Transformers documentation
Optimization
Optimization
.optimization モジュールは以下を提供します。
- モデルの微調整に使用できる重み減衰が修正されたオプティマイザー、および
_LRScheduleから継承するスケジュール オブジェクトの形式のいくつかのスケジュール:- 複数のバッチの勾配を累積するための勾配累積クラス
AdamW (PyTorch)
class transformers.AdamW
< source >( params: Iterable lr: float = 0.001 betas: Tuple = (0.9, 0.999) eps: float = 1e-06 weight_decay: float = 0.0 correct_bias: bool = True no_deprecation_warning: bool = False )
Parameters
- params (
Iterable[nn.parameter.Parameter]) — Iterable of parameters to optimize or dictionaries defining parameter groups. - lr (
float, optional, defaults to 0.001) — The learning rate to use. - betas (
Tuple[float,float], optional, defaults to(0.9, 0.999)) — Adam’s betas parameters (b1, b2). - eps (
float, optional, defaults to 1e-06) — Adam’s epsilon for numerical stability. - weight_decay (
float, optional, defaults to 0.0) — Decoupled weight decay to apply. - correct_bias (
bool, optional, defaults toTrue) — Whether or not to correct bias in Adam (for instance, in Bert TF repository they useFalse). - no_deprecation_warning (
bool, optional, defaults toFalse) — A flag used to disable the deprecation warning (set toTrueto disable the warning).
Implements Adam algorithm with weight decay fix as introduced in Decoupled Weight Decay Regularization.
step
< source >( closure: Callable = None )
Performs a single optimization step.
AdaFactor (PyTorch)
class transformers.Adafactor
< source >( params lr = None eps = (1e-30, 0.001) clip_threshold = 1.0 decay_rate = -0.8 beta1 = None weight_decay = 0.0 scale_parameter = True relative_step = True warmup_init = False )
Parameters
- params (
Iterable[nn.parameter.Parameter]) — Iterable of parameters to optimize or dictionaries defining parameter groups. - lr (
float, optional) — The external learning rate. - eps (
Tuple[float, float], optional, defaults to(1e-30, 0.001)) — Regularization constants for square gradient and parameter scale respectively - clip_threshold (
float, optional, defaults to 1.0) — Threshold of root mean square of final gradient update - decay_rate (
float, optional, defaults to -0.8) — Coefficient used to compute running averages of square - beta1 (
float, optional) — Coefficient used for computing running averages of gradient - weight_decay (
float, optional, defaults to 0.0) — Weight decay (L2 penalty) - scale_parameter (
bool, optional, defaults toTrue) — If True, learning rate is scaled by root mean square - relative_step (
bool, optional, defaults toTrue) — If True, time-dependent learning rate is computed instead of external learning rate - warmup_init (
bool, optional, defaults toFalse) — Time-dependent learning rate computation depends on whether warm-up initialization is being used
AdaFactor pytorch implementation can be used as a drop in replacement for Adam original fairseq code: https://github.com/pytorch/fairseq/blob/master/fairseq/optim/adafactor.py
Paper: Adafactor: Adaptive Learning Rates with Sublinear Memory Cost https://arxiv.org/abs/1804.04235 Note that
this optimizer internally adjusts the learning rate depending on the scale_parameter, relative_step and
warmup_init options. To use a manual (external) learning rate schedule you should set scale_parameter=False and
relative_step=False.
This implementation handles low-precision (FP16, bfloat) values, but we have not thoroughly tested.
Recommended T5 finetuning settings (https://discuss.huggingface.co/t/t5-finetuning-tips/684/3):
Training without LR warmup or clip_threshold is not recommended.
- use scheduled LR warm-up to fixed LR
- use clip_threshold=1.0 (https://arxiv.org/abs/1804.04235)
Disable relative updates
Use scale_parameter=False
Additional optimizer operations like gradient clipping should not be used alongside Adafactor
Example:
Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)Others reported the following combination to work well:
Adafactor(model.parameters(), scale_parameter=True, relative_step=True, warmup_init=True, lr=None)When using lr=None with Trainer you will most likely need to use AdafactorSchedule
scheduler as following:
from transformers.optimization import Adafactor, AdafactorSchedule
optimizer = Adafactor(model.parameters(), scale_parameter=True, relative_step=True, warmup_init=True, lr=None)
lr_scheduler = AdafactorSchedule(optimizer)
trainer = Trainer(..., optimizers=(optimizer, lr_scheduler))Usage:
# replace AdamW with Adafactor
optimizer = Adafactor(
model.parameters(),
lr=1e-3,
eps=(1e-30, 1e-3),
clip_threshold=1.0,
decay_rate=-0.8,
beta1=None,
weight_decay=0.0,
relative_step=False,
scale_parameter=False,
warmup_init=False,
)step
< source >( closure = None )
Performs a single optimization step
AdamWeightDecay (TensorFlow)
class transformers.AdamWeightDecay
< source >( learning_rate: Union = 0.001 beta_1: float = 0.9 beta_2: float = 0.999 epsilon: float = 1e-07 amsgrad: bool = False weight_decay_rate: float = 0.0 include_in_weight_decay: Optional = None exclude_from_weight_decay: Optional = None name: str = 'AdamWeightDecay' **kwargs )
Parameters
- learning_rate (
Union[float, LearningRateSchedule], optional, defaults to 0.001) — The learning rate to use or a schedule. - beta_1 (
float, optional, defaults to 0.9) — The beta1 parameter in Adam, which is the exponential decay rate for the 1st momentum estimates. - beta_2 (
float, optional, defaults to 0.999) — The beta2 parameter in Adam, which is the exponential decay rate for the 2nd momentum estimates. - epsilon (
float, optional, defaults to 1e-07) — The epsilon parameter in Adam, which is a small constant for numerical stability. - amsgrad (
bool, optional, defaults toFalse) — Whether to apply AMSGrad variant of this algorithm or not, see On the Convergence of Adam and Beyond. - weight_decay_rate (
float, optional, defaults to 0.0) — The weight decay to apply. - include_in_weight_decay (
List[str], optional) — List of the parameter names (or re patterns) to apply weight decay to. If none is passed, weight decay is applied to all parameters by default (unless they are inexclude_from_weight_decay). - exclude_from_weight_decay (
List[str], optional) — List of the parameter names (or re patterns) to exclude from applying weight decay to. If ainclude_in_weight_decayis passed, the names in it will supersede this list. - name (
str, optional, defaults to"AdamWeightDecay") — Optional name for the operations created when applying gradients. - kwargs (
Dict[str, Any], optional) — Keyword arguments. Allowed to be {clipnorm,clipvalue,lr,decay}.clipnormis clip gradients by norm;clipvalueis clip gradients by value,decayis included for backward compatibility to allow time inverse decay of learning rate.lris included for backward compatibility, recommended to uselearning_rateinstead.
Adam enables L2 weight decay and clip_by_global_norm on gradients. Just adding the square of the weights to the loss function is not the correct way of using L2 regularization/weight decay with Adam, since that will interact with the m and v parameters in strange ways as shown in Decoupled Weight Decay Regularization.
Instead we want to decay the weights in a manner that doesn’t interact with the m/v parameters. This is equivalent to adding the square of the weights to the loss with plain (non-momentum) SGD.
Creates an optimizer from its config with WarmUp custom object.
transformers.create_optimizer
< source >( init_lr: float num_train_steps: int num_warmup_steps: int min_lr_ratio: float = 0.0 adam_beta1: float = 0.9 adam_beta2: float = 0.999 adam_epsilon: float = 1e-08 adam_clipnorm: Optional = None adam_global_clipnorm: Optional = None weight_decay_rate: float = 0.0 power: float = 1.0 include_in_weight_decay: Optional = None )
Parameters
- init_lr (
float) — The desired learning rate at the end of the warmup phase. - num_train_steps (
int) — The total number of training steps. - num_warmup_steps (
int) — The number of warmup steps. - min_lr_ratio (
float, optional, defaults to 0) — The final learning rate at the end of the linear decay will beinit_lr * min_lr_ratio. - adam_beta1 (
float, optional, defaults to 0.9) — The beta1 to use in Adam. - adam_beta2 (
float, optional, defaults to 0.999) — The beta2 to use in Adam. - adam_epsilon (
float, optional, defaults to 1e-8) — The epsilon to use in Adam. - adam_clipnorm (
float, optional, defaults toNone) — If notNone, clip the gradient norm for each weight tensor to this value. - adam_global_clipnorm (
float, optional, defaults toNone) — If notNone, clip gradient norm to this value. When using this argument, the norm is computed over all weight tensors, as if they were concatenated into a single vector. - weight_decay_rate (
float, optional, defaults to 0) — The weight decay to use. - power (
float, optional, defaults to 1.0) — The power to use for PolynomialDecay. - include_in_weight_decay (
List[str], optional) — List of the parameter names (or re patterns) to apply weight decay to. If none is passed, weight decay is applied to all parameters except bias and layer norm parameters.
Creates an optimizer with a learning rate schedule using a warmup phase followed by a linear decay.
Schedules
Learning Rate Schedules (Pytorch)
class transformers.SchedulerType
< source >( value names = None module = None qualname = None type = None start = 1 )
Scheduler names for the parameter lr_scheduler_type in TrainingArguments.
By default, it uses “linear”. Internally, this retrieves get_linear_schedule_with_warmup scheduler from Trainer.
Scheduler types:
- “linear” = get_linear_schedule_with_warmup
- “cosine” = get_cosine_schedule_with_warmup
- “cosine_with_restarts” = get_cosine_with_hard_restarts_schedule_with_warmup
- “polynomial” = get_polynomial_decay_schedule_with_warmup
- “constant” = get_constant_schedule
- “constant_with_warmup” = get_constant_schedule_with_warmup
- “inverse_sqrt” = get_inverse_sqrt_schedule
- “reduce_lr_on_plateau” = get_reduce_on_plateau_schedule
- “cosine_with_min_lr” = get_cosine_with_min_lr_schedule_with_warmup
- “warmup_stable_decay” = get_wsd_schedule
transformers.get_scheduler
< source >( name: Union optimizer: Optimizer num_warmup_steps: Optional = None num_training_steps: Optional = None scheduler_specific_kwargs: Optional = None )
Parameters
- name (
strorSchedulerType) — The name of the scheduler to use. - optimizer (
torch.optim.Optimizer) — The optimizer that will be used during training. - num_warmup_steps (
int, optional) — The number of warmup steps to do. This is not required by all schedulers (hence the argument being optional), the function will raise an error if it’s unset and the scheduler type requires it. - num_training_steps (`int“, optional) — The number of training steps to do. This is not required by all schedulers (hence the argument being optional), the function will raise an error if it’s unset and the scheduler type requires it.
- scheduler_specific_kwargs (
dict, optional) — Extra parameters for schedulers such as cosine with restarts. Mismatched scheduler types and scheduler parameters will cause the scheduler function to raise a TypeError.
Unified API to get any scheduler from its name.
transformers.get_constant_schedule
< source >( optimizer: Optimizer last_epoch: int = -1 )
Create a schedule with a constant learning rate, using the learning rate set in optimizer.
transformers.get_constant_schedule_with_warmup
< source >( optimizer: Optimizer num_warmup_steps: int last_epoch: int = -1 )
Create a schedule with a constant learning rate preceded by a warmup period during which the learning rate increases linearly between 0 and the initial lr set in the optimizer.
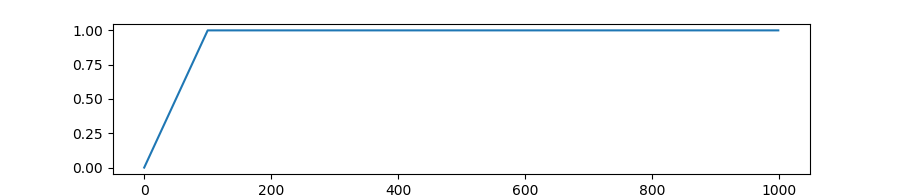
transformers.get_cosine_schedule_with_warmup
< source >( optimizer: Optimizer num_warmup_steps: int num_training_steps: int num_cycles: float = 0.5 last_epoch: int = -1 )
Parameters
- optimizer (
~torch.optim.Optimizer) — The optimizer for which to schedule the learning rate. - num_warmup_steps (
int) — The number of steps for the warmup phase. - num_training_steps (
int) — The total number of training steps. - num_cycles (
float, optional, defaults to 0.5) — The number of waves in the cosine schedule (the defaults is to just decrease from the max value to 0 following a half-cosine). - last_epoch (
int, optional, defaults to -1) — The index of the last epoch when resuming training.
Create a schedule with a learning rate that decreases following the values of the cosine function between the initial lr set in the optimizer to 0, after a warmup period during which it increases linearly between 0 and the initial lr set in the optimizer.
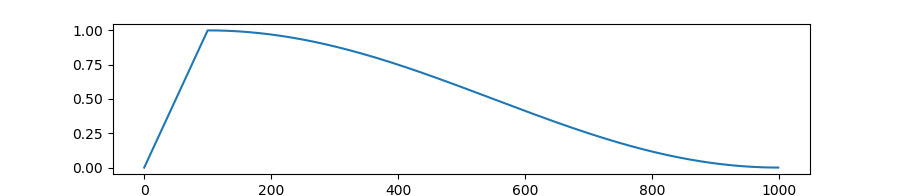
transformers.get_cosine_with_hard_restarts_schedule_with_warmup
< source >( optimizer: Optimizer num_warmup_steps: int num_training_steps: int num_cycles: int = 1 last_epoch: int = -1 )
Parameters
- optimizer (
~torch.optim.Optimizer) — The optimizer for which to schedule the learning rate. - num_warmup_steps (
int) — The number of steps for the warmup phase. - num_training_steps (
int) — The total number of training steps. - num_cycles (
int, optional, defaults to 1) — The number of hard restarts to use. - last_epoch (
int, optional, defaults to -1) — The index of the last epoch when resuming training.
Create a schedule with a learning rate that decreases following the values of the cosine function between the initial lr set in the optimizer to 0, with several hard restarts, after a warmup period during which it increases linearly between 0 and the initial lr set in the optimizer.
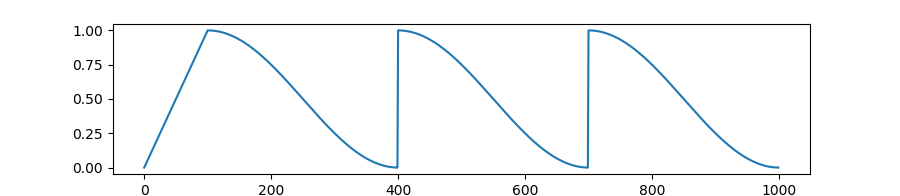
transformers.get_linear_schedule_with_warmup
< source >( optimizer num_warmup_steps num_training_steps last_epoch = -1 )
Parameters
- optimizer (
~torch.optim.Optimizer) — The optimizer for which to schedule the learning rate. - num_warmup_steps (
int) — The number of steps for the warmup phase. - num_training_steps (
int) — The total number of training steps. - last_epoch (
int, optional, defaults to -1) — The index of the last epoch when resuming training.
Create a schedule with a learning rate that decreases linearly from the initial lr set in the optimizer to 0, after a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.
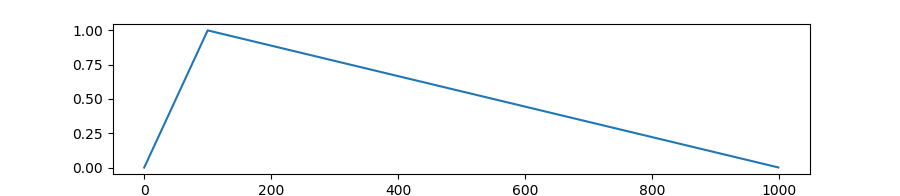
transformers.get_polynomial_decay_schedule_with_warmup
< source >( optimizer num_warmup_steps num_training_steps lr_end = 1e-07 power = 1.0 last_epoch = -1 )
Parameters
- optimizer (
~torch.optim.Optimizer) — The optimizer for which to schedule the learning rate. - num_warmup_steps (
int) — The number of steps for the warmup phase. - num_training_steps (
int) — The total number of training steps. - lr_end (
float, optional, defaults to 1e-7) — The end LR. - power (
float, optional, defaults to 1.0) — Power factor. - last_epoch (
int, optional, defaults to -1) — The index of the last epoch when resuming training.
Create a schedule with a learning rate that decreases as a polynomial decay from the initial lr set in the optimizer to end lr defined by lr_end, after a warmup period during which it increases linearly from 0 to the initial lr set in the optimizer.
Note: power defaults to 1.0 as in the fairseq implementation, which in turn is based on the original BERT implementation at https://github.com/google-research/bert/blob/f39e881b169b9d53bea03d2d341b31707a6c052b/optimization.py#L37
transformers.get_inverse_sqrt_schedule
< source >( optimizer: Optimizer num_warmup_steps: int timescale: int = None last_epoch: int = -1 )
Parameters
- optimizer (
~torch.optim.Optimizer) — The optimizer for which to schedule the learning rate. - num_warmup_steps (
int) — The number of steps for the warmup phase. - timescale (
int, optional, defaults tonum_warmup_steps) — Time scale. - last_epoch (
int, optional, defaults to -1) — The index of the last epoch when resuming training.
Create a schedule with an inverse square-root learning rate, from the initial lr set in the optimizer, after a warmup period which increases lr linearly from 0 to the initial lr set in the optimizer.
Warmup (TensorFlow)
class transformers.WarmUp
< source >( initial_learning_rate: float decay_schedule_fn: Callable warmup_steps: int power: float = 1.0 name: str = None )
Parameters
- initial_learning_rate (
float) — The initial learning rate for the schedule after the warmup (so this will be the learning rate at the end of the warmup). - decay_schedule_fn (
Callable) — The schedule function to apply after the warmup for the rest of training. - warmup_steps (
int) — The number of steps for the warmup part of training. - power (
float, optional, defaults to 1.0) — The power to use for the polynomial warmup (defaults is a linear warmup). - name (
str, optional) — Optional name prefix for the returned tensors during the schedule.
Applies a warmup schedule on a given learning rate decay schedule.
Gradient Strategies
GradientAccumulator (TensorFlow)
Gradient accumulation utility. When used with a distribution strategy, the accumulator should be called in a
replica context. Gradients will be accumulated locally on each replica and without synchronization. Users should
then call .gradients, scale the gradients if required, and pass the result to apply_gradients.
Resets the accumulated gradients on the current replica.