¿Cómo los 🤗 Transformers resuelven tareas?
En Lo que 🤗 Transformers puede hacer, aprendiste sobre el procesamiento de lenguaje natural (NLP), tareas de voz y audio, visión por computadora y algunas aplicaciones importantes de ellas. Esta página se centrará en cómo los modelos resuelven estas tareas y explicará lo que está sucediendo debajo de la superficie. Hay muchas maneras de resolver una tarea dada, y diferentes modelos pueden implementar ciertas técnicas o incluso abordar la tarea desde un ángulo nuevo, pero para los modelos Transformer, la idea general es la misma. Debido a su arquitectura flexible, la mayoría de los modelos son una variante de una estructura de codificador, descodificador o codificador-descodificador. Además de los modelos Transformer, nuestra biblioteca también tiene varias redes neuronales convolucionales (CNNs) modernas, que todavía se utilizan hoy en día para tareas de visión por computadora. También explicaremos cómo funciona una CNN moderna.
Para explicar cómo se resuelven las tareas, caminaremos a través de lo que sucede dentro del modelo para generar predicciones útiles.
- Wav2Vec2 para clasificación de audio y reconocimiento automático de habla (ASR)
- Transformador de Visión (ViT) y ConvNeXT para clasificación de imágenes
- DETR para detección de objetos
- Mask2Former para segmentación de imagen
- GLPN para estimación de profundidad
- BERT para tareas de NLP como clasificación de texto, clasificación de tokens y preguntas y respuestas que utilizan un codificador
- GPT2 para tareas de NLP como generación de texto que utilizan un descodificador
- BART para tareas de NLP como resumen y traducción que utilizan un codificador-descodificador
Antes de continuar, es bueno tener un conocimiento básico de la arquitectura original del Transformer. Saber cómo funcionan los codificadores, decodificadores y la atención te ayudará a entender cómo funcionan los diferentes modelos de Transformer. Si estás empezando o necesitas repasar, ¡echa un vistazo a nuestro curso para obtener más información!
Habla y audio
Wav2Vec2 es un modelo auto-supervisado preentrenado en datos de habla no etiquetados y ajustado en datos etiquetados para clasificación de audio y reconocimiento automático de voz.
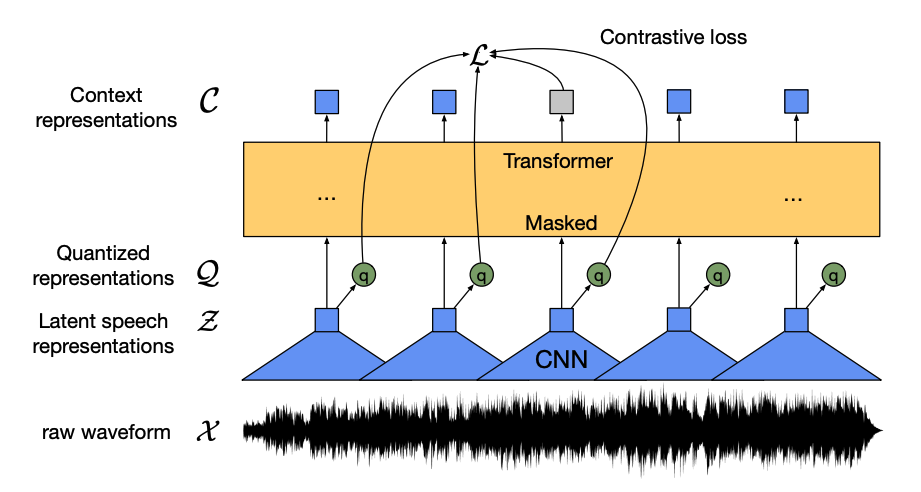
Este modelo tiene cuatro componentes principales:
Un codificador de características toma la forma de onda de audio cruda, la normaliza a media cero y varianza unitaria, y la convierte en una secuencia de vectores de características, cada uno de 20 ms de duración.
Las formas de onda son continuas por naturaleza, por lo que no se pueden dividir en unidades separadas como una secuencia de texto se puede dividir en palabras. Por eso, los vectores de características se pasan a un módulo de cuantificación, que tiene como objetivo aprender unidades de habla discretas. La unidad de habla se elige de una colección de palabras de código, conocidas como codebook (puedes pensar en esto como el vocabulario). Del codebook, se elige el vector o unidad de habla que mejor representa la entrada de audio continua y se envía a través del modelo.
Alrededor de la mitad de los vectores de características se enmascaran aleatoriamente, y el vector de características enmascarado se alimenta a una red de contexto, que es un codificador Transformer que también agrega incrustaciones posicionales relativas.
El objetivo del preentrenamiento de la red de contexto es una tarea contrastiva. El modelo tiene que predecir la verdadera representación de habla cuantizada de la predicción enmascarada a partir de un conjunto de falsas, lo que anima al modelo a encontrar el vector de contexto y la unidad de habla cuantizada más similares (la etiqueta objetivo).
¡Ahora que wav2vec2 está preentrenado, puedes ajustarlo con tus datos para clasificación de audio o reconocimiento automático de voz!
Clasificación de audio
Para usar el modelo preentrenado para la clasificación de audio, añade una capa de clasificación de secuencia encima del modelo base de Wav2Vec2. La capa de clasificación es una capa lineal que acepta los estados ocultos del codificador. Los estados ocultos representan las características aprendidas de cada fotograma de audio, que pueden tener longitudes variables. Para crear un vector de longitud fija, primero se agrupan los estados ocultos y luego se transforman en logits sobre las etiquetas de clase. La pérdida de entropía cruzada se calcula entre los logits y el objetivo para encontrar la clase más probable.
¿Listo para probar la clasificación de audio? ¡Consulta nuestra guía completa de clasificación de audio para aprender cómo ajustar Wav2Vec2 y usarlo para inferencia!
Reconocimiento automático de voz
Para usar el modelo preentrenado para el reconocimiento automático de voz, añade una capa de modelado del lenguaje encima del modelo base de Wav2Vec2 para CTC (clasificación temporal conexista). La capa de modelado del lenguaje es una capa lineal que acepta los estados ocultos del codificador y los transforma en logits. Cada logit representa una clase de token (el número de tokens proviene del vocabulario de la tarea). La pérdida de CTC se calcula entre los logits y los objetivos para encontrar la secuencia de tokens más probable, que luego se decodifican en una transcripción.
¿Listo para probar el reconocimiento automático de voz? ¡Consulta nuestra guía completa de reconocimiento automático de voz para aprender cómo ajustar Wav2Vec2 y usarlo para inferencia!
Visión por computadora
Hay dos formas de abordar las tareas de visión por computadora:
- Dividir una imagen en una secuencia de parches y procesarlos en paralelo con un Transformer.
- Utilizar una CNN moderna, como ConvNeXT, que se basa en capas convolucionales pero adopta diseños de redes modernas.
Un tercer enfoque combina Transformers con convoluciones (por ejemplo, Convolutional Vision Transformer o LeViT). No discutiremos estos porque simplemente combinan los dos enfoques que examinamos aquí.
ViT y ConvNeXT se utilizan comúnmente para la clasificación de imágenes, pero para otras tareas de visión como la detección de objetos, la segmentación y la estimación de profundidad, veremos DETR, Mask2Former y GLPN, respectivamente; estos modelos son más adecuados para esas tareas.
Clasificación de imágenes
ViT y ConvNeXT pueden usarse ambos para la clasificación de imágenes; la diferencia principal es que ViT utiliza un mecanismo de atención mientras que ConvNeXT utiliza convoluciones.
Transformer
ViT reemplaza completamente las convoluciones con una arquitectura de Transformer pura. Si estás familiarizado con el Transformer original, entonces ya estás en el camino para entender ViT.

El cambio principal que introdujo ViT fue en cómo se alimentan las imágenes a un Transformer:
Una imagen se divide en parches cuadrados no superpuestos, cada uno de los cuales se convierte en un vector o incrustación de parche(patch embedding). Las incrustaciones de parche se generan a partir de una capa convolucional 2D que crea las dimensiones de entrada adecuadas (que para un Transformer base son 768 valores para cada incrustación de parche). Si tuvieras una imagen de 224x224 píxeles, podrías dividirla en 196 parches de imagen de 16x16. Al igual que el texto se tokeniza en palabras, una imagen se “tokeniza” en una secuencia de parches.
Se agrega una incrustación aprendida - un token especial
[CLS]- al principio de las incrustaciones del parche, al igual que en BERT. El estado oculto final del token[CLS]se utiliza como la entrada para la cabecera de clasificación adjunta; otras salidas se ignoran. Este token ayuda al modelo a aprender cómo codificar una representación de la imagen.Lo último que se agrega a las incrustaciones de parche e incrustaciones aprendidas son las incrustaciones de posición porque el modelo no sabe cómo están ordenados los parches de imagen. Las incrustaciones de posición también son aprendibles y tienen el mismo tamaño que las incrustaciones de parche. Finalmente, todas las incrustaciones se pasan al codificador Transformer.
La salida, específicamente solo la salida con el token
[CLS], se pasa a una cabecera de perceptrón multicapa (MLP). El objetivo del preentrenamiento de ViT es simplemente la clasificación. Al igual que otras cabeceras de clasificación, la cabecera de MLP convierte la salida en logits sobre las etiquetas de clase y calcula la pérdida de entropía cruzada para encontrar la clase más probable.
¿Listo para probar la clasificación de imágenes? ¡Consulta nuestra guía completa de clasificación de imágenes para aprender cómo ajustar ViT y usarlo para inferencia!
CNN
Esta sección explica brevemente las convoluciones, pero sería útil tener un entendimiento previo de cómo cambian la forma y el tamaño de una imagen. Si no estás familiarizado con las convoluciones, ¡echa un vistazo al capítulo de Redes Neuronales Convolucionales del libro fastai!
ConvNeXT es una arquitectura de CNN que adopta diseños de redes nuevas y modernas para mejorar el rendimiento. Sin embargo, las convoluciones siguen siendo el núcleo del modelo. Desde una perspectiva de alto nivel, una convolución es una operación donde una matriz más pequeña (kernel) se multiplica por una pequeña ventana de píxeles de la imagen. Esta calcula algunas características de ella, como una textura particular o la curvatura de una línea. Luego, se desliza hacia la siguiente ventana de píxeles; la distancia que recorre la convolución se conoce como el stride.

Puedes alimentar esta salida a otra capa convolucional, y con cada capa sucesiva, la red aprende cosas más complejas y abstractas como perros calientes o cohetes. Entre capas convolucionales, es común añadir una capa de agrupación para reducir la dimensionalidad y hacer que el modelo sea más robusto a las variaciones de la posición de una característica.

ConvNeXT moderniza una CNN de cinco maneras:
Cambia el número de bloques en cada etapa y “fragmenta” una imagen con un paso y tamaño de kernel más grandes. La ventana deslizante no superpuesta hace que esta estrategia de fragmentación sea similar a cómo ViT divide una imagen en parches.
Una capa de cuello de botella reduce el número de canales y luego lo restaura porque es más rápido hacer una convolución de 1x1, y se puede aumentar la profundidad. Un cuello de botella invertido hace lo contrario al expandir el número de canales y luego reducirlos, lo cual es más eficiente en memoria.
Reemplaza la típica capa convolucional de 3x3 en la capa de cuello de botella con una convolución depthwise, que aplica una convolución a cada canal de entrada por separado y luego los apila de nuevo al final. Esto ensancha el ancho de la red para mejorar el rendimiento.
ViT tiene un campo receptivo global, lo que significa que puede ver más de una imagen a la vez gracias a su mecanismo de atención. ConvNeXT intenta replicar este efecto aumentando el tamaño del kernel a 7x7.
ConvNeXT también hace varios cambios en el diseño de capas que imitan a los modelos Transformer. Hay menos capas de activación y normalización, la función de activación se cambia a GELU en lugar de ReLU, y utiliza LayerNorm en lugar de BatchNorm.
La salida de los bloques convolucionales se pasa a una cabecera de clasificación que convierte las salidas en logits y calcula la pérdida de entropía cruzada para encontrar la etiqueta más probable.
Object detection
DETR, DEtection TRansformer, es un modelo de detección de objetos de un extremo a otro que combina una CNN con un codificador-decodificador Transformer.
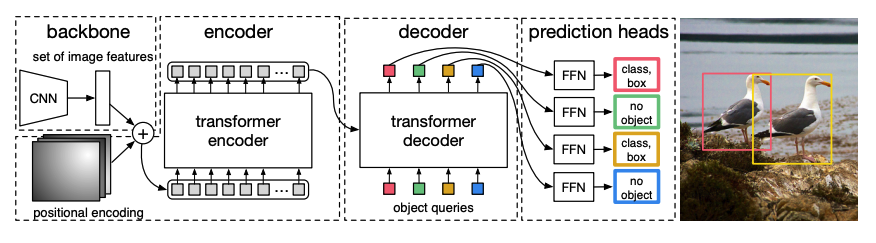
Una CNN preentrenada backbone toma una imagen, representada por sus valores de píxeles, y crea un mapa de características de baja resolución de la misma. A continuación, se aplica una convolución 1x1 al mapa de características para reducir la dimensionalidad y se crea un nuevo mapa de características con una representación de imagen de alto nivel. Dado que el Transformer es un modelo secuencial, el mapa de características se aplana en una secuencia de vectores de características que se combinan con incrustaciones posicionales.
Los vectores de características se pasan al codificador, que aprende las representaciones de imagen usando sus capas de atención. A continuación, los estados ocultos del codificador se combinan con consultas de objeto en el decodificador. Las consultas de objeto son incrustaciones aprendidas que se enfocan en las diferentes regiones de una imagen, y se actualizan a medida que avanzan a través de cada capa de atención. Los estados ocultos del decodificador se pasan a una red feedforward que predice las coordenadas del cuadro delimitador y la etiqueta de clase para cada consulta de objeto, o
no objetosi no hay ninguno.DETR descodifica cada consulta de objeto en paralelo para producir N predicciones finales, donde N es el número de consultas. A diferencia de un modelo autoregresivo típico que predice un elemento a la vez, la detección de objetos es una tarea de predicción de conjuntos (
cuadro delimitador,etiqueta de clase) que hace N predicciones en un solo paso.DETR utiliza una pérdida de coincidencia bipartita durante el entrenamiento para comparar un número fijo de predicciones con un conjunto fijo de etiquetas de verdad básica. Si hay menos etiquetas de verdad básica en el conjunto de N etiquetas, entonces se rellenan con una clase
no objeto. Esta función de pérdida fomenta que DETR encuentre una asignación uno a uno entre las predicciones y las etiquetas de verdad básica. Si los cuadros delimitadores o las etiquetas de clase no son correctos, se incurre en una pérdida. Del mismo modo, si DETR predice un objeto que no existe, se penaliza. Esto fomenta que DETR encuentre otros objetos en una imagen en lugar de centrarse en un objeto realmente prominente.
Se añade una cabecera de detección de objetos encima de DETR para encontrar la etiqueta de clase y las coordenadas del cuadro delimitador. Hay dos componentes en la cabecera de detección de objetos: una capa lineal para transformar los estados ocultos del decodificador en logits sobre las etiquetas de clase, y una MLP para predecir el cuadro delimitador.
¿Listo para probar la detección de objetos? ¡Consulta nuestra guía completa de detección de objetos para aprender cómo ajustar DETR y usarlo para inferencia!
Segmentación de imágenes
Mask2Former es una arquitectura universal para resolver todos los tipos de tareas de segmentación de imágenes. Los modelos de segmentación tradicionales suelen estar adaptados a una tarea particular de segmentación de imágenes, como la segmentación de instancias, semántica o panóptica. Mask2Former enmarca cada una de esas tareas como un problema de clasificación de máscaras. La clasificación de máscaras agrupa píxeles en N segmentos, y predice N máscaras y su etiqueta de clase correspondiente para una imagen dada. Explicaremos cómo funciona Mask2Former en esta sección, y luego podrás probar el ajuste fino de SegFormer al final.

Hay tres componentes principales en Mask2Former:
Un backbone Swin acepta una imagen y crea un mapa de características de imagen de baja resolución a partir de 3 convoluciones consecutivas de 3x3.
El mapa de características se pasa a un decodificador de píxeles que aumenta gradualmente las características de baja resolución en incrustaciones de alta resolución por píxel. De hecho, el decodificador de píxeles genera características multiescala (contiene características de baja y alta resolución) con resoluciones de 1/32, 1/16 y 1/8 de la imagen original.
Cada uno de estos mapas de características de diferentes escalas se alimenta sucesivamente a una capa decodificadora Transformer a la vez para capturar objetos pequeños de las características de alta resolución. La clave de Mask2Former es el mecanismo de atención enmascarada en el decodificador. A diferencia de la atención cruzada que puede atender a toda la imagen, la atención enmascarada solo se centra en cierta área de la imagen. Esto es más rápido y conduce a un mejor rendimiento porque las características locales de una imagen son suficientes para que el modelo aprenda.
Al igual que DETR, Mask2Former también utiliza consultas de objetos aprendidas y las combina con las características de la imagen del decodificador de píxeles para hacer una predicción de conjunto (
etiqueta de clase,predicción de máscara). Los estados ocultos del decodificador se pasan a una capa lineal y se transforman en logits sobre las etiquetas de clase. Se calcula la pérdida de entropía cruzada entre los logits y la etiqueta de clase para encontrar la más probable.Las predicciones de máscara se generan combinando las incrustaciones de píxeles con los estados ocultos finales del decodificador. La pérdida de entropía cruzada sigmoidea y de la pérdida DICE se calcula entre los logits y la máscara de verdad básica para encontrar la máscara más probable.
¿Listo para probar la detección de objetos? ¡Consulta nuestra guía completa de segmentación de imágenes para aprender cómo ajustar SegFormer y usarlo para inferencia!
Estimación de profundidad
GLPN, Global-Local Path Network, es un Transformer para la estimación de profundidad que combina un codificador SegFormer con un decodificador ligero.

Al igual que ViT, una imagen se divide en una secuencia de parches, excepto que estos parches de imagen son más pequeños. Esto es mejor para tareas de predicción densa como la segmentación o la estimación de profundidad. Los parches de imagen se transforman en incrustaciones de parches (ver la sección de clasificación de imágenes para más detalles sobre cómo se crean las incrustaciones de parches), que se alimentan al codificador.
El codificador acepta las incrustaciones de parches y las pasa a través de varios bloques codificadores. Cada bloque consiste en capas de atención y Mix-FFN. El propósito de este último es proporcionar información posicional. Al final de cada bloque codificador hay una capa de fusión de parches para crear representaciones jerárquicas. Las características de cada grupo de parches vecinos se concatenan, y se aplica una capa lineal a las características concatenadas para reducir el número de parches a una resolución de 1/4. Esto se convierte en la entrada al siguiente bloque codificador, donde se repite todo este proceso hasta que tengas características de imagen con resoluciones de 1/8, 1/16 y 1/32.
Un decodificador ligero toma el último mapa de características (escala 1/32) del codificador y lo aumenta a una escala de 1/16. A partir de aquí, la característica se pasa a un módulo de Fusión Selectiva de Características (SFF), que selecciona y combina características locales y globales de un mapa de atención para cada característica y luego la aumenta a 1/8. Este proceso se repite hasta que las características decodificadas sean del mismo tamaño que la imagen original. La salida se pasa a través de dos capas de convolución y luego se aplica una activación sigmoide para predecir la profundidad de cada píxel.
Procesamiento del lenguaje natural
El Transformer fue diseñado inicialmente para la traducción automática, y desde entonces, prácticamente se ha convertido en la arquitectura predeterminada para resolver todas las tareas de procesamiento del lenguaje natural (NLP, por sus siglas en inglés). Algunas tareas se prestan a la estructura del codificador del Transformer, mientras que otras son más adecuadas para el decodificador. Todavía hay otras tareas que hacen uso de la estructura codificador-decodificador del Transformer.
Clasificación de texto
BERT es un modelo que solo tiene codificador y es el primer modelo en implementar efectivamente la bidireccionalidad profunda para aprender representaciones más ricas del texto al atender a las palabras en ambos lados.
BERT utiliza la tokenización WordPiece para generar una incrustación de tokens del texto. Para diferenciar entre una sola oración y un par de oraciones, se agrega un token especial
[SEP]para diferenciarlos. También se agrega un token especial[CLS]al principio de cada secuencia de texto. La salida final con el token[CLS]se utiliza como la entrada a la cabeza de clasificación para tareas de clasificación. BERT también agrega una incrustación de segmento para indicar si un token pertenece a la primera o segunda oración en un par de oraciones.BERT se preentrena con dos objetivos: modelar el lenguaje enmascarado y predecir de próxima oración. En el modelado de lenguaje enmascarado, un cierto porcentaje de los tokens de entrada se enmascaran aleatoriamente, y el modelo necesita predecir estos. Esto resuelve el problema de la bidireccionalidad, donde el modelo podría hacer trampa y ver todas las palabras y “predecir” la siguiente palabra. Los estados ocultos finales de los tokens de máscara predichos se pasan a una red feedforward con una softmax sobre el vocabulario para predecir la palabra enmascarada.
El segundo objetivo de preentrenamiento es la predicción de próxima oración. El modelo debe predecir si la oración B sigue a la oración A. La mitad del tiempo, la oración B es la siguiente oración, y la otra mitad del tiempo, la oración B es una oración aleatoria. La predicción, ya sea que sea la próxima oración o no, se pasa a una red feedforward con una softmax sobre las dos clases (
EsSiguienteyNoSiguiente).Las incrustaciones de entrada se pasan a través de múltiples capas codificadoras para producir algunos estados ocultos finales.
Para usar el modelo preentrenado para clasificación de texto, se añade una cabecera de clasificación de secuencia encima del modelo base de BERT. La cabecera de clasificación de secuencia es una capa lineal que acepta los estados ocultos finales y realiza una transformación lineal para convertirlos en logits. Se calcula la pérdida de entropía cruzada entre los logits y el objetivo para encontrar la etiqueta más probable.
¿Listo para probar la clasificación de texto? ¡Consulta nuestra guía completa de clasificación de texto para aprender cómo ajustar DistilBERT y usarlo para inferencia!
Clasificación de tokens
Para usar BERT en tareas de clasificación de tokens como el reconocimiento de entidades nombradas (NER), añade una cabecera de clasificación de tokens encima del modelo base de BERT. La cabecera de clasificación de tokens es una capa lineal que acepta los estados ocultos finales y realiza una transformación lineal para convertirlos en logits. Se calcula la pérdida de entropía cruzada entre los logits y cada token para encontrar la etiqueta más probable.
¿Listo para probar la clasificación de tokens? ¡Consulta nuestra guía completa de clasificación de tokens para aprender cómo ajustar DistilBERT y usarlo para inferencia!
Respuesta a preguntas
Para usar BERT en la respuesta a preguntas, añade una cabecera de clasificación de span encima del modelo base de BERT. Esta capa lineal acepta los estados ocultos finales y realiza una transformación lineal para calcular los logits de inicio y fin del span correspondiente a la respuesta. Se calcula la pérdida de entropía cruzada entre los logits y la posición de la etiqueta para encontrar el span más probable de texto correspondiente a la respuesta.
¿Listo para probar la respuesta a preguntas? ¡Consulta nuestra guía completa de respuesta a preguntas para aprender cómo ajustar DistilBERT y usarlo para inferencia!
💡 ¡Observa lo fácil que es usar BERT para diferentes tareas una vez que ha sido preentrenado! ¡Solo necesitas añadir una cabecera específica al modelo preentrenado para manipular los estados ocultos en tu salida deseada!
Generación de texto
GPT-2 es un modelo que solo tiene decodificador y se preentrena en una gran cantidad de texto. Puede generar texto convincente (¡aunque no siempre verdadero!) dado un estímulo y completar otras tareas de procesamiento del lenguaje natural como responder preguntas, a pesar de no haber sido entrenado explícitamente para ello.
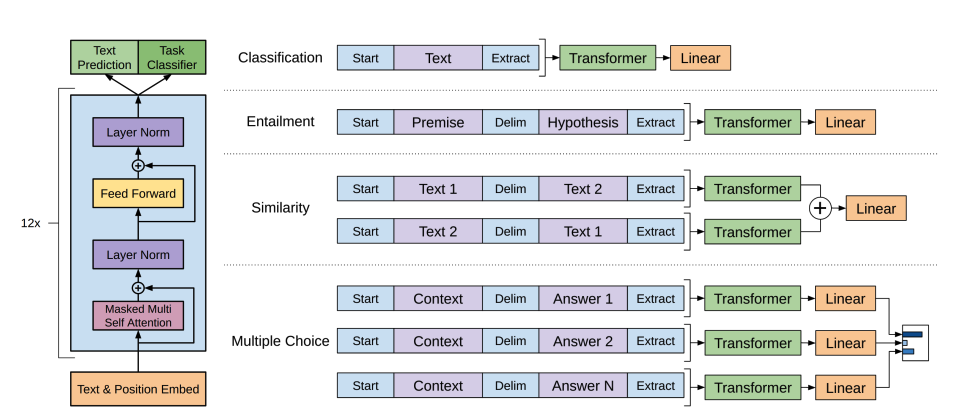
GPT-2 utiliza codificación de pares de bytes (BPE) para tokenizar palabras y generar una incrustación de token. Se añaden incrustaciones posicionales a las incrustaciones de token para indicar la posición de cada token en la secuencia. Las incrustaciones de entrada se pasan a través de varios bloques decodificadores para producir algún estado oculto final. Dentro de cada bloque decodificador, GPT-2 utiliza una capa de autoatención enmascarada, lo que significa que GPT-2 no puede atender a los tokens futuros. Solo puede atender a los tokens a la izquierda. Esto es diferente al token
maskde BERT porque, en la autoatención enmascarada, se utiliza una máscara de atención para establecer la puntuación en0para los tokens futuros.La salida del decodificador se pasa a una cabecera de modelado de lenguaje, que realiza una transformación lineal para convertir los estados ocultos en logits. La etiqueta es el siguiente token en la secuencia, que se crea desplazando los logits a la derecha en uno. Se calcula la pérdida de entropía cruzada entre los logits desplazados y las etiquetas para obtener el siguiente token más probable.
El objetivo del preentrenamiento de GPT-2 se basa completamente en el modelado de lenguaje causal, prediciendo la siguiente palabra en una secuencia. Esto hace que GPT-2 sea especialmente bueno en tareas que implican la generación de texto.
¿Listo para probar la generación de texto? ¡Consulta nuestra guía completa de modelado de lenguaje causal para aprender cómo ajustar DistilGPT-2 y usarlo para inferencia!
Para obtener más información sobre la generación de texto, ¡consulta la guía de estrategias de generación de texto!
Resumir
Los modelos codificador-decodificador como BART y T5 están diseñados para el patrón de secuencia a secuencia de una tarea de resumen. Explicaremos cómo funciona BART en esta sección, y luego podrás probar el ajuste fino de T5 al final.
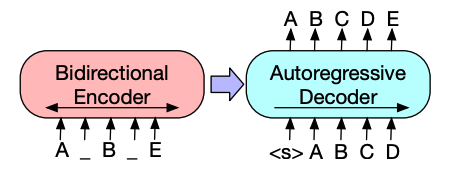
La arquitectura del codificador de BART es muy similar a la de BERT y acepta una incrustación de token y posicional del texto. BART se preentrena corrompiendo la entrada y luego reconstruyéndola con el decodificador. A diferencia de otros codificadores con estrategias específicas de corrupción, BART puede aplicar cualquier tipo de corrupción. Sin embargo, la estrategia de corrupción de relleno de texto funciona mejor. En el relleno de texto, varios fragmentos de texto se reemplazan con un único token
mask. Esto es importante porque el modelo tiene que predecir los tokens enmascarados, y le enseña al modelo a predecir la cantidad de tokens faltantes. Las incrustaciones de entrada y los fragmentos enmascarados se pasan a través del codificador para producir algunos estados ocultos finales, pero a diferencia de BERT, BART no añade una red feedforward final al final para predecir una palabra.La salida del codificador se pasa al decodificador, que debe predecir los tokens enmascarados y cualquier token no corrompido de la salida del codificador. Esto proporciona un contexto adicional para ayudar al decodificador a restaurar el texto original. La salida del decodificador se pasa a una cabeza de modelado de lenguaje, que realiza una transformación lineal para convertir los estados ocultos en logits. Se calcula la pérdida de entropía cruzada entre los logits y la etiqueta, que es simplemente el token desplazado hacia la derecha.
¿Listo para probar la sumarización? ¡Consulta nuestra guía completa de Generación de resúmenes para aprender cómo ajustar T5 y usarlo para inferencia!
Para obtener más información sobre la generación de texto, ¡consulta la guía de estrategias de generación de texto!
Traducción
La traducción es otro ejemplo de una tarea de secuencia a secuencia, lo que significa que puedes usar un modelo codificador-decodificador como BART o T5 para hacerlo. Explicaremos cómo funciona BART en esta sección, y luego podrás probar el ajuste fino de T5 al final.
BART se adapta a la traducción añadiendo un codificador separado inicializado aleatoriamente para mapear un idioma fuente a una entrada que pueda ser decodificada en el idioma objetivo. Las incrustaciones de este nuevo codificador se pasan al codificador preentrenado en lugar de las incrustaciones de palabras originales. El codificador de origen se entrena actualizando el codificador de origen, las incrustaciones posicionales y las incrustaciones de entrada con la pérdida de entropía cruzada de la salida del modelo. Los parámetros del modelo están congelados en este primer paso, y todos los parámetros del modelo se entrenan juntos en el segundo paso.
Desde entonces, BART ha sido seguido por una versión multilingüe, mBART, destinada a la traducción y preentrenada en muchos idiomas diferentes.
¿Listo para probar la traducción? ¡Consulta nuestra guía completa de traducción para aprender cómo ajustar T5 y usarlo para inferencia!
Para obtener más información sobre la generación de texto, ¡consulta la guía de estrategias de generación de texto!