Transformers documentation
SigLIP
SigLIP
Overview
The SigLIP model was proposed in Sigmoid Loss for Language Image Pre-Training by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer. SigLIP proposes to replace the loss function used in CLIP by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet.
The abstract from the paper is the following:
We propose a simple pairwise Sigmoid loss for Language-Image Pre-training (SigLIP). Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. The sigmoid loss simultaneously allows further scaling up the batch size, while also performing better at smaller batch sizes. Combined with Locked-image Tuning, with only four TPUv4 chips, we train a SigLiT model that achieves 84.5% ImageNet zero-shot accuracy in two days. The disentanglement of the batch size from the loss further allows us to study the impact of examples vs pairs and negative to positive ratio. Finally, we push the batch size to the extreme, up to one million, and find that the benefits of growing batch size quickly diminish, with a more reasonable batch size of 32k being sufficient.
Usage tips
- Usage of SigLIP is similar to CLIP. The main difference is the training loss, which does not require a global view of all the pairwise similarities of images and texts within a batch. One needs to apply the sigmoid activation function to the logits, rather than the softmax.
- Training is supported but does not use
torch.distributedutilities which may limit the scalability of batch size. However, DDP and FDSP works on single-node multi-gpu setup. - When using the standalone SiglipTokenizer or SiglipProcessor, make sure to pass
padding="max_length"as that’s how the model was trained. - To get the same results as the pipeline, a prompt template of “This is a photo of {label}.” should be used.
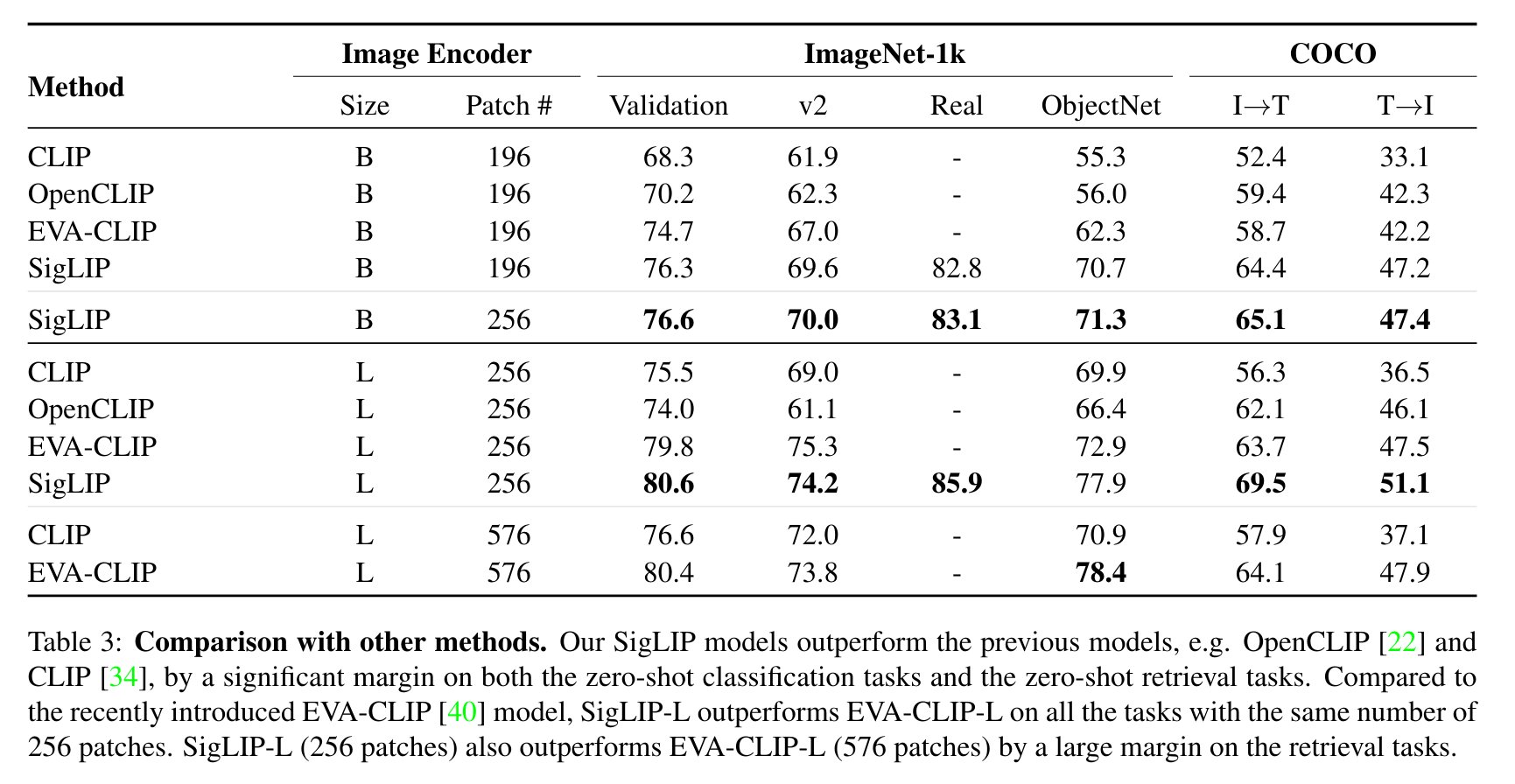 SigLIP evaluation results compared to CLIP. Taken from the original paper.
SigLIP evaluation results compared to CLIP. Taken from the original paper. This model was contributed by nielsr. The original code can be found here.
Usage example
There are 2 main ways to use SigLIP: either using the pipeline API, which abstracts away all the complexity for you, or by using the SiglipModel class yourself.
Pipeline API
The pipeline allows to use the model in a few lines of code:
>>> from transformers import pipeline
>>> from PIL import Image
>>> import requests
>>> # load pipe
>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
>>> # load image
>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # inference
>>> candidate_labels = ["2 cats", "a plane", "a remote"]
>>> outputs = image_classifier(image, candidate_labels=candidate_labels)
>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
>>> print(outputs)
[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]Using the model yourself
If you want to do the pre- and postprocessing yourself, here’s how to do that:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
>>> candidate_labels = [f'This is a photo of {label}.' for label in candidate_labels]
>>> # important: we pass `padding=max_length` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
31.9% that image 0 is 'a photo of 2 cats'Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SigLIP.
- Zero-shot image classification task guide
- Demo notebooks for SigLIP can be found here. 🌎
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
Combining SigLIP and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16“)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> import requests
>>> from PIL import Image
>>> from transformers import SiglipProcessor, SiglipModel
>>> device = "cuda" # the device to load the model onto
>>> model = SiglipModel.from_pretrained(
... "google/siglip-so400m-patch14-384",
... attn_implementation="flash_attention_2",
... torch_dtype=torch.float16,
... device_map=device,
... )
>>> processor = SiglipProcessor.from_pretrained("google/siglip-so400m-patch14-384")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> candidate_labels = ["2 cats", "2 dogs"]
# follows the pipeline prompt template to get same results
>>> candidate_labels = [f'This is a photo of {label}.' for label in candidate_labels]
# important: we pass `padding=max_length` since the model was trained with this
>>> inputs = processor(text=candidate_labels, images=image, padding="max_length", return_tensors="pt")
>>> inputs.to(device)
>>> with torch.no_grad():
... with torch.autocast(device):
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{candidate_labels[0]}'")
51.3% that image 0 is 'This is a photo of 2 cats.'Using Scaled Dot Product Attention (SDPA)
PyTorch includes a native scaled dot-product attention (SDPA) operator as part of torch.nn.functional. This function
encompasses several implementations that can be applied depending on the inputs and the hardware in use. See the
official documentation
or the GPU Inference
page for more information.
You may set attn_implementation="sdpa" in from_pretrained() to explicitly request SDPA to be used. Make sure you have torch>=2.1.1.
>>> from transformers import SiglipModel
>>> model = SiglipModel.from_pretrained(
... "google/siglip-so400m-patch14-384",
... attn_implementation="sdpa",
... torch_dtype=torch.float16,
... device_map=device,
... )For the best speedups, we recommend loading the model in half-precision (e.g. torch.float16 or torch.bfloat16).
Expected speedups
Below is an expected speedup diagram that compares inference time between the native implementation in transformers using google/siglip-so400m-patch14-384 checkpoint in float16 precision and the Flash Attention 2 / SDPA version of the model using different batch sizes.

SiglipConfig
class transformers.SiglipConfig
< source >( text_config = None vision_config = None **kwargs )
Parameters
- text_config (
dict, optional) — Dictionary of configuration options used to initialize SiglipTextConfig. - vision_config (
dict, optional) — Dictionary of configuration options used to initialize SiglipVisionConfig. - kwargs (optional) — Dictionary of keyword arguments.
SiglipConfig is the configuration class to store the configuration of a SiglipModel. It is used to instantiate a Siglip model according to the specified arguments, defining the text model and vision model configs. Instantiating a configuration with the defaults will yield a similar configuration to that of the Siglip google/siglip-base-patch16-224 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import SiglipConfig, SiglipModel
>>> # Initializing a SiglipConfig with google/siglip-base-patch16-224 style configuration
>>> configuration = SiglipConfig()
>>> # Initializing a SiglipModel (with random weights) from the google/siglip-base-patch16-224 style configuration
>>> model = SiglipModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
>>> # We can also initialize a SiglipConfig from a SiglipTextConfig and a SiglipVisionConfig
>>> from transformers import SiglipTextConfig, SiglipVisionConfig
>>> # Initializing a SiglipText and SiglipVision configuration
>>> config_text = SiglipTextConfig()
>>> config_vision = SiglipVisionConfig()
>>> config = SiglipConfig.from_text_vision_configs(config_text, config_vision)from_text_vision_configs
< source >( text_config: SiglipTextConfig vision_config: SiglipVisionConfig **kwargs ) → SiglipConfig
Instantiate a SiglipConfig (or a derived class) from siglip text model configuration and siglip vision model configuration.
SiglipTextConfig
class transformers.SiglipTextConfig
< source >( vocab_size = 32000 hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 max_position_embeddings = 64 hidden_act = 'gelu_pytorch_tanh' layer_norm_eps = 1e-06 attention_dropout = 0.0 pad_token_id = 1 bos_token_id = 49406 eos_token_id = 49407 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 32000) — Vocabulary size of the Siglip text model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling SiglipModel. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - max_position_embeddings (
int, optional, defaults to 64) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - hidden_act (
strorfunction, optional, defaults to"gelu_pytorch_tanh") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new""quick_gelu"are supported. - layer_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the layer normalization layers. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - pad_token_id (
int, optional, defaults to 1) — The id of the padding token in the vocabulary. - bos_token_id (
int, optional, defaults to 49406) — The id of the beginning-of-sequence token in the vocabulary. - eos_token_id (
int, optional, defaults to 49407) — The id of the end-of-sequence token in the vocabulary.
This is the configuration class to store the configuration of a SiglipTextModel. It is used to instantiate a Siglip text encoder according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the text encoder of the Siglip google/siglip-base-patch16-224 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import SiglipTextConfig, SiglipTextModel
>>> # Initializing a SiglipTextConfig with google/siglip-base-patch16-224 style configuration
>>> configuration = SiglipTextConfig()
>>> # Initializing a SiglipTextModel (with random weights) from the google/siglip-base-patch16-224 style configuration
>>> model = SiglipTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSiglipVisionConfig
class transformers.SiglipVisionConfig
< source >( hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 num_channels = 3 image_size = 224 patch_size = 16 hidden_act = 'gelu_pytorch_tanh' layer_norm_eps = 1e-06 attention_dropout = 0.0 **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - num_channels (
int, optional, defaults to 3) — Number of channels in the input images. - image_size (
int, optional, defaults to 224) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 16) — The size (resolution) of each patch. - hidden_act (
strorfunction, optional, defaults to"gelu_pytorch_tanh") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new""quick_gelu"are supported. - layer_norm_eps (
float, optional, defaults to 1e-06) — The epsilon used by the layer normalization layers. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities.
This is the configuration class to store the configuration of a SiglipVisionModel. It is used to instantiate a Siglip vision encoder according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the vision encoder of the Siglip google/siglip-base-patch16-224 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import SiglipVisionConfig, SiglipVisionModel
>>> # Initializing a SiglipVisionConfig with google/siglip-base-patch16-224 style configuration
>>> configuration = SiglipVisionConfig()
>>> # Initializing a SiglipVisionModel (with random weights) from the google/siglip-base-patch16-224 style configuration
>>> model = SiglipVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configSiglipTokenizer
class transformers.SiglipTokenizer
< source >( vocab_file eos_token = '</s>' unk_token = '<unk>' pad_token = '</s>' additional_special_tokens = None sp_model_kwargs: Optional = None model_max_length = 64 do_lower_case = True **kwargs )
Parameters
- vocab_file (
str) — SentencePiece file (generally has a .spm extension) that contains the vocabulary necessary to instantiate a tokenizer. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - pad_token (
str, optional, defaults to"</s>") — The token used for padding, for example when batching sequences of different lengths. - additional_special_tokens (
List[str], optional) — Additional special tokens used by the tokenizer. - sp_model_kwargs (
dict, optional) — Will be passed to theSentencePieceProcessor.__init__()method. The Python wrapper for SentencePiece can be used, among other things, to set:-
enable_sampling: Enable subword regularization. -
nbest_size: Sampling parameters for unigram. Invalid for BPE-Dropout.nbest_size = {0,1}: No sampling is performed.nbest_size > 1: samples from the nbest_size results.nbest_size < 0: assuming that nbest_size is infinite and samples from the all hypothesis (lattice) using forward-filtering-and-backward-sampling algorithm.
-
alpha: Smoothing parameter for unigram sampling, and dropout probability of merge operations for BPE-dropout.
-
- model_max_length (
int, optional, defaults to 64) — The maximum length (in number of tokens) for model inputs. - do_lower_case (
bool, optional, defaults toTrue) — Whether or not to lowercase the input when tokenizing.
Construct a Siglip tokenizer. Based on SentencePiece.
This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
build_inputs_with_special_tokens
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. A sequence has the following format:
- single sequence:
X </s> - pair of sequences:
A </s> B </s>
get_special_tokens_mask
< source >( token_ids_0: List token_ids_1: Optional = None already_has_special_tokens: bool = False ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs. - already_has_special_tokens (
bool, optional, defaults toFalse) — Whether or not the token list is already formatted with special tokens for the model.
Returns
List[int]
A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer prepare_for_model method.
create_token_type_ids_from_sequences
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make use of token type ids, therefore a list of zeros is returned.
SiglipImageProcessor
class transformers.SiglipImageProcessor
< source >( do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BICUBIC: 3> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_convert_rgb: bool = None **kwargs )
Parameters
- do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden bydo_resizein thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"height" -- 224, "width": 224}): Size of the image after resizing. Can be overridden bysizein thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BICUBIC) — Resampling filter to use if resizing the image. Can be overridden byresamplein thepreprocessmethod. - do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overridden bydo_rescalein thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overridden byrescale_factorin thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image by the specified mean and standard deviation. Can be overridden bydo_normalizein thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults to[0.5, 0.5, 0.5]) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults to[0.5, 0.5, 0.5]) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_convert_rgb (
bool, optional, defaults toTrue) — Whether to convert the image to RGB.
Constructs a SigLIP image processor.
preprocess
< source >( images: Union do_resize: bool = None size: Dict = None resample: Resampling = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: Optional = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None do_convert_rgb: bool = None )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size of the image after resizing. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling. Only has an effect ifdo_resizeis set toTrue. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation to use for normalization. Only has an effect ifdo_normalizeis set toTrue. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
- do_convert_rgb (
bool, optional, defaults toself.do_convert_rgb) — Whether to convert the image to RGB.
Preprocess an image or batch of images.
SiglipProcessor
class transformers.SiglipProcessor
< source >( image_processor tokenizer )
Parameters
- image_processor (SiglipImageProcessor) — The image processor is a required input.
- tokenizer (SiglipTokenizer) — The tokenizer is a required input.
Constructs a Siglip processor which wraps a Siglip image processor and a Siglip tokenizer into a single processor.
SiglipProcessor offers all the functionalities of SiglipImageProcessor and SiglipTokenizer. See the
__call__() and decode() for more information.
This method forwards all its arguments to SiglipTokenizer’s batch_decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to SiglipTokenizer’s decode(). Please refer to the docstring of this method for more information.
SiglipModel
class transformers.SiglipModel
< source >( config: SiglipConfig )
Parameters
- config (SiglipConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None pixel_values: Optional = None attention_mask: Optional = None position_ids: Optional = None return_loss: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None interpolate_pos_encoding: bool = False ) → transformers.models.siglip.modeling_siglip.SiglipOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using AutoImageProcessor. See CLIPImageProcessor.call() for details. - return_loss (
bool, optional) — Whether or not to return the contrastive loss. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.siglip.modeling_siglip.SiglipOutput or tuple(torch.FloatTensor)
A transformers.models.siglip.modeling_siglip.SiglipOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.siglip.configuration_siglip.SiglipConfig'>) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenreturn_lossisTrue) — Contrastive loss for image-text similarity. - logits_per_image (
torch.FloatTensorof shape(image_batch_size, text_batch_size)) — The scaled dot product scores betweenimage_embedsandtext_embeds. This represents the image-text similarity scores. - logits_per_text (
torch.FloatTensorof shape(text_batch_size, image_batch_size)) — The scaled dot product scores betweentext_embedsandimage_embeds. This represents the text-image similarity scores. - text_embeds (
torch.FloatTensorof shape(batch_size, output_dim) — The text embeddings obtained by applying the projection layer to the pooled output of SiglipTextModel. - image_embeds (
torch.FloatTensorof shape(batch_size, output_dim) — The image embeddings obtained by applying the projection layer to the pooled output of SiglipVisionModel. - text_model_output (
BaseModelOutputWithPooling) — The output of the SiglipTextModel. - vision_model_output (
BaseModelOutputWithPooling) — The output of the SiglipVisionModel.
The SiglipModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
>>> # important: we pass `padding=max_length` since the model was trained with this
>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image
>>> probs = torch.sigmoid(logits_per_image) # these are the probabilities
>>> print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
31.9% that image 0 is 'a photo of 2 cats'get_text_features
< source >( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → text_features (torch.FloatTensor of shape (batch_size, output_dim)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
text_features (torch.FloatTensor of shape (batch_size, output_dim)
The text embeddings obtained by applying the projection layer to the pooled output of SiglipTextModel.
The SiglipModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
>>> # important: make sure to set padding="max_length" as that's how the model was trained
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
>>> with torch.no_grad():
... text_features = model.get_text_features(**inputs)get_image_features
< source >( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None interpolate_pos_encoding: bool = False ) → image_features (torch.FloatTensor of shape (batch_size, output_dim)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using AutoImageProcessor. See CLIPImageProcessor.call() for details. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
image_features (torch.FloatTensor of shape (batch_size, output_dim)
The image embeddings obtained by applying the projection layer to the pooled output of SiglipVisionModel.
The SiglipModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, AutoModel
>>> import torch
>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> with torch.no_grad():
... image_features = model.get_image_features(**inputs)SiglipTextModel
class transformers.SiglipTextModel
< source >( config: SiglipTextConfig )
Parameters
- config (SiglipConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The text model from SigLIP without any head or projection on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None position_ids: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.siglip.configuration_siglip.SiglipTextConfig'>) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The SiglipTextModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, SiglipTextModel
>>> model = SiglipTextModel.from_pretrained("google/siglip-base-patch16-224")
>>> tokenizer = AutoTokenizer.from_pretrained("google/siglip-base-patch16-224")
>>> # important: make sure to set padding="max_length" as that's how the model was trained
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) statesSiglipVisionModel
class transformers.SiglipVisionModel
< source >( config: SiglipVisionConfig )
Parameters
- config (SiglipConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The vision model from SigLIP without any head or projection on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None interpolate_pos_encoding: bool = False ) → transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using AutoImageProcessor. See CLIPImageProcessor.call() for details. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.siglip.configuration_siglip.SiglipVisionConfig'>) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The SiglipVisionModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, SiglipVisionModel
>>> model = SiglipVisionModel.from_pretrained("google/siglip-base-patch16-224")
>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled featuresSiglipForImageClassification
class transformers.SiglipForImageClassification
< source >( config: SiglipConfig )
Parameters
- config (SiglipConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
SigLIP vision encoder with an image classification head on top (a linear layer on top of the pooled final hidden states of the patch tokens) e.g. for ImageNet.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None interpolate_pos_encoding: bool = False ) → transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using AutoImageProcessor. See CLIPImageProcessor.call() for details. - return_loss (
bool, optional) — Whether or not to return the contrastive loss. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - interpolate_pos_encoding (
bool, optional, defaults toFalse) — Whether to interpolate the pre-trained position encodings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.ImageClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.ImageClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (SiglipConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each stage) of shape(batch_size, sequence_length, hidden_size). Hidden-states (also called feature maps) of the model at the output of each stage. -
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, patch_size, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The SiglipForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, SiglipForImageClassification
>>> import torch
>>> from PIL import Image
>>> import requests
>>> torch.manual_seed(3)
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # note: we are loading a `SiglipModel` from the hub here,
>>> # so the head will be randomly initialized, hence the predictions will be random if seed is not set above.
>>> image_processor = AutoImageProcessor.from_pretrained("google/siglip-base-patch16-224")
>>> model = SiglipForImageClassification.from_pretrained("google/siglip-base-patch16-224")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the two classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: LABEL_1