Transformers documentation
تحميل نماذج مدربة مسبقًا باستخدام AutoClass
تحميل نماذج مدربة مسبقًا باستخدام AutoClass
لم ترغب في إنشاء محول معماري لمؤشر الترابط الخاص بك، فهناك العديد من محولات المعمارية المختلفة التي يمكنك الاختيار من بينها. كجزء من الفلسفة الأساسية لـ 🤗 Transformers لجعل المكتبة سهلة وبسيطة ومرنة، فإن فئة AutoClass تستدل تلقائيًا وتحمّل البنية الصحيحة من نسخة نموذج (Model Checkpoint) معينة. تسمح لك طريقة from_pretrained() بتحميل نموذج مُدرب مسبقًا لأي بنية بسرعة حتى لا تضطر إلى تكريس الوقت والموارد لتدريب نموذج من الصفر. إن إنتاج هذا النوع من التعليمات البرمجية غير المعتمدة على نسخ يعني أنه إذا نجح رمزك مع ننسخة واحدة، فسيتم تشغيله مع أخرى - طالما تم تدريبه لمهمة مماثلة - حتى إذا كانت البنية المعمارية مختلفة.
تذكر أن البنية تشير إلى هيكل النموذج، والنسخ هي الأوزان لبنية معمارية معينة. على سبيل المثال، BERT هي بنية معمارية، في حين أن google-bert/bert-base-uncased هي نسخة. “النموذج” هو مصطلح عام يمكن أن يعني إما البنية أو نالنسخة.
في هذا البرنامج التعليمي، ستتعلم كيفية:
- تحميل مُجزّئ الرموز مُدرب مسبقًا
- تحميل معالج صور مُدرب مسبقًا
- تحميل مستخرج ميزات مُدرب مسبقًا
- تحميل معالج مُدرب مسبقًا
- تحميل نموذج مُدرب مسبقًا
- تحميل نموذج كعمود فقري
AutoTokenizer
تبدأ كل مهمة NLP تقريبًا بمُجزّئ للرموز. يقوم المُجزّئ بتحويل النص إلى شكل يمكن للنموذج معالجته.
قم بتحميل المُجزّئ باستخدام AutoTokenizer.from_pretrained():
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-uncased")ثم قم بتحليل إدخالك على النحو الموضح أدناه:
>>> sequence = "In a hole in the ground there lived a hobbit."
>>> print(tokenizer(sequence))
{'input_ids': [101, 1999, 1037, 4920, 1999, 1996, 2598, 2045, 2973, 1037, 7570, 10322, 4183, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}معالج الصور التلقائي (AutoImageProcessor)
بالنسبة لمهمات الرؤية، يقوم معالج الصور بمعالجة الصورة إلى تنسيق الإدخال الصحيح.
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")AutoBackbone
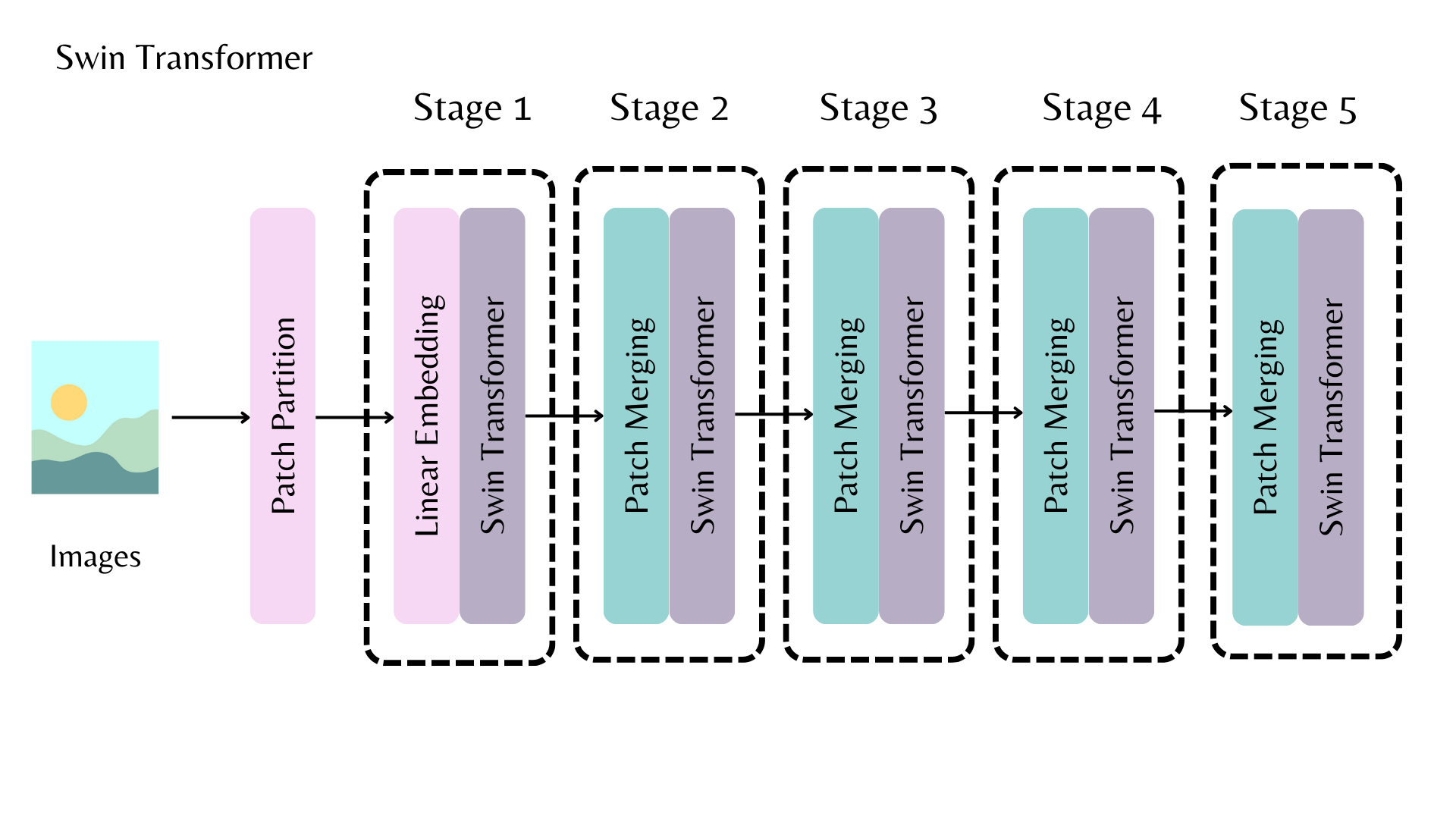
يسمح لك AutoBackbone باستخدام النماذج المُدربة مسبقًا كعمود فقري للحصول على خرائط ميزات من مراحل مختلفة من العمود الفقري. يجب عليك تحديد أحد المعلمات التالية في from_pretrained():
out_indicesهو فهرس الطبقة التي تريد الحصول على خريطة الميزات منهاout_featuresهو اسم الطبقة التي تريد الحصول على خريطة الميزات منها
يمكن استخدام هذه المعلمات بشكل متبادل، ولكن إذا كنت تستخدم كلاً منها، فتأكد من أنها متوائمة مع بعضها البعض! إذا لم تمرر أيًا من هذه المعلمات، فسيقوم العمود الفقري بإرجاع خريطة الميزات من الطبقة الأخيرة.
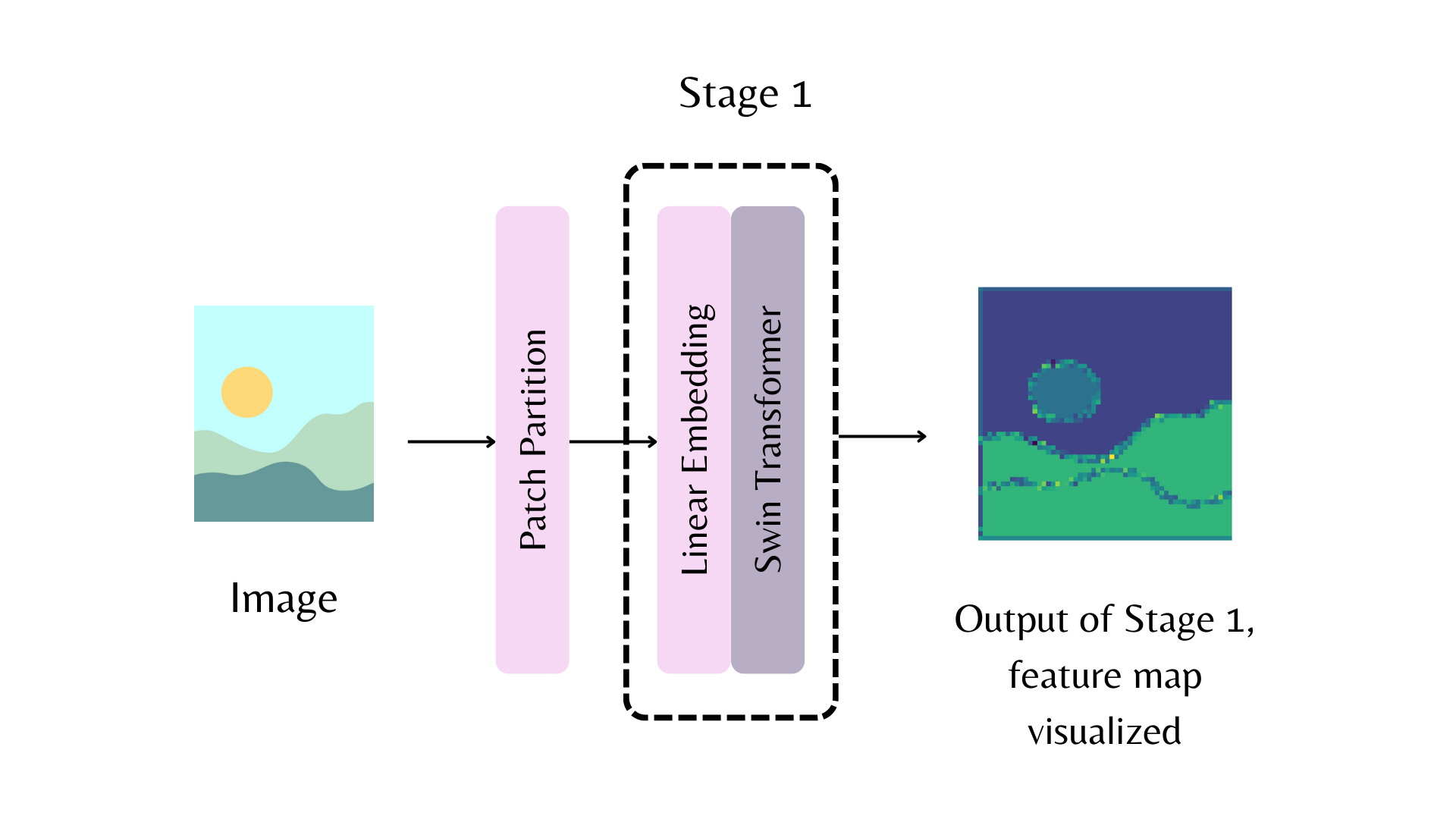
على سبيل المثال، في الرسم التخطيطي أعلاه، لإرجاع خريطة الميزات من المرحلة الأولى من العمود الفقري Swin، يمكنك تعيين out_indices=(1,):
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(1,))
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_mapsالآن يمكنك الوصول إلى كائن feature_maps من المرحلة الأولى من العمود الفقري:
>>> list(feature_maps[0].shape)
[1, 96, 56, 56]مستخرج الميزات التلقائي (AutoFeatureExtractor)
بالنسبة للمهام الصوتية، يقوم مستخرج الميزات بمعالجة إشارة الصوت إلى تنسيق الإدخال الصحيح.
قم بتحميل مستخرج ميزات باستخدام AutoFeatureExtractor.from_pretrained():
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained(
... "ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )المعالج التلقائي (AutoProcessor)
تتطلب المهام متعددة الوسائط معالجًا يجمع بين نوعين من أدوات المعالجة المسبقة. على سبيل المثال، يتطلب نموذج LayoutLMV2 معالج صور لمعالجة الصور ومُجزّئ لمعالجة النص؛ يجمع المعالج كليهما.
قم بتحميل معالج باستخدام AutoProcessor.from_pretrained():
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("microsoft/layoutlmv2-base-uncased")النموذج التلقائي (AutoModel)
تسمح لك فئات AutoModelFor بتحميل نموذج مُدرب مسبقًا لمهمة معينة (راجع هنا للحصول على قائمة كاملة بالمهام المتاحة). على سبيل المثال، قم بتحميل نموذج لتصنيف التسلسل باستخدام AutoModelForSequenceClassification.from_pretrained():
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")أعد استخدام نفس نقطة التفتيش لتحميل بنية لمهمة مختلفة:
>>> from transformers import AutoModelForTokenClassification
>>> model = AutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")بالنسبة لنماذج PyTorch، تستخدم طريقة from_pretrained() torch.load() التي تستخدم داخليًا pickle والتي يُعرف أنها غير آمنة. بشكل عام، لا تقم مطلقًا بتحميل نموذج قد يكون مصدره مصدرًا غير موثوق به، أو قد يكون تم العبث به. يتم تخفيف هذا الخطر الأمني جزئيًا للنماذج العامة المستضافة على Hub Hugging Face، والتي يتم فحصها بحثًا عن البرامج الضارة في كل ارتكاب. راجع توثيق Hub للحصول على أفضل الممارسات مثل التحقق من التوقيع باستخدام GPG.
لا تتأثر نقاط تفتيش TensorFlow و Flax، ويمكن تحميلها داخل بنيات PyTorch باستخدام from_tf و from_flax kwargs لطريقة from_pretrained للتحايل على هذه المشكلة.
بشكل عام، نوصي باستخدام فئة AutoTokenizer وفئة AutoModelFor لتحميل مثيلات مُدربة مسبقًا من النماذج. سيساعدك هذا في تحميل البنية الصحيحة في كل مرة. في البرنامج التعليمي التالي، تعرف على كيفية استخدام المحلل اللغوي ومعالج الصور ومستخرج الميزات والمعالج الذي تم تحميله حديثًا لمعالجة مجموعة بيانات للضبط الدقيق.
أخيرًا، تسمح لك فئات TFAutoModelFor بتحميل نموذج مُدرب مسبقًا لمهمة معينة (راجع هنا للحصول على قائمة كاملة بالمهام المتاحة). على سبيل المثال، قم بتحميل نموذج لتصنيف التسلسل باستخدام TFAutoModelForSequenceClassification.from_pretrained():
>>> from transformers import TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")أعد استخدام نفس نقطة التفتيش لتحميل بنية لمهمة مختلفة:
>>> from transformers import TFAutoModelForTokenClassification
>>> model = TFAutoModelForTokenClassification.from_pretrained("distilbert/distilbert-base-uncased")بشكل عام، نوصي باستخدام فئة AutoTokenizer وفئة TFAutoModelFor لتحميل نسخ لنماذج مُدربة مسبقًا. سيساعدك هذا في تحميل البنية الصحيحة في كل مرة. في البرنامج التعليمي التالي، ستتعرف على كيفية استخدام المُجزّئ اللغوي ومعالج الصور ومستخرج الميزات والمعالج الذي تم تحميله حديثًا لمعالجة مجموعة بيانات للضبط الدقيق.