Text generation strategies
Text generation is essential to many NLP tasks, such as open-ended text generation, summarization, translation, and more. It also plays a role in a variety of mixed-modality applications that have text as an output like speech-to-text and vision-to-text. Some of the models that can generate text include GPT2, XLNet, OpenAI GPT, CTRL, TransformerXL, XLM, Bart, T5, GIT, Whisper.
Check out a few examples that use generate() method to produce text outputs for different tasks:
Note that the inputs to the generate method depend on the model’s modality. They are returned by the model’s preprocessor class, such as AutoTokenizer or AutoProcessor. If a model’s preprocessor creates more than one kind of input, pass all the inputs to generate(). You can learn more about the individual model’s preprocessor in the corresponding model’s documentation.
The process of selecting output tokens to generate text is known as decoding, and you can customize the decoding strategy
that the generate() method will use. Modifying a decoding strategy does not change the values of any trainable parameters.
However, it can have a noticeable impact on the quality of the generated output. It can help reduce repetition in the text
and make it more coherent.
This guide describes:
- default generation configuration
- common decoding strategies and their main parameters
- saving and sharing custom generation configurations with your fine-tuned model on 🤗 Hub
Default text generation configuration
A decoding strategy for a model is defined in its generation configuration. When using pre-trained models for inference
within a pipeline(), the models call the PreTrainedModel.generate() method that applies a default generation
configuration under the hood. The default configuration is also used when no custom configuration has been saved with
the model.
When you load a model explicitly, you can inspect the generation configuration that comes with it through
model.generation_config:
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
>>> model.generation_config
GenerationConfig {
"bos_token_id": 50256,
"eos_token_id": 50256
}
<BLANKLINE>Printing out the model.generation_config reveals only the values that are different from the default generation
configuration, and does not list any of the default values.
The default generation configuration limits the size of the output combined with the input prompt to a maximum of 20 tokens to avoid running into resource limitations. The default decoding strategy is greedy search, which is the simplest decoding strategy that picks a token with the highest probability as the next token. For many tasks and small output sizes this works well. However, when used to generate longer outputs, greedy search can start producing highly repetitive results.
Customize text generation
You can override any generation_config by passing the parameters and their values directly to the generate method:
>>> my_model.generate(**inputs, num_beams=4, do_sample=True)Even if the default decoding strategy mostly works for your task, you can still tweak a few things. Some of the commonly adjusted parameters include:
max_new_tokens: the maximum number of tokens to generate. In other words, the size of the output sequence, not including the tokens in the prompt. As an alternative to using the output’s length as a stopping criteria, you can choose to stop generation whenever the full generation exceeds some amount of time. To learn more, check StoppingCriteria.num_beams: by specifying a number of beams higher than 1, you are effectively switching from greedy search to beam search. This strategy evaluates several hypotheses at each time step and eventually chooses the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability sequences that start with a lower probability initial tokens and would’ve been ignored by the greedy search. Visualize how it works here.do_sample: if set toTrue, this parameter enables decoding strategies such as multinomial sampling, beam-search multinomial sampling, Top-K sampling and Top-p sampling. All these strategies select the next token from the probability distribution over the entire vocabulary with various strategy-specific adjustments.num_return_sequences: the number of sequence candidates to return for each input. This option is only available for the decoding strategies that support multiple sequence candidates, e.g. variations of beam search and sampling. Decoding strategies like greedy search and contrastive search return a single output sequence.
Save a custom decoding strategy with your model
If you would like to share your fine-tuned model with a specific generation configuration, you can:
- Create a GenerationConfig class instance
- Specify the decoding strategy parameters
- Save your generation configuration with GenerationConfig.save_pretrained(), making sure to leave its
config_file_nameargument empty - Set
push_to_hubtoTrueto upload your config to the model’s repo
>>> from transformers import AutoModelForCausalLM, GenerationConfig
>>> model = AutoModelForCausalLM.from_pretrained("my_account/my_model")
>>> generation_config = GenerationConfig(
... max_new_tokens=50, do_sample=True, top_k=50, eos_token_id=model.config.eos_token_id
... )
>>> generation_config.save_pretrained("my_account/my_model", push_to_hub=True)You can also store several generation configurations in a single directory, making use of the config_file_name
argument in GenerationConfig.save_pretrained(). You can later instantiate them with GenerationConfig.from_pretrained(). This is useful if you want to
store several generation configurations for a single model (e.g. one for creative text generation with sampling, and
one for summarization with beam search). You must have the right Hub permissions to add configuration files to a model.
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, GenerationConfig
>>> tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-small")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-small")
>>> translation_generation_config = GenerationConfig(
... num_beams=4,
... early_stopping=True,
... decoder_start_token_id=0,
... eos_token_id=model.config.eos_token_id,
... pad_token=model.config.pad_token_id,
... )
>>> # Tip: add `push_to_hub=True` to push to the Hub
>>> translation_generation_config.save_pretrained("/tmp", "translation_generation_config.json")
>>> # You could then use the named generation config file to parameterize generation
>>> generation_config = GenerationConfig.from_pretrained("/tmp", "translation_generation_config.json")
>>> inputs = tokenizer("translate English to French: Configuration files are easy to use!", return_tensors="pt")
>>> outputs = model.generate(**inputs, generation_config=generation_config)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Les fichiers de configuration sont faciles à utiliser!']Streaming
The generate() supports streaming, through its streamer input. The streamer input is compatible with any instance
from a class that has the following methods: put() and end(). Internally, put() is used to push new tokens and
end() is used to flag the end of text generation.
The API for the streamer classes is still under development and may change in the future.
In practice, you can craft your own streaming class for all sorts of purposes! We also have basic streaming classes
ready for you to use. For example, you can use the TextStreamer class to stream the output of generate() into
your screen, one word at a time:
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
>>> tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
>>> streamer = TextStreamer(tok)
>>> # Despite returning the usual output, the streamer will also print the generated text to stdout.
>>> _ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
An increasing sequence: one, two, three, four, five, six, seven, eight, nine, ten, eleven,Watermarking
The generate() supports watermarking the generated text by randomly marking a portion of tokens as “green”.
When generating the “green” will have a small ‘bias’ value added to their logits, thus having a higher chance to be generated.
The watermarked text can be detected by calculating the proportion of “green” tokens in the text and estimating how likely it is
statistically to obtain that amount of “green” tokens for human-generated text. This watermarking strategy was proposed in the paper
“On the Reliability of Watermarks for Large Language Models”. For more information on
the inner functioning of watermarking, it is recommended to refer to the paper.
The watermarking can be used with any generative model in tranformers and does not require an extra classification model
to detect watermarked text. To trigger watermarking, pass in a WatermarkingConfig with needed arguments directly to the
.generate() method or add it to the GenerationConfig. Watermarked text can be later detected with a WatermarkDetector.
The WatermarkDetector internally relies on the proportion of “green” tokens, and whether generated text follows the coloring pattern. That is why it is recommended to strip off the prompt text, if it is much longer than the generated text. This also can have an effect when one sequence in the batch is a lot longer causing other rows to be padded. Additionally, the detector must be initiated with identical watermark configuration arguments used when generating.
Let’s generate some text with watermarking. In the below code snippet, we set the bias to 2.5 which is a value that
will be added to “green” tokens’ logits. After generating watermarked text, we can pass it directly to the WatermarkDetector
to check if the text is machine-generated (outputs True for machine-generated and False otherwise).
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, WatermarkDetector, WatermarkingConfig
>>> model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> tok = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> tok.pad_token_id = tok.eos_token_id
>>> tok.padding_side = "left"
>>> inputs = tok(["This is the beginning of a long story", "Alice and Bob are"], padding=True, return_tensors="pt")
>>> input_len = inputs["input_ids"].shape[-1]
>>> watermarking_config = WatermarkingConfig(bias=2.5, seeding_scheme="selfhash")
>>> out = model.generate(**inputs, watermarking_config=watermarking_config, do_sample=False, max_length=20)
>>> detector = WatermarkDetector(model_config=model.config, device="cpu", watermarking_config=watermarking_config)
>>> detection_out = detector(out, return_dict=True)
>>> detection_out.prediction
array([True, True])Decoding strategies
Certain combinations of the generate() parameters, and ultimately generation_config, can be used to enable specific
decoding strategies. If you are new to this concept, we recommend reading this blog post that illustrates how common decoding strategies work.
Here, we’ll show some of the parameters that control the decoding strategies and illustrate how you can use them.
Greedy Search
generate uses greedy search decoding by default so you don’t have to pass any parameters to enable it. This means the parameters num_beams is set to 1 and do_sample=False.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "I look forward to"
>>> checkpoint = "distilbert/distilgpt2"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['I look forward to seeing you all again!\n\n\n\n\n\n\n\n\n\n\n']Contrastive search
The contrastive search decoding strategy was proposed in the 2022 paper A Contrastive Framework for Neural Text Generation.
It demonstrates superior results for generating non-repetitive yet coherent long outputs. To learn how contrastive search
works, check out this blog post.
The two main parameters that enable and control the behavior of contrastive search are penalty_alpha and top_k:
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> checkpoint = "openai-community/gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Hugging Face Company is"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Hugging Face Company is a family owned and operated business. We pride ourselves on being the best
in the business and our customer service is second to none.\n\nIf you have any questions about our
products or services, feel free to contact us at any time. We look forward to hearing from you!']Multinomial sampling
As opposed to greedy search that always chooses a token with the highest probability as the next token, multinomial sampling (also called ancestral sampling) randomly selects the next token based on the probability distribution over the entire vocabulary given by the model. Every token with a non-zero probability has a chance of being selected, thus reducing the risk of repetition.
To enable multinomial sampling set do_sample=True and num_beams=1.
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> set_seed(0) # For reproducibility
>>> checkpoint = "openai-community/gpt2-large"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> prompt = "Today was an amazing day because"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
["Today was an amazing day because we received these wonderful items by the way of a gift shop. The box arrived on a Thursday and I opened it on Monday afternoon to receive the gifts. Both bags featured pieces from all the previous years!\n\nThe box had lots of surprises in it, including some sweet little mini chocolate chips! I don't think I'd eat all of these. This was definitely one of the most expensive presents I have ever got, I actually got most of them for free!\n\nThe first package came"]Beam-search decoding
Unlike greedy search, beam-search decoding keeps several hypotheses at each time step and eventually chooses the hypothesis that has the overall highest probability for the entire sequence. This has the advantage of identifying high-probability sequences that start with lower probability initial tokens and would’ve been ignored by the greedy search.
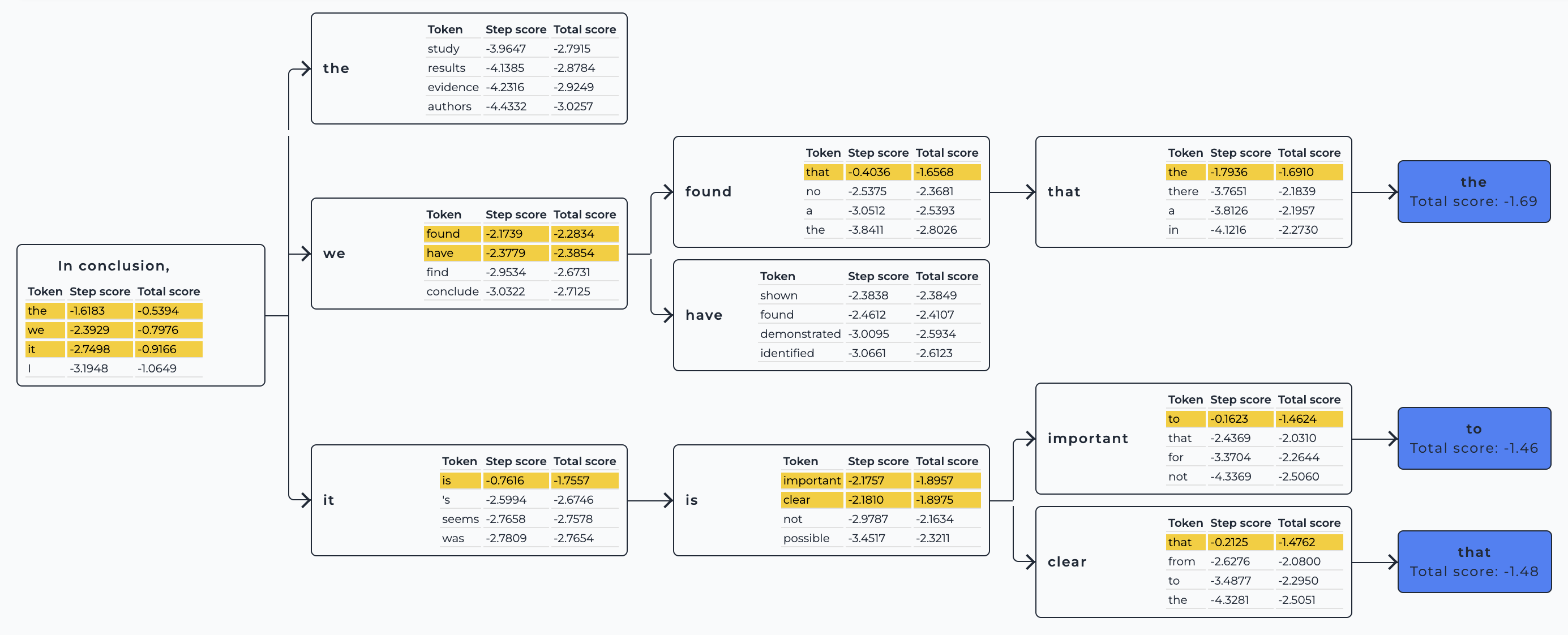
You can visualize how beam-search decoding works in this interactive demo: type your input sentence, and play with the parameters to see how the decoding beams change.
To enable this decoding strategy, specify the num_beams (aka number of hypotheses to keep track of) that is greater than 1.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "It is astonishing how one can"
>>> checkpoint = "openai-community/gpt2-medium"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']Beam-search multinomial sampling
As the name implies, this decoding strategy combines beam search with multinomial sampling. You need to specify
the num_beams greater than 1, and set do_sample=True to use this decoding strategy.
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
>>> set_seed(0) # For reproducibility
>>> prompt = "translate English to German: The house is wonderful."
>>> checkpoint = "google-t5/t5-small"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'Das Haus ist wunderbar.'Diverse beam search decoding
The diverse beam search decoding strategy is an extension of the beam search strategy that allows for generating a more diverse
set of beam sequences to choose from. To learn how it works, refer to Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models.
This approach has three main parameters: num_beams, num_beam_groups, and diversity_penalty.
The diversity penalty ensures the outputs are distinct across groups, and beam search is used within each group.
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> checkpoint = "google/pegasus-xsum"
>>> prompt = (
... "The Permaculture Design Principles are a set of universal design principles "
... "that can be applied to any location, climate and culture, and they allow us to design "
... "the most efficient and sustainable human habitation and food production systems. "
... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
... "as ecology, landscape design, environmental science and energy conservation, and the "
... "Permaculture design principles are drawn from these various disciplines. Each individual "
... "design principle itself embodies a complete conceptual framework based on sound "
... "scientific principles. When we bring all these separate principles together, we can "
... "create a design system that both looks at whole systems, the parts that these systems "
... "consist of, and how those parts interact with each other to create a complex, dynamic, "
... "living system. Each design principle serves as a tool that allows us to integrate all "
... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
... "whole system, where the elements harmoniously interact and work together in the most "
... "efficient way possible."
... )
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
'The Design Principles are a set of universal design principles that can be applied to any location, climate and
culture, and they allow us to design the'This guide illustrates the main parameters that enable various decoding strategies. More advanced parameters exist for the
generate method, which gives you even further control over the generate method’s behavior.
For the complete list of the available parameters, refer to the API documentation.
Speculative Decoding
Speculative decoding (also known as assisted decoding) is a modification of the decoding strategies above, that uses an
assistant model (ideally a much smaller one) with the same tokenizer, to generate a few candidate tokens. The main
model then validates the candidate tokens in a single forward pass, which speeds up the decoding process. If
do_sample=True, then the token validation with resampling introduced in the
speculative decoding paper is used.
Currently, only greedy search and sampling are supported with assisted decoding, and assisted decoding doesn’t support batched inputs. To learn more about assisted decoding, check this blog post.
To enable assisted decoding, set the assistant_model argument with a model.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']When using assisted decoding with sampling methods, you can use the temperature argument to control the randomness,
just like in multinomial sampling. However, in assisted decoding, reducing the temperature may help improve the latency.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
>>> set_seed(42) # For reproducibility
>>> prompt = "Alice and Bob"
>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Alice and Bob, a couple of friends of mine, who are both in the same office as']Alternativelly, you can also set the prompt_lookup_num_tokens to trigger n-gram based assisted decoding, as opposed
to model based assisted decoding. You can read more about it here.
DoLa Decoding
Decoding by Contrasting Layers (DoLa) is a contrastive decoding strategy to improve the factuality and reduce the hallucinations of LLMs, as described in this paper of ICLR 2024 DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models.
DoLa is achieved by contrasting the differences in logits obtained from final layers versus earlier layers, thus amplify the factual knowledge localized to particular part of transformer layers.
Do the following two steps to activate DoLa decoding when calling the model.generate function:
- Set the
dola_layersargument, which can be either a string or a list of integers.- If set to a string, it can be one of
low,high. - If set to a list of integers, it should be a list of layer indices between 0 and the total number of layers in the model. The 0-th layer is word embedding, and the 1st layer is the first transformer layer, and so on.
- If set to a string, it can be one of
- Set
repetition_penalty = 1.2is suggested to reduce repetition in DoLa decoding.
See the following examples for DoLa decoding with the 32-layer LLaMA-7B model.
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
>>> model = AutoModelForCausalLM.from_pretrained("huggyllama/llama-7b", torch_dtype=torch.float16)
>>> device = 'cuda' if torch.cuda.is_available() else 'cpu'
>>> model.to(device)
>>> set_seed(42)
>>> text = "On what date was the Declaration of Independence officially signed?"
>>> inputs = tokenizer(text, return_tensors="pt").to(device)
# Vanilla greddy decoding
>>> vanilla_output = model.generate(**inputs, do_sample=False, max_new_tokens=50)
>>> tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
['\nThe Declaration of Independence was signed on July 4, 1776.\nWhat was the date of the signing of the Declaration of Independence?\nThe Declaration of Independence was signed on July 4,']
# DoLa decoding with contrasting higher part of layers (layers 16,18,...,30)
>>> dola_high_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers='high')
>>> tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
['\nJuly 4, 1776, when the Continental Congress voted to separate from Great Britain. The 56 delegates to the Continental Congress signed the Declaration on August 2, 1776.']
# DoLa decoding with contrasting specific layers (layers 28 and 30)
>>> dola_custom_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers=[28,30], repetition_penalty=1.2)
>>> tokenizer.batch_decode(dola_custom_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
['\nIt was officially signed on 2 August 1776, when 56 members of the Second Continental Congress, representing the original 13 American colonies, voted unanimously for the resolution for independence. The 2']Understanding the dola_layers argument
dola_layers stands for the candidate layers in premature layer selection, as described in the DoLa paper. The selected premature layer will be contrasted with the final layer.
Setting dola_layers to 'low' or 'high' will select the lower or higher part of the layers to contrast, respectively.
- For
N-layer models withN <= 40layers, the layers ofrange(0, N // 2, 2)andrange(N // 2, N, 2)are used for'low'and'high'layers, respectively. - For models with
N > 40layers, the layers ofrange(0, 20, 2)andrange(N - 20, N, 2)are used for'low'and'high'layers, respectively. - If the model has tied word embeddings, we skip the word embeddings (0-th) layer and start from the 2nd layer, as the early exit from word embeddings will become identity function.
- Set the
dola_layersto a list of integers for layer indices to contrast manually specified layers. For example, settingdola_layers=[28,30]will contrast the final layer (32-th layer) with the 28-th and 30-th layers.
The paper suggested that contrasting 'high' layers to improve short-answer tasks like TruthfulQA, and contrasting 'low' layers to improve all the other long-answer reasoning tasks, such as GSM8K, StrategyQA, FACTOR, and VicunaQA. Applying DoLa to smaller models like GPT-2 is not recommended, as the results shown in the Appendix N of the paper.