Transformers documentation
How 🤗 Transformers solve tasks
How 🤗 Transformers solve tasks
🤗 Transformersでできることで、自然言語処理(NLP)、音声とオーディオ、コンピュータビジョンのタスク、それらの重要なアプリケーションについて学びました。このページでは、モデルがこれらのタスクをどのように解決するかを詳しく見て、モデルの内部で何が起こっているかを説明します。特定のタスクを解決するためには多くの方法があり、一部のモデルは特定のテクニックを実装するか、または新しい観点からタスクに取り組むかもしれませんが、Transformerモデルにとって、一般的なアイデアは同じです。柔軟なアーキテクチャのおかげで、ほとんどのモデルはエンコーダ、デコーダ、またはエンコーダ-デコーダ構造の変種です。Transformerモデル以外にも、当社のライブラリにはコンピュータビジョンタスクに今でも使用されているいくつかの畳み込みニューラルネットワーク(CNN)もあります。また、現代のCNNがどのように機能するかも説明します。
タスクがどのように解決されるかを説明するために、モデル内部で有用な予測を出力するために何が起こるかについて説明します。
- Wav2Vec2:オーディオ分類および自動音声認識(ASR)向け
- Vision Transformer(ViT)およびConvNeXT:画像分類向け
- DETR:オブジェクト検出向け
- Mask2Former:画像セグメンテーション向け
- GLPN:深度推定向け
- BERT:エンコーダを使用するテキスト分類、トークン分類、および質問応答などのNLPタスク向け
- GPT2:デコーダを使用するテキスト生成などのNLPタスク向け
- BART:エンコーダ-デコーダを使用する要約および翻訳などのNLPタスク向け
さらに進む前に、元のTransformerアーキテクチャの基本的な知識を持つと良いです。エンコーダ、デコーダ、および注意力がどのように動作するかを知っておくと、異なるTransformerモデルがどのように動作するかを理解するのに役立ちます。始めているか、リフレッシュが必要な場合は、詳細な情報については当社のコースをチェックしてください!
Speech and audio
Wav2Vec2は、未ラベルの音声データで事前トレーニングされ、オーディオ分類および自動音声認識のラベル付きデータでファインチューンされた自己教師モデルです。
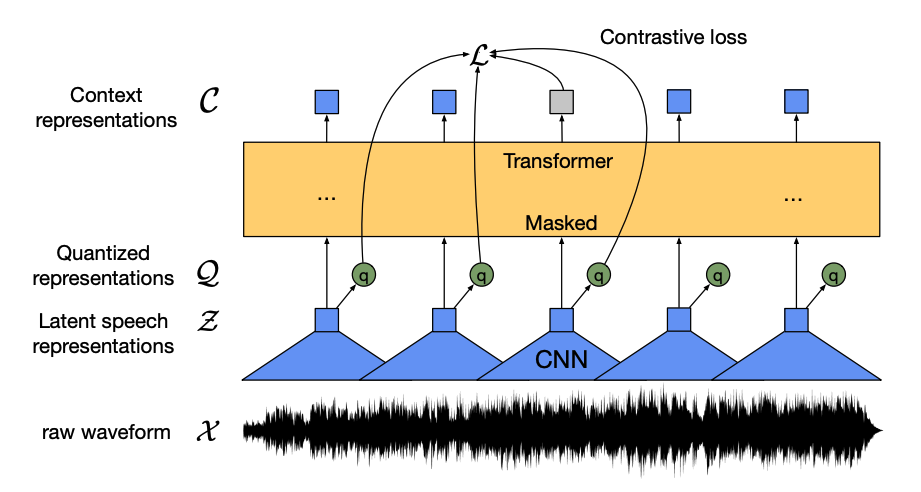
このモデルには主に次の4つのコンポーネントがあります。
特徴エンコーダ:生の音声波形を受け取り、平均値をゼロに正規化し、単位分散に変換し、それを20msごとの特徴ベクトルのシーケンスに変換します。
波形は自然に連続しているため、テキストのシーケンスを単語に分割できるようにできるように、特徴ベクトルは量子化モジュールに渡され、離散音声ユニットを学習しようとします。音声ユニットはコードブック(語彙と考えることができます)として知られるコードワードのコレクションから選択されます。コードブックから、連続したオーディオ入力を最もよく表すベクトルまたは音声ユニット(ターゲットラベルと考えることができます)が選択され、モデルを介して転送されます。
特徴ベクトルの約半分はランダムにマスクされ、マスクされた特徴ベクトルはコンテキストネットワークに供給されます。これは、相対的な位置エンベッディングも追加するTransformerエンコーダです。
コンテキストネットワークの事前トレーニングの目的はコントラスティブタスクです。モデルはマスクされた予測の真の量子化音声表現を、偽の予測のセットから予測しなければならず、モデルは最も似たコンテキストベクトルと量子化音声ユニット(ターゲットラベル)を見つけるように促されます。
今、Wav2Vec2は事前トレーニングされているので、オーディオ分類または自動音声認識のためにデータをファインチューンできます!
Audio classification
事前トレーニングされたモデルをオーディオ分類に使用するには、基本的なWav2Vec2モデルの上にシーケンス分類ヘッドを追加します。分類ヘッドはエンコーダの隠れた状態を受け入れる線形層で、各オーディオフレームから学習された特徴を表します。これらの隠れた状態は長さが異なる可能性があるため、最初に隠れた状態がプールされ、次にクラスラベルに対するロジットに変換されます。ロジットとターゲット間のクロスエントロピー損失が計算され、最も可能性の高いクラスを見つけるために使用されます。
オーディオ分類を試す準備はできましたか?Wav2Vec2をファインチューンして推論に使用する方法を学ぶための完全なオーディオ分類ガイドをチェックしてください!
Automatic speech recognition
事前トレーニングされたモデルを自動音声認識に使用するには、connectionist temporal classification(CTC)のための基本的なWav2Vec2モデルの上に言語モデリングヘッドを追加します。言語モデリングヘッドはエンコーダの隠れた状態を受け入れ、それらをロジットに変換します。各ロジットはトークンクラスを表し(トークン数はタスクの語彙から来ます)、ロジットとターゲット間のCTC損失が計算され、次に転写に変換されます。
自動音声認識を試す準備はできましたか?Wav2Vec2をファインチューンして推論に使用する方法を学ぶための完全な自動音声認識ガイドをチェックしてください!
Computer vision
コンピュータビジョンのタスクをアプローチする方法は2つあります。
- 画像をパッチのシーケンスに分割し、Transformerを使用して並列に処理します。
- ConvNeXTなどのモダンなCNNを使用します。これらは畳み込み層を使用しますが、モダンなネットワーク設計を採用しています。
サードアプローチでは、Transformerと畳み込みを組み合わせたものもあります(例:Convolutional Vision TransformerまたはLeViT)。これらについては議論しませんが、これらはここで調べる2つのアプローチを組み合わせています。
ViTとConvNeXTは画像分類によく使用されますが、オブジェクト検出、セグメンテーション、深度推定などの他のビジョンタスクに対しては、DETR、Mask2Former、GLPNなどが適しています。
Image classification
ViTとConvNeXTの両方を画像分類に使用できます。主な違いは、ViTが注意メカニズムを使用し、ConvNeXTが畳み込みを使用することです。
Transformer
ViTは畳み込みを完全にTransformerアーキテクチャで置き換えます。元のTransformerに精通している場合、ViTの理解は既にほとんど完了しています。

ViTが導入した主な変更点は、画像をTransformerに供給する方法です。
画像は正方形で重ならないパッチのシーケンスに分割され、各パッチはベクトルまたはパッチ埋め込みに変換されます。パッチ埋め込みは、適切な入力次元を作成するために2D畳み込み層から生成されます(基本のTransformerの場合、各パッチ埋め込みに768の値があります)。224x224ピクセルの画像がある場合、それを16x16の画像パッチに分割できます。テキストが単語にトークン化されるように、画像はパッチのシーケンスに「トークン化」されます。
学習埋め込み、つまり特別な
[CLS]トークンが、BERTのようにパッチ埋め込みの先頭に追加されます。[CLS]トークンの最終的な隠れた状態は、付属の分類ヘッドの入力として使用されます。他の出力は無視されます。このトークンは、モデルが画像の表現をエンコードする方法を学ぶのに役立ちます。パッチと学習埋め込みに追加する最後の要素は位置埋め込みです。モデルは画像パッチがどのように並べられているかを知りませんので、位置埋め込みも学習可能で、パッチ埋め込みと同じサイズを持ちます。最後に、すべての埋め込みがTransformerエンコーダに渡されます。
出力、具体的には
[CLS]トークンの出力だけが、多層パーセプトロンヘッド(MLP)に渡されます。ViTの事前トレーニングの目的は単純に分類です。他の分類ヘッドと同様に、MLPヘッドは出力をクラスラベルに対するロジットに変換し、クロスエントロピー損失を計算して最も可能性の高いクラスを見つけます。
画像分類を試す準備はできましたか?ViTをファインチューンして推論に使用する方法を学ぶための完全な画像分類ガイドをチェックしてください!
CNN
このセクションでは畳み込みについて簡単に説明していますが、画像の形状とサイズがどのように変化するかを事前に理解していると役立ちます。畳み込みに慣れていない場合は、fastaiの書籍からConvolution Neural Networks chapterをチェックしてみてください!
ConvNeXTは、性能を向上させるために新しいモダンなネットワーク設計を採用したCNNアーキテクチャです。ただし、畳み込みはモデルの中核にまだあります。高レベルから見た場合、畳み込み(convolution)は、小さな行列(カーネル)が画像のピクセルの小さなウィンドウに乗算される操作です。それは特定のテクスチャや線の曲率などの特徴を計算します。その後、次のピクセルのウィンドウに移動します。畳み込みが移動する距離はストライドとして知られています。

この出力を別の畳み込み層に供給し、各連続した層ごとに、ネットワークはホットドッグやロケットのようなより複雑で抽象的なものを学習します。畳み込み層の間には、特徴の次元を削減し、特徴の位置の変動に対してモデルをより堅牢にするためにプーリング層を追加するのが一般的です。

ConvNeXTは、以下の5つの方法でCNNをモダン化しています。
各ステージのブロック数を変更し、画像をより大きなストライドと対応するカーネルサイズでパッチ化します。重ならないスライディングウィンドウは、これにより画像をパッチに分割するViTの戦略と似ています。
ボトルネック レイヤーはチャネル数を縮小し、それを復元します。1x1の畳み込みを実行するのは速く、深さを増やすことができます。逆ボトルネックは逆のことを行い、チャネル数を拡張し、それを縮小します。これはメモリ効率が高いです。
ボトルネックレイヤー内の通常の3x3の畳み込み層を、深度方向の畳み込みで置き換えます。これは各入力チャネルに個別に畳み込みを適用し、最後にそれらを積み重ねる畳み込みです。これにより、性能向上のためにネットワーク幅が広がります。
ViTはグローバル受容野を持っているため、その注意メカニズムのおかげで一度に画像の多くを見ることができます。ConvNeXTはこの効果を再現しようとし、カーネルサイズを7x7に増やします。
ConvNeXTはまた、Transformerモデルを模倣するいくつかのレイヤーデザイン変更を行っています。アクティベーションと正規化レイヤーが少なく、活性化関数はReLUの代わりにGELUに切り替え、BatchNormの代わりにLayerNormを使用しています。
畳み込みブロックからの出力は、分類ヘッドに渡され、出力をロジットに変換し、最も可能性の高いラベルを見つけるためにクロスエントロピー損失が計算されます。
Object detection
DETR、DEtection TRansformer、はCNNとTransformerエンコーダーデコーダーを組み合わせたエンドツーエンドのオブジェクト検出モデルです。
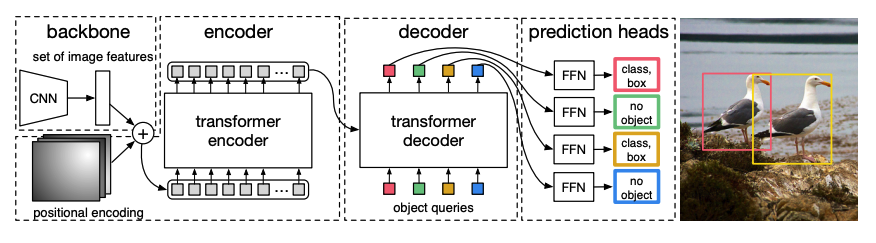
事前トレーニングされたCNN バックボーン は、ピクセル値で表される画像を受け取り、それの低解像度の特徴マップを作成します。特徴マップには次元削減のために1x1の畳み込みが適用され、高レベルの画像表現を持つ新しい特徴マップが作成されます。Transformerは連続モデルであるため、特徴マップは特徴ベクトルのシーケンスに平坦化され、位置エンベディングと組み合わせられます。
特徴ベクトルはエンコーダーに渡され、その注意レイヤーを使用して画像表現を学習します。次に、エンコーダーの隠れ状態はデコーダーのオブジェクトクエリと組み合わされます。オブジェクトクエリは、画像の異なる領域に焦点を当てる学習埋め込みで、各注意レイヤーを進行するにつれて更新されます。デコーダーの隠れ状態は、各オブジェクトクエリに対してバウンディングボックスの座標とクラスラベルを予測するフィードフォワードネットワークに渡されます。または、存在しない場合は
no objectが渡されます。DETRは各オブジェクトクエリを並行してデコードして、Nの最終的な予測(Nはクエリの数)を出力します。典型的な自己回帰モデルが1つの要素を1回ずつ予測するのとは異なり、オブジェクト検出はセット予測タスク(
バウンディングボックス、クラスラベル)であり、1回のパスでNの予測を行います。訓練中、DETRは二部マッチング損失を使用して、固定された数の予測と固定された一連の正解ラベルを比較します。 Nのラベルセットに正解ラベルが少ない場合、
no objectクラスでパディングされます。この損失関数は、DETRに予測と正解ラベルとの間で1対1の割り当てを見つけるように促します。バウンディングボックスまたはクラスラベルのどちらかが正しくない場合、損失が発生します。同様に、DETRが存在しないオブジェクトを予測した場合、罰金が科せられます。これにより、DETRは1つの非常に顕著なオブジェクトに焦点を当てるのではなく、画像内の他のオブジェクトを見つけるように促されます。
DETRの上にオブジェクト検出ヘッドを追加して、クラスラベルとバウンディングボックスの座標を見つけます。オブジェクト検出ヘッドには2つのコンポーネントがあります:デコーダーの隠れ状態をクラスラベルのロジットに変換するための線形層、およびバウンディングボックスを予測するためのMLPです。
オブジェクト検出を試す準備はできましたか?DETROの完全なオブジェクト検出ガイドをチェックして、DETROのファインチューニング方法と推論方法を学んでください!
Image segmentation
Mask2Formerは、すべての種類の画像セグメンテーションタスクを解決するためのユニバーサルアーキテクチャです。従来のセグメンテーションモデルは通常、インスタンス、セマンティック、またはパノプティックセグメンテーションの特定のサブタスクに合わせて設計されています。Mask2Formerは、それらのタスクのそれぞれをマスク分類の問題として捉えます。マスク分類はピクセルをNのセグメントにグループ化し、与えられた画像に対してNのマスクとそれに対応するクラスラベルを予測します。このセクションでは、Mask2Formerの動作方法を説明し、最後にSegFormerのファインチューニングを試すことができます。

Mask2Formerの主要なコンポーネントは次の3つです。
Swinバックボーンは画像を受け入れ、3つの連続する3x3の畳み込みから低解像度の画像特徴マップを作成します。
特徴マップはピクセルデコーダーに渡され、低解像度の特徴を高解像度のピクセル埋め込みに徐々にアップサンプリングします。ピクセルデコーダーは実際には解像度1/32、1/16、および1/8のオリジナル画像のマルチスケール特徴(低解像度と高解像度の特徴を含む)を生成します。
これらの異なるスケールの特徴マップのそれぞれは、高解像度の特徴から小さいオブジェクトをキャプチャするために1回ずつトランスフォーマーデコーダーレイヤーに渡されます。Mask2Formerの要点は、デコーダーのマスクアテンションメカニズムです。クロスアテンションが画像全体に注意を向けることができるのに対し、マスクアテンションは画像の特定の領域にのみ焦点を当てます。これは速く、ローカルな画像特徴だけでもモデルが学習できるため、パフォーマンスが向上します。
DETRと同様に、Mask2Formerも学習されたオブジェクトクエリを使用し、画像の特徴と組み合わせてセットの予測(
クラスラベル、マスク予測)を行います。デコーダーの隠れ状態は線形層に渡され、クラスラベルに対するロジットに変換されます。ロジットと正解ラベル間のクロスエントロピー損失が最も可能性の高いものを見つけます。マスク予測は、ピクセル埋め込みと最終的なデコーダーの隠れ状態を組み合わせて生成されます。シグモイドクロスエントロピーやダイス損失がロジットと正解マスクの間で最も可能性の高いマスクを見つけます。
セグメンテーションタスクに取り組む準備ができましたか?SegFormerのファインチューニング方法と推論方法を学ぶために、完全な画像セグメンテーションガイドをチェックしてみてください!
Depth estimation
GLPN、Global-Local Path Network、はセグメンテーションまたは深度推定などの密な予測タスクに適しています。SegFormerエンコーダーを軽量デコーダーと組み合わせたTransformerベースの深度推定モデルです。

ViTのように、画像はパッチのシーケンスに分割されますが、これらの画像パッチは小さいです。これはセグメンテーションや深度推定などの密な予測タスクに適しています。画像パッチはパッチ埋め込みに変換されます(パッチ埋め込みの作成方法の詳細については、画像分類セクションを参照してください)。これらのパッチ埋め込みはエンコーダーに渡されます。
エンコーダーはパッチ埋め込みを受け入れ、複数のエンコーダーブロックを通じてそれらを渡します。各ブロックにはアテンションとMix-FFNレイヤーが含まれています。後者の役割は位置情報を提供することです。各エンコーダーブロックの最後には、階層的表現を作成するためのパッチマージングレイヤーがあります。隣接するパッチのグループごとの特徴が連結され、連結された特徴に対して線形層が適用され、パッチの数を1/4の解像度に削減します。これが次のエンコーダーブロックへの入力となり、ここではこのプロセス全体が繰り返され、元の画像の1/8、1/16、および1/32の解像度の画像特徴が得られます。
軽量デコーダーは、エンコーダーからの最後の特徴マップ(1/32スケール)を受け取り、それを1/16スケールにアップサンプリングします。その後、特徴は各特徴に対するアテンションマップからローカルとグローバルな特徴を選択して組み合わせるセレクティブフィーチャーフュージョン(SFF)モジュールに渡され、1/8にアップサンプリングされます。このプロセスはデコードされた特徴が元の画像と同じサイズになるまで繰り返されます。
デコードされた特徴は、最終的な予測を行うためにセマンティックセグメンテーション、深度推定、またはその他の密な予測タスクに供給されます。セマンティックセグメンテーションの場合、特徴はクラス数に対するロジットに変換され、クロスエントロピー損失を使用して最適化されます。深度推定の場合、特徴は深度マップに変換され、平均絶対誤差(MAE)または平均二乗誤差(MSE)損失が使用されます。
Natural language processing
Transformerは最初に機械翻訳のために設計され、それ以降、ほとんどのNLPタスクを解決するためのデフォルトのアーキテクチャとなっています。一部のタスクはTransformerのエンコーダー構造に適しており、他のタスクはデコーダーに適しています。さらに、一部のタスクではTransformerのエンコーダー-デコーダー構造を使用します。
Text classification
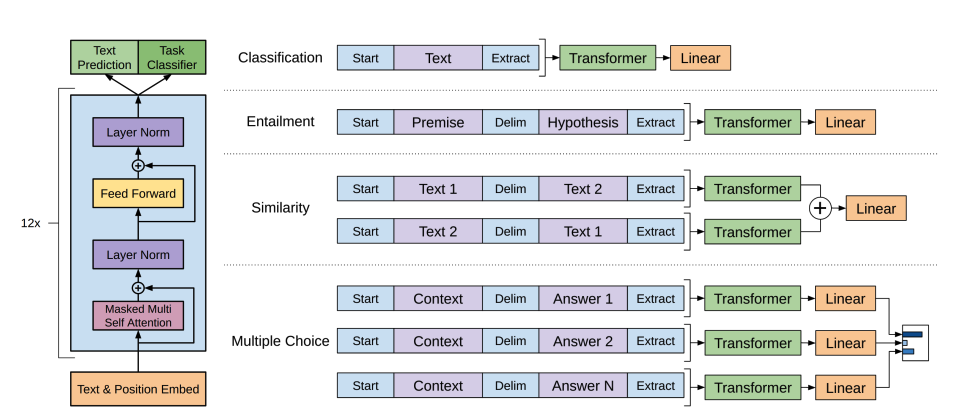
BERTはエンコーダーのみのモデルであり、テキストの豊かな表現を学習するために両側の単語に注意を払うことで、深い双方向性を効果的に実装した最初のモデルです。
BERTはWordPieceトークナイゼーションを使用してテキストのトークン埋め込みを生成します。単一の文と文のペアを区別するために、特別な
[SEP]トークンが追加されます。[CLS]トークンはすべてのテキストシーケンスの先頭に追加されます。[CLS]トークンとともに最終出力は、分類タスクのための入力として使用されます。BERTはまた、トークンが文のペアの最初または2番目の文に属するかどうかを示すセグメント埋め込みを追加します。BERTは、事前トレーニングで2つの目標を使用します:マスクされた言語モデリングと次の文の予測です。マスクされた言語モデリングでは、入力トークンの一部がランダムにマスクされ、モデルはこれらを予測する必要があります。これにより、モデルが全ての単語を見て「次の単語」を予測することができる双方向性の問題が解決されます。予測されたマスクトークンの最終的な隠れた状態は、ソフトマックスを使用した単語のマスクを予測するためのフィードフォワードネットワークに渡されます。
2番目の事前トレーニングオブジェクトは次の文の予測です。モデルは文Aの後に文Bが続くかどうかを予測する必要があります。半分の場合、文Bは次の文であり、残りの半分の場合、文Bはランダムな文です。予測(次の文かどうか)は、2つのクラス(
IsNextおよびNotNext)に対するソフトマックスを持つフィードフォワードネットワークに渡されます。入力埋め込みは、最終的な隠れた状態を出力するために複数のエンコーダーレイヤーを介して渡されます。
事前訓練済みモデルをテキスト分類に使用するには、ベースのBERTモデルの上にシーケンス分類ヘッドを追加します。シーケンス分類ヘッドは最終的な隠れた状態を受け入れ、それらをロジットに変換するための線形層です。クロスエントロピー損失は、ロジットとターゲット間で最も可能性の高いラベルを見つけるために計算されます。
テキスト分類を試してみる準備はできましたか?DistilBERTを微調整し、推論に使用する方法を学ぶために、完全なテキスト分類ガイドをチェックしてみてください!
Token classification
BERTを名前エンティティ認識(NER)などのトークン分類タスクに使用するには、ベースのBERTモデルの上にトークン分類ヘッドを追加します。トークン分類ヘッドは最終的な隠れた状態を受け入れ、それらをロジットに変換するための線形層です。クロスエントロピー損失は、ロジットと各トークン間で最も可能性の高いラベルを見つけるために計算されます。
トークン分類を試してみる準備はできましたか?DistilBERTを微調整し、推論に使用する方法を学ぶために、完全なトークン分類ガイドをチェックしてみてください!
Question answering
BERTを質問応答に使用するには、ベースのBERTモデルの上にスパン分類ヘッドを追加します。この線形層は最終的な隠れた状態を受け入れ、回答に対応するテキストの「スパン」開始と終了のロジットを計算します。クロスエントロピー損失は、ロジットとラベル位置との間で最も可能性の高いテキストスパンを見つけるために計算されます。
質問応答を試してみる準備はできましたか?DistilBERTを微調整し、推論に使用する方法を学ぶために、完全な質問応答ガイドをチェックしてみてください!
💡 注意してください。一度事前トレーニングが完了したBERTを使用してさまざまなタスクに簡単に適用できることに注目してください。必要なのは、事前トレーニング済みモデルに特定のヘッドを追加して、隠れた状態を所望の出力に変換することだけです!
Text generation
GPT-2は大量のテキストで事前トレーニングされたデコーダー専用モデルです。プロンプトを与えると説得力のあるテキストを生成し、明示的にトレーニングされていないにもかかわらず、質問応答などの他のNLPタスクも完了できます。
GPT-2はバイトペアエンコーディング(BPE)を使用して単語をトークナイズし、トークン埋め込みを生成します。位置エンコーディングがトークン埋め込みに追加され、各トークンの位置を示します。入力埋め込みは複数のデコーダーブロックを介して最終的な隠れた状態を出力するために渡されます。各デコーダーブロック内で、GPT-2は「マスクされた自己注意」レイヤーを使用します。これは、GPT-2が未来のトークンに注意を払うことはできないことを意味します。GPT-2は左側のトークンにのみ注意を払うことが許可されています。これはBERTの
maskトークンとは異なり、マスクされた自己注意では未来のトークンに対してスコアを0に設定するための注意マスクが使用されます。デコーダーからの出力は、言語モデリングヘッドに渡され、最終的な隠れた状態をロジットに変換するための線形変換を実行します。ラベルはシーケンス内の次のトークンであり、これはロジットを右に1つずらして生成されます。クロスエントロピー損失は、シフトされたロジットとラベル間で計算され、次に最も可能性の高いトークンを出力します。
GPT-2の事前トレーニングの目標は完全に因果言語モデリングに基づいており、シーケンス内の次の単語を予測します。これにより、GPT-2はテキスト生成を含むタスクで特に優れた性能を発揮します。
テキスト生成を試してみる準備はできましたか?DistilGPT-2を微調整し、推論に使用する方法を学ぶために、完全な因果言語モデリングガイドをチェックしてみてください!
テキスト生成に関する詳細は、テキスト生成戦略ガイドをチェックしてみてください!
Summarization
BART や T5 のようなエンコーダーデコーダーモデルは、要約タスクのシーケンス・トゥ・シーケンス・パターンに設計されています。このセクションでは、BARTの動作方法を説明し、最後にT5の微調整を試すことができます。
BARTのエンコーダーアーキテクチャは、BERTと非常に似ており、テキストのトークンと位置エンベディングを受け入れます。BARTは、入力を破壊してからデコーダーで再構築することによって事前トレーニングされます。特定の破壊戦略を持つ他のエンコーダーとは異なり、BARTは任意の種類の破壊を適用できます。ただし、テキストインフィリング破壊戦略が最適です。テキストインフィリングでは、いくつかのテキストスパンが単一の
maskトークンで置き換えられます。これは重要です、なぜならモデルはマスクされたトークンを予測しなければならず、モデルに欠落トークンの数を予測させるからです。入力埋め込みとマスクされたスパンはエンコーダーを介して最終的な隠れた状態を出力しますが、BERTとは異なり、BARTは単語を予測するための最終的なフィードフォワードネットワークを最後に追加しません。エンコーダーの出力はデコーダーに渡され、デコーダーはエンコーダーの出力からマスクされたトークンと非破壊トークンを予測する必要があります。これにより、デコーダーは元のテキストを復元するのに役立つ追加のコンテキストが提供されます。デコーダーからの出力は言語モデリングヘッドに渡され、隠れた状態をロジットに変換するための線形変換を実行します。クロスエントロピー損失は、ロジットとラベルの間で計算され、ラベルは単に右にシフトされたトークンです。
要約を試す準備はできましたか?T5を微調整して推論に使用する方法を学ぶために、完全な要約ガイドをご覧ください!
テキスト生成に関する詳細は、テキスト生成戦略ガイドをチェックしてみてください!
Translation
翻訳は、もう一つのシーケンス・トゥ・シーケンス・タスクの例であり、BART や T5 のようなエンコーダーデコーダーモデルを使用して実行できます。このセクションでは、BARTの動作方法を説明し、最後にT5の微調整を試すことができます。
BARTは、ソース言語をターゲット言語にデコードできるようにするために、別個にランダムに初期化されたエンコーダーを追加することで翻訳に適応します。この新しいエンコーダーの埋め込みは、元の単語埋め込みの代わりに事前トレーニング済みのエンコーダーに渡されます。ソースエンコーダーは、モデルの出力からのクロスエントロピー損失を用いてソースエンコーダー、位置エンベディング、および入力エンベディングを更新することによって訓練されます。この最初のステップではモデルパラメータが固定され、すべてのモデルパラメータが2番目のステップで一緒に訓練されます。
その後、翻訳のために多言語版のmBARTが登場し、多言語で事前トレーニングされたモデルとして利用可能です。
翻訳を試す準備はできましたか?T5を微調整して推論に使用する方法を学ぶために、完全な翻訳ガイドをご覧ください!
テキスト生成に関する詳細は、テキスト生成戦略ガイドをチェックしてみてください!