Transformers documentation
ImageGPT
ImageGPT
Overview
The ImageGPT model was proposed in Generative Pretraining from Pixels by Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, Ilya Sutskever. ImageGPT (iGPT) is a GPT-2-like model trained to predict the next pixel value, allowing for both unconditional and conditional image generation.
The abstract from the paper is the following:
Inspired by progress in unsupervised representation learning for natural language, we examine whether similar models can learn useful representations for images. We train a sequence Transformer to auto-regressively predict pixels, without incorporating knowledge of the 2D input structure. Despite training on low-resolution ImageNet without labels, we find that a GPT-2 scale model learns strong image representations as measured by linear probing, fine-tuning, and low-data classification. On CIFAR-10, we achieve 96.3% accuracy with a linear probe, outperforming a supervised Wide ResNet, and 99.0% accuracy with full fine-tuning, matching the top supervised pre-trained models. We are also competitive with self-supervised benchmarks on ImageNet when substituting pixels for a VQVAE encoding, achieving 69.0% top-1 accuracy on a linear probe of our features.
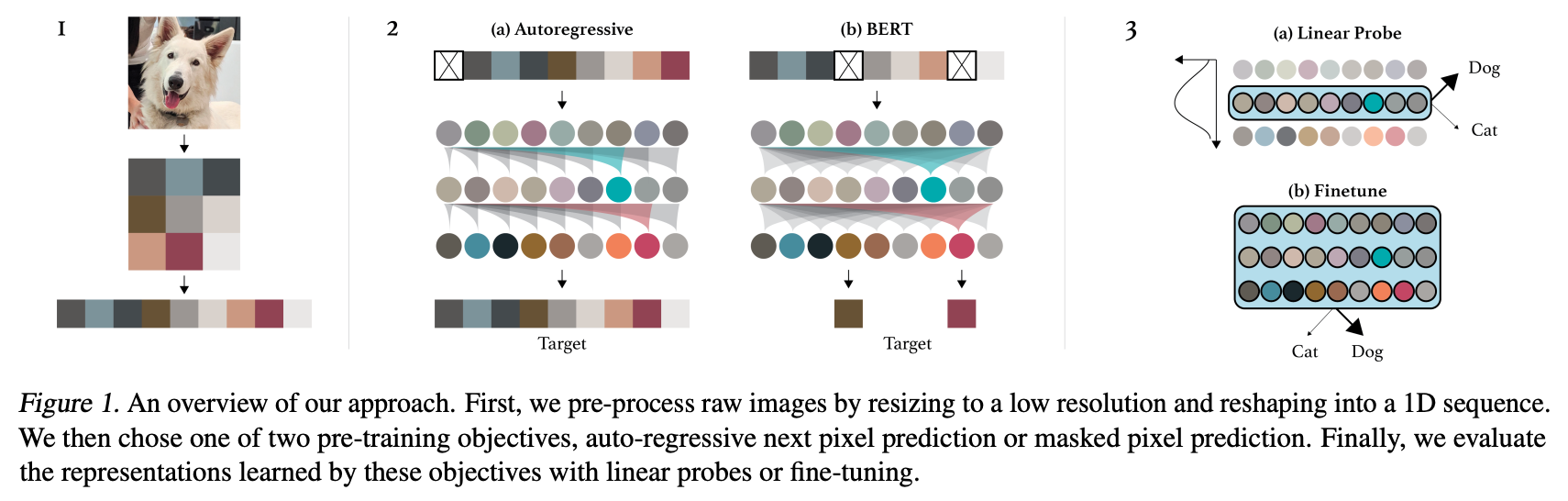 Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
Summary of the approach. Taken from the [original paper](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf). This model was contributed by nielsr, based on this issue. The original code can be found here.
Usage tips
- ImageGPT is almost exactly the same as GPT-2, with the exception that a different activation function is used (namely “quick gelu”), and the layer normalization layers don’t mean center the inputs. ImageGPT also doesn’t have tied input- and output embeddings.
- As the time- and memory requirements of the attention mechanism of Transformers scales quadratically in the sequence length, the authors pre-trained ImageGPT on smaller input resolutions, such as 32x32 and 64x64. However, feeding a sequence of 32x32x3=3072 tokens from 0..255 into a Transformer is still prohibitively large. Therefore, the authors applied k-means clustering to the (R,G,B) pixel values with k=512. This way, we only have a 32*32 = 1024-long sequence, but now of integers in the range 0..511. So we are shrinking the sequence length at the cost of a bigger embedding matrix. In other words, the vocabulary size of ImageGPT is 512, + 1 for a special “start of sentence” (SOS) token, used at the beginning of every sequence. One can use ImageGPTImageProcessor to prepare images for the model.
- Despite being pre-trained entirely unsupervised (i.e. without the use of any labels), ImageGPT produces fairly
performant image features useful for downstream tasks, such as image classification. The authors showed that the
features in the middle of the network are the most performant, and can be used as-is to train a linear model (such as
a sklearn logistic regression model for example). This is also referred to as “linear probing”. Features can be
easily obtained by first forwarding the image through the model, then specifying
output_hidden_states=True, and then average-pool the hidden states at whatever layer you like. - Alternatively, one can further fine-tune the entire model on a downstream dataset, similar to BERT. For this, you can use ImageGPTForImageClassification.
- ImageGPT comes in different sizes: there’s ImageGPT-small, ImageGPT-medium and ImageGPT-large. The authors did also train an XL variant, which they didn’t release. The differences in size are summarized in the following table:
| Model variant | Depths | Hidden sizes | Decoder hidden size | Params (M) | ImageNet-1k Top 1 |
|---|---|---|---|---|---|
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ImageGPT.
- Demo notebooks for ImageGPT can be found here.
- ImageGPTForImageClassification is supported by this example script and notebook.
- See also: Image classification task guide
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
ImageGPTConfig
class transformers.ImageGPTConfig
< source >( vocab_size = 513 n_positions = 1024 n_embd = 512 n_layer = 24 n_head = 8 n_inner = None activation_function = 'quick_gelu' resid_pdrop = 0.1 embd_pdrop = 0.1 attn_pdrop = 0.1 layer_norm_epsilon = 1e-05 initializer_range = 0.02 scale_attn_weights = True use_cache = True tie_word_embeddings = False scale_attn_by_inverse_layer_idx = False reorder_and_upcast_attn = False **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 512) — Vocabulary size of the GPT-2 model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling ImageGPTModel orTFImageGPTModel. - n_positions (
int, optional, defaults to 32*32) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - n_embd (
int, optional, defaults to 512) — Dimensionality of the embeddings and hidden states. - n_layer (
int, optional, defaults to 24) — Number of hidden layers in the Transformer encoder. - n_head (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer encoder. - n_inner (
int, optional, defaults to None) — Dimensionality of the inner feed-forward layers.Nonewill set it to 4 times n_embd - activation_function (
str, optional, defaults to"quick_gelu") — Activation function (can be one of the activation functions defined in src/transformers/activations.py). Defaults to “quick_gelu”. - resid_pdrop (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - embd_pdrop (
int, optional, defaults to 0.1) — The dropout ratio for the embeddings. - attn_pdrop (
float, optional, defaults to 0.1) — The dropout ratio for the attention. - layer_norm_epsilon (
float, optional, defaults to 1e-5) — The epsilon to use in the layer normalization layers. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - scale_attn_weights (
bool, optional, defaults toTrue) — Scale attention weights by dividing by sqrt(hidden_size).. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). - scale_attn_by_inverse_layer_idx (
bool, optional, defaults toFalse) — Whether to additionally scale attention weights by1 / layer_idx + 1. - reorder_and_upcast_attn (
bool, optional, defaults toFalse) — Whether to scale keys (K) prior to computing attention (dot-product) and upcast attention dot-product/softmax to float() when training with mixed precision.
This is the configuration class to store the configuration of a ImageGPTModel or a TFImageGPTModel. It is
used to instantiate a GPT-2 model according to the specified arguments, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the ImageGPT
openai/imagegpt-small architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import ImageGPTConfig, ImageGPTModel
>>> # Initializing a ImageGPT configuration
>>> configuration = ImageGPTConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = ImageGPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configImageGPTFeatureExtractor
Preprocess an image or a batch of images.
ImageGPTImageProcessor
class transformers.ImageGPTImageProcessor
< source >( clusters: Union = None do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_normalize: bool = True do_color_quantize: bool = True **kwargs )
Parameters
- clusters (
np.ndarrayorList[List[int]], optional) — The color clusters to use, of shape(n_clusters, 3)when color quantizing. Can be overriden byclustersinpreprocess. - do_resize (
bool, optional, defaults toTrue) — Whether to resize the image’s dimensions to(size["height"], size["width"]). Can be overridden bydo_resizeinpreprocess. - size (
Dict[str, int]optional, defaults to{"height" -- 256, "width": 256}): Size of the image after resizing. Can be overridden bysizeinpreprocess. - resample (
PILImageResampling, optional, defaults toResampling.BILINEAR) — Resampling filter to use if resizing the image. Can be overridden byresampleinpreprocess. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image pixel value to between [-1, 1]. Can be overridden bydo_normalizeinpreprocess. - do_color_quantize (
bool, optional, defaults toTrue) — Whether to color quantize the image. Can be overridden bydo_color_quantizeinpreprocess.
Constructs a ImageGPT image processor. This image processor can be used to resize images to a smaller resolution (such as 32x32 or 64x64), normalize them and finally color quantize them to obtain sequences of “pixel values” (color clusters).
preprocess
< source >( images: Union do_resize: bool = None size: Dict = None resample: Resampling = None do_normalize: bool = None do_color_quantize: Optional = None clusters: Union = None return_tensors: Union = None data_format: Union = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_normalize=False. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size of the image after resizing. - resample (
int, optional, defaults toself.resample) — Resampling filter to use if resizing the image. This can be one of the enumPILImageResampling, Only has an effect ifdo_resizeis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image - do_color_quantize (
bool, optional, defaults toself.do_color_quantize) — Whether to color quantize the image. - clusters (
np.ndarrayorList[List[int]], optional, defaults toself.clusters) — Clusters used to quantize the image of shape(n_clusters, 3). Only has an effect ifdo_color_quantizeis set toTrue. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:ChannelDimension.FIRST: image in (num_channels, height, width) format.ChannelDimension.LAST: image in (height, width, num_channels) format. Only has an effect ifdo_color_quantizeis set toFalse.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
ImageGPTModel
class transformers.ImageGPTModel
< source >( config: ImageGPTConfig )
Parameters
- config (ImageGPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare ImageGPT Model transformer outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None **kwargs: Any ) → transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.If
past_key_valuesis used, onlyinput_idsthat do not have their past calculated should be passed asinput_ids.Indices can be obtained using AutoImageProcessor. See ImageGPTImageProcessor.call() for details.
- past_key_values (
Tuple[Tuple[torch.Tensor]]of lengthconfig.n_layers) — Contains precomputed hidden-states (key and values in the attention blocks) as computed by the model (seepast_key_valuesoutput below). Can be used to speed up sequential decoding. Theinput_idswhich have their past given to this model should not be passed asinput_idsas they have already been computed. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.If
past_key_valuesis used, optionally only the lastinputs_embedshave to be input (seepast_key_values). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for language modeling. Note that the labels are shifted inside the model, i.e. you can setlabels = input_idsIndices are selected in[-100, 0, ..., config.vocab_size]All labels set to-100are ignored (masked), the loss is only computed for labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ImageGPTConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and optionally ifconfig.is_encoder_decoder=True2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally if
config.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueandconfig.add_cross_attention=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The ImageGPTModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, ImageGPTModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTModel.from_pretrained("openai/imagegpt-small")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateImageGPTForCausalImageModeling
class transformers.ImageGPTForCausalImageModeling
< source >( config: ImageGPTConfig )
Parameters
- config (ImageGPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The ImageGPT Model transformer with a language modeling head on top (linear layer with weights tied to the input embeddings).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None encoder_hidden_states: Optional = None encoder_attention_mask: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None **kwargs: Any ) → transformers.modeling_outputs.CausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.If
past_key_valuesis used, onlyinput_idsthat do not have their past calculated should be passed asinput_ids.Indices can be obtained using AutoImageProcessor. See ImageGPTImageProcessor.call() for details.
- past_key_values (
Tuple[Tuple[torch.Tensor]]of lengthconfig.n_layers) — Contains precomputed hidden-states (key and values in the attention blocks) as computed by the model (seepast_key_valuesoutput below). Can be used to speed up sequential decoding. Theinput_idswhich have their past given to this model should not be passed asinput_idsas they have already been computed. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.If
past_key_valuesis used, optionally only the lastinputs_embedshave to be input (seepast_key_values). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for language modeling. Note that the labels are shifted inside the model, i.e. you can setlabels = input_idsIndices are selected in[-100, 0, ..., config.vocab_size]All labels set to-100are ignored (masked), the loss is only computed for labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutputWithCrossAttentions or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ImageGPTConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Cross attentions weights after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftorch.FloatTensortuples of lengthconfig.n_layers, with each tuple containing the cached key, value states of the self-attention and the cross-attention layers if model is used in encoder-decoder setting. Only relevant ifconfig.is_decoder = True.Contains pre-computed hidden-states (key and values in the attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.
The ImageGPTForCausalImageModeling forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, ImageGPTForCausalImageModeling
>>> import torch
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> image_processor = AutoImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForCausalImageModeling.from_pretrained("openai/imagegpt-small")
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> model.to(device)
>>> # unconditional generation of 8 images
>>> batch_size = 4
>>> context = torch.full((batch_size, 1), model.config.vocab_size - 1) # initialize with SOS token
>>> context = context.to(device)
>>> output = model.generate(
... input_ids=context, max_length=model.config.n_positions + 1, temperature=1.0, do_sample=True, top_k=40
... )
>>> clusters = image_processor.clusters
>>> height = image_processor.size["height"]
>>> width = image_processor.size["width"]
>>> samples = output[:, 1:].cpu().detach().numpy()
>>> samples_img = [
... np.reshape(np.rint(127.5 * (clusters[s] + 1.0)), [height, width, 3]).astype(np.uint8) for s in samples
... ] # convert color cluster tokens back to pixels
>>> f, axes = plt.subplots(1, batch_size, dpi=300)
>>> for img, ax in zip(samples_img, axes):
... ax.axis("off")
... ax.imshow(img)ImageGPTForImageClassification
class transformers.ImageGPTForImageClassification
< source >( config: ImageGPTConfig )
Parameters
- config (ImageGPTConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The ImageGPT Model transformer with an image classification head on top (linear layer). ImageGPTForImageClassification average-pools the hidden states in order to do the classification.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None **kwargs: Any ) → transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) —input_ids_length=sequence_lengthifpast_key_valuesisNoneelsepast_key_values[0][0].shape[-2](sequence_lengthof input past key value states). Indices of input sequence tokens in the vocabulary.If
past_key_valuesis used, onlyinput_idsthat do not have their past calculated should be passed asinput_ids.Indices can be obtained using AutoImageProcessor. See ImageGPTImageProcessor.call() for details.
- past_key_values (
Tuple[Tuple[torch.Tensor]]of lengthconfig.n_layers) — Contains precomputed hidden-states (key and values in the attention blocks) as computed by the model (seepast_key_valuesoutput below). Can be used to speed up sequential decoding. Theinput_idswhich have their past given to this model should not be passed asinput_idsas they have already been computed. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]:- 0 corresponds to a sentence A token,
- 1 corresponds to a sentence B token.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix.If
past_key_valuesis used, optionally only the lastinputs_embedshave to be input (seepast_key_values). - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (ImageGPTConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The ImageGPTForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, ImageGPTForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("openai/imagegpt-small")
>>> model = ImageGPTForImageClassification.from_pretrained("openai/imagegpt-small")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits