/distilbert-imdb).
Here’s an overview of the notebooks and scripts in the trl repository:
| File | Description | Colab link |
|---|---|---|
gpt2-sentiment_peft.py |
Same as the sentiment analysis example, but learning a low rank adapter on a 8-bit base model | |
cm_finetune_peft_imdb.py |
Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset. | |
merge_peft_adapter.py |
Merging of the adapter layers into the base model’s weights and storing these on the hub. | |
gpt-neo-20b_sentiment_peft.py |
Sentiment fine-tuning of a Low Rank Adapter to create positive reviews. | |
gpt-neo-1b_peft.py |
Sentiment fine-tuning of a Low Rank Adapter to create positive reviews using 2 GPUs. |
Installation
Note: peft is in active development, so we install directly from their github page. Peft also relies on the latest version of transformers.pip install trl[peft]
pip install bitsandbytes loralib
pip install git+https://github.com/huggingface/transformers.git@main
#optional: wandb
pip install wandbNote: if you don’t want to log with wandb remove log_with="wandb" in the scripts/notebooks. You can also replace it with your favourite experiment tracker that’s supported by accelerate.
Launch scripts
The trl library is powered by accelerate. As such it is best to configure and launch trainings with the following commands:
accelerate config # will prompt you to define the training configuration
accelerate launch scripts/gpt2-sentiment_peft.py # launches training
Using trl + peft and Data Parallelism
You can scale up to as many GPUs as you want, as long as you are able to fit the training process in a single device. The only tweak you need to apply is to load the model as follows:
from accelerate import Accelerator
...
current_device = Accelerator().process_index
pretrained_model = AutoModelForCausalLM.from_pretrained(
config.model_name, load_in_8bit=True, device_map={"": current_device}
)The reason behind device_map={"": current_device} is that when you set "":device_number, accelerate will set the entire model on the device_number device. Therefore this trick enables to set the model on the correct device for each process.
As the Accelerator object from accelerate will take care of initializing the distributed setup correctly.
Make sure to initialize your accelerate config by specifying that you are training in a multi-gpu setup, by running accelerate config and make sure to run the training script with accelerator launch your_script.py.
Finally make sure that the rewards are computed on current_device as well.
Naive pipeline parallelism (NPP) for large models (>60B models)
The trl library also supports naive pipeline parallelism (NPP) for large models (>60B models). This is a simple way to parallelize the model across multiple GPUs.
This paradigm, termed as “Naive Pipeline Parallelism” (NPP) is a simple way to parallelize the model across multiple GPUs. We load the model and the adapters across multiple GPUs and the activations and gradients will be naively communicated across the GPUs. This supports int8 models as well as other dtype models.
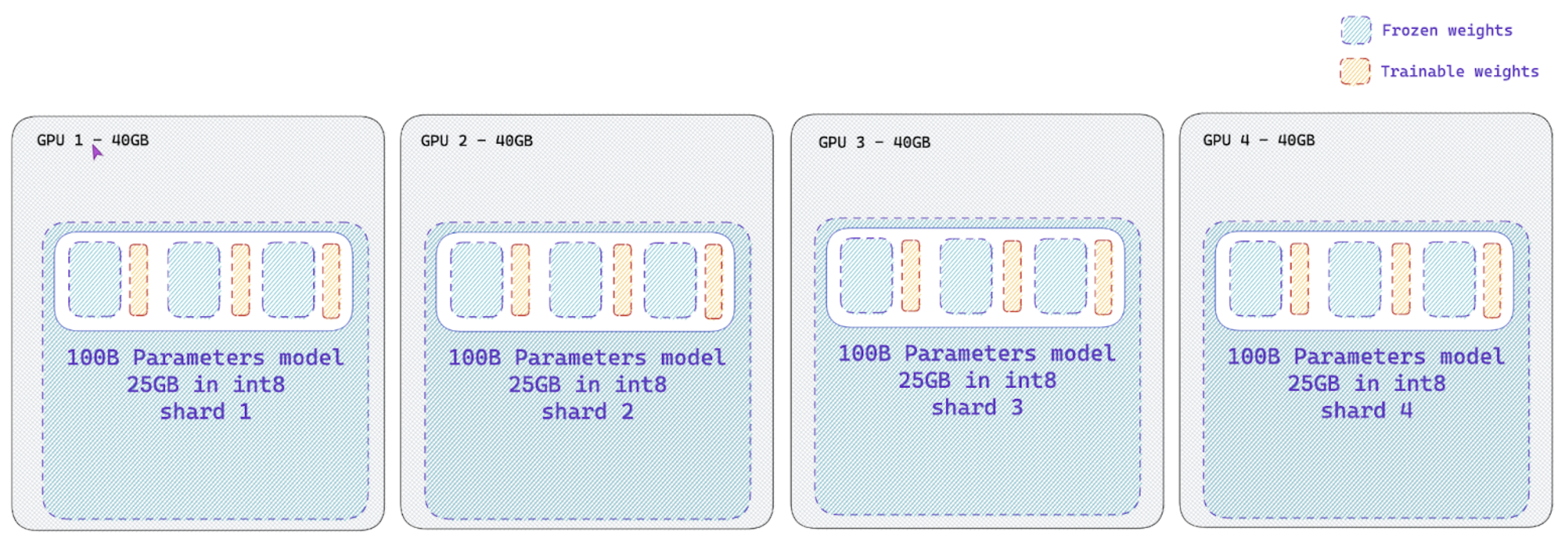
How to use NPP?
Simply load your model with a custom device_map argument on the from_pretrained to split your model across multiple devices. Check out this nice tutorial on how to properly create a device_map for your model.
Also make sure to have the lm_head module on the first GPU device as it may throw an error if it is not on the first device. As this time of writing, you need to install the main branch of accelerate: pip install git+https://github.com/huggingface/accelerate.git@main and peft: pip install git+https://github.com/huggingface/peft.git@main.
That all you need to do to use NPP. Check out the gpt-neo-1b_peft.py example for a more details usage of NPP.
Launch scripts
Although trl library is powered by accelerate, you should run your training script in a single process. Note that we do not support Data Parallelism together with NPP yet.
python PATH_TO_SCRIPT