Transformers documentation
UDOP
UDOP
Overview
The UDOP model was proposed in Unifying Vision, Text, and Layout for Universal Document Processing by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
The abstract from the paper is the following:
We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).*
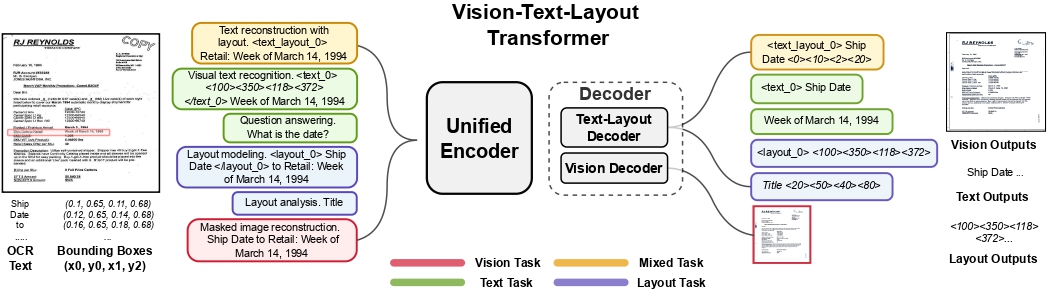 UDOP architecture. Taken from the original paper.
UDOP architecture. Taken from the original paper. Usage tips
- In addition to input_ids, UdopForConditionalGeneration also expects the input
bbox, which are the bounding boxes (i.e. 2D-positions) of the input tokens. These can be obtained using an external OCR engine such as Google’s Tesseract (there’s a Python wrapper available). Each bounding box should be in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner. Note that one first needs to normalize the bounding boxes to be on a 0-1000 scale. To normalize, you can use the following function:
def normalize_bbox(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]Here, width and height correspond to the width and height of the original document in which the token
occurs. Those can be obtained using the Python Image Library (PIL) library for example, as follows:
from PIL import Image
# Document can be a png, jpg, etc. PDFs must be converted to images.
image = Image.open(name_of_your_document).convert("RGB")
width, height = image.sizeOne can use UdopProcessor to prepare images and text for the model, which takes care of all of this. By default, this class uses the Tesseract engine to extract a list of words and boxes (coordinates) from a given document. Its functionality is equivalent to that of LayoutLMv3Processor, hence it supports passing either apply_ocr=False in case you prefer to use your own OCR engine or apply_ocr=True in case you want the default OCR engine to be used. Refer to the usage guide of LayoutLMv2 regarding all possible use cases (the functionality of UdopProcessor is identical).
- If using an own OCR engine of choice, one recommendation is Azure’s Read API, which supports so-called line segments. Use of segment position embeddings typically results in better performance.
- At inference time, it’s recommended to use the
generatemethod to autoregressively generate text given a document image. - The model has been pre-trained on both self-supervised and supervised objectives. One can use the various task prefixes (prompts) used during pre-training to test out the out-of-the-box capabilities. For instance, the model can be prompted with “Question answering. What is the date?”, as “Question answering.” is the task prefix used during pre-training for DocVQA. Refer to the paper (table 1) for all task prefixes.
- One can also fine-tune UdopEncoderModel, which is the encoder-only part of UDOP, which can be seen as a LayoutLMv3-like Transformer encoder. For discriminative tasks, one can just add a linear classifier on top of it and fine-tune it on a labeled dataset.
This model was contributed by nielsr. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with UDOP. If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
- Demo notebooks regarding UDOP can be found here that show how to fine-tune UDOP on a custom dataset as well as inference. 🌎
- Document question answering task guide
UdopConfig
class transformers.UdopConfig
< source >( vocab_size = 33201 d_model = 1024 d_kv = 64 d_ff = 4096 num_layers = 24 num_decoder_layers = None num_heads = 16 relative_attention_num_buckets = 32 relative_attention_max_distance = 128 relative_bias_args = [{'type': '1d'}, {'type': 'horizontal'}, {'type': 'vertical'}] dropout_rate = 0.1 layer_norm_epsilon = 1e-06 initializer_factor = 1.0 feed_forward_proj = 'relu' is_encoder_decoder = True use_cache = True pad_token_id = 0 eos_token_id = 1 max_2d_position_embeddings = 1024 image_size = 224 patch_size = 16 num_channels = 3 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 33201) — Vocabulary size of the UDOP model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling UdopForConditionalGeneration. - d_model (
int, optional, defaults to 1024) — Size of the encoder layers and the pooler layer. - d_kv (
int, optional, defaults to 64) — Size of the key, query, value projections per attention head. Theinner_dimof the projection layer will be defined asnum_heads * d_kv. - d_ff (
int, optional, defaults to 4096) — Size of the intermediate feed forward layer in eachUdopBlock. - num_layers (
int, optional, defaults to 24) — Number of hidden layers in the Transformer encoder and decoder. - num_decoder_layers (
int, optional) — Number of hidden layers in the Transformer decoder. Will use the same value asnum_layersif not set. - num_heads (
int, optional, defaults to 16) — Number of attention heads for each attention layer in the Transformer encoder and decoder. - relative_attention_num_buckets (
int, optional, defaults to 32) — The number of buckets to use for each attention layer. - relative_attention_max_distance (
int, optional, defaults to 128) — The maximum distance of the longer sequences for the bucket separation. - relative_bias_args (
List[dict], optional, defaults to[{'type' -- '1d'}, {'type': 'horizontal'}, {'type': 'vertical'}]): A list of dictionaries containing the arguments for the relative bias layers. - dropout_rate (
float, optional, defaults to 0.1) — The ratio for all dropout layers. - layer_norm_epsilon (
float, optional, defaults to 1e-06) — The epsilon used by the layer normalization layers. - initializer_factor (
float, optional, defaults to 1.0) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing). - feed_forward_proj (
string, optional, defaults to"relu") — Type of feed forward layer to be used. Should be one of"relu"or"gated-gelu". Udopv1.1 uses the"gated-gelu"feed forward projection. Original Udop uses"relu". - is_encoder_decoder (
bool, optional, defaults toTrue) — Whether the model should behave as an encoder/decoder or not. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). - pad_token_id (
int, optional, defaults to 0) — The id of the padding token in the vocabulary. - eos_token_id (
int, optional, defaults to 1) — The id of the end-of-sequence token in the vocabulary. - max_2d_position_embeddings (
int, optional, defaults to 1024) — The maximum absolute position embeddings for relative position encoding. - image_size (
int, optional, defaults to 224) — The size of the input images. - patch_size (
int, optional, defaults to 16) — The patch size used by the vision encoder. - num_channels (
int, optional, defaults to 3) — The number of channels in the input images.
This is the configuration class to store the configuration of a UdopForConditionalGeneration. It is used to instantiate a UDOP model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the UDOP microsoft/udop-large architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
UdopTokenizer
class transformers.UdopTokenizer
< source >( vocab_file eos_token = '</s>' unk_token = '<unk>' sep_token = '</s>' pad_token = '<pad>' sep_token_box = [1000, 1000, 1000, 1000] pad_token_box = [0, 0, 0, 0] pad_token_label = -100 only_label_first_subword = True additional_special_tokens = None sp_model_kwargs: Optional = None legacy = True add_prefix_space = True **kwargs )
Parameters
- vocab_file (
str) — Path to the vocabulary file. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - sep_token_box (
List[int], optional, defaults to[1000, 1000, 1000, 1000]) — The bounding box to use for the special [SEP] token. - pad_token_box (
List[int], optional, defaults to[0, 0, 0, 0]) — The bounding box to use for the special [PAD] token. - pad_token_label (
int, optional, defaults to -100) — The label to use for padding tokens. Defaults to -100, which is theignore_indexof PyTorch’s CrossEntropyLoss. - only_label_first_subword (
bool, optional, defaults toTrue) — Whether or not to only label the first subword, in case word labels are provided. - additional_special_tokens (
List[str], optional, defaults to["<s>NOTUSED", "</s>NOTUSED"]) — Additional special tokens used by the tokenizer. - sp_model_kwargs (
dict, optional) — Will be passed to theSentencePieceProcessor.__init__()method. The Python wrapper for SentencePiece can be used, among other things, to set:-
enable_sampling: Enable subword regularization. -
nbest_size: Sampling parameters for unigram. Invalid for BPE-Dropout.nbest_size = {0,1}: No sampling is performed.nbest_size > 1: samples from the nbest_size results.nbest_size < 0: assuming that nbest_size is infinite and samples from the all hypothesis (lattice) using forward-filtering-and-backward-sampling algorithm.
-
alpha: Smoothing parameter for unigram sampling, and dropout probability of merge operations for BPE-dropout.
-
- legacy (
bool, optional, defaults toTrue) — Whether or not thelegacybehaviour of the tokenizer should be used. Legacy is before the merge of #24622 which includes fixes to properly handle tokens that appear after special tokens. A simple example:legacy=True:
Adapted from LayoutXLMTokenizer and T5Tokenizer. Based on SentencePiece.
This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
build_inputs_with_special_tokens
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. A sequence has the following format:
- single sequence:
X </s> - pair of sequences:
A </s> B </s>
get_special_tokens_mask
< source >( token_ids_0: List token_ids_1: Optional = None already_has_special_tokens: bool = False ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs. - already_has_special_tokens (
bool, optional, defaults toFalse) — Whether or not the token list is already formatted with special tokens for the model.
Returns
List[int]
A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
Retrieve sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer prepare_for_model method.
create_token_type_ids_from_sequences
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Create a mask from the two sequences passed to be used in a sequence-pair classification task. T5 does not make use of token type ids, therefore a list of zeros is returned.
UdopTokenizerFast
class transformers.UdopTokenizerFast
< source >( vocab_file = None tokenizer_file = None eos_token = '</s>' sep_token = '</s>' unk_token = '<unk>' pad_token = '<pad>' sep_token_box = [1000, 1000, 1000, 1000] pad_token_box = [0, 0, 0, 0] pad_token_label = -100 only_label_first_subword = True additional_special_tokens = None **kwargs )
Parameters
- vocab_file (
str, optional) — Path to the vocabulary file. - tokenizer_file (
str, optional) — Path to the tokenizer file. - eos_token (
str, optional, defaults to"</s>") — The end of sequence token.When building a sequence using special tokens, this is not the token that is used for the end of sequence. The token used is the
sep_token. - sep_token (
str, optional, defaults to"</s>") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. - unk_token (
str, optional, defaults to"<unk>") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - pad_token (
str, optional, defaults to"<pad>") — The token used for padding, for example when batching sequences of different lengths. - sep_token_box (
List[int], optional, defaults to[1000, 1000, 1000, 1000]) — The bounding box to use for the special [SEP] token. - pad_token_box (
List[int], optional, defaults to[0, 0, 0, 0]) — The bounding box to use for the special [PAD] token. - pad_token_label (
int, optional, defaults to -100) — The label to use for padding tokens. Defaults to -100, which is theignore_indexof PyTorch’s CrossEntropyLoss. - only_label_first_subword (
bool, optional, defaults toTrue) — Whether or not to only label the first subword, in case word labels are provided. - additional_special_tokens (
List[str], optional, defaults to["<s>NOTUSED", "</s>NOTUSED"]) — Additional special tokens used by the tokenizer.
Construct a “fast” UDOP tokenizer (backed by HuggingFace’s tokenizers library). Adapted from LayoutXLMTokenizer and T5Tokenizer. Based on BPE.
This tokenizer inherits from PreTrainedTokenizerFast which contains most of the main methods. Users should refer to this superclass for more information regarding those methods.
batch_encode_plus_boxes
< source >( batch_text_or_text_pairs: Union is_pair: bool = None boxes: Optional = None word_labels: Optional = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
Parameters
- batch_text_or_text_pairs (
List[str],List[Tuple[str, str]],List[List[str]],List[Tuple[List[str], List[str]]], and for not-fast tokenizers, alsoList[List[int]],List[Tuple[List[int], List[int]]]) — Batch of sequences or pair of sequences to be encoded. This can be a list of string/string-sequences/int-sequences or a list of pair of string/string-sequences/int-sequence (see details inencode_plus).
Tokenize and prepare for the model a list of sequences or a list of pairs of sequences.
This method is deprecated, __call__ should be used instead.
build_inputs_with_special_tokens
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Parameters
- token_ids_0 (
List[int]) — List of IDs to which the special tokens will be added. - token_ids_1 (
List[int], optional) — Optional second list of IDs for sequence pairs.
Returns
List[int]
List of input IDs with the appropriate special tokens.
Build model inputs from a sequence or a pair of sequence for sequence classification tasks by concatenating and adding special tokens. An XLM-RoBERTa sequence has the following format:
- single sequence:
<s> X </s> - pair of sequences:
<s> A </s></s> B </s>
call_boxes
< source >( text: Union text_pair: Union = None boxes: Union = None word_labels: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs ) → BatchEncoding
Parameters
- text (
str,List[str],List[List[str]]) — The sequence or batch of sequences to be encoded. Each sequence can be a string, a list of strings (words of a single example or questions of a batch of examples) or a list of list of strings (batch of words). - text_pair (
List[str],List[List[str]]) — The sequence or batch of sequences to be encoded. Each sequence should be a list of strings (pretokenized string). - boxes (
List[List[int]],List[List[List[int]]]) — Word-level bounding boxes. Each bounding box should be normalized to be on a 0-1000 scale. - word_labels (
List[int],List[List[int]], optional) — Word-level integer labels (for token classification tasks such as FUNSD, CORD). - add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to encode the sequences with the special tokens relative to their model. - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,stror TruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'longest_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate token by token, removing a token from the longest sequence in the pair if a pair of sequences (or a batch of pairs) is provided.'only_first': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.'only_second': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will only truncate the second sequence of a pair if a pair of sequences (or a batch of pairs) is provided.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.If left unset or set to
None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. - stride (
int, optional, defaults to 0) — If set to a number along withmax_length, the overflowing tokens returned whenreturn_overflowing_tokens=Truewill contain some tokens from the end of the truncated sequence returned to provide some overlap between truncated and overflowing sequences. The value of this argument defines the number of overlapping tokens. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability>= 7.5(Volta). - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
- return_token_type_ids (
bool, optional) — Whether to return token type IDs. If left to the default, will return the token type IDs according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_attention_mask (
bool, optional) — Whether to return the attention mask. If left to the default, will return the attention mask according to the specific tokenizer’s default, defined by thereturn_outputsattribute. - return_overflowing_tokens (
bool, optional, defaults toFalse) — Whether or not to return overflowing token sequences. If a pair of sequences of input ids (or a batch of pairs) is provided withtruncation_strategy = longest_firstorTrue, an error is raised instead of returning overflowing tokens. - return_special_tokens_mask (
bool, optional, defaults toFalse) — Whether or not to return special tokens mask information. - return_offsets_mapping (
bool, optional, defaults toFalse) — Whether or not to return(char_start, char_end)for each token.This is only available on fast tokenizers inheriting from PreTrainedTokenizerFast, if using Python’s tokenizer, this method will raise
NotImplementedError. - return_length (
bool, optional, defaults toFalse) — Whether or not to return the lengths of the encoded inputs. - verbose (
bool, optional, defaults toTrue) — Whether or not to print more information and warnings. **kwargs — passed to theself.tokenize()method
Returns
A BatchEncoding with the following fields:
-
input_ids — List of token ids to be fed to a model.
-
bbox — List of bounding boxes to be fed to a model.
-
token_type_ids — List of token type ids to be fed to a model (when
return_token_type_ids=Trueor if “token_type_ids” is inself.model_input_names). -
attention_mask — List of indices specifying which tokens should be attended to by the model (when
return_attention_mask=Trueor if “attention_mask” is inself.model_input_names). -
labels — List of labels to be fed to a model. (when
word_labelsis specified). -
overflowing_tokens — List of overflowing tokens sequences (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
num_truncated_tokens — Number of tokens truncated (when a
max_lengthis specified andreturn_overflowing_tokens=True). -
special_tokens_mask — List of 0s and 1s, with 1 specifying added special tokens and 0 specifying regular sequence tokens (when
add_special_tokens=Trueandreturn_special_tokens_mask=True). -
length — The length of the inputs (when
return_length=True).
Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of sequences with word-level normalized bounding boxes and optional labels.
create_token_type_ids_from_sequences
< source >( token_ids_0: List token_ids_1: Optional = None ) → List[int]
Create a mask from the two sequences passed to be used in a sequence-pair classification task. XLM-RoBERTa does not make use of token type ids, therefore a list of zeros is returned.
encode_boxes
< source >( text: Union text_pair: Union = None boxes: Optional = None word_labels: Optional = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 return_tensors: Union = None **kwargs )
Parameters
- Converts a string to a sequence of ids (integer), using the tokenizer and vocabulary. Same as doing —
self.convert_tokens_to_ids(self.tokenize(text)). — text (str,List[str]orList[int]): The first sequence to be encoded. This can be a string, a list of strings (tokenized string using thetokenizemethod) or a list of integers (tokenized string ids using theconvert_tokens_to_idsmethod). text_pair (str,List[str]orList[int], optional): Optional second sequence to be encoded. This can be a string, a list of strings (tokenized string using thetokenizemethod) or a list of integers (tokenized string ids using theconvert_tokens_to_idsmethod).
encode_plus_boxes
< source >( text: Union text_pair: Optional = None boxes: Optional = None word_labels: Optional = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
Parameters
- text (
str,List[str]orList[int](the latter only for not-fast tokenizers)) — The first sequence to be encoded. This can be a string, a list of strings (tokenized string using thetokenizemethod) or a list of integers (tokenized string ids using theconvert_tokens_to_idsmethod). - text_pair (
str,List[str]orList[int], optional) — Optional second sequence to be encoded. This can be a string, a list of strings (tokenized string using thetokenizemethod) or a list of integers (tokenized string ids using theconvert_tokens_to_idsmethod).
Tokenize and prepare for the model a sequence or a pair of sequences.
This method is deprecated, __call__ should be used instead.
UdopProcessor
class transformers.UdopProcessor
< source >( image_processor tokenizer )
Parameters
- image_processor (
LayoutLMv3ImageProcessor) — An instance of LayoutLMv3ImageProcessor. The image processor is a required input. - tokenizer (
UdopTokenizerorUdopTokenizerFast) — An instance of UdopTokenizer or UdopTokenizerFast. The tokenizer is a required input.
Constructs a UDOP processor which combines a LayoutLMv3 image processor and a UDOP tokenizer into a single processor.
UdopProcessor offers all the functionalities you need to prepare data for the model.
It first uses LayoutLMv3ImageProcessor to resize, rescale and normalize document images, and optionally applies OCR
to get words and normalized bounding boxes. These are then provided to UdopTokenizer or UdopTokenizerFast,
which turns the words and bounding boxes into token-level input_ids, attention_mask, token_type_ids, bbox.
Optionally, one can provide integer word_labels, which are turned into token-level labels for token
classification tasks (such as FUNSD, CORD).
Additionally, it also supports passing text_target and text_pair_target to the tokenizer, which can be used to
prepare labels for language modeling tasks.
__call__
< source >( images: Union = None text: Union = None text_pair: Union = None boxes: Union = None word_labels: Union = None text_target: Union = None text_pair_target: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = False max_length: Optional = None stride: int = 0 pad_to_multiple_of: Optional = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True return_tensors: Union = None )
This method first forwards the images argument to ~UdopImageProcessor.__call__. In case
UdopImageProcessor was initialized with apply_ocr set to True, it passes the obtained words and
bounding boxes along with the additional arguments to __call__() and returns the output,
together with the prepared pixel_values. In case UdopImageProcessor was initialized with apply_ocr set
to False, it passes the words (text/`text_pair) and boxes specified by the user along with the
additional arguments to __call__() and returns the output, together with the prepared
pixel_values.
Alternatively, one can pass text_target and text_pair_target to prepare the targets of UDOP.
Please refer to the docstring of the above two methods for more information.
UdopModel
class transformers.UdopModel
< source >( config )
Parameters
- config (UdopConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare UDOP encoder-decoder Transformer outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Tensor = None attention_mask: Tensor = None bbox: Dict = None pixel_values: Optional = None visual_bbox: Dict = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None inputs_embeds: Optional = None encoder_outputs: Optional = None past_key_values: Optional = None head_mask: Optional = None decoder_inputs_embeds: Optional = None decoder_head_mask: Optional = None cross_attn_head_mask: Optional = None use_cache = True output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.Seq2SeqModelOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. UDOP is a model with relative position embeddings so you should be able to pad the inputs on both the right and the left. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for detail. What are input IDs? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- bbox (
torch.LongTensorof shape({0}, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner.Note that
sequence_length = token_sequence_length + patch_sequence_length + 1where1is for [CLS] token. Seepixel_valuesforpatch_sequence_length. - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Batch of document images. Each image is divided into patches of shape(num_channels, config.patch_size, config.patch_size)and the total number of patches (=patch_sequence_length) equals to((height / config.patch_size) * (width / config.patch_size)). - visual_bbox (
torch.LongTensorof shape(batch_size, patch_sequence_length, 4), optional) — Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model. - decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are decoder input IDs? T5 uses thepad_token_idas the starting token fordecoder_input_idsgeneration. Ifpast_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values). To know more on how to preparedecoder_input_idsfor pretraining take a look at T5 Training. - decoder_attention_mask (
torch.BoolTensorof shape(batch_size, target_sequence_length), optional) — Default behavior: generate a tensor that ignores pad tokens indecoder_input_ids. Causal mask will also be used by default. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- decoder_head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- cross_attn_head_mask (
torch.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state,optional: hidden_states,optional: attentions)last_hidden_stateof shape(batch_size, sequence_length, hidden_size)is a sequence of hidden states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - past_key_values (
tuple(tuple(torch.FloatTensor))of lengthconfig.n_layerswith each tuple having 4 tensors of shape(batch_size, num_heads, sequence_length - 1, embed_size_per_head)) — Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding. Ifpast_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix. Ifdecoder_input_idsanddecoder_inputs_embedsare both unset,decoder_inputs_embedstakes the value ofinputs_embeds. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.Seq2SeqModelOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.Seq2SeqModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (UdopConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the decoder of the model.If
past_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the decoder at the output of each layer plus the optional initial embedding outputs.
-
decoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. -
encoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the encoder at the output of each layer plus the optional initial embedding outputs.
-
encoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
The UdopModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, AutoModel
>>> from datasets import load_dataset
>>> import torch
>>> # load model and processor
>>> # in this case, we already have performed OCR ourselves
>>> # so we initialize the processor with `apply_ocr=False`
>>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
>>> model = AutoModel.from_pretrained("microsoft/udop-large")
>>> # load an example image, along with the words and coordinates
>>> # which were extracted using an OCR engine
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> image = example["image"]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> inputs = processor(image, words, boxes=boxes, return_tensors="pt")
>>> decoder_input_ids = torch.tensor([[model.config.decoder_start_token_id]])
>>> # forward pass
>>> outputs = model(**inputs, decoder_input_ids=decoder_input_ids)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 1, 1024]UdopForConditionalGeneration
class transformers.UdopForConditionalGeneration
< source >( config )
Parameters
- config (UdopConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The UDOP encoder-decoder Transformer with a language modeling head on top, enabling to generate text given document images and an optional prompt.
This class is based on T5ForConditionalGeneration, extended to deal with images and layout (2D) data. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Tensor = None attention_mask: Tensor = None bbox: Dict = None pixel_values: Optional = None visual_bbox: Dict = None decoder_input_ids: Optional = None decoder_attention_mask: Optional = None inputs_embeds: Optional = None encoder_outputs: Optional = None past_key_values: Optional = None head_mask: Optional = None decoder_inputs_embeds: Optional = None decoder_head_mask: Optional = None cross_attn_head_mask: Optional = None use_cache = True output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None labels: Optional = None ) → transformers.modeling_outputs.Seq2SeqLMOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. UDOP is a model with relative position embeddings so you should be able to pad the inputs on both the right and the left. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for detail. What are input IDs? - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- bbox (
torch.LongTensorof shape({0}, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner.Note that
sequence_length = token_sequence_length + patch_sequence_length + 1where1is for [CLS] token. Seepixel_valuesforpatch_sequence_length. - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Batch of document images. Each image is divided into patches of shape(num_channels, config.patch_size, config.patch_size)and the total number of patches (=patch_sequence_length) equals to((height / config.patch_size) * (width / config.patch_size)). - visual_bbox (
torch.LongTensorof shape(batch_size, patch_sequence_length, 4), optional) — Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model. - decoder_input_ids (
torch.LongTensorof shape(batch_size, target_sequence_length), optional) — Indices of decoder input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are decoder input IDs? T5 uses thepad_token_idas the starting token fordecoder_input_idsgeneration. Ifpast_key_valuesis used, optionally only the lastdecoder_input_idshave to be input (seepast_key_values). To know more on how to preparedecoder_input_idsfor pretraining take a look at T5 Training. - decoder_attention_mask (
torch.BoolTensorof shape(batch_size, target_sequence_length), optional) — Default behavior: generate a tensor that ignores pad tokens indecoder_input_ids. Causal mask will also be used by default. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- decoder_head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- cross_attn_head_mask (
torch.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the cross-attention modules in the decoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state,optional: hidden_states,optional: attentions)last_hidden_stateof shape(batch_size, sequence_length, hidden_size)is a sequence of hidden states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - past_key_values (
tuple(tuple(torch.FloatTensor))of lengthconfig.n_layerswith each tuple having 4 tensors of shape(batch_size, num_heads, sequence_length - 1, embed_size_per_head)) — Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding. Ifpast_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of alldecoder_input_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, target_sequence_length, hidden_size), optional) — Optionally, instead of passingdecoder_input_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastdecoder_inputs_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertdecoder_input_idsindices into associated vectors than the model’s internal embedding lookup matrix. Ifdecoder_input_idsanddecoder_inputs_embedsare both unset,decoder_inputs_embedstakes the value ofinputs_embeds. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size - 1]. All labels set to-100are ignored (masked), the loss is only computed for labels in[0, ..., config.vocab_size].
Returns
transformers.modeling_outputs.Seq2SeqLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.Seq2SeqLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (UdopConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and 2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the decoder at the output of each layer plus the initial embedding outputs.
-
decoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
-
cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
-
encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. -
encoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the encoder at the output of each layer plus the initial embedding outputs.
-
encoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
The UdopForConditionalGeneration forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, UdopForConditionalGeneration
>>> from datasets import load_dataset
>>> # load model and processor
>>> # in this case, we already have performed OCR ourselves
>>> # so we initialize the processor with `apply_ocr=False`
>>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
>>> model = UdopForConditionalGeneration.from_pretrained("microsoft/udop-large")
>>> # load an example image, along with the words and coordinates
>>> # which were extracted using an OCR engine
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> image = example["image"]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> # one can use the various task prefixes (prompts) used during pre-training
>>> # e.g. the task prefix for DocVQA is "Question answering. "
>>> question = "Question answering. What is the date on the form?"
>>> encoding = processor(image, question, words, boxes=boxes, return_tensors="pt")
>>> # autoregressive generation
>>> predicted_ids = model.generate(**encoding)
>>> print(processor.batch_decode(predicted_ids, skip_special_tokens=True)[0])
9/30/92UdopEncoderModel
class transformers.UdopEncoderModel
< source >( config: UdopConfig )
Parameters
- config (UdopConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare UDOP Model transformer outputting encoder’s raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Tensor = None bbox: Dict = None attention_mask: Tensor = None pixel_values: Optional = None visual_bbox: Dict = None head_mask: Optional = None inputs_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.udop.modeling_udop.BaseModelOutputWithAttentionMask or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. T5 is a model with relative position embeddings so you should be able to pad the inputs on both the right and the left.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for detail.
To know more on how to prepare
input_idsfor pretraining take a look a T5 Training. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- bbox (
torch.LongTensorof shape({0}, 4), optional) — Bounding boxes of each input sequence tokens. Selected in the range[0, config.max_2d_position_embeddings-1]. Each bounding box should be a normalized version in (x0, y0, x1, y1) format, where (x0, y0) corresponds to the position of the upper left corner in the bounding box, and (x1, y1) represents the position of the lower right corner.Note that
sequence_length = token_sequence_length + patch_sequence_length + 1where1is for [CLS] token. Seepixel_valuesforpatch_sequence_length. - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Batch of document images. Each image is divided into patches of shape(num_channels, config.patch_size, config.patch_size)and the total number of patches (=patch_sequence_length) equals to((height / config.patch_size) * (width / config.patch_size)). - visual_bbox (
torch.LongTensorof shape(batch_size, patch_sequence_length, 4), optional) — Bounding boxes of each patch in the image. If not provided, bounding boxes are created in the model. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.udop.modeling_udop.BaseModelOutputWithAttentionMask or tuple(torch.FloatTensor)
A transformers.models.udop.modeling_udop.BaseModelOutputWithAttentionMask or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (UdopConfig) and inputs.
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. Ifpast_key_valuesis used only the last hidden-state of the sequences of shape(batch_size, 1, hidden_size)is output. - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or - when
config.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)) and optionally ifconfig.is_encoder_decoder=True2 additional tensors of shape(batch_size, num_heads, encoder_sequence_length, embed_size_per_head). Contains pre-computed hidden-states (key and values in the self-attention blocks and optionally ifconfig.is_encoder_decoder=Truein the cross-attention blocks) that can be used (seepast_key_valuesinput) to speed up sequential decoding. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or - when
config.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the optional initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or when config.output_attentions=True): Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.- cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueand config.add_cross_attention=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads.
The UdopEncoderModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoProcessor, UdopEncoderModel
>>> from huggingface_hub import hf_hub_download
>>> from datasets import load_dataset
>>> # load model and processor
>>> # in this case, we already have performed OCR ourselves
>>> # so we initialize the processor with `apply_ocr=False`
>>> processor = AutoProcessor.from_pretrained("microsoft/udop-large", apply_ocr=False)
>>> model = UdopEncoderModel.from_pretrained("microsoft/udop-large")
>>> # load an example image, along with the words and coordinates
>>> # which were extracted using an OCR engine
>>> dataset = load_dataset("nielsr/funsd-layoutlmv3", split="train")
>>> example = dataset[0]
>>> image = example["image"]
>>> words = example["tokens"]
>>> boxes = example["bboxes"]
>>> encoding = processor(image, words, boxes=boxes, return_tensors="pt")
>>> outputs = model(**encoding)
>>> last_hidden_states = outputs.last_hidden_state