Transformers documentation
Image Segmentation
Image Segmentation
Image segmentation models separate areas corresponding to different areas of interest in an image. These models work by assigning a label to each pixel. There are several types of segmentation: semantic segmentation, instance segmentation, and panoptic segmentation.
In this guide, we will:
- Take a look at different types of segmentation.
- Have an end-to-end fine-tuning example for semantic segmentation.
Before you begin, make sure you have all the necessary libraries installed:
# uncomment to install the necessary libraries
!pip install -q datasets transformers evaluate accelerateWe encourage you to log in to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to log in:
>>> from huggingface_hub import notebook_login
>>> notebook_login()Types of Segmentation
Semantic segmentation assigns a label or class to every single pixel in an image. Let’s take a look at a semantic segmentation model output. It will assign the same class to every instance of an object it comes across in an image, for example, all cats will be labeled as “cat” instead of “cat-1”, “cat-2”. We can use transformers’ image segmentation pipeline to quickly infer a semantic segmentation model. Let’s take a look at the example image.
from transformers import pipeline
from PIL import Image
import requests
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/segmentation_input.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image
We will use nvidia/segformer-b1-finetuned-cityscapes-1024-1024.
semantic_segmentation = pipeline("image-segmentation", "nvidia/segformer-b1-finetuned-cityscapes-1024-1024")
results = semantic_segmentation(image)
resultsThe segmentation pipeline output includes a mask for every predicted class.
[{'score': None,
'label': 'road',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'sidewalk',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'building',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'wall',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'pole',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'traffic sign',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'vegetation',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'terrain',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'sky',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': None,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>}]Taking a look at the mask for the car class, we can see every car is classified with the same mask.
results[-1]["mask"]
In instance segmentation, the goal is not to classify every pixel, but to predict a mask for every instance of an object in a given image. It works very similar to object detection, where there is a bounding box for every instance, there’s a segmentation mask instead. We will use facebook/mask2former-swin-large-cityscapes-instance for this.
instance_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-instance")
results = instance_segmentation(image)
resultsAs you can see below, there are multiple cars classified, and there’s no classification for pixels other than pixels that belong to car and person instances.
[{'score': 0.999944,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999945,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999652,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.903529,
'label': 'person',
'mask': <PIL.Image.Image image mode=L size=612x415>}]Checking out one of the car masks below.
results[2]["mask"]
Panoptic segmentation combines semantic segmentation and instance segmentation, where every pixel is classified into a class and an instance of that class, and there are multiple masks for each instance of a class. We can use facebook/mask2former-swin-large-cityscapes-panoptic for this.
panoptic_segmentation = pipeline("image-segmentation", "facebook/mask2former-swin-large-cityscapes-panoptic")
results = panoptic_segmentation(image)
resultsAs you can see below, we have more classes. We will later illustrate to see that every pixel is classified into one of the classes.
[{'score': 0.999981,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999958,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.99997,
'label': 'vegetation',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999575,
'label': 'pole',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999958,
'label': 'building',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999634,
'label': 'road',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.996092,
'label': 'sidewalk',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.999221,
'label': 'car',
'mask': <PIL.Image.Image image mode=L size=612x415>},
{'score': 0.99987,
'label': 'sky',
'mask': <PIL.Image.Image image mode=L size=612x415>}]Let’s have a side by side comparison for all types of segmentation.
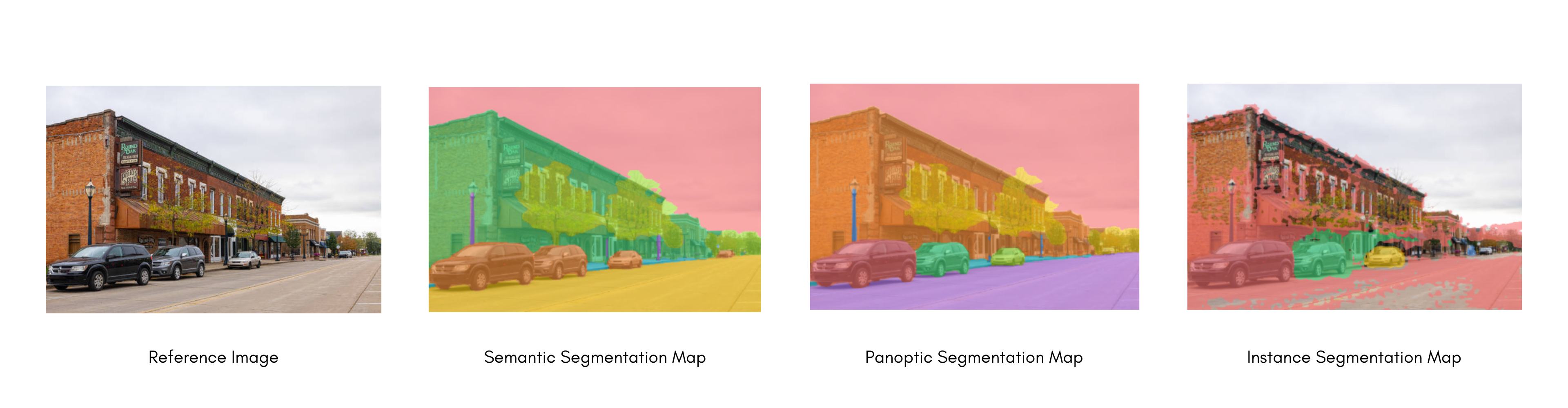
Seeing all types of segmentation, let’s have a deep dive on fine-tuning a model for semantic segmentation.
Common real-world applications of semantic segmentation include training self-driving cars to identify pedestrians and important traffic information, identifying cells and abnormalities in medical imagery, and monitoring environmental changes from satellite imagery.
Fine-tuning a Model for Segmentation
We will now:
- Finetune SegFormer on the SceneParse150 dataset.
- Use your fine-tuned model for inference.
To see all architectures and checkpoints compatible with this task, we recommend checking the task-page
Load SceneParse150 dataset
Start by loading a smaller subset of the SceneParse150 dataset from the 🤗 Datasets library. This’ll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
>>> from datasets import load_dataset
>>> ds = load_dataset("scene_parse_150", split="train[:50]")Split the dataset’s train split into a train and test set with the train_test_split method:
>>> ds = ds.train_test_split(test_size=0.2)
>>> train_ds = ds["train"]
>>> test_ds = ds["test"]Then take a look at an example:
>>> train_ds[0]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=512x683 at 0x7F9B0C201F90>,
'annotation': <PIL.PngImagePlugin.PngImageFile image mode=L size=512x683 at 0x7F9B0C201DD0>,
'scene_category': 368}
# view the image
>>> train_ds[0]["image"]image: a PIL image of the scene.annotation: a PIL image of the segmentation map, which is also the model’s target.scene_category: a category id that describes the image scene like “kitchen” or “office”. In this guide, you’ll only needimageandannotation, both of which are PIL images.
You’ll also want to create a dictionary that maps a label id to a label class which will be useful when you set up the model later. Download the mappings from the Hub and create the id2label and label2id dictionaries:
>>> import json
>>> from pathlib import Path
>>> from huggingface_hub import hf_hub_download
>>> repo_id = "huggingface/label-files"
>>> filename = "ade20k-id2label.json"
>>> id2label = json.loads(Path(hf_hub_download(repo_id, filename, repo_type="dataset")).read_text())
>>> id2label = {int(k): v for k, v in id2label.items()}
>>> label2id = {v: k for k, v in id2label.items()}
>>> num_labels = len(id2label)Custom dataset
You could also create and use your own dataset if you prefer to train with the run_semantic_segmentation.py script instead of a notebook instance. The script requires:
a DatasetDict with two Image columns, “image” and “label”
from datasets import Dataset, DatasetDict, Image image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"] label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"] image_paths_validation = [...] label_paths_validation = [...] def create_dataset(image_paths, label_paths): dataset = Dataset.from_dict({"image": sorted(image_paths), "label": sorted(label_paths)}) dataset = dataset.cast_column("image", Image()) dataset = dataset.cast_column("label", Image()) return dataset # step 1: create Dataset objects train_dataset = create_dataset(image_paths_train, label_paths_train) validation_dataset = create_dataset(image_paths_validation, label_paths_validation) # step 2: create DatasetDict dataset = DatasetDict({ "train": train_dataset, "validation": validation_dataset, } ) # step 3: push to Hub (assumes you have ran the huggingface-cli login command in a terminal/notebook) dataset.push_to_hub("your-name/dataset-repo") # optionally, you can push to a private repo on the Hub # dataset.push_to_hub("name of repo on the hub", private=True)an id2label dictionary mapping the class integers to their class names
import json # simple example id2label = {0: 'cat', 1: 'dog'} with open('id2label.json', 'w') as fp: json.dump(id2label, fp)
As an example, take a look at this example dataset which was created with the steps shown above.
Preprocess
The next step is to load a SegFormer image processor to prepare the images and annotations for the model. Some datasets, like this one, use the zero-index as the background class. However, the background class isn’t actually included in the 150 classes, so you’ll need to set do_reduce_labels=True to subtract one from all the labels. The zero-index is replaced by 255 so it’s ignored by SegFormer’s loss function:
>>> from transformers import AutoImageProcessor
>>> checkpoint = "nvidia/mit-b0"
>>> image_processor = AutoImageProcessor.from_pretrained(checkpoint, do_reduce_labels=True)It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting. In this guide, you’ll use the ColorJitter function from torchvision to randomly change the color properties of an image, but you can also use any image library you like.
>>> from torchvision.transforms import ColorJitter
>>> jitter = ColorJitter(brightness=0.25, contrast=0.25, saturation=0.25, hue=0.1)Now create two preprocessing functions to prepare the images and annotations for the model. These functions convert the images into pixel_values and annotations to labels. For the training set, jitter is applied before providing the images to the image processor. For the test set, the image processor crops and normalizes the images, and only crops the labels because no data augmentation is applied during testing.
>>> def train_transforms(example_batch):
... images = [jitter(x) for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputs
>>> def val_transforms(example_batch):
... images = [x for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputsTo apply the jitter over the entire dataset, use the 🤗 Datasets set_transform function. The transform is applied on the fly which is faster and consumes less disk space:
>>> train_ds.set_transform(train_transforms)
>>> test_ds.set_transform(val_transforms)It is common to apply some data augmentations to an image dataset to make a model more robust against overfitting.
In this guide, you’ll use tf.image to randomly change the color properties of an image, but you can also use any image
library you like.
Define two separate transformation functions:
- training data transformations that include image augmentation
- validation data transformations that only transpose the images, since computer vision models in 🤗 Transformers expect channels-first layout
>>> import tensorflow as tf
>>> def aug_transforms(image):
... image = tf.keras.utils.img_to_array(image)
... image = tf.image.random_brightness(image, 0.25)
... image = tf.image.random_contrast(image, 0.5, 2.0)
... image = tf.image.random_saturation(image, 0.75, 1.25)
... image = tf.image.random_hue(image, 0.1)
... image = tf.transpose(image, (2, 0, 1))
... return image
>>> def transforms(image):
... image = tf.keras.utils.img_to_array(image)
... image = tf.transpose(image, (2, 0, 1))
... return imageNext, create two preprocessing functions to prepare batches of images and annotations for the model. These functions apply
the image transformations and use the earlier loaded image_processor to convert the images into pixel_values and
annotations to labels. ImageProcessor also takes care of resizing and normalizing the images.
>>> def train_transforms(example_batch):
... images = [aug_transforms(x.convert("RGB")) for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputs
>>> def val_transforms(example_batch):
... images = [transforms(x.convert("RGB")) for x in example_batch["image"]]
... labels = [x for x in example_batch["annotation"]]
... inputs = image_processor(images, labels)
... return inputsTo apply the preprocessing transformations over the entire dataset, use the 🤗 Datasets set_transform function. The transform is applied on the fly which is faster and consumes less disk space:
>>> train_ds.set_transform(train_transforms)
>>> test_ds.set_transform(val_transforms)Evaluate
Including a metric during training is often helpful for evaluating your model’s performance. You can quickly load an evaluation method with the 🤗 Evaluate library. For this task, load the mean Intersection over Union (IoU) metric (see the 🤗 Evaluate quick tour to learn more about how to load and compute a metric):
>>> import evaluate
>>> metric = evaluate.load("mean_iou")Then create a function to compute the metrics. Your predictions need to be converted to
logits first, and then reshaped to match the size of the labels before you can call compute:
>>> import numpy as np
>>> import torch
>>> from torch import nn
>>> def compute_metrics(eval_pred):
... with torch.no_grad():
... logits, labels = eval_pred
... logits_tensor = torch.from_numpy(logits)
... logits_tensor = nn.functional.interpolate(
... logits_tensor,
... size=labels.shape[-2:],
... mode="bilinear",
... align_corners=False,
... ).argmax(dim=1)
... pred_labels = logits_tensor.detach().cpu().numpy()
... metrics = metric.compute(
... predictions=pred_labels,
... references=labels,
... num_labels=num_labels,
... ignore_index=255,
... reduce_labels=False,
... )
... for key, value in metrics.items():
... if isinstance(value, np.ndarray):
... metrics[key] = value.tolist()
... return metrics>>> def compute_metrics(eval_pred):
... logits, labels = eval_pred
... logits = tf.transpose(logits, perm=[0, 2, 3, 1])
... logits_resized = tf.image.resize(
... logits,
... size=tf.shape(labels)[1:],
... method="bilinear",
... )
... pred_labels = tf.argmax(logits_resized, axis=-1)
... metrics = metric.compute(
... predictions=pred_labels,
... references=labels,
... num_labels=num_labels,
... ignore_index=-1,
... reduce_labels=image_processor.do_reduce_labels,
... )
... per_category_accuracy = metrics.pop("per_category_accuracy").tolist()
... per_category_iou = metrics.pop("per_category_iou").tolist()
... metrics.update({f"accuracy_{id2label[i]}": v for i, v in enumerate(per_category_accuracy)})
... metrics.update({f"iou_{id2label[i]}": v for i, v in enumerate(per_category_iou)})
... return {"val_" + k: v for k, v in metrics.items()}Your compute_metrics function is ready to go now, and you’ll return to it when you setup your training.
Train
If you aren’t familiar with finetuning a model with the Trainer, take a look at the basic tutorial here!
You’re ready to start training your model now! Load SegFormer with AutoModelForSemanticSegmentation, and pass the model the mapping between label ids and label classes:
>>> from transformers import AutoModelForSemanticSegmentation, TrainingArguments, Trainer
>>> model = AutoModelForSemanticSegmentation.from_pretrained(checkpoint, id2label=id2label, label2id=label2id)At this point, only three steps remain:
- Define your training hyperparameters in TrainingArguments. It is important you don’t remove unused columns because this’ll drop the
imagecolumn. Without theimagecolumn, you can’t createpixel_values. Setremove_unused_columns=Falseto prevent this behavior! The only other required parameter isoutput_dirwhich specifies where to save your model. You’ll push this model to the Hub by settingpush_to_hub=True(you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the Trainer will evaluate the IoU metric and save the training checkpoint. - Pass the training arguments to Trainer along with the model, dataset, tokenizer, data collator, and
compute_metricsfunction. - Call train() to finetune your model.
>>> training_args = TrainingArguments(
... output_dir="segformer-b0-scene-parse-150",
... learning_rate=6e-5,
... num_train_epochs=50,
... per_device_train_batch_size=2,
... per_device_eval_batch_size=2,
... save_total_limit=3,
... eval_strategy="steps",
... save_strategy="steps",
... save_steps=20,
... eval_steps=20,
... logging_steps=1,
... eval_accumulation_steps=5,
... remove_unused_columns=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=train_ds,
... eval_dataset=test_ds,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()Once training is completed, share your model to the Hub with the push_to_hub() method so everyone can use your model:
>>> trainer.push_to_hub()If you are unfamiliar with fine-tuning a model with Keras, check out the basic tutorial first!
To fine-tune a model in TensorFlow, follow these steps:
- Define the training hyperparameters, and set up an optimizer and a learning rate schedule.
- Instantiate a pretrained model.
- Convert a 🤗 Dataset to a
tf.data.Dataset. - Compile your model.
- Add callbacks to calculate metrics and upload your model to 🤗 Hub
- Use the
fit()method to run the training.
Start by defining the hyperparameters, optimizer and learning rate schedule:
>>> from transformers import create_optimizer
>>> batch_size = 2
>>> num_epochs = 50
>>> num_train_steps = len(train_ds) * num_epochs
>>> learning_rate = 6e-5
>>> weight_decay_rate = 0.01
>>> optimizer, lr_schedule = create_optimizer(
... init_lr=learning_rate,
... num_train_steps=num_train_steps,
... weight_decay_rate=weight_decay_rate,
... num_warmup_steps=0,
... )Then, load SegFormer with TFAutoModelForSemanticSegmentation along with the label mappings, and compile it with the optimizer. Note that Transformers models all have a default task-relevant loss function, so you don’t need to specify one unless you want to:
>>> from transformers import TFAutoModelForSemanticSegmentation
>>> model = TFAutoModelForSemanticSegmentation.from_pretrained(
... checkpoint,
... id2label=id2label,
... label2id=label2id,
... )
>>> model.compile(optimizer=optimizer) # No loss argument!Convert your datasets to the tf.data.Dataset format using the to_tf_dataset and the DefaultDataCollator:
>>> from transformers import DefaultDataCollator
>>> data_collator = DefaultDataCollator(return_tensors="tf")
>>> tf_train_dataset = train_ds.to_tf_dataset(
... columns=["pixel_values", "label"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )
>>> tf_eval_dataset = test_ds.to_tf_dataset(
... columns=["pixel_values", "label"],
... shuffle=True,
... batch_size=batch_size,
... collate_fn=data_collator,
... )To compute the accuracy from the predictions and push your model to the 🤗 Hub, use Keras callbacks.
Pass your compute_metrics function to KerasMetricCallback,
and use the PushToHubCallback to upload the model:
>>> from transformers.keras_callbacks import KerasMetricCallback, PushToHubCallback
>>> metric_callback = KerasMetricCallback(
... metric_fn=compute_metrics, eval_dataset=tf_eval_dataset, batch_size=batch_size, label_cols=["labels"]
... )
>>> push_to_hub_callback = PushToHubCallback(output_dir="scene_segmentation", tokenizer=image_processor)
>>> callbacks = [metric_callback, push_to_hub_callback]Finally, you are ready to train your model! Call fit() with your training and validation datasets, the number of epochs,
and your callbacks to fine-tune the model:
>>> model.fit(
... tf_train_dataset,
... validation_data=tf_eval_dataset,
... callbacks=callbacks,
... epochs=num_epochs,
... )Congratulations! You have fine-tuned your model and shared it on the 🤗 Hub. You can now use it for inference!
Inference
Great, now that you’ve finetuned a model, you can use it for inference!
Reload the dataset and load an image for inference.
>>> from datasets import load_dataset
>>> ds = load_dataset("scene_parse_150", split="train[:50]")
>>> ds = ds.train_test_split(test_size=0.2)
>>> test_ds = ds["test"]
>>> image = ds["test"][0]["image"]
>>> image
We will now see how to infer without a pipeline. Process the image with an image processor and place the pixel_values on a GPU:
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # use GPU if available, otherwise use a CPU
>>> encoding = image_processor(image, return_tensors="pt")
>>> pixel_values = encoding.pixel_values.to(device)Pass your input to the model and return the logits:
>>> outputs = model(pixel_values=pixel_values)
>>> logits = outputs.logits.cpu()Next, rescale the logits to the original image size:
>>> upsampled_logits = nn.functional.interpolate(
... logits,
... size=image.size[::-1],
... mode="bilinear",
... align_corners=False,
... )
>>> pred_seg = upsampled_logits.argmax(dim=1)[0]Load an image processor to preprocess the image and return the input as TensorFlow tensors:
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("MariaK/scene_segmentation")
>>> inputs = image_processor(image, return_tensors="tf")Pass your input to the model and return the logits:
>>> from transformers import TFAutoModelForSemanticSegmentation
>>> model = TFAutoModelForSemanticSegmentation.from_pretrained("MariaK/scene_segmentation")
>>> logits = model(**inputs).logitsNext, rescale the logits to the original image size and apply argmax on the class dimension:
>>> logits = tf.transpose(logits, [0, 2, 3, 1])
>>> upsampled_logits = tf.image.resize(
... logits,
... # We reverse the shape of `image` because `image.size` returns width and height.
... image.size[::-1],
... )
>>> pred_seg = tf.math.argmax(upsampled_logits, axis=-1)[0]To visualize the results, load the dataset color palette as ade_palette() that maps each class to their RGB values.
def ade_palette():
return np.asarray([
[0, 0, 0],
[120, 120, 120],
[180, 120, 120],
[6, 230, 230],
[80, 50, 50],
[4, 200, 3],
[120, 120, 80],
[140, 140, 140],
[204, 5, 255],
[230, 230, 230],
[4, 250, 7],
[224, 5, 255],
[235, 255, 7],
[150, 5, 61],
[120, 120, 70],
[8, 255, 51],
[255, 6, 82],
[143, 255, 140],
[204, 255, 4],
[255, 51, 7],
[204, 70, 3],
[0, 102, 200],
[61, 230, 250],
[255, 6, 51],
[11, 102, 255],
[255, 7, 71],
[255, 9, 224],
[9, 7, 230],
[220, 220, 220],
[255, 9, 92],
[112, 9, 255],
[8, 255, 214],
[7, 255, 224],
[255, 184, 6],
[10, 255, 71],
[255, 41, 10],
[7, 255, 255],
[224, 255, 8],
[102, 8, 255],
[255, 61, 6],
[255, 194, 7],
[255, 122, 8],
[0, 255, 20],
[255, 8, 41],
[255, 5, 153],
[6, 51, 255],
[235, 12, 255],
[160, 150, 20],
[0, 163, 255],
[140, 140, 140],
[250, 10, 15],
[20, 255, 0],
[31, 255, 0],
[255, 31, 0],
[255, 224, 0],
[153, 255, 0],
[0, 0, 255],
[255, 71, 0],
[0, 235, 255],
[0, 173, 255],
[31, 0, 255],
[11, 200, 200],
[255, 82, 0],
[0, 255, 245],
[0, 61, 255],
[0, 255, 112],
[0, 255, 133],
[255, 0, 0],
[255, 163, 0],
[255, 102, 0],
[194, 255, 0],
[0, 143, 255],
[51, 255, 0],
[0, 82, 255],
[0, 255, 41],
[0, 255, 173],
[10, 0, 255],
[173, 255, 0],
[0, 255, 153],
[255, 92, 0],
[255, 0, 255],
[255, 0, 245],
[255, 0, 102],
[255, 173, 0],
[255, 0, 20],
[255, 184, 184],
[0, 31, 255],
[0, 255, 61],
[0, 71, 255],
[255, 0, 204],
[0, 255, 194],
[0, 255, 82],
[0, 10, 255],
[0, 112, 255],
[51, 0, 255],
[0, 194, 255],
[0, 122, 255],
[0, 255, 163],
[255, 153, 0],
[0, 255, 10],
[255, 112, 0],
[143, 255, 0],
[82, 0, 255],
[163, 255, 0],
[255, 235, 0],
[8, 184, 170],
[133, 0, 255],
[0, 255, 92],
[184, 0, 255],
[255, 0, 31],
[0, 184, 255],
[0, 214, 255],
[255, 0, 112],
[92, 255, 0],
[0, 224, 255],
[112, 224, 255],
[70, 184, 160],
[163, 0, 255],
[153, 0, 255],
[71, 255, 0],
[255, 0, 163],
[255, 204, 0],
[255, 0, 143],
[0, 255, 235],
[133, 255, 0],
[255, 0, 235],
[245, 0, 255],
[255, 0, 122],
[255, 245, 0],
[10, 190, 212],
[214, 255, 0],
[0, 204, 255],
[20, 0, 255],
[255, 255, 0],
[0, 153, 255],
[0, 41, 255],
[0, 255, 204],
[41, 0, 255],
[41, 255, 0],
[173, 0, 255],
[0, 245, 255],
[71, 0, 255],
[122, 0, 255],
[0, 255, 184],
[0, 92, 255],
[184, 255, 0],
[0, 133, 255],
[255, 214, 0],
[25, 194, 194],
[102, 255, 0],
[92, 0, 255],
])Then you can combine and plot your image and the predicted segmentation map:
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> color_seg = np.zeros((pred_seg.shape[0], pred_seg.shape[1], 3), dtype=np.uint8)
>>> palette = np.array(ade_palette())
>>> for label, color in enumerate(palette):
... color_seg[pred_seg == label, :] = color
>>> color_seg = color_seg[..., ::-1] # convert to BGR
>>> img = np.array(image) * 0.5 + color_seg * 0.5 # plot the image with the segmentation map
>>> img = img.astype(np.uint8)
>>> plt.figure(figsize=(15, 10))
>>> plt.imshow(img)
>>> plt.show()