Transformers documentation
خطوط الأنابيب الاستدلال
خطوط الأنابيب الاستدلال
يجعل pipeline() من السهل استخدام أي نموذج من Hub للاستدلال لأي مهام خاصة باللغة أو الرؤية الحاسوبية أو الكلام أو المهام متعددة الوسائط. حتى إذا لم يكن لديك خبرة في طريقة معينة أو لم تكن على دراية بالرمز الأساسي وراء النماذج، يمكنك مع ذلك استخدامها للاستدلال باستخدام pipeline()! سوف يُعلمك هذا البرنامج التعليمي ما يلي:
- استخدام
pipeline()للاستدلال. - استخدم مُجزّئ أو نموذجًا محددًا.
- استخدم
pipeline()للمهام الصوتية والبصرية والمتعددة الوسائط.
اطلع على وثائق pipeline() للحصول على القائمة كاملة بالمهام المدعومة والمعلمات المتاحة.
استخدام الأنابيب
على الرغم من أن لكل مهمة أنبوب pipeline() خاص بها، إلا أنه من الأبسط استخدام تجريد خط الأنابيب العام pipeline() الذي يحتوي على جميع خطوط الأنابيب الخاصة بالمهمة. يقوم pipeline() تلقائيًا بتحميل نموذج افتراضي وفئة معالجة مسبقة قادرة على الاستدلال لمهمتك. دعنا نأخذ مثال استخدام pipeline() للتعرف التلقائي على الكلام (ASR)، أو تحويل الكلام إلى نص.
- ابدأ بإنشاء
pipeline()وحدد مهمة الاستدلال:
>>> from transformers import pipeline
>>> transcriber = pipeline(task="automatic-speech-recognition")- مرر إدخالك إلى
pipeline(). في حالة التعرف على الكلام، يكون هذا ملف إدخال صوتي:
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': 'I HAVE A DREAM BUT ONE DAY THIS NATION WILL RISE UP LIVE UP THE TRUE MEANING OF ITS TREES'}لم تحصل على النتيجة التي تريدها؟ تحقق من بعض نماذج التعرف على الكلام الأكثر تنزيلًا على Hub لمعرفة ما إذا كان بإمكانك الحصول على نسخة منقحة أفضل.
لنَجرب نموذج Whisper large-v2 من OpenAI. تم إصدار Whisper بعد عامين من إصدار Wav2Vec2، وتم تدريبه على ما يقرب من 10 أضعاف كمية البيانات. وبهذه الصفة، فإنه يتفوق على Wav2Vec2 في معظم معظم المقاييس. كما أنه يمتلك ميزة إضافية وهي في التنبؤ بعلامات الترقيم وحالة الأحرف، والتي لا يمكن تحقيقها مع Wav2Vec2.
دعونا نجربها هنا لنرى كيف تؤدي:
>>> transcriber = pipeline(model="openai/whisper-large-v2")
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.'}الآن تبدو هذه النتيجة أكثر دقة! لمقارنة عميقة حول Wav2Vec2 مقابل Whisper، راجع دورة Audio Transformers. نشجعك بشدة على التحقق من Hub للحصول على نماذج بلغات مختلفة، ونماذج متخصصة في مجالك، وأكثر من ذلك. يمكنك التحقق من نتائج النموذج ومقارنتها مباشرة من متصفحك على Hub لمعرفة ما إذا كان يناسبها أو التعامل مع الحالات الخاصة بشكل أفضل من غيرها. وإذا لم تجد نموذجًا لحالتك الاستخدام، فيمكنك دائمًا البدء في التدريب الخاص بك!
إذا كان لديك عدة مدخلات، فيمكنك تمرير إدخالك كقائمة:
transcriber(
[
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac",
"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/1.flac",
]
)تعد خطوط الأنابيب مثالية للتجريب نظرًا لأن التبديل من نموذج إلى آخر أمر بسيط للغاية؛ ومع ذلك، هناك بعض الطرق لتحسينها لأحمال عمل أكبر من التجريب. راجع الأدلة التالية التي تتعمق فى التكرار عبر مجموعات البيانات الكاملة أو استخدام خطوط الأنابيب في خادم ويب: من الوثائق:
المعلمات
يدعم pipeline() العديد من المعلمات؛ بعضها خاص بالمهمة، والبعض الآخر عام لجميع خطوط الأنابيب.
بشكل عام، يمكنك تحديد المعلمات في أي مكان تريده:
transcriber = pipeline(model="openai/whisper-large-v2", my_parameter=1)
out = transcriber(...) # سيتم استخدام هذا `my_parameter=1`.
out = transcriber(..., my_parameter=2) # سيتم تجاوز هذا واستخدام `my_parameter=2`.
out = transcriber(...) # سيتم الرجوع إلى استخدام `my_parameter=1`.دعونا نلقي نظرة على 3 مهمة:
الجهاز
إذا كنت تستخدم device=n، فإن خط الأنابيب يضع النموذج تلقائيًا على الجهاز المحدد.
سيعمل هذا بغض النظر عما إذا كنت تستخدم PyTorch أو Tensorflow.
transcriber = pipeline(model="openai/whisper-large-v2", device=0)إذا كان النموذج كبيرًا جدًا بالنسبة لوحدة معالجة الرسومات (GPU) واحدة، وأنت تستخدم PyTorch، فيمكنك تعيين torch_dtype='float16' لتمكين الاستدلال بدقة FP16. عادةً ما لا يتسبب ذلك في حدوث انخفاضات كبيرة في الأداء، ولكن تأكد من تقييمه على نماذجك!
بدلاً من ذلك، يمكنك تعيين device_map="auto" لتحديد كيفية تحميل مخزنات النموذج وتخزينها تلقائيًا. يتطلب استخدام معامل device_map مكتبه 🤗 Accelerate:
pip install --upgrade accelerate
تقوم الشفرة التالية بتحميل مخزنات النموذج وتخزينها تلقائيًا عبر الأجهزة:
transcriber = pipeline(model="openai/whisper-large-v2", device_map="auto")لاحظ أنه إذا تم تمرير device_map="auto"، فلا توجد حاجة لإضافة حجة device=device عند إنشاء خط الأنابيب الخاص بك، فقد تواجه بعض السلوكيات غير المتوقعة!
حجم الدفعة
بشكل افتراضي، لن تقوم خطوط الأنابيب بتجميع الاستدلال لأسباب مفصلة هنا. والسبب هو أن التجميع ليست أسرع بالضرورة، ويمكن أن تكون أبطأ في الواقع في بعض الحالات.
ولكن إذا نجحت في حالتك الاستخدام، فيمكنك استخدام ما يلي:
transcriber = pipeline(model="openai/whisper-large-v2", device=0, batch_size=2)
audio_filenames = [f"https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/{i}.flac" for i in range(1, 5)]
texts = transcriber(audio_filenames)هذا يشغل خط الأنابيب على ملفات الصوت الأربعة المتاحة، ولكنه سيمررها على دفعتين إلى النموذج (الذي يوجد على وحدة معالجة الرسومات (GPU)، حيث من المرجح أن تساعد التجميع) دون الحاجة إلى أي رمز إضافي منك. يجب أن تتطابق الإخراج دائمًا مع ما كنت ستحصل عليه دون التجميع. المقصود منه فقط كطريقة لمساعدتك في الحصول على سرعة أكبر من خط الأنابيب.
يمكن لخطوط الأنابيب أيضًا تخفيف بعض تعقيدات التجميع لأنه، بالنسبة لبعض خطوط الأنابيب، يجب تقسيم عنصر واحد (مثل ملف صوتي طويل) إلى أجزاء متعددة لمعالجته بواسطة نموذج. يقوم خط الأنابيب بأداء هذه العملية التي تسمى تجميع الأجزاء batch batching نيابة عنك.
معلمات خاصة بالمهمة
توفر جميع المهام معلمات خاصة بالمهمة تتيح المرونة والخيارات الإضافية لمساعدتك في أداء عملك.
على سبيل المثال، تحتوي طريقة transformers.AutomaticSpeechRecognitionPipeline.__call__() على معلمة return_timestamps التي تبدو واعدة لترجمة مقاطع الفيديو:
>>> transcriber = pipeline(model="openai/whisper-large-v2", return_timestamps=True)
>>> transcriber("https://huggingface.co/datasets/Narsil/asr_dummy/resolve/main/mlk.flac")
{'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its creed.', 'chunks': [{'timestamp': (0.0, 11.88), 'text': ' I have a dream that one day this nation will rise up and live out the true meaning of its'}, {'timestamp': (11.88, 12.38), 'text': ' creed.'}]}كما ترون، استنتج النموذج النص.وكذلك حدد وقت نطق الجمل المختلفة.
تتوفر العديد من المعلمات لكل مهمة، لذا تحقق من مرجع API لكل مهمة لمعرفة ما يمكنك تعديله!
على سبيل المثال، تحتوي AutomaticSpeechRecognitionPipeline على معلمة chunk_length_s مفيدة
للعمل على ملفات الصوت الطويلة جدًا (على سبيل المثال، ترجمة الأفلام أو مقاطع الفيديو التي تستغرق ساعة) والتي لا يمكن للنموذج التعامل معها بمفرده:
>>> transcriber = pipeline(model="openai/whisper-large-v2", chunk_length_s=30)
>>> transcriber("https://huggingface.co/datasets/reach-vb/random-audios/resolve/main/ted_60.wav")
{'text': " So in college, I was a government major, which means I had to write a lot of papers. Now, when a normal student writes a paper, they might spread the work out a little like this. So, you know. You get started maybe a little slowly, but you get enough done in the first week that with some heavier days later on, everything gets done and things stay civil. And I would want to do that like that. That would be the plan. I would have it all ready to go, but then actually the paper would come along, and then I would kind of do this. And that would happen every single paper. But then came my 90-page senior thesis, a paper you're supposed to spend a year on. I knew for a paper like that, my normal workflow was not an option, it was way too big a project. So I planned things out and I decided I kind of had to go something like this. This is how the year would go. So I'd start off light and I'd bump it up"}إذا لم تتمكن من العثور على معلمة قد تساعدك حقًا، فلا تتردد في طلبها!
استخدام خطوط الأنابيب على مجموعة بيانات
يمكن أيضًا تشغيل خط الأنابيب للاستدلال على مجموعة بيانات كبيرة. أسهل طريقة نوصي بها للقيام بذلك هي باستخدام المتكرر (iterator).:
def data():
for i in range(1000):
yield f"My example {i}"
pipe = pipeline(model="openai-community/gpt2", device=0)
generated_characters = 0
for out in pipe(data()):
generated_characters += len(out[0]["generated_text"])يقوم المؤشر data() بإرجاع كل نتيجة، ويتعرف خط الأنابيب تلقائيًا
المدخل قابل للتحديد ويبدأ في جلب البيانات أثناء
يستمر في معالجتها على وحدة معالجة الرسومات (GPU) (يستخدم هذا DataLoader تحت الغطاء).
هذا أمر مهم لأنك لا تحتاج إلى تخصيص ذاكرة لمجموعة البيانات بأكملها
ويمكنك تغذية وحدة معالجة الرسومات (GPU) بأسرع ما يمكن.
نظرًا لأن التجميع قد تسرع الأمور، فقد يكون من المفيد ضبط معلمة batch_size هنا.
أبسط طريقة للتنقل خلال مجموعة بيانات هي فقط تحميل واحدة من 🤗 Datasets:
# KeyDataset هي أداة مساعدة ستقوم فقط بإخراج العنصر الذي نهتم به.
from transformers.pipelines.pt_utils import KeyDataset
from datasets import load_dataset
pipe = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")
for out in pipe(KeyDataset(dataset, "audio")):
print(out)استخدام خطوط الأنابيب لخادم ويب
خط أنابيب الرؤية
إن استخدام pipeline() لمهام الرؤية مماثل تمامًا.
حدد مهمتك ومرر صورتك إلى المصنف. يمكن أن تكون الصورة رابطًا أو مسارًا محليًا أو صورة مشفرة بتنسيق base64. على سبيل المثال، ما نوع القطط الموضح أدناه؟

>>> from transformers import pipeline
>>> vision_classifier = pipeline(model="google/vit-base-patch16-224")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]خط أنابيب النص
إن استخدام pipeline() لمهام NLP مماثل تمامًا.
>>> from transformers import pipeline
>>> # هذا النموذج هو نموذج "zero-shot-classification".
>>> # سيصنف النص، ولكن يمكنك اختيار أي تسمية قد تتخيلها
>>> classifier = pipeline(model="facebook/bart-large-mnli")
>>> classifier(
... "I have a problem with my iphone that needs to be resolved asap!!",
... candidate_labels=["urgent", "not urgent", "phone", "tablet", "computer"],
... )
{'sequence': 'I have a problem with my iphone that needs to be resolved asap!!', 'labels': ['urgent', 'phone', 'computer', 'not urgent', 'tablet'], 'scores': [0.504, 0.479, 0.013, 0.003, 0.002]}خط أنابيب متعدد الوسائط
تدعم pipeline() أكثر من طريقة واحدة. على سبيل المثال، تجمع مهمة الإجابة على الأسئلة المرئية (VQA) بين النص والصورة. لا تتردد في استخدام أي رابط صورة تريده وسؤال تريد طرحه حول الصورة. يمكن أن تكون الصورة عنوان URL أو مسارًا محليًا للصورة.
على سبيل المثال، إذا كنت تستخدم هذه صورة الفاتورة:
{kind=link}
>>> from transformers import pipeline
>>> vqa = pipeline(model="impira/layoutlm-document-qa")
>>> output = vqa(
... image="https://huggingface.co/spaces/impira/docquery/resolve/2359223c1837a7587402bda0f2643382a6eefeab/invoice.png",
... question="What is the invoice number?",
... )
>>> output[0]["score"] = round(output[0]["score"], 3)
>>> output
[{'score': 0.425, 'answer': 'us-001', 'start': 16, 'end': 16}]لتشغيل المثال أعلاه، تحتاج إلى تثبيت pytesseract بالإضافة إلى 🤗 Transformers:
sudo apt install -y tesseract-ocr pip install pytesseract
استخدام pipeline على نماذج كبيرة مع 🤗 accelerate :
يمكنك بسهولة تشغيل pipeline على نماذج كبيرة باستخدام 🤗 accelerate! أولاً، تأكد من تثبيت accelerate باستخدام pip install accelerate.
قم أولاً بتحميل نموذجك باستخدام device_map="auto"! سنستخدم facebook/opt-1.3b كمثال لنا.
# pip install accelerate
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", torch_dtype=torch.bfloat16, device_map="auto")
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)يمكنك أيضًا تمرير نماذج محملة بـ 8 بت إذا قمت بتثبيت bitsandbytes وإضافة الحجة load_in_8bit=True
# pip install accelerate bitsandbytes
import torch
from transformers import pipeline
pipe = pipeline(model="facebook/opt-1.3b", device_map="auto", model_kwargs={"load_in_8bit": True})
output = pipe("This is a cool example!", do_sample=True, top_p=0.95)لاحظ أنه يمكنك استبدال نقطة التفتيش بأي نموذج من Hugging Face يدعم تحميل النماذج الكبيرة، مثل BLOOM.
إنشاء عروض توضيحية ويب من خطوط الأنابيب باستخدام gradio
يتم دعم خطوط الأنابيب تلقائيًا في Gradio، وهي مكتبة تجعل إنشاء تطبيقات تعليم الآلة الجميلة والسهلة الاستخدام على الويب أمرًا سهلاً. أولاً، تأكد من تثبيت Gradio:
pip install gradioبعد ذلك، يمكنك إنشاء عرض توضيحي ويب حول خط أنابيب تصنيف الصور (أو أي خط أنابيب آخر) في سطر واحد من التعليمات البرمجية عن طريق استدعاء وظيفة Interface.from_pipeline في Gradio لإطلاق خط الأنابيب. يقوم هذا بإنشاء واجهة بديهية للسحب والإفلات في مستعرضك:
from transformers import pipeline
import gradio as gr
pipe = pipeline("image-classification", model="google/vit-base-patch16-224")
gr.Interface.from_pipeline(pipe).launch()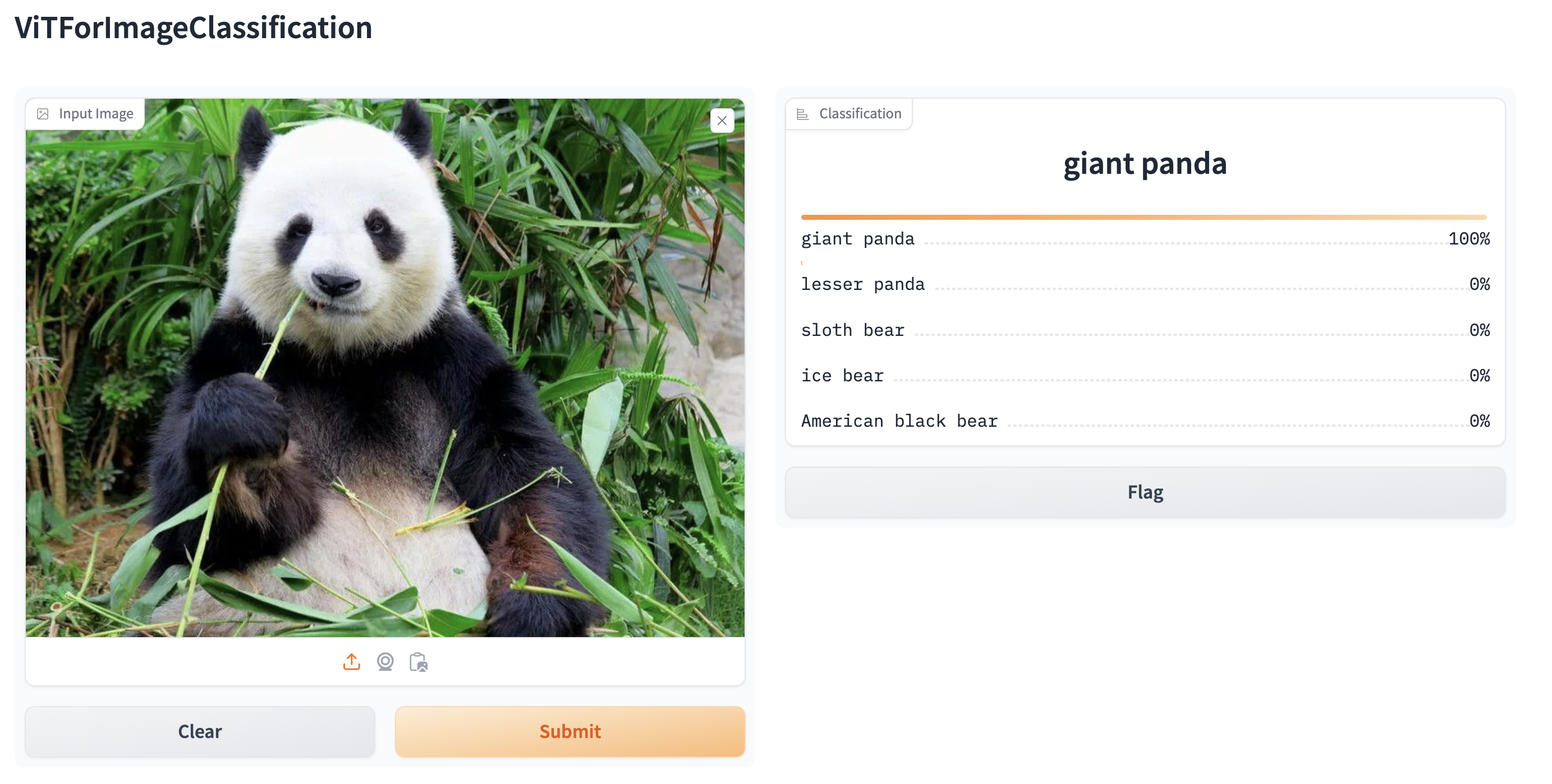
بشكل افتراضي، يعمل العرض التوضيحي على خادم محلي. إذا كنت تريد مشاركتها مع الآخرين، فيمكنك إنشاء رابط عام مؤقت عن طريق تعيين share=True في launch(). يمكنك أيضًا استضافة عرضك التوضيحي على Hugging Face Spaces للحصول على رابط دائم.