TRL documentation
Supervised Fine-tuning Trainer
Supervised Fine-tuning Trainer
Supervised fine-tuning (or SFT for short) is a crucial step in RLHF. In TRL we provide an easy-to-use API to create your SFT models and train them with few lines of code on your dataset.
Check out a complete flexible example at trl/scripts/sft.py.
Experimental support for Vision Language Models is also included in the example examples/scripts/sft_vlm.py.
Quickstart
If you have a dataset hosted on the 🤗 Hub, you can easily fine-tune your SFT model using SFTTrainer from TRL. Let us assume your dataset is imdb, the text you want to predict is inside the text field of the dataset, and you want to fine-tune the facebook/opt-350m model.
The following code-snippet takes care of all the data pre-processing and training for you:
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
dataset = load_dataset("stanfordnlp/imdb", split="train")
training_args = SFTConfig(
max_seq_length=512,
output_dir="/tmp",
)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=training_args,
)
trainer.train()Make sure to pass the correct value for max_seq_length as the default value will be set to min(tokenizer.model_max_length, 1024).
You can also construct a model outside of the trainer and pass it as follows:
from transformers import AutoModelForCausalLM
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
dataset = load_dataset("stanfordnlp/imdb", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
training_args = SFTConfig(output_dir="/tmp")
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=training_args,
)
trainer.train()The above snippets will use the default training arguments from the SFTConfig class. If you want to modify the defaults pass in your modification to the SFTConfig constructor and pass them to the trainer via the args argument.
Advanced usage
Train on completions only
You can use the DataCollatorForCompletionOnlyLM to train your model on the generated prompts only. Note that this works only in the case when packing=False.
To instantiate that collator for instruction data, pass a response template and the tokenizer. Here is an example of how it would work to fine-tune opt-350m on completions only on the CodeAlpaca dataset:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("lucasmccabe-lmi/CodeAlpaca-20k", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['instruction'])):
text = f"### Question: {example['instruction'][i]}\n ### Answer: {example['output'][i]}"
output_texts.append(text)
return output_texts
response_template = " ### Answer:"
collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=SFTConfig(output_dir="/tmp"),
formatting_func=formatting_prompts_func,
data_collator=collator,
)
trainer.train()To instantiate that collator for assistant style conversation data, pass a response template, an instruction template and the tokenizer. Here is an example of how it would work to fine-tune opt-350m on assistant completions only on the Open Assistant Guanaco dataset:
from transformers import AutoModelForCausalLM, AutoTokenizer
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer, DataCollatorForCompletionOnlyLM
dataset = load_dataset("timdettmers/openassistant-guanaco", split="train")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
instruction_template = "### Human:"
response_template = "### Assistant:"
collator = DataCollatorForCompletionOnlyLM(instruction_template=instruction_template, response_template=response_template, tokenizer=tokenizer, mlm=False)
trainer = SFTTrainer(
model,
args=SFTConfig(output_dir="/tmp"),
train_dataset=dataset,
data_collator=collator,
)
trainer.train()Make sure to have a pad_token_id which is different from eos_token_id which can result in the model not properly predicting EOS (End of Sentence) tokens during generation.
Using token_ids directly for response_template
Some tokenizers like Llama 2 (meta-llama/Llama-2-XXb-hf) tokenize sequences differently depending on whether they have context or not. For example:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
def print_tokens_with_ids(txt):
tokens = tokenizer.tokenize(txt, add_special_tokens=False)
token_ids = tokenizer.encode(txt, add_special_tokens=False)
print(list(zip(tokens, token_ids)))
prompt = """### User: Hello\n\n### Assistant: Hi, how can I help you?"""
print_tokens_with_ids(prompt) # [..., ('▁Hello', 15043), ('<0x0A>', 13), ('<0x0A>', 13), ('##', 2277), ('#', 29937), ('▁Ass', 4007), ('istant', 22137), (':', 29901), ...]
response_template = "### Assistant:"
print_tokens_with_ids(response_template) # [('▁###', 835), ('▁Ass', 4007), ('istant', 22137), (':', 29901)]In this case, and due to lack of context in response_template, the same string (”### Assistant:”) is tokenized differently:
- Text (with context):
[2277, 29937, 4007, 22137, 29901] response_template(without context):[835, 4007, 22137, 29901]
This will lead to an error when the DataCollatorForCompletionOnlyLM does not find the response_template in the dataset example text:
RuntimeError: Could not find response key [835, 4007, 22137, 29901] in token IDs tensor([ 1, 835, ...])To solve this, you can tokenize the response_template with the same context as in the dataset, truncate it as needed and pass the token_ids directly to the response_template argument of the DataCollatorForCompletionOnlyLM class. For example:
response_template_with_context = "\n### Assistant:" # We added context here: "\n". This is enough for this tokenizer
response_template_ids = tokenizer.encode(response_template_with_context, add_special_tokens=False)[2:] # Now we have it like in the dataset texts: `[2277, 29937, 4007, 22137, 29901]`
data_collator = DataCollatorForCompletionOnlyLM(response_template_ids, tokenizer=tokenizer)Add Special Tokens for Chat Format
Adding special tokens to a language model is crucial for training chat models. These tokens are added between the different roles in a conversation, such as the user, assistant, and system and help the model recognize the structure and flow of a conversation. This setup is essential for enabling the model to generate coherent and contextually appropriate responses in a chat environment.
The setup_chat_format() function in trl easily sets up a model and tokenizer for conversational AI tasks. This function:
- Adds special tokens to the tokenizer, e.g.
<|im_start|>and<|im_end|>, to indicate the start and end of a conversation. - Resizes the model’s embedding layer to accommodate the new tokens.
- Sets the
chat_templateof the tokenizer, which is used to format the input data into a chat-like format. The default ischatmlfrom OpenAI. - optionally you can pass
resize_to_multiple_ofto resize the embedding layer to a multiple of theresize_to_multiple_ofargument, e.g. 64. If you want to see more formats being supported in the future, please open a GitHub issue on trl
from transformers import AutoModelForCausalLM, AutoTokenizer
from trl import setup_chat_format
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
# Set up the chat format with default 'chatml' format
model, tokenizer = setup_chat_format(model, tokenizer)
With our model and tokenizer set up, we can now fine-tune our model on a conversational dataset. Below is an example of how a dataset can be formatted for fine-tuning.
Dataset format support
The SFTTrainer supports popular dataset formats. This allows you to pass the dataset to the trainer without any pre-processing directly. The following formats are supported:
- conversational format
{"messages": [{"role": "system", "content": "You are helpful"}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "..."}]}
{"messages": [{"role": "system", "content": "You are helpful"}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "..."}]}
{"messages": [{"role": "system", "content": "You are helpful"}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "..."}]}- instruction format
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}If your dataset uses one of the above formats, you can directly pass it to the trainer without pre-processing. The SFTTrainer will then format the dataset for you using the defined format from the model’s tokenizer with the apply_chat_template method.
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
...
# load jsonl dataset
dataset = load_dataset("json", data_files="path/to/dataset.jsonl", split="train")
# load dataset from the HuggingFace Hub
dataset = load_dataset("philschmid/dolly-15k-oai-style", split="train")
...
training_args = SFTConfig(packing=True)
trainer = SFTTrainer(
"facebook/opt-350m",
args=training_args,
train_dataset=dataset,
)If the dataset is not in one of those format you can either preprocess the dataset to match the formatting or pass a formatting function to the SFTTrainer to do it for you. Let’s have a look.
Format your input prompts
For instruction fine-tuning, it is quite common to have two columns inside the dataset: one for the prompt & the other for the response. This allows people to format examples like Stanford-Alpaca did as follows:
Below is an instruction ...
### Instruction
{prompt}
### Response:
{completion}Let us assume your dataset has two fields, question and answer. Therefore you can just run:
...
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['question'])):
text = f"### Question: {example['question'][i]}\n ### Answer: {example['answer'][i]}"
output_texts.append(text)
return output_texts
trainer = SFTTrainer(
model,
args=training_args,
train_dataset=dataset,
formatting_func=formatting_prompts_func,
)
trainer.train()To properly format your input make sure to process all the examples by looping over them and returning a list of processed text. Check out a full example of how to use SFTTrainer on alpaca dataset here
Packing dataset ( ConstantLengthDataset )
SFTTrainer supports example packing, where multiple short examples are packed in the same input sequence to increase training efficiency. This is done with the ConstantLengthDataset utility class that returns constant length chunks of tokens from a stream of examples. To enable the usage of this dataset class, simply pass packing=True to the SFTConfig constructor.
...
training_args = SFTConfig(packing=True)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=training_args
)
trainer.train()Note that if you use a packed dataset and if you pass max_steps in the training arguments you will probably train your models for more than few epochs, depending on the way you have configured the packed dataset and the training protocol. Double check that you know and understand what you are doing.
If you don’t want to pack your eval_dataset, you can pass eval_packing=False to the SFTConfig init method.
Customize your prompts using packed dataset
If your dataset has several fields that you want to combine, for example if the dataset has question and answer fields and you want to combine them, you can pass a formatting function to the trainer that will take care of that. For example:
def formatting_func(example):
text = f"### Question: {example['question']}\n ### Answer: {example['answer']}"
return text
training_args = SFTConfig(packing=True)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=training_args,
formatting_func=formatting_func
)
trainer.train()You can also customize the ConstantLengthDataset much more by directly passing the arguments to the SFTConfig constructor. Please refer to that class’ signature for more information.
Control over the pretrained model
You can directly pass the kwargs of the from_pretrained() method to the SFTConfig. For example, if you want to load a model in a different precision, analogous to
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.bfloat16)
...
training_args = SFTConfig(
model_init_kwargs={
"torch_dtype": "bfloat16",
},
output_dir="/tmp",
)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=training_args,
)
trainer.train()Note that all keyword arguments of from_pretrained() are supported.
Training adapters
We also support tight integration with 🤗 PEFT library so that any user can conveniently train adapters and share them on the Hub instead of training the entire model.
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
from peft import LoraConfig
dataset = load_dataset("trl-lib/Capybara", split="train")
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
target_modules="all-linear",
modules_to_save=["lm_head", "embed_token"],
task_type="CAUSAL_LM",
)
trainer = SFTTrainer(
"Qwen/Qwen2.5-0.5B",
train_dataset=dataset,
args=SFTConfig(output_dir="Qwen2.5-0.5B-SFT"),
peft_config=peft_config
)
trainer.train()If the chat template contains special tokens like <|im_start|> (ChatML) or <|eot_id|> (Llama), the embedding layer and LM head must be included in the trainable parameters via the modules_to_save argument. Without this, the fine-tuned model will produce unbounded or nonsense generations. If the chat template doesn’t contain special tokens (e.g. Alpaca), then the modules_to_save argument can be ignored or set to None.
You can also continue training your PeftModel. For that, first load a PeftModel outside SFTTrainer and pass it directly to the trainer without the peft_config argument being passed.
Training adapters with base 8 bit models
For that, you need to first load your 8 bit model outside the Trainer and pass a PeftConfig to the trainer. For example:
...
peft_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-neo-125m",
load_in_8bit=True,
device_map="auto",
)
trainer = SFTTrainer(
model,
train_dataset=dataset,
args=SFTConfig(),
peft_config=peft_config,
)
trainer.train()Using Flash Attention and Flash Attention 2
You can benefit from Flash Attention 1 & 2 using SFTTrainer out of the box with minimal changes of code. First, to make sure you have all the latest features from transformers, install transformers from source
pip install -U git+https://github.com/huggingface/transformers.git
Note that Flash Attention only works on GPU now and under half-precision regime (when using adapters, base model loaded in half-precision) Note also both features are perfectly compatible with other tools such as quantization.
Using Flash-Attention 1
For Flash Attention 1 you can use the BetterTransformer API and force-dispatch the API to use Flash Attention kernel. First, install the latest optimum package:
pip install -U optimum
Once you have loaded your model, wrap the trainer.train() call under the with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False): context manager:
...
+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
trainer.train()Note that you cannot train your model using Flash Attention 1 on an arbitrary dataset as torch.scaled_dot_product_attention does not support training with padding tokens if you use Flash Attention kernels. Therefore you can only use that feature with packing=True. If your dataset contains padding tokens, consider switching to Flash Attention 2 integration.
Below are some numbers you can get in terms of speedup and memory efficiency, using Flash Attention 1, on a single NVIDIA-T4 16GB.
| use_flash_attn_1 | model_name | max_seq_len | batch_size | time per training step |
|---|---|---|---|---|
| x | facebook/opt-350m | 2048 | 8 | ~59.1s |
| facebook/opt-350m | 2048 | 8 | OOM | |
| x | facebook/opt-350m | 2048 | 4 | ~30.3s |
| facebook/opt-350m | 2048 | 4 | ~148.9s |
Using Flash Attention-2
To use Flash Attention 2, first install the latest flash-attn package:
pip install -U flash-attn
And add attn_implementation="flash_attention_2" when calling from_pretrained:
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2"
)If you don’t use quantization, make sure your model is loaded in half-precision and dispatch your model on a supported GPU device. After loading your model, you can either train it as it is, or attach adapters and train adapters on it in case your model is quantized.
In contrast to Flash Attention 1, the integration makes it possible to train your model on an arbitrary dataset that also includes padding tokens.
Using model creation utility
We included a utility function to create your model.
class trl.ModelConfig
< source >( model_name_or_path: typing.Optional[str] = None model_revision: str = 'main' torch_dtype: typing.Optional[typing.Literal['auto', 'bfloat16', 'float16', 'float32']] = None trust_remote_code: bool = False attn_implementation: typing.Optional[str] = None use_peft: bool = False lora_r: int = 16 lora_alpha: int = 32 lora_dropout: float = 0.05 lora_target_modules: typing.Optional[list[str]] = None lora_modules_to_save: typing.Optional[list[str]] = None lora_task_type: str = 'CAUSAL_LM' use_rslora: bool = False load_in_8bit: bool = False load_in_4bit: bool = False bnb_4bit_quant_type: typing.Literal['fp4', 'nf4'] = 'nf4' use_bnb_nested_quant: bool = False )
Parameters
- model_name_or_path (
Optional[str], optional, defaults toNone) — Model checkpoint for weights initialization. - model_revision (
str, optional, defaults to"main") — Specific model version to use. It can be a branch name, a tag name, or a commit id. - torch_dtype (
Optional[Literal["auto", "bfloat16", "float16", "float32"]], optional, defaults toNone) — Override the defaulttorch.dtypeand load the model under this dtype. Possible values are"bfloat16":torch.bfloat16"float16":torch.float16"float32":torch.float32"auto": Automatically derive the dtype from the model’s weights.
- trust_remote_code (
bool, optional, defaults toFalse) — Whether to allow for custom models defined on the Hub in their own modeling files. This option should only be set toTruefor repositories you trust and in which you have read the code, as it will execute code present on the Hub on your local machine. - attn_implementation (
Optional[str], optional, defaults toNone) — Which attention implementation to use. You can run--attn_implementation=flash_attention_2, in which case you must install this manually by runningpip install flash-attn --no-build-isolation. - use_peft (
bool, optional, defaults toFalse) — Whether to use PEFT for training. - lora_r (
int, optional, defaults to16) — LoRA R value. - lora_alpha (
int, optional, defaults to32) — LoRA alpha. - lora_dropout (
float, optional, defaults to0.05) — LoRA dropout. - lora_target_modules (
Optional[Union[str, list[str]]], optional, defaults toNone) — LoRA target modules. - lora_modules_to_save (
Optional[list[str]], optional, defaults toNone) — Model layers to unfreeze & train. - lora_task_type (
str, optional, defaults to"CAUSAL_LM") — Task type to pass for LoRA (use"SEQ_CLS"for reward modeling). - use_rslora (
bool, optional, defaults toFalse) — Whether to use Rank-Stabilized LoRA, which sets the adapter scaling factor tolora_alpha/√r, instead of the original default value oflora_alpha/r. - load_in_8bit (
bool, optional, defaults toFalse) — Whether to use 8 bit precision for the base model. Works only with LoRA. - load_in_4bit (
bool, optional, defaults toFalse) — Whether to use 4 bit precision for the base model. Works only with LoRA. - bnb_4bit_quant_type (
str, optional, defaults to"nf4") — Quantization type ("fp4"or"nf4"). - use_bnb_nested_quant (
bool, optional, defaults toFalse) — Whether to use nested quantization.
Configuration class for the models.
Using HfArgumentParser we can turn this class into argparse arguments that can be specified on the command line.
from trl import ModelConfig, SFTTrainer, get_kbit_device_map, get_peft_config, get_quantization_config
model_args = ModelConfig(
model_name_or_path="facebook/opt-350m"
attn_implementation=None, # or "flash_attention_2"
)
torch_dtype = (
model_args.torch_dtype
if model_args.torch_dtype in ["auto", None]
else getattr(torch, model_args.torch_dtype)
)
quantization_config = get_quantization_config(model_args)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
model = AutoModelForCausalLM.from_pretrained(model_args.model_name_or_path, **model_kwargs)
trainer = SFTTrainer(
...,
model=model_args.model_name_or_path,
peft_config=get_peft_config(model_args),
)Enhance the model’s performances using NEFTune
NEFTune is a technique to boost the performance of chat models and was introduced by the paper “NEFTune: Noisy Embeddings Improve Instruction Finetuning” from Jain et al. it consists of adding noise to the embedding vectors during training. According to the abstract of the paper:
Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
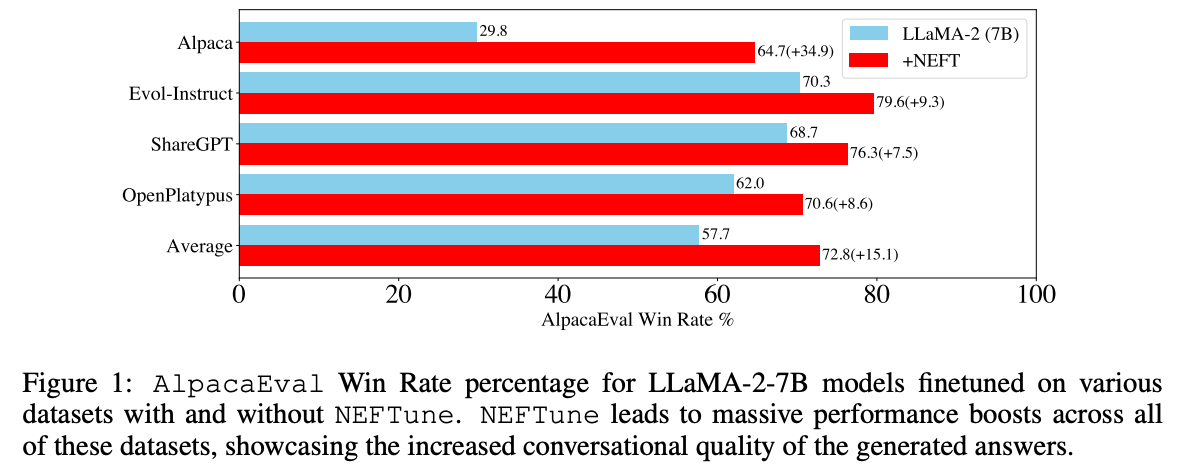
To use it in SFTTrainer simply pass neftune_noise_alpha when creating your SFTConfig instance. Note that to avoid any surprising behaviour, NEFTune is disabled after training to retrieve back the original behaviour of the embedding layer.
from datasets import load_dataset
from trl import SFTConfig, SFTTrainer
dataset = load_dataset("stanfordnlp/imdb", split="train")
training_args = SFTConfig(
neftune_noise_alpha=5,
)
trainer = SFTTrainer(
"facebook/opt-350m",
train_dataset=dataset,
args=training_args,
)
trainer.train()We have tested NEFTune by training mistralai/Mistral-7B-v0.1 on the OpenAssistant dataset and validated that using NEFTune led to a performance boost of ~25% on MT Bench.
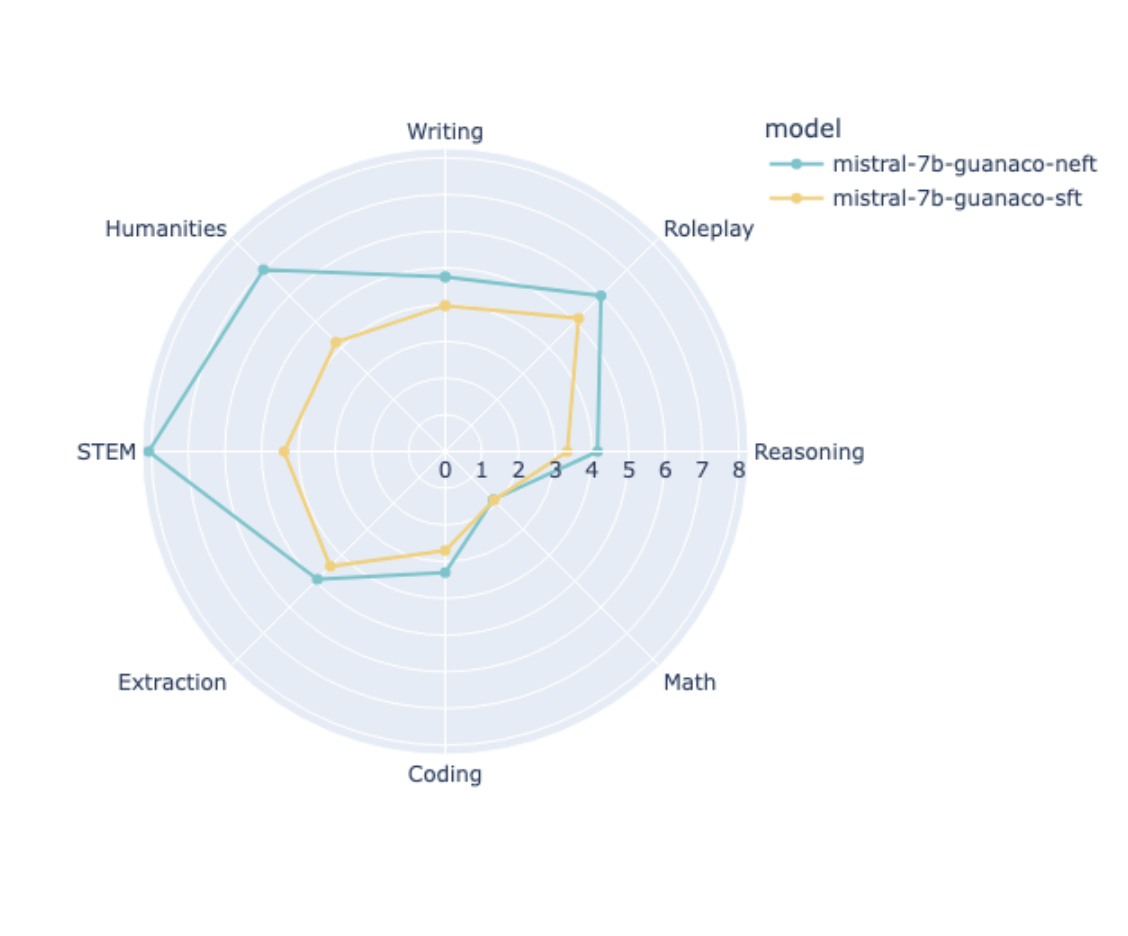
Note however, that the amount of performance gain is dataset dependent and in particular, applying NEFTune on synthetic datasets like UltraChat typically produces smaller gains.
Accelerate fine-tuning 2x using unsloth
You can further accelerate QLoRA / LoRA (2x faster, 60% less memory) using the unsloth library that is fully compatible with SFTTrainer. Currently unsloth supports only Llama (Yi, TinyLlama, Qwen, Deepseek etc) and Mistral architectures. Some benchmarks on 1x A100 listed below:
| 1 A100 40GB | Dataset | 🤗 | 🤗 + Flash Attention 2 | 🦥 Unsloth | 🦥 VRAM saved |
|---|---|---|---|---|---|
| Code Llama 34b | Slim Orca | 1x | 1.01x | 1.94x | -22.7% |
| Llama-2 7b | Slim Orca | 1x | 0.96x | 1.87x | -39.3% |
| Mistral 7b | Slim Orca | 1x | 1.17x | 1.88x | -65.9% |
| Tiny Llama 1.1b | Alpaca | 1x | 1.55x | 2.74x | -57.8% |
First install unsloth according to the official documentation. Once installed, you can incorporate unsloth into your workflow in a very simple manner; instead of loading AutoModelForCausalLM, you just need to load a FastLanguageModel as follows:
import torch
from trl import SFTConfig, SFTTrainer
from unsloth import FastLanguageModel
max_seq_length = 2048 # Supports automatic RoPE Scaling, so choose any number
# Load model
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/mistral-7b",
max_seq_length=max_seq_length,
dtype=None, # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit=True, # Use 4bit quantization to reduce memory usage. Can be False
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0, # Dropout = 0 is currently optimized
bias="none", # Bias = "none" is currently optimized
use_gradient_checkpointing=True,
random_state=3407,
)
training_args = SFTConfig(output_dir="./output", max_seq_length=max_seq_length)
trainer = SFTTrainer(
model=model,
args=training_args,
train_dataset=dataset,
)
trainer.train()The saved model is fully compatible with Hugging Face’s transformers library. Learn more about unsloth in their official repository.
Liger-Kernel: Increase 20% throughput and reduces 60% memory for multi-GPU training
Liger Kernel is a collection of Triton kernels designed specifically for LLM training. It can effectively increase multi-GPU training throughput by 20% and reduces memory usage by 60%. That way, we can 4x our context length, as described in the benchmark below. They have implemented Hugging Face Compatible RMSNorm, RoPE, SwiGLU, CrossEntropy, FusedLinearCrossEntropy, and more to come. The kernel works out of the box with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed.
With great memory reduction, you can potentially turn off cpu_offloading or gradient checkpointing to further boost the performance.
| Speed Up | Memory Reduction |
|---|---|
 |  |
- To use Liger-Kernel in
SFTTrainer, first install by
pip install liger-kernel
- Once installed, set
use_ligerin SFTConfig. No other changes are needed!
training_args = SFTConfig(
use_liger=True
)To learn more about Liger-Kernel, visit their official repository.
Best practices
Pay attention to the following best practices when training a model with that trainer:
- SFTTrainer always pads by default the sequences to the
max_seq_lengthargument of the SFTTrainer. If none is passed, the trainer will retrieve that value from the tokenizer. Some tokenizers do not provide a default value, so there is a check to retrieve the minimum between 2048 and that value. Make sure to check it before training. - For training adapters in 8bit, you might need to tweak the arguments of the
prepare_model_for_kbit_trainingmethod from PEFT, hence we advise users to useprepare_in_int8_kwargsfield, or create thePeftModeloutside the SFTTrainer and pass it. - For a more memory-efficient training using adapters, you can load the base model in 8bit, for that simply add
load_in_8bitargument when creating the SFTTrainer, or create a base model in 8bit outside the trainer and pass it. - If you create a model outside the trainer, make sure to not pass to the trainer any additional keyword arguments that are relative to
from_pretrained()method.
Multi-GPU Training
Trainer (and thus SFTTrainer) supports multi-GPU training. If you run your script with python script.py it will default to using DP as the strategy, which may be slower than expected. To use DDP (which is generally recommended, see here for more info) you must launch the script with python -m torch.distributed.launch script.py or accelerate launch script.py. For DDP to work you must also check the following:
- If you’re using gradient_checkpointing, add the following to the TrainingArguments:
gradient_checkpointing_kwargs={'use_reentrant':False}(more info here - Ensure that the model is placed on the correct device:
from accelerate import PartialState
device_string = PartialState().process_index
model = AutoModelForCausalLM.from_pretrained(
...
device_map={'':device_string}
)GPTQ Conversion
You may experience some issues with GPTQ Quantization after completing training. Lowering gradient_accumulation_steps to 4 will resolve most issues during the quantization process to GPTQ format.
Extending SFTTrainer for Vision Language Models
SFTTrainer does not inherently support vision-language data. However, we provide a guide on how to tweak the trainer to support vision-language data. Specifically, you need to use a custom data collator that is compatible with vision-language data. This guide outlines the steps to make these adjustments. For a concrete example, refer to the script examples/scripts/sft_vlm.py which demonstrates how to fine-tune the LLaVA 1.5 model on the HuggingFaceH4/llava-instruct-mix-vsft dataset.
Preparing the Data
The data format is flexible, provided it is compatible with the custom collator that we will define later. A common approach is to use conversational data. Given that the data includes both text and images, the format needs to be adjusted accordingly. Below is an example of a conversational data format involving both text and images:
images = ["obama.png"]
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "Who is this?"},
{"type": "image"}
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "Barack Obama"}
]
},
{
"role": "user",
"content": [
{"type": "text", "text": "What is he famous for?"}
]
},
{
"role": "assistant",
"content": [
{"type": "text", "text": "He is the 44th President of the United States."}
]
}
]To illustrate how this data format will be processed using the LLaVA model, you can use the following code:
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("llava-hf/llava-1.5-7b-hf")
print(processor.apply_chat_template(messages, tokenize=False))The output will be formatted as follows:
Who is this? ASSISTANT: Barack Obama USER: What is he famous for? ASSISTANT: He is the 44th President of the United States.
A custom collator for processing multi-modal data
Unlike the default behavior of SFTTrainer, processing multi-modal data is done on the fly during the data collation process. To do this, you need to define a custom collator that processes both the text and images. This collator must take a list of examples as input (see the previous section for an example of the data format) and return a batch of processed data. Below is an example of such a collator:
def collate_fn(examples):
# Get the texts and images, and apply the chat template
texts = [processor.apply_chat_template(example["messages"], tokenize=False) for example in examples]
images = [example["images"][0] for example in examples]
# Tokenize the texts and process the images
batch = processor(texts, images, return_tensors="pt", padding=True)
# The labels are the input_ids, and we mask the padding tokens in the loss computation
labels = batch["input_ids"].clone()
labels[labels == processor.tokenizer.pad_token_id] = -100
batch["labels"] = labels
return batchWe can verify that the collator works as expected by running the following code:
from datasets import load_dataset
dataset = load_dataset("HuggingFaceH4/llava-instruct-mix-vsft", split="train")
examples = [dataset[0], dataset[1]] # Just two examples for the sake of the example
collated_data = collate_fn(examples)
print(collated_data.keys()) # dict_keys(['input_ids', 'attention_mask', 'pixel_values', 'labels'])Training the vision-language model
Now that we have prepared the data and defined the collator, we can proceed with training the model. To ensure that the data is not processed as text-only, we need to set a couple of arguments in the SFTConfig, specifically remove_unused_columns and skip_prepare_dataset to True to avoid the default processing of the dataset. Below is an example of how to set up the SFTTrainer.
training_args.remove_unused_columns = False
training_args.dataset_kwargs = {"skip_prepare_dataset": True}
trainer = SFTTrainer(
model=model,
args=training_args,
data_collator=collate_fn,
train_dataset=train_dataset,
processing_class=processor.tokenizer,
)A full example of training LLaVa 1.5 on the HuggingFaceH4/llava-instruct-mix-vsft dataset can be found in the script examples/scripts/sft_vlm.py.
SFTTrainer
class trl.SFTTrainer
< source >( model: typing.Union[transformers.modeling_utils.PreTrainedModel, torch.nn.modules.module.Module, str, NoneType] = None args: typing.Optional[trl.trainer.sft_config.SFTConfig] = None data_collator: typing.Optional[transformers.data.data_collator.DataCollator] = None train_dataset: typing.Optional[datasets.arrow_dataset.Dataset] = None eval_dataset: typing.Union[datasets.arrow_dataset.Dataset, dict[str, datasets.arrow_dataset.Dataset], NoneType] = None processing_class: typing.Union[transformers.tokenization_utils_base.PreTrainedTokenizerBase, transformers.image_processing_utils.BaseImageProcessor, transformers.feature_extraction_utils.FeatureExtractionMixin, transformers.processing_utils.ProcessorMixin, NoneType] = None model_init: typing.Optional[typing.Callable[[], transformers.modeling_utils.PreTrainedModel]] = None compute_metrics: typing.Optional[typing.Callable[[transformers.trainer_utils.EvalPrediction], dict]] = None callbacks: typing.Optional[list[transformers.trainer_callback.TrainerCallback]] = None optimizers: tuple = (None, None) preprocess_logits_for_metrics: typing.Optional[typing.Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None peft_config: typing.Optional[ForwardRef('PeftConfig')] = None formatting_func: typing.Optional[typing.Callable] = None )
Parameters
- model (Union[
transformers.PreTrainedModel,nn.Module,str]) — The model to train, can be aPreTrainedModel, atorch.nn.Moduleor a string with the model name to load from cache or download. The model can be also converted to aPeftModelif aPeftConfigobject is passed to thepeft_configargument. - args (
Optional[SFTConfig]) — The arguments to tweak for training. Will default to a basic instance of SFTConfig with theoutput_dirset to a directory named tmp_trainer in the current directory if not provided. - data_collator (
Optional[transformers.DataCollator]) — The data collator to use for training. - train_dataset (
Optional[datasets.Dataset]) — The dataset to use for training. We recommend users to usetrl.trainer.ConstantLengthDatasetto create their dataset. - eval_dataset (Optional[Union[
datasets.Dataset, dict[str,datasets.Dataset]]]) — The dataset to use for evaluation. We recommend users to usetrl.trainer.ConstantLengthDatasetto create their dataset. - processing_class (
PreTrainedTokenizerBaseorBaseImageProcessororFeatureExtractionMixinorProcessorMixin, optional) — Processing class used to process the data. If provided, will be used to automatically process the inputs for the model, and it will be saved along the model to make it easier to rerun an interrupted training or reuse the fine-tuned model. This supercedes thetokenizerargument, which is now deprecated. - model_init (
Callable[[], transformers.PreTrainedModel]) — The model initializer to use for training. If None is specified, the default model initializer will be used. - compute_metrics (
Callable[[transformers.EvalPrediction], dict], optional defaults to None) — The function used to compute metrics during evaluation. It should return a dictionary mapping metric names to metric values. If not specified, only the loss will be computed during evaluation. - callbacks (
list[transformers.TrainerCallback]) — The callbacks to use for training. - optimizers (
tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR]) — The optimizer and scheduler to use for training. - preprocess_logits_for_metrics (
Callable[[torch.Tensor, torch.Tensor], torch.Tensor]) — The function to use to preprocess the logits before computing the metrics. - peft_config (
Optional[PeftConfig]) — The PeftConfig object to use to initialize the PeftModel. - formatting_func (
Optional[Callable]) — The formatting function to be used for creating theConstantLengthDataset.
Class definition of the Supervised Finetuning Trainer (SFT Trainer).
This class is a wrapper around the transformers.Trainer class and inherits all of its attributes and methods.
The trainer takes care of properly initializing the PeftModel in case a user passes a PeftConfig object.
create_model_card
< source >( model_name: typing.Optional[str] = None dataset_name: typing.Optional[str] = None tags: typing.Union[str, list[str], NoneType] = None )
Creates a draft of a model card using the information available to the Trainer.
SFTConfig
class trl.SFTConfig
< source >( output_dir: str overwrite_output_dir: bool = False do_train: bool = False do_eval: bool = False do_predict: bool = False eval_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'no' prediction_loss_only: bool = False per_device_train_batch_size: int = 8 per_device_eval_batch_size: int = 8 per_gpu_train_batch_size: typing.Optional[int] = None per_gpu_eval_batch_size: typing.Optional[int] = None gradient_accumulation_steps: int = 1 eval_accumulation_steps: typing.Optional[int] = None eval_delay: typing.Optional[float] = 0 torch_empty_cache_steps: typing.Optional[int] = None learning_rate: float = 2e-05 weight_decay: float = 0.0 adam_beta1: float = 0.9 adam_beta2: float = 0.999 adam_epsilon: float = 1e-08 max_grad_norm: float = 1.0 num_train_epochs: float = 3.0 max_steps: int = -1 lr_scheduler_type: typing.Union[transformers.trainer_utils.SchedulerType, str] = 'linear' lr_scheduler_kwargs: typing.Union[dict, str, NoneType] = <factory> warmup_ratio: float = 0.0 warmup_steps: int = 0 log_level: typing.Optional[str] = 'passive' log_level_replica: typing.Optional[str] = 'warning' log_on_each_node: bool = True logging_dir: typing.Optional[str] = None logging_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = 'steps' logging_first_step: bool = False logging_steps: float = 500 logging_nan_inf_filter: bool = True save_strategy: typing.Union[transformers.trainer_utils.SaveStrategy, str] = 'steps' save_steps: float = 500 save_total_limit: typing.Optional[int] = None save_safetensors: typing.Optional[bool] = True save_on_each_node: bool = False save_only_model: bool = False restore_callback_states_from_checkpoint: bool = False no_cuda: bool = False use_cpu: bool = False use_mps_device: bool = False seed: int = 42 data_seed: typing.Optional[int] = None jit_mode_eval: bool = False use_ipex: bool = False bf16: bool = False fp16: bool = False fp16_opt_level: str = 'O1' half_precision_backend: str = 'auto' bf16_full_eval: bool = False fp16_full_eval: bool = False tf32: typing.Optional[bool] = None local_rank: int = -1 ddp_backend: typing.Optional[str] = None tpu_num_cores: typing.Optional[int] = None tpu_metrics_debug: bool = False debug: typing.Union[str, typing.List[transformers.debug_utils.DebugOption]] = '' dataloader_drop_last: bool = False eval_steps: typing.Optional[float] = None dataloader_num_workers: int = 0 dataloader_prefetch_factor: typing.Optional[int] = None past_index: int = -1 run_name: typing.Optional[str] = None disable_tqdm: typing.Optional[bool] = None remove_unused_columns: typing.Optional[bool] = True label_names: typing.Optional[typing.List[str]] = None load_best_model_at_end: typing.Optional[bool] = False metric_for_best_model: typing.Optional[str] = None greater_is_better: typing.Optional[bool] = None ignore_data_skip: bool = False fsdp: typing.Union[typing.List[transformers.trainer_utils.FSDPOption], str, NoneType] = '' fsdp_min_num_params: int = 0 fsdp_config: typing.Union[dict, str, NoneType] = None fsdp_transformer_layer_cls_to_wrap: typing.Optional[str] = None accelerator_config: typing.Union[dict, str, NoneType] = None deepspeed: typing.Union[dict, str, NoneType] = None label_smoothing_factor: float = 0.0 optim: typing.Union[transformers.training_args.OptimizerNames, str] = 'adamw_torch' optim_args: typing.Optional[str] = None adafactor: bool = False group_by_length: bool = False length_column_name: typing.Optional[str] = 'length' report_to: typing.Union[NoneType, str, typing.List[str]] = None ddp_find_unused_parameters: typing.Optional[bool] = None ddp_bucket_cap_mb: typing.Optional[int] = None ddp_broadcast_buffers: typing.Optional[bool] = None dataloader_pin_memory: bool = True dataloader_persistent_workers: bool = False skip_memory_metrics: bool = True use_legacy_prediction_loop: bool = False push_to_hub: bool = False resume_from_checkpoint: typing.Optional[str] = None hub_model_id: typing.Optional[str] = None hub_strategy: typing.Union[transformers.trainer_utils.HubStrategy, str] = 'every_save' hub_token: typing.Optional[str] = None hub_private_repo: typing.Optional[bool] = None hub_always_push: bool = False gradient_checkpointing: bool = False gradient_checkpointing_kwargs: typing.Union[dict, str, NoneType] = None include_inputs_for_metrics: bool = False include_for_metrics: typing.List[str] = <factory> eval_do_concat_batches: bool = True fp16_backend: str = 'auto' evaluation_strategy: typing.Union[transformers.trainer_utils.IntervalStrategy, str] = None push_to_hub_model_id: typing.Optional[str] = None push_to_hub_organization: typing.Optional[str] = None push_to_hub_token: typing.Optional[str] = None mp_parameters: str = '' auto_find_batch_size: bool = False full_determinism: bool = False torchdynamo: typing.Optional[str] = None ray_scope: typing.Optional[str] = 'last' ddp_timeout: typing.Optional[int] = 1800 torch_compile: bool = False torch_compile_backend: typing.Optional[str] = None torch_compile_mode: typing.Optional[str] = None dispatch_batches: typing.Optional[bool] = None split_batches: typing.Optional[bool] = None include_tokens_per_second: typing.Optional[bool] = False include_num_input_tokens_seen: typing.Optional[bool] = False neftune_noise_alpha: typing.Optional[float] = None optim_target_modules: typing.Union[NoneType, str, typing.List[str]] = None batch_eval_metrics: bool = False eval_on_start: bool = False use_liger_kernel: typing.Optional[bool] = False eval_use_gather_object: typing.Optional[bool] = False average_tokens_across_devices: typing.Optional[bool] = False dataset_text_field: str = 'text' packing: bool = False max_seq_length: typing.Optional[int] = None dataset_num_proc: typing.Optional[int] = None dataset_batch_size: int = 1000 model_init_kwargs: typing.Optional[dict[str, typing.Any]] = None dataset_kwargs: typing.Optional[dict[str, typing.Any]] = None eval_packing: typing.Optional[bool] = None num_of_sequences: int = 1024 chars_per_token: float = 3.6 use_liger: bool = False )
Parameters
- dataset_text_field (
str, optional, defaults to"text") — Name of the text field of the dataset. If provided, the trainer will automatically create aConstantLengthDatasetbased ondataset_text_field. - packing (
bool, optional, defaults toFalse) — Controls whether theConstantLengthDatasetpacks the sequences of the dataset. - learning_rate (
float, optional, defaults to2e-5) — Initial learning rate forAdamWoptimizer. The default value replaces that of TrainingArguments. - max_seq_length (
Optional[int], optional, defaults toNone) — Maximum sequence length for theConstantLengthDatasetand for automatically creating the dataset. IfNone, it uses the smaller value betweentokenizer.model_max_lengthand1024. - dataset_num_proc (
Optional[int], optional, defaults toNone) — Number of processes to use for processing the dataset. Only used whenpacking=False. - dataset_batch_size (
Union[int, None], optional, defaults to1000) — Number of examples to tokenize per batch. Ifdataset_batch_size <= 0ordataset_batch_size is None, tokenizes the full dataset as a single batch. - model_init_kwargs (
Optional[dict[str, Any]], optional, defaults toNone) — Keyword arguments to pass toAutoModelForCausalLM.from_pretrainedwhen instantiating the model from a string. - dataset_kwargs (
Optional[dict[str, Any]], optional, defaults toNone) — Dictionary of optional keyword arguments to pass when creating packed or non-packed datasets. - eval_packing (
Optional[bool], optional, defaults toNone) — Whether to pack the eval dataset. IfNone, uses the same value aspacking. - num_of_sequences (
int, optional, defaults to1024) — Number of sequences to use for theConstantLengthDataset. - chars_per_token (
float, optional, defaults to3.6) — Number of characters per token to use for theConstantLengthDataset. See chars_token_ratio for more details. - use_liger (
bool, optional, defaults toFalse) — Monkey patch the model with Liger kernels to increase throughput and reduce memory usage.
Configuration class for the SFTTrainer.
Using HfArgumentParser we can turn this class into argparse arguments that can be specified on the command line.
Datasets
In the SFTTrainer we smartly support datasets.IterableDataset in addition to other style datasets. This is useful if you are using large corpora that you do not want to save all to disk. The data will be tokenized and processed on the fly, even when packing is enabled.
Additionally, in the SFTTrainer, we support pre-tokenized datasets if they are datasets.Dataset or datasets.IterableDataset. In other words, if such a dataset has a column of input_ids, no further processing (tokenization or packing) will be done, and the dataset will be used as-is. This can be useful if you have pretokenized your dataset outside of this script and want to re-use it directly.
ConstantLengthDataset
class trl.trainer.ConstantLengthDataset
< source >( tokenizer dataset dataset_text_field = None formatting_func = None infinite = False seq_length = 1024 num_of_sequences = 1024 chars_per_token = 3.6 eos_token_id = 0 shuffle = True append_concat_token = True add_special_tokens = True )
Parameters
- tokenizer (
transformers.PreTrainedTokenizer) — The processor used for processing the data. - dataset (
dataset.Dataset) — Dataset with text files. - dataset_text_field (
Optional[str], optional, defaults toNone) — Name of the field in the dataset that contains the text. Only one ofdataset_text_fieldandformatting_funcshould be provided. - formatting_func (
Callable, optional) — Function that formats the text before tokenization. Usually it is recommended to have follows a certain pattern such as"### Question: {question} ### Answer: {answer}". Only one ofdataset_text_fieldandformatting_funcshould be provided. - infinite (
bool, optional, defaults toFalse) — If True the iterator is reset after dataset reaches end else stops. - seq_length (
int, optional, defaults to1024) — Length of token sequences to return. - num_of_sequences (
int, optional, defaults to1024) — Number of token sequences to keep in buffer. - chars_per_token (
int, optional, defaults to3.6) — Number of characters per token used to estimate number of tokens in text buffer. - eos_token_id (
int, optional, defaults to0) — Id of the end of sequence token if the passed tokenizer does not have an EOS token. - shuffle (
bool, optional, defaults toTrue) — Shuffle the examples before they are returned - append_concat_token (
bool, optional, defaults toTrue) — If true, appendseos_token_idat the end of each sample being packed. - add_special_tokens (
bool, optional, defaults toTrue) — If true, tokenizers adds special tokens to each sample being packed.
Iterable dataset that returns constant length chunks of tokens from stream of text files. The dataset also formats the text before tokenization with a specific format that is provided by the user.