Transformers documentation
DiT
DiT
Overview
DiT was proposed in DiT: Self-supervised Pre-training for Document Image Transformer by Junlong Li, Yiheng Xu, Tengchao Lv, Lei Cui, Cha Zhang, Furu Wei. DiT applies the self-supervised objective of BEiT (BERT pre-training of Image Transformers) to 42 million document images, allowing for state-of-the-art results on tasks including:
- document image classification: the RVL-CDIP dataset (a collection of 400,000 images belonging to one of 16 classes).
- document layout analysis: the PubLayNet dataset (a collection of more than 360,000 document images constructed by automatically parsing PubMed XML files).
- table detection: the ICDAR 2019 cTDaR dataset (a collection of 600 training images and 240 testing images).
The abstract from the paper is the following:
Image Transformer has recently achieved significant progress for natural image understanding, either using supervised (ViT, DeiT, etc.) or self-supervised (BEiT, MAE, etc.) pre-training techniques. In this paper, we propose DiT, a self-supervised pre-trained Document Image Transformer model using large-scale unlabeled text images for Document AI tasks, which is essential since no supervised counterparts ever exist due to the lack of human labeled document images. We leverage DiT as the backbone network in a variety of vision-based Document AI tasks, including document image classification, document layout analysis, as well as table detection. Experiment results have illustrated that the self-supervised pre-trained DiT model achieves new state-of-the-art results on these downstream tasks, e.g. document image classification (91.11 → 92.69), document layout analysis (91.0 → 94.9) and table detection (94.23 → 96.55).
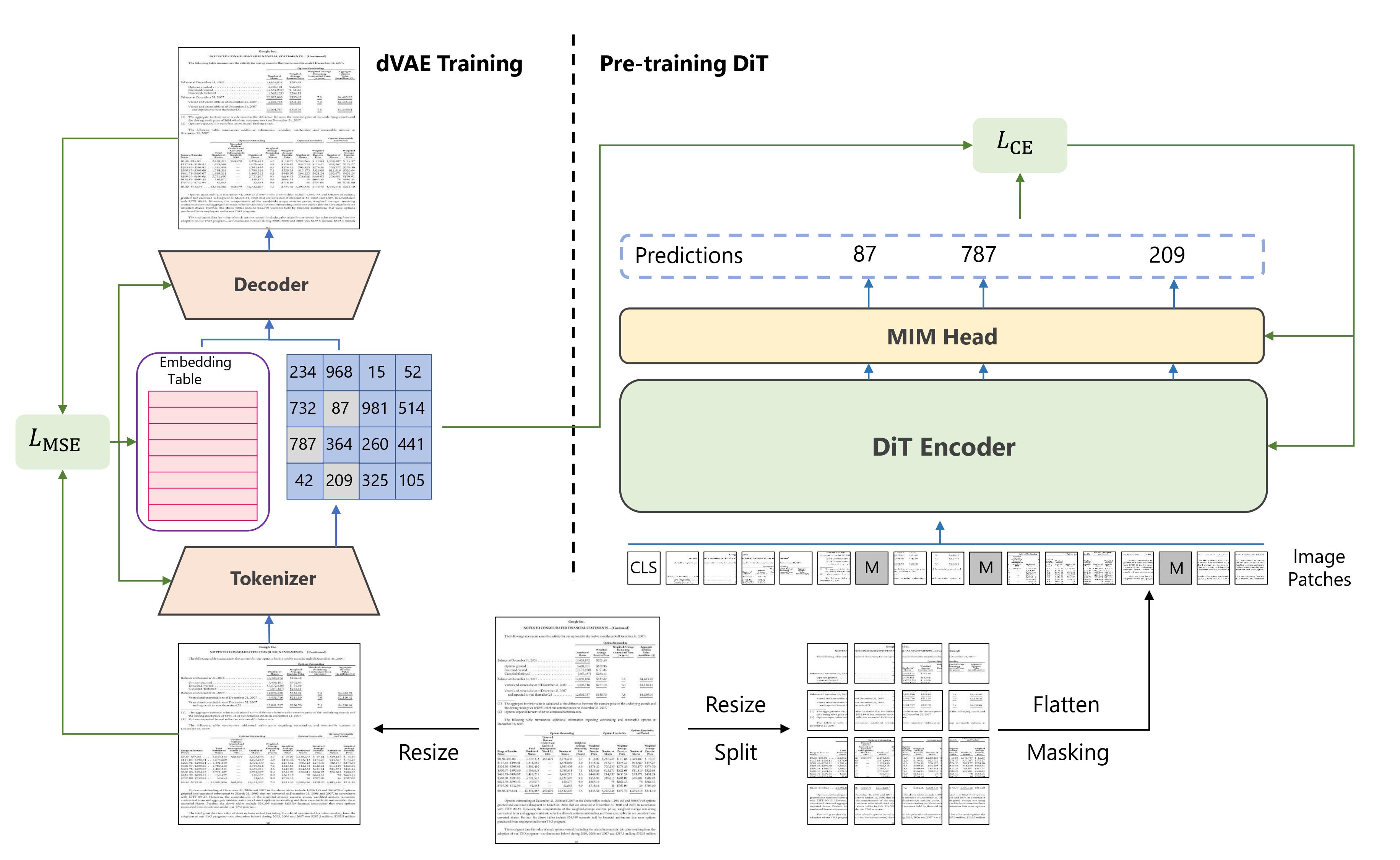 Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378).
Summary of the approach. Taken from the [original paper](https://arxiv.org/abs/2203.02378). This model was contributed by nielsr. The original code can be found here.
Usage tips
One can directly use the weights of DiT with the AutoModel API:
from transformers import AutoModel
model = AutoModel.from_pretrained("microsoft/dit-base")This will load the model pre-trained on masked image modeling. Note that this won’t include the language modeling head on top, used to predict visual tokens.
To include the head, you can load the weights into a BeitForMaskedImageModeling model, like so:
from transformers import BeitForMaskedImageModeling
model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")You can also load a fine-tuned model from the hub, like so:
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")This particular checkpoint was fine-tuned on RVL-CDIP, an important benchmark for document image classification. A notebook that illustrates inference for document image classification can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DiT.
- BeitForImageClassification is supported by this example script and notebook.
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
As DiT’s architecture is equivalent to that of BEiT, one can refer to BEiT’s documentation page for all tips, code examples and notebooks.