TRL documentation
Tune GPT2 to generate positive reviews
Tune GPT2 to generate positive reviews
Optimise GPT2 to produce positive IMDB movie reviews using a BERT sentiment classifier as a reward function.Experiment setup to tune GPT2. The yellow arrows are outside the scope of this notebook, but the trained models are available through Hugging Face:
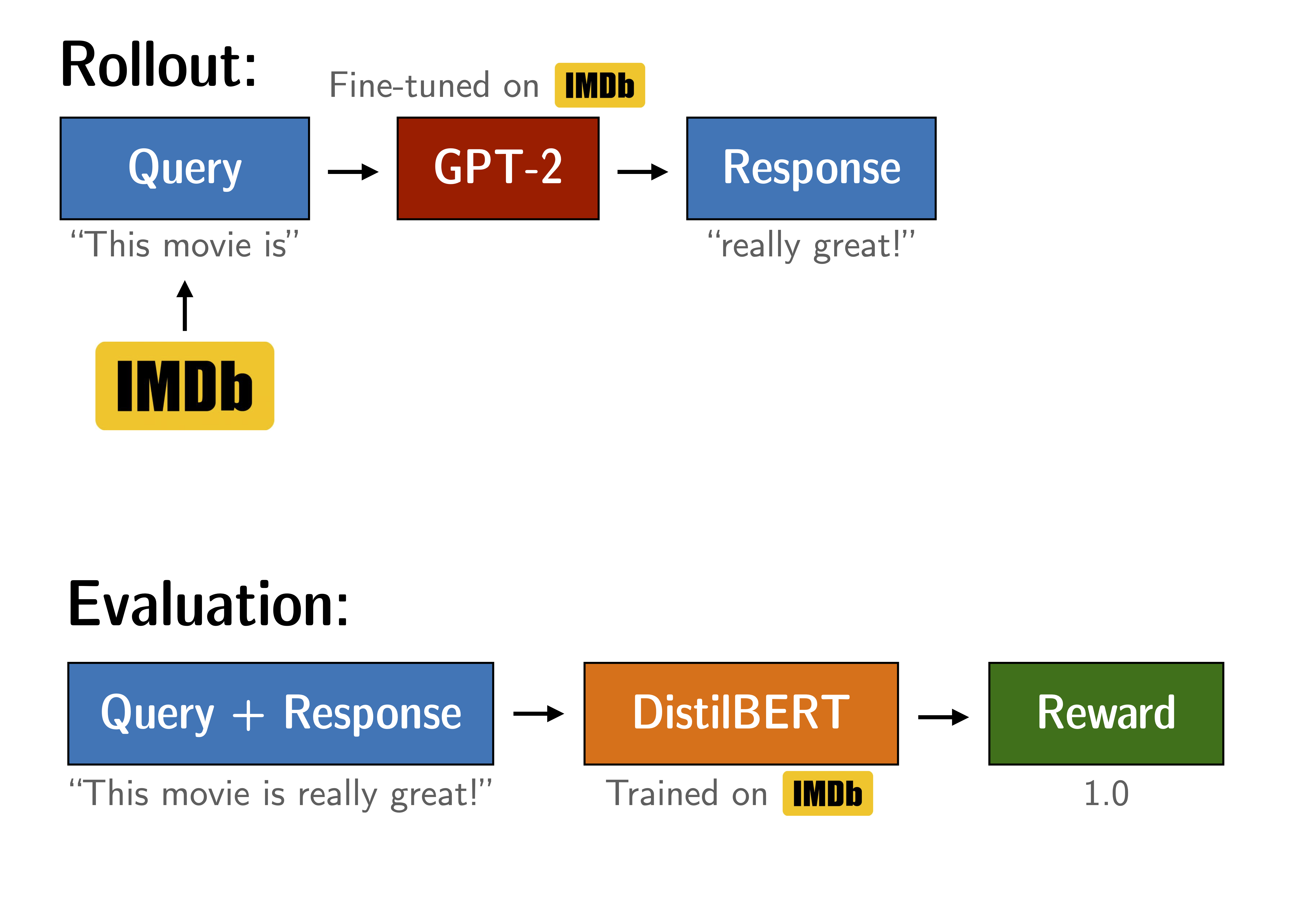
In this notebook we fine-tune GPT2 (small) to generate positive movie reviews based on the IMDB dataset. The model gets the start of a real review and is tasked to produce positive continuations. To reward positive continuations we use a BERT classifier to analyse the sentiment of the produced sentences and use the classifier’s outputs as rewards signals for PPO training.
Setup experiment
First we need to setup a few things: imports, configuration, and logger.
Install dependencies
pip install datasets
Import dependencies
import torch
import wandb
import time
import os
from tqdm import tqdm
import numpy as np
import pandas as pd
tqdm.pandas()
from datasets import load_dataset
from transformers import AutoTokenizer, pipeline
from trl.gpt2 import AutoModelForCausalLMWithValueHead
from trl.ppo import PPOTrainer
from trl.core import build_bert_batch_from_txt, listify_batchConfiguration
Next we setup a few configs for the training:
config = {
"model_name": "lvwerra/gpt2-imdb",
"cls_model_name": "lvwerra/distilbert-imdb",
"steps": 20000,
"batch_size": 256,
"forward_batch_size": 16,
"ppo_epochs": 4,
"txt_in_min_len": 2,
"txt_in_max_len": 8,
"txt_out_min_len": 4,
"txt_out_max_len": 16,
"lr": 1.41e-5,
"init_kl_coef":0.2,
"target": 6,
"horizon":10000,
"gamma":1,
"lam":0.95,
"cliprange": .2,
"cliprange_value":.2,
"vf_coef":.1,
}Forward batching: Since the models can be fairly big and we want to rollout large PPO batches this can lead to out-of-memory errors when doing the forward passes for text generation and sentiment analysis. We introduce the parameter forward_batch_size to split the forward passes into smaller batches. Although this hurts performance a little this is neglectible compared to the computations of the backward passes when optimizing the model. The same parameter is used in the PPOTrainer when doing forward passes. The batch_size should multiple of forward_batch_size.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pipe_device = 0 if torch.cuda.is_available() else -1You can see that we load a GPT2 model called gpt2_imdb. This model was additionally fine-tuned on the IMDB dataset for 1 epoch with the Hugging Face script (no special settings). The other parameters are mostly taken from the original paper “Fine-Tuning Language Models from Human Preferences”. This model as well as the BERT model is available in the Hugging Face model zoo here. The following code will automatically download the models.
Initialize W&B logger
We use `wandb`to log all the metrics during training.wandb.init(name='run-42', project='gpt2-test', config=config, )Load data and models
Load IMDB dataset
The IMDB dataset contains 50k movie review annotated with "positive"/"negative" feedback indicating the sentiment. We load the IMDB dataset into a DataFrame and filter for comments that are at least 500 characters long and take the first 1000 characters of each comment. The first filter we apply to avoid comments that are less than `txt_in_len` token long and the second to avoid tokenizing way more text than we actually need.ds = load_dataset('imdb', split='train')
ds = ds.rename_columns({'text': 'review', 'label': 'sentiment'})
ds = ds.filter(lambda x: len(x["review"])>200, batched=False)
ds Dataset({
features: ['review', 'sentiment'],
num_rows: 24895
})Load BERT classifier
We load a BERT classifier fine-tuned on the IMDB dataset.sent_kwargs = {
"return_all_scores": True,
"function_to_apply": "none",
"batch_size": config["forward_batch_size"]
}
sentiment_pipe = pipeline("sentiment-analysis","lvwerra/distilbert-imdb", device=pipe_device)The model outputs are the logits for the negative and positive class. We will use the logits for positive class as a reward signal for the language model.
text = 'this movie was really bad!!'
sentiment_pipe(text, **sent_kwargs) [[{'label': 'NEGATIVE', 'score': 2.335048198699951},
{'label': 'POSITIVE', 'score': -2.726576566696167}]]text = 'this movie was really good!!'
sentiment_pipe(text, **sent_kwargs) [[{'label': 'NEGATIVE', 'score': -2.2947897911071777},
{'label': 'POSITIVE', 'score': 2.557039737701416}]]Load pre-trained GPT2 language models
We load the GPT2 model with a value head and the tokenizer. We load the model twice; the first model is optimized while the second model serves as a reference to calculate the KL-divergence from the starting point. This serves as an additional reward signal in the PPO training to make sure the optimized model does not deviate too much from the original language model.
gpt2_model = AutoModelForCausalLMWithValueHead.from_pretrained(config['model_name'])
gpt2_model_ref = AutoModelForCausalLMWithValueHead.from_pretrained(config['model_name'])
gpt2_tokenizer = AutoTokenizer.from_pretrained(config['model_name'])
gpt2_tokenizer.pad_token = gpt2_tokenizer.eos_tokenWatch model with wandb
This wandb magic logs the gradients and weights of the model during training.wandb.watch(gpt2_model, log='all')Move models to GPU
If cuda is available move the computations to the GPU.
gpt2_model.to(device); gpt2_model_ref.to(device);
Tokenize IMDB reviews
We want to randomize the query and response length so we introduce a LengthSampler that uniformly samples values from an interval.
class LengthSampler:
def __init__(self, min_value, max_value):
self.values = list(range(min_value, max_value))
def __call__(self):
return np.random.choice(self.values)
input_size = LengthSampler(config["txt_in_min_len"], config["txt_in_max_len"])
output_size = LengthSampler(config["txt_out_min_len"], config["txt_out_max_len"])We pre-tokenize all IMDB in advance to avoid tokenizing twice. In the first step we encode the queries and slice the first input_size() tokens. In a second step we decode these tokens back to text for later display.
def tokenize(sample):
sample["tokens"] = gpt2_tokenizer.encode(sample["review"])[:input_size()]
sample["query"] = gpt2_tokenizer.decode(sample["tokens"])
return sample
ds = ds.map(tokenize, batched=False)Generation settings
For the response generation we just use sampling and make sure top-k and nucleus sampling are turned off as well as a minimal length.gen_kwargs = {
"min_length":-1,
"top_k": 0.0,
"top_p": 1.0,
"do_sample": True,
"pad_token_id": gpt2_tokenizer.eos_token_id
}Optimize model
Dataloader
We use a dataloader to return the batches of queries used for each PPO epoch:def collator(data):
return dict((key, [d[key] for d in data]) for key in data[0])
dataloader = torch.utils.data.DataLoader(ds, batch_size=config['batch_size'], collate_fn=collator)Training loop
The training loop consists of the following main steps:
- Get the query responses from the policy network (GPT-2)
- Get sentiments for query/responses from BERT
- Optimize policy with PPO using the (query, response, reward) triplet
Training time
This step takes ~2h on a V100 GPU with the above specified settings.
ppo_trainer = PPOTrainer(gpt2_model, gpt2_model_ref, gpt2_tokenizer, **config)
total_ppo_epochs = int(np.ceil(config["steps"]/config['batch_size']))
for epoch, batch in tqdm(zip(range(total_ppo_epochs), iter(dataloader))):
logs, timing = dict(), dict()
t0 = time.time()
query_tensors = [torch.tensor(t).long().to(device) for t in batch["tokens"]]
#### Get response from gpt2
t = time.time()
response_tensors = []
for i in range(config['batch_size']):
gen_len = output_size()
response = gpt2_model.generate(query_tensors[i].unsqueeze(dim=0),
max_new_tokens=gen_len, **gen_kwargs)
response_tensors.append(response.squeeze()[-gen_len:])
batch['response'] = [gpt2_tokenizer.decode(r.squeeze()) for r in response_tensors]
timing['time/get_response'] = time.time()-t
#### Compute sentiment score
t = time.time()
texts = [q + r for q,r in zip(batch['query'], batch['response'])]
pipe_outputs = sentiment_pipe(texts, **sent_kwargs)
rewards = torch.tensor([output[1]["score"] for output in pipe_outputs]).to(device)
timing['time/get_sentiment_preds'] = time.time()-t
#### Run PPO step
t = time.time()
stats = ppo_trainer.step(query_tensors, response_tensors, rewards)
timing['time/optimization'] = time.time()-t
#### Log everything
timing['time/epoch'] = time.time()-t0
table_rows = [list(r) for r in zip(batch['query'], batch['response'], rewards.cpu().tolist())]
logs.update({'game_log': wandb.Table(columns=['query', 'response', 'reward'], rows=table_rows)})
logs.update(timing)
logs.update(stats)
logs['env/reward_mean'] = torch.mean(rewards).cpu().numpy()
logs['env/reward_std'] = torch.std(rewards).cpu().numpy()
logs['env/reward_dist'] = rewards.cpu().numpy()
wandb.log(logs)Training progress
If you are tracking the training progress with Weights&Biases you should see a plot similar to the one below. Check out the interactive sample report on wandb.ai: [link](https://app.wandb.ai/lvwerra/trl-showcase/runs/1jtvxb1m/).Reward mean and distribution evolution during training:

One can observe how the model starts to generate more positive outputs after a few optimisation steps.
Note: Investigating the KL-divergence will probably show that at this point the model has not converged to the target KL-divergence, yet. To get there would require longer training or starting with a higher inital coefficient.
Model inspection
Let's inspect some examples from the IMDB dataset. We can use `gpt2_model_ref` to compare the tuned model `gpt2_model` against the model before optimisation.#### get a batch from the dataset
bs = 16
game_data = dict()
ds.set_format("pandas")
df_batch = ds[:].sample(bs)
game_data['query'] = df_batch['query'].tolist()
query_tensors = df_batch['tokens'].tolist()
response_tensors_ref, response_tensors = [], []
#### get response from gpt2 and gpt2_ref
for i in range(bs):
gen_len = output_size()
output = gpt2_model_ref.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),
max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]
response_tensors_ref.append(output)
output = gpt2_model.generate(torch.tensor(query_tensors[i]).unsqueeze(dim=0).to(device),
max_new_tokens=gen_len, **gen_kwargs).squeeze()[-gen_len:]
response_tensors.append(output)
#### decode responses
game_data['response (before)'] = [gpt2_tokenizer.decode(response_tensors_ref[i]) for i in range(bs)]
game_data['response (after)'] = [gpt2_tokenizer.decode(response_tensors[i]) for i in range(bs)]
#### sentiment analysis of query/response pairs before/after
texts = [q + r for q,r in zip(game_data['query'], game_data['response (before)'])]
game_data['rewards (before)'] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]
texts = [q + r for q,r in zip(game_data['query'], game_data['response (after)'])]
game_data['rewards (after)'] = [output[1]["score"] for output in sentiment_pipe(texts, **sent_kwargs)]
# store results in a dataframe
df_results = pd.DataFrame(game_data)
df_resultsLooking at the reward mean/median of the generated sequences we observe a significant difference.
print('mean:')
display(df_results[["rewards (before)", "rewards (after)"]].mean())
print()
print('median:')
display(df_results[["rewards (before)", "rewards (after)"]].median())mean: rewards (before) 0.156629 rewards (after) 1.686487
median: rewards (before) -0.547091 rewards (after) 2.479868
Save model
Finally, we save the model and push it to the Hugging Face for later usage. Before we can push the model to the hub we need to make sure we logged in:huggingface-cli login
gpt2_model.save_pretrained('gpt2-imdb-pos-v2', push_to_hub=True)
gpt2_tokenizer.save_pretrained('gpt2-imdb-pos-v2', push_to_hub=True)