TRL documentation
TRL - Transformer Reinforcement Learning

TRL - Transformer Reinforcement Learning
TRL is a full stack library where we provide a set of tools to train transformer language models with Reinforcement Learning, from the Supervised Fine-tuning step (SFT), Reward Modeling step (RM) to the Proximal Policy Optimization (PPO) step. The library is integrated with 🤗 transformers.
Learn post-training
Learn post-training with the 🤗 smol course.
API documentation
- Model Classes: A brief overview of what each public model class does.
SFTTrainer: Supervise Fine-tune your model easily withSFTTrainerRewardTrainer: Train easily your reward model usingRewardTrainer.PPOTrainer: Further fine-tune the supervised fine-tuned model using PPO algorithm- Best-of-N Sampling: Use best of n sampling as an alternative way to sample predictions from your active model
DPOTrainer: Direct Preference Optimization training usingDPOTrainer.TextEnvironment: Text environment to train your model using tools with RL.
Examples
- Sentiment Tuning: Fine tune your model to generate positive movie contents
- Training with PEFT: Memory efficient RLHF training using adapters with PEFT
- Detoxifying LLMs: Detoxify your language model through RLHF
- StackLlama: End-to-end RLHF training of a Llama model on Stack exchange dataset
- Learning with Tools: Walkthrough of using
TextEnvironments - Multi-Adapter Training: Use a single base model and multiple adapters for memory efficient end-to-end training
Blog posts

Published on July 10, 2024
Preference Optimization for Vision Language Models with TRL

Published on June 12, 2024
Putting RL back in RLHF

Published on September 29, 2023
Finetune Stable Diffusion Models with DDPO via TRL

Published on August 8, 2023
Fine-tune Llama 2 with DPO

Published on April 5, 2023
StackLLaMA: A hands-on guide to train LLaMA with RLHF

Published on March 9, 2023
Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
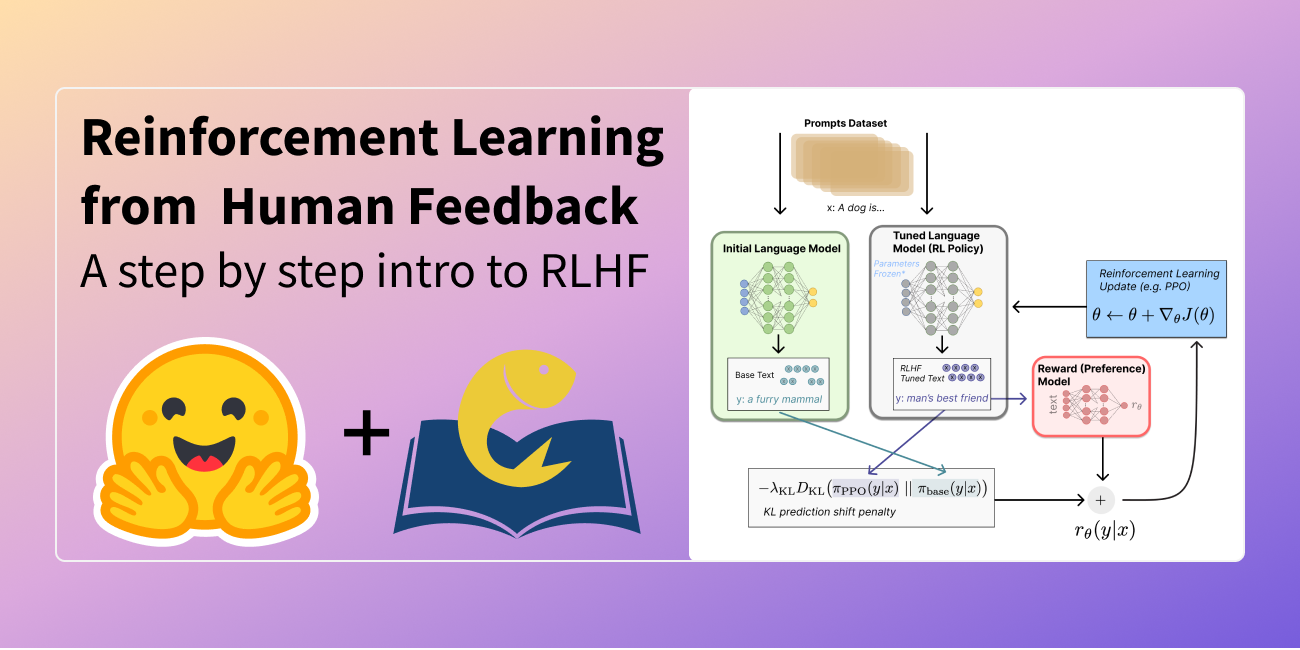
Published on December 9, 2022
Illustrating Reinforcement Learning from Human Feedback