Transformers documentation
Grounding DINO
Grounding DINO
Overview
The Grounding DINO model was proposed in Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
The abstract from the paper is the following:
In this paper, we present an open-set object detector, called Grounding DINO, by marrying Transformer-based detector DINO with grounded pre-training, which can detect arbitrary objects with human inputs such as category names or referring expressions. The key solution of open-set object detection is introducing language to a closed-set detector for open-set concept generalization. To effectively fuse language and vision modalities, we conceptually divide a closed-set detector into three phases and propose a tight fusion solution, which includes a feature enhancer, a language-guided query selection, and a cross-modality decoder for cross-modality fusion. While previous works mainly evaluate open-set object detection on novel categories, we propose to also perform evaluations on referring expression comprehension for objects specified with attributes. Grounding DINO performs remarkably well on all three settings, including benchmarks on COCO, LVIS, ODinW, and RefCOCO/+/g. Grounding DINO achieves a 52.5 AP on the COCO detection zero-shot transfer benchmark, i.e., without any training data from COCO. It sets a new record on the ODinW zero-shot benchmark with a mean 26.1 AP.
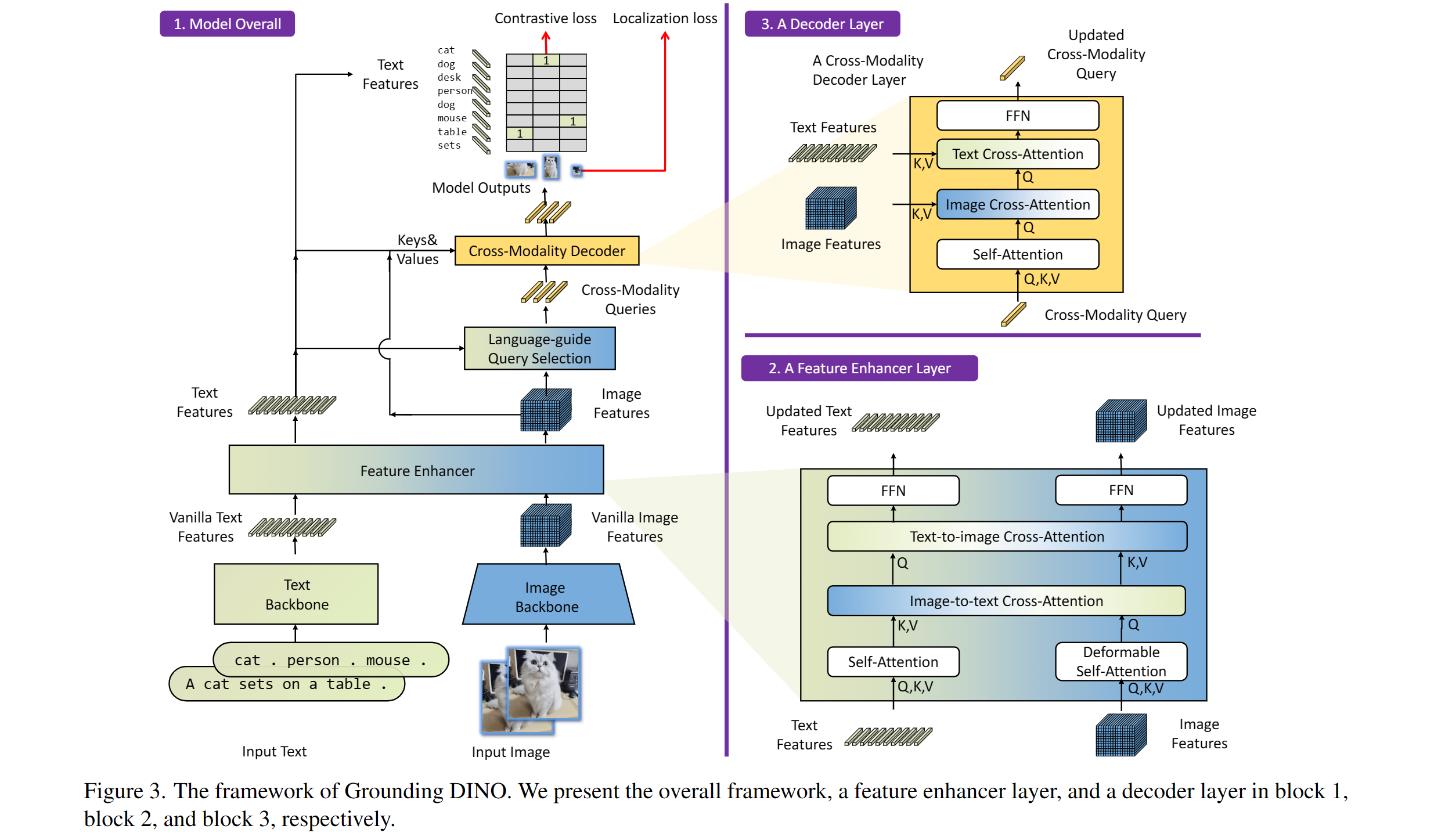 Grounding DINO overview. Taken from the original paper.
Grounding DINO overview. Taken from the original paper. This model was contributed by EduardoPacheco and nielsr. The original code can be found here.
Usage tips
- One can use GroundingDinoProcessor to prepare image-text pairs for the model.
- To separate classes in the text use a period e.g. “a cat. a dog.”
- When using multiple classes (e.g.
"a cat. a dog."), usepost_process_grounded_object_detectionfrom GroundingDinoProcessor to post process outputs. Since, the labels returned frompost_process_object_detectionrepresent the indices from the model dimension where prob > threshold.
Here’s how to use the model for zero-shot object detection:
import requests
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection,
model_id = "IDEA-Research/grounding-dino-tiny"
processor = AutoProcessor.from_pretrained(model_id)
model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Check for cats and remote controls
text = "a cat. a remote control."
inputs = processor(images=image, text=text, return_tensors="pt").to(device)
with torch.no_grad():
outputs = model(**inputs)
results = processor.post_process_grounded_object_detection(
outputs,
inputs.input_ids,
box_threshold=0.4,
text_threshold=0.3,
target_sizes=[image.size[::-1]]
)Grounded SAM
One can combine Grounding DINO with the Segment Anything model for text-based mask generation as introduced in Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks. You can refer to this demo notebook 🌍 for details.
 Grounded SAM overview. Taken from the original repository.
Grounded SAM overview. Taken from the original repository. Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Grounding DINO. If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Demo notebooks regarding inference with Grounding DINO as well as combining it with SAM can be found here. 🌎
GroundingDinoImageProcessor
class transformers.GroundingDinoImageProcessor
< source >( format: Union = <AnnotationFormat.COCO_DETECTION: 'coco_detection'> do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None do_convert_annotations: Optional = None do_pad: bool = True pad_size: Optional = None **kwargs )
Parameters
- format (
str, optional, defaults toAnnotationFormat.COCO_DETECTION) — Data format of the annotations. One of “coco_detection” or “coco_panoptic”. - do_resize (
bool, optional, defaults toTrue) — Controls whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overridden by thedo_resizeparameter in thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"shortest_edge" -- 800, "longest_edge": 1333}): Size of the image’s(height, width)dimensions after resizing. Can be overridden by thesizeparameter in thepreprocessmethod. Available options are:{"height": int, "width": int}: The image will be resized to the exact size(height, width). Do NOT keep the aspect ratio.{"shortest_edge": int, "longest_edge": int}: The image will be resized to a maximum size respecting the aspect ratio and keeping the shortest edge less or equal toshortest_edgeand the longest edge less or equal tolongest_edge.{"max_height": int, "max_width": int}: The image will be resized to the maximum size respecting the aspect ratio and keeping the height less or equal tomax_heightand the width less or equal tomax_width.
- resample (
PILImageResampling, optional, defaults toResampling.BILINEAR) — Resampling filter to use if resizing the image. - do_rescale (
bool, optional, defaults toTrue) — Controls whether to rescale the image by the specified scalerescale_factor. Can be overridden by thedo_rescaleparameter in thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overridden by therescale_factorparameter in thepreprocessmethod. Controls whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toIMAGENET_DEFAULT_MEAN) — Mean values to use when normalizing the image. Can be a single value or a list of values, one for each channel. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toIMAGENET_DEFAULT_STD) — Standard deviation values to use when normalizing the image. Can be a single value or a list of values, one for each channel. Can be overridden by theimage_stdparameter in thepreprocessmethod. - do_convert_annotations (
bool, optional, defaults toTrue) — Controls whether to convert the annotations to the format expected by the DETR model. Converts the bounding boxes to the format(center_x, center_y, width, height)and in the range[0, 1]. Can be overridden by thedo_convert_annotationsparameter in thepreprocessmethod. - do_pad (
bool, optional, defaults toTrue) — Controls whether to pad the image. Can be overridden by thedo_padparameter in thepreprocessmethod. IfTrue, padding will be applied to the bottom and right of the image with zeros. Ifpad_sizeis provided, the image will be padded to the specified dimensions. Otherwise, the image will be padded to the maximum height and width of the batch. - pad_size (
Dict[str, int], optional) — The size{"height": int, "width" int}to pad the images to. Must be larger than any image size provided for preprocessing. Ifpad_sizeis not provided, images will be padded to the largest height and width in the batch.
Constructs a Grounding DINO image processor.
preprocess
< source >( images: Union annotations: Union = None return_segmentation_masks: bool = None masks_path: Union = None do_resize: Optional = None size: Optional = None resample = None do_rescale: Optional = None rescale_factor: Union = None do_normalize: Optional = None do_convert_annotations: Optional = None image_mean: Union = None image_std: Union = None do_pad: Optional = None format: Union = None return_tensors: Union = None data_format: Union = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None pad_size: Optional = None **kwargs )
Parameters
- images (
ImageInput) — Image or batch of images to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - annotations (
AnnotationTypeorList[AnnotationType], optional) — List of annotations associated with the image or batch of images. If annotation is for object detection, the annotations should be a dictionary with the following keys:- “image_id” (
int): The image id. - “annotations” (
List[Dict]): List of annotations for an image. Each annotation should be a dictionary. An image can have no annotations, in which case the list should be empty. If annotation is for segmentation, the annotations should be a dictionary with the following keys: - “image_id” (
int): The image id. - “segments_info” (
List[Dict]): List of segments for an image. Each segment should be a dictionary. An image can have no segments, in which case the list should be empty. - “file_name” (
str): The file name of the image.
- “image_id” (
- return_segmentation_masks (
bool, optional, defaults to self.return_segmentation_masks) — Whether to return segmentation masks. - masks_path (
strorpathlib.Path, optional) — Path to the directory containing the segmentation masks. - do_resize (
bool, optional, defaults to self.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults to self.size) — Size of the image’s(height, width)dimensions after resizing. Available options are:{"height": int, "width": int}: The image will be resized to the exact size(height, width). Do NOT keep the aspect ratio.{"shortest_edge": int, "longest_edge": int}: The image will be resized to a maximum size respecting the aspect ratio and keeping the shortest edge less or equal toshortest_edgeand the longest edge less or equal tolongest_edge.{"max_height": int, "max_width": int}: The image will be resized to the maximum size respecting the aspect ratio and keeping the height less or equal tomax_heightand the width less or equal tomax_width.
- resample (
PILImageResampling, optional, defaults to self.resample) — Resampling filter to use when resizing the image. - do_rescale (
bool, optional, defaults to self.do_rescale) — Whether to rescale the image. - rescale_factor (
float, optional, defaults to self.rescale_factor) — Rescale factor to use when rescaling the image. - do_normalize (
bool, optional, defaults to self.do_normalize) — Whether to normalize the image. - do_convert_annotations (
bool, optional, defaults to self.do_convert_annotations) — Whether to convert the annotations to the format expected by the model. Converts the bounding boxes from the format(top_left_x, top_left_y, width, height)to(center_x, center_y, width, height)and in relative coordinates. - image_mean (
floatorList[float], optional, defaults to self.image_mean) — Mean to use when normalizing the image. - image_std (
floatorList[float], optional, defaults to self.image_std) — Standard deviation to use when normalizing the image. - do_pad (
bool, optional, defaults to self.do_pad) — Whether to pad the image. IfTrue, padding will be applied to the bottom and right of the image with zeros. Ifpad_sizeis provided, the image will be padded to the specified dimensions. Otherwise, the image will be padded to the maximum height and width of the batch. - format (
strorAnnotationFormat, optional, defaults to self.format) — Format of the annotations. - return_tensors (
strorTensorType, optional, defaults to self.return_tensors) — Type of tensors to return. IfNone, will return the list of images. - data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
- pad_size (
Dict[str, int], optional) — The size{"height": int, "width" int}to pad the images to. Must be larger than any image size provided for preprocessing. Ifpad_sizeis not provided, images will be padded to the largest height and width in the batch.
Preprocess an image or a batch of images so that it can be used by the model.
post_process_object_detection
< source >( outputs threshold: float = 0.1 target_sizes: Union = None ) → List[Dict]
Parameters
- outputs (
GroundingDinoObjectDetectionOutput) — Raw outputs of the model. - threshold (
float, optional) — Score threshold to keep object detection predictions. - target_sizes (
torch.TensororList[Tuple[int, int]], optional) — Tensor of shape(batch_size, 2)or list of tuples (Tuple[int, int]) containing the target size(height, width)of each image in the batch. If unset, predictions will not be resized.
Returns
List[Dict]
A list of dictionaries, each dictionary containing the scores, labels and boxes for an image in the batch as predicted by the model.
Converts the raw output of GroundingDinoForObjectDetection into final bounding boxes in (top_left_x, top_left_y, bottom_right_x, bottom_right_y) format.
GroundingDinoProcessor
class transformers.GroundingDinoProcessor
< source >( image_processor tokenizer )
Parameters
- image_processor (
GroundingDinoImageProcessor) — An instance of GroundingDinoImageProcessor. The image processor is a required input. - tokenizer (
AutoTokenizer) — An instance of [‘PreTrainedTokenizer`]. The tokenizer is a required input.
Constructs a Grounding DINO processor which wraps a Deformable DETR image processor and a BERT tokenizer into a single processor.
GroundingDinoProcessor offers all the functionalities of GroundingDinoImageProcessor and
AutoTokenizer. See the docstring of __call__() and decode()
for more information.
post_process_grounded_object_detection
< source >( outputs input_ids box_threshold: float = 0.25 text_threshold: float = 0.25 target_sizes: Union = None ) → List[Dict]
Parameters
- outputs (
GroundingDinoObjectDetectionOutput) — Raw outputs of the model. - input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — The token ids of the input text. - box_threshold (
float, optional, defaults to 0.25) — Score threshold to keep object detection predictions. - text_threshold (
float, optional, defaults to 0.25) — Score threshold to keep text detection predictions. - target_sizes (
torch.TensororList[Tuple[int, int]], optional) — Tensor of shape(batch_size, 2)or list of tuples (Tuple[int, int]) containing the target size(height, width)of each image in the batch. If unset, predictions will not be resized.
Returns
List[Dict]
A list of dictionaries, each dictionary containing the scores, labels and boxes for an image in the batch as predicted by the model.
Converts the raw output of GroundingDinoForObjectDetection into final bounding boxes in (top_left_x, top_left_y, bottom_right_x, bottom_right_y) format and get the associated text label.
GroundingDinoConfig
class transformers.GroundingDinoConfig
< source >( backbone_config = None backbone = None use_pretrained_backbone = False use_timm_backbone = False backbone_kwargs = None text_config = None num_queries = 900 encoder_layers = 6 encoder_ffn_dim = 2048 encoder_attention_heads = 8 decoder_layers = 6 decoder_ffn_dim = 2048 decoder_attention_heads = 8 is_encoder_decoder = True activation_function = 'relu' d_model = 256 dropout = 0.1 attention_dropout = 0.0 activation_dropout = 0.0 auxiliary_loss = False position_embedding_type = 'sine' num_feature_levels = 4 encoder_n_points = 4 decoder_n_points = 4 two_stage = True class_cost = 1.0 bbox_cost = 5.0 giou_cost = 2.0 bbox_loss_coefficient = 5.0 giou_loss_coefficient = 2.0 focal_alpha = 0.25 disable_custom_kernels = False max_text_len = 256 text_enhancer_dropout = 0.0 fusion_droppath = 0.1 fusion_dropout = 0.0 embedding_init_target = True query_dim = 4 decoder_bbox_embed_share = True two_stage_bbox_embed_share = False positional_embedding_temperature = 20 init_std = 0.02 layer_norm_eps = 1e-05 **kwargs )
Parameters
- backbone_config (
PretrainedConfigordict, optional, defaults toResNetConfig()) — The configuration of the backbone model. - backbone (
str, optional) — Name of backbone to use whenbackbone_configisNone. Ifuse_pretrained_backboneisTrue, this will load the corresponding pretrained weights from the timm or transformers library. Ifuse_pretrained_backboneisFalse, this loads the backbone’s config and uses that to initialize the backbone with random weights. - use_pretrained_backbone (
bool, optional, defaults toFalse) — Whether to use pretrained weights for the backbone. - use_timm_backbone (
bool, optional, defaults toFalse) — Whether to loadbackbonefrom the timm library. IfFalse, the backbone is loaded from the transformers library. - backbone_kwargs (
dict, optional) — Keyword arguments to be passed to AutoBackbone when loading from a checkpoint e.g.{'out_indices': (0, 1, 2, 3)}. Cannot be specified ifbackbone_configis set. - text_config (
Union[AutoConfig, dict], optional, defaults toBertConfig) — The config object or dictionary of the text backbone. - num_queries (
int, optional, defaults to 900) — Number of object queries, i.e. detection slots. This is the maximal number of objects GroundingDinoModel can detect in a single image. - encoder_layers (
int, optional, defaults to 6) — Number of encoder layers. - encoder_ffn_dim (
int, optional, defaults to 2048) — Dimension of the “intermediate” (often named feed-forward) layer in decoder. - encoder_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer encoder. - decoder_layers (
int, optional, defaults to 6) — Number of decoder layers. - decoder_ffn_dim (
int, optional, defaults to 2048) — Dimension of the “intermediate” (often named feed-forward) layer in decoder. - decoder_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer decoder. - is_encoder_decoder (
bool, optional, defaults toTrue) — Whether the model is used as an encoder/decoder or not. - activation_function (
strorfunction, optional, defaults to"relu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. - d_model (
int, optional, defaults to 256) — Dimension of the layers. - dropout (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - activation_dropout (
float, optional, defaults to 0.0) — The dropout ratio for activations inside the fully connected layer. - auxiliary_loss (
bool, optional, defaults toFalse) — Whether auxiliary decoding losses (loss at each decoder layer) are to be used. - position_embedding_type (
str, optional, defaults to"sine") — Type of position embeddings to be used on top of the image features. One of"sine"or"learned". - num_feature_levels (
int, optional, defaults to 4) — The number of input feature levels. - encoder_n_points (
int, optional, defaults to 4) — The number of sampled keys in each feature level for each attention head in the encoder. - decoder_n_points (
int, optional, defaults to 4) — The number of sampled keys in each feature level for each attention head in the decoder. - two_stage (
bool, optional, defaults toTrue) — Whether to apply a two-stage deformable DETR, where the region proposals are also generated by a variant of Grounding DINO, which are further fed into the decoder for iterative bounding box refinement. - class_cost (
float, optional, defaults to 1.0) — Relative weight of the classification error in the Hungarian matching cost. - bbox_cost (
float, optional, defaults to 5.0) — Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost. - giou_cost (
float, optional, defaults to 2.0) — Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost. - bbox_loss_coefficient (
float, optional, defaults to 5.0) — Relative weight of the L1 bounding box loss in the object detection loss. - giou_loss_coefficient (
float, optional, defaults to 2.0) — Relative weight of the generalized IoU loss in the object detection loss. - focal_alpha (
float, optional, defaults to 0.25) — Alpha parameter in the focal loss. - disable_custom_kernels (
bool, optional, defaults toFalse) — Disable the use of custom CUDA and CPU kernels. This option is necessary for the ONNX export, as custom kernels are not supported by PyTorch ONNX export. - max_text_len (
int, optional, defaults to 256) — The maximum length of the text input. - text_enhancer_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the text enhancer. - fusion_droppath (
float, optional, defaults to 0.1) — The droppath ratio for the fusion module. - fusion_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the fusion module. - embedding_init_target (
bool, optional, defaults toTrue) — Whether to initialize the target with Embedding weights. - query_dim (
int, optional, defaults to 4) — The dimension of the query vector. - decoder_bbox_embed_share (
bool, optional, defaults toTrue) — Whether to share the bbox regression head for all decoder layers. - two_stage_bbox_embed_share (
bool, optional, defaults toFalse) — Whether to share the bbox embedding between the two-stage bbox generator and the region proposal generation. - positional_embedding_temperature (
float, optional, defaults to 20) — The temperature for Sine Positional Embedding that is used together with vision backbone. - init_std (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers.
This is the configuration class to store the configuration of a GroundingDinoModel. It is used to instantiate a Grounding DINO model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Grounding DINO IDEA-Research/grounding-dino-tiny architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Examples:
>>> from transformers import GroundingDinoConfig, GroundingDinoModel
>>> # Initializing a Grounding DINO IDEA-Research/grounding-dino-tiny style configuration
>>> configuration = GroundingDinoConfig()
>>> # Initializing a model (with random weights) from the IDEA-Research/grounding-dino-tiny style configuration
>>> model = GroundingDinoModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configGroundingDinoModel
class transformers.GroundingDinoModel
< source >( config: GroundingDinoConfig )
Parameters
- config (GroundingDinoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Grounding DINO Model (consisting of a backbone and encoder-decoder Transformer) outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: Tensor input_ids: Tensor token_type_ids: Optional = None attention_mask: Optional = None pixel_mask: Optional = None encoder_outputs = None output_attentions = None output_hidden_states = None return_dict = None ) → transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoModelOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it.Pixel values can be obtained using AutoImageProcessor. See GroundingDinoImageProcessor.call() for details.
- input_ids (
torch.LongTensorof shape(batch_size, text_sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See
GroundingDinoTokenizer.__call__for details. - token_type_ids (
torch.LongTensorof shape(batch_size, text_sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]: 0 corresponds to asentence Atoken, 1 corresponds to asentence Btoken - attention_mask (
torch.LongTensorof shape(batch_size, text_sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are real (i.e. not masked),
- 0 for tokens that are padding (i.e. masked).
- pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
- encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state_vision, optional:last_hidden_state_text, optional:vision_hidden_states, optional:text_hidden_states, optional:attentions)last_hidden_state_visionof shape(batch_size, sequence_length, hidden_size), optional) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoModelOutput or tuple(torch.FloatTensor)
A transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GroundingDinoConfig) and inputs.
- last_hidden_state (
torch.FloatTensorof shape(batch_size, num_queries, hidden_size)) — Sequence of hidden-states at the output of the last layer of the decoder of the model. - init_reference_points (
torch.FloatTensorof shape(batch_size, num_queries, 4)) — Initial reference points sent through the Transformer decoder. - intermediate_hidden_states (
torch.FloatTensorof shape(batch_size, config.decoder_layers, num_queries, hidden_size)) — Stacked intermediate hidden states (output of each layer of the decoder). - intermediate_reference_points (
torch.FloatTensorof shape(batch_size, config.decoder_layers, num_queries, 4)) — Stacked intermediate reference points (reference points of each layer of the decoder). - decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, num_queries, hidden_size). Hidden-states of the decoder at the output of each layer plus the initial embedding outputs. - decoder_attentions (
tuple(tuple(torch.FloatTensor)), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple of tuples oftorch.FloatTensor(one for attention for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention, cross-attention and multi-scale deformable attention heads. - encoder_last_hidden_state_vision (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. - encoder_last_hidden_state_text (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. - encoder_vision_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the vision embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the vision encoder at the output of each layer plus the initial embedding outputs. - encoder_text_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the text embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the text encoder at the output of each layer plus the initial embedding outputs. - encoder_attentions (
tuple(tuple(torch.FloatTensor)), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple of tuples oftorch.FloatTensor(one for attention for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and multi-scale deformable attention heads. attention softmax, used to compute the weighted average in the bi-attention heads. - enc_outputs_class (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels), optional, returned whenconfig.two_stage=True) — Predicted bounding boxes scores where the topconfig.num_queriesscoring bounding boxes are picked as region proposals in the first stage. Output of bounding box binary classification (i.e. foreground and background). - enc_outputs_coord_logits (
torch.FloatTensorof shape(batch_size, sequence_length, 4), optional, returned whenconfig.two_stage=True) — Logits of predicted bounding boxes coordinates in the first stage.
The GroundingDinoModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, AutoModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "a cat."
>>> processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
>>> model = AutoModel.from_pretrained("IDEA-Research/grounding-dino-tiny")
>>> inputs = processor(images=image, text=text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 900, 256]GroundingDinoForObjectDetection
class transformers.GroundingDinoForObjectDetection
< source >( config: GroundingDinoConfig )
Parameters
- config (GroundingDinoConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Grounding DINO Model (consisting of a backbone and encoder-decoder Transformer) with object detection heads on top, for tasks such as COCO detection.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor input_ids: LongTensor token_type_ids: LongTensor = None attention_mask: LongTensor = None pixel_mask: Optional = None encoder_outputs: Union = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: List = None ) → transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoObjectDetectionOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it.Pixel values can be obtained using AutoImageProcessor. See GroundingDinoImageProcessor.call() for details.
- input_ids (
torch.LongTensorof shape(batch_size, text_sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See
GroundingDinoTokenizer.__call__for details. - token_type_ids (
torch.LongTensorof shape(batch_size, text_sequence_length), optional) — Segment token indices to indicate first and second portions of the inputs. Indices are selected in[0, 1]: 0 corresponds to asentence Atoken, 1 corresponds to asentence Btoken - attention_mask (
torch.LongTensorof shape(batch_size, text_sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are real (i.e. not masked),
- 0 for tokens that are padding (i.e. masked).
- pixel_mask (
torch.LongTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
- encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state_vision, optional:last_hidden_state_text, optional:vision_hidden_states, optional:text_hidden_states, optional:attentions)last_hidden_state_visionof shape(batch_size, sequence_length, hidden_size), optional) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
List[Dict]of len(batch_size,), optional) — Labels for computing the bipartite matching loss. List of dicts, each dictionary containing at least the following 2 keys: ‘class_labels’ and ‘boxes’ (the class labels and bounding boxes of an image in the batch respectively). The class labels themselves should be atorch.LongTensorof len(number of bounding boxes in the image,)and the boxes atorch.FloatTensorof shape(number of bounding boxes in the image, 4).
Returns
transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoObjectDetectionOutput or tuple(torch.FloatTensor)
A transformers.models.grounding_dino.modeling_grounding_dino.GroundingDinoObjectDetectionOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (GroundingDinoConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsare provided)) — Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized scale-invariant IoU loss. - loss_dict (
Dict, optional) — A dictionary containing the individual losses. Useful for logging. - logits (
torch.FloatTensorof shape(batch_size, num_queries, num_classes + 1)) — Classification logits (including no-object) for all queries. - pred_boxes (
torch.FloatTensorof shape(batch_size, num_queries, 4)) — Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding possible padding). You can use~GroundingDinoProcessor.post_process_object_detectionto retrieve the unnormalized bounding boxes. - auxiliary_outputs (
List[Dict], optional) — Optional, only returned when auxilary losses are activated (i.e.config.auxiliary_lossis set toTrue) and labels are provided. It is a list of dictionaries containing the two above keys (logitsandpred_boxes) for each decoder layer. - last_hidden_state (
torch.FloatTensorof shape(batch_size, num_queries, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the decoder of the model. - decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, num_queries, hidden_size). Hidden-states of the decoder at the output of each layer plus the initial embedding outputs. - decoder_attentions (
tuple(tuple(torch.FloatTensor)), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple of tuples oftorch.FloatTensor(one for attention for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention, cross-attention and multi-scale deformable attention heads. - encoder_last_hidden_state_vision (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. - encoder_last_hidden_state_text (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. - encoder_vision_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the vision embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the vision encoder at the output of each layer plus the initial embedding outputs. - encoder_text_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the text embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the text encoder at the output of each layer plus the initial embedding outputs. - encoder_attentions (
tuple(tuple(torch.FloatTensor)), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple of tuples oftorch.FloatTensor(one for attention for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the text-vision attention, vision-text attention, text-enhancer (self-attention) and multi-scale deformable attention heads. - intermediate_hidden_states (
torch.FloatTensorof shape(batch_size, config.decoder_layers, num_queries, hidden_size)) — Stacked intermediate hidden states (output of each layer of the decoder). - intermediate_reference_points (
torch.FloatTensorof shape(batch_size, config.decoder_layers, num_queries, 4)) — Stacked intermediate reference points (reference points of each layer of the decoder). - init_reference_points (
torch.FloatTensorof shape(batch_size, num_queries, 4)) — Initial reference points sent through the Transformer decoder. - enc_outputs_class (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels), optional, returned whenconfig.two_stage=True) — Predicted bounding boxes scores where the topconfig.num_queriesscoring bounding boxes are picked as region proposals in the first stage. Output of bounding box binary classification (i.e. foreground and background). - enc_outputs_coord_logits (
torch.FloatTensorof shape(batch_size, sequence_length, 4), optional, returned whenconfig.two_stage=True) — Logits of predicted bounding boxes coordinates in the first stage.
The GroundingDinoForObjectDetection forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, GroundingDinoForObjectDetection
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "a cat."
>>> processor = AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny")
>>> model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny")
>>> inputs = processor(images=image, text=text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to COCO API
>>> target_sizes = torch.tensor([image.size[::-1]])
>>> results = processor.image_processor.post_process_object_detection(
... outputs, threshold=0.35, target_sizes=target_sizes
... )[0]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 1) for i in box.tolist()]
... print(f"Detected {label.item()} with confidence " f"{round(score.item(), 2)} at location {box}")
Detected 1 with confidence 0.45 at location [344.8, 23.2, 637.4, 373.8]
Detected 1 with confidence 0.41 at location [11.9, 51.6, 316.6, 472.9]