Transformers documentation
OWLv2
OWLv2
Overview
OWLv2 was proposed in Scaling Open-Vocabulary Object Detection by Matthias Minderer, Alexey Gritsenko, Neil Houlsby. OWLv2 scales up OWL-ViT using self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. This results in large gains over the previous state-of-the-art for zero-shot object detection.
The abstract from the paper is the following:
Open-vocabulary object detection has benefited greatly from pretrained vision-language models, but is still limited by the amount of available detection training data. While detection training data can be expanded by using Web image-text pairs as weak supervision, this has not been done at scales comparable to image-level pretraining. Here, we scale up detection data with self-training, which uses an existing detector to generate pseudo-box annotations on image-text pairs. Major challenges in scaling self-training are the choice of label space, pseudo-annotation filtering, and training efficiency. We present the OWLv2 model and OWL-ST self-training recipe, which address these challenges. OWLv2 surpasses the performance of previous state-of-the-art open-vocabulary detectors already at comparable training scales (~10M examples). However, with OWL-ST, we can scale to over 1B examples, yielding further large improvement: With an L/14 architecture, OWL-ST improves AP on LVIS rare classes, for which the model has seen no human box annotations, from 31.2% to 44.6% (43% relative improvement). OWL-ST unlocks Web-scale training for open-world localization, similar to what has been seen for image classification and language modelling.
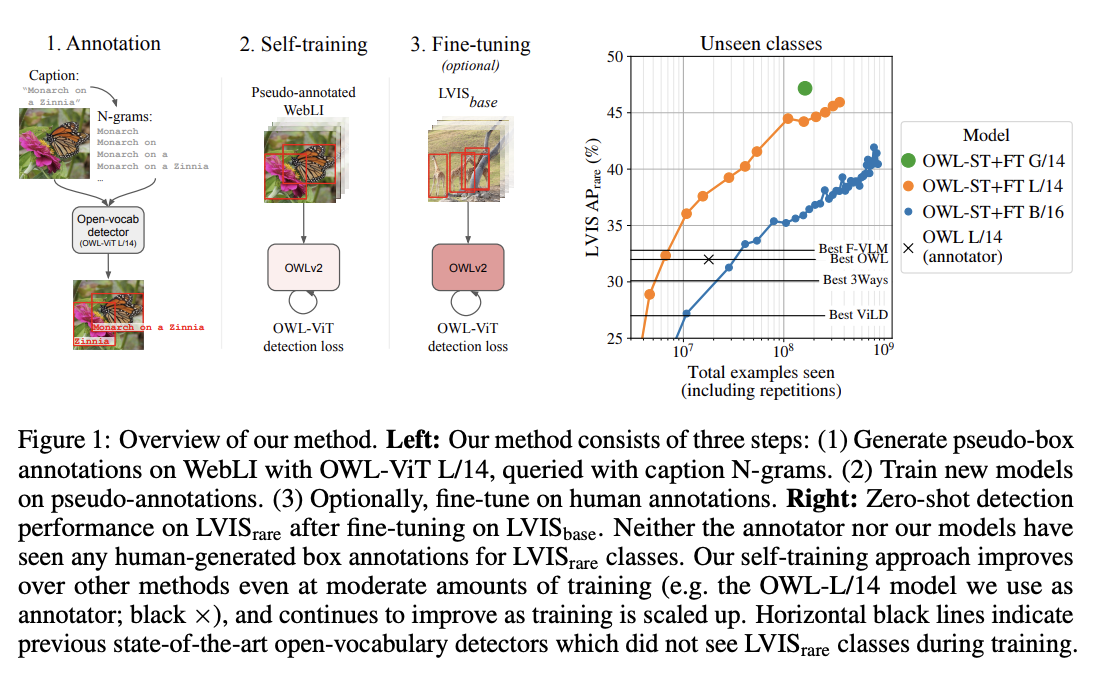 OWLv2 high-level overview. Taken from the original paper.
OWLv2 high-level overview. Taken from the original paper. This model was contributed by nielsr. The original code can be found here.
Usage example
OWLv2 is, just like its predecessor OWL-ViT, a zero-shot text-conditioned object detection model. OWL-ViT uses CLIP as its multi-modal backbone, with a ViT-like Transformer to get visual features and a causal language model to get the text features. To use CLIP for detection, OWL-ViT removes the final token pooling layer of the vision model and attaches a lightweight classification and box head to each transformer output token. Open-vocabulary classification is enabled by replacing the fixed classification layer weights with the class-name embeddings obtained from the text model. The authors first train CLIP from scratch and fine-tune it end-to-end with the classification and box heads on standard detection datasets using a bipartite matching loss. One or multiple text queries per image can be used to perform zero-shot text-conditioned object detection.
Owlv2ImageProcessor can be used to resize (or rescale) and normalize images for the model and CLIPTokenizer is used to encode the text. Owlv2Processor wraps Owlv2ImageProcessor and CLIPTokenizer into a single instance to both encode the text and prepare the images. The following example shows how to perform object detection using Owlv2Processor and Owlv2ForObjectDetection.
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC Format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.614 at location [341.67, 17.54, 642.32, 278.51]
Detected a photo of a cat with confidence 0.665 at location [6.75, 38.97, 326.62, 354.85]Resources
- A demo notebook on using OWLv2 for zero- and one-shot (image-guided) object detection can be found here.
- Zero-shot object detection task guide
The architecture of OWLv2 is identical to OWL-ViT, however the object detection head now also includes an objectness classifier, which predicts the (query-agnostic) likelihood that a predicted box contains an object (as opposed to background). The objectness score can be used to rank or filter predictions independently of text queries. Usage of OWLv2 is identical to OWL-ViT with a new, updated image processor (Owlv2ImageProcessor).
Owlv2Config
class transformers.Owlv2Config
< source >( text_config = None vision_config = None projection_dim = 512 logit_scale_init_value = 2.6592 return_dict = True **kwargs )
Parameters
- text_config (
dict, optional) — Dictionary of configuration options used to initialize Owlv2TextConfig. - vision_config (
dict, optional) — Dictionary of configuration options used to initialize Owlv2VisionConfig. - projection_dim (
int, optional, defaults to 512) — Dimensionality of text and vision projection layers. - logit_scale_init_value (
float, optional, defaults to 2.6592) — The inital value of the logit_scale parameter. Default is used as per the original OWLv2 implementation. - return_dict (
bool, optional, defaults toTrue) — Whether or not the model should return a dictionary. IfFalse, returns a tuple. - kwargs (optional) — Dictionary of keyword arguments.
Owlv2Config is the configuration class to store the configuration of an Owlv2Model. It is used to instantiate an OWLv2 model according to the specified arguments, defining the text model and vision model configs. Instantiating a configuration with the defaults will yield a similar configuration to that of the OWLv2 google/owlv2-base-patch16 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
from_text_vision_configs
< source >( text_config: Dict vision_config: Dict **kwargs ) → Owlv2Config
Instantiate a Owlv2Config (or a derived class) from owlv2 text model configuration and owlv2 vision model configuration.
Owlv2TextConfig
class transformers.Owlv2TextConfig
< source >( vocab_size = 49408 hidden_size = 512 intermediate_size = 2048 num_hidden_layers = 12 num_attention_heads = 8 max_position_embeddings = 16 hidden_act = 'quick_gelu' layer_norm_eps = 1e-05 attention_dropout = 0.0 initializer_range = 0.02 initializer_factor = 1.0 pad_token_id = 0 bos_token_id = 49406 eos_token_id = 49407 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 49408) — Vocabulary size of the OWLv2 text model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling Owlv2TextModel. - hidden_size (
int, optional, defaults to 512) — Dimensionality of the encoder layers and the pooler layer. - intermediate_size (
int, optional, defaults to 2048) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 8) — Number of attention heads for each attention layer in the Transformer encoder. - max_position_embeddings (
int, optional, defaults to 16) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - hidden_act (
strorfunction, optional, defaults to"quick_gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"`"quick_gelu"are supported. - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - initializer_factor (
float, optional, defaults to 1.0) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing). - pad_token_id (
int, optional, defaults to 0) — The id of the padding token in the input sequences. - bos_token_id (
int, optional, defaults to 49406) — The id of the beginning-of-sequence token in the input sequences. - eos_token_id (
int, optional, defaults to 49407) — The id of the end-of-sequence token in the input sequences.
This is the configuration class to store the configuration of an Owlv2TextModel. It is used to instantiate an Owlv2 text encoder according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Owlv2 google/owlv2-base-patch16 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import Owlv2TextConfig, Owlv2TextModel
>>> # Initializing a Owlv2TextModel with google/owlv2-base-patch16 style configuration
>>> configuration = Owlv2TextConfig()
>>> # Initializing a Owlv2TextConfig from the google/owlv2-base-patch16 style configuration
>>> model = Owlv2TextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOwlv2VisionConfig
class transformers.Owlv2VisionConfig
< source >( hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 num_channels = 3 image_size = 768 patch_size = 16 hidden_act = 'quick_gelu' layer_norm_eps = 1e-05 attention_dropout = 0.0 initializer_range = 0.02 initializer_factor = 1.0 **kwargs )
Parameters
- hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (i.e., feed-forward) layer in the Transformer encoder. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - num_channels (
int, optional, defaults to 3) — Number of channels in the input images. - image_size (
int, optional, defaults to 768) — The size (resolution) of each image. - patch_size (
int, optional, defaults to 16) — The size (resolution) of each patch. - hidden_act (
strorfunction, optional, defaults to"quick_gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","selu"and"gelu_new"`"quick_gelu"are supported. - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the layer normalization layers. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - initializer_factor (
float, optional, defaults to 1.0) — A factor for initializing all weight matrices (should be kept to 1, used internally for initialization testing).
This is the configuration class to store the configuration of an Owlv2VisionModel. It is used to instantiate an OWLv2 image encoder according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the OWLv2 google/owlv2-base-patch16 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import Owlv2VisionConfig, Owlv2VisionModel
>>> # Initializing a Owlv2VisionModel with google/owlv2-base-patch16 style configuration
>>> configuration = Owlv2VisionConfig()
>>> # Initializing a Owlv2VisionModel model from the google/owlv2-base-patch16 style configuration
>>> model = Owlv2VisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configOwlv2ImageProcessor
class transformers.Owlv2ImageProcessor
< source >( do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_pad: bool = True do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )
Parameters
- do_rescale (
bool, optional, defaults toTrue) — Whether to rescale the image by the specified scalerescale_factor. Can be overriden bydo_rescalein thepreprocessmethod. - rescale_factor (
intorfloat, optional, defaults to1/255) — Scale factor to use if rescaling the image. Can be overriden byrescale_factorin thepreprocessmethod. - do_pad (
bool, optional, defaults toTrue) — Whether to pad the image to a square with gray pixels on the bottom and the right. Can be overriden bydo_padin thepreprocessmethod. - do_resize (
bool, optional, defaults toTrue) — Controls whether to resize the image’s (height, width) dimensions to the specifiedsize. Can be overriden bydo_resizein thepreprocessmethod. - size (
Dict[str, int]optional, defaults to{"height" -- 960, "width": 960}): Size to resize the image to. Can be overriden bysizein thepreprocessmethod. - resample (
PILImageResampling, optional, defaults toResampling.BILINEAR) — Resampling method to use if resizing the image. Can be overriden byresamplein thepreprocessmethod. - do_normalize (
bool, optional, defaults toTrue) — Whether to normalize the image. Can be overridden by thedo_normalizeparameter in thepreprocessmethod. - image_mean (
floatorList[float], optional, defaults toOPENAI_CLIP_MEAN) — Mean to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_meanparameter in thepreprocessmethod. - image_std (
floatorList[float], optional, defaults toOPENAI_CLIP_STD) — Standard deviation to use if normalizing the image. This is a float or list of floats the length of the number of channels in the image. Can be overridden by theimage_stdparameter in thepreprocessmethod.
Constructs an OWLv2 image processor.
preprocess
< source >( images: Union do_pad: bool = None do_resize: bool = None size: Dict = None do_rescale: bool = None rescale_factor: float = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: ChannelDimension = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
Parameters
- images (
ImageInput) — Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If passing in images with pixel values between 0 and 1, setdo_rescale=False. - do_pad (
bool, optional, defaults toself.do_pad) — Whether to pad the image to a square with gray pixels on the bottom and the right. - do_resize (
bool, optional, defaults toself.do_resize) — Whether to resize the image. - size (
Dict[str, int], optional, defaults toself.size) — Size to resize the image to. - do_rescale (
bool, optional, defaults toself.do_rescale) — Whether to rescale the image values between [0 - 1]. - rescale_factor (
float, optional, defaults toself.rescale_factor) — Rescale factor to rescale the image by ifdo_rescaleis set toTrue. - do_normalize (
bool, optional, defaults toself.do_normalize) — Whether to normalize the image. - image_mean (
floatorList[float], optional, defaults toself.image_mean) — Image mean. - image_std (
floatorList[float], optional, defaults toself.image_std) — Image standard deviation. - return_tensors (
strorTensorType, optional) — The type of tensors to return. Can be one of:- Unset: Return a list of
np.ndarray. TensorType.TENSORFLOWor'tf': Return a batch of typetf.Tensor.TensorType.PYTORCHor'pt': Return a batch of typetorch.Tensor.TensorType.NUMPYor'np': Return a batch of typenp.ndarray.TensorType.JAXor'jax': Return a batch of typejax.numpy.ndarray.
- Unset: Return a list of
- data_format (
ChannelDimensionorstr, optional, defaults toChannelDimension.FIRST) — The channel dimension format for the output image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format.- Unset: Use the channel dimension format of the input image.
- input_data_format (
ChannelDimensionorstr, optional) — The channel dimension format for the input image. If unset, the channel dimension format is inferred from the input image. Can be one of:"channels_first"orChannelDimension.FIRST: image in (num_channels, height, width) format."channels_last"orChannelDimension.LAST: image in (height, width, num_channels) format."none"orChannelDimension.NONE: image in (height, width) format.
Preprocess an image or batch of images.
post_process_object_detection
< source >( outputs threshold: float = 0.1 target_sizes: Union = None ) → List[Dict]
Parameters
- outputs (
OwlViTObjectDetectionOutput) — Raw outputs of the model. - threshold (
float, optional) — Score threshold to keep object detection predictions. - target_sizes (
torch.TensororList[Tuple[int, int]], optional) — Tensor of shape(batch_size, 2)or list of tuples (Tuple[int, int]) containing the target size(height, width)of each image in the batch. If unset, predictions will not be resized.
Returns
List[Dict]
A list of dictionaries, each dictionary containing the scores, labels and boxes for an image in the batch as predicted by the model.
Converts the raw output of OwlViTForObjectDetection into final bounding boxes in (top_left_x, top_left_y, bottom_right_x, bottom_right_y) format.
post_process_image_guided_detection
< source >( outputs threshold = 0.0 nms_threshold = 0.3 target_sizes = None ) → List[Dict]
Parameters
- outputs (
OwlViTImageGuidedObjectDetectionOutput) — Raw outputs of the model. - threshold (
float, optional, defaults to 0.0) — Minimum confidence threshold to use to filter out predicted boxes. - nms_threshold (
float, optional, defaults to 0.3) — IoU threshold for non-maximum suppression of overlapping boxes. - target_sizes (
torch.Tensor, optional) — Tensor of shape (batch_size, 2) where each entry is the (height, width) of the corresponding image in the batch. If set, predicted normalized bounding boxes are rescaled to the target sizes. If left to None, predictions will not be unnormalized.
Returns
List[Dict]
A list of dictionaries, each dictionary containing the scores, labels and boxes for an image
in the batch as predicted by the model. All labels are set to None as
OwlViTForObjectDetection.image_guided_detection perform one-shot object detection.
Converts the output of OwlViTForObjectDetection.image_guided_detection() into the format expected by the COCO api.
Owlv2Processor
class transformers.Owlv2Processor
< source >( image_processor tokenizer **kwargs )
Parameters
- image_processor (Owlv2ImageProcessor) — The image processor is a required input.
- tokenizer ([
CLIPTokenizer,CLIPTokenizerFast]) — The tokenizer is a required input.
Constructs an Owlv2 processor which wraps Owlv2ImageProcessor and CLIPTokenizer/CLIPTokenizerFast into
a single processor that interits both the image processor and tokenizer functionalities. See the
__call__() and decode() for more information.
This method forwards all its arguments to CLIPTokenizerFast’s batch_decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to CLIPTokenizerFast’s decode(). Please refer to the docstring of this method for more information.
This method forwards all its arguments to OwlViTImageProcessor.post_process_one_shot_object_detection.
Please refer to the docstring of this method for more information.
This method forwards all its arguments to OwlViTImageProcessor.post_process_object_detection(). Please refer to the docstring of this method for more information.
Owlv2Model
class transformers.Owlv2Model
< source >( config: Owlv2Config )
Parameters
- config (
Owvl2Config) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None pixel_values: Optional = None attention_mask: Optional = None return_loss: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_base_image_embeds: Optional = None return_dict: Optional = None ) → transformers.models.owlv2.modeling_owlv2.Owlv2Output or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- return_loss (
bool, optional) — Whether or not to return the contrastive loss. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_base_image_embeds (
bool, optional) — Whether or not to return the base image embeddings. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.owlv2.modeling_owlv2.Owlv2Output or tuple(torch.FloatTensor)
A transformers.models.owlv2.modeling_owlv2.Owlv2Output or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.owlv2.configuration_owlv2.Owlv2Config'>) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenreturn_lossisTrue) — Contrastive loss for image-text similarity. - logits_per_image (
torch.FloatTensorof shape(image_batch_size, text_batch_size)) — The scaled dot product scores betweenimage_embedsandtext_embeds. This represents the image-text similarity scores. - logits_per_text (
torch.FloatTensorof shape(text_batch_size, image_batch_size)) — The scaled dot product scores betweentext_embedsandimage_embeds. This represents the text-image similarity scores. - text_embeds (
torch.FloatTensorof shape(batch_size * num_max_text_queries, output_dim) — The text embeddings obtained by applying the projection layer to the pooled output of Owlv2TextModel. - image_embeds (
torch.FloatTensorof shape(batch_size, output_dim) — The image embeddings obtained by applying the projection layer to the pooled output of Owlv2VisionModel. - text_model_output (Tuple
BaseModelOutputWithPooling) — The output of the Owlv2TextModel. - vision_model_output (
BaseModelOutputWithPooling) — The output of the Owlv2VisionModel.
The Owlv2Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Owlv2Model
>>> model = Owlv2Model.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=[["a photo of a cat", "a photo of a dog"]], images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilitiesget_text_features
< source >( input_ids: Optional = None attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → text_features (torch.FloatTensor of shape (batch_size, output_dim)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size * num_max_text_queries, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, num_max_text_queries, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
text_features (torch.FloatTensor of shape (batch_size, output_dim)
The text embeddings obtained by applying the projection layer to the pooled output of Owlv2TextModel.
The Owlv2Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, Owlv2Model
>>> model = Owlv2Model.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> inputs = processor(
... text=[["a photo of a cat", "a photo of a dog"], ["photo of a astranaut"]], return_tensors="pt"
... )
>>> text_features = model.get_text_features(**inputs)get_image_features
< source >( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → image_features (torch.FloatTensor of shape (batch_size, output_dim)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
image_features (torch.FloatTensor of shape (batch_size, output_dim)
The image embeddings obtained by applying the projection layer to the pooled output of Owlv2VisionModel.
The Owlv2Model forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Owlv2Model
>>> model = Owlv2Model.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> image_features = model.get_image_features(**inputs)Owlv2TextModel
forward
< source >( input_ids: Tensor attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size * num_max_text_queries, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - attention_mask (
torch.Tensorof shape(batch_size, num_max_text_queries, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.owlv2.configuration_owlv2.Owlv2TextConfig'>) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Owlv2TextModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoProcessor, Owlv2TextModel
>>> model = Owlv2TextModel.from_pretrained("google/owlv2-base-patch16")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16")
>>> inputs = processor(
... text=[["a photo of a cat", "a photo of a dog"], ["photo of a astranaut"]], return_tensors="pt"
... )
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) statesOwlv2VisionModel
forward
< source >( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.owlv2.configuration_owlv2.Owlv2VisionConfig'>) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The Owlv2VisionModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, Owlv2VisionModel
>>> model = Owlv2VisionModel.from_pretrained("google/owlv2-base-patch16")
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled CLS statesOwlv2ForObjectDetection
forward
< source >( input_ids: Tensor pixel_values: FloatTensor attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.owlv2.modeling_owlv2.Owlv2ObjectDetectionOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. - input_ids (
torch.LongTensorof shape(batch_size * num_max_text_queries, sequence_length), optional) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs?. - attention_mask (
torch.Tensorof shape(batch_size, num_max_text_queries, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked. What are attention masks?
- output_hidden_states (
bool, optional) — Whether or not to return the last hidden state. Seetext_model_last_hidden_stateandvision_model_last_hidden_stateunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.owlv2.modeling_owlv2.Owlv2ObjectDetectionOutput or tuple(torch.FloatTensor)
A transformers.models.owlv2.modeling_owlv2.Owlv2ObjectDetectionOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.owlv2.configuration_owlv2.Owlv2Config'>) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsare provided)) — Total loss as a linear combination of a negative log-likehood (cross-entropy) for class prediction and a bounding box loss. The latter is defined as a linear combination of the L1 loss and the generalized scale-invariant IoU loss. - loss_dict (
Dict, optional) — A dictionary containing the individual losses. Useful for logging. - logits (
torch.FloatTensorof shape(batch_size, num_patches, num_queries)) — Classification logits (including no-object) for all queries. - objectness_logits (
torch.FloatTensorof shape(batch_size, num_patches, 1)) — The objectness logits of all image patches. OWL-ViT represents images as a set of image patches where the total number of patches is (image_size / patch_size)**2. - pred_boxes (
torch.FloatTensorof shape(batch_size, num_patches, 4)) — Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These values are normalized in [0, 1], relative to the size of each individual image in the batch (disregarding possible padding). You can use post_process_object_detection() to retrieve the unnormalized bounding boxes. - text_embeds (
torch.FloatTensorof shape(batch_size, num_max_text_queries, output_dim) — The text embeddings obtained by applying the projection layer to the pooled output of Owlv2TextModel. - image_embeds (
torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — Pooled output of Owlv2VisionModel. OWLv2 represents images as a set of image patches and computes image embeddings for each patch. - class_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size)) — Class embeddings of all image patches. OWLv2 represents images as a set of image patches where the total number of patches is (image_size / patch_size)**2. - text_model_output (Tuple
BaseModelOutputWithPooling) — The output of the Owlv2TextModel. - vision_model_output (
BaseModelOutputWithPooling) — The output of the Owlv2VisionModel.
The Owlv2ForObjectDetection forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> import requests
>>> from PIL import Image
>>> import numpy as np
>>> import torch
>>> from transformers import AutoProcessor, Owlv2ForObjectDetection
>>> from transformers.utils.constants import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # Note: boxes need to be visualized on the padded, unnormalized image
>>> # hence we'll set the target image sizes (height, width) based on that
>>> def get_preprocessed_image(pixel_values):
... pixel_values = pixel_values.squeeze().numpy()
... unnormalized_image = (pixel_values * np.array(OPENAI_CLIP_STD)[:, None, None]) + np.array(OPENAI_CLIP_MEAN)[:, None, None]
... unnormalized_image = (unnormalized_image * 255).astype(np.uint8)
... unnormalized_image = np.moveaxis(unnormalized_image, 0, -1)
... unnormalized_image = Image.fromarray(unnormalized_image)
... return unnormalized_image
>>> unnormalized_image = get_preprocessed_image(inputs.pixel_values)
>>> target_sizes = torch.Tensor([unnormalized_image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to final bounding boxes and scores
>>> results = processor.post_process_object_detection(
... outputs=outputs, threshold=0.2, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.614 at location [512.5, 35.08, 963.48, 557.02]
Detected a photo of a cat with confidence 0.665 at location [10.13, 77.94, 489.93, 709.69]image_guided_detection
< source >( pixel_values: FloatTensor query_pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.models.owlv2.modeling_owlv2.Owlv2ImageGuidedObjectDetectionOutput or tuple(torch.FloatTensor)
Parameters
- pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. - query_pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values of query image(s) to be detected. Pass in one query image per target image. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.owlv2.modeling_owlv2.Owlv2ImageGuidedObjectDetectionOutput or tuple(torch.FloatTensor)
A transformers.models.owlv2.modeling_owlv2.Owlv2ImageGuidedObjectDetectionOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (<class 'transformers.models.owlv2.configuration_owlv2.Owlv2Config'>) and inputs.
- logits (
torch.FloatTensorof shape(batch_size, num_patches, num_queries)) — Classification logits (including no-object) for all queries. - target_pred_boxes (
torch.FloatTensorof shape(batch_size, num_patches, 4)) — Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These values are normalized in [0, 1], relative to the size of each individual target image in the batch (disregarding possible padding). You can use post_process_object_detection() to retrieve the unnormalized bounding boxes. - query_pred_boxes (
torch.FloatTensorof shape(batch_size, num_patches, 4)) — Normalized boxes coordinates for all queries, represented as (center_x, center_y, width, height). These values are normalized in [0, 1], relative to the size of each individual query image in the batch (disregarding possible padding). You can use post_process_object_detection() to retrieve the unnormalized bounding boxes. - image_embeds (
torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — Pooled output of Owlv2VisionModel. OWLv2 represents images as a set of image patches and computes image embeddings for each patch. - query_image_embeds (
torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — Pooled output of Owlv2VisionModel. OWLv2 represents images as a set of image patches and computes image embeddings for each patch. - class_embeds (
torch.FloatTensorof shape(batch_size, num_patches, hidden_size)) — Class embeddings of all image patches. OWLv2 represents images as a set of image patches where the total number of patches is (image_size / patch_size)**2. - text_model_output (Tuple
BaseModelOutputWithPooling) — The output of the Owlv2TextModel. - vision_model_output (
BaseModelOutputWithPooling) — The output of the Owlv2VisionModel.
The Owlv2ForObjectDetection forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> import requests
>>> from PIL import Image
>>> import torch
>>> import numpy as np
>>> from transformers import AutoProcessor, Owlv2ForObjectDetection
>>> from transformers.utils.constants import OPENAI_CLIP_MEAN, OPENAI_CLIP_STD
>>> processor = AutoProcessor.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000001675.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
>>> inputs = processor(images=image, query_images=query_image, return_tensors="pt")
>>> # forward pass
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
>>> # Note: boxes need to be visualized on the padded, unnormalized image
>>> # hence we'll set the target image sizes (height, width) based on that
>>> def get_preprocessed_image(pixel_values):
... pixel_values = pixel_values.squeeze().numpy()
... unnormalized_image = (pixel_values * np.array(OPENAI_CLIP_STD)[:, None, None]) + np.array(OPENAI_CLIP_MEAN)[:, None, None]
... unnormalized_image = (unnormalized_image * 255).astype(np.uint8)
... unnormalized_image = np.moveaxis(unnormalized_image, 0, -1)
... unnormalized_image = Image.fromarray(unnormalized_image)
... return unnormalized_image
>>> unnormalized_image = get_preprocessed_image(inputs.pixel_values)
>>> target_sizes = torch.Tensor([unnormalized_image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_image_guided_detection(
... outputs=outputs, threshold=0.9, nms_threshold=0.3, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image
>>> boxes, scores = results[i]["boxes"], results[i]["scores"]
>>> for box, score in zip(boxes, scores):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected similar object with confidence {round(score.item(), 3)} at location {box}")
Detected similar object with confidence 0.938 at location [490.96, 109.89, 821.09, 536.11]
Detected similar object with confidence 0.959 at location [8.67, 721.29, 928.68, 732.78]
Detected similar object with confidence 0.902 at location [4.27, 720.02, 941.45, 761.59]
Detected similar object with confidence 0.985 at location [265.46, -58.9, 1009.04, 365.66]
Detected similar object with confidence 1.0 at location [9.79, 28.69, 937.31, 941.64]
Detected similar object with confidence 0.998 at location [869.97, 58.28, 923.23, 978.1]
Detected similar object with confidence 0.985 at location [309.23, 21.07, 371.61, 932.02]
Detected similar object with confidence 0.947 at location [27.93, 859.45, 969.75, 915.44]
Detected similar object with confidence 0.996 at location [785.82, 41.38, 880.26, 966.37]
Detected similar object with confidence 0.998 at location [5.08, 721.17, 925.93, 998.41]
Detected similar object with confidence 0.969 at location [6.7, 898.1, 921.75, 949.51]
Detected similar object with confidence 0.966 at location [47.16, 927.29, 981.99, 942.14]
Detected similar object with confidence 0.924 at location [46.4, 936.13, 953.02, 950.78]