Transformers documentation
ViLT
ViLT
Overview
The ViLT model was proposed in ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision by Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT incorporates text embeddings into a Vision Transformer (ViT), allowing it to have a minimal design for Vision-and-Language Pre-training (VLP).
The abstract from the paper is the following:
Vision-and-Language Pre-training (VLP) has improved performance on various joint vision-and-language downstream tasks. Current approaches to VLP heavily rely on image feature extraction processes, most of which involve region supervision (e.g., object detection) and the convolutional architecture (e.g., ResNet). Although disregarded in the literature, we find it problematic in terms of both (1) efficiency/speed, that simply extracting input features requires much more computation than the multimodal interaction steps; and (2) expressive power, as it is upper bounded to the expressive power of the visual embedder and its predefined visual vocabulary. In this paper, we present a minimal VLP model, Vision-and-Language Transformer (ViLT), monolithic in the sense that the processing of visual inputs is drastically simplified to just the same convolution-free manner that we process textual inputs. We show that ViLT is up to tens of times faster than previous VLP models, yet with competitive or better downstream task performance.
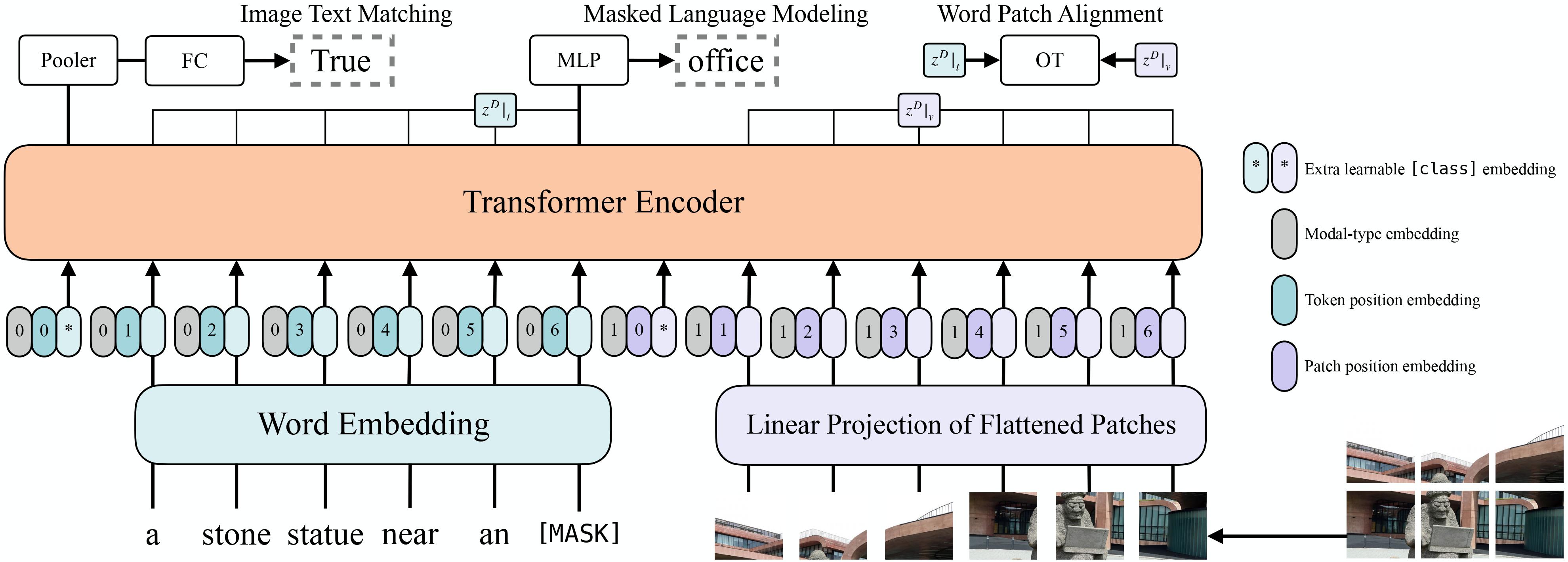 ViLT architecture. Taken from the original paper.
ViLT architecture. Taken from the original paper. This model was contributed by nielsr. The original code can be found here.
Usage tips
- The quickest way to get started with ViLT is by checking the example notebooks (which showcase both inference and fine-tuning on custom data).
- ViLT is a model that takes both
pixel_valuesandinput_idsas input. One can use ViltProcessor to prepare data for the model. This processor wraps a image processor (for the image modality) and a tokenizer (for the language modality) into one. - ViLT is trained with images of various sizes: the authors resize the shorter edge of input images to 384 and limit the longer edge to
under 640 while preserving the aspect ratio. To make batching of images possible, the authors use a
pixel_maskthat indicates which pixel values are real and which are padding. ViltProcessor automatically creates this for you. - The design of ViLT is very similar to that of a standard Vision Transformer (ViT). The only difference is that the model includes additional embedding layers for the language modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
ViltConfig
class transformers.ViltConfig
< source >( vocab_size = 30522 type_vocab_size = 2 modality_type_vocab_size = 2 max_position_embeddings = 40 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 initializer_range = 0.02 layer_norm_eps = 1e-12 image_size = 384 patch_size = 32 num_channels = 3 qkv_bias = True max_image_length = -1 tie_word_embeddings = False num_images = -1 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 30522) — Vocabulary size of the text part of the model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling ViltModel. - type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of thetoken_type_idspassed when calling ViltModel. This is used when encoding text. - modality_type_vocab_size (
int, optional, defaults to 2) — The vocabulary size of the modalities passed when calling ViltModel. This is used after concatening the embeddings of the text and image modalities. - max_position_embeddings (
int, optional, defaults to 40) — The maximum sequence length that this model might ever be used with. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - hidden_dropout_prob (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_probs_dropout_prob (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. - image_size (
int, optional, defaults to 384) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 32) — The size (resolution) of each patch. - num_channels (
int, optional, defaults to 3) — The number of input channels. - qkv_bias (
bool, optional, defaults toTrue) — Whether to add a bias to the queries, keys and values. - max_image_length (
int, optional, defaults to -1) — The maximum number of patches to take as input for the Transformer encoder. If set to a positive integer, the encoder will samplemax_image_lengthpatches at maximum. If set to -1, will not be taken into account. - num_images (
int, optional, defaults to -1) — The number of images to use for natural language visual reasoning. If set to a positive integer, will be used by ViltForImagesAndTextClassification for defining the classifier head.
This is the configuration class to store the configuration of a ViLTModel. It is used to instantiate an ViLT
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the ViLT
dandelin/vilt-b32-mlm architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import ViLTModel, ViLTConfig
>>> # Initializing a ViLT dandelin/vilt-b32-mlm style configuration
>>> configuration = ViLTConfig()
>>> # Initializing a model from the dandelin/vilt-b32-mlm style configuration
>>> model = ViLTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configViltFeatureExtractor
Preprocess an image or a batch of images.
ViltImageProcessor
class transformers.ViltImageProcessor
< source >( do_resize: bool = True size: Dict = None size_divisor: int = 32 resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_pad: bool = True **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"shortest_edge" -- 384}): Resize the shorter side of the input tosize["shortest_edge"]. The longer side will be limited to underint((1333 / 800) * size["shortest_edge"])while preserving the aspect ratio. Only has an effect ifdo_resizeis set toTrue. Can be overridden by thesizeparameter in thepreprocessmethod. - size_divisor (
int, optional, defaults to 32) — The size by which to make sure both the height and width can be divided. Only has an effect ifdo_resizeis set toTrue. Can be overridden by thesize_divisorparameter in thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BICUBIC) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. Can be overridden by theresampleparameter in thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Wwhether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Only has an effect ifdo_rescaleis set toTrue. Can be overridden by therescale_factorparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_STANDARD_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_STANDARD_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_pad (
bool, optional, defaults toTrue) — Whether to pad the image to the(max_height, max_width)of the images in the batch. Can be overridden by thedo_padparameter in thepreprocessmethod.
Constructs a ViLT image processor.
preprocess
< source >( images: Union do_resize: Optional = None size: Optional = None size_divisor: Optional = None resample: Resampling = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None do_pad: Optional = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Controls the size of the image afterresize. The shortest edge of the image is resized tosize["shortest_edge"]whilst preserving the aspect ratio. If the longest edge of this resized image is >int(size["shortest_edge"] * (1333 / 800)), then the image is resized again to make the longest edge equal toint(size["shortest_edge"] * (1333 / 800)). - size_divisor (
int, optional, defaults toself.size_divisor) — The image is resized to a size that is a multiple of this value. - resample (
PILImageResampling, optional, defaults toself.resample) — Resampling filter to use if resizing the image. Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean to normalize the image by ifdo_normalizeis set toTrue. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation to normalize the image by ifdo_normalizeis set toTrue. - do_pad (
bool, optional, defaults toself.do_pad) — Whether to pad the image to the (max_height, max_width) in the batch. IfTrue, a pixel mask is also created and returned. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
ViltProcessor
class transformers.ViltProcessor
< source >( image_processor = None tokenizer = None **kwargs )
Parameters
- image_processor (
ViltImageProcessor, optional) — An instance of ViltImageProcessor. The image processor is a required input. - tokenizer (
BertTokenizerFast, optional) — An instance of [‘BertTokenizerFast`]. The tokenizer is a required input.
Constructs a ViLT processor which wraps a BERT tokenizer and ViLT image processor into a single processor.
ViltProcessor offers all the functionalities of ViltImageProcessor and BertTokenizerFast. See the
docstring of call() and decode() for more information.
__call__
< source >( images text: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 pad_to_multiple_of: Optional = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: Union = None **kwargs )
This method uses ViltImageProcessor.call() method to prepare image(s) for the model, and BertTokenizerFast.call() to prepare text for the model.
Please refer to the docstring of the above two methods for more information.
ViltModel
class transformers.ViltModel
< source >( config add_pooling_layer = True )
Parameters
- config (ViltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare ViLT Model transformer outputting raw hidden-states without any specific head on top.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None image_token_type_idx: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViltConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViltModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ViltProcessor, ViltModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-mlm")
>>> model = ViltModel.from_pretrained("dandelin/vilt-b32-mlm")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateViltForMaskedLM
class transformers.ViltForMaskedLM
< source >( config )
Parameters
- config (ViltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
ViLT Model with a language modeling head on top as done during pretraining.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (torch.LongTensor of shape (batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in [-100, 0, …, config.vocab_size] (see input_ids docstring) Tokens with indices set to -100 are ignored (masked), the loss is only computed for the tokens with labels in [0, …, config.vocab_size]
Returns
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViltForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ViltProcessor, ViltForMaskedLM
>>> import requests
>>> from PIL import Image
>>> import re
>>> import torch
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "a bunch of [MASK] laying on a [MASK]."
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-mlm")
>>> model = ViltForMaskedLM.from_pretrained("dandelin/vilt-b32-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> tl = len(re.findall("\[MASK\]", text))
>>> inferred_token = [text]
>>> # gradually fill in the MASK tokens, one by one
>>> with torch.no_grad():
... for i in range(tl):
... encoded = processor.tokenizer(inferred_token)
... input_ids = torch.tensor(encoded.input_ids)
... encoded = encoded["input_ids"][0][1:-1]
... outputs = model(input_ids=input_ids, pixel_values=encoding.pixel_values)
... mlm_logits = outputs.logits[0] # shape (seq_len, vocab_size)
... # only take into account text features (minus CLS and SEP token)
... mlm_logits = mlm_logits[1 : input_ids.shape[1] - 1, :]
... mlm_values, mlm_ids = mlm_logits.softmax(dim=-1).max(dim=-1)
... # only take into account text
... mlm_values[torch.tensor(encoded) != 103] = 0
... select = mlm_values.argmax().item()
... encoded[select] = mlm_ids[select].item()
... inferred_token = [processor.decode(encoded)]
>>> selected_token = ""
>>> encoded = processor.tokenizer(inferred_token)
>>> output = processor.decode(encoded.input_ids[0], skip_special_tokens=True)
>>> print(output)
a bunch of cats laying on a couch.ViltForQuestionAnswering
class transformers.ViltForQuestionAnswering
< source >( config )
Parameters
- config (ViltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Vilt Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the [CLS] token) for visual question answering, e.g. for VQAv2.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.FloatTensorof shape(batch_size, num_labels), optional) — Labels for computing the visual question answering loss. This tensor must be either a one-hot encoding of all answers that are applicable for a given example in the batch, or a soft encoding indicating which answers are applicable, where 1.0 is the highest score.
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViltForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ViltProcessor, ViltForQuestionAnswering
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "How many cats are there?"
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
>>> model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> logits = outputs.logits
>>> idx = logits.argmax(-1).item()
>>> print("Predicted answer:", model.config.id2label[idx])
Predicted answer: 2ViltForImagesAndTextClassification
class transformers.ViltForImagesAndTextClassification
< source >( config )
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_images, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, num_images, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_images, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Vilt Model transformer with a classifier head on top for natural language visual reasoning, e.g. NLVR2.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.vilt.modeling_vilt.ViltForImagesAndTextClassificationOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Binary classification labels.
Returns
transformers.models.vilt.modeling_vilt.ViltForImagesAndTextClassificationOutput or tuple(torch.FloatTensor)
A transformers.models.vilt.modeling_vilt.ViltForImagesAndTextClassificationOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViltConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. - logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). - hidden_states (
List[tuple(torch.FloatTensor)], optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — List of tuples oftorch.FloatTensor(one for each image-text pair, each tuple containing the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
List[tuple(torch.FloatTensor)], optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — List of tuples oftorch.FloatTensor(one for each image-text pair, each tuple containing the attention weights of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViltForImagesAndTextClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ViltProcessor, ViltForImagesAndTextClassification
>>> import requests
>>> from PIL import Image
>>> image1 = Image.open(requests.get("https://lil.nlp.cornell.edu/nlvr/exs/ex0_0.jpg", stream=True).raw)
>>> image2 = Image.open(requests.get("https://lil.nlp.cornell.edu/nlvr/exs/ex0_1.jpg", stream=True).raw)
>>> text = "The left image contains twice the number of dogs as the right image."
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-nlvr2")
>>> model = ViltForImagesAndTextClassification.from_pretrained("dandelin/vilt-b32-finetuned-nlvr2")
>>> # prepare inputs
>>> encoding = processor([image1, image2], text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(input_ids=encoding.input_ids, pixel_values=encoding.pixel_values.unsqueeze(0))
>>> logits = outputs.logits
>>> idx = logits.argmax(-1).item()
>>> print("Predicted answer:", model.config.id2label[idx])
Predicted answer: TrueViltForImageAndTextRetrieval
class transformers.ViltForImageAndTextRetrieval
< source >( config )
Parameters
- config (ViltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Vilt Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the [CLS] token) for image-to-text or text-to-image retrieval, e.g. MSCOCO and F30K.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels are currently not supported.
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViltForImageAndTextRetrieval forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import ViltProcessor, ViltForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-coco")
>>> model = ViltForImageAndTextRetrieval.from_pretrained("dandelin/vilt-b32-finetuned-coco")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, :].item()ViltForTokenClassification
class transformers.ViltForTokenClassification
< source >( config )
Parameters
- config (ViltConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
ViLT Model with a token classification head on top (a linear layer on top of the final hidden-states of the text tokens) e.g. for Named-Entity-Recognition (NER) tasks.
This model is a PyTorch torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None pixel_values: Optional = None pixel_mask: Optional = None head_mask: Optional = None inputs_embeds: Optional = None image_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape({0})) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.FloatTensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- token_type_ids (
torch.LongTensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token. What are token type IDs?
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViltImageProcessor.call() for details. - pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
What are attention masks? <../glossary.html#attention-mask>__
- head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - image_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size), optional) — Optionally, instead of passingpixel_values, you can choose to directly pass an embedded representation. This is useful if you want more control over how to convertpixel_valuesinto patch embeddings. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, text_sequence_length), optional) — Labels for computing the token classification loss. Indices should be in[0, ..., config.num_labels - 1].
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ViltConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ViltForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.