Transformers documentation
Phi
Phi
Overview
The Phi-1 model was proposed in Textbooks Are All You Need by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in Textbooks Are All You Need II: phi-1.5 technical report by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
Summary
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size. They selected high quality “textbook” data alongside with synthetically generated data for training their small sized Transformer based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability to “think step by step” or perform some rudimentary in-context learning. With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
The abstract from the Phi-1 paper is the following:
We introduce phi-1, a new large language model for code, with significantly smaller size than competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on 8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as phi-1 that still achieves 45% on HumanEval.
The abstract from the Phi-1.5 paper is the following:
We continue the investigation into the power of smaller Transformer-based language models as initiated by TinyStories – a 10 million parameter model that can produce coherent English – and the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to generate “textbook quality” data as a way to enhance the learning process compared to traditional web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5, with performance on natural language tasks comparable to models 5x larger, and surpassing most non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such as the ability to “think step by step” or perform some rudimentary in-context learning– and bad, including hallucinations and the potential for toxic and biased generations –encouragingly though, we are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to promote further research on these urgent topics.
This model was contributed by Susnato Dhar.
The original code for Phi-1, Phi-1.5 and Phi-2 can be found here, here and here, respectively.
Usage tips
- This model is quite similar to
Llamawith the main difference inPhiDecoderLayer, where they usedPhiAttentionandPhiMLPlayers in parallel configuration. - The tokenizer used for this model is identical to the CodeGenTokenizer.
How to use Phi-2
Phi-2 has been integrated in the development version (4.37.0.dev) of transformers. Until the official version is released through pip, ensure that you are doing one of the following:
When loading the model, ensure that
trust_remote_code=Trueis passed as an argument of thefrom_pretrained()function.Update your local
transformersto the development version:pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers. The previous command is an alternative to cloning and installing from the source.
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
>>> inputs = tokenizer('Can you help me write a formal email to a potential business partner proposing a joint venture?', return_tensors="pt", return_attention_mask=False)
>>> outputs = model.generate(**inputs, max_length=30)
>>> text = tokenizer.batch_decode(outputs)[0]
>>> print(text)
'Can you help me write a formal email to a potential business partner proposing a joint venture?\nInput: Company A: ABC Inc.\nCompany B: XYZ Ltd.\nJoint Venture: A new online platform for e-commerce'Example :
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
pip install -U flash-attn --no-build-isolation
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16“)
To load and run a model using Flash Attention 2, refer to the snippet below:
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'Expected speedups
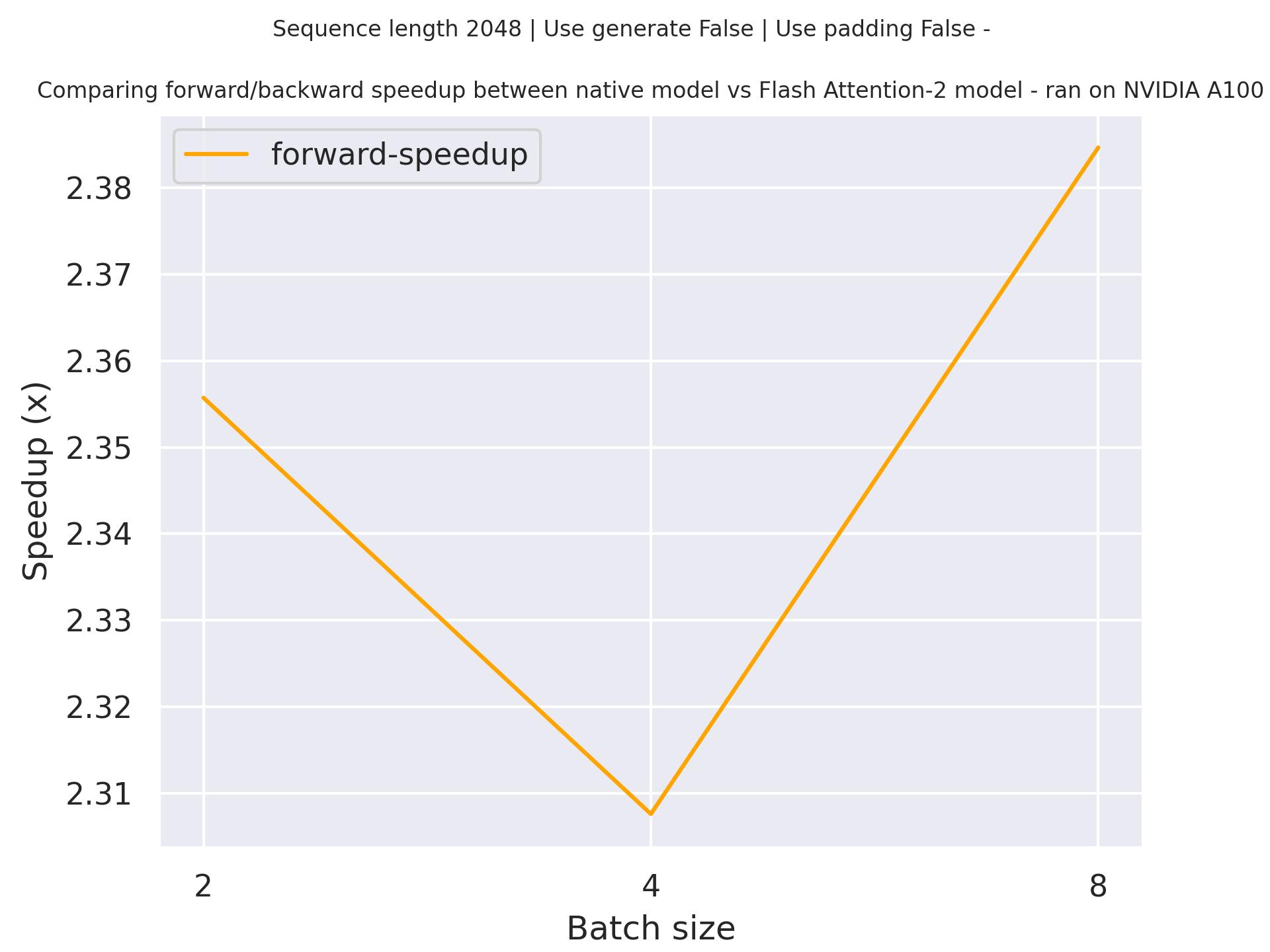
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using microsoft/phi-1 checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
PhiConfig
class transformers.PhiConfig
< source >( vocab_size = 51200 hidden_size = 2048 intermediate_size = 8192 num_hidden_layers = 24 num_attention_heads = 32 num_key_value_heads = None resid_pdrop = 0.0 embd_pdrop = 0.0 attention_dropout = 0.0 hidden_act = 'gelu_new' max_position_embeddings = 2048 initializer_range = 0.02 layer_norm_eps = 1e-05 use_cache = True tie_word_embeddings = False rope_theta = 10000.0 rope_scaling = None partial_rotary_factor = 0.5 qk_layernorm = False bos_token_id = 1 eos_token_id = 2 **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 51200) — Vocabulary size of the Phi model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling PhiModel. - hidden_size (
int, optional, defaults to 2048) — Dimension of the hidden representations. - intermediate_size (
int, optional, defaults to 8192) — Dimension of the MLP representations. - num_hidden_layers (
int, optional, defaults to 24) — Number of hidden layers in the Transformer decoder. - num_attention_heads (
int, optional, defaults to 32) — Number of attention heads for each attention layer in the Transformer decoder. - num_key_value_heads (
int, optional) — This is the number of key_value heads that should be used to implement Grouped Query Attention. Ifnum_key_value_heads=num_attention_heads, the model will use Multi Head Attention (MHA), ifnum_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed by meanpooling all the original heads within that group. For more details checkout [this paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default tonum_attention_heads`. - resid_pdrop (
float, optional, defaults to 0.0) — Dropout probability for mlp outputs. - embd_pdrop (
int, optional, defaults to 0.0) — The dropout ratio for the embeddings. - attention_dropout (
float, optional, defaults to 0.0) — The dropout ratio after computing the attention scores. - hidden_act (
strorfunction, optional, defaults to"gelu_new") — The non-linear activation function (function or string) in the decoder. - max_position_embeddings (
int, optional, defaults to 2048) — The maximum sequence length that this model might ever be used with. Phi-1 and Phi-1.5 supports up to 2048 tokens. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-05) — The epsilon used by the rms normalization layers. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). Only relevant ifconfig.is_decoder=True. Whether to tie weight embeddings or not. - tie_word_embeddings (
bool, optional, defaults toFalse) — Whether to tie weight embeddings - rope_theta (
float, optional, defaults to 10000.0) — The base period of the RoPE embeddings. - rope_scaling (
Dict, optional) — Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling strategies: linear and dynamic. Their scaling factor must be an float greater than 1. The expected format is{"type": strategy name, "factor": scaling factor}. When using this flag, don’t updatemax_position_embeddingsto the expected new maximum. See the following thread for more information on how these scaling strategies behave: https://www.reddit.com/r/LocalPersimmon/comments/14mrgpr/dynamically_scaled_rope_further_increases/. This is an experimental feature, subject to breaking API changes in future versions. - partial_rotary_factor (
float, optional, defaults to 0.5) — Percentage of the query and keys which will have rotary embedding. - qk_layernorm (
bool, optional, defaults toFalse) — Whether or not to normalize the Queries and Keys after projecting the hidden states. - bos_token_id (
int, optional, defaults to 1) — Denotes beginning of sequences token id. - eos_token_id (
int, optional, defaults to 2) — Denotes end of sequences token id.
This is the configuration class to store the configuration of a PhiModel. It is used to instantiate an Phi model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Phi microsoft/phi-1.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import PhiModel, PhiConfig
>>> # Initializing a Phi-1 style configuration
>>> configuration = PhiConfig.from_pretrained("microsoft/phi-1")
>>> # Initializing a model from the configuration
>>> model = PhiModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configPhiModel
class transformers.PhiModel
< source >( config: PhiConfig )
Parameters
- config (PhiConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights. config — PhiConfig
The bare Phi Model outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
Transformer decoder consisting of config.num_hidden_layers layers. Each layer is a PhiDecoderLayer
forward
< source >( input_ids: LongTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Two formats are allowed:
- a Cache instance;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The PhiModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
PhiForCausalLM
forward
< source >( input_ids: LongTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Two formats are allowed:
- a Cache instance;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.Args — labels (
torch.LongTensorof shape(batch_size, sequence_length), optional): Labels for computing the masked language modeling loss. Indices should either be in[0, ..., config.vocab_size]or -100 (seeinput_idsdocstring). Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size].
Returns
transformers.modeling_outputs.CausalLMOutputWithPast or tuple(torch.FloatTensor)
A transformers.modeling_outputs.CausalLMOutputWithPast or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PhiConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Language modeling loss (for next-token prediction). -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cache=Trueis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head))Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The PhiForCausalLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, PhiForCausalLM
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
>>> prompt = "This is an example script ."
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
'This is an example script .\n\n\n\nfrom typing import List\n\ndef find_most_common_letter(words: List[str'generate
< source >( inputs: Optional = None generation_config: Optional = None logits_processor: Optional = None stopping_criteria: Optional = None prefix_allowed_tokens_fn: Optional = None synced_gpus: Optional = None assistant_model: Optional = None streamer: Optional = None negative_prompt_ids: Optional = None negative_prompt_attention_mask: Optional = None **kwargs ) → ModelOutput or torch.LongTensor
Parameters
- inputs (
torch.Tensorof varying shape depending on the modality, optional) — The sequence used as a prompt for the generation or as model inputs to the encoder. IfNonethe method initializes it withbos_token_idand a batch size of 1. For decoder-only modelsinputsshould of in the format ofinput_ids. For encoder-decoder models inputs can represent any ofinput_ids,input_values,input_features, orpixel_values. - generation_config (
~generation.GenerationConfig, optional) — The generation configuration to be used as base parametrization for the generation call.**kwargspassed to generate matching the attributes ofgeneration_configwill override them. Ifgeneration_configis not provided, the default will be used, which had the following loading priority: 1) from thegeneration_config.jsonmodel file, if it exists; 2) from the model configuration. Please note that unspecified parameters will inherit GenerationConfig’s default values, whose documentation should be checked to parameterize generation. - logits_processor (
LogitsProcessorList, optional) — Custom logits processors that complement the default logits processors built from arguments and generation config. If a logit processor is passed that is already created with the arguments or a generation config an error is thrown. This feature is intended for advanced users. - stopping_criteria (
StoppingCriteriaList, optional) — Custom stopping criteria that complement the default stopping criteria built from arguments and a generation config. If a stopping criteria is passed that is already created with the arguments or a generation config an error is thrown. If your stopping criteria depends on thescoresinput, make sure you passreturn_dict_in_generate=True, output_scores=Truetogenerate. This feature is intended for advanced users. - prefix_allowed_tokens_fn (
Callable[[int, torch.Tensor], List[int]], optional) — If provided, this function constraints the beam search to allowed tokens only at each step. If not provided no constraint is applied. This function takes 2 arguments: the batch IDbatch_idandinput_ids. It has to return a list with the allowed tokens for the next generation step conditioned on the batch IDbatch_idand the previously generated tokensinputs_ids. This argument is useful for constrained generation conditioned on the prefix, as described in Autoregressive Entity Retrieval. - synced_gpus (
bool, optional) — Whether to continue running the while loop until max_length. Unless overridden this flag will be set toTrueunder DeepSpeed ZeRO Stage 3 multiple GPUs environment to avoid hanging if one GPU finished generating before other GPUs. Otherwise it’ll be set toFalse. - assistant_model (
PreTrainedModel, optional) — An assistant model that can be used to accelerate generation. The assistant model must have the exact same tokenizer. The acceleration is achieved when forecasting candidate tokens with the assistent model is much faster than running generation with the model you’re calling generate from. As such, the assistant model should be much smaller. - streamer (
BaseStreamer, optional) — Streamer object that will be used to stream the generated sequences. Generated tokens are passed throughstreamer.put(token_ids)and the streamer is responsible for any further processing. - negative_prompt_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — The negative prompt needed for some processors such as CFG. The batch size must match the input batch size. This is an experimental feature, subject to breaking API changes in future versions. - negative_prompt_attention_mask (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Attention_mask fornegative_prompt_ids. - kwargs (
Dict[str, Any], optional) — Ad hoc parametrization ofgenerate_configand/or additional model-specific kwargs that will be forwarded to theforwardfunction of the model. If the model is an encoder-decoder model, encoder specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with decoder_.
Returns
ModelOutput or torch.LongTensor
A ModelOutput (if return_dict_in_generate=True
or when config.return_dict_in_generate=True) or a torch.FloatTensor.
If the model is not an encoder-decoder model (model.config.is_encoder_decoder=False), the possible
ModelOutput types are:
If the model is an encoder-decoder model (model.config.is_encoder_decoder=True), the possible
ModelOutput types are:
Generates sequences of token ids for models with a language modeling head.
Most generation-controlling parameters are set in generation_config which, if not passed, will be set to the
model’s default generation configuration. You can override any generation_config by passing the corresponding
parameters to generate(), e.g. .generate(inputs, num_beams=4, do_sample=True).
For an overview of generation strategies and code examples, check out the following guide.
PhiForSequenceClassification
class transformers.PhiForSequenceClassification
< source >( config )
Parameters
- config (PhiConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The PhiModel with a sequence classification head on top (linear layer).
PhiForSequenceClassification uses the last token in order to do the classification, as other causal models (e.g. GPT-2) do.
Since it does classification on the last token, it requires to know the position of the last token. If a
pad_token_id is defined in the configuration, it finds the last token that is not a padding token in each row. If
no pad_token_id is defined, it simply takes the last value in each row of the batch. Since it cannot guess the
padding tokens when inputs_embeds are passed instead of input_ids, it does the same (take the last value in
each row of the batch).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: LongTensor = None attention_mask: Optional = None position_ids: Optional = None past_key_values: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Two formats are allowed:
- a Cache instance;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
The PhiForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
PhiForTokenClassification
class transformers.PhiForTokenClassification
< source >( config: PhiConfig )
Parameters
- config (PhiConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
PhiModel with a token classification head on top (a linear layer on top of the hidden-states output) e.g. for Named-Entity-Recognition (NER) tasks.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None **deprecated_arguments ) → transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
- attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details.
If
past_key_valuesis used, optionally only the lastinput_idshave to be input (seepast_key_values).If you want to change padding behavior, you should read
modeling_opt._prepare_decoder_attention_maskand modify to your needs. See diagram 1 in the paper for more information on the default strategy.- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.n_positions - 1]. - past_key_values (
Cacheortuple(tuple(torch.FloatTensor)), optional) — Pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used to speed up sequential decoding. This typically consists in thepast_key_valuesreturned by the model at a previous stage of decoding, whenuse_cache=Trueorconfig.use_cache=True.Two formats are allowed:
- a Cache instance;
- Tuple of
tuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head)). This is also known as the legacy cache format.
The model will output the same cache format that is fed as input. If no
past_key_valuesare passed, the legacy cache format will be returned.If
past_key_valuesare used, the user can optionally input only the lastinput_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.TokenClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (PhiConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.num_labels)) — Classification scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The PhiForTokenClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoTokenizer, PhiForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1")
>>> model = PhiForTokenClassification.from_pretrained("microsoft/phi-1")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).loss