Transformers documentation
Pipelines para inferencia
Pipelines para inferencia
Un pipeline() simplifica el uso de cualquier modelo del Hub para la inferencia en una variedad de tareas como la generación de texto, la segmentación de imágenes y la clasificación de audio. Incluso si no tienes experiencia con una modalidad específica o no comprendes el código que alimenta los modelos, ¡aún puedes usarlos con el pipeline()! Este tutorial te enseñará a:
- Utilizar un
pipeline()para inferencia. - Utilizar un tokenizador o modelo específico.
- Utilizar un
pipeline()para tareas de audio y visión.
Echa un vistazo a la documentación de pipeline() para obtener una lista completa de tareas admitidas.
Uso del pipeline
Si bien cada tarea tiene un pipeline() asociado, es más sencillo usar la abstracción general pipeline() que contiene todos los pipelines de tareas específicas. El pipeline() carga automáticamente un modelo predeterminado y un tokenizador con capacidad de inferencia para tu tarea. Veamos el ejemplo de usar un pipeline() para reconocimiento automático del habla (ASR), o texto a voz.
- Comienza creando un
pipeline()y específica una tarea de inferencia:
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")- Pasa tu entrada a la
pipeline(). En el caso del reconocimiento del habla, esto es un archivo de entrada de audio:
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}¿No es el resultado que tenías en mente? Echa un vistazo a algunos de los modelos de reconocimiento automático del habla más descargados en el Hub para ver si puedes obtener una mejor transcripción.
Intentemos con el modelo Whisper large-v2 de OpenAI. Whisper se lanzó
2 años después que Wav2Vec2, y se entrenó con cerca de 10 veces más datos. Como tal, supera a Wav2Vec2 en la mayoría de las pruebas
downstream. También tiene el beneficio adicional de predecir puntuación y mayúsculas, ninguno de los cuales es posible con
Wav2Vec2.
Vamos a probarlo aquí para ver cómo se desempeña:
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}¡Ahora este resultado parece más preciso! Para una comparación detallada de Wav2Vec2 vs Whisper, consulta el Curso de Transformers de Audio. Realmente te animamos a que eches un vistazo al Hub para modelos en diferentes idiomas, modelos especializados en tu campo, y más. Puedes comparar directamente los resultados de los modelos desde tu navegador en el Hub para ver si se adapta o maneja casos de borde mejor que otros. Y si no encuentras un modelo para tu caso de uso, siempre puedes empezar a entrenar el tuyo propio.
Si tienes varias entradas, puedes pasar tu entrada como una lista:
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)Los pipelines son ideales para la experimentación, ya que cambiar de un modelo a otro es trivial; sin embargo, hay algunas formas de optimizarlas para cargas de trabajo más grandes que la experimentación. Consulta las siguientes guías que profundizan en iterar sobre conjuntos de datos completos o utilizar pipelines en un servidor web: de la documentación:
Parámetros
pipeline() admite muchos parámetros; algunos son específicos de la tarea y algunos son generales para todas las pipelines. En general, puedes especificar parámetros en cualquier lugar que desees:
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # This will use `my_parameter=1`.
out = transcriber(..., my_parameter=2) # This will override and use `my_parameter=2`.
out = transcriber(...) # This will go back to using `my_parameter=1`.Vamos a echar un vistazo a tres importantes:
Device
Si usas device=n, el pipeline automáticamente coloca el modelo en el dispositivo especificado. Esto funcionará independientemente de si estás utilizando PyTorch o Tensorflow.
transcriber = pipeline(model="openai/whisper-large-v2", device=0)Si el modelo es demasiado grande para una sola GPU y estás utilizando PyTorch, puedes establecer device_map="auto" para determinar automáticamente cómo cargar y almacenar los pesos del modelo. Utilizar el argumento device_map requiere el paquete 🤗 Accelerate:
pip install --upgrade accelerate
El siguiente código carga y almacena automáticamente los pesos del modelo en varios dispositivos:
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")Tenga en cuenta que si se pasa device_map="auto", no es necesario agregar el argumento device=device al instanciar tu pipeline, ¡ya que podrías encontrar algún comportamiento inesperado!
Batch size
Por defecto, los pipelines no realizarán inferencia por lotes por razones explicadas en detalle aquí. La razón es que la agrupación en lotes no es necesariamente más rápida y, de hecho, puede ser bastante más lenta en algunos casos.
Pero si funciona en tu caso de uso, puedes utilizar:
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)Esto ejecuta el pipeline en los 4 archivos de audio proporcionados, pero los pasará en lotes de a 2 al modelo (que está en una GPU, donde la agrupación en lotes es más probable que ayude) sin requerir ningún código adicional de tu parte. La salida siempre debería coincidir con lo que habrías recibido sin agrupación en lotes. Solo se pretende como una forma de ayudarte a obtener más velocidad de una pipeline.
Los pipelines también pueden aliviar algunas de las complejidades de la agrupación en lotes porque, para algunos pipelines, un solo elemento (como un archivo de audio largo) necesita ser dividido en varias partes para ser procesado por un modelo. El pipeline realiza esta agrupación en lotes de fragmentos por ti.
Task specific parameters
Todas las tareas proporcionan parámetros específicos de la tarea que permiten flexibilidad adicional y opciones para ayudarte a completar tu trabajo. Por ejemplo, el método transformers.AutomaticSpeechRecognitionPipeline.__call__() tiene un parámetro return_timestamps que suena prometedor para subtítulos de videos:
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}Como puedes ver, el modelo infirió el texto y también salió cuándo se pronunciaron las distintas oraciones.
Hay muchos parámetros disponibles para cada tarea, así que echa un vistazo a la referencia de la API de cada tarea para ver qué puedes ajustar. Por ejemplo, el AutomaticSpeechRecognitionPipeline tiene un parámetro chunk_length_s que es útil para trabajar con archivos de audio realmente largos (por ejemplo, subtítulos de películas completas o videos de una hora de duración) que un modelo típicamente no puede manejar solo:
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}¡Si no puedes encontrar un parámetro que te ayude, no dudes en solicitarlo!
Uso de pipelines en un conjunto de datos
Los pipeline también puede ejecutar inferencia en un conjunto de datos grande. La forma más fácil que recomendamos para hacer esto es utilizando un iterador:
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="openai-community/gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])El iterador data() produce cada resultado, y el pipeline automáticamente
reconoce que la entrada es iterable y comenzará a buscar los datos mientras
continúa procesándolos en la GPU (dicho proceso utiliza DataLoader). Esto es importante porque no tienes que asignar memoria para todo el conjunto de datos y puedes alimentar la GPU lo más rápido posible.
Dado que la agrupación en lotes podría acelerar las cosas, puede ser útil intentar ajustar el parámetro batch_size aquí.
La forma más sencilla de iterar sobre un conjunto de datos es cargandolo desde 🤗 Datasets:
# KeyDataset is a util that will just output the item we're interested in.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)Uso de pipelines para un servidor web
Pipeline de visión
Usar un pipeline() para tareas de visión es prácticamente idéntico.
Especifica tu tarea y pasa tu imagen al clasificador. La imagen puede ser un enlace, una ruta local o una imagen codificada en base64. Por ejemplo, ¿qué especie de gato se muestra a continuación?

>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]Pipeline de texto
Usar un pipeline() para tareas de PLN es prácticamente idéntico.
>>> from transformers import pipeline
>>> # This model is a `zero-shot-classification` model.
>>> # It will classify text, except you are free to choose any label you might imagine
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}Pipeline multimodal
pipeline() admite más de una modalidad. Por ejemplo, una tarea de respuesta a preguntas visuales (VQA) combina texto e imagen. No dudes en usar cualquier enlace de imagen que desees y una pregunta que quieras hacer sobre la imagen. La imagen puede ser una URL o una ruta local a la imagen.
Por ejemplo, si usas esta imagen de factura:
{kind=link}
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> output = vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
>>> output[0]["score"] = round(output[0]["score"], 3)
>>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]Para ejecutar el ejemplo anterior, debe tener instalado pytesseract además de 🤗 Transformers:
sudo apt install -y tesseract-ocr pip install pytesseract
Uso de pipeline en modelos grandes con 🤗 accelerate :
¡Puedes ejecutar fácilmente pipeline en modelos grandes utilizando 🤗 accelerate! Primero asegúrate de haber instalado accelerate con pip install accelerate.
¡Luego carga tu modelo utilizando device_map="auto"! Utilizaremos facebook/opt-1.3b para nuestro ejemplo.
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)También puedes pasar modelos cargados de 8 bits sí instalas bitsandbytes y agregas el argumento load_in_8bit=True
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)Nota que puedes reemplazar el punto de control con cualquier modelo de Hugging Face que admita la carga de modelos grandes, como BLOOM.
Crear demos web desde pipelines con gradio
Los pipelines están automáticamente soportadas en Gradio, una biblioteca que hace que crear aplicaciones de aprendizaje automático hermosas y fáciles de usar en la web sea un proceso sencillo. Primero, asegúrate de tener Gradio instalado:
pip install gradioLuego, puedes crear una demo web alrededor de una pipeline de clasificación de imágenes (o cualquier otra pipeline) en una sola línea de código llamando a la función Interface.from_pipeline de Gradio para lanzar la pipeline. Esto crea una interfaz intuitiva drag-and-drop en tu navegador:
from transformers import pipeline
import gradio as gr
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
gr.Interface.from_pipeline(pipe).launch()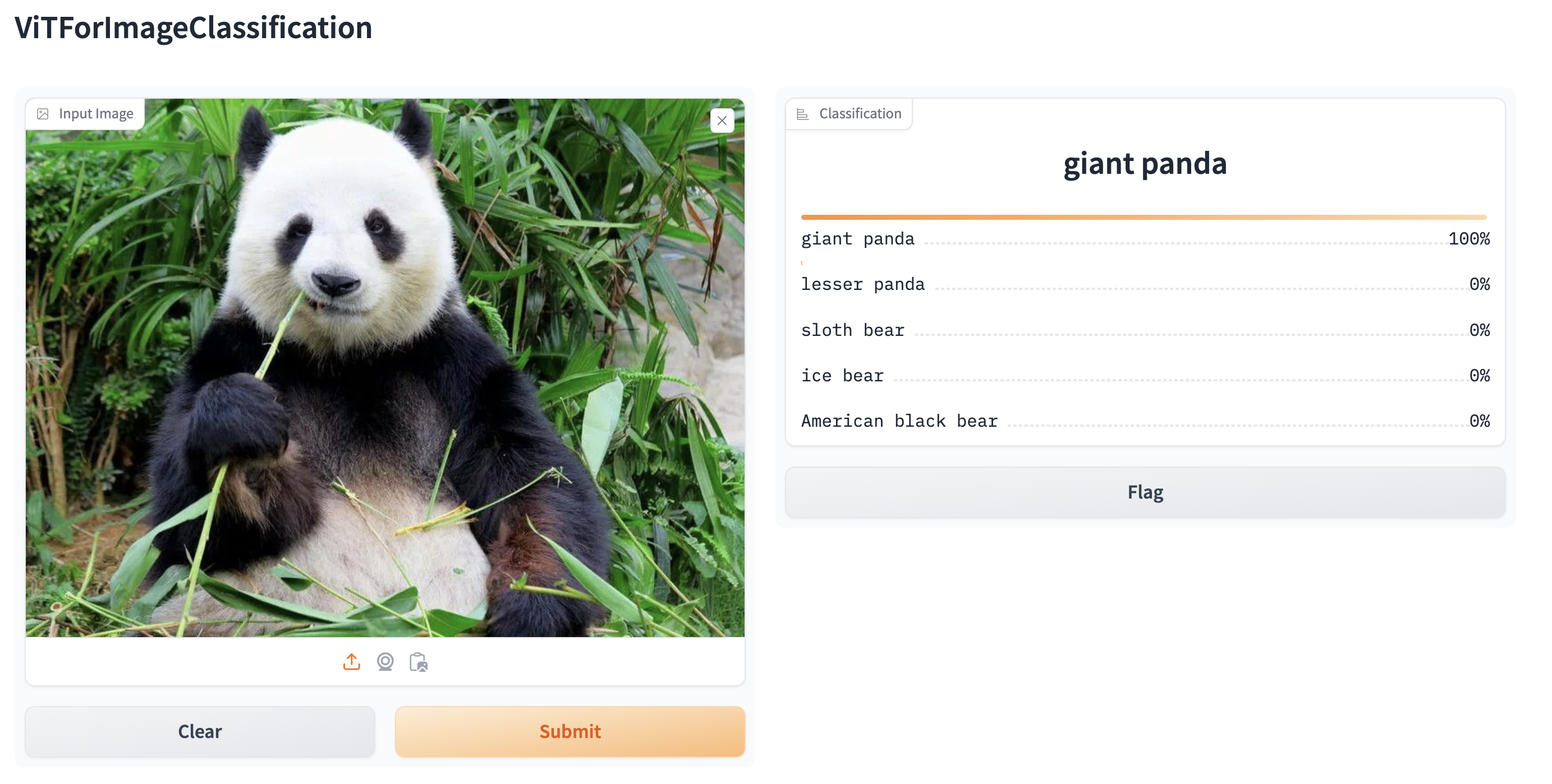
De forma predeterminada, la demo web se ejecuta en un servidor local. Si deseas compartirlo con otros, puedes generar un enlace público temporal estableciendo share=True en launch(). También puedes hospedar tu demo en Hugging Face Spaces para un enlace permanente.