Transformers documentation
Backbones
Backbones
Backbones are models used for feature extraction for computer vision tasks. One can use a model as backbone in two ways:
- initializing
AutoBackboneclass with a pretrained model, - initializing a supported backbone configuration and passing it to the model architecture.
Using AutoBackbone
You can use AutoBackbone class to initialize a model as a backbone and get the feature maps for any stage. You can define out_indices to indicate the index of the layers which you would like to get the feature maps from. You can also use out_features if you know the name of the layers. You can use them interchangeably. If you are using both out_indices and out_features, ensure they are consistent. Not passing any of the feature map arguments will make the backbone yield the feature maps of the last layer.
To visualize how stages look like, let’s take the Swin model. Each stage is responsible from feature extraction, outputting feature maps.
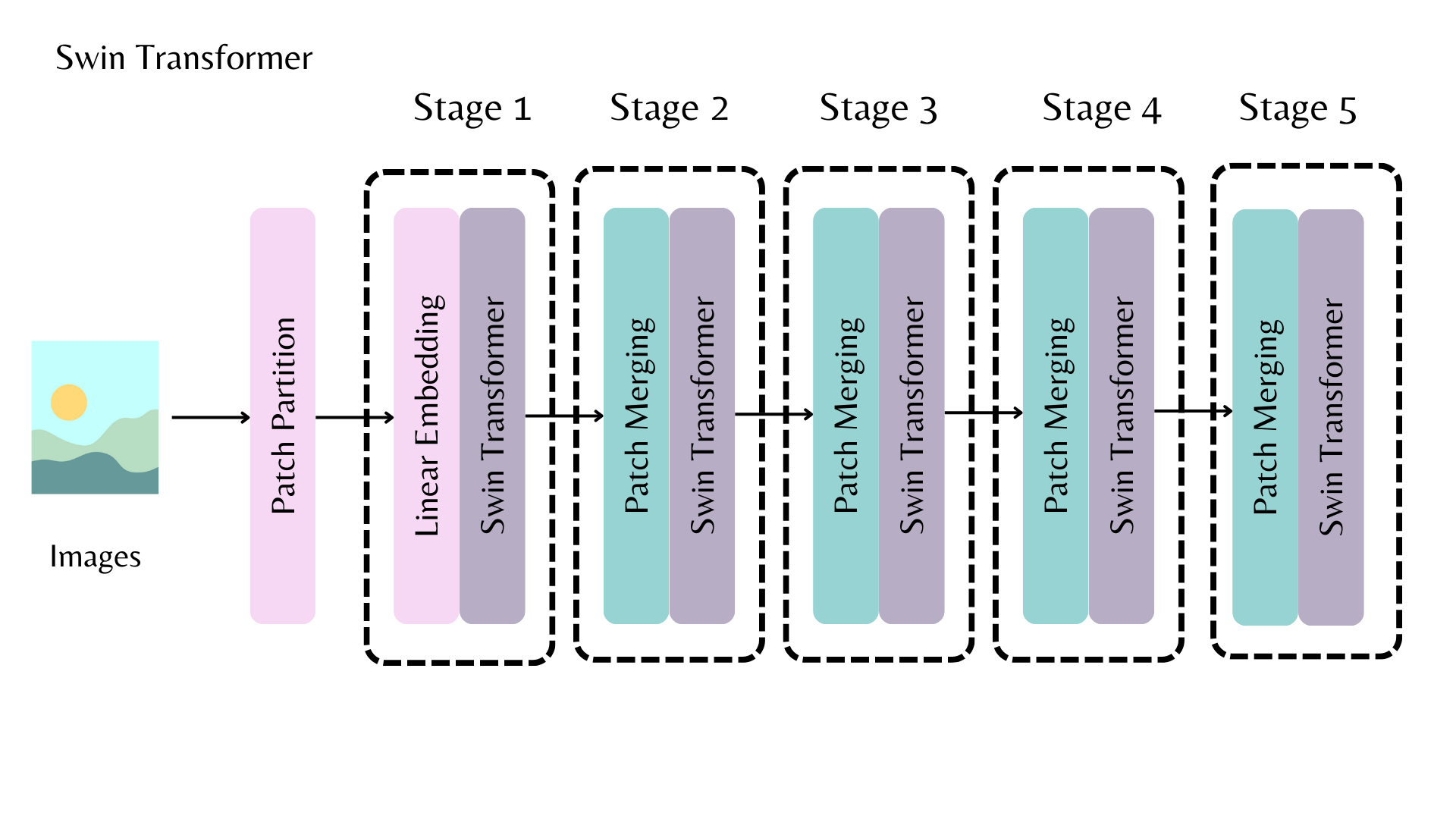
Illustrating feature maps of the first stage looks like below.
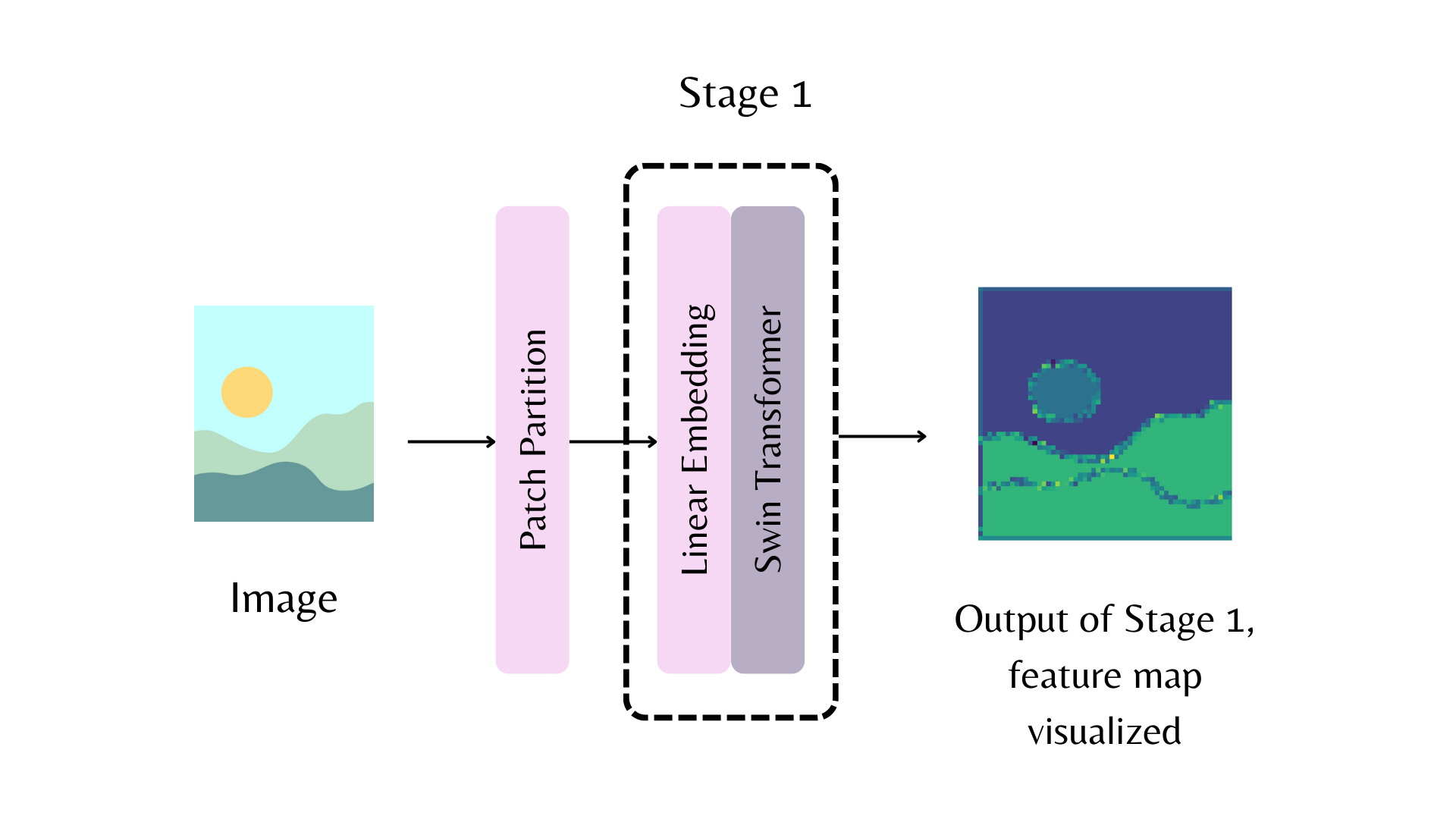
Let’s see with an example. Note that out_indices=(0,) results in yielding the stem of the model. Stem refers to the stage before the first feature extraction stage. In above diagram, it refers to patch partition. We would like to have the feature maps from stem, first, and second stage of the model.
>>> from transformers import AutoImageProcessor, AutoBackbone
>>> import torch
>>> from PIL import Image
>>> import requests
>>> processor = AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224")
>>> model = AutoBackbone.from_pretrained("microsoft/swin-tiny-patch4-window7-224", out_indices=(0,1,2))
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> feature_maps = outputs.feature_mapsfeature_maps object now has three feature maps, each can be accessed like below. Say we would like to get the feature map of the stem.
>>> list(feature_maps[0].shape)
[1, 96, 56, 56]We can get the feature maps of first and second stages like below.
>>> list(feature_maps[1].shape)
[1, 96, 56, 56]
>>> list(feature_maps[2].shape)
[1, 192, 28, 28]Initializing Backbone Configuration
In computer vision, models consist of backbone, neck, and a head. Backbone extracts the features, neck transforms the output of the backbone and head is used for the main task (e.g. object detection). You can initialize neck and head with model backbones by passing a model configuration to backbone_config. For example, below you can see how to initialize the MaskFormer model with instance segmentation head with ResNet backbone.
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation, ResNetConfig
backbone_config = ResNetConfig.from_pretrained("microsoft/resnet-50")
config = MaskFormerConfig(backbone_config=backbone_config)
model = MaskFormerForInstanceSegmentation(config)You can also initialize a backbone with random weights to initialize the model neck with it.
backbone_config = ResNetConfig() config = MaskFormerConfig(backbone_config=backbone_config) model = MaskFormerForInstanceSegmentation(config)
timm models are also supported in transformers through TimmBackbone and TimmBackboneConfig.
from transformers import TimmBackboneConfig, TimmBackbone
backbone_config = TimmBackboneConfig("resnet50")
model = TimmBackbone(config=backbone_config)