TRL documentation
Using LLaMA models with TRL
Using LLaMA models with TRL
We’ve begun rolling out examples to use Meta’s LLaMA models in trl (see Meta’s LLaMA release for the original LLaMA model).
Efficient training strategies
Even training the smallest LLaMA model requires an enormous amount of memory. Some quick math: in bf16, every parameter uses 2 bytes (in fp32 4 bytes) in addition to 8 bytes used, e.g., in the Adam optimizer (see the performance docs in Transformers for more info). So a 7B parameter model would use (2+8)*7B=70GB just to fit in memory and would likely need more when you compute intermediate values such as attention scores. So you couldn’t train the model even on a single 80GB A100 like that. You can use some tricks, like more efficient optimizers of half-precision training, to squeeze a bit more into memory, but you’ll run out sooner or later.
Another option is to use Parameter-Efficient Fine-Tuning (PEFT) techniques, such as the peft library, which can perform low-rank adaptation (LoRA) on a model loaded in 8-bit.
For more on peft + trl, see the docs.
Loading the model in 8bit reduces the memory footprint drastically since you only need one byte per parameter for the weights (e.g. 7B LlaMa is 7GB in memory). Instead of training the original weights directly, LoRA adds small adapter layers on top of some specific layers (usually the attention layers); thus, the number of trainable parameters is drastically reduced.
In this scenario, a rule of thumb is to allocate ~1.2-1.4GB per billion parameters (depending on the batch size and sequence length) to fit the entire fine-tuning setup. This enables fine-tuning larger models (up to 50-60B scale models on a NVIDIA A100 80GB) at low cost.
Now we can fit very large models into a single GPU, but the training might still be very slow. The simplest strategy in this scenario is data parallelism: we replicate the same training setup into separate GPUs and pass different batches to each GPU. With this, you can parallelize the forward/backward passes of the model and scale with the number of GPUs.
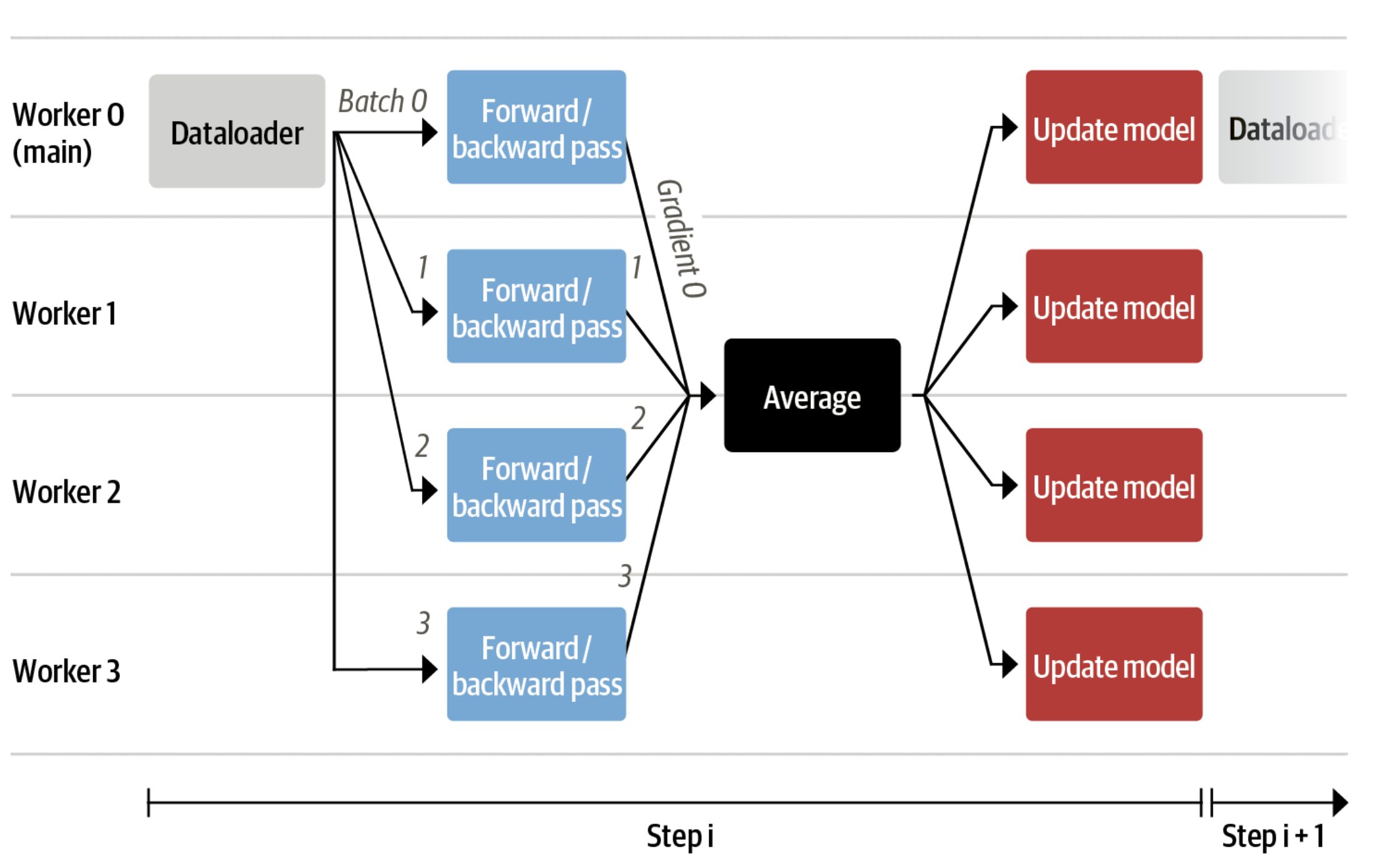
We use either the transformers.Trainer or accelerate, which both support data parallelism without any code changes, by simply passing arguments when calling the scripts with torchrun or accelerate launch. The following runs a training script with 8 GPUs on a single machine with accelerate and torchrun, respectively.
accelerate launch --multi_gpu --num_machines 1 --num_processes 8 my_accelerate_script.py torchrun --nnodes 1 --nproc_per_node 8 my_torch_script.py
Supervised fine-tuning
Before we start training reward models and tuning our model with RL, it helps if the model is already good in the domain we are interested in. In our case, we want it to answer questions, while for other use cases, we might want it to follow instructions, in which case instruction tuning is a great idea. The easiest way to achieve this is by continuing to train the language model with the language modeling objective on texts from the domain or task. The StackExchange dataset is enormous (over 10 million instructions), so we can easily train the language model on a subset of it.
There is nothing special about fine-tuning the model before doing RLHF - it’s just the causal language modeling objective from pretraining that we apply here. To use the data efficiently, we use a technique called packing: instead of having one text per sample in the batch and then padding to either the longest text or the maximal context of the model, we concatenate a lot of texts with a EOS token in between and cut chunks of the context size to fill the batch without any padding.
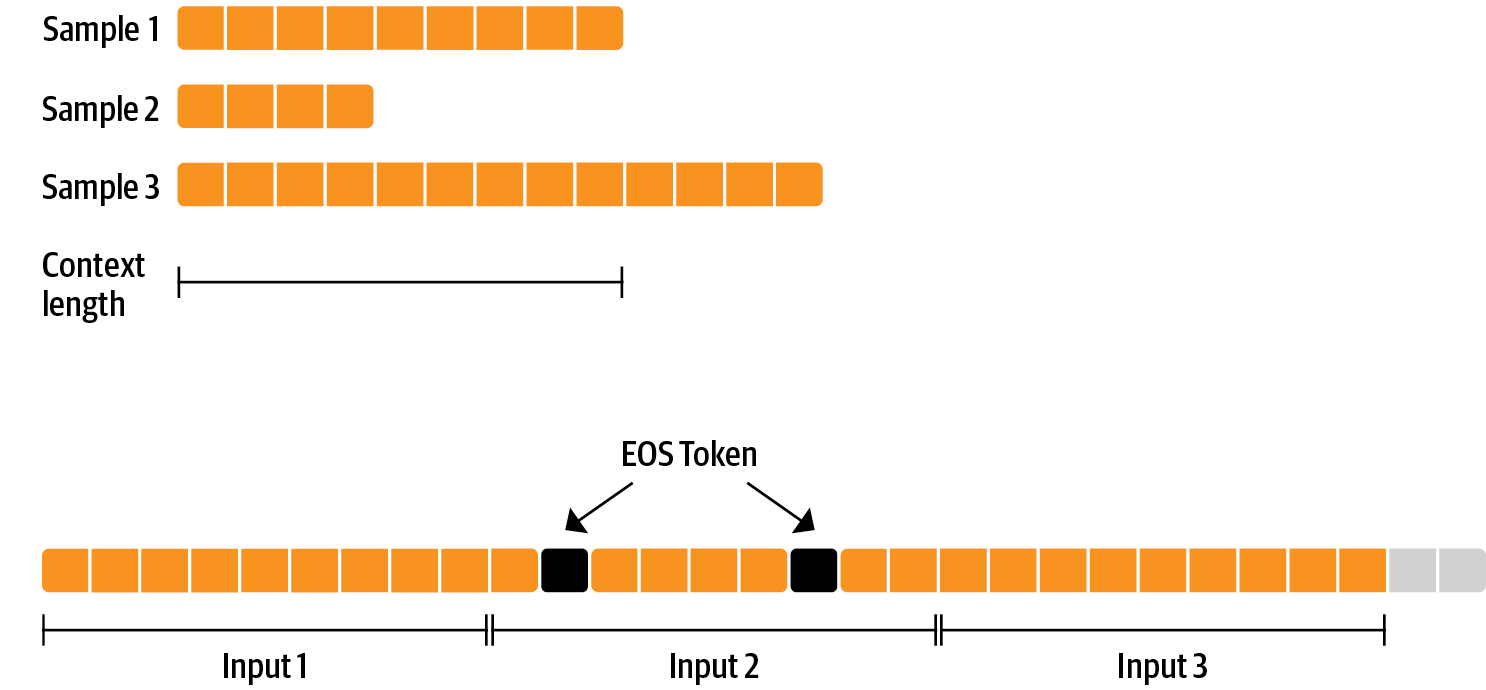
With this approach the training is much more efficient as each token that is passed through the model is also trained in contrast to padding tokens which are usually masked from the loss. If you don’t have much data and are more concerned about occasionally cutting off some tokens that are overflowing the context you can also use a classical data loader.
The packing is handled by the ConstantLengthDataset and we can then use the Trainer after loading the model with peft. First, we load the model in int8, prepare it for training, and then add the LoRA adapters.
# load model in 8bit
model = AutoModelForCausalLM.from_pretrained(
args.model_path,
load_in_8bit=True,
device_map={"": Accelerator().local_process_index}
)
model = prepare_model_for_kbit_training(model)
# add LoRA to model
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)We train the model for a few thousand steps with the causal language modeling objective and save the model. Since we will tune the model again with different objectives, we merge the adapter weights with the original model weights.
Disclaimer: due to LLaMA’s license, we release only the adapter weights for this and the model checkpoints in the following sections.
You can apply for access to the base model’s weights by filling out Meta AI’s form and then converting them to the 🤗 Transformers format by running this script.
Note that you’ll also need to install 🤗 Transformers from source until the v4.28 is released.
Now that we have fine-tuned the model for the task, we are ready to train a reward model.
Reward modeling and human preferences
In principle, we could fine-tune the model using RLHF directly with the human annotations. However, this would require us to send some samples to humans for rating after each optimization iteration. This is expensive and slow due to the number of training samples needed for convergence and the inherent latency of human reading and annotator speed.
A trick that works well instead of direct feedback is training a reward model on human annotations collected before the RL loop.
The goal of the reward model is to imitate how a human would rate a text. There are several possible strategies to build a reward model: the most straightforward way would be to predict the annotation (e.g. a rating score or a binary value for “good”/”bad”).
In practice, what works better is to predict the ranking of two examples, where the reward model is presented with two candidates (y_k, y_j) for a given prompt x and has to predict which one would be rated higher by a human annotator.
With the StackExchange dataset, we can infer which of the two answers was preferred by the users based on the score.
With that information and the loss defined above, we can then modify the transformers.Trainer by adding a custom loss function.
class RewardTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return lossWe utilize a subset of a 100,000 pair of candidates and evaluate on a held-out set of 50,000. With a modest training batch size of 4, we train the Llama model using the LoRA peft adapter for a single epoch using the Adam optimizer with BF16 precision. Our LoRA configuration is:
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)As detailed in the next section, the resulting adapter can be merged into the frozen model and saved for further downstream use.
Reinforcement Learning from Human Feedback
With the fine-tuned language model and the reward model at hand, we are now ready to run the RL loop. It follows roughly three steps:
- Generate responses from prompts,
- Rate the responses with the reward model,
- Run a reinforcement learning policy-optimization step with the ratings.
The Query and Response prompts are templated as follows before being tokenized and passed to the model:
Question: <Query> Answer: <Response>
The same template was used for SFT, RM and RLHF stages.
Once more, we utilize peft for memory-efficient training, which offers an extra advantage in the RLHF context.
Here, the reference model and policy share the same base, the SFT model, which we load in 8-bit and freeze during training.
We exclusively optimize the policy’s LoRA weights using PPO while sharing the base model’s weights.
for epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# sample from the policy and to generate responses
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
length_sampler=output_length_sampler,
**generation_kwargs,
)
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# Compute sentiment score
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = [torch.tensor(output[0]["score"] - script_args.reward_baseline) for output in pipe_outputs]
# Run PPO step
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
# Log stats to Wandb
ppo_trainer.log_stats(stats, batch, rewards)For the rest of the details and evaluation, please refer to our blog post on StackLLaMA.
< > Update on GitHub