Transformers documentation
Neighborhood Attention Transformer
Neighborhood Attention Transformer
Overview
NAT was proposed in Neighborhood Attention Transformer by Ali Hassani, Steven Walton, Jiachen Li, Shen Li, and Humphrey Shi.
It is a hierarchical vision transformer based on Neighborhood Attention, a sliding-window self attention pattern.
The abstract from the paper is the following:
We present Neighborhood Attention (NA), the first efficient and scalable sliding-window attention mechanism for vision. NA is a pixel-wise operation, localizing self attention (SA) to the nearest neighboring pixels, and therefore enjoys a linear time and space complexity compared to the quadratic complexity of SA. The sliding-window pattern allows NA’s receptive field to grow without needing extra pixel shifts, and preserves translational equivariance, unlike Swin Transformer’s Window Self Attention (WSA). We develop NATTEN (Neighborhood Attention Extension), a Python package with efficient C++ and CUDA kernels, which allows NA to run up to 40% faster than Swin’s WSA while using up to 25% less memory. We further present Neighborhood Attention Transformer (NAT), a new hierarchical transformer design based on NA that boosts image classification and downstream vision performance. Experimental results on NAT are competitive; NAT-Tiny reaches 83.2% top-1 accuracy on ImageNet, 51.4% mAP on MS-COCO and 48.4% mIoU on ADE20K, which is 1.9% ImageNet accuracy, 1.0% COCO mAP, and 2.6% ADE20K mIoU improvement over a Swin model with similar size.
Tips:
- One can use the AutoImageProcessor API to prepare images for the model.
- NAT can be used as a backbone. When
output_hidden_states = True, it will output bothhidden_statesandreshaped_hidden_states. Thereshaped_hidden_stateshave a shape of(batch, num_channels, height, width)rather than(batch_size, height, width, num_channels).
Notes:
- NAT depends on NATTEN’s implementation of Neighborhood Attention.
You can install it with pre-built wheels for Linux by referring to shi-labs.com/natten,
or build on your system by running
pip install natten. Note that the latter will likely take time to compile. NATTEN does not support Windows devices yet. - Patch size of 4 is only supported at the moment.
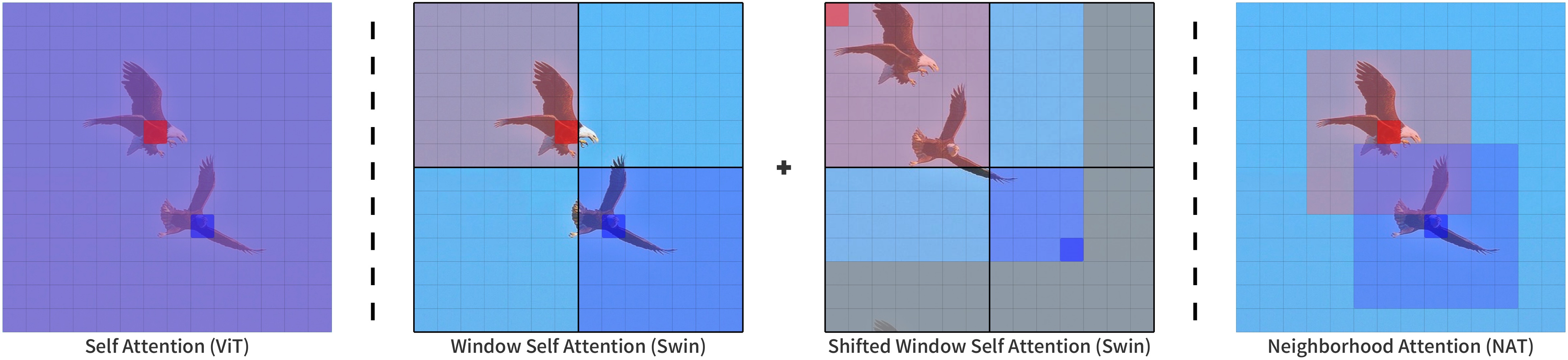 Neighborhood Attention compared to other attention patterns.
Taken from the original paper.
Neighborhood Attention compared to other attention patterns.
Taken from the original paper.
This model was contributed by Ali Hassani. The original code can be found here.
Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with NAT.
- NatForImageClassification is supported by this example script and notebook.
- See also: Image classification task guide
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
NatConfig
class transformers.NatConfig
< source >( patch_size = 4 num_channels = 3 embed_dim = 64 depths = [3, 4, 6, 5] num_heads = [2, 4, 8, 16] kernel_size = 7 mlp_ratio = 3.0 qkv_bias = True hidden_dropout_prob = 0.0 attention_probs_dropout_prob = 0.0 drop_path_rate = 0.1 hidden_act = 'gelu' initializer_range = 0.02 layer_norm_eps = 1e-05 layer_scale_init_value = 0.0 out_features = None out_indices = None **kwargs )
Parameters
-
patch_size (
int, optional, defaults to 4) — The size (resolution) of each patch. NOTE: Only patch size of 4 is supported at the moment. -
num_channels (
int, optional, defaults to 3) — The number of input channels. -
embed_dim (
int, optional, defaults to 64) — Dimensionality of patch embedding. -
depths (
List[int], optional, defaults to[2, 2, 6, 2]) — Number of layers in each level of the encoder. -
num_heads (
List[int], optional, defaults to[3, 6, 12, 24]) — Number of attention heads in each layer of the Transformer encoder. -
kernel_size (
int, optional, defaults to 7) — Neighborhood Attention kernel size. -
mlp_ratio (
float, optional, defaults to 3.0) — Ratio of MLP hidden dimensionality to embedding dimensionality. -
qkv_bias (
bool, optional, defaults toTrue) — Whether or not a learnable bias should be added to the queries, keys and values. -
hidden_dropout_prob (
float, optional, defaults to 0.0) — The dropout probability for all fully connected layers in the embeddings and encoder. -
attention_probs_dropout_prob (
float, optional, defaults to 0.0) — The dropout ratio for the attention probabilities. -
drop_path_rate (
float, optional, defaults to 0.1) — Stochastic depth rate. -
hidden_act (
strorfunction, optional, defaults to"gelu") — The non-linear activation function (function or string) in the encoder. If string,"gelu","relu","selu"and"gelu_new"are supported. -
initializer_range (
float, optional, defaults to 0.02) — The standard deviation of the truncated_normal_initializer for initializing all weight matrices. -
layer_norm_eps (
float, optional, defaults to 1e-12) — The epsilon used by the layer normalization layers. -
layer_scale_init_value (
float, optional, defaults to 0.0) — The initial value for the layer scale. Disabled if <=0. -
out_features (
List[str], optional) — If used as backbone, list of features to output. Can be any of"stem","stage1","stage2", etc. (depending on how many stages the model has). If unset andout_indicesis set, will default to the corresponding stages. If unset andout_indicesis unset, will default to the last stage. -
out_indices (
List[int], optional) — If used as backbone, list of indices of features to output. Can be any of 0, 1, 2, etc. (depending on how many stages the model has). If unset andout_featuresis set, will default to the corresponding stages. If unset andout_featuresis unset, will default to the last stage.
This is the configuration class to store the configuration of a NatModel. It is used to instantiate a Nat model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the Nat shi-labs/nat-mini-in1k-224 architecture.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
Example:
>>> from transformers import NatConfig, NatModel
>>> # Initializing a Nat shi-labs/nat-mini-in1k-224 style configuration
>>> configuration = NatConfig()
>>> # Initializing a model (with random weights) from the shi-labs/nat-mini-in1k-224 style configuration
>>> model = NatModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.configNatModel
class transformers.NatModel
< source >( config add_pooling_layer = True )
Parameters
- config (NatConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
The bare Nat Model transformer outputting raw hidden-states without any specific head on top. This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: typing.Optional[torch.FloatTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.models.nat.modeling_nat.NatModelOutput or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViTImageProcessor.call() for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple.
Returns
transformers.models.nat.modeling_nat.NatModelOutput or tuple(torch.FloatTensor)
A transformers.models.nat.modeling_nat.NatModelOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (NatConfig) and inputs.
-
last_hidden_state (
torch.FloatTensorof shape(batch_size, sequence_length, hidden_size)) — Sequence of hidden-states at the output of the last layer of the model. -
pooler_output (
torch.FloatTensorof shape(batch_size, hidden_size), optional, returned whenadd_pooling_layer=Trueis passed) — Average pooling of the last layer hidden-state. -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each stage) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each stage) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
reshaped_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each stage) of shape(batch_size, hidden_size, height, width).Hidden-states of the model at the output of each layer plus the initial embedding outputs reshaped to include the spatial dimensions.
The NatModel forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoImageProcessor, NatModel
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> model = NatModel.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
[1, 7, 7, 512]NatForImageClassification
class transformers.NatForImageClassification
< source >( config )
Parameters
- config (NatConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Nat Model transformer with an image classification head on top (a linear layer on top of the final hidden state of the [CLS] token) e.g. for ImageNet.
This model is a PyTorch torch.nn.Module sub-class. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
forward
< source >(
pixel_values: typing.Optional[torch.FloatTensor] = None
labels: typing.Optional[torch.LongTensor] = None
output_attentions: typing.Optional[bool] = None
output_hidden_states: typing.Optional[bool] = None
return_dict: typing.Optional[bool] = None
)
→
transformers.models.nat.modeling_nat.NatImageClassifierOutput or tuple(torch.FloatTensor)
Parameters
-
pixel_values (
torch.FloatTensorof shape(batch_size, num_channels, height, width)) — Pixel values. Pixel values can be obtained using AutoImageProcessor. See ViTImageProcessor.call() for details. -
output_attentions (
bool, optional) — Whether or not to return the attentions tensors of all attention layers. Seeattentionsunder returned tensors for more detail. -
output_hidden_states (
bool, optional) — Whether or not to return the hidden states of all layers. Seehidden_statesunder returned tensors for more detail. -
return_dict (
bool, optional) — Whether or not to return a ModelOutput instead of a plain tuple. -
labels (
torch.LongTensorof shape(batch_size,), optional) — Labels for computing the image classification/regression loss. Indices should be in[0, ..., config.num_labels - 1]. Ifconfig.num_labels == 1a regression loss is computed (Mean-Square loss), Ifconfig.num_labels > 1a classification loss is computed (Cross-Entropy).
Returns
transformers.models.nat.modeling_nat.NatImageClassifierOutput or tuple(torch.FloatTensor)
A transformers.models.nat.modeling_nat.NatImageClassifierOutput or a tuple of
torch.FloatTensor (if return_dict=False is passed or when config.return_dict=False) comprising various
elements depending on the configuration (NatConfig) and inputs.
-
loss (
torch.FloatTensorof shape(1,), optional, returned whenlabelsis provided) — Classification (or regression if config.num_labels==1) loss. -
logits (
torch.FloatTensorof shape(batch_size, config.num_labels)) — Classification (or regression if config.num_labels==1) scores (before SoftMax). -
hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each stage) of shape(batch_size, sequence_length, hidden_size).Hidden-states of the model at the output of each layer plus the initial embedding outputs.
-
attentions (
tuple(torch.FloatTensor), optional, returned whenoutput_attentions=Trueis passed or whenconfig.output_attentions=True) — Tuple oftorch.FloatTensor(one for each stage) of shape(batch_size, num_heads, sequence_length, sequence_length).Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
-
reshaped_hidden_states (
tuple(torch.FloatTensor), optional, returned whenoutput_hidden_states=Trueis passed or whenconfig.output_hidden_states=True) — Tuple oftorch.FloatTensor(one for the output of the embeddings + one for the output of each stage) of shape(batch_size, hidden_size, height, width).Hidden-states of the model at the output of each layer plus the initial embedding outputs reshaped to include the spatial dimensions.
The NatForImageClassification forward method, overrides the __call__ special method.
Although the recipe for forward pass needs to be defined within this function, one should call the Module
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
Example:
>>> from transformers import AutoImageProcessor, NatForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> model = NatForImageClassification.from_pretrained("shi-labs/nat-mini-in1k-224")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
tiger cat