Transformers documentation
TAPAS
TAPAS
Overview
The TAPAS model was proposed in TAPAS: Weakly Supervised Table Parsing via Pre-training by Jonathan Herzig, Paweł Krzysztof Nowak, Thomas Müller, Francesco Piccinno and Julian Martin Eisenschlos. It’s a BERT-based model specifically designed (and pre-trained) for answering questions about tabular data. Compared to BERT, TAPAS uses relative position embeddings and has 7 token types that encode tabular structure. TAPAS is pre-trained on the masked language modeling (MLM) objective on a large dataset comprising millions of tables from English Wikipedia and corresponding texts.
For question answering, TAPAS has 2 heads on top: a cell selection head and an aggregation head, for (optionally) performing aggregations (such as counting or summing) among selected cells. TAPAS has been fine-tuned on several datasets:
- SQA (Sequential Question Answering by Microsoft)
- WTQ (Wiki Table Questions by Stanford University)
- WikiSQL (by Salesforce).
It achieves state-of-the-art on both SQA and WTQ, while having comparable performance to SOTA on WikiSQL, with a much simpler architecture.
The abstract from the paper is the following:
Answering natural language questions over tables is usually seen as a semantic parsing task. To alleviate the collection cost of full logical forms, one popular approach focuses on weak supervision consisting of denotations instead of logical forms. However, training semantic parsers from weak supervision poses difficulties, and in addition, the generated logical forms are only used as an intermediate step prior to retrieving the denotation. In this paper, we present TAPAS, an approach to question answering over tables without generating logical forms. TAPAS trains from weak supervision, and predicts the denotation by selecting table cells and optionally applying a corresponding aggregation operator to such selection. TAPAS extends BERT’s architecture to encode tables as input, initializes from an effective joint pre-training of text segments and tables crawled from Wikipedia, and is trained end-to-end. We experiment with three different semantic parsing datasets, and find that TAPAS outperforms or rivals semantic parsing models by improving state-of-the-art accuracy on SQA from 55.1 to 67.2 and performing on par with the state-of-the-art on WIKISQL and WIKITQ, but with a simpler model architecture. We additionally find that transfer learning, which is trivial in our setting, from WIKISQL to WIKITQ, yields 48.7 accuracy, 4.2 points above the state-of-the-art.
In addition, the authors have further pre-trained TAPAS to recognize table entailment, by creating a balanced dataset of millions of automatically created training examples which are learned in an intermediate step prior to fine-tuning. The authors of TAPAS call this further pre-training intermediate pre-training (since TAPAS is first pre-trained on MLM, and then on another dataset). They found that intermediate pre-training further improves performance on SQA, achieving a new state-of-the-art as well as state-of-the-art on TabFact, a large-scale dataset with 16k Wikipedia tables for table entailment (a binary classification task). For more details, see their follow-up paper: Understanding tables with intermediate pre-training by Julian Martin Eisenschlos, Syrine Krichene and Thomas Müller.
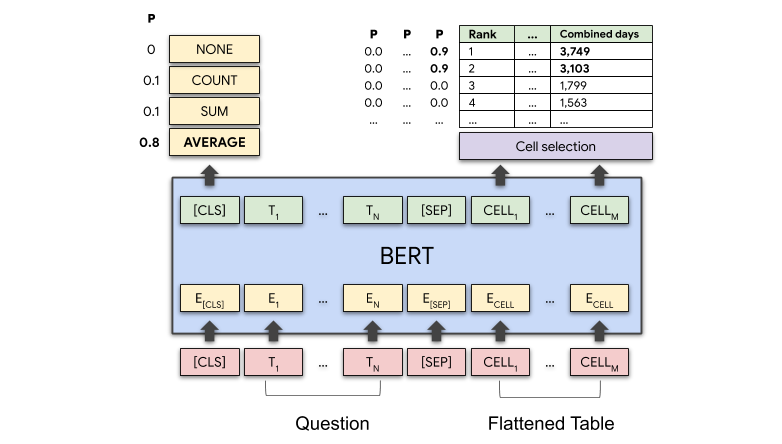 TAPAS architecture. Taken from the original blog post.
TAPAS architecture. Taken from the original blog post. This model was contributed by nielsr. The Tensorflow version of this model was contributed by kamalkraj. The original code can be found here.
Tips:
- TAPAS is a model that uses relative position embeddings by default (restarting the position embeddings at every cell of the table). Note that this is something that was added after the publication of the original TAPAS paper. According to the authors, this usually results in a slightly better performance, and allows you to encode longer sequences without running out of embeddings. This is reflected in the
reset_position_index_per_cellparameter of TapasConfig, which is set toTrueby default. The default versions of the models available on the hub all use relative position embeddings. You can still use the ones with absolute position embeddings by passing in an additional argumentrevision="no_reset"when calling thefrom_pretrained()method. Note that it’s usually advised to pad the inputs on the right rather than the left. - TAPAS is based on BERT, so
TAPAS-basefor example corresponds to aBERT-basearchitecture. Of course,TAPAS-largewill result in the best performance (the results reported in the paper are fromTAPAS-large). Results of the various sized models are shown on the original Github repository. - TAPAS has checkpoints fine-tuned on SQA, which are capable of answering questions related to a table in a conversational set-up. This means that you can ask follow-up questions such as “what is his age?” related to the previous question. Note that the forward pass of TAPAS is a bit different in case of a conversational set-up: in that case, you have to feed every table-question pair one by one to the model, such that the
prev_labelstoken type ids can be overwritten by the predictedlabelsof the model to the previous question. See “Usage” section for more info. - TAPAS is similar to BERT and therefore relies on the masked language modeling (MLM) objective. It is therefore efficient at predicting masked tokens and at NLU in general, but is not optimal for text generation. Models trained with a causal language modeling (CLM) objective are better in that regard. Note that TAPAS can be used as an encoder in the EncoderDecoderModel framework, to combine it with an autoregressive text decoder such as GPT-2.
Usage: fine-tuning
Here we explain how you can fine-tune TapasForQuestionAnswering on your own dataset.
STEP 1: Choose one of the 3 ways in which you can use TAPAS - or experiment
Basically, there are 3 different ways in which one can fine-tune TapasForQuestionAnswering, corresponding to the different datasets on which Tapas was fine-tuned:
- SQA: if you’re interested in asking follow-up questions related to a table, in a conversational set-up. For example if you first ask “what’s the name of the first actor?” then you can ask a follow-up question such as “how old is he?“. Here, questions do not involve any aggregation (all questions are cell selection questions).
- WTQ: if you’re not interested in asking questions in a conversational set-up, but rather just asking questions related to a table, which might involve aggregation, such as counting a number of rows, summing up cell values or averaging cell values. You can then for example ask “what’s the total number of goals Cristiano Ronaldo made in his career?“. This case is also called weak supervision, since the model itself must learn the appropriate aggregation operator (SUM/COUNT/AVERAGE/NONE) given only the answer to the question as supervision.
- WikiSQL-supervised: this dataset is based on WikiSQL with the model being given the ground truth aggregation operator during training. This is also called strong supervision. Here, learning the appropriate aggregation operator is much easier.
To summarize:
| Task | Example dataset | Description |
|---|---|---|
| Conversational | SQA | Conversational, only cell selection questions |
| Weak supervision for aggregation | WTQ | Questions might involve aggregation, and the model must learn this given only the answer as supervision |
| Strong supervision for aggregation | WikiSQL-supervised | Questions might involve aggregation, and the model must learn this given the gold aggregation operator |
Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below.
>>> from transformers import TapasConfig, TapasForQuestionAnswering
>>> # for example, the base sized model with default SQA configuration
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base")
>>> # or, the base sized model with WTQ configuration
>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> # or, the base sized model with WikiSQL configuration
>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)Of course, you don’t necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing TapasConfig, and then create a TapasForQuestionAnswering based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here’s an example:
>>> from transformers import TapasConfig, TapasForQuestionAnswering
>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
>>> # initializing the pre-trained base sized model with our custom classification heads
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)Initializing a model with a pre-trained base and randomly initialized classification heads from the hub can be done as shown below. Be sure to have installed the tensorflow_probability dependency:
>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
>>> # for example, the base sized model with default SQA configuration
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base")
>>> # or, the base sized model with WTQ configuration
>>> config = TapasConfig.from_pretrained("google/tapas-base-finetuned-wtq")
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> # or, the base sized model with WikiSQL configuration
>>> config = TapasConfig("google-base-finetuned-wikisql-supervised")
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)Of course, you don’t necessarily have to follow one of these three ways in which TAPAS was fine-tuned. You can also experiment by defining any hyperparameters you want when initializing TapasConfig, and then create a TFTapasForQuestionAnswering based on that configuration. For example, if you have a dataset that has both conversational questions and questions that might involve aggregation, then you can do it this way. Here’s an example:
>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
>>> # you can initialize the classification heads any way you want (see docs of TapasConfig)
>>> config = TapasConfig(num_aggregation_labels=3, average_logits_per_cell=True)
>>> # initializing the pre-trained base sized model with our custom classification heads
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)What you can also do is start from an already fine-tuned checkpoint. A note here is that the already fine-tuned checkpoint on WTQ has some issues due to the L2-loss which is somewhat brittle. See here for more info.
For a list of all pre-trained and fine-tuned TAPAS checkpoints available on HuggingFace’s hub, see here.
STEP 2: Prepare your data in the SQA format
Second, no matter what you picked above, you should prepare your dataset in the SQA format. This format is a TSV/CSV file with the following columns:
id: optional, id of the table-question pair, for bookkeeping purposes.annotator: optional, id of the person who annotated the table-question pair, for bookkeeping purposes.position: integer indicating if the question is the first, second, third,… related to the table. Only required in case of conversational setup (SQA). You don’t need this column in case you’re going for WTQ/WikiSQL-supervised.question: stringtable_file: string, name of a csv file containing the tabular dataanswer_coordinates: list of one or more tuples (each tuple being a cell coordinate, i.e. row, column pair that is part of the answer)answer_text: list of one or more strings (each string being a cell value that is part of the answer)aggregation_label: index of the aggregation operator. Only required in case of strong supervision for aggregation (the WikiSQL-supervised case)float_answer: the float answer to the question, if there is one (np.nan if there isn’t). Only required in case of weak supervision for aggregation (such as WTQ and WikiSQL)
The tables themselves should be present in a folder, each table being a separate csv file. Note that the authors of the TAPAS algorithm used conversion scripts with some automated logic to convert the other datasets (WTQ, WikiSQL) into the SQA format. The author explains this here. A conversion of this script that works with HuggingFace’s implementation can be found here. Interestingly, these conversion scripts are not perfect (the answer_coordinates and float_answer fields are populated based on the answer_text), meaning that WTQ and WikiSQL results could actually be improved.
STEP 3: Convert your data into tensors using TapasTokenizer
Third, given that you’ve prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use TapasTokenizer to convert table-question pairs into input_ids, attention_mask, token_type_ids and so on. Again, based on which of the three cases you picked above, TapasForQuestionAnswering requires different
inputs to be fine-tuned:
| Task | Required inputs |
|---|---|
| Conversational | input_ids, attention_mask, token_type_ids, labels |
| Weak supervision for aggregation | input_ids, attention_mask, token_type_ids, labels, numeric_values, numeric_values_scale, float_answer |
| Strong supervision for aggregation | input ids, attention mask, token type ids, labels, aggregation_labels |
TapasTokenizer creates the labels, numeric_values and numeric_values_scale based on the answer_coordinates and answer_text columns of the TSV file. The float_answer and aggregation_labels are already in the TSV file of step 2. Here’s an example:
>>> from transformers import TapasTokenizer
>>> import pandas as pd
>>> model_name = "google/tapas-base"
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(
... table=table,
... queries=queries,
... answer_coordinates=answer_coordinates,
... answer_text=answer_text,
... padding="max_length",
... return_tensors="pt",
... )
>>> inputs
{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}Note that TapasTokenizer expects the data of the table to be text-only. You can use .astype(str) on a dataframe to turn it into text-only data.
Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
>>> import torch
>>> import pandas as pd
>>> tsv_path = "your_path_to_the_tsv_file"
>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
>>> class TableDataset(torch.utils.data.Dataset):
... def __init__(self, data, tokenizer):
... self.data = data
... self.tokenizer = tokenizer
... def __getitem__(self, idx):
... item = data.iloc[idx]
... table = pd.read_csv(table_csv_path + item.table_file).astype(
... str
... ) # be sure to make your table data text only
... encoding = self.tokenizer(
... table=table,
... queries=item.question,
... answer_coordinates=item.answer_coordinates,
... answer_text=item.answer_text,
... truncation=True,
... padding="max_length",
... return_tensors="pt",
... )
... # remove the batch dimension which the tokenizer adds by default
... encoding = {key: val.squeeze(0) for key, val in encoding.items()}
... # add the float_answer which is also required (weak supervision for aggregation case)
... encoding["float_answer"] = torch.tensor(item.float_answer)
... return encoding
... def __len__(self):
... return len(self.data)
>>> data = pd.read_csv(tsv_path, sep="\t")
>>> train_dataset = TableDataset(data, tokenizer)
>>> train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=32)Third, given that you’ve prepared your data in this TSV/CSV format (and corresponding CSV files containing the tabular data), you can then use TapasTokenizer to convert table-question pairs into input_ids, attention_mask, token_type_ids and so on. Again, based on which of the three cases you picked above, TFTapasForQuestionAnswering requires different
inputs to be fine-tuned:
| Task | Required inputs |
|---|---|
| Conversational | input_ids, attention_mask, token_type_ids, labels |
| Weak supervision for aggregation | input_ids, attention_mask, token_type_ids, labels, numeric_values, numeric_values_scale, float_answer |
| Strong supervision for aggregation | input ids, attention mask, token type ids, labels, aggregation_labels |
TapasTokenizer creates the labels, numeric_values and numeric_values_scale based on the answer_coordinates and answer_text columns of the TSV file. The float_answer and aggregation_labels are already in the TSV file of step 2. Here’s an example:
>>> from transformers import TapasTokenizer
>>> import pandas as pd
>>> model_name = "google/tapas-base"
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> answer_coordinates = [[(0, 0)], [(2, 1)], [(0, 1), (1, 1), (2, 1)]]
>>> answer_text = [["Brad Pitt"], ["69"], ["209"]]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(
... table=table,
... queries=queries,
... answer_coordinates=answer_coordinates,
... answer_text=answer_text,
... padding="max_length",
... return_tensors="tf",
... )
>>> inputs
{'input_ids': tensor([[ ... ]]), 'attention_mask': tensor([[...]]), 'token_type_ids': tensor([[[...]]]),
'numeric_values': tensor([[ ... ]]), 'numeric_values_scale: tensor([[ ... ]]), labels: tensor([[ ... ]])}Note that TapasTokenizer expects the data of the table to be text-only. You can use .astype(str) on a dataframe to turn it into text-only data.
Of course, this only shows how to encode a single training example. It is advised to create a dataloader to iterate over batches:
>>> import tensorflow as tf
>>> import pandas as pd
>>> tsv_path = "your_path_to_the_tsv_file"
>>> table_csv_path = "your_path_to_a_directory_containing_all_csv_files"
>>> class TableDataset:
... def __init__(self, data, tokenizer):
... self.data = data
... self.tokenizer = tokenizer
... def __iter__(self):
... for idx in range(self.__len__()):
... item = self.data.iloc[idx]
... table = pd.read_csv(table_csv_path + item.table_file).astype(
... str
... ) # be sure to make your table data text only
... encoding = self.tokenizer(
... table=table,
... queries=item.question,
... answer_coordinates=item.answer_coordinates,
... answer_text=item.answer_text,
... truncation=True,
... padding="max_length",
... return_tensors="tf",
... )
... # remove the batch dimension which the tokenizer adds by default
... encoding = {key: tf.squeeze(val, 0) for key, val in encoding.items()}
... # add the float_answer which is also required (weak supervision for aggregation case)
... encoding["float_answer"] = tf.convert_to_tensor(item.float_answer, dtype=tf.float32)
... yield encoding["input_ids"], encoding["attention_mask"], encoding["numeric_values"], encoding[
... "numeric_values_scale"
... ], encoding["token_type_ids"], encoding["labels"], encoding["float_answer"]
... def __len__(self):
... return len(self.data)
>>> data = pd.read_csv(tsv_path, sep="\t")
>>> train_dataset = TableDataset(data, tokenizer)
>>> output_signature = (
... tf.TensorSpec(shape=(512,), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.float32),
... tf.TensorSpec(shape=(512,), dtype=tf.float32),
... tf.TensorSpec(shape=(512, 7), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.int32),
... tf.TensorSpec(shape=(512,), dtype=tf.float32),
... )
>>> train_dataloader = tf.data.Dataset.from_generator(train_dataset, output_signature=output_signature).batch(32)Note that here, we encode each table-question pair independently. This is fine as long as your dataset is not conversational. In case your dataset involves conversational questions (such as in SQA), then you should first group together the queries, answer_coordinates and answer_text per table (in the order of their position
index) and batch encode each table with its questions. This will make sure that the prev_labels token types (see docs of TapasTokenizer) are set correctly. See this notebook for more info. See this notebook for more info regarding using the TensorFlow model.
**STEP 4: Train (fine-tune) the model
You can then fine-tune TapasForQuestionAnswering as follows (shown here for the weak supervision for aggregation case):
>>> from transformers import TapasConfig, TapasForQuestionAnswering, AdamW
>>> # this is the default WTQ configuration
>>> config = TapasConfig(
... num_aggregation_labels=4,
... use_answer_as_supervision=True,
... answer_loss_cutoff=0.664694,
... cell_selection_preference=0.207951,
... huber_loss_delta=0.121194,
... init_cell_selection_weights_to_zero=True,
... select_one_column=True,
... allow_empty_column_selection=False,
... temperature=0.0352513,
... )
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> optimizer = AdamW(model.parameters(), lr=5e-5)
>>> model.train()
>>> for epoch in range(2): # loop over the dataset multiple times
... for batch in train_dataloader:
... # get the inputs;
... input_ids = batch["input_ids"]
... attention_mask = batch["attention_mask"]
... token_type_ids = batch["token_type_ids"]
... labels = batch["labels"]
... numeric_values = batch["numeric_values"]
... numeric_values_scale = batch["numeric_values_scale"]
... float_answer = batch["float_answer"]
... # zero the parameter gradients
... optimizer.zero_grad()
... # forward + backward + optimize
... outputs = model(
... input_ids=input_ids,
... attention_mask=attention_mask,
... token_type_ids=token_type_ids,
... labels=labels,
... numeric_values=numeric_values,
... numeric_values_scale=numeric_values_scale,
... float_answer=float_answer,
... )
... loss = outputs.loss
... loss.backward()
... optimizer.step()You can then fine-tune TFTapasForQuestionAnswering as follows (shown here for the weak supervision for aggregation case):
>>> import tensorflow as tf
>>> from transformers import TapasConfig, TFTapasForQuestionAnswering
>>> # this is the default WTQ configuration
>>> config = TapasConfig(
... num_aggregation_labels=4,
... use_answer_as_supervision=True,
... answer_loss_cutoff=0.664694,
... cell_selection_preference=0.207951,
... huber_loss_delta=0.121194,
... init_cell_selection_weights_to_zero=True,
... select_one_column=True,
... allow_empty_column_selection=False,
... temperature=0.0352513,
... )
>>> model = TFTapasForQuestionAnswering.from_pretrained("google/tapas-base", config=config)
>>> optimizer = tf.keras.optimizers.Adam(learning_rate=5e-5)
>>> for epoch in range(2): # loop over the dataset multiple times
... for batch in train_dataloader:
... # get the inputs;
... input_ids = batch[0]
... attention_mask = batch[1]
... token_type_ids = batch[4]
... labels = batch[-1]
... numeric_values = batch[2]
... numeric_values_scale = batch[3]
... float_answer = batch[6]
... # forward + backward + optimize
... with tf.GradientTape() as tape:
... outputs = model(
... input_ids=input_ids,
... attention_mask=attention_mask,
... token_type_ids=token_type_ids,
... labels=labels,
... numeric_values=numeric_values,
... numeric_values_scale=numeric_values_scale,
... float_answer=float_answer,
... )
... grads = tape.gradient(outputs.loss, model.trainable_weights)
... optimizer.apply_gradients(zip(grads, model.trainable_weights))Usage: inference
Here we explain how you can use TapasForQuestionAnswering or TFTapasForQuestionAnswering for inference (i.e. making predictions on new data). For inference, only input_ids, attention_mask and token_type_ids (which you can obtain using TapasTokenizer) have to be provided to the model to obtain the logits. Next, you can use the handy ~models.tapas.tokenization_tapas.convert_logits_to_predictions method to convert these into predicted coordinates and optional aggregation indices.
However, note that inference is different depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here’s an example of that:
>>> from transformers import TapasTokenizer, TapasForQuestionAnswering
>>> import pandas as pd
>>> model_name = "google/tapas-base-finetuned-wtq"
>>> model = TapasForQuestionAnswering.from_pretrained(model_name)
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
... inputs, outputs.logits.detach(), outputs.logits_aggregation.detach()
... )
>>> # let's print out the results:
>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
>>> answers = []
>>> for coordinates in predicted_answer_coordinates:
... if len(coordinates) == 1:
... # only a single cell:
... answers.append(table.iat[coordinates[0]])
... else:
... # multiple cells
... cell_values = []
... for coordinate in coordinates:
... cell_values.append(table.iat[coordinate])
... answers.append(", ".join(cell_values))
>>> display(table)
>>> print("")
>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
... print(query)
... if predicted_agg == "NONE":
... print("Predicted answer: " + answer)
... else:
... print("Predicted answer: " + predicted_agg + " > " + answer)
What is the name of the first actor?
Predicted answer: Brad Pitt
How many movies has George Clooney played in?
Predicted answer: COUNT > 69
What is the total number of movies?
Predicted answer: SUM > 87, 53, 69Here we explain how you can use TFTapasForQuestionAnswering for inference (i.e. making predictions on new data). For inference, only input_ids, attention_mask and token_type_ids (which you can obtain using TapasTokenizer) have to be provided to the model to obtain the logits. Next, you can use the handy ~models.tapas.tokenization_tapas.convert_logits_to_predictions method to convert these into predicted coordinates and optional aggregation indices.
However, note that inference is different depending on whether or not the setup is conversational. In a non-conversational set-up, inference can be done in parallel on all table-question pairs of a batch. Here’s an example of that:
>>> from transformers import TapasTokenizer, TFTapasForQuestionAnswering
>>> import pandas as pd
>>> model_name = "google/tapas-base-finetuned-wtq"
>>> model = TFTapasForQuestionAnswering.from_pretrained(model_name)
>>> tokenizer = TapasTokenizer.from_pretrained(model_name)
>>> data = {"Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"], "Number of movies": ["87", "53", "69"]}
>>> queries = [
... "What is the name of the first actor?",
... "How many movies has George Clooney played in?",
... "What is the total number of movies?",
... ]
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
>>> outputs = model(**inputs)
>>> predicted_answer_coordinates, predicted_aggregation_indices = tokenizer.convert_logits_to_predictions(
... inputs, outputs.logits, outputs.logits_aggregation
... )
>>> # let's print out the results:
>>> id2aggregation = {0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"}
>>> aggregation_predictions_string = [id2aggregation[x] for x in predicted_aggregation_indices]
>>> answers = []
>>> for coordinates in predicted_answer_coordinates:
... if len(coordinates) == 1:
... # only a single cell:
... answers.append(table.iat[coordinates[0]])
... else:
... # multiple cells
... cell_values = []
... for coordinate in coordinates:
... cell_values.append(table.iat[coordinate])
... answers.append(", ".join(cell_values))
>>> display(table)
>>> print("")
>>> for query, answer, predicted_agg in zip(queries, answers, aggregation_predictions_string):
... print(query)
... if predicted_agg == "NONE":
... print("Predicted answer: " + answer)
... else:
... print("Predicted answer: " + predicted_agg + " > " + answer)
What is the name of the first actor?
Predicted answer: Brad Pitt
How many movies has George Clooney played in?
Predicted answer: COUNT > 69
What is the total number of movies?
Predicted answer: SUM > 87, 53, 69In case of a conversational set-up, then each table-question pair must be provided sequentially to the model, such that the prev_labels token types can be overwritten by the predicted labels of the previous table-question pair. Again, more info can be found in this notebook (for PyTorch) and this notebook (for TensorFlow).
Documentation resources
TAPAS specific outputs
class transformers.models.tapas.modeling_tapas.TableQuestionAnsweringOutput
< source >( loss: typing.Optional[torch.FloatTensor] = None logits: FloatTensor = None logits_aggregation: FloatTensor = None hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor]] = None attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None )
Parameters
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabels(and possiblyanswer,aggregation_labels,numeric_valuesandnumeric_values_scaleare provided)) — Total loss as the sum of the hierarchical cell selection log-likelihood loss and (optionally) the semi-supervised regression loss and (optionally) supervised loss for aggregations. - logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Prediction scores of the cell selection head, for every token. - logits_aggregation (
torch.FloatTensor, optional, of shape(batch_size, num_aggregation_labels)) — Prediction scores of the aggregation head, for every aggregation operator. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
Output type of TapasForQuestionAnswering.
TapasConfig
class transformers.TapasConfig
< source >( vocab_size = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 intermediate_size = 3072 hidden_act = 'gelu' hidden_dropout_prob = 0.1 attention_probs_dropout_prob = 0.1 max_position_embeddings = 1024 type_vocab_sizes = [3, 256, 256, 2, 256, 256, 10] initializer_range = 0.02 layer_norm_eps = 1e-12 pad_token_id = 0 positive_label_weight = 10.0 num_aggregation_labels = 0 aggregation_loss_weight = 1.0 use_answer_as_supervision = None answer_loss_importance = 1.0 use_normalized_answer_loss = False huber_loss_delta = None temperature = 1.0 aggregation_temperature = 1.0 use_gumbel_for_cells = False use_gumbel_for_aggregation = False average_approximation_function = 'ratio' cell_selection_preference = None answer_loss_cutoff = None max_num_rows = 64 max_num_columns = 32 average_logits_per_cell = False select_one_column = True allow_empty_column_selection = False init_cell_selection_weights_to_zero = False reset_position_index_per_cell = True disable_per_token_loss = False aggregation_labels = None no_aggregation_label_index = None **kwargs )
Parameters
- vocab_size (
int, optional, defaults to 30522) — Vocabulary size of the TAPAS model. Defines the number of different tokens that can be represented by theinputs_idspassed when calling TapasModel. - hidden_size (
int, optional, defaults to 768) — Dimensionality of the encoder layers and the pooler layer. - num_hidden_layers (
int, optional, defaults to 12) — Number of hidden layers in the Transformer encoder. - num_attention_heads (
int, optional, defaults to 12) — Number of attention heads for each attention layer in the Transformer encoder. - intermediate_size (
int, optional, defaults to 3072) — Dimensionality of the “intermediate” (often named feed-forward) layer in the Transformer encoder. - hidden_act (
strorCallable, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder and pooler. If string,"gelu","relu","swish"and"gelu_new"are supported. - hidden_dropout_prob (
float, optional, defaults to 0.1) — The dropout probability for all fully connected layers in the embeddings, encoder, and pooler. - attention_probs_dropout_prob (
float, optional, defaults to 0.1) — The dropout ratio for the attention probabilities. - max_position_embeddings (
int, optional, defaults to 1024) — The maximum sequence length that this model might ever be used with. Typically set this to something large just in case (e.g., 512 or 1024 or 2048). - type_vocab_sizes (
List[int], optional, defaults to[3, 256, 256, 2, 256, 256, 10]) — The vocabulary sizes of thetoken_type_idspassed when calling TapasModel. - initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. - layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. - positive_label_weight (
float, optional, defaults to 10.0) — Weight for positive labels. - num_aggregation_labels (
int, optional, defaults to 0) — The number of aggregation operators to predict. - aggregation_loss_weight (
float, optional, defaults to 1.0) — Importance weight for the aggregation loss. - use_answer_as_supervision (
bool, optional) — Whether to use the answer as the only supervision for aggregation examples. - answer_loss_importance (
float, optional, defaults to 1.0) — Importance weight for the regression loss. - use_normalized_answer_loss (
bool, optional, defaults toFalse) — Whether to normalize the answer loss by the maximum of the predicted and expected value. - huber_loss_delta (
float, optional) — Delta parameter used to calculate the regression loss. - temperature (
float, optional, defaults to 1.0) — Value used to control (OR change) the skewness of cell logits probabilities. - aggregation_temperature (
float, optional, defaults to 1.0) — Scales aggregation logits to control the skewness of probabilities. - use_gumbel_for_cells (
bool, optional, defaults toFalse) — Whether to apply Gumbel-Softmax to cell selection. - use_gumbel_for_aggregation (
bool, optional, defaults toFalse) — Whether to apply Gumbel-Softmax to aggregation selection. - average_approximation_function (
string, optional, defaults to"ratio") — Method to calculate the expected average of cells in the weak supervision case. One of"ratio","first_order"or"second_order". - cell_selection_preference (
float, optional) — Preference for cell selection in ambiguous cases. Only applicable in case of weak supervision for aggregation (WTQ, WikiSQL). If the total mass of the aggregation probabilities (excluding the “NONE” operator) is higher than this hyperparameter, then aggregation is predicted for an example. - answer_loss_cutoff (
float, optional) — Ignore examples with answer loss larger than cutoff. - max_num_rows (
int, optional, defaults to 64) — Maximum number of rows. - max_num_columns (
int, optional, defaults to 32) — Maximum number of columns. - average_logits_per_cell (
bool, optional, defaults toFalse) — Whether to average logits per cell. - select_one_column (
bool, optional, defaults toTrue) — Whether to constrain the model to only select cells from a single column. - allow_empty_column_selection (
bool, optional, defaults toFalse) — Whether to allow not to select any column. - init_cell_selection_weights_to_zero (
bool, optional, defaults toFalse) — Whether to initialize cell selection weights to 0 so that the initial probabilities are 50%. - reset_position_index_per_cell (
bool, optional, defaults toTrue) — Whether to restart position indexes at every cell (i.e. use relative position embeddings). - disable_per_token_loss (
bool, optional, defaults toFalse) — Whether to disable any (strong or weak) supervision on cells. - aggregation_labels (
Dict[int, label], optional) — The aggregation labels used to aggregate the results. For example, the WTQ models have the following aggregation labels:{0: "NONE", 1: "SUM", 2: "AVERAGE", 3: "COUNT"} - no_aggregation_label_index (
int, optional) — If the aggregation labels are defined and one of these labels represents “No aggregation”, this should be set to its index. For example, the WTQ models have the “NONE” aggregation label at index 0, so that value should be set to 0 for these models.
This is the configuration class to store the configuration of a TapasModel. It is used to instantiate a TAPAS model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the TAPAS google/tapas-base-finetuned-sqa architecture.
Configuration objects inherit from PreTrainedConfig and can be used to control the model outputs. Read the
documentation from PretrainedConfig for more information.
Hyperparameters additional to BERT are taken from run_task_main.py and hparam_utils.py of the original implementation. Original implementation available at https://github.com/google-research/tapas/tree/master.
Example:
>>> from transformers import TapasModel, TapasConfig
>>> # Initializing a default (SQA) Tapas configuration
>>> configuration = TapasConfig()
>>> # Initializing a model from the configuration
>>> model = TapasModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configTapasTokenizer
class transformers.TapasTokenizer
< source >( vocab_file do_lower_case = True do_basic_tokenize = True never_split = None unk_token = '[UNK]' sep_token = '[SEP]' pad_token = '[PAD]' cls_token = '[CLS]' mask_token = '[MASK]' empty_token = '[EMPTY]' tokenize_chinese_chars = True strip_accents = None cell_trim_length: int = -1 max_column_id: int = None max_row_id: int = None strip_column_names: bool = False update_answer_coordinates: bool = False min_question_length = None max_question_length = None model_max_length: int = 512 additional_special_tokens: typing.Optional[typing.List[str]] = None **kwargs )
Parameters
- vocab_file (
str) — File containing the vocabulary. - do_lower_case (
bool, optional, defaults toTrue) — Whether or not to lowercase the input when tokenizing. - do_basic_tokenize (
bool, optional, defaults toTrue) — Whether or not to do basic tokenization before WordPiece. - never_split (
Iterable, optional) — Collection of tokens which will never be split during tokenization. Only has an effect whendo_basic_tokenize=True - unk_token (
str, optional, defaults to"[UNK]") — The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this token instead. - sep_token (
str, optional, defaults to"[SEP]") — The separator token, which is used when building a sequence from multiple sequences, e.g. two sequences for sequence classification or for a text and a question for question answering. It is also used as the last token of a sequence built with special tokens. - pad_token (
str, optional, defaults to"[PAD]") — The token used for padding, for example when batching sequences of different lengths. - cls_token (
str, optional, defaults to"[CLS]") — The classifier token which is used when doing sequence classification (classification of the whole sequence instead of per-token classification). It is the first token of the sequence when built with special tokens. - mask_token (
str, optional, defaults to"[MASK]") — The token used for masking values. This is the token used when training this model with masked language modeling. This is the token which the model will try to predict. - empty_token (
str, optional, defaults to"[EMPTY]") — The token used for empty cell values in a table. Empty cell values include "", “n/a”, “nan” and ”?“. - tokenize_chinese_chars (
bool, optional, defaults toTrue) — Whether or not to tokenize Chinese characters. This should likely be deactivated for Japanese (see this issue). - strip_accents (
bool, optional) — Whether or not to strip all accents. If this option is not specified, then it will be determined by the value forlowercase(as in the original BERT). - cell_trim_length (
int, optional, defaults to -1) — If > 0: Trim cells so that the length is <= this value. Also disables further cell trimming, should thus be used withtruncationset toTrue. - max_column_id (
int, optional) — Max column id to extract. - max_row_id (
int, optional) — Max row id to extract. - strip_column_names (
bool, optional, defaults toFalse) — Whether to add empty strings instead of column names. - update_answer_coordinates (
bool, optional, defaults toFalse) — Whether to recompute the answer coordinates from the answer text. - min_question_length (
int, optional) — Minimum length of each question in terms of tokens (will be skipped otherwise). - max_question_length (
int, optional) — Maximum length of each question in terms of tokens (will be skipped otherwise).
Construct a TAPAS tokenizer. Based on WordPiece. Flattens a table and one or more related sentences to be used by TAPAS models.
This tokenizer inherits from PreTrainedTokenizer which contains most of the main methods. Users should refer to
this superclass for more information regarding those methods. TapasTokenizer creates several token type ids to
encode tabular structure. To be more precise, it adds 7 token type ids, in the following order: segment_ids,
column_ids, row_ids, prev_labels, column_ranks, inv_column_ranks and numeric_relations:
- segment_ids: indicate whether a token belongs to the question (0) or the table (1). 0 for special tokens and padding.
- column_ids: indicate to which column of the table a token belongs (starting from 1). Is 0 for all question tokens, special tokens and padding.
- row_ids: indicate to which row of the table a token belongs (starting from 1). Is 0 for all question tokens, special tokens and padding. Tokens of column headers are also 0.
- prev_labels: indicate whether a token was (part of) an answer to the previous question (1) or not (0). Useful in a conversational setup (such as SQA).
- column_ranks: indicate the rank of a table token relative to a column, if applicable. For example, if you have a column “number of movies” with values 87, 53 and 69, then the column ranks of these tokens are 3, 1 and 2 respectively. 0 for all question tokens, special tokens and padding.
- inv_column_ranks: indicate the inverse rank of a table token relative to a column, if applicable. For example, if you have a column “number of movies” with values 87, 53 and 69, then the inverse column ranks of these tokens are 1, 3 and 2 respectively. 0 for all question tokens, special tokens and padding.
- numeric_relations: indicate numeric relations between the question and the tokens of the table. 0 for all question tokens, special tokens and padding.
TapasTokenizer runs end-to-end tokenization on a table and associated sentences: punctuation splitting and wordpiece.
__call__
< source >( table: pd.DataFrame queries: typing.Union[str, typing.List[str], typing.List[int], typing.List[typing.List[str]], typing.List[typing.List[int]], NoneType] = None answer_coordinates: typing.Union[typing.List[typing.Tuple], typing.List[typing.List[typing.Tuple]], NoneType] = None answer_text: typing.Union[typing.List[str], typing.List[typing.List[str]], NoneType] = None add_special_tokens: bool = True padding: typing.Union[bool, str, transformers.utils.generic.PaddingStrategy] = False truncation: typing.Union[bool, str, transformers.models.tapas.tokenization_tapas.TapasTruncationStrategy] = False max_length: typing.Optional[int] = None pad_to_multiple_of: typing.Optional[int] = None return_tensors: typing.Union[str, transformers.utils.generic.TensorType, NoneType] = None return_token_type_ids: typing.Optional[bool] = None return_attention_mask: typing.Optional[bool] = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True **kwargs )
Parameters
- table (
pd.DataFrame) — Table containing tabular data. Note that all cell values must be text. Use .astype(str) on a Pandas dataframe to convert it to string. - queries (
strorList[str]) — Question or batch of questions related to a table to be encoded. Note that in case of a batch, all questions must refer to the same table. - answer_coordinates (
List[Tuple]orList[List[Tuple]], optional) — Answer coordinates of each table-question pair in the batch. In case only a single table-question pair is provided, then the answer_coordinates must be a single list of one or more tuples. Each tuple must be a (row_index, column_index) pair. The first data row (not the column header row) has index 0. The first column has index 0. In case a batch of table-question pairs is provided, then the answer_coordinates must be a list of lists of tuples (each list corresponding to a single table-question pair). - answer_text (
List[str]orList[List[str]], optional) — Answer text of each table-question pair in the batch. In case only a single table-question pair is provided, then the answer_text must be a single list of one or more strings. Each string must be the answer text of a corresponding answer coordinate. In case a batch of table-question pairs is provided, then the answer_coordinates must be a list of lists of strings (each list corresponding to a single table-question pair). - add_special_tokens (
bool, optional, defaults toTrue) — Whether or not to encode the sequences with the special tokens relative to their model. - padding (
bool,stror PaddingStrategy, optional, defaults toFalse) — Activates and controls padding. Accepts the following values:Trueor'longest': Pad to the longest sequence in the batch (or no padding if only a single sequence if provided).'max_length': Pad to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided.Falseor'do_not_pad'(default): No padding (i.e., can output a batch with sequences of different lengths).
- truncation (
bool,strorTapasTruncationStrategy, optional, defaults toFalse) — Activates and controls truncation. Accepts the following values:Trueor'drop_rows_to_fit': Truncate to a maximum length specified with the argumentmax_lengthor to the maximum acceptable input length for the model if that argument is not provided. This will truncate row by row, removing rows from the table.Falseor'do_not_truncate'(default): No truncation (i.e., can output batch with sequence lengths greater than the model maximum admissible input size).
- max_length (
int, optional) — Controls the maximum length to use by one of the truncation/padding parameters.If left unset or set to
None, this will use the predefined model maximum length if a maximum length is required by one of the truncation/padding parameters. If the model has no specific maximum input length (like XLNet) truncation/padding to a maximum length will be deactivated. - is_split_into_words (
bool, optional, defaults toFalse) — Whether or not the input is already pre-tokenized (e.g., split into words). If set toTrue, the tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace) which it will tokenize. This is useful for NER or token classification. - pad_to_multiple_of (
int, optional) — If set will pad the sequence to a multiple of the provided value. This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability>= 7.5(Volta). - return_tensors (
stror TensorType, optional) — If set, will return tensors instead of list of python integers. Acceptable values are:'tf': Return TensorFlowtf.constantobjects.'pt': Return PyTorchtorch.Tensorobjects.'np': Return Numpynp.ndarrayobjects.
Main method to tokenize and prepare for the model one or several sequence(s) related to a table.
convert_logits_to_predictions
< source >( data logits logits_agg = None cell_classification_threshold = 0.5 ) → tuple comprising various elements depending on the inputs
Parameters
- data (
dict) — Dictionary mapping features to actual values. Should be created using TapasTokenizer. - logits (
torch.Tensorortf.Tensorof shape(batch_size, sequence_length)) — Tensor containing the logits at the token level. - logits_agg (
torch.Tensorortf.Tensorof shape(batch_size, num_aggregation_labels), optional) — Tensor containing the aggregation logits. - cell_classification_threshold (
float, optional, defaults to 0.5) — Threshold to be used for cell selection. All table cells for which their probability is larger than this threshold will be selected.
Returns
tuple comprising various elements depending on the inputs
- predicted_answer_coordinates (
List[List[[tuple]]of lengthbatch_size): Predicted answer coordinates as a list of lists of tuples. Each element in the list contains the predicted answer coordinates of a single example in the batch, as a list of tuples. Each tuple is a cell, i.e. (row index, column index). - predicted_aggregation_indices (
List[int]of lengthbatch_size, optional, returned whenlogits_aggregationis provided): Predicted aggregation operator indices of the aggregation head.
Converts logits of TapasForQuestionAnswering to actual predicted answer coordinates and optional aggregation indices.
The original implementation, on which this function is based, can be found here.
TapasModel
class transformers.TapasModel
< source >( config add_pooling_layer = True )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Tapas Model transformer outputting raw hidden-states without any specific head on top. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its models (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
This class is a small change compared to BertModel, taking into account the additional token type ids.
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of cross-attention is added between the self-attention layers, following the architecture described in Attention is all you need by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None encoder_hidden_states: typing.Optional[torch.FloatTensor] = None encoder_attention_mask: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]: - 1 indicates the head is not masked, - 0 indicates the head is masked. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
A transformers.modeling_outputs.BaseModelOutputWithPooling or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TapasConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) after further processing through the layers used for the auxiliary pretraining task. E.g. for BERT-family of models, this returns the classification token after processing through a linear layer and a tanh activation function. The linear layer weights are trained from the next sentence prediction (classification) objective during pretraining. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TapasModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasModel
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base")
>>> model = TapasModel.from_pretrained("google/tapas-base")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> queries = ["How many movies has George Clooney played in?", "How old is Brad Pitt?"]
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateTapasForMaskedLM
class transformers.TapasForMaskedLM
< source >( config )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tapas Model with a language modeling head on top.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the
library implements for all its models (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None encoder_hidden_states: typing.Optional[torch.FloatTensor] = None encoder_attention_mask: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None **kwargs ) → transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]: - 1 indicates the head is not masked, - 0 indicates the head is masked. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_outputs.MaskedLMOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.MaskedLMOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TapasConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
torch.FloatTensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TapasForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasForMaskedLM
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base")
>>> model = TapasForMaskedLM.from_pretrained("google/tapas-base")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(
... table=table, queries="How many [MASK] has George [MASK] played in?", return_tensors="pt"
... )
>>> labels = tokenizer(
... table=table, queries="How many movies has George Clooney played in?", return_tensors="pt"
... )["input_ids"]
>>> outputs = model(**inputs, labels=labels)
>>> logits = outputs.logitsTapasForSequenceClassification
class transformers.TapasForSequenceClassification
< source >( config )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tapas Model with a sequence classification head on top (a linear layer on top of the pooled output), e.g. for table entailment tasks, such as TabFact (Chen et al., 2020).
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its models (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None labels: typing.Optional[torch.LongTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]: - 1 indicates the head is not masked, - 0 indicates the head is masked. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy). Note: this is called “classification_class_index” in the original implementation.
Returns
transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
A transformers.modeling_outputs.SequenceClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TapasConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TapasForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasForSequenceClassification
>>> import torch
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base-finetuned-tabfact")
>>> model = TapasForSequenceClassification.from_pretrained("google/tapas-base-finetuned-tabfact")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> queries = [
... "There is only one actor who is 45 years old",
... "There are 3 actors which played in more than 60 movies",
... ]
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
>>> labels = torch.tensor([1, 0]) # 1 means entailed, 0 means refuted
>>> outputs = model(**inputs, labels=labels)
>>> loss = outputs.loss
>>> logits = outputs.logitsTapasForQuestionAnswering
class transformers.TapasForQuestionAnswering
< source >( config: TapasConfig )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tapas Model with a cell selection head and optional aggregation head on top for question-answering tasks on tables
(linear layers on top of the hidden-states output to compute logits and optional logits_aggregation), e.g. for
SQA, WTQ or WikiSQL-supervised tasks.
This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its models (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch torch.nn.Module subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >( input_ids: typing.Optional[torch.LongTensor] = None attention_mask: typing.Optional[torch.FloatTensor] = None token_type_ids: typing.Optional[torch.LongTensor] = None position_ids: typing.Optional[torch.LongTensor] = None head_mask: typing.Optional[torch.FloatTensor] = None inputs_embeds: typing.Optional[torch.FloatTensor] = None table_mask: typing.Optional[torch.LongTensor] = None labels: typing.Optional[torch.LongTensor] = None aggregation_labels: typing.Optional[torch.LongTensor] = None float_answer: typing.Optional[torch.FloatTensor] = None numeric_values: typing.Optional[torch.FloatTensor] = None numeric_values_scale: typing.Optional[torch.FloatTensor] = None output_attentions: typing.Optional[bool] = None output_hidden_states: typing.Optional[bool] = None return_dict: typing.Optional[bool] = None ) → transformers.models.tapas.modeling_tapas.TableQuestionAnsweringOutput or tuple(torch.FloatTensor)
Parameters
- input_ids (
torch.LongTensorof shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary. Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.call() for details. - attention_mask (
torch.FloatTensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
torch.LongTensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
torch.LongTensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
torch.FloatTensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]: - 1 indicates the head is not masked, - 0 indicates the head is masked. - inputs_embeds (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. - table_mask (
torch.LongTensorof shape(batch_size, seq_length), optional) — Mask for the table. Indicates which tokens belong to the table (1). Question tokens, table headers and padding are 0. - labels (
torch.LongTensorof shape(batch_size, seq_length), optional) — Labels per token for computing the hierarchical cell selection loss. This encodes the positions of the answer appearing in the table. Can be obtained using AutoTokenizer.- 1 for tokens that are part of the answer,
- 0 for tokens that are not part of the answer.
- aggregation_labels (
torch.LongTensorof shape(batch_size, ), optional) — Aggregation function index for every example in the batch for computing the aggregation loss. Indices should be in[0, ..., config.num_aggregation_labels - 1]. Only required in case of strong supervision for aggregation (WikiSQL-supervised). - float_answer (
torch.FloatTensorof shape(batch_size, ), optional) — Float answer for every example in the batch. Set to float(‘nan’) for cell selection questions. Only required in case of weak supervision (WTQ) to calculate the aggregate mask and regression loss. - numeric_values (
torch.FloatTensorof shape(batch_size, seq_length), optional) — Numeric values of every token, NaN for tokens which are not numeric values. Can be obtained using AutoTokenizer. Only required in case of weak supervision for aggregation (WTQ) to calculate the regression loss. - numeric_values_scale (
torch.FloatTensorof shape(batch_size, seq_length), optional) — Scale of the numeric values of every token. Can be obtained using AutoTokenizer. Only required in case of weak supervision for aggregation (WTQ) to calculate the regression loss.
Returns
transformers.models.tapas.modeling_tapas.TableQuestionAnsweringOutput or tuple(torch.FloatTensor)
A transformers.models.tapas.modeling_tapas.TableQuestionAnsweringOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (TapasConfig) and inputs.
- loss (
torch.FloatTensorof shape(1,), optional, returned whenlabels(and possiblyanswer,aggregation_labels,numeric_valuesandnumeric_values_scaleare provided)) — Total loss as the sum of the hierarchical cell selection log-likelihood loss and (optionally) the semi-supervised regression loss and (optionally) supervised loss for aggregations. - logits (
torch.FloatTensorof shape(batch_size, sequence_length)) — Prediction scores of the cell selection head, for every token. - logits_aggregation (
torch.FloatTensor, optional, of shape(batch_size, num_aggregation_labels)) — Prediction scores of the aggregation head, for every aggregation operator. - hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TapasForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasForQuestionAnswering
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base-finetuned-wtq")
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base-finetuned-wtq")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> queries = ["How many movies has George Clooney played in?", "How old is Brad Pitt?"]
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> logits_aggregation = outputs.logits_aggregationTFTapasModel
class transformers.TFTapasModel
< source >( *args **kwargs )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Tapas Model transformer outputting raw hidden-states without any specific head on top.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or tuple(tf.Tensor)
Parameters
- input_ids (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation).
Returns
transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFBaseModelOutputWithPooling or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (TapasConfig) and inputs.
-
last_hidden_state (
tf.Tensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
tf.Tensorof shape(batch_size, hidden_size)) — Last layer hidden-state of the first token of the sequence (classification token) further processed by a Linear layer and a Tanh activation function. The Linear layer weights are trained from the next sentence prediction (classification) objective during pretraining.This output is usually not a good summary of the semantic content of the input, you’re often better with averaging or pooling the sequence of hidden-states for the whole input sequence.
-
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFTapasModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasModel
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base")
>>> model = TapasModel.from_pretrained("google/tapas-base")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> queries = ["How many movies has George Clooney played in?", "How old is Brad Pitt?"]
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_stateTFTapasForMaskedLM
class transformers.TFTapasForMaskedLM
< source >( *args **kwargs )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tapas Model with a language modeling head on top.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFMaskedLMOutput or tuple(tf.Tensor)
Parameters
- input_ids (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation). - labels (
tf.Tensorornp.ndarrayof shape(batch_size, sequence_length), optional) — Labels for computing the masked language modeling loss. Indices should be in[-100, 0, ..., config.vocab_size](seeinput_idsdocstring) Tokens with indices set to-100are ignored (masked), the loss is only computed for the tokens with labels in[0, ..., config.vocab_size]
Returns
transformers.modeling_tf_outputs.TFMaskedLMOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFMaskedLMOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (TapasConfig) and inputs.
-
loss (
tf.Tensorof shape(n,), optional, where n is the number of non-masked labels, returned whenlabelsis provided) — Masked language modeling (MLM) loss. -
logits (
tf.Tensorof shape(batch_size, sequence_length, config.vocab_size)) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax). -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFTapasForMaskedLM forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasForMaskedLM
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base")
>>> model = TapasForMaskedLM.from_pretrained("google/tapas-base")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> inputs = tokenizer(
... table=table, queries="How many [MASK] has George [MASK] played in?", return_tensors="tf"
... )
>>> labels = tokenizer(
... table=table, queries="How many movies has George Clooney played in?", return_tensors="tf"
... )["input_ids"]
>>> outputs = model(**inputs, labels=labels)
>>> logits = outputs.logitsTFTapasForSequenceClassification
class transformers.TFTapasForSequenceClassification
< source >( *args **kwargs )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tapas Model with a sequence classification head on top (a linear layer on top of the pooled output), e.g. for table entailment tasks, such as TabFact (Chen et al., 2020).
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
Parameters
- input_ids (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, num_choices, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape(batch_size, num_choices, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape(batch_size, num_choices, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
np.ndarrayortf.Tensorof shape(batch_size, num_choices, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape(batch_size, num_choices, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation). - labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the sequence classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy). Note: this is called “classification_class_index” in the original implementation.
Returns
transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
A transformers.modeling_tf_outputs.TFSequenceClassifierOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (TapasConfig) and inputs.
-
loss (
tf.Tensorof shape(batch_size, ), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
tf.Tensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFTapasForSequenceClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasForSequenceClassification
>>> import tensorflow as tf
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base-finetuned-tabfact")
>>> model = TapasForSequenceClassification.from_pretrained("google/tapas-base-finetuned-tabfact")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> queries = [
... "There is only one actor who is 45 years old",
... "There are 3 actors which played in more than 60 movies",
... ]
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
>>> labels = tf.convert_to_tensor([1, 0]) # 1 means entailed, 0 means refuted
>>> outputs = model(**inputs, labels=labels)
>>> loss = outputs.loss
>>> logits = outputs.logitsTFTapasForQuestionAnswering
class transformers.TFTapasForQuestionAnswering
< source >( *args **kwargs )
Parameters
- config (TapasConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Tapas Model with a cell selection head and optional aggregation head on top for question-answering tasks on tables
(linear layers on top of the hidden-states output to compute logits and optional logits_aggregation), e.g. for
SQA, WTQ or WikiSQL-supervised tasks.
This model inherits from TFPreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a tf.keras.Model subclass. Use it as a regular TF 2.0 Keras Model and refer to the TF 2.0 documentation for all matter related to general usage and behavior.
TensorFlow models and layers in transformers accept two formats as input:
- having all inputs as keyword arguments (like PyTorch models), or
- having all inputs as a list, tuple or dict in the first positional argument.
The reason the second format is supported is that Keras methods prefer this format when passing inputs to models
and layers. Because of this support, when using methods like model.fit() things should “just work” for you - just
pass your inputs and labels in any format that model.fit() supports! If, however, you want to use the second
format outside of Keras methods like fit() and predict(), such as when creating your own layers or models with
the Keras Functional API, there are three possibilities you can use to gather all the input Tensors in the first
positional argument:
- a single Tensor with
input_idsonly and nothing else:model(input_ids) - a list of varying length with one or several input Tensors IN THE ORDER given in the docstring:
model([input_ids, attention_mask])ormodel([input_ids, attention_mask, token_type_ids]) - a dictionary with one or several input Tensors associated to the input names given in the docstring:
model({"input_ids": input_ids, "token_type_ids": token_type_ids})
Note that when creating models and layers with subclassing then you don’t need to worry about any of this, as you can just pass inputs like you would to any other Python function!
call
< source >( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None table_mask: np.ndarray | tf.Tensor | None = None aggregation_labels: np.ndarray | tf.Tensor | None = None float_answer: np.ndarray | tf.Tensor | None = None numeric_values: np.ndarray | tf.Tensor | None = None numeric_values_scale: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → transformers.models.tapas.modeling_tf_tapas.TFTableQuestionAnsweringOutput or tuple(tf.Tensor)
Parameters
- input_ids (
np.ndarray,tf.Tensor,List[tf.Tensor]`Dict[str, tf.Tensor]orDict[str, np.ndarray]and each example must have the shape(batch_size, sequence_length)) — Indices of input sequence tokens in the vocabulary.Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.call() and PreTrainedTokenizer.encode() for details.
- attention_mask (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length), optional) — Mask to avoid performing attention on padding token indices. Mask values selected in[0, 1]:- 1 for tokens that are not masked,
- 0 for tokens that are masked.
- token_type_ids (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length, 7), optional) — Token indices that encode tabular structure. Indices can be obtained using AutoTokenizer. See this class for more info. - position_ids (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length), optional) — Indices of positions of each input sequence tokens in the position embeddings. Ifreset_position_index_per_cellof TapasConfig is set toTrue, relative position embeddings will be used. Selected in the range[0, config.max_position_embeddings - 1]. - head_mask (
np.ndarrayortf.Tensorof shape(num_heads,)or(num_layers, num_heads), optional) — Mask to nullify selected heads of the self-attention modules. Mask values selected in[0, 1]:- 1 indicates the head is not masked,
- 0 indicates the head is masked.
- inputs_embeds (
np.ndarrayortf.Tensorof shape(batch_size, sequence_length, hidden_size), optional) — Optionally, instead of passinginput_idsyou can choose to directly pass an embedded representation. This is useful if you want more control over how to convertinput_idsindices into associated vectors than the model’s internal embedding lookup matrix. - output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. This argument can be used only in eager mode, in graph mode the value in the config will be used instead. - return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. This argument can be used in eager mode, in graph mode the value will always be set to True. - training (
bool, optional, defaults to `False“) — Whether or not to use the model in training mode (some modules like dropout modules have different behaviors between training and evaluation). - table_mask (
tf.Tensorof shape(batch_size, seq_length), optional) — Mask for the table. Indicates which tokens belong to the table (1). Question tokens, table headers and padding are 0. - labels (
tf.Tensorof shape(batch_size, seq_length), optional) — Labels per token for computing the hierarchical cell selection loss. This encodes the positions of the answer appearing in the table. Can be obtained using AutoTokenizer.- 1 for tokens that are part of the answer,
- 0 for tokens that are not part of the answer.
- aggregation_labels (
tf.Tensorof shape(batch_size, ), optional) — Aggregation function index for every example in the batch for computing the aggregation loss. Indices should be in[0, ..., config.num_aggregation_labels - 1]. Only required in case of strong supervision for aggregation (WikiSQL-supervised). - float_answer (
tf.Tensorof shape(batch_size, ), optional) — Float answer for every example in the batch. Set to float(‘nan’) for cell selection questions. Only required in case of weak supervision (WTQ) to calculate the aggregate mask and regression loss. - numeric_values (
tf.Tensorof shape(batch_size, seq_length), optional) — Numeric values of every token, NaN for tokens which are not numeric values. Can be obtained using AutoTokenizer. Only required in case of weak supervision for aggregation (WTQ) to calculate the regression loss. - numeric_values_scale (
tf.Tensorof shape(batch_size, seq_length), optional) — Scale of the numeric values of every token. Can be obtained using AutoTokenizer. Only required in case of weak supervision for aggregation (WTQ) to calculate the regression loss.
Returns
transformers.models.tapas.modeling_tf_tapas.TFTableQuestionAnsweringOutput or tuple(tf.Tensor)
A transformers.models.tapas.modeling_tf_tapas.TFTableQuestionAnsweringOutput or a tuple of tf.Tensor (if
return_dict=False is passed or when config.return_dict=False) comprising various elements depending on the
configuration (TapasConfig) and inputs.
- loss (
tf.Tensorof shape(1,), optional, returned whenlabels(and possiblyanswer,aggregation_labels,numeric_valuesandnumeric_values_scaleare provided)) — Total loss as the sum of the hierarchical cell selection log-likelihood loss and (optionally) the semi-supervised regression loss and (optionally) supervised loss for aggregations. - logits (
tf.Tensorof shape(batch_size, sequence_length)) — Prediction scores of the cell selection head, for every token. - logits_aggregation (
tf.Tensor, optional, of shape(batch_size, num_aggregation_labels)) — Prediction scores of the aggregation head, for every aggregation operator. - hidden_states (
tuple(tf.Tensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftf.Tensor(one for the output of the embeddings + one for the output of each layer) of shape(batch_size, sequence_length, hidden_size). Hidden-states of the model at the output of each layer plus the initial embedding outputs. - attentions (
tuple(tf.Tensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftf.Tensor(one for each layer) of shape(batch_size, num_heads, sequence_length, sequence_length). Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The TFTapasForQuestionAnswering forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Examples:
>>> from transformers import AutoTokenizer, TapasForQuestionAnswering
>>> import pandas as pd
>>> tokenizer = AutoTokenizer.from_pretrained("google/tapas-base-finetuned-wtq")
>>> model = TapasForQuestionAnswering.from_pretrained("google/tapas-base-finetuned-wtq")
>>> data = {
... "Actors": ["Brad Pitt", "Leonardo Di Caprio", "George Clooney"],
... "Age": ["56", "45", "59"],
... "Number of movies": ["87", "53", "69"],
... }
>>> table = pd.DataFrame.from_dict(data)
>>> queries = ["How many movies has George Clooney played in?", "How old is Brad Pitt?"]
>>> inputs = tokenizer(table=table, queries=queries, padding="max_length", return_tensors="tf")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> logits_aggregation = outputs.logits_aggregation