Transformers documentation
M2M100
M2M100
Overview
The M2M100 model was proposed in Beyond English-Centric Multilingual Machine Translation by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky, Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
The abstract from the paper is the following:
Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
This model was contributed by valhalla.
Usage tips and examples
M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
source and target text. The source text format is [lang_code] X [eos], where lang_code is source language
id for source text and target language id for target text, with X being the source or target text.
The M2M100Tokenizer depends on sentencepiece so be sure to install it before running the
examples. To install sentencepiece run pip install sentencepiece.
Supervised Training
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward passGeneration
M2M100 uses the eos_token_id as the decoder_start_token_id for generation with the target language id
being forced as the first generated token. To force the target language id as the first generated token, pass the
forced_bos_token_id parameter to the generate method. The following example shows how to translate between
Hindi to French and Chinese to English using the facebook/m2m100_418M checkpoint.
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> chinese_text = "生活就像一盒巧克力。"
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."
>>> # translate Chinese to English
>>> tokenizer.src_lang = "zh"
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Life is like a box of chocolate."Resources
M2M100Config
class transformers.M2M100Config
< source >( vocab_size = 128112 max_position_embeddings = 1024 encoder_layers = 12 encoder_ffn_dim = 4096 encoder_attention_heads = 16 decoder_layers = 12 decoder_ffn_dim = 4096 decoder_attention_heads = 16 encoder_layerdrop = 0.05 decoder_layerdrop = 0.05 use_cache = True is_encoder_decoder = True activation_function = 'relu' d_model = 1024 dropout = 0.1 attention_dropout = 0.1 activation_dropout = 0.0 init_std = 0.02 decoder_start_token_id = 2 scale_embedding = True pad_token_id = 1 bos_token_id = 0 eos_token_id = 2 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 50265) — Vocabulary size of the M2M100 model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling M2M100Model or - d_model (
int, optional, defaults to 1024) — Dimensionality of the layers and the pooler layer. - encoder_layers (
int, optional, defaults to 12) — Number of encoder layers. - decoder_layers (
int, optional, defaults to 12) — Number of decoder layers. - encoder_attention_heads (
int, optional, defaults to 16) — Number of attention heads for each attention layer in the Transformer encoder. - decoder_attention_heads (
int, optional, defaults to 16) — Number of attention heads for each attention layer in the Transformer decoder. - decoder_ffn_dim (
int, optional, defaults to 4096) — Dimensionality of the “intermediate” (often named feed-forward) layer in decoder. - encoder_ffn_dim (
int, optional, defaults to 4096) — Dimensionality of the “intermediate” (often named feed-forward) layer in decoder. - activation_function (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. - dropout (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - activation_dropout (
float, optional, defaults to 0.0) — The dropout ratio for activations inside the fully connected layer. - classifier_dropout (
float, optional, defaults to 0.0) — The dropout ratio for classifier. - max_position_embeddings (
int, optional, defaults to 1024) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - init_std (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - encoder_layerdrop (
float, optional, defaults to 0.0) — The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - decoder_layerdrop (
float, optional, defaults to 0.0) — The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models).
This is the configuration class to store the configuration of a M2M100Model. It is used to instantiate an M2M100 model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the M2M100 facebook/m2m100_418M architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import M2M100Config, M2M100Model
>>> # Initializing a M2M100 facebook/m2m100_418M style configuration
>>> configuration = M2M100Config()
>>> # Initializing a model (with random weights) from the facebook/m2m100_418M style configuration
>>> model = M2M100Model(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configM2M100Tokenizer
class transformers.M2M100Tokenizer
< source >( vocab_file spm_file src_lang = None tgt_lang = None bos_token = '<s>' eos_token = '</s>' sep_token = '</s>' pad_token = '<pad>' unk_token = '<unk>' language_codes = 'm2m100' sp_model_kwargs: Optional = None num_madeup_words = 8 **kwargs )
Parameters
- vocab_file (
str) — Path to the vocabulary file. - spm_file (
str) — Path to SentencePiece file (generally has a .spm extension) that contains the vocabulary. - src_lang (
str, optional) — A string representing the source language. - tgt_lang (
str, optional) — A string representing the target language. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token. - sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - language_codes (
str, optional, defaults to"m2m100") — What language codes to use. Should be one of"m2m100"or"wmt21". - sp_model_kwargs (
dict, optional) — Will be passed to theSentencePieceProcessor.__init__()method. The Python wrapper for SentencePiece can be used, among other things, to set:-
enable_sampling: Enable subword regularization. -
nbest_size: Sampling parameters for unigram. Invalid for BPE-Dropout.nbest_size = {0,1}: No sampling is performed.nbest_size > 1: samples from the nbest_size results.nbest_size < 0: assuming that nbest_size is infinite and samples from the all hypothesis (lattice) using forward-filtering-and-backward-sampling algorithm.
-
alpha: Smoothing parameter for unigram sampling, and dropout probability of merge operations for BPE-dropout.
-
Construct an M2M100 tokenizer. Based on SentencePiece.
This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
Examples:
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="ro")
>>> src_text = " UN Chief Says There Is No Military Solution in Syria"
>>> tgt_text = "Şeful ONU declară că nu există o soluţie militară în Siria"
>>> model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
>>> outputs = model(**model_inputs) # should workbuild_inputs_with_special_tokens
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and
adding special tokens. An MBART sequence has the following format, where X represents the sequence:
input_ids(for encoder)X [eos, src_lang_code]decoder_input_ids: (for decoder)X [eos, tgt_lang_code]
BOS is never used. Pairs of sequences are not the expected use case, but they will be handled without a separator.
get_special_tokens_mask
< source >( token_ids_0: List token_ids_1: Optional = None already_has_special_tokens: bool = False ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs. - already_has_special_tokens (
bool, optional, defaults toFalse) — Whether or not the token list is already formatted with special tokens for the model.
Returns
List[int]
A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer prepare_for_model method.
create_token_type_ids_from_sequences
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Create the token type IDs corresponding to the sequences passed. What are token type IDs?
Should be overridden in a subclass if the model has a special way of building those.
M2M100Model
class transformers.M2M100Model
< source >( config: M2M100Config )
Parameters
- config (M2M100Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare M2M100 Model outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None head_mask: Optional = None decoder_head_mask: Optional = None cross_attn_head_mask: Optional = None encoder_outputs: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None decoder_inputs_embeds: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.Seq2SeqModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
M2M100 uses the
eos_token_idas the starting token fordecoder_input_idsgeneration. Ifpast_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values). - decoder_attention_mask (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Default behavior: generate a tensor that ignores pad tokens indecoder_input_ids. Causal mask will also be used by default. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- decoder_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- cross_attn_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state, optional:hidden_states, optional:attentions)last_hidden_stateof shape(batch_size, sequence_length, hidden_size), optional) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix.If
decoder_input_idsanddecoder_inputs_embedsare both unset,decoder_inputs_embedstakes the value ofinputs_embeds. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.Seq2SeqModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.Seq2SeqModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (M2M100Config) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the decoder of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the decoder at the output of each layer plus the optional initial embedding outputs.
-
decoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. -
encoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the encoder at the output of each layer plus the optional initial embedding outputs.
-
encoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
The M2M100Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, M2M100Model
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/m2m100_418M")
>>> model = M2M100Model.from_pretrained("facebook/m2m100_418M")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateM2M100ForConditionalGeneration
class transformers.M2M100ForConditionalGeneration
< source >( config: M2M100Config )
Parameters
- config (M2M100Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The M2M100 Model with a language modeling head. Can be used for summarization. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None attention_mask: Optional = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None head_mask: Optional = None decoder_head_mask: Optional = None cross_attn_head_mask: Optional = None encoder_outputs: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None decoder_inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.Seq2SeqLMOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
M2M100 uses the
eos_token_idas the starting token fordecoder_input_idsgeneration. Ifpast_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values). - decoder_attention_mask (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Default behavior: generate a tensor that ignores pad tokens indecoder_input_ids. Causal mask will also be used by default. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- decoder_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- cross_attn_head_mask (
torch.Tensorof shape(decoder_layers, decoder_attention_heads), optional) — Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state, optional:hidden_states, optional:attentions)last_hidden_stateof shape(batch_size, sequence_length, hidden_size), optional) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix.If
decoder_input_idsanddecoder_inputs_embedsare both unset,decoder_inputs_embedstakes the value ofinputs_embeds. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].
Returns
transformers.modeling_outputs.Seq2SeqLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.Seq2SeqLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (M2M100Config) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
-
decoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. -
encoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
-
encoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
The M2M100ForConditionalGeneration forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Translation example:
>>> from transformers import AutoTokenizer, M2M100ForConditionalGeneration
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/m2m100_418M")
>>> text_to_translate = "Life is like a box of chocolates"
>>> model_inputs = tokenizer(text_to_translate, return_tensors="pt")
>>> # translate to French
>>> gen_tokens = model.generate(**model_inputs, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> print(tokenizer.batch_decode(gen_tokens, skip_special_tokens=True))Using Flash Attention 2
Flash Attention 2 is a faster, optimized version of the attention scores computation which relies on cuda kernels.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
To load a model using Flash Attention 2, we can pass the argument attn_implementation="flash_attention_2" to .from_pretrained. You can use either torch.float16 or torch.bfloat16 precision.
>>> import torch
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda").eval()
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt").to("cuda")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
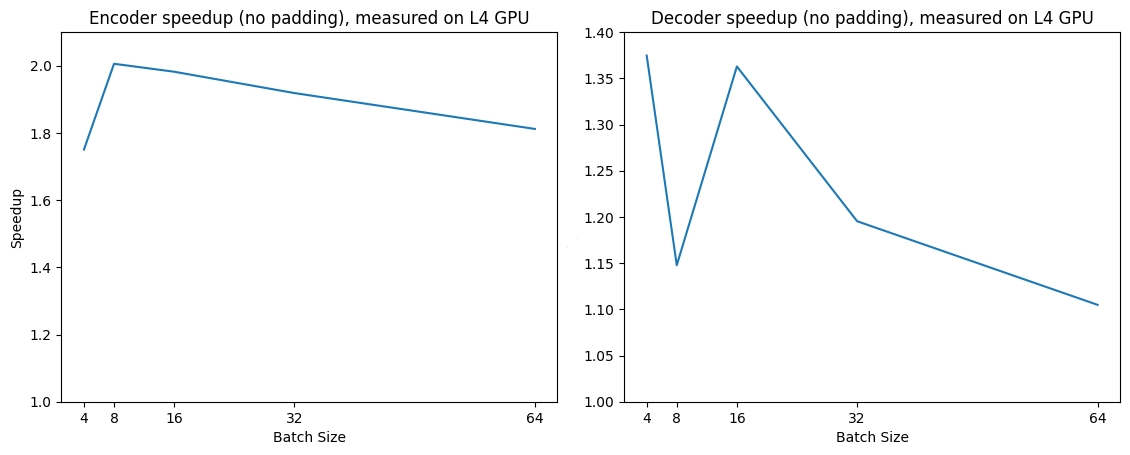
"La vie est comme une boîte de chocolat."Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation and the Flash Attention 2.