Transformers documentation
Image captioning
Image captioning
画像のキャプション付けは、特定の画像のキャプションを予測するタスクです。一般的な現実世界のアプリケーションには次のものがあります。 視覚障害者がさまざまな状況を乗り越えられるよう支援します。したがって、画像のキャプション 画像を説明することで人々のコンテンツへのアクセシビリティを向上させるのに役立ちます。
このガイドでは、次の方法を説明します。
- 画像キャプション モデルを微調整します。
- 微調整されたモデルを推論に使用します。
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
pip install transformers datasets evaluate -q pip install jiwer -q
モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
from huggingface_hub import notebook_login
notebook_login()Load the Pokémon BLIP captions dataset
🤗 データセット ライブラリを使用して、{image-caption} ペアで構成されるデータセットを読み込みます。独自の画像キャプション データセットを作成するには PyTorch では、このノートブック を参照できます。
ds = load_dataset("lambdalabs/pokemon-blip-captions")
dsDatasetDict({
train: Dataset({
features: ['image', 'text'],
num_rows: 833
})
})データセットには imageとtextの 2 つの機能があります。
多くの画像キャプション データセットには、画像ごとに複数のキャプションが含まれています。このような場合、一般的な戦略は、トレーニング中に利用可能なキャプションの中からランダムにキャプションをサンプリングすることです。
[~datasets.Dataset.train_test_split] メソッドを使用して、データセットのトレイン スプリットをトレイン セットとテスト セットに分割します。
ds = ds["train"].train_test_split(test_size=0.1)
train_ds = ds["train"]
test_ds = ds["test"]トレーニング セットからのいくつかのサンプルを視覚化してみましょう。
from textwrap import wrap
import matplotlib.pyplot as plt
import numpy as np
def plot_images(images, captions):
plt.figure(figsize=(20, 20))
for i in range(len(images)):
ax = plt.subplot(1, len(images), i + 1)
caption = captions[i]
caption = "\n".join(wrap(caption, 12))
plt.title(caption)
plt.imshow(images[i])
plt.axis("off")
sample_images_to_visualize = [np.array(train_ds[i]["image"]) for i in range(5)]
sample_captions = [train_ds[i]["text"] for i in range(5)]
plot_images(sample_images_to_visualize, sample_captions)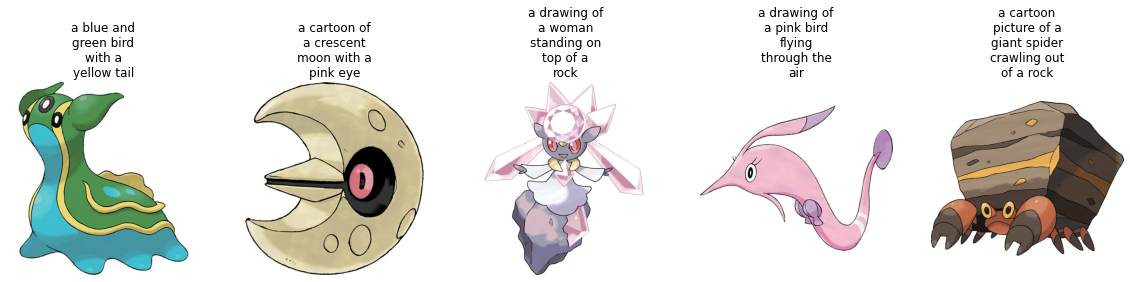
Preprocess the dataset
データセットには 2 つのモダリティ (画像とテキスト) があるため、前処理パイプラインは画像とキャプションを前処理します。
これを行うには、微調整しようとしているモデルに関連付けられたプロセッサ クラスをロードします。
from transformers import AutoProcessor
checkpoint = "microsoft/git-base"
processor = AutoProcessor.from_pretrained(checkpoint)プロセッサは内部で画像を前処理し (サイズ変更やピクセル スケーリングを含む)、キャプションをトークン化します。
def transforms(example_batch):
images = [x for x in example_batch["image"]]
captions = [x for x in example_batch["text"]]
inputs = processor(images=images, text=captions, padding="max_length")
inputs.update({"labels": inputs["input_ids"]})
return inputs
train_ds.set_transform(transforms)
test_ds.set_transform(transforms)データセットの準備ができたら、微調整用にモデルをセットアップできます。
Load a base model
“microsoft/git-base” を AutoModelForCausalLM オブジェクト。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(checkpoint)Evaluate
画像キャプション モデルは通常、Rouge Score または Word Error Rate で評価されます。そうだった)。このガイドでは、Word Error Rate (WER) を使用します。
これを行うには 🤗 Evaluate ライブラリを使用します。 WER の潜在的な制限やその他の問題点については、このガイド を参照してください。
from evaluate import load
import torch
wer = load("wer")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predicted = logits.argmax(-1)
decoded_labels = processor.batch_decode(labels, skip_special_tokens=True)
decoded_predictions = processor.batch_decode(predicted, skip_special_tokens=True)
wer_score = wer.compute(predictions=decoded_predictions, references=decoded_labels)
return {"wer_score": wer_score}Train!
これで、モデルの微調整を開始する準備が整いました。これには 🤗 Trainer を使用します。
まず、TrainingArguments を使用してトレーニング引数を定義します。
from transformers import TrainingArguments, Trainer
model_name = checkpoint.split("/")[1]
training_args = TrainingArguments(
output_dir=f"{model_name}-pokemon",
learning_rate=5e-5,
num_train_epochs=50,
fp16=True,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
gradient_accumulation_steps=2,
save_total_limit=3,
evaluation_strategy="steps",
eval_steps=50,
save_strategy="steps",
save_steps=50,
logging_steps=50,
remove_unused_columns=False,
push_to_hub=True,
label_names=["labels"],
load_best_model_at_end=True,
)Trainer 次に、次に、データセットとモデルと一緒に 🤗 に渡します。
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_ds,
eval_dataset=test_ds,
compute_metrics=compute_metrics,
)トレーニングを開始するには、Trainer オブジェクトの train() を呼び出すだけです。
trainer.train()
トレーニングが進むにつれて、トレーニングの損失がスムーズに減少することがわかります。
トレーニングが完了したら、 push_to_hub() メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
trainer.push_to_hub()
Inference
test_ds からサンプル画像を取得してモデルをテストします。
from PIL import Image
import requests
url = "https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/pokemon.png"
image = Image.open(requests.get(url, stream=True).raw)
image
モデル用の画像を準備します。
device = "cuda" if torch.cuda.is_available() else "cpu"
inputs = processor(images=image, return_tensors="pt").to(device)
pixel_values = inputs.pixel_valuesgenerate を呼び出して予測をデコードします。
generated_ids = model.generate(pixel_values=pixel_values, max_length=50)
generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_caption)a drawing of a pink and blue pokemon
微調整されたモデルにより、非常に優れたキャプションが生成されたようです。