Transformers documentation
Table Transformer
Table Transformer
Overview
The Table Transformer model was proposed in PubTables-1M: Towards comprehensive table extraction from unstructured documents by Brandon Smock, Rohith Pesala, Robin Abraham. The authors introduce a new dataset, PubTables-1M, to benchmark progress in table extraction from unstructured documents, as well as table structure recognition and functional analysis. The authors train 2 DETR models, one for table detection and one for table structure recognition, dubbed Table Transformers.
The abstract from the paper is the following:
Recently, significant progress has been made applying machine learning to the problem of table structure inference and extraction from unstructured documents. However, one of the greatest challenges remains the creation of datasets with complete, unambiguous ground truth at scale. To address this, we develop a new, more comprehensive dataset for table extraction, called PubTables-1M. PubTables-1M contains nearly one million tables from scientific articles, supports multiple input modalities, and contains detailed header and location information for table structures, making it useful for a wide variety of modeling approaches. It also addresses a significant source of ground truth inconsistency observed in prior datasets called oversegmentation, using a novel canonicalization procedure. We demonstrate that these improvements lead to a significant increase in training performance and a more reliable estimate of model performance at evaluation for table structure recognition. Further, we show that transformer-based object detection models trained on PubTables-1M produce excellent results for all three tasks of detection, structure recognition, and functional analysis without the need for any special customization for these tasks.
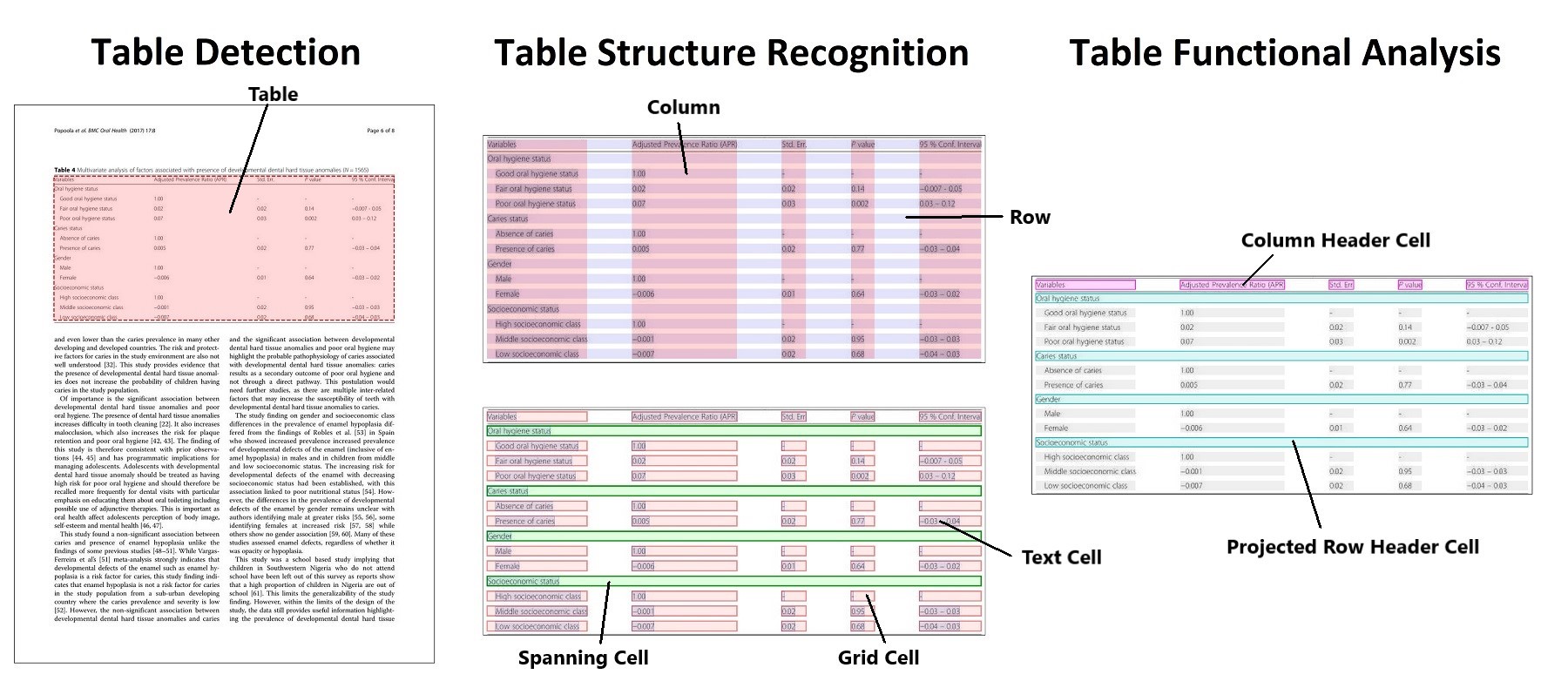 Table detection and table structure recognition clarified. Taken from the original paper.
Table detection and table structure recognition clarified. Taken from the original paper. The authors released 2 models, one for table detection in documents, one for table structure recognition (the task of recognizing the individual rows, columns etc. in a table).
This model was contributed by nielsr. The original code can be found here.
Resources
- A demo notebook for the Table Transformer can be found here.
- It turns out padding of images is quite important for detection. An interesting Github thread with replies from the authors can be found here.
TableTransformerConfig
class transformers.TableTransformerConfig
< source >( use_timm_backbone = True backbone_config = None num_channels = 3 num_queries = 100 encoder_layers = 6 encoder_ffn_dim = 2048 encoder_attention_heads = 8 decoder_layers = 6 decoder_ffn_dim = 2048 decoder_attention_heads = 8 encoder_layerdrop = 0.0 decoder_layerdrop = 0.0 is_encoder_decoder = True activation_function = 'relu' d_model = 256 dropout = 0.1 attention_dropout = 0.0 activation_dropout = 0.0 init_std = 0.02 init_xavier_std = 1.0 auxiliary_loss = False position_embedding_type = 'sine' backbone = 'resnet50' use_pretrained_backbone = True backbone_kwargs = None dilation = False class_cost = 1 bbox_cost = 5 giou_cost = 2 mask_loss_coefficient = 1 dice_loss_coefficient = 1 bbox_loss_coefficient = 5 giou_loss_coefficient = 2 eos_coefficient = 0.1 **kwargs )
Parameters
- use_timm_backbone (
bool, optional, defaults toTrue) — Whether or not to use thetimmlibrary for the backbone. If set toFalse, will use the AutoBackbone API. - backbone_config (
PretrainedConfigordict, optional) — The configuration of the backbone model. Only used in caseuse_timm_backboneis set toFalsein which case it will default toResNetConfig(). - num_channels (
int, optional, defaults to 3) — The number of input channels. - num_queries (
int, optional, defaults to 100) — Number of object queries, i.e. detection slots. This is the maximal number of objects TableTransformerModel can detect in a single image. For COCO, we recommend 100 queries. - d_model (
int, optional, defaults to 256) — Dimension of the layers. - encoder_layers (
int, optional, defaults to 6) — Number of encoder layers. - decoder_layers (
int, optional, defaults to 6) — Number of decoder layers. - encoder_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer encoder. - decoder_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer decoder. - decoder_ffn_dim (
int, optional, defaults to 2048) — Dimension of the “intermediate” (often named feed-forward) layer in decoder. - encoder_ffn_dim (
int, optional, defaults to 2048) — Dimension of the “intermediate” (often named feed-forward) layer in decoder. - activation_function (
strorfunction, optional, defaults to"relu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","silu"and"gelu_new"are supported. - dropout (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - activation_dropout (
float, optional, defaults to 0.0) — The dropout ratio for activations inside the fully connected layer. - init_std (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - init_xavier_std (
float, optional, defaults to 1) — The scaling factor used for the Xavier initialization gain in the HM Attention map module. - encoder_layerdrop (
float, optional, defaults to 0.0) — The LayerDrop probability for the encoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - decoder_layerdrop (
float, optional, defaults to 0.0) — The LayerDrop probability for the decoder. See the [LayerDrop paper](see https://arxiv.org/abs/1909.11556) for more details. - auxiliary_loss (
bool, optional, defaults toFalse) — Whether auxiliary decoding losses (loss at each decoder layer) are to be used. - position_embedding_type (
str, optional, defaults to"sine") — Type of position embeddings to be used on top of the image features. One of"sine"or"learned". - backbone (
str, optional) — Name of backbone to use whenbackbone_configisNone. Ifuse_pretrained_backboneisTrue, this will load the corresponding pretrained weights from the timm or transformers library. Ifuse_pretrained_backboneisFalse, this loads the backbone’s config and uses that to initialize the backbone with random weights. - use_pretrained_backbone (
bool, optional,True) — Whether to use pretrained weights for the backbone. - backbone_kwargs (
dict, optional) — Keyword arguments to be passed to AutoBackbone when loading from a checkpoint e.g.{'out_indices': (0, 1, 2, 3)}. Cannot be specified ifbackbone_configis set. - dilation (
bool, optional, defaults toFalse) — Whether to replace stride with dilation in the last convolutional block (DC5). Only supported whenuse_timm_backbone=True. - class_cost (
float, optional, defaults to 1) — Relative weight of the classification error in the Hungarian matching cost. - bbox_cost (
float, optional, defaults to 5) — Relative weight of the L1 error of the bounding box coordinates in the Hungarian matching cost. - giou_cost (
float, optional, defaults to 2) — Relative weight of the generalized IoU loss of the bounding box in the Hungarian matching cost. - mask_loss_coefficient (
float, optional, defaults to 1) — Relative weight of the Focal loss in the panoptic segmentation loss. - dice_loss_coefficient (
float, optional, defaults to 1) — Relative weight of the DICE/F-1 loss in the panoptic segmentation loss. - bbox_loss_coefficient (
float, optional, defaults to 5) — Relative weight of the L1 bounding box loss in the object detection loss. - giou_loss_coefficient (
float, optional, defaults to 2) — Relative weight of the generalized IoU loss in the object detection loss. - eos_coefficient (
float, optional, defaults to 0.1) — Relative classification weight of the ‘no-object’ class in the object detection loss.
This is the configuration class to store the configuration of a TableTransformerModel. It is used to instantiate a Table Transformer model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Table Transformer microsoft/table-transformer-detection architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Examples:
>>> from transformers import TableTransformerModel, TableTransformerConfig
>>> # Initializing a Table Transformer microsoft/table-transformer-detection style configuration
>>> configuration = TableTransformerConfig()
>>> # Initializing a model from the microsoft/table-transformer-detection style configuration
>>> model = TableTransformerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTableTransformerModel
class transformers.TableTransformerModel
< source >( config: TableTransformerConfig )
Parameters
- config (TableTransformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Table Transformer Model (consisting of a backbone and encoder-decoder Transformer) outputting raw hidden-states without any specific head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor pixel_mask: Optional = None decoder_attention_mask: Optional = None encoder_outputs: Optional = None inputs_embeds: Optional = None decoder_inputs_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it.Pixel values can be obtained using DetrImageProcessor. See DetrImageProcessor.call() for details.
- pixel_mask (
torch.FloatTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
- decoder_attention_mask (
torch.FloatTensorof shape(batch_size, num_queries), optional) — Not used by default. Can be used to mask object queries. - encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state, optional:hidden_states, optional:attentions)last_hidden_stateof shape(batch_size, sequence_length, hidden_size), optional) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passing the flattened feature map (output of the backbone + projection layer), you can choose to directly pass a flattened representation of an image. - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, num_queries, hidden_size), optional) — Optionally, instead of initializing the queries with a tensor of zeros, you can choose to directly pass an embedded representation. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput or tuple(torch.FloatTensor)
A transformers.models.table_transformer.modeling_table_transformer.TableTransformerModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TableTransformerConfig) and inputs.
- last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the decoder of the model. - decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the decoder at the output of each layer plus the initial embedding outputs. - decoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads. - encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. - encoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the encoder at the output of each layer plus the initial embedding outputs. - encoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads. - intermediate_hidden_states (
torch.FloatTensorof shape(config.decoder_layers, batch_size, sequence_length, hidden_size), optional, returned whenconfig.auxiliary_loss=True) — Intermediate decoder activations, i.e. the output of each decoder layer, each of them gone through a layernorm.
The TableTransformerModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoImageProcessor, TableTransformerModel
>>> from huggingface_hub import hf_hub_download
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerModel.from_pretrained("microsoft/table-transformer-detection")
>>> # prepare image for the model
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**inputs)
>>> # the last hidden states are the final query embeddings of the Transformer decoder
>>> # these are of shape (batch_size, num_queries, hidden_size)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 15, 256]TableTransformerForObjectDetection
class transformers.TableTransformerForObjectDetection
< source >( config: TableTransformerConfig )
Parameters
- config (TableTransformerConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Table Transformer Model (consisting of a backbone and encoder-decoder Transformer) with object detection heads on top, for tasks such as COCO detection.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( pixel_values: FloatTensor pixel_mask: Optional = None decoder_attention_mask: Optional = None encoder_outputs: Optional = None inputs_embeds: Optional = None decoder_inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Padding will be ignored by default should you provide it.Pixel values can be obtained using DetrImageProcessor. See DetrImageProcessor.call() for details.
- pixel_mask (
torch.FloatTensorof shape(batch_size, height, width), optional) — Mask to avoid performing attention on padding pixel values. Mask values selected in[0, 1]:- 1 for pixels that are real (i.e. not masked),
- 0 for pixels that are padding (i.e. masked).
- decoder_attention_mask (
torch.FloatTensorof shape(batch_size, num_queries), optional) — Not used by default. Can be used to mask object queries. - encoder_outputs (
tuple(tuple(torch.FloatTensor), optional) — Tuple consists of (last_hidden_state, optional:hidden_states, optional:attentions)last_hidden_stateof shape(batch_size, sequence_length, hidden_size), optional) is a sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention of the decoder. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passing the flattened feature map (output of the backbone + projection layer), you can choose to directly pass a flattened representation of an image. - decoder_inputs_embeds (
torch.FloatTensorof shape(batch_size, num_queries, hidden_size), optional) — Optionally, instead of initializing the queries with a tensor of zeros, you can choose to directly pass an embedded representation. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
List[Dict]of len(batch_size,), optional) — Labels for computing the bipartite matching loss. List of dicts, each dictionary containing at least the following 2 keys: ‘class_labels’ and ‘boxes’ (the class labels and bounding boxes of an image in the batch respectively). The class labels themselves should be atorch.LongTensorof len(number of bounding boxes in the image,)and the boxes atorch.FloatTensorof shape(number of bounding boxes in the image, 4).
Returns
transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput or tuple(torch.FloatTensor)
A transformers.models.table_transformer.modeling_table_transformer.TableTransformerObjectDetectionOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TableTransformerConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsare provided)) — Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized scale-invariant IoU loss. - loss_dict (
Dict, optional) — A dictionary containing the individual losses. Useful for logging. - logits (
torch.FloatTensorof shape(batch_size, num_queries, num_classes + 1)) — Classification logits (including no-object) for all queries. - pred_boxes (
torch.FloatTensorof shape(batch_size, num_queries, 4)) — Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding possible padding). You can use~TableTransformerImageProcessor.post_process_object_detectionto retrieve the unnormalized bounding boxes. - auxiliary_outputs (
list[Dict], optional) — Optional, only returned when auxilary losses are activated (i.e.config.auxiliary_lossis set toTrue) and labels are provided. It is a list of dictionaries containing the two above keys (logitsandpred_boxes) for each decoder layer. - last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the decoder of the model. - decoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the decoder at the output of each layer plus the initial embedding outputs. - decoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder, after the attention softmax, used to compute the weighted average in the self-attention heads. - cross_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the decoder’s cross-attention layer, after the attention softmax, used to compute the weighted average in the cross-attention heads. - encoder_last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Sequence of hidden-states at the output of the last layer of the encoder of the model. - encoder_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the encoder at the output of each layer plus the initial embedding outputs. - encoder_attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights of the encoder, after the attention softmax, used to compute the weighted average in the self-attention heads.
The TableTransformerForObjectDetection forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from huggingface_hub import hf_hub_download
>>> from transformers import AutoImageProcessor, TableTransformerForObjectDetection
>>> import torch
>>> from PIL import Image
>>> file_path = hf_hub_download(repo_id="nielsr/example-pdf", repo_type="dataset", filename="example_pdf.png")
>>> image = Image.open(file_path).convert("RGB")
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/table-transformer-detection")
>>> model = TableTransformerForObjectDetection.from_pretrained("microsoft/table-transformer-detection")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> target_sizes = torch.tensor([image.size[::-1]])
>>> results = image_processor.post_process_object_detection(outputs, threshold=0.9, target_sizes=target_sizes)[
... 0
... ]
>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
... box = [round(i, 2) for i in box.tolist()]
... print(
... f"Detected {model.config.id2label[label.item()]} with confidence "
... f"{round(score.item(), 3)} at location {box}"
... )
Detected table with confidence 1.0 at location [202.1, 210.59, 1119.22, 385.09]