Transformers documentation
Pipelines for inference
Pipelines for inference
The pipeline() makes it simple to use any model from the Hub for inference on any language, computer vision, speech, and multimodal tasks. Even if you don’t have experience with a specific modality or aren’t familiar with the underlying code behind the models, you can still use them for inference with the pipeline()! This tutorial will teach you to:
- Use a pipeline() for inference.
- Use a specific tokenizer or model.
- Use a pipeline() for audio, vision, and multimodal tasks.
Take a look at the pipeline() documentation for a complete list of supported tasks and available parameters.
Pipeline usage
While each task has an associated pipeline(), it is simpler to use the general pipeline() abstraction which contains all the task-specific pipelines. The pipeline() automatically loads a default model and a preprocessing class capable of inference for your task. Let’s take the example of using the pipeline() for automatic speech recognition (ASR), or speech-to-text.
- Start by creating a pipeline() and specify the inference task:
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")- Pass your input to the pipeline(). In the case of speech recognition, this is an audio input file:
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}Not the result you had in mind? Check out some of the most downloaded automatic speech recognition models on the Hub to see if you can get a better transcription.
Let’s try the Whisper large-v2 model from OpenAI. Whisper was released
2 years later than Wav2Vec2, and was trained on close to 10x more data. As such, it beats Wav2Vec2 on most downstream
benchmarks. It also has the added benefit of predicting punctuation and casing, neither of which are possible with
Wav2Vec2.
Let’s give it a try here to see how it performs:
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}Now this result looks more accurate! For a deep-dive comparison on Wav2Vec2 vs Whisper, refer to the Audio Transformers Course. We really encourage you to check out the Hub for models in different languages, models specialized in your field, and more. You can check out and compare model results directly from your browser on the Hub to see if it fits or handles corner cases better than other ones. And if you don’t find a model for your use case, you can always start training your own!
If you have several inputs, you can pass your input as a list:
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)Pipelines are great for experimentation as switching from one model to another is trivial; however, there are some ways to optimize them for larger workloads than experimentation. See the following guides that dive into iterating over whole datasets or using pipelines in a webserver: of the docs:
Parameters
pipeline() supports many parameters; some are task specific, and some are general to all pipelines. In general, you can specify parameters anywhere you want:
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.Let’s check out 3 important ones:
Device
If you use device=n, the pipeline automatically puts the model on the specified device.
This will work regardless of whether you are using PyTorch or Tensorflow.
transcriber = pipeline(model="openai/whisper-large-v2", device=0)If the model is too large for a single GPU and you are using PyTorch, you can set torch_dtype='float16' to enable FP16 precision inference. Usually this would not cause significant performance drops but make sure you evaluate it on your models!
Alternatively, you can set device_map="auto" to automatically
determine how to load and store the model weights. Using the device_map argument requires the 🤗 Accelerate
package:
pip install --upgrade accelerate
The following code automatically loads and stores model weights across devices:
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")Note that if device_map="auto" is passed, there is no need to add the argument device=device when instantiating your pipeline as you may encounter some unexpected behavior!
Batch size
By default, pipelines will not batch inference for reasons explained in detail here. The reason is that batching is not necessarily faster, and can actually be quite slower in some cases.
But if it works in your use case, you can use:
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)This runs the pipeline on the 4 provided audio files, but it will pass them in batches of 2 to the model (which is on a GPU, where batching is more likely to help) without requiring any further code from you. The output should always match what you would have received without batching. It is only meant as a way to help you get more speed out of a pipeline.
Pipelines can also alleviate some of the complexities of batching because, for some pipelines, a single item (like a long audio file) needs to be chunked into multiple parts to be processed by a model. The pipeline performs this chunk batching for you.
Task specific parameters
All tasks provide task specific parameters which allow for additional flexibility and options to help you get your job done.
For instance, the transformers.AutomaticSpeechRecognitionPipeline.call() method has a return_timestamps parameter which sounds promising for subtitling videos:
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}As you can see, the model inferred the text and also outputted when the various sentences were pronounced.
There are many parameters available for each task, so check out each task’s API reference to see what you can tinker with!
For instance, the AutomaticSpeechRecognitionPipeline has a chunk_length_s parameter which is helpful
for working on really long audio files (for example, subtitling entire movies or hour-long videos) that a model typically
cannot handle on its own:
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}If you can’t find a parameter that would really help you out, feel free to request it!
Using pipelines on a dataset
The pipeline can also run inference on a large dataset. The easiest way we recommend doing this is by using an iterator:
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="openai-community/gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])The iterator data() yields each result, and the pipeline automatically
recognizes the input is iterable and will start fetching the data while
it continues to process it on the GPU (this uses DataLoader under the hood).
This is important because you don’t have to allocate memory for the whole dataset
and you can feed the GPU as fast as possible.
Since batching could speed things up, it may be useful to try tuning the batch_size parameter here.
The simplest way to iterate over a dataset is to just load one from 🤗 Datasets:
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)Using pipelines for a webserver
Vision pipeline
Using a pipeline() for vision tasks is practically identical.
Specify your task and pass your image to the classifier. The image can be a link, a local path or a base64-encoded image. For example, what species of cat is shown below?

>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]Text pipeline
Using a pipeline() for NLP tasks is practically identical.
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}Multimodal pipeline
The pipeline() supports more than one modality. For example, a visual question answering (VQA) task combines text and image. Feel free to use any image link you like and a question you want to ask about the image. The image can be a URL or a local path to the image.
For example, if you use this invoice image:
{kind=link}
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> output = vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
>>> output[0]["score"] = round(output[0]["score"], 3)
>>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]To run the example above you need to have pytesseract installed in addition to 🤗 Transformers:
sudo apt install -y tesseract-ocr pip install pytesseract
Using pipeline on large models with 🤗 accelerate :
You can easily run pipeline on large models using 🤗 accelerate! First make sure you have installed accelerate with pip install accelerate.
First load your model using device_map="auto"! We will use facebook/opt-1.3b for our example.
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)You can also pass 8-bit loaded models if you install bitsandbytes and add the argument load_in_8bit=True
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)Note that you can replace the checkpoint with any Hugging Face model that supports large model loading, such as BLOOM.
Creating web demos from pipelines with gradio
Pipelines are automatically supported in Gradio, a library that makes creating beautiful and user-friendly machine learning apps on the web a breeze. First, make sure you have Gradio installed:
pip install gradioThen, you can create a web demo around an image classification pipeline (or any other pipeline) in a single line of code by calling Gradio’s Interface.from_pipeline function to launch the pipeline. This creates an intuitive drag-and-drop interface in your browser:
from transformers import pipeline
import gradio as gr
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
gr.Interface.from_pipeline(pipe).launch()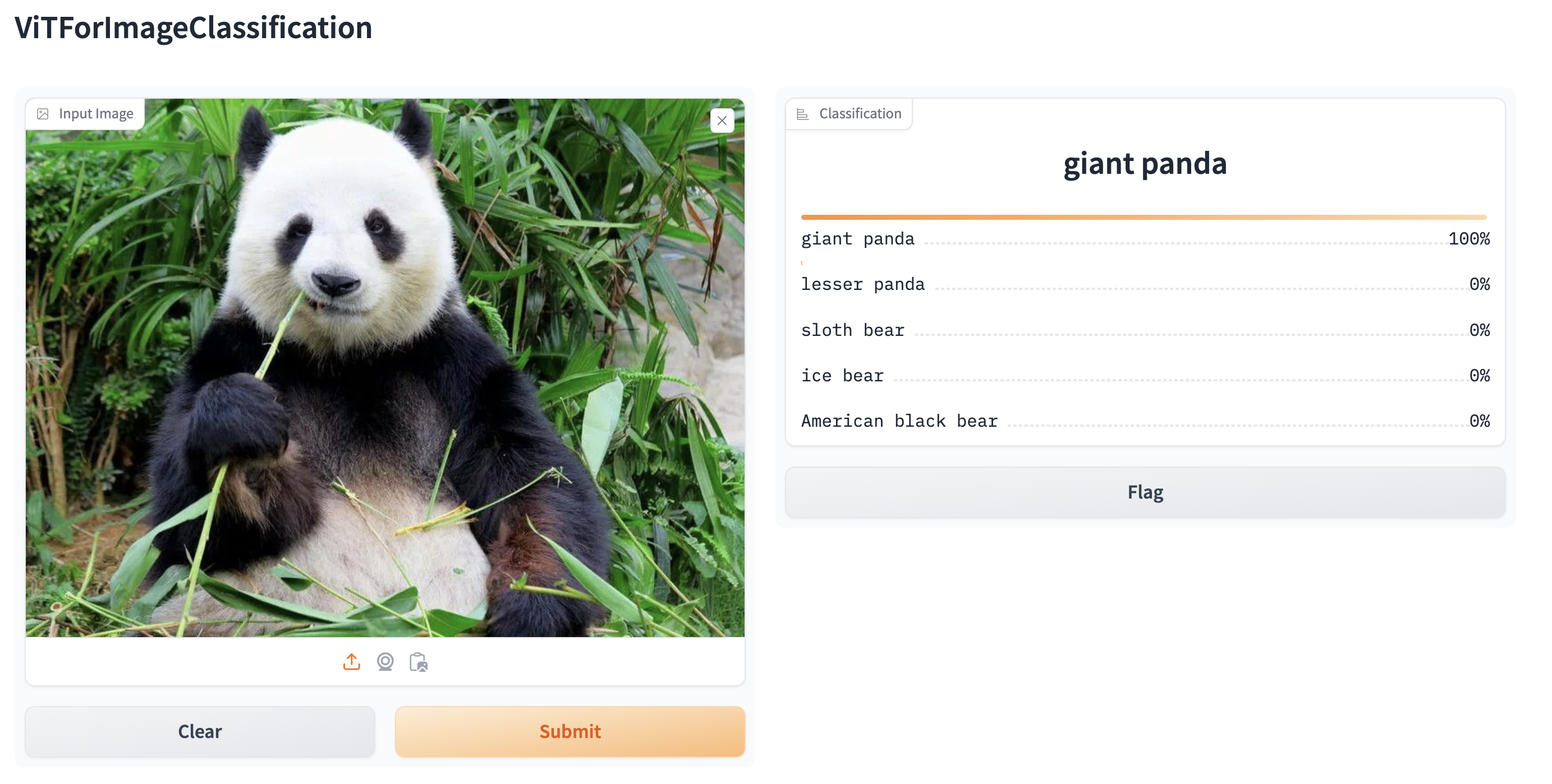
By default, the web demo runs on a local server. If you’d like to share it with others, you can generate a temporary public
link by setting share=True in launch(). You can also host your demo on Hugging Face Spaces for a permanent link.