Transformers documentation
대규모 언어 모델의 속도 및 메모리 최적화
대규모 언어 모델의 속도 및 메모리 최적화
GPT3/4, Falcon, Llama와 같은 대규모 언어 모델의 인간 중심 과제를 해결하는 능력이 빠르게 발전하고 있으며, 현대 지식 기반 산업에서 필수 도구로 자리잡고 있습니다. 그러나 이러한 모델을 실제 과제에 배포하는 것은 여전히 어려운 과제입니다.
- 인간과 비슷한 텍스트 이해 및 생성 능력을 보이기 위해, 현재 대규모 언어 모델은 수십억 개의 매개변수로 구성되어야 합니다 (참조: Kaplan et al, Wei et. al). 이는 추론을 위한 메모리 요구를 크게 증가시킵니다.
- 많은 실제 과제에서 대규모 언어 모델은 방대한 맥락 정보를 제공받아야 합니다. 이는 모델이 추론 과정에서 매우 긴 입력 시퀀스를 처리할 수 있어야 한다는 것을 뜻합니다.
이러한 과제의 핵심은 대규모 언어 모델의 계산 및 메모리 활용 능력을 증대시키는 데 있습니다. 특히 방대한 입력 시퀀스를 처리할 때 이러한 능력이 중요합니다.
이 가이드에서는 효율적인 대규모 언어 모델 배포를 위한 효과적인 기법들을 살펴보겠습니다.
낮은 정밀도: 연구에 따르면, 8비트와 4비트와 같이 낮은 수치 정밀도로 작동하면 모델 성능의 큰 저하 없이 계산상의 이점을 얻을 수 있습니다.
플래시 어텐션: 플래시 어텐션은 메모리 효율성을 높일 뿐만 아니라 최적화된 GPU 메모리 활용을 통해 효율성을 향상시키는 어텐션 알고리즘의 변형입니다.
아키텍처 혁신: 추론 시 대규모 언어 모델은 주로 동일한 방식(긴 입력 맥락을 가진 자기회귀 텍스트 생성 방식)으로 배포되는데, 더 효율적인 추론을 가능하게 하는 특화된 모델 아키텍처가 제안되었습니다. 이러한 모델 아키텍처의 가장 중요한 발전으로는 Alibi, Rotary embeddings, Multi-Query Attention (MQA), Grouped-Query-Attention (GQA)이 있습니다.
이 가이드에서는 텐서의 관점에서 자기회귀 생성에 대한 분석을 제공합니다. 낮은 정밀도를 채택하는 것의 장단점을 논의하고, 최신 어텐션 알고리즘을 포괄적으로 탐구하며, 향상된 대규모 언어 모델 아키텍처에 대해 논합니다. 이 과정에서 각 기능의 개선 사항을 보여주는 실용적인 예제를 확인합니다.
1. 낮은 정밀도
대규모 언어 모델을 가중치 행렬과 벡터의 집합으로 보고, 텍스트 입력을 벡터의 시퀀스로 본다면, 대규모 언어 모델의 메모리 요구사항을 가장 잘 이해할 수 있습니다. 이어지는 내용에서 가중치는 모델의 모든 가중치 행렬과 벡터를 의미합니다.
이 가이드를 작성하는 시점의 대규모 언어 모델은 최소 몇십억 개의 매개변수로 구성되어 있습니다. 각 매개변수는 4.5689와 같은 십진수로 이루어져 있으며, 보통 float32, bfloat16 또는 float16 형식으로 저장됩니다. 이를 통해 대규모 언어 모델을 메모리에 로드하는 데 필요한 메모리의 요구사항을 쉽게 계산할 수 있습니다:
X 10억 개의 매개변수를 가진 모델의 가중치를 로드하려면 float32 정밀도에서 대략 4 X GB의 VRAM이 필요합니다.
요즘에는 모델이 float32 정밀도로 훈련되는 경우는 드물고, 일반적으로 bfloat16 정밀도나 가끔 float16 정밀도로 훈련됩니다. 따라서 경험적으로 알아낸 법칙은 다음과 같습니다:
X 10억 개의 매개변수를 가진 모델의 가중치를 로드하려면 bfloat16/float16 정밀도에서 대략 2 X GB의 VRAM이 필요합니다.
짧은 텍스트 입력(1024 토큰 미만)의 경우, 추론을 위한 메모리 요구 사항의 대부분은 가중치를 로드하는 데 필요한 메모리 요구 사항입니다. 따라서 지금은 추론을 위한 메모리 요구 사항이 모델의 가중치를 GPU VRAM에 로드하는 데 필요한 메모리 요구 사항과 같다고 가정합시다.
모델을 bfloat16으로 로드하는 데 대략 얼마나 많은 VRAM이 필요한지 몇 가지 예를 들어보겠습니다:
- GPT3는 2 * 175 GB = 350 GB VRAM이 필요합니다.
- Bloom은 2 * 176 GB = 352 GB VRAM이 필요합니다.
- Llama-2-70b는 2 * 70 GB = 140 GB VRAM이 필요합니다.
- Falcon-40b는 2 * 40 GB = 80 GB VRAM이 필요합니다.
- MPT-30b는 2 * 30 GB = 60 GB VRAM이 필요합니다.
- bigcode/starcoder는 2 * 15.5 GB = 31 GB VRAM이 필요합니다.
이 문서를 작성하는 시점에서, 현재 시장에서 가장 큰 GPU 칩은 80GB의 VRAM을 제공하는 A100과 H100입니다. 앞서 언급된 대부분의 모델들은 로드하기 위해서는 최소 80GB 이상의 용량을 필요로 하며, 따라서 텐서 병렬 처리 및/또는 파이프라인 병렬 처리를 반드시 필요로 합니다.
🤗 Transformers는 텐서 병렬 처리를 바로 지원하지 않습니다. 이는 모델 아키텍처가 특정 방식으로 작성되어야 하기 때문입니다. 텐서 병렬 처리를 지원하는 방식으로 모델을 작성하는 데 관심이 있다면 the text-generation-inference library를 참조해 보시기 바랍니다.
기본적인 파이프라인 병렬 처리는 바로 지원됩니다. 이를 위해 단순히 모델을 device="auto"로 로드하면 여기에 설명된 대로 사용 가능한 GPU에 모델의 서로 다른 레이어를 자동으로 배치합니다. 이것은 매우 효과적이긴 하지만 이러한 기본 파이프라인 병렬 처리는 GPU 유휴 문제를 해결하지 못한다는 점을 유의해야 합니다. 더 발전된 파이프라인 병렬 처리가 필요하며, 이에 대한 설명은 여기에서 확인할 수 있습니다.
80GB A100 GPU 8개를 가진 노드에 접근할 수 있다면, BLOOM을 다음과 같이 로드할 수 있습니다.
!pip install transformers accelerate bitsandbytes optimum
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("bigscience/bloom", device_map="auto", pad_token_id=0)device_map="auto"를 사용하면 모든 사용 가능한 GPU에 어텐션 레이어가 고르게 분산됩니다.
이 가이드에서는 bigcode/octocoder를 사용할 것입니다. 이 모델은 단일 40GB A100 GPU 장치에서 실행할 수 있습니다. 앞으로 적용할 모든 메모리 및 속도 최적화는 모델 또는 텐서 병렬 처리를 필요로 하는 다른 모델에도 동일하게 적용될 수 있습니다.
모델이 bfloat16 정밀도로 로드되기 때문에, 위의 경험적으로 알아낸 법칙을 사용하면 bigcode/octocoder를 사용하여 추론을 실행하기 위한 메모리 요구 사항이 약 31GB VRAM일 것으로 예상됩니다. 한 번 시도해 보겠습니다.
먼저 모델과 토크나이저를 로드한 다음, 둘 다 Transformers의 파이프라인 객체에 전달합니다.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto", pad_token_id=0)
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)prompt = "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer:"
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result출력:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single좋습니다. 이제 결과를 직접 사용하여 바이트를 기가바이트로 변환할 수 있습니다.
def bytes_to_giga_bytes(bytes):
return bytes / 1024 / 1024 / 1024torch.cuda.max_memory_allocated를 호출하여 최대 GPU 메모리 할당을 측정해 보겠습니다.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
출력:
29.0260648727417
대략적으로 계산한 결과와 거의 일치합니다! 바이트에서 킬로바이트로 변환할 때 1000이 아닌 1024로 곱해야 하므로 숫자가 정확하지 않은 것을 알 수 있습니다. 따라서 대략적으로 계산할 때 공식은 “최대 X GB”으로 이해할 수 있습니다. 만약 우리가 모델을 float32 정밀도로 실행하려고 했다면 더 큰 크기인 64GB의 VRAM이 필요했을 것입니다.
거의 모든 모델이 요즘 bfloat16으로 학습되므로, GPU가 bfloat16을 지원한다면 모델을 float32 정밀도로 실행할 이유가 없습니다. float32로 돌리는 모델은 학습할 때 사용했던 정밀도보다 더 나은 추론 결과를 제공하지 않습니다.
모델 가중치가 어떤 정밀도 형식으로 Hub에 저장되어 있는지 확실하지 않은 경우, HuggingFace Hub에서 해당 체크포인트 config의 "torch_dtype"을 확인하면 됩니다, 예를 들어 여기를 확인하세요. 모델을 from_pretrained(..., torch_dtype=...)로 로드할 때는 config에 명시된 정밀도 유형과 동일한 정밀도로 설정하는 것이 권장됩니다. 단, 원래 유형이 float32인 경우 추론을 위해 float16 또는 bfloat16을 둘 다 사용할 수 있습니다.
이제 flush(...) 함수를 정의하여 모든 메모리를 해제하고, GPU 메모리의 최대 할당량을 정확하게 측정하도록 합시다.
del pipe
del model
import gc
import torch
def flush():
gc.collect()
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()다음 실험을 위해 바로 호출해 봅시다.
flush()
최근 버전의 accelerate 라이브러리에서는 release_memory()라는 유틸리티 메소드도 사용할 수 있습니다.
from accelerate.utils import release_memory
# ...
release_memory(model)만약 GPU에 32GB의 VRAM이 없다면 어떻게 될까요? 모델 가중치를 성능에 큰 손실 없이 8비트 또는 4비트로 양자화할 수 있다는 것이 밝혀졌습니다(참고: Dettmers et al.). 최근의 GPTQ 논문 에서는 모델을 3비트 또는 2비트로 양자화해도 성능 손실이 허용 가능한 수준임을 보여주었습니다🤯.
너무 자세한 내용은 다루지 않고 설명하자면, 양자화는 가중치의 정밀도를 줄이면서 모델의 추론 결과를 가능한 한 정확하게(즉, bfloat16과 최대한 가깝게) 유지하려고 합니다. 양자화는 특히 텍스트 생성에 잘 작동하는데, 이는 우리가 가장 가능성 있는 다음 토큰 집합을 선택하는 것에 초점을 두고 있기 때문이며, 다음 토큰의 logit 분포값을 정확하게 예측할 필요는 없기 때문입니다. 핵심은 다음 토큰 logit 분포가 대략적으로 동일하게 유지되어 argmax 또는 topk 연산이 동일한 결과를 제공하는 것입니다.
다양한 양자화 기법이 존재하지만, 자세히 다루지는 않을 것입니다. 일반적으로 모든 양자화 기법은 다음과 같이 작동합니다:
- 모든 가중치를 목표 정밀도로 양자화합니다.
- 양자화된 가중치를 로드하고, bfloat16 정밀도의 입력 벡터 시퀀스를 모델에 전달합니다.
- 가중치를 동적으로 bfloat16으로 반대로 양자화(dequantize)하여 입력 벡터와 함께 bfloat16 정밀도로 계산을 수행합니다.
간단히 말해서, 입력-가중치 행렬 곱셈은,가 입력,가 가중치 행렬,가 출력인 경우 다음과 같습니다:
위 공식이 다음과 같이 변경됩니다
모든 행렬 곱셈에 대해 위와 같이 수행됩니다. 입력이 네트워크 그래프를 통과하면서 모든 가중치 행렬에 대해 역양자화(dequantization)와 재양자화(re-quantization)가 순차적으로 수행됩니다.
따라서, 양자화된 가중치를 사용할 때 추론 시간이 감소하지 않고 오히려 증가하는 경우가 많습니다. 이제 이론은 충분하니 실제로 시도해 봅시다! Transformers를 사용하여 가중치를 양자화하려면 bitsandbytes 라이브러리가 설치되어 있는지 확인해야 합니다.
!pip install bitsandbytes
그런 다음 from_pretrained에 load_in_8bit=True 플래그를 추가하여 8비트 양자화로 모델을 로드할 수 있습니다.
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_8bit=True, pad_token_id=0)이제 예제를 다시 실행하고 메모리 사용량을 측정해 봅시다.
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result출력:
Here is a Python function that transforms bytes to Giga bytes:\n\n```python\ndef bytes_to_giga_bytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single좋습니다. 정확도 손실 없이 이전과 동일한 결과를 얻고 있습니다! 이번에는 사용된 메모리 양을 확인해 봅시다.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
출력:
15.219234466552734훨씬 적네요! 메모리 사용량이 15GB를 조금 넘는 수준으로 줄어들어 4090과 같은 소비자용 GPU에서도 이 모델을 실행할 수 있습니다. 메모리 효율성에서 매우 큰 향상을 보이고 있으며 모델 출력의 품질 저하도 거의 없습니다. 그러나 추론 중에 약간의 속도 저하가 발생한 것을 확인할 수 있습니다.
모델을 삭제하고 메모리를 다시 초기화합니다.
del model
del pipeflush()
이제 4비트 양자화가 제공하는 최대 GPU 메모리 사용량을 확인해 봅시다. 4비트로 모델을 양자화하려면 이전과 동일한 API를 사용하되 이번에는 load_in_8bit=True 대신 load_in_4bit=True를 전달하면 됩니다.
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", load_in_4bit=True, low_cpu_mem_usage=True, pad_token_id=0)
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
result = pipe(prompt, max_new_tokens=60)[0]["generated_text"][len(prompt):]
result출력:
Here is a Python function that transforms bytes to Giga bytes:\n\n```\ndef bytes_to_gigabytes(bytes):\n return bytes / 1024 / 1024 / 1024\n```\n\nThis function takes a single argument바로 전 코드 스니펫에서 python만 누락되고, 이 전과 거의 동일한 출력 텍스트를 보고 있습니다. 이제 얼마나 많은 메모리가 필요했는지 확인해 봅시다.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
출력:
9.5435743331909189.5GB밖에 되지 않습니다! 150억 개 이상의 파라미터를 가진 모델인 것을 감안하면 매우 적은 양입니다.
여기서는 모델의 정확도 저하가 거의 없음을 확인할 수 있지만, 실제로는 4비트 양자화를 8비트 양자화나 bfloat16를 사용한 추론 결과와 비교하면 결과가 다를 수 있습니다. 사용자가 직접 시도해 보는 것이 좋겠습니다.
또한 4비트 양자화에 사용된 더 공격적인 양자화 방법으로 인해 추론 시와 과정이 더 오래 걸리므로 여기서도 8비트 양자화와 비교하여 추론 속도가 약간 느려졌음을 유의하세요.
del model
del pipeflush()
전체적으로 OctoCoder를 8비트 정밀도로 실행하면 필요한 GPU VRAM이 32GB에서 15GB로 줄어들었고, 4비트 정밀도로 모델을 실행하면 필요한 GPU VRAM이 9GB로 더 줄어드는 것을 확인했습니다.
4비트 양자화는 RTX3090, V100, T4와 같은 GPU에서 모델을 실행할 수 있게 해주며, 이는 대부분의 사람들이 접근할 수 있는 GPU입니다.
양자화에 대한 더 많은 정보를 확인하고 4비트보다 더 적은 GPU VRAM 메모리로 모델을 양자화하거나, 더 많은 양자화 관련 정보를 보려면 AutoGPTQ 구현을 참조하는 것을 추천합니다.
결론적으로, 모델 양자화는 향상된 메모리 효율성과 모델 정확성 간의 균형을 맞추는 것이며, 경우에 따라 추론 시간에도 영향을 미칠 수 있습니다.
실제 사례에서 GPU 메모리가 충분하다면, 양자화를 고려할 필요가 없습니다. 그러나 많은 GPU는 양자화 없이 대규모 언어 모델을 실행할 수 없으며, 이 경우 4비트 및 8비트 양자화가 매우 유용한 도구입니다.
사용과 관련한 더 자세한 정보는 트랜스포머 양자화 문서를 참고하는 것을 강력히 추천합니다. 다음으로, 더 나은 알고리즘과 개선된 모델 아키텍처를 사용하여 계산 및 메모리 효율성을 향상시키는 방법을 살펴보겠습니다.
2. 플래시 어텐션
오늘날의 최고 성능을 자랑하는 대규모 언어 모델은 대체로 피드포워드 레이어(feed-forward layer), 활성화 레이어(activation layer), 레이어 정규화 레이어(layer normalization layer), 그리고 가장 중요한 셀프 어텐션 레이어(self-attention layer)로 구성된 아키텍처를 공유하고 있습니다.
셀프 어텐션 레이어는 입력 토큰 간의 문맥적 관계를 이해할 수 있게 해 주기 때문에 대규모 언어 모델의 핵심 요소입니다. 하지만 셀프 어텐션 레이어의 최대 GPU 메모리 소비는 입력 토큰의 수(이하으로 표기)와 함께 계산 및 메모리 복잡성이 2차적으로 증가합니다. 입력 시퀀스가 짧은 경우(최대 1000개)에는 크게 눈에 띄지 않지만, 더 긴 입력 시퀀스(약 16000개)에서는 심각한 문제가 됩니다.
자세히 한 번 들여다 봅시다. 길이의 입력에 대한 셀프 어텐션 레이어의 출력을 계산하는 공식은 다음과 같습니다: 는 어텐션 레이어의 입력 시퀀스입니다. 프로젝션와는 각각개의 벡터로 구성되며, 그 결과의 크기는가 됩니다.
대규모 언어 모델은 일반적으로 여러 개의 어텐션 헤드를 가지고 있어 여러 개의 셀프 어텐션 계산을 병렬로 수행합니다. 대규모 언어 모델이 40개의 어텐션 헤드를 가지고 bfloat16 정밀도로 실행된다고 가정하면, 행렬을 저장하는 데 필요한 메모리를 바이트로 계산할 수 있습니다.일 때는 약 50MB의 VRAM만 필요하지만,일 때는 19GB의 VRAM이 필요하며,일 때는 행렬을 저장하기 위해 거의 1TB의 VRAM이 필요합니다.
요약하자면, 기본 셀프 어텐션 알고리즘은 큰 입력 컨텍스트에 대해 매우 과도한 메모리 사용을 요구하게 됩니다.
대규모 언어 모델의 텍스트 이해 및 생성 능력이 개선되면서 점점 더 복잡한 작업에 사용되고 있습니다. 한때 몇 문장의 번역이나 요약을 처리하던 모델이 이제는 전체 페이지를 처리해야 하게 되면서 광범위한 입력 길이를 처리할 수 있는 능력이 요구되고 있습니다.
어떻게 하면 큰 입력 길이에 대한 과도한 메모리 요구를 없앨 수 있을까요? 행렬을 제거하는 새로운 셀프 어텐션 메커니즘을 계산하는 방법이 필요합니다. Tri Dao et al.은 바로 이러한 새로운 알고리즘을 개발하였고, 그것이 플래시 어텐션(Flash Attention)입니다.
간단히 말해, 플래시 어텐션은) 계산을 분할하는데, 여러 번의 소프트맥스 계산을 반복하면서 작은 청크 단위로 출력을 계산합니다:
여기서와는 각와에 대해 계산되는 소프트맥스 정규화 통계량입니다.
플래시 어텐션의 전체 알고리즘은 더 복잡하며, 본 가이드의 범위를 벗어나기 때문에 크게 단순화하였습니다. 여러분은 잘 작성된 Flash Attention paper 논문을 참조하여 더 자세한 내용을 확인해 보시기 바랍니다.
주요 요점은 다음과 같습니다:
소프트맥스 정규화 통계량과 몇 가지 스마트한 수학적 방법을 사용함으로써, 플래시 어텐션은 기본 셀프 어텐션 레이어와 숫자적으로 동일한 출력을 제공하고 메모리 비용은에 따라 선형적으로만 증가합니다.
공식을 보면, 플래시 어텐션이 더 많은 계산을 필요로 하기 때문에 기본 셀프 어텐션 공식보다 훨씬 느릴 것이라고 생각할 수 있습니다. 실제로 플래시 어텐션은 소프트맥스 정규화 통계량을 지속적으로 다시 계산해야 하기 때문에 일반 어텐션보다 더 많은 FLOP이 필요합니다. (더 자세한 내용은 논문을 참조하세요)
그러나 플래시 어텐션은 기본 어텐션보다 추론 속도가 훨씬 빠릅니다. 이는 GPU의 느리고 고대역폭 메모리(VRAM)의 사용량을 크게 줄이고 대신 빠른 온칩 메모리(SRAM)에 집중할 수 있기 때문입니다.
본질적으로, 플래시 어텐션의 모든 중간 단계의 쓰기 및 읽기 작업은 느린 VRAM 메모리에 접근하지 않고 빠른 온칩 SRAM 메모리를 사용하여 출력 벡터를 계산할 수 있도록 합니다.
현실적으로 플래시 어텐션이 사용 가능한 경우 이를 사용하지 않을 이유는 전혀 없습니다. 이 알고리즘은 수학적으로 동일한 출력을 제공하며, 더 빠르고 메모리 효율적입니다.
실제 예를 살펴보겠습니다.
우리의 OctoCoder 모델은 이제 시스템 프롬프트가 포함된 훨씬 더 긴 입력 프롬프트를 받게 됩니다. 시스템 프롬프트는 대규모 언어 모델을 사용자의 작업에 맞춘 더 나은 어시스턴트로 유도하는 데 사용됩니다. 다음 예제에서는 OctoCoder를 더 나은 코딩 어시스턴트로 만들기 위한 시스템 프롬프트를 사용합니다.
system_prompt = """Below are a series of dialogues between various people and an AI technical assistant.
The assistant tries to be helpful, polite, honest, sophisticated, emotionally aware, and humble but knowledgeable.
The assistant is happy to help with code questions and will do their best to understand exactly what is needed.
It also tries to avoid giving false or misleading information, and it caveats when it isn't entirely sure about the right answer.
That said, the assistant is practical really does its best, and doesn't let caution get too much in the way of being useful.
The Starcoder models are a series of 15.5B parameter models trained on 80+ programming languages from The Stack (v1.2) (excluding opt-out requests).
The model uses Multi Query Attention, was trained using the Fill-in-the-Middle objective, and with 8,192 tokens context window for a trillion tokens of heavily deduplicated data.
-----
Question: Write a function that takes two lists and returns a list that has alternating elements from each input list.
Answer: Sure. Here is a function that does that.
def alternating(list1, list2):
results = []
for i in range(len(list1)):
results.append(list1[i])
results.append(list2[i])
return results
Question: Can you write some test cases for this function?
Answer: Sure, here are some tests.
assert alternating([10, 20, 30], [1, 2, 3]) == [10, 1, 20, 2, 30, 3]
assert alternating([True, False], [4, 5]) == [True, 4, False, 5]
assert alternating([], []) == []
Question: Modify the function so that it returns all input elements when the lists have uneven length. The elements from the longer list should be at the end.
Answer: Here is the modified function.
def alternating(list1, list2):
results = []
for i in range(min(len(list1), len(list2))):
results.append(list1[i])
results.append(list2[i])
if len(list1) > len(list2):
results.extend(list1[i+1:])
else:
results.extend(list2[i+1:])
return results
-----
"""시연을 위해 시스템 프롬프트를 10번 중복하여 증가시켜 플래시 어텐션의 메모리 절약 효과를 관찰할 수 있을 만큼 입력 길이를 충분히 길게 만듭니다. 원래의 텍스트 프롬프트를 다음과 같이 추가합니다. "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
long_prompt = 10 * system_prompt + prompt모델을 다시 bfloat16 정밀도로 인스턴스화합니다.
model = AutoModelForCausalLM.from_pretrained("bigcode/octocoder", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("bigcode/octocoder")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)이제 플래시 어텐션을 사용하지 않고 이전과 동일하게 모델을 실행하여 최대 GPU 메모리 요구량과 추론 시간을 측정해 봅시다.
import time
start_time = time.time()
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result출력:
Generated in 10.96854019165039 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef이전과 동일한 출력을 얻고 있지만, 이번에는 모델이 답변을 여러 번 반복하여 60개의 토큰이 잘릴 때까지 계속됩니다. 시연을 위해 시스템 프롬프트를 10번 반복했기 때문에 모델이 스스로 반복하도록 유도한 결과입니다. 이는 놀라운 일이 아닙니다.
참고 실제 응용에서는 시스템 프롬프트를 10번 반복할 필요가 없습니다. 한 번만 사용하면 충분합니다!
최대 GPU 메모리 요구량을 측정해 봅시다.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
출력:
37.668193340301514
보시다시피 최대 GPU 메모리 요구량이 처음보다 상당히 높아졌습니다. 이는 주로 입력 시퀀스가 길어졌기 때문입니다. 또한 생성 시간이 이제 1분을 넘어갑니다.
다음 실험을 위해 flush()를 호출하여 GPU 메모리를 초기화합니다.
flush()
비교를 위해, 동일한 기능을 실행하되 플래시 어텐션을 활성화해 보겠습니다. 이를 위해 모델을 BetterTransformer로 변환하고, 이를 통해 PyTorch의 SDPA self-attention을 활성화하면 플래시 어텐션을 사용할 수 있습니다.
model.to_bettertransformer()
이제 이전과 동일한 코드 스니펫을 실행하면, 내부적으로 Transformers가 플래시 어텐션을 사용할 것입니다.
start_time = time.time()
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
result = pipe(long_prompt, max_new_tokens=60)[0]["generated_text"][len(long_prompt):]
print(f"Generated in {time.time() - start_time} seconds.")
result출력:
Generated in 3.0211617946624756 seconds.
Sure. Here is a function that does that.\n\ndef bytes_to_giga(bytes):\n return bytes / 1024 / 1024 / 1024\n\nAnswer: Sure. Here is a function that does that.\n\ndef이전과 동일한 결과를 얻었지만, 플래시 어텐션 덕분에 매우 큰 속도 향상을 관찰할 수 있습니다.
메모리 소비량을 마지막으로 한 번 더 측정해 봅시다.
bytes_to_giga_bytes(torch.cuda.max_memory_allocated())
출력:
32.617331981658936그리고 우리는 처음에 보았던 GPU 메모리 요구량인 29GB로 돌아왔습니다.
플래시 어텐션을 사용하여 매우 긴 입력 시퀀스를 전달할 때 처음에 짧은 입력 시퀀스를 전달했을 때와 비교하여 약 100MB 정도의 GPU 메모리를 더 사용한다는 것을 관찰할 수 있습니다.
flush()
플래시 어텐션 사용에 대한 자세한 정보는 이 문서 페이지를 참조해 주세요.
3. 아키텍처 혁신
지금까지 우리는 계산 및 메모리 효율성을 개선하기 위해 다음을 살펴보았습니다:
- 가중치를 낮은 정밀도 형식으로 변환
- 셀프 어텐션 알고리즘을 보다 더 메모리 및 계산 효율적인 버전으로 교체
이제 긴 텍스트 입력이 필요한 작업에 가장 효과적이고 효율적인 대규모 언어 모델 아키텍처로 변경하는 방법을 살펴보겠습니다. 작업의 예시는 다음과 같습니다:
- 검색 증강 질의 응답
- 요약
- 채팅
채팅을 위해서는 대규모 언어 모델이 긴 텍스트 입력을 처리하는 것뿐만 아니라 사용자와 어시스턴트 간의 대화도 효율적으로 처리할 수 있어야 합니다(예: ChatGPT).
한번 학습된 후에는 대규모 언어 모델의 기본 아키텍처를 변경하기 어렵기 때문에, 대규모 언어 모델의 작업에 대한 고려를 미리 하고 이에 따라 모델의 아키텍처를 최적화하는 것이 중요합니다. 긴 입력 시퀀스에 대해 메모리 또는 성능의 병목 현상을 빠르게 발생시키는 모델 아키텍처의 중요한 두 가지 구성 요소가 있습니다.
- 위치 임베딩
- 키-값 캐시
각 구성 요소를 더 자세히 살펴보겠습니다.
3.1 대규모 언어 모델의 위치 임베딩 개선
셀프 어텐션은 각 토큰을 서로의 토큰과 연관시킵니다. 예를 들어, 텍스트 입력 시퀀스 “Hello”, “I”, “love”, “you”의 행렬은 다음과 같을 수 있습니다:
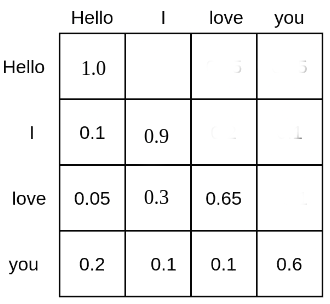
각 단어 토큰은 다른 모든 단어 토큰에 주의를 기울이는 확률 질량을 부여받아 모든 다른 단어 토큰과 관계를 맺게 됩니다. 예를 들어, 단어 “love”는 단어 “Hello”에 5%, “I”에 30%, 그리고 자신에게 65%의 주의를 기울입니다.
셀프 어텐션 기반 대규모 언어 모델이 위치 임베딩이 없는 경우 텍스트 입력의 위치를 이해하는 데 큰 어려움을 겪을 것입니다. 이는에 의해 계산된 확률 점수가 상대적 위치 거리에 상관없이 각 단어 토큰을 다른 모든 단어 토큰과 계산으로 연관시키기 때문입니다. 따라서 위치 임베딩이 없는 대규모 언어 모델은 각 토큰이 다른 모든 토큰과 동일한 거리에 있는 것으로 나타나기 때문에, “Hello I love you”와 “You love I hello”를 구분하는 것이 매우 어렵습니다.
대규모 언어 모델이 문장의 순서를 이해하려면 추가적인 단서가 필요하며, 이는 일반적으로 위치 인코딩 (또는 위치 임베딩이라고도 함)의 형태로 적용됩니다. 위치 인코딩은 각 토큰의 위치를 숫자 표현으로 인코딩하여 대규모 언어 모델이 문장의 순서를 더 잘 이해할 수 있도록 도와줍니다.
Attention Is All You Need 논문의 저자들은 사인 함수 기반의 위치 임베딩을 도입했습니다. 각 벡터는 위치의 사인 함수로 계산됩니다. 위치 인코딩은 입력 시퀀스 벡터에 단순히 더해져 = 모델이 문장 순서를 더 잘 학습할 수 있도록 합니다.
고정된 위치 임베딩 대신 Devlin et al.과 같은 다른 연구자들은 학습된 위치 인코딩을 사용했습니다. 이 경우 위치 임베딩은 학습 중에 사용됩니다.
사인 함수 및 학습된 위치 임베딩은 문장 순서를 대규모 언어 모델에 인코딩하는 주요 방법이었지만, 이러한 위치 인코딩과 관련된 몇 가지 문제가 발견되었습니다:
- 사인 함수와 학습된 위치 임베딩은 모두 절대 위치 임베딩으로, 각 위치 ID에 대해 고유한 임베딩을 인코딩합니다. Huang et al. 및 Su et al.의 연구에 따르면, 절대 위치 임베딩은 긴 텍스트 입력에 대해 대규모 언어 모델 성능이 저하됩니다. 긴 텍스트 입력의 경우, 모델이 절대 위치 대신 입력 토큰 간의 상대적 위치 거리를 학습하는 것이 유리합니다.
- 학습된 위치 임베딩을 사용할 때, 대규모 언어 모델은 고정된 입력 길이으로 학습되어야 하므로, 학습된 입력 길이보다 더 긴 입력 길이에 대해 추론하는 것이 어렵습니다.
최근에는 위에서 언급한 문제를 해결할 수 있는 상대적 위치 임베딩이 더 인기를 끌고 있습니다. 특히 다음과 같은 방법들이 주목받고 있습니다:
RoPE와 ALiBi는 모두 셀프 어텐션 알고리즘 내에서 직접적으로 문장 순서를 모델에게 알려주는 것이 최선이라고 주장합니다. 이는 단어 토큰이 서로 관계를 맺는 곳이기 때문입니다. 구체적으로, 문장 순서를 계산을 수정하는 방식으로 알려주어야 한다는 것입니다.
너무 많은 세부 사항을 다루지 않고, RoPE는 위치 정보를 쿼리-키 쌍에 인코딩할 수 있다고 지적합니다. 예를 들어, 각 벡터와를 각각와의 각도로 회전시킴으로써 다음과 같이 표현할 수 있습니다:
여기서는 회전 행렬을 나타냅니다.는 훈련 중에 학습되지 않으며, 대신 학습 중 최대 입력 시퀀스 길이에 따라 사전 정의된 값으로 설정됩니다.
이렇게 함으로써와 간의 확률 점수는인 경우에만 영향을 받으며, 각 벡터의 특정 위치와와는 상관없이 오직 상대적 거리에만 의존하게 됩니다.
RoPE는 현재 여러 중요한 대규모 언어 모델이 사용되고 있습니다. 예를 들면:
대안으로, ALiBi는 훨씬 더 간단한 상대적 위치 인코딩 방식을 제안합니다. 입력 토큰 간의 상대적 거리를 음수인 정수로서 사전 정의된 값 m으로 스케일링하여 행렬의 각 쿼리-키 항목에 소프트맥스 계산 직전에 추가합니다.
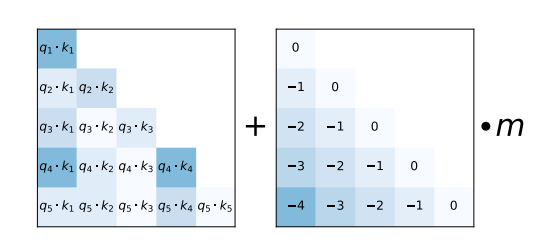
ALiBi 논문에서 보여주듯이, 이 간단한 상대적 위치 인코딩은 매우 긴 텍스트 입력 시퀀스에서도 모델이 높은 성능을 유지할 수 있게 합니다.
ALiBi는 현재 여러 중요한 대규모 언어 모델 모델이 사용하고 있습니다. 예를 들면:
RoPE와 ALiBi 위치 인코딩은 모두 학습 중에 보지 못한 입력 길이에 대해 확장할 수 있으며, ALiBi가 RoPE보다 더 잘 확장되는 것으로 나타났습니다. ALiBi의 경우, 하삼각 위치 행렬의 값을 입력 시퀀스 길이에 맞추어 증가시키기만 하면 됩니다. RoPE의 경우, 학습 중에 사용된 동일한를 유지하면 학습 중에 보지 못한 매우 긴 텍스트 입력을 전달할 때 성능이 저하됩니다(참고: Press et al.). 그러나 커뮤니티는를 조정하는 몇 가지 효과적인 트릭을 찾아냈으며, 이를 통해 RoPE 위치 임베딩이 확장된 텍스트 입력 시퀀스에서도 잘 작동할 수 있게 되었습니다(참고: here).
RoPE와 ALiBi는 모두 훈련 중에 학습되지 않는 상대적 위치 임베딩으로 다음과 같은 직관에 기반합니다:
- 텍스트 입력에 대한 위치 단서는 셀프 어텐션 레이어의 행렬에 직접 제공되어야 합니다.
- 대규모 언어 모델은 일정한 상대적 거리 위치 인코딩을 서로 학습하도록 유도되어야 합니다.
- 텍스트 입력 토큰 간의 거리가 멀어질수록, 그들의 쿼리-값 확률은 낮아져야 합니다. RoPE와 ALiBi는 서로 멀리 떨어진 토큰의 쿼리-키 확률을 낮춥니다. RoPE는 쿼리-키 벡터 간의 각도를 증가시켜 벡터 곱을 감소시키는 방식으로, ALiBi는 벡터 곱에 큰 음수를 추가하는 방식으로 이 작업을 수행합니다.
결론적으로, 큰 텍스트 입력을 처리해야 하는 작업에 배포될 예정인 대규모 언어 모델은 RoPE와 ALiBi와 같은 상대적 위치 임베딩으로 훈련하는 것이 더 좋습니다. 또한 RoPE와 ALiBi를 사용하여 훈련된 대규모 언어 모델이 고정 길이에서만 훈련되었더라도 위치 임베딩을 외삽하여보다 훨씬 큰 텍스트 입력로 실습에서 사용할 수 있음을 유의하세요.
3.2 키-값 캐시
대규모 언어 모델을 이용한 자기회귀 텍스트 생성은 입력 시퀀스를 반복적으로 넣고, 다음 토큰을 샘플링하며, 그 다음 토큰을 입력 시퀀스에 추가하고, 대규모 언어 모델이 생성을 완료했다는 토큰을 생성할 때까지 이를 계속 수행하는 방식으로 작동합니다.
자기회귀 생성이 어떻게 작동하는지에 대한 시각적 설명을 보려면 Transformer’s Generate Text Tutorial을 참조하세요.
자기회귀 생성이 실제로 어떻게 작동하는지 보여주는 간단한 코드 스니펫을 실행해 보겠습니다. 여기서는 torch.argmax를 통해 가장 가능성이 높은 다음 토큰을 가져올 것입니다.
input_ids = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits = model(input_ids)["logits"][:, -1:]
next_token_id = torch.argmax(next_logits,dim=-1)
input_ids = torch.cat([input_ids, next_token_id], dim=-1)
print("shape of input_ids", input_ids.shape)
generated_text = tokenizer.batch_decode(input_ids[:, -5:])
generated_text출력:
shape of input_ids torch.Size([1, 21])
shape of input_ids torch.Size([1, 22])
shape of input_ids torch.Size([1, 23])
shape of input_ids torch.Size([1, 24])
shape of input_ids torch.Size([1, 25])
[' Here is a Python function']보시다시피 샘플링된 토큰에 의해 텍스트 입력 토큰을 매번 증가시킵니다.
매우 예외적인 경우를 제외하고, 대규모 언어 모델은 인과적인 언어 모델링 목표를 사용하여 학습되므로 어텐션 점수의 상삼각 행렬을 마스킹합니다. 이것이 위의 두 다이어그램에서 어텐션 점수가 비어 있는 이유입니다 (즉, 0 확률을 가짐). 인과 언어 모델링에 대한 빠른 요약은 Illustrated Self Attention 블로그를 참조할 수 있습니다.
결과적으로, 토큰은 절대 이전 토큰에 의존하지 않습니다. 더 구체적으로는 벡터가인 경우 어떤 키, 값 벡터와도 연관되지 않습니다. 대신는 이전의 키-값 벡터에만 주의를 기울입니다. 불필요한 계산을 줄이기 위해 각 층의 키-값 벡터를 모든 이전 시간 단계에 대해 캐시할 수 있습니다.
다음으로, 대규모 언어 모델이 각 포워드 패스마다 키-값 캐시를 검색하고 전달하여 이를 활용하도록 합니다.
Transformers에서는 forward 호출에 use_cache 플래그를 전달하여 키-값 캐시를 검색한 다음 현재 토큰과 함께 전달할 수 있습니다.
past_key_values = None # past_key_values 는 키-값 캐시를 의미
generated_tokens = []
next_token_id = tokenizer(prompt, return_tensors="pt")["input_ids"].to("cuda")
for _ in range(5):
next_logits, past_key_values = model(next_token_id, past_key_values=past_key_values, use_cache=True).to_tuple()
next_logits = next_logits[:, -1:]
next_token_id = torch.argmax(next_logits, dim=-1)
print("shape of input_ids", next_token_id.shape)
print("length of key-value cache", len(past_key_values[0][0])) # past_key_values 형태: [num_layers, 0 for k, 1 for v, batch_size, length, hidden_dim]
generated_tokens.append(next_token_id.item())
generated_text = tokenizer.batch_decode(generated_tokens)
generated_text출력:
shape of input_ids torch.Size([1, 1])
length of key-value cache 20
shape of input_ids torch.Size([1, 1])
length of key-value cache 21
shape of input_ids torch.Size([1, 1])
length of key-value cache 22
shape of input_ids torch.Size([1, 1])
length of key-value cache 23
shape of input_ids torch.Size([1, 1])
length of key-value cache 24
[' Here', ' is', ' a', ' Python', ' function']키-값 캐시를 사용할 때, 텍스트 입력 토큰의 길이는 증가하지 않고 단일 입력 벡터로 유지되는 것을 볼 수 있습니다. 반면에 키-값 캐시의 길이는 각 디코딩 단계마다 하나씩 증가합니다.
키-값 캐시를 사용하면가 본질적으로로 줄어드는데, 여기서는 현재 전달된 입력 토큰의 쿼리 프로젝션으로, 항상 단일 벡터입니다.
키-값 캐시를 사용하는 것에는 두 가지 장점이 있습니다:
- 전체 행렬을 계산하는 것과 비교하여 계산 효율성이 크게 향상됩니다. 이는 추론 속도의 증가로 이어집니다.
- 생성된 토큰 수에 따라 필요한 최대 메모리가 이차적으로 증가하지 않고, 선형적으로만 증가합니다.
더 긴 입력 시퀀스에 대해 동일한 결과와 큰 속도 향상을 가져오기 때문에 키-값 캐시를 항상 사용해야 합니다. Transformers는 텍스트 파이프라인이나
generate메서드를 사용할 때 기본적으로 키-값 캐시를 활성화합니다.
참고로, 키-값 캐시를 사용할 것을 권장하지만, 이를 사용할 때 LLM 출력이 약간 다를 수 있습니다. 이것은 행렬 곱셈 커널 자체의 특성 때문입니다 — 더 자세한 내용은 여기에서 읽어볼 수 있습니다.
3.2.1 멀티 라운드 대화
키-값 캐시는 여러 번의 자기회귀 디코딩이 필요한 채팅과 같은 애플리케이션에 특히 유용합니다. 예제를 살펴보겠습니다.
User: How many people live in France?
Assistant: Roughly 75 million people live in France
User: And how many are in Germany?
Assistant: Germany has ca. 81 million inhabitants이 채팅에서 대규모 언어 모델은 두 번의 자기회귀 디코딩을 실행합니다:
- 첫 번째로, 키-값 캐시는 비어 있고 입력 프롬프트는
"User: How many people live in France?"입니다. 모델은 자기회귀적으로"Roughly 75 million people live in France"라는 텍스트를 생성하며 디코딩 단계마다 키-값 캐시를 증가시킵니다. - 두 번째로, 입력 프롬프트는
"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many in Germany?"입니다. 캐시 덕분에 첫 번째 두 문장에 대한 모든 키-값 벡터는 이미 계산되어 있습니다. 따라서 입력 프롬프트는"User: And how many in Germany?"로만 구성됩니다. 줄어든 입력 프롬프트를 처리하는 동안 계산된 키-값 벡터가 첫 번째 디코딩의 키-값 캐시에 연결됩니다. 두 번째 어시스턴트의 답변인"Germany has ca. 81 million inhabitants"는"User: How many people live in France? \n Assistant: Roughly 75 million people live in France \n User: And how many are in Germany?"의 인코딩된 키-값 벡터로 구성된 키-값 캐시를 사용하여 자기회귀적으로 생성됩니다.
여기서 두 가지를 주목해야 합니다:
- 대규모 언어 모델이 대화의 모든 이전 문맥을 이해할 수 있도록 모든 문맥을 유지하는 것이 채팅에 배포된 대규모 언어 모델에서는 매우 중요합니다. 예를 들어, 위의 예에서 대규모 언어 모델은 사용자가
"And how many are in Germany"라고 물을 때 인구를 언급하고 있음을 이해해야 합니다. - 키-값 캐시는 채팅에서 매우 유용합니다. 이는 인코딩된 채팅 기록을 처음부터 다시 인코딩할 필요 없이 계속해서 확장할 수 있게 해주기 때문입니다(예: 인코더-디코더 아키텍처를 사용할 때와 같은 경우).
transformers에서 generate 호출은 기본적으로 use_cache=True와 함께 return_dict_in_generate=True를 전달하면 past_key_values를 반환합니다. 이는 아직 pipeline 인터페이스를 통해서는 사용할 수 없습니다.
# 일반적인 생성
prompt = system_prompt + "Question: Please write a function in Python that transforms bytes to Giga bytes.\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(**model_inputs, max_new_tokens=60, return_dict_in_generate=True)
decoded_output = tokenizer.batch_decode(generation_output.sequences)[0]
# 리턴된 `past_key_values`를 파이프라인화하여 다음 대화 라운드를 가속화
prompt = decoded_output + "\nQuestion: How can I modify the function above to return Mega bytes instead?\n\nAnswer: Here"
model_inputs = tokenizer(prompt, return_tensors='pt')
generation_output = model.generate(
**model_inputs,
past_key_values=generation_output.past_key_values,
max_new_tokens=60,
return_dict_in_generate=True
)
tokenizer.batch_decode(generation_output.sequences)[0][len(prompt):]출력:
is a modified version of the function that returns Mega bytes instead.
def bytes_to_megabytes(bytes):
return bytes / 1024 / 1024
Answer: The function takes a number of bytes as input and returns the number of훌륭합니다. 어텐션 층의 동일한 키와 값을 다시 계산하는 데 추가 시간이 소요되지 않습니다! 그러나 한 가지 문제가 있습니다. 행렬에 필요한 최대 메모리는 크게 줄어들지만, 긴 입력 시퀀스나 다회차 채팅의 경우 키-값 캐시를 메모리에 보관하는 것이 매우 메모리 집약적이 될 수 있습니다. 키-값 캐시는 모든 자기 어텐션 층과 모든 어텐션 헤드에 대해 이전 입력 벡터의 키-값 벡터를 저장해야 한다는 점을 기억하세요.
이전에 사용한 대규모 언어 모델 bigcode/octocoder에 대해 키-값 캐시에 저장해야 하는 부동 소수점 값의 수를 계산해 봅시다.
부동 소수점 값의 수는 시퀀스 길이의 두 배의 어텐션 헤드 수, 어텐션 헤드 차원, 레이어 수를 곱한 값입니다.
가상의 입력 시퀀스 길이 16000에서 대규모 언어 모델에 대해 이를 계산하면 다음과 같습니다.
config = model.config
2 * 16_000 * config.n_layer * config.n_head * config.n_embd // config.n_head출력:
7864320000대략 80억 개의 부동 소수점 값입니다! float16 정밀도로 80억 개의 부동 소수점 값을 저장하는 데는 약 15GB의 RAM이 필요하며, 이는 모델 가중치 자체의 절반 정도입니다.
연구자들은 키-값 캐시를 저장하는 데 필요한 메모리 비용을 크게 줄일 수 있는 두 가지 방법을 제안했으며, 이는 다음 절에서 살펴보겠습니다.
3.2.2 멀티 쿼리 어텐션 (MQA)
멀티 쿼리 어텐션 (MQA)은 Noam Shazeer의 Fast Transformer Decoding: One Write-Head is All You Need 논문에서 제안되었습니다. 제목에서 알 수 있듯이, Noam은 n_head 키-값 프로젝션 가중치 대신, 모든 어텐션 헤드에서 공유되는 단일 헤드-값 프로젝션 가중치를 사용할 수 있으며, 이를 통해 모델 성능이 크게 저하되지 않는다는 것을 발견했습니다.
단일 헤드-값 프로젝션 가중치를 사용함으로써, 키-값 벡터는 모든 어텐션 헤드에서 동일해야 하며, 이는 캐시에
n_head개 대신 하나의 키-값 프로젝션 쌍만 저장하면 된다는 것을 의미합니다.
대부분의 대규모 언어 모델이 20에서 100 사이의 어텐션 헤드를 사용하기 때문에, MQA는 키-값 캐시의 메모리 소비를 크게 줄입니다. 이 노트북에서 사용된 대규모 언어 모델의 경우, 입력 시퀀스 길이 16000에서 필요한 메모리 소비를 15GB에서 400MB 미만으로 줄일 수 있습니다.
메모리 절감 외에도, MQA는 계산 효율성도 향상시킵니다. 다음과 같이 설명합니다. 자기회귀 디코딩에서는 큰 키-값 벡터를 다시 로드하고, 현재 키-값 벡터 쌍과 연결한 후 계산에 매 단계마다 입력해야 합니다. 자기회귀 디코딩의 경우, 지속적인 재로드에 필요한 메모리 대역폭이 심각한 시간 병목 현상을 가져올 수 있습니다. 키-값 벡터의 크기를 줄이면 접근해야 하는 메모리 양이 줄어들어 메모리 대역폭 병목 현상이 감소합니다. 자세한 내용은 Noam의 논문을 참조하세요.
여기서 이해해야 할 중요한 부분은 키-값 어텐션 헤드 수를 1로 줄이는 것이 키-값 캐시를 사용할 때만 의미가 있다는 것입니다. 키-값 캐시 없이 단일 포워드 패스에 대한 모델의 최대 메모리 소비는 변경되지 않으며, 각 어텐션 헤드는 여전히 고유한 쿼리 벡터를 가지므로 각 어텐션 헤드는 여전히 다른 행렬을 가집니다.
MQA는 커뮤니티에서 널리 채택되어 현재 가장 인기 있는 많은 대규모 언어 모델에서 사용되고 있습니다.
또한, 이 노트북에서 사용된 체크포인트 bigcode/octocoder는 MQA를 사용합니다.
3.2.3 그룹 쿼리 어텐션 (GQA)
그룹 쿼리 어텐션 (GQA)은 Google의 Ainslie 등의 연구진들에 의해 제안되었습니다. 그들은 MQA를 사용하는 것이 종종 일반적인 멀티 키-값 헤드 프로젝션을 사용하는 것보다 품질 저하를 가져올 수 있다는 것을 발견했습니다. 이 논문은 쿼리 헤드 프로젝션 가중치의 수를 너무 극단적으로 줄이는 대신, 더 많은 모델 성능을 유지할 수 있다고 주장합니다. 단일 키-값 프로젝션 가중치 대신, n < n_head 키-값 프로젝션 가중치를 사용해야 합니다. n_head보다 훨씬 작은 n값, 예를 들어 2, 4 또는 8을 선택하면, MQA의 거의 모든 메모리 및 속도 이점을 유지하면서 모델 용량을 덜 희생하고 따라서 성능 저하를 줄일 수 있습니다.
또한, GQA의 저자들은 기존 모델 체크포인트를 원래 사전 학습 계산의 5% 정도의 적은 양으로 GQA 아키텍처로 업트레이닝할 수 있음을 발견했습니다. 원래 사전 학습 계산의 5%가 여전히 엄청난 양일 수 있지만, GQA 업트레이닝은 기존 체크포인트가 더 긴 입력 시퀀스에서도 유용하도록 합니다.
GQA는 최근에 제안되었기 때문에 이 노트북을 작성할 당시에는 채택이 덜 되었습니다. GQA의 가장 주목할 만한 적용 사례는 Llama-v2입니다.
결론적으로, 대규모 언어 모델이 자기회귀 디코딩으로 배포되면서 채팅과 같이 큰 입력 시퀀스를 가진 작업을 처리해야 하는 경우 GQA 또는 MQA를 사용하는 것이 강력히 권장됩니다.
결론
연구 커뮤니티는 점점 더 큰 대규모 언어 모델의 추론 시간을 가속화하기 위한 새로운 기발한 방법들을 끊임없이 찾아내고 있습니다. 예를 들어, 추측 디코딩이라는 유망한 연구 방향이 있습니다. 여기서 “쉬운 토큰”은 더 작고 빠른 언어 모델에 의해 생성되고, “어려운 토큰”만 대규모 언어 모델 자체에 의해 생성됩니다. 자세한 내용은 이 노트북의 범위를 벗어나지만, 멋진 블로그 포스트에서 읽어볼 수 있습니다.
GPT3/4, Llama-2-70b, Claude, PaLM과 같은 거대한 대규모 언어 모델이 Hugging Face Chat 또는 ChatGPT와 같은 채팅 인터페이스에서 빠르게 실행될 수 있는 이유는 위에서 언급한 정밀도, 알고리즘, 아키텍처의 개선 덕분입니다. 앞으로 GPU, TPU 등과 같은 가속기는 점점 더 빨라지고 더 많은 메모리를 사용할 것입니다. 따라서 가장 좋은 알고리즘과 아키텍처를 사용하여 최고의 효율을 얻는 것이 중요합니다 🤗
< > Update on GitHub