Transformers documentation
Bark
Bark
Overview
Bark is a transformer-based text-to-speech model proposed by Suno AI in suno-ai/bark.
Bark is made of 4 main models:
- BarkSemanticModel (also referred to as the ‘text’ model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- BarkCoarseModel (also referred to as the ‘coarse acoustics’ model): a causal autoregressive transformer, that takes as input the results of the BarkSemanticModel model. It aims at predicting the first two audio codebooks necessary for EnCodec.
- BarkFineModel (the ‘fine acoustics’ model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the EncodecModel, Bark uses it to decode the output audio array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
This model was contributed by Yoach Lacombe (ylacombe) and Sanchit Gandhi (sanchit-gandhi). The original code can be found here.
Optimizing Bark
Bark can be optimized with just a few extra lines of code, which significantly reduces its memory footprint and accelerates inference.
Using half-precision
You can speed up inference and reduce memory footprint by 50% simply by loading the model in half-precision.
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)Using CPU offload
As mentioned above, Bark is made up of 4 sub-models, which are called up sequentially during audio generation. In other words, while one sub-model is in use, the other sub-models are idle.
If you’re using a CUDA device, a simple solution to benefit from an 80% reduction in memory footprint is to offload the submodels from GPU to CPU when they’re idle. This operation is called CPU offloading. You can use it with one line of code as follows:
model.enable_cpu_offload()
Note that 🤗 Accelerate must be installed before using this feature. Here’s how to install it.
Using Better Transformer
Better Transformer is an 🤗 Optimum feature that performs kernel fusion under the hood. You can gain 20% to 30% in speed with zero performance degradation. It only requires one line of code to export the model to 🤗 Better Transformer:
model = model.to_bettertransformer()
Note that 🤗 Optimum must be installed before using this feature. Here’s how to install it.
Using Flash Attention 2
Flash Attention 2 is an even faster, optimized version of the previous optimization.
Installation
First, check whether your hardware is compatible with Flash Attention 2. The latest list of compatible hardware can be found in the official documentation. If your hardware is not compatible with Flash Attention 2, you can still benefit from attention kernel optimisations through Better Transformer support covered above.
Next, install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolation
Usage
To load a model using Flash Attention 2, we can pass the attn_implementation="flash_attention_2" flag to .from_pretrained. We’ll also load the model in half-precision (e.g. torch.float16), since it results in almost no degradation to audio quality but significantly lower memory usage and faster inference:
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)Performance comparison
The following diagram shows the latency for the native attention implementation (no optimisation) against Better Transformer and Flash Attention 2. In all cases, we generate 400 semantic tokens on a 40GB A100 GPU with PyTorch 2.1. Flash Attention 2 is also consistently faster than Better Transformer, and its performance improves even more as batch sizes increase:
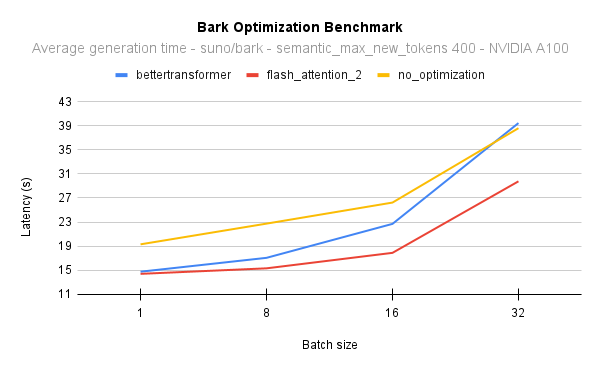
To put this into perspective, on an NVIDIA A100 and when generating 400 semantic tokens with a batch size of 16, you can get 17 times the throughput and still be 2 seconds faster than generating sentences one by one with the native model implementation. In other words, all the samples will be generated 17 times faster.
At batch size 8, on an NVIDIA A100, Flash Attention 2 is also 10% faster than Better Transformer, and at batch size 16, 25%.
Combining optimization techniques
You can combine optimization techniques, and use CPU offload, half-precision and Flash Attention 2 (or 🤗 Better Transformer) all at once.
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# load in fp16 and use Flash Attention 2
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to(device)
# enable CPU offload
model.enable_cpu_offload()Find out more on inference optimization techniques here.
Usage tips
Suno offers a library of voice presets in a number of languages here. These presets are also uploaded in the hub here or here.
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark")
>>> model = BarkModel.from_pretrained("suno/bark")
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()Bark can generate highly realistic, multilingual speech as well as other audio - including music, background noise and simple sound effects.
>>> # Multilingual speech - simplified Chinese
>>> inputs = processor("惊人的!我会说中文")
>>> # Multilingual speech - French - let's use a voice_preset as well
>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
>>> inputs = processor("♪ Hello, my dog is cute ♪")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()The model can also produce nonverbal communications like laughing, sighing and crying.
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()To save the audio, simply take the sample rate from the model config and some scipy utility:
>>> from scipy.io.wavfile import write as write_wav
>>> # save audio to disk, but first take the sample rate from the model config
>>> sample_rate = model.generation_config.sample_rate
>>> write_wav("bark_generation.wav", sample_rate, audio_array)BarkConfig
class transformers.BarkConfig
< source >( semantic_config: typing.Dict = None coarse_acoustics_config: typing.Dict = None fine_acoustics_config: typing.Dict = None codec_config: typing.Dict = None initializer_range = 0.02 **kwargs )
Parameters
- semantic_config (BarkSemanticConfig, optional) — Configuration of the underlying semantic sub-model.
- coarse_acoustics_config (BarkCoarseConfig, optional) — Configuration of the underlying coarse acoustics sub-model.
- fine_acoustics_config (BarkFineConfig, optional) — Configuration of the underlying fine acoustics sub-model.
- codec_config (AutoConfig, optional) —
Configuration of the underlying codec sub-model.
Example —
This is the configuration class to store the configuration of a BarkModel. It is used to instantiate a Bark model according to the specified sub-models configurations, defining the model architecture.
Instantiating a configuration with the defaults will yield a similar configuration to that of the Bark suno/bark architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
from_sub_model_configs
< source >( semantic_config: BarkSemanticConfig coarse_acoustics_config: BarkCoarseConfig fine_acoustics_config: BarkFineConfig codec_config: PretrainedConfig **kwargs ) → BarkConfig
Instantiate a BarkConfig (or a derived class) from bark sub-models configuration.
BarkProcessor
class transformers.BarkProcessor
< source >( tokenizer speaker_embeddings = None )
Parameters
- tokenizer (PreTrainedTokenizer) — An instance of PreTrainedTokenizer.
- speaker_embeddings (
Dict[Dict[str]], optional) — Optional nested speaker embeddings dictionary. The first level contains voice preset names (e.g"en_speaker_4"). The second level contains"semantic_prompt","coarse_prompt"and"fine_prompt"embeddings. The values correspond to the path of the correspondingnp.ndarray. See here for a list ofvoice_preset_names.
Constructs a Bark processor which wraps a text tokenizer and optional Bark voice presets into a single processor.
__call__
< source >( text = None voice_preset = None return_tensors = 'pt' max_length = 256 add_special_tokens = False return_attention_mask = True return_token_type_ids = False **kwargs ) → Tuple(BatchEncoding, BatchFeature)
Parameters
- text (
str,List[str],List[List[str]]) — The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings (pretokenized string). If the sequences are provided as list of strings (pretokenized), you must setis_split_into_words=True(to lift the ambiguity with a batch of sequences). - voice_preset (
str,Dict[np.ndarray]) — The voice preset, i.e the speaker embeddings. It can either be a valid voice_preset name, e.g"en_speaker_1", or directly a dictionnary ofnp.ndarrayembeddings for each submodel ofBark. Or it can be a valid file name of a local.npzsingle voice preset. - return_tensors (
stror TensorType, optional) — If set, will return tensors of a particular framework. Acceptable values are:'pt': Return PyTorchtorch.Tensorobjects.'np': Return NumPynp.ndarrayobjects.
Returns
Tuple(BatchEncoding, BatchFeature)
A tuple composed of a BatchEncoding, i.e the output of the
tokenizer and a BatchFeature, i.e the voice preset with the right tensors type.
Main method to prepare for the model one or several sequences(s). This method forwards the text and kwargs
arguments to the AutoTokenizer’s __call__() to encode the text. The method also proposes a
voice preset which is a dictionary of arrays that conditions Bark’s output. kwargs arguments are forwarded
to the tokenizer and to cached_file method if voice_preset is a valid filename.
from_pretrained
< source >( pretrained_processor_name_or_path speaker_embeddings_dict_path = 'speaker_embeddings_path.json' **kwargs )
Parameters
- pretrained_model_name_or_path (
stroros.PathLike) — This can be either:- a string, the model id of a pretrained BarkProcessor hosted inside a model repo on
huggingface.co. Valid model ids can be located at the root-level, like
bert-base-uncased, or namespaced under a user or organization name, likedbmdz/bert-base-german-cased. - a path to a directory containing a processor saved using the save_pretrained()
method, e.g.,
./my_model_directory/.
- a string, the model id of a pretrained BarkProcessor hosted inside a model repo on
huggingface.co. Valid model ids can be located at the root-level, like
- speaker_embeddings_dict_path (
str, optional, defaults to"speaker_embeddings_path.json") — The name of the.jsonfile containing the speaker_embeddings dictionnary located inpretrained_model_name_or_path. IfNone, no speaker_embeddings is loaded. **kwargs — Additional keyword arguments passed along to both~tokenization_utils_base.PreTrainedTokenizer.from_pretrained.
Instantiate a Bark processor associated with a pretrained model.
save_pretrained
< source >( save_directory speaker_embeddings_dict_path = 'speaker_embeddings_path.json' speaker_embeddings_directory = 'speaker_embeddings' push_to_hub: bool = False **kwargs )
Parameters
- save_directory (
stroros.PathLike) — Directory where the tokenizer files and the speaker embeddings will be saved (directory will be created if it does not exist). - speaker_embeddings_dict_path (
str, optional, defaults to"speaker_embeddings_path.json") — The name of the.jsonfile that will contains the speaker_embeddings nested path dictionnary, if it exists, and that will be located inpretrained_model_name_or_path/speaker_embeddings_directory. - speaker_embeddings_directory (
str, optional, defaults to"speaker_embeddings/") — The name of the folder in which the speaker_embeddings arrays will be saved. - push_to_hub (
bool, optional, defaults toFalse) — Whether or not to push your model to the Hugging Face model hub after saving it. You can specify the repository you want to push to withrepo_id(will default to the name ofsave_directoryin your namespace). kwargs — Additional key word arguments passed along to the push_to_hub() method.
Saves the attributes of this processor (tokenizer…) in the specified directory so that it can be reloaded using the from_pretrained() method.
BarkModel
class transformers.BarkModel
< source >( config )
Parameters
- config (BarkConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The full Bark model, a text-to-speech model composed of 4 sub-models:
- BarkSemanticModel (also referred to as the ‘text’ model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- BarkCoarseModel (also refered to as the ‘coarse acoustics’ model), also a causal autoregressive transformer,
that takes into input the results of the last model. It aims at regressing the first two audio codebooks necessary
to
encodec. - BarkFineModel (the ‘fine acoustics’ model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the EncodecModel, Bark uses it to decode the output audio array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
generate
< source >( input_ids: typing.Optional[torch.Tensor] = None history_prompt: typing.Union[typing.Dict[str, torch.Tensor], NoneType] = None return_output_lengths: typing.Optional[bool] = None **kwargs ) → By default
Parameters
- input_ids (
Optional[torch.Tensor]of shape (batch_size, seq_len), optional) — Input ids. Will be truncated up to 256 tokens. Note that the output audios will be as long as the longest generation among the batch. - history_prompt (
Optional[Dict[str,torch.Tensor]], optional) — OptionalBarkspeaker prompt. Note that for now, this model takes only one speaker prompt per batch. - kwargs (optional) — Remaining dictionary of keyword arguments. Keyword arguments are of two types:
- Without a prefix, they will be entered as
**kwargsfor thegeneratemethod of each sub-model. - With a semantic_, coarse_, fine_ prefix, they will be input for the
generatemethod of the semantic, coarse and fine respectively. It has the priority over the keywords without a prefix.
This means you can, for example, specify a generation strategy for all sub-models except one.
- Without a prefix, they will be entered as
- return_output_lengths (
bool, optional) — Whether or not to return the waveform lengths. Useful when batching.
Returns
By default
- audio_waveform (
torch.Tensorof shape (batch_size, seq_len)): Generated audio waveform. Whenreturn_output_lengths=True: Returns a tuple made of: - audio_waveform (
torch.Tensorof shape (batch_size, seq_len)): Generated audio waveform. - output_lengths (
torch.Tensorof shape (batch_size)): The length of each waveform in the batch
Generates audio from an input prompt and an additional optional Bark speaker prompt.
Example:
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark-small")
>>> model = BarkModel.from_pretrained("suno/bark-small")
>>> # To add a voice preset, you can pass `voice_preset` to `BarkProcessor.__call__(...)`
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute, I need him in my life", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs, semantic_max_new_tokens=100)
>>> audio_array = audio_array.cpu().numpy().squeeze()enable_cpu_offload
< source >( gpu_id: typing.Optional[int] = 0 )
Offloads all sub-models to CPU using accelerate, reducing memory usage with a low impact on performance. This method moves one whole sub-model at a time to the GPU when it is used, and the sub-model remains in GPU until the next sub-model runs.
BarkSemanticModel
class transformers.BarkSemanticModel
< source >( config )
Parameters
- config (BarkSemanticConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Bark semantic (or text) model. It shares the same architecture as the coarse model. It is a GPT-2 like autoregressive model with a language modeling head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cacheis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- input_embeds (
torch.FloatTensorof shape(batch_size, input_sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. Here, due toBarkparticularities, ifpast_key_valuesis used,input_embedswill be ignored and you have to useinput_ids. Ifpast_key_valuesis not used anduse_cacheis set toTrue,input_embedsis used in priority instead ofinput_ids. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The BarkCausalModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
BarkCoarseModel
class transformers.BarkCoarseModel
< source >( config )
Parameters
- config (BarkCoarseConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Bark coarse acoustics model. It shares the same architecture as the semantic (or text) model. It is a GPT-2 like autoregressive model with a language modeling head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cacheis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- input_embeds (
torch.FloatTensorof shape(batch_size, input_sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. Here, due toBarkparticularities, ifpast_key_valuesis used,input_embedswill be ignored and you have to useinput_ids. Ifpast_key_valuesis not used anduse_cacheis set toTrue,input_embedsis used in priority instead ofinput_ids. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The BarkCausalModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
BarkFineModel
class transformers.BarkFineModel
< source >( config )
Parameters
- config (BarkFineConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Bark fine acoustics model. It is a non-causal GPT-like model with config.n_codes_total embedding layers and
language modeling heads, one for each codebook.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( codebook_idx: int input_ids: typing.Optional[torch.Tensor] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- codebook_idx (
int) — Index of the codebook that will be predicted. - input_ids (
torch.LongTensorof shape(batch_size, sequence_length, number_of_codebooks)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. Initially, indices of the first two codebooks are obtained from thecoarsesub-model. The rest is predicted recursively by attending the previously predicted channels. The model predicts on windows of length 1024. - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — NOT IMPLEMENTED YET. - input_embeds (
torch.FloatTensorof shape(batch_size, input_sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. Ifpast_key_valuesis used, optionally only the lastinput_embedshave to be input (seepast_key_values). This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The BarkFineModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
BarkCausalModel
forward
< source >( input_ids: typing.Optional[torch.Tensor] = None past_key_values: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attention_mask: typing.Optional[torch.Tensor] = None position_ids: typing.Optional[torch.Tensor] = None head_mask: typing.Optional[torch.Tensor] = None labels: typing.Optional[torch.LongTensor] = None input_embeds: typing.Optional[torch.Tensor] = None use_cache: typing.Optional[bool] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None )
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. What are input IDs? - past_key_values (
tuple(tuple(torch.FloatTensor)), optional, returned whenuse_cacheis passed or whenconfig.use_cache=True) — Tuple oftuple(torch.FloatTensor)of lengthconfig.n_layers, with each tuple having 2 tensors of shape(batch_size, num_heads, sequence_length, embed_size_per_head).Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see
past_key_valuesinput) to speed up sequential decoding.If
past_key_valuesare used, the user can optionally input only the lastdecoder_input_ids(those that don’t have their past key value states given to this model) of shape(batch_size, 1)instead of allinput_idsof shape(batch_size, sequence_length). - attention_mask (
torch.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.Tensorof shape(encoder_layers, encoder_attention_heads), optional) — Mask to nullify selected heads of the attention modules in the encoder. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- input_embeds (
torch.FloatTensorof shape(batch_size, input_sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. Here, due toBarkparticularities, ifpast_key_valuesis used,input_embedswill be ignored and you have to useinput_ids. Ifpast_key_valuesis not used anduse_cacheis set toTrue,input_embedsis used in priority instead ofinput_ids. - use_cache (
bool, optional) — If set toTrue,past_key_valueskey value states are returned and can be used to speed up decoding (seepast_key_values). - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
The BarkCausalModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
BarkCoarseConfig
class transformers.BarkCoarseConfig
< source >( block_size = 1024 input_vocab_size = 10048 output_vocab_size = 10048 num_layers = 12 num_heads = 12 hidden_size = 768 dropout = 0.0 bias = True initializer_range = 0.02 use_cache = True **kwargs )
Parameters
- block_size (
int, optional, defaults to 1024) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - input_vocab_size (
int, optional, defaults to 10_048) — Vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling BarkCoarseModel. Defaults to 10_048 but should be carefully thought with regards to the chosen sub-model. - output_vocab_size (
int, optional, defaults to 10_048) — Output vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by the:output_idswhen passing forward a BarkCoarseModel. Defaults to 10_048 but should be carefully thought with regards to the chosen sub-model. - num_layers (
int, optional, defaults to 12) — Number of hidden layers in the given sub-model. - num_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer architecture. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the “intermediate” (often named feed-forward) layer in the architecture. - dropout (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - bias (
bool, optional, defaults toTrue) — Whether or not to use bias in the linear layers and layer norm layers. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models).
This is the configuration class to store the configuration of a BarkCoarseModel. It is used to instantiate the model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Bark suno/bark architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import BarkCoarseConfig, BarkCoarseModel
>>> # Initializing a Bark sub-module style configuration
>>> configuration = BarkCoarseConfig()
>>> # Initializing a model (with random weights) from the suno/bark style configuration
>>> model = BarkCoarseModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configBarkFineConfig
class transformers.BarkFineConfig
< source >( tie_word_embeddings = True n_codes_total = 8 n_codes_given = 1 **kwargs )
Parameters
- block_size (
int, optional, defaults to 1024) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - input_vocab_size (
int, optional, defaults to 10_048) — Vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling BarkFineModel. Defaults to 10_048 but should be carefully thought with regards to the chosen sub-model. - output_vocab_size (
int, optional, defaults to 10_048) — Output vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by the:output_idswhen passing forward a BarkFineModel. Defaults to 10_048 but should be carefully thought with regards to the chosen sub-model. - num_layers (
int, optional, defaults to 12) — Number of hidden layers in the given sub-model. - num_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer architecture. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the “intermediate” (often named feed-forward) layer in the architecture. - dropout (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - bias (
bool, optional, defaults toTrue) — Whether or not to use bias in the linear layers and layer norm layers. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models). - n_codes_total (
int, optional, defaults to 8) — The total number of audio codebooks predicted. Used in the fine acoustics sub-model. - n_codes_given (
int, optional, defaults to 1) — The number of audio codebooks predicted in the coarse acoustics sub-model. Used in the acoustics sub-models.
This is the configuration class to store the configuration of a BarkFineModel. It is used to instantiate the model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Bark suno/bark architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import BarkFineConfig, BarkFineModel
>>> # Initializing a Bark sub-module style configuration
>>> configuration = BarkFineConfig()
>>> # Initializing a model (with random weights) from the suno/bark style configuration
>>> model = BarkFineModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configBarkSemanticConfig
class transformers.BarkSemanticConfig
< source >( block_size = 1024 input_vocab_size = 10048 output_vocab_size = 10048 num_layers = 12 num_heads = 12 hidden_size = 768 dropout = 0.0 bias = True initializer_range = 0.02 use_cache = True **kwargs )
Parameters
- block_size (
int, optional, defaults to 1024) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - input_vocab_size (
int, optional, defaults to 10_048) — Vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling BarkSemanticModel. Defaults to 10_048 but should be carefully thought with regards to the chosen sub-model. - output_vocab_size (
int, optional, defaults to 10_048) — Output vocabulary size of a Bark sub-model. Defines the number of different tokens that can be represented by the:output_idswhen passing forward a BarkSemanticModel. Defaults to 10_048 but should be carefully thought with regards to the chosen sub-model. - num_layers (
int, optional, defaults to 12) — Number of hidden layers in the given sub-model. - num_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer architecture. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the “intermediate” (often named feed-forward) layer in the architecture. - dropout (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - bias (
bool, optional, defaults toTrue) — Whether or not to use bias in the linear layers and layer norm layers. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - use_cache (
bool, optional, defaults toTrue) — Whether or not the model should return the last key/values attentions (not used by all models).
This is the configuration class to store the configuration of a BarkSemanticModel. It is used to instantiate the model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Bark suno/bark architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import BarkSemanticConfig, BarkSemanticModel
>>> # Initializing a Bark sub-module style configuration
>>> configuration = BarkSemanticConfig()
>>> # Initializing a model (with random weights) from the suno/bark style configuration
>>> model = BarkSemanticModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config