마스크 생성
마스크 생성(Mask generation)은 이미지에 대한 의미 있는 마스크를 생성하는 작업입니다. 이 작업은 이미지 분할과 매우 유사하지만, 많은 차이점이 있습니다. 이미지 분할 모델은 라벨이 달린 데이터셋으로 학습되며, 학습 중에 본 클래스들로만 제한됩니다. 이미지가 주어지면, 이미지 분할 모델은 여러 마스크와 그에 해당하는 클래스를 반환합니다.
반면, 마스크 생성 모델은 대량의 데이터로 학습되며 두 가지 모드로 작동합니다.
- 프롬프트 모드(Prompting mode): 이 모드에서는 모델이 이미지와 프롬프트를 입력받습니다. 프롬프트는 이미지 내 객체의 2D 좌표(XY 좌표)나 객체를 둘러싼 바운딩 박스가 될 수 있습니다. 프롬프트 모드에서는 모델이 프롬프트가 가리키는 객체의 마스크만 반환합니다.
- 전체 분할 모드(Segment Everything mode): 이 모드에서는 주어진 이미지 내에서 모든 마스크를 생성합니다. 이를 위해 그리드 형태의 점들을 생성하고 이를 이미지에 오버레이하여 추론합니다.
마스크 생성 작업은 전체 분할 모드(Segment Anything Model, SAM)에 의해 지원됩니다. SAM은 Vision Transformer 기반 이미지 인코더, 프롬프트 인코더, 그리고 양방향 트랜스포머 마스크 디코더로 구성된 강력한 모델입니다. 이미지와 프롬프트는 인코딩되고, 디코더는 이러한 임베딩을 받아 유효한 마스크를 생성합니다.
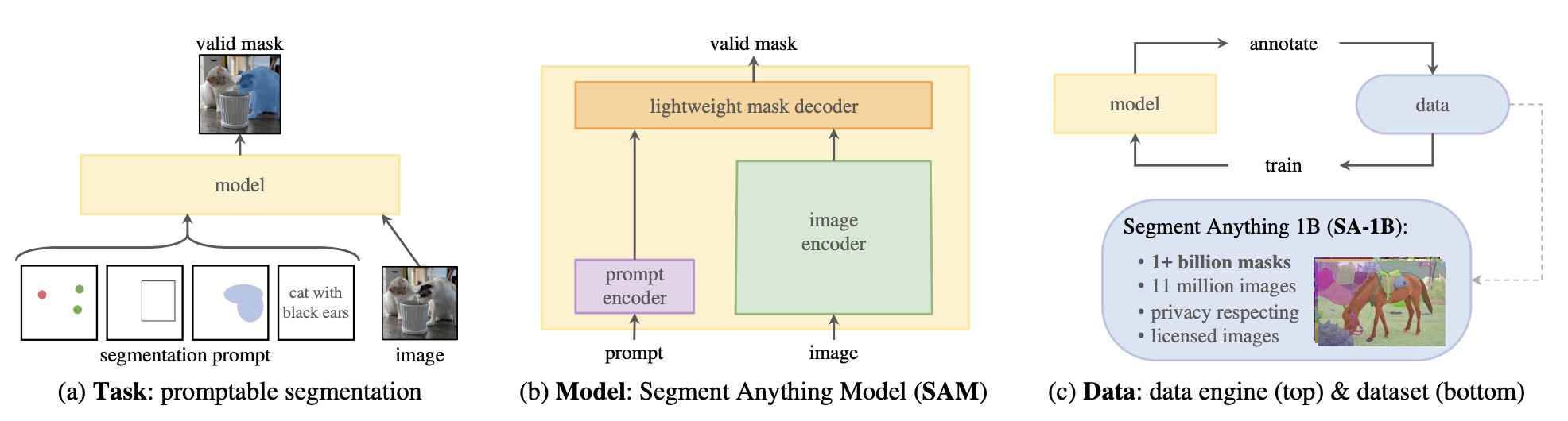
SAM은 대규모 데이터를 다룰 수 있는 강력한 분할 기반 모델입니다. 이 모델은 100만 개의 이미지와 11억 개의 마스크를 포함하는 SA-1B 데이터 세트로 학습되었습니다.
이 가이드에서는 다음과 같은 내용을 배우게 됩니다:
- 배치 처리와 함께 전체 분할 모드에서 추론하는 방법
- 포인트 프롬프팅 모드에서 추론하는 방법
- 박스 프롬프팅 모드에서 추론하는 방법
먼저, transformers를 설치해 봅시다:
pip install -q transformers
마스크 생성 파이프라인
마스크 생성 모델로 추론하는 가장 쉬운 방법은 mask-generation 파이프라인을 사용하는 것입니다.
>>> from transformers import pipeline
>>> checkpoint = "facebook/sam-vit-base"
>>> mask_generator = pipeline(model=checkpoint, task="mask-generation")이미지를 예시로 봅시다.
from PIL import Image
import requests
img_url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg"
image = Image.open(requests.get(img_url, stream=True).raw).convert("RGB")
전체적으로 분할해봅시다. points-per-batch는 전체 분할 모드에서 점들의 병렬 추론을 가능하게 합니다. 이를 통해 추론 속도가 빨라지지만, 더 많은 메모리를 소모하게 됩니다. 또한, SAM은 이미지가 아닌 점들에 대해서만 배치 처리를 지원합니다. pred_iou_thresh는 IoU 신뢰 임계값으로, 이 임계값을 초과하는 마스크만 반환됩니다.
masks = mask_generator(image, points_per_batch=128, pred_iou_thresh=0.88)masks 는 다음과 같이 생겼습니다:
{'masks': [array([[False, False, False, ..., True, True, True],
[False, False, False, ..., True, True, True],
[False, False, False, ..., True, True, True],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]),
array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
...,
'scores': tensor([0.9972, 0.9917,
...,
}위 내용을 아래와 같이 시각화할 수 있습니다:
import matplotlib.pyplot as plt
plt.imshow(image, cmap='gray')
for i, mask in enumerate(masks["masks"]):
plt.imshow(mask, cmap='viridis', alpha=0.1, vmin=0, vmax=1)
plt.axis('off')
plt.show()아래는 회색조 원본 이미지에 다채로운 색상의 맵을 겹쳐놓은 모습입니다. 매우 인상적인 결과입니다.

모델 추론
포인트 프롬프팅
파이프라인 없이도 모델을 사용할 수 있습니다. 이를 위해 모델과 프로세서를 초기화해야 합니다.
from transformers import SamModel, SamProcessor
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SamModel.from_pretrained("facebook/sam-vit-base").to(device)
processor = SamProcessor.from_pretrained("facebook/sam-vit-base")포인트 프롬프팅을 하기 위해, 입력 포인트를 프로세서에 전달한 다음, 프로세서 출력을 받아 모델에 전달하여 추론합니다. 모델 출력을 후처리하려면, 출력과 함께 프로세서의 초기 출력에서 가져온 original_sizes와 reshaped_input_sizes를 전달해야 합니다. 왜냐하면, 프로세서가 이미지 크기를 조정하고 출력을 추정해야 하기 때문입니다.
input_points = [[[2592, 1728]]] # 벌의 포인트 위치
inputs = processor(image, input_points=input_points, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
masks = processor.image_processor.post_process_masks(outputs.pred_masks.cpu(), inputs["original_sizes"].cpu(), inputs["reshaped_input_sizes"].cpu())masks 출력으로 세 가지 마스크를 시각화할 수 있습니다.
import matplotlib.pyplot as plt
import numpy as np
fig, axes = plt.subplots(1, 4, figsize=(15, 5))
axes[0].imshow(image)
axes[0].set_title('Original Image')
mask_list = [masks[0][0][0].numpy(), masks[0][0][1].numpy(), masks[0][0][2].numpy()]
for i, mask in enumerate(mask_list, start=1):
overlayed_image = np.array(image).copy()
overlayed_image[:,:,0] = np.where(mask == 1, 255, overlayed_image[:,:,0])
overlayed_image[:,:,1] = np.where(mask == 1, 0, overlayed_image[:,:,1])
overlayed_image[:,:,2] = np.where(mask == 1, 0, overlayed_image[:,:,2])
axes[i].imshow(overlayed_image)
axes[i].set_title(f'Mask {i}')
for ax in axes:
ax.axis('off')
plt.show()
박스 프롬프팅
박스 프롬프팅도 포인트 프롬프팅과 유사한 방식으로 할 수 있습니다. 입력 박스를 [x_min, y_min, x_max, y_max] 형식의 리스트로 작성하여 이미지와 함께 processor에 전달할 수 있습니다. 프로세서 출력을 받아 모델에 직접 전달한 후, 다시 출력을 후처리해야 합니다.
# 벌 주위의 바운딩 박스
box = [2350, 1600, 2850, 2100]
inputs = processor(
image,
input_boxes=[[[box]]],
return_tensors="pt"
).to("cuda")
with torch.no_grad():
outputs = model(**inputs)
mask = processor.image_processor.post_process_masks(
outputs.pred_masks.cpu(),
inputs["original_sizes"].cpu(),
inputs["reshaped_input_sizes"].cpu()
)[0][0][0].numpy()이제 아래와 같이, 벌 주위의 바운딩 박스를 시각화할 수 있습니다.
import matplotlib.patches as patches
fig, ax = plt.subplots()
ax.imshow(image)
rectangle = patches.Rectangle((2350, 1600), 500, 500, linewidth=2, edgecolor='r', facecolor='none')
ax.add_patch(rectangle)
ax.axis("off")
plt.show()
아래에서 추론 결과를 확인할 수 있습니다.
fig, ax = plt.subplots()
ax.imshow(image)
ax.imshow(mask, cmap='viridis', alpha=0.4)
ax.axis("off")
plt.show()