Transformers documentation
Hubert
Hubert
Overview
Hubert was proposed in HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
The abstract from the paper is the following:
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
This model was contributed by patrickvonplaten.
Usage tips
- Hubert is a speech model that accepts a float array corresponding to the raw waveform of the speech signal.
- Hubert model was fine-tuned using connectionist temporal classification (CTC) so the model output has to be decoded using Wav2Vec2CTCTokenizer.
Using Flash Attention 2
Flash Attention 2 is an faster, optimized version of the model.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation. If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered above.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
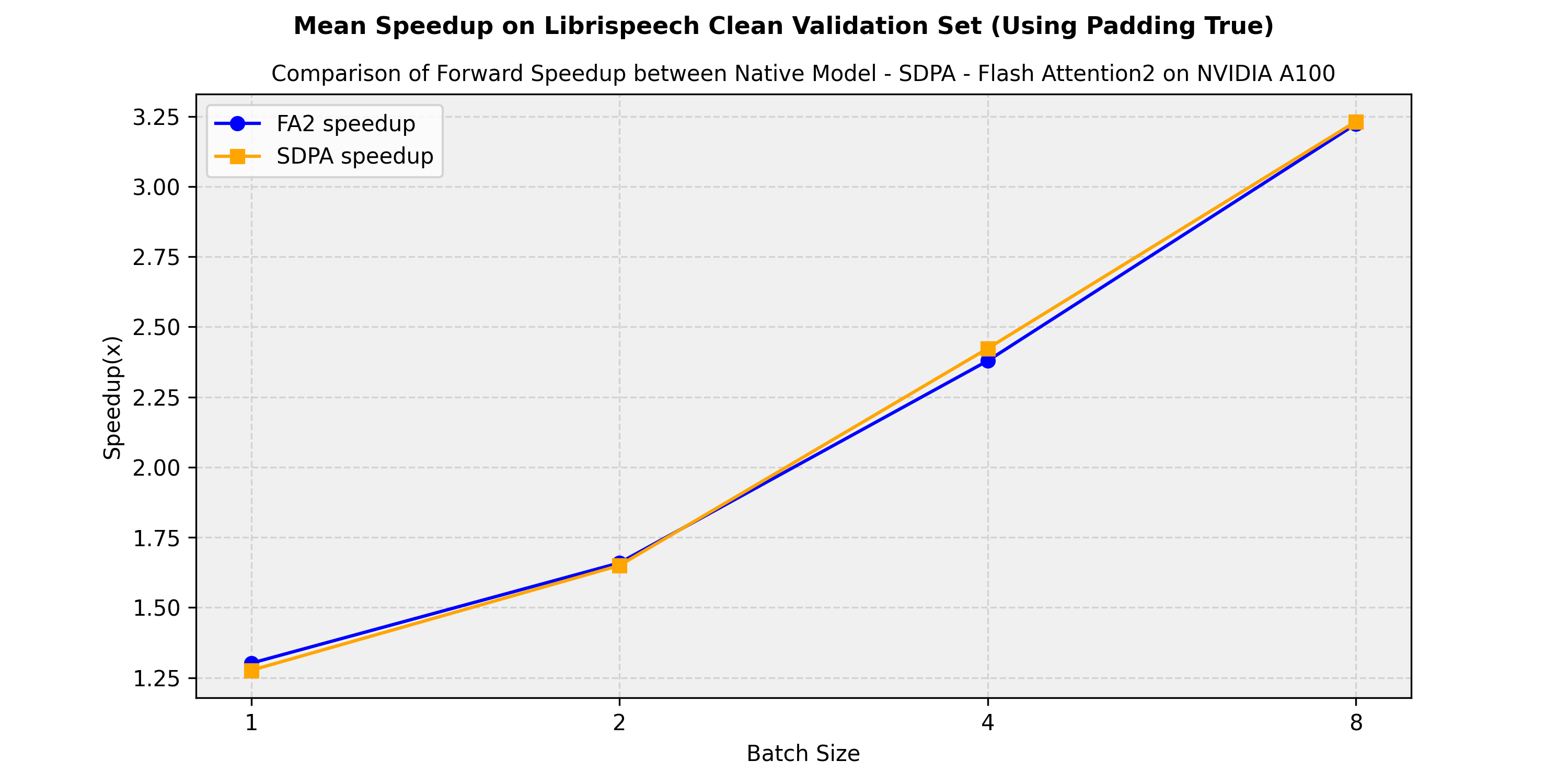
Below is an expected speedup diagram comparing the pure inference time between the native implementation in transformers of facebook/hubert-large-ls960-ft, the flash-attention-2 and the sdpa (scale-dot-product-attention) version. We show the average speedup obtained on the librispeech_asr clean validation split:
>>> from transformers import Wav2Vec2Model
model = Wav2Vec2Model.from_pretrained("facebook/hubert-large-ls960-ft", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
...Expected speedups
Below is an expected speedup diagram comparing the pure inference time between the native implementation in transformers of the facebook/hubert-large-ls960-ft model and the flash-attention-2 and sdpa (scale-dot-product-attention) versions. . We show the average speedup obtained on the librispeech_asr clean validation split:
Resources
HubertConfig
class transformers.HubertConfig
< source >( vocab_size = 32 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout = 0.1 activation_dropout = 0.1 attention_dropout = 0.1 feat_proj_layer_norm = True feat_proj_dropout = 0.0 final_dropout = 0.1 layerdrop = 0.1 initializer_range = 0.02 layer_norm_eps = 1e-05 feat_extract_norm = 'group' feat_extract_activation = 'gelu' conv_dim = (512, 512, 512, 512, 512, 512, 512) conv_stride = (5, 2, 2, 2, 2, 2, 2) conv_kernel = (10, 3, 3, 3, 3, 2, 2) conv_bias = False num_conv_pos_embeddings = 128 num_conv_pos_embedding_groups = 16 do_stable_layer_norm = False apply_spec_augment = True mask_time_prob = 0.05 mask_time_length = 10 mask_time_min_masks = 2 mask_feature_prob = 0.0 mask_feature_length = 10 mask_feature_min_masks = 0 ctc_loss_reduction = 'sum' ctc_zero_infinity = False use_weighted_layer_sum = False classifier_proj_size = 256 pad_token_id = 0 bos_token_id = 1 eos_token_id = 2 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 32) — Vocabulary size of the Hubert model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling HubertModel. Vocabulary size of the model. Defines the different tokens that can be represented by the inputs_ids passed to the forward method of HubertModel. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"are supported. - hidden_dropout(
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - activation_dropout (
float, optional, defaults to 0.1) — The dropout ratio for activations inside the fully connected layer. - attention_dropout(
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. - final_dropout (
float, optional, defaults to 0.1) — The dropout probability for the final projection layer of Wav2Vec2ForCTC. - layerdrop (
float, optional, defaults to 0.1) — The LayerDrop probability. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. - feat_extract_norm (
str, optional, defaults to"group") — The norm to be applied to 1D convolutional layers in feature encoder. One of"group"for group normalization of only the first 1D convolutional layer or"layer"for layer normalization of all 1D convolutional layers. - feat_proj_dropout (
float, optional, defaults to 0.0) — The dropout probability for output of the feature encoder. - feat_proj_layer_norm (
bool, optional, defaults toTrue) — Whether to apply LayerNorm to the output of the feature encoder. - feat_extract_activation (
str,optional, defaults to“gelu”) -- The non-linear activation function (function or string) in the 1D convolutional layers of the feature extractor. If string,“gelu”,“relu”,“selu”and“gelu_new”` are supported. - conv_dim (
Tuple[int], optional, defaults to(512, 512, 512, 512, 512, 512, 512)) — A tuple of integers defining the number of input and output channels of each 1D convolutional layer in the feature encoder. The length of conv_dim defines the number of 1D convolutional layers. - conv_stride (
Tuple[int], optional, defaults to(5, 2, 2, 2, 2, 2, 2)) — A tuple of integers defining the stride of each 1D convolutional layer in the feature encoder. The length of conv_stride defines the number of convolutional layers and has to match the length of conv_dim. - conv_kernel (
Tuple[int], optional, defaults to(10, 3, 3, 3, 3, 3, 3)) — A tuple of integers defining the kernel size of each 1D convolutional layer in the feature encoder. The length of conv_kernel defines the number of convolutional layers and has to match the length of conv_dim. - conv_bias (
bool, optional, defaults toFalse) — Whether the 1D convolutional layers have a bias. - num_conv_pos_embeddings (
int, optional, defaults to 128) — Number of convolutional positional embeddings. Defines the kernel size of 1D convolutional positional embeddings layer. - num_conv_pos_embedding_groups (
int, optional, defaults to 16) — Number of groups of 1D convolutional positional embeddings layer. - do_stable_layer_norm (
bool, optional, defaults toFalse) — Whether do apply stable layer norm architecture of the Transformer encoder.do_stable_layer_norm is Truecorresponds to applying layer norm before the attention layer, whereasdo_stable_layer_norm is Falsecorresponds to applying layer norm after the attention layer. - apply_spec_augment (
bool, optional, defaults toTrue) — Whether to apply SpecAugment data augmentation to the outputs of the feature encoder. For reference see SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. - mask_time_prob (
float, optional, defaults to 0.05) — Percentage (between 0 and 1) of all feature vectors along the time axis which will be masked. The masking procecure generates ”mask_time_problen(time_axis)/mask_time_length” independent masks over the axis. If reasoning from the propability of each feature vector to be chosen as the start of the vector span to be masked, mask_time_prob should be `prob_vector_startmask_time_length. Note that overlap may decrease the actual percentage of masked vectors. This is only relevant ifapply_spec_augment is True`. - mask_time_length (
int, optional, defaults to 10) — Length of vector span along the time axis. - mask_time_min_masks (
int, optional, defaults to 2), — The minimum number of masks of lengthmask_feature_lengthgenerated along the time axis, each time step, irrespectively ofmask_feature_prob. Only relevant if ”mask_time_prob*len(time_axis)/mask_time_length < mask_time_min_masks” - mask_feature_prob (
float, optional, defaults to 0.0) — Percentage (between 0 and 1) of all feature vectors along the feature axis which will be masked. The masking procecure generates ”mask_feature_problen(feature_axis)/mask_time_length” independent masks over the axis. If reasoning from the propability of each feature vector to be chosen as the start of the vector span to be masked, mask_feature_prob should be `prob_vector_startmask_feature_length. Note that overlap may decrease the actual percentage of masked vectors. This is only relevant ifapply_spec_augment is True`. - mask_feature_length (
int, optional, defaults to 10) — Length of vector span along the feature axis. - mask_feature_min_masks (
int, optional, defaults to 0), — The minimum number of masks of lengthmask_feature_lengthgenerated along the feature axis, each time step, irrespectively ofmask_feature_prob. Only relevant if ”mask_feature_prob*len(feature_axis)/mask_feature_length < mask_feature_min_masks” - ctc_loss_reduction (
str, optional, defaults to"sum") — Specifies the reduction to apply to the output oftorch.nn.CTCLoss. Only relevant when training an instance of HubertForCTC. - ctc_zero_infinity (
bool, optional, defaults toFalse) — Whether to zero infinite losses and the associated gradients oftorch.nn.CTCLoss. Infinite losses mainly occur when the inputs are too short to be aligned to the targets. Only relevant when training an instance of HubertForCTC. - use_weighted_layer_sum (
bool, optional, defaults toFalse) — Whether to use a weighted average of layer outputs with learned weights. Only relevant when using an instance of HubertForSequenceClassification. - classifier_proj_size (
int, optional, defaults to 256) — Dimensionality of the projection before token mean-pooling for classification.
This is the configuration class to store the configuration of a HubertModel. It is used to instantiate an Hubert model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Hubert facebook/hubert-base-ls960 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import HubertModel, HubertConfig
>>> # Initializing a Hubert facebook/hubert-base-ls960 style configuration
>>> configuration = HubertConfig()
>>> # Initializing a model from the facebook/hubert-base-ls960 style configuration
>>> model = HubertModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configHubertModel
class transformers.HubertModel
< source >( config: HubertConfig )
Parameters
- config (HubertConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Hubert Model transformer outputting raw hidden-states without any specific head on top. Hubert was proposed in HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None mask_time_indices: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as hubert-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (HubertConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The HubertModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, HubertModel
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="pt").input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateHubertForCTC
class transformers.HubertForCTC
< source >( config target_lang: Optional = None )
Parameters
- config (HubertConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Hubert Model with a language modeling head on top for Connectionist Temporal Classification (CTC).
Hubert was proposed in HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden
Units by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia,
Ruslan Salakhutdinov, Abdelrahman Mohamed.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.CausalLMOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as hubert-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, target_length), optional) — Labels for connectionist temporal classification. Note thattarget_lengthhas to be smaller or equal to the sequence length of the output logits. Indices are selected in[-100, 0, ..., config.vocab_size - 1]. All labels set to-100are ignored (masked), the loss is only computed for labels in[0, ..., config.vocab_size - 1].
Returns
transformers.modeling_outputs.CausalLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (HubertConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The HubertForCTC forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, HubertForCTC
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = HubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
'MISTER QUILTER IS THE APOSTLE OF THE MIDDLE CLASSES AND WE ARE GLAD TO WELCOME HIS GOSPEL'
>>> inputs["labels"] = processor(text=dataset[0]["text"], return_tensors="pt").input_ids
>>> # compute loss
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
22.68HubertForSequenceClassification
class transformers.HubertForSequenceClassification
< source >( config )
Parameters
- config (HubertConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Hubert Model with a sequence classification head on top (a linear layer over the pooled output) for tasks like SUPERB Keyword Spotting.
Hubert was proposed in HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units by Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, Abdelrahman Mohamed.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving etc.).
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_values: Optional attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_values (
torch.FloatTensorof shape(batch_size, sequence_length)) — Float values of input raw speech waveform. Values can be obtained by loading a.flacor.wavaudio file into an array of typeList[float]or anumpy.ndarray, e.g. via the soundfile library (pip install soundfile). To prepare the array intoinput_values, the AutoProcessor should be used for padding and conversion into a tensor of typetorch.FloatTensor. See Wav2Vec2Processor.call() for details. - attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing convolution and attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
attention_maskshould only be passed if the corresponding processor hasconfig.return_attention_mask == True. For all models whose processor hasconfig.return_attention_mask == False, such as hubert-base,attention_maskshould not be passed to avoid degraded performance when doing batched inference. For such modelsinput_valuesshould simply be padded with 0 and passed withoutattention_mask. Be aware that these models also yield slightly different results depending on whetherinput_valuesis padded or not. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (HubertConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The HubertForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoFeatureExtractor, HubertForSequenceClassification
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation", trust_remote_code=True)
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("superb/hubert-base-superb-ks")
>>> model = HubertForSequenceClassification.from_pretrained("superb/hubert-base-superb-ks")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'_unknown_'
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
8.53TFHubertModel
class transformers.TFHubertModel
< source >( config: HubertConfig *inputs **kwargs )
Parameters
- config (HubertConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare TFHubert Model transformer outputing raw hidden-states without any specific head on top.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_valuesonly and nothing else:model(input_values) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_values, attention_mask])ormodel([input_values, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_values": input_values, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: bool = False ) → transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
Parameters
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_valuesyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_valuesindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation).
Returns
transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFBaseModelOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (HubertConfig) and inputs.
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
hidden_states (
tuple(tf.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFHubertModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, TFHubertModel
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = TFHubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> hidden_states = model(input_values).last_hidden_stateTFHubertForCTC
class transformers.TFHubertForCTC
< source >( config: HubertConfig *inputs **kwargs )
Parameters
- config (HubertConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
TFHubert Model with a language modeling head on top for Connectionist Temporal Classification (CTC).
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_valuesonly and nothing else:model(input_values) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_values, attention_mask])ormodel([input_values, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_values": input_values, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_values: tf.Tensor attention_mask: tf.Tensor | None = None token_type_ids: tf.Tensor | None = None position_ids: tf.Tensor | None = None head_mask: tf.Tensor | None = None inputs_embeds: tf.Tensor | None = None output_attentions: Optional[bool] = None labels: tf.Tensor | None = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFCausalLMOutput or tuple(tf.Tensor)
Parameters
- input_values (
np.ndarray,tf.Tensor,List[tf.Tensor]Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape({0})) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape({0}), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
np.ndarrayortf.Tensorof shape({0}), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape({0}, hidden_size), optional) — Optionally, instead of passinginput_valuesyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_valuesindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation). - labels (
tf.Tensorornp.ndarrayof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_valuesdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_tf_outputs.TFCausalLMOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFCausalLMOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (HubertConfig) and inputs.
-
loss (
tf.Tensorof shape(n,), optional, where n is the number of non-masked labels, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFHubertForCTC forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> import tensorflow as tf
>>> from transformers import AutoProcessor, TFHubertForCTC
>>> from datasets import load_dataset
>>> import soundfile as sf
>>> processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
>>> model = TFHubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft")
>>> def map_to_array(batch):
... speech, _ = sf.read(batch["file"])
... batch["speech"] = speech
... return batch
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> ds = ds.map(map_to_array)
>>> input_values = processor(ds["speech"][0], return_tensors="tf").input_values # Batch size 1
>>> logits = model(input_values).logits
>>> predicted_ids = tf.argmax(logits, axis=-1)
>>> transcription = processor.decode(predicted_ids[0])
>>> # compute loss
>>> target_transcription = "A MAN SAID TO THE UNIVERSE SIR I EXIST"
>>> # Pass the transcription as text to encode labels
>>> labels = processor(text=transcription, return_tensors="tf").input_values
>>> loss = model(input_values, labels=labels).loss