MGP-STR
Overview
The MGP-STR model was proposed in Multi-Granularity Prediction for Scene Text Recognition by Peng Wang, Cheng Da, and Cong Yao. MGP-STR is a conceptually simple yet powerful vision Scene Text Recognition (STR) model, which is built upon the Vision Transformer (ViT). To integrate linguistic knowledge, Multi-Granularity Prediction (MGP) strategy is proposed to inject information from the language modality into the model in an implicit way.
The abstract from the paper is the following:
Scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this challenging problem, numerous innovative methods have been successively proposed and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet powerful vision STR model, which is built upon ViT and outperforms previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, i.e. , subword representations (BPE and WordPiece) widely-used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. The resultant algorithm (termed MGP-STR) is able to push the performance envelop of STR to an even higher level. Specifically, it achieves an average recognition accuracy of 93.35% on standard benchmarks.
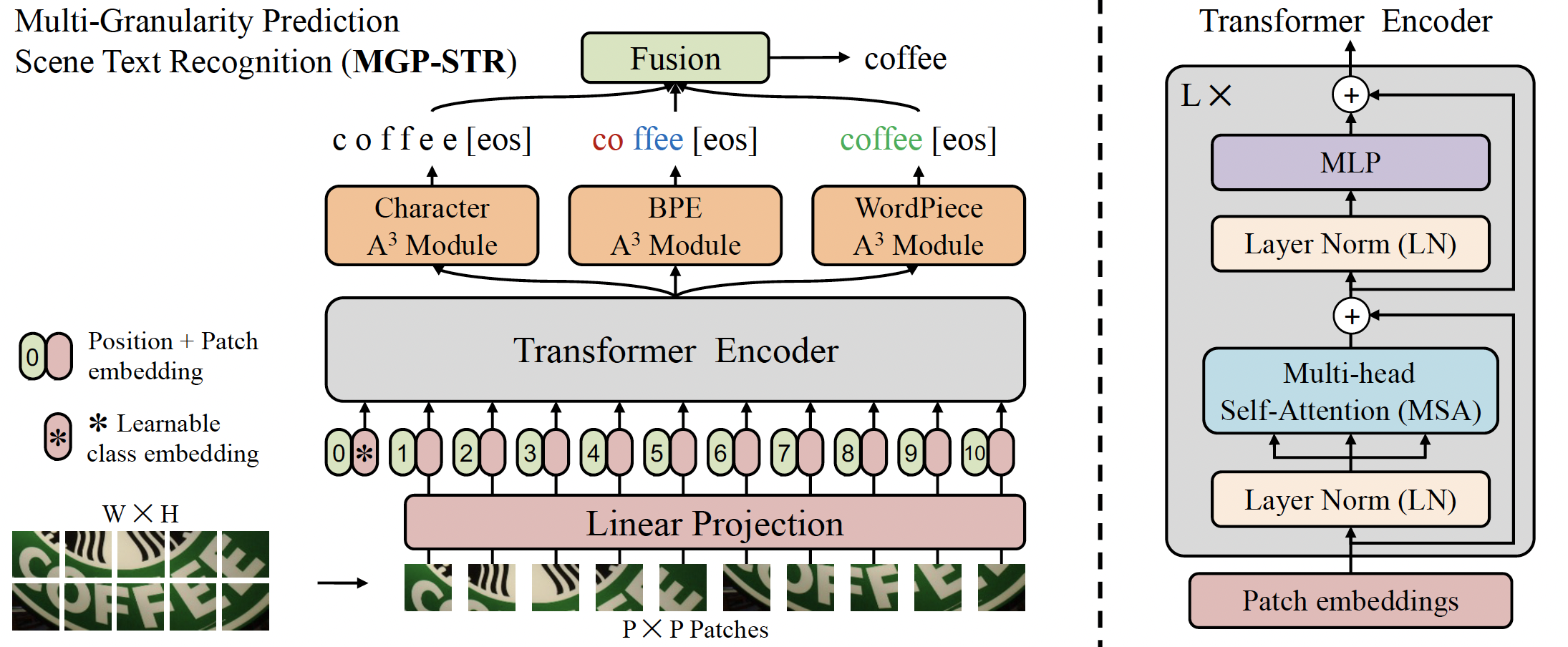 MGP-STR architecture. Taken from the original paper.
MGP-STR architecture. Taken from the original paper. MGP-STR is trained on two synthetic datasets MJSynth (MJ) and SynthText (ST) without fine-tuning on other datasets. It achieves state-of-the-art results on six standard Latin scene text benchmarks, including 3 regular text datasets (IC13, SVT, IIIT) and 3 irregular ones (IC15, SVTP, CUTE). This model was contributed by yuekun. The original code can be found here.
Inference example
MgpstrModel accepts images as input and generates three types of predictions, which represent textual information at different granularities. The three types of predictions are fused to give the final prediction result.
The ViTImageProcessor class is responsible for preprocessing the input image and MgpstrTokenizer decodes the generated character tokens to the target string. The MgpstrProcessor wraps ViTImageProcessor and MgpstrTokenizer into a single instance to both extract the input features and decode the predicted token ids.
- Step-by-step Optical Character Recognition (OCR)
>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
>>> import requests
>>> from PIL import Image
>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(pixel_values)
>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']MgpstrConfig
class transformers.MgpstrConfig
< source >( image_size = [32, 128] patch_size = 4 num_channels = 3 max_token_length = 27 num_character_labels = 38 num_bpe_labels = 50257 num_wordpiece_labels = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 mlp_ratio = 4.0 qkv_bias = True distilled = False layer_norm_eps = 1e-05 drop_rate = 0.0 attn_drop_rate = 0.0 drop_path_rate = 0.0 output_a3_attentions = False initializer_range = 0.02 **kwargs )
Parameters
- image_size (
List[int], optional, defaults to[32, 128]) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 4) — The size (resolution) of each patch. - num_channels (
int, optional, defaults to 3) — The number of input channels. - max_token_length (
int, optional, defaults to 27) — The max number of output tokens. - num_character_labels (
int, optional, defaults to 38) — The number of classes for character head . - num_bpe_labels (
int, optional, defaults to 50257) — The number of classes for bpe head . - num_wordpiece_labels (
int, optional, defaults to 30522) — The number of classes for wordpiece head . - hidden_size (
int, optional, defaults to 768) — The embedding dimension. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - mlp_ratio (
float, optional, defaults to 4.0) — The ratio of mlp hidden dim to embedding dim. - qkv_bias (
bool, optional, defaults toTrue) — Whether to add a bias to the queries, keys and values. - distilled (
bool, optional, defaults toFalse) — Model includes a distillation token and head as in DeiT models. - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - drop_rate (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder. - attn_drop_rate (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - drop_path_rate (
float, optional, defaults to 0.0) — The stochastic depth rate. - output_a3_attentions (
bool, optional, defaults toFalse) — Whether or not the model should returns A^3 module attentions. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
This is the configuration class to store the configuration of an MgpstrModel. It is used to instantiate an MGP-STR model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the MGP-STR alibaba-damo/mgp-str-base architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import MgpstrConfig, MgpstrForSceneTextRecognition
>>> # Initializing a Mgpstr mgp-str-base style configuration
>>> configuration = MgpstrConfig()
>>> # Initializing a model (with random weights) from the mgp-str-base style configuration
>>> model = MgpstrForSceneTextRecognition(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configMgpstrTokenizer
class transformers.MgpstrTokenizer
< source >( vocab_file unk_token = '[GO]' bos_token = '[GO]' eos_token = '[s]' pad_token = '[GO]' **kwargs )
Parameters
- vocab_file (
str) — Path to the vocabulary file. - unk_token (
str, optional, defaults to"[GO]") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - bos_token (
str, optional, defaults to"[GO]") — The beginning of sequence token. - eos_token (
str, optional, defaults to"[s]") — The end of sequence token. - pad_token (
strortokenizers.AddedToken, optional, defaults to"[GO]") — A special token used to make arrays of tokens the same size for batching purpose. Will then be ignored by attention mechanisms or loss computation.
Construct a MGP-STR char tokenizer.
This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
MgpstrProcessor
class transformers.MgpstrProcessor
< source >( image_processor = None tokenizer = None **kwargs )
Parameters
- image_processor (
ViTImageProcessor, optional) — An instance ofViTImageProcessor. The image processor is a required input. - tokenizer (MgpstrTokenizer, optional) — The tokenizer is a required input.
Constructs a MGP-STR processor which wraps an image processor and MGP-STR tokenizers into a single
MgpstrProcessor offers all the functionalities of ViTImageProcessor] and MgpstrTokenizer. See the
call() and batch_decode() for more information.
When used in normal mode, this method forwards all its arguments to ViTImageProcessor’s
call() and returns its output. This method also forwards the text and kwargs
arguments to MgpstrTokenizer’s call() if text is not None to encode the text. Please
refer to the doctsring of the above methods for more information.
batch_decode
< source >( sequences ) → Dict[str, any]
Parameters
Returns
Dict[str, any]
Dictionary of all the outputs of the decoded results.
generated_text (List[str]): The final results after fusion of char, bpe, and wp. scores
(List[float]): The final scores after fusion of char, bpe, and wp. char_preds (List[str]): The list
of character decoded sentences. bpe_preds (List[str]): The list of bpe decoded sentences. wp_preds
(List[str]): The list of wp decoded sentences.
Convert a list of lists of token ids into a list of strings by calling decode.
This method forwards all its arguments to PreTrainedTokenizer’s batch_decode(). Please refer to the docstring of this method for more information.
MgpstrModel
class transformers.MgpstrModel
< source >( config: MgpstrConfig )
Parameters
- config (MgpstrConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare MGP-STR Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViTImageProcessor.call() for details. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The MgpstrModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
MgpstrForSceneTextRecognition
class transformers.MgpstrForSceneTextRecognition
< source >( config: MgpstrConfig )
Parameters
- config (MgpstrConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
MGP-STR Model transformer with three classification heads on top (three A^3 modules and three linear layer on top of the transformer encoder output) for scene text recognition (STR) .
This model is a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor output_attentions: Optional = None output_a3_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViTImageProcessor.call() for details. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - output_a3_attentions (
bool, optional) — Whether or not to return the attentions tensors of a3 modules. Seea3_attentionsunder returned tensors for more detail.
Returns
transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput or tuple(torch.FloatTensor)
A transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.mgp_str.configuration_mgp_str.MgpstrConfig'>) and inputs.
-
logits (
tuple(torch.FloatTensor)of shape(batch_size, config.num_character_labels)) — Tuple oftorch.FloatTensor(one for the output of character of shape(batch_size, config.max_token_length, config.num_character_labels), + one for the output of bpe of shape(batch_size, config.max_token_length, config.num_bpe_labels), + one for the output of wordpiece of shape(batch_size, config.max_token_length, config.num_wordpiece_labels)) .Classification scores (before SoftMax) of character, bpe and wordpiece.
-
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, config.max_token_length, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
a3_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_a3_attentions=Trueis passed or whenconfig.output_a3_attentions=True) — Tuple oftorch.FloatTensor(one for the attention of character, + one for the attention of bpe, + one for the attention of wordpiece) of shape(batch_size, config.max_token_length, sequence_length)`.Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The MgpstrForSceneTextRecognition forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import (
... MgpstrProcessor,
... MgpstrForSceneTextRecognition,
... )
>>> import requests
>>> from PIL import Image
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> processor = MgpstrProcessor.from_pretrained("alibaba-damo/mgp-str-base")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> model = MgpstrForSceneTextRecognition.from_pretrained("alibaba-damo/mgp-str-base")
>>> # inference
>>> outputs = model(pixel_values)
>>> out_strs = processor.batch_decode(outputs.logits)
>>> out_strs["generated_text"]
'["ticket"]'